Taurus.MVC 性能压力测试(ap 压测 和 linux 下wrk 压测):.NET Core 版本
前言:
最近的 Taurus.MVC 版本,对性能这一块有了不少优化,因此准备进行一下压测,来测试并记录一下 Taurus.MVC 框架的性能,以便后续持续优化改进。
今天先压测 .NET Core 版本,后续有时间再压测一下.NET 版本。
下面来看不同场景下的压测结果,以下测试结果会由两台电脑进行分别测试。
一、旧电脑环境:
CPU :Intel(R) Core(TM) i5-9400 CPU @ 2.90GHz内核:6逻辑处理器:6
内存:16G
程序在 .NET8 编绎,以 Kestrel 为主机直接运行在 Window 环境:
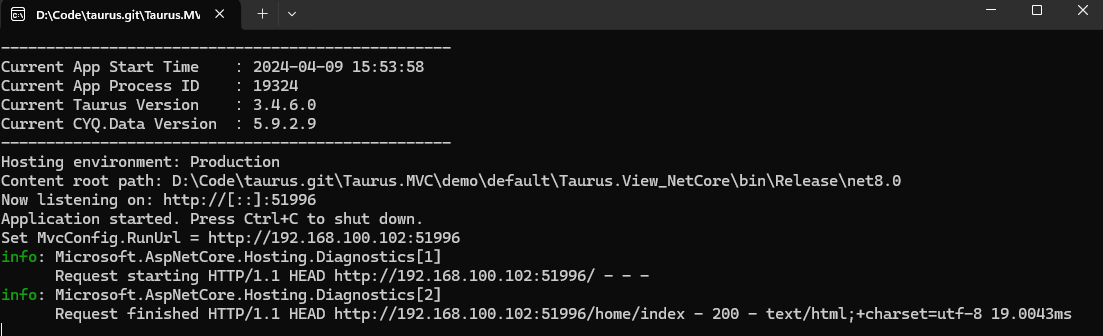
1、测试 Window 11 下,单机ab工具压测:
由于ab工具占用资源不多,发起的并发能力也有限,先用它进行本机压测,试试水。
ab的版本信息:

A、先测试单线程的运行性能(简单接口返回,控制台带日志输出):
ab -n 100000 -c 1 http://192.168.100.102:51996/api/hello
测试结果:并发数1,qps = 3263
Server Software:
Server Hostname:192.168.100.102Server Port:51996Document Path:/api/hello
Document Length:24bytes
Concurrency Level:1Time takenfor tests: 30.641seconds
Complete requests:100000Failed requests:0Write errors:0Total transferred:13900000bytes
HTML transferred:2400000bytes
Requests per second:3263.63 [#/sec] (mean)
Time per request:0.306[ms] (mean)
Time per request:0.306[ms] (mean, across all concurrent requests)
Transfer rate:443.01 [Kbytes/sec] received
看一下程序运行的时间:
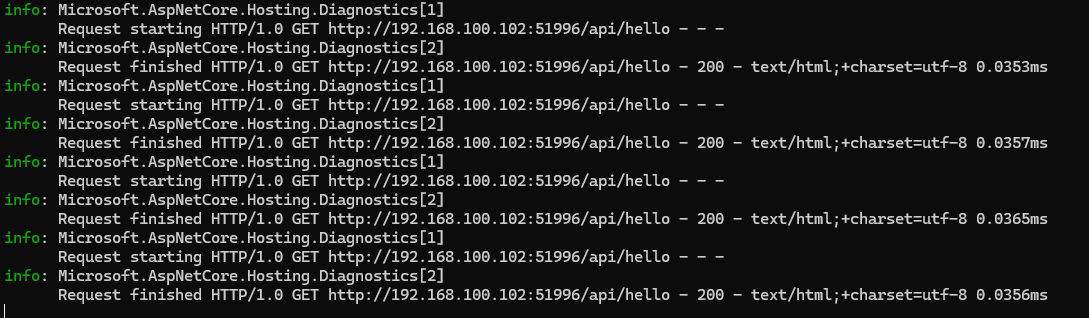
从程序打印的日志上看,接口执行时间仅有0.03毫秒,理论值单线程压测是可以达到1000/0.0345= 28089,
去掉控制器日志输出,还能再提升1下,再配置个64核cpu,就是传说中的轻轻松松的单机百万qps了。
B、我们调整一下参数,看看ab在单机下能压出多少来(简单接口返回,控制台带日志输出):
ab -n 100000 -c 2 http://192.168.100.102:51996/api/hello
测试结果:
Concurrency Level: 2Time takenfor tests: 18.187seconds
Complete requests:100000Failed requests:0Write errors:0Total transferred:13900000bytes
HTML transferred:2400000bytes
Requests per second:5498.28 [#/sec] (mean)
Time per request:0.364[ms] (mean)
Time per request:0.182[ms] (mean, across all concurrent requests)
Transfer rate:746.35 [Kbytes/sec] received
没办法,只能压 2 个并发链接,CPU 跑满了,程序占40%多,ab也占了40%多,说好的ab不吃资源的,直接cpu拉走一半,呵呵。
C、我们关闭日志输出,重新看看上面的两个能测试出多少(简单接口返回,控制台无日志输出):
我们添加以下代码,关闭 Kestrel 默认的控制台信息输出:
services.AddLogging(op => op.SetMinimumLevel(LogLevel.None));
【后续的测试,都保持控制器日志关闭】
重新编绎后,进行重新测试:
测试结果:并发数1,qps = 3595
Concurrency Level: 1Time takenfor tests: 2.781seconds
Complete requests:10000Failed requests:0Write errors:0Total transferred:1390000bytes
HTML transferred:240000bytes
Requests per second:3595.51 [#/sec] (mean)
Time per request:0.278[ms] (mean)
Time per request:0.278[ms] (mean, across all concurrent requests)
Transfer rate:488.06 [Kbytes/sec] received
关闭日志,提升了300多,后续测试,将会保持控制台日志的关闭。
测试结果:并发数 2,qps = 5765
Concurrency Level: 2Time takenfor tests: 1.734seconds
Complete requests:10000Failed requests:0Write errors:0Total transferred:1390000bytes
HTML transferred:240000bytes
Requests per second:5765.77 [#/sec] (mean)
Time per request:0.347[ms] (mean)
Time per request:0.173[ms] (mean, across all concurrent requests)
Transfer rate:782.66 [Kbytes/sec] received
接下来,我们将接口调整一下,单纯的返回 Hello World 没啥看头,改成常规一些。
D、使用 CYQ.Data 读数据库,输出 Json,来看看压测结果(读数据库接口,控制台无日志输出)
测试代码:
public void Hello(stringmsg)
{string conn = "server=.;database=MSLog;uid=sa;pwd=123456";using (MProc proc = new MProc("select top 1 * from SysLogs", conn))
{
Write(proc.ExeJson());
}
}
运行结果:返回一条数据:

下面直接进行压测结果:并发数 2 ,qps = 5470,和未关闭日志输出时差不多。
Concurrency Level: 2Time takenfor tests: 1.828seconds
Complete requests:10000Failed requests:0Write errors:0Total transferred:10810000bytes
HTML transferred:9590000bytes
Requests per second:5470.23 [#/sec] (mean)
Time per request:0.366[ms] (mean)
Time per request:0.183[ms] (mean, across all concurrent requests)
Transfer rate:5774.73 [Kbytes/sec] received
小结:
从上面的测试结果,观察CPU中可以看出,ab 这个工具,吃 cpu 资源不说,其并发数量也有限。
下面更换 wrk 进行测试,由于 wrk 只能在 linux 中运行,因此在本机上,开启了虚拟机。
2、测试 Window 11 下,虚拟机wrk工具压测:(读数据库输出,控制台无日志输出)
虚拟机环境:
CPU :Intel(R) Core(TM) i5-9400 CPU @ 2.90GHz
内核:2逻辑处理器:2内存:4G
分完虚拟机后,本机就剩下 4 核了,再去掉打开任务管理器,就占掉了10%的cpu,我了个去,当个3核用了。
不过问题不大,尽管测就是了,为了保持接口的通用性,继续使用读数据库输出 Json 的接口:
先使用1线程1并发测试试试水:
wrk -t 1 -c1 -d 10s http://192.168.100.102:51996/api/hello
测试结果:qps = 1518
Running 10s test @ http://192.168.100.102:51996/api/hello 1 threads and 1connections
Thread Stats Avg Stdev Max+/-Stdev
Latency2.76ms 14.97ms 200.26ms 98.45%Req/Sec 1.54k 402.67 2.62k 73.74% 15294 requests in 10.07s, 16.07MB read
Requests/sec: 1518.47Transfer/sec: 1.60MB
测试过程,通过虚拟机(top 指令)和Windows(任务管理器)观察 cpu,发现没怎么动,看来 wrk 要跑满性能,得加量。
我们给虚拟机分了2个核,不能浪费,要跑满它,于是不断调整参数:
wrk -t 2 -c4096 -d 10s http://192.168.100.102:51996/api/hello
测试结果:qps = 23303
Running 10s test @ http://192.168.100.102:51996/api/hello 2 threads and 4096connections
Thread Stats Avg Stdev Max+/-Stdev
Latency28.17ms 19.27ms 307.26ms 82.72%Req/Sec 11.63k 12.33k 37.01k 77.53% 234427 requests in 10.06s, 246.37MB read
Socket errors: connect3077, read 0, write 0, timeout 0Requests/sec: 23303.58Transfer/sec: 24.49MB
从测试结果观察,wrk 更能压测出性能的极限,当然,这是 wrk 的极限,不是程序的极限。
因为整个压测过程,程序只占了30%左右的cpu,但没办法,cpu 让其它资源给吃光了。
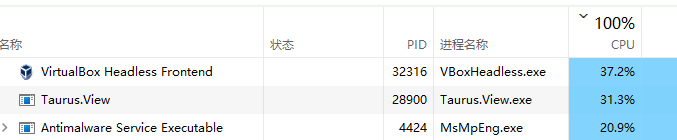
我们知道,.NET Core 的程序,跑在 Linux 下,能会有更优的性能,不过不急先。
由于本机资源有限,干扰程序较多,这里打算拿出我的新电脑,来进行重新测试,看看程序在新电脑的表现如何。
二、新电脑环境:
CPU 13th Gen Intel(R) Core(TM) i5-13600KF内核:14逻辑处理器:20内存:64G
接下来,我们看看新电脑的表现如何,使用一样的程序:
1、测试 Window 11 下,单机ab工具压测:
A、先测试单线程的运行性能(简单接口返回,控制台无日志输出):
ab -n 100000 -c 1 http://192.168.100.102:51996/api/hello
测试结果:并发数1,qps = 11389
Concurrency Level: 1Time takenfor tests: 0.878seconds
Complete requests:10000Failed requests:0Write errors:0Total transferred:1410000bytes
HTML transferred:260000bytes
Requests per second:11389.76 [#/sec] (mean)
Time per request:0.088[ms] (mean)
Time per request:0.088[ms] (mean, across all concurrent requests)
Transfer rate:1568.32 [Kbytes/sec] received
B、我们调整一下参数,看看ab在单机下能压出多少来(简单接口返回,控制台无日志输出):
ab -n 100000 -c 4 http://192.168.100.101:51996/api/hello
测试结果:并发数4,qps = 18247
Concurrency Level: 4Time takenfor tests: 5.480seconds
Complete requests:100000Failed requests:0Write errors:0Total transferred:14100000bytes
HTML transferred:2600000bytes
Requests per second:18247.09 [#/sec] (mean)
Time per request:0.219[ms] (mean)
Time per request:0.055[ms] (mean, across all concurrent requests)
Transfer rate:2512.54 [Kbytes/sec] received
看来 ab 不行啊,压不出结果,程序的cpu才跑了不到2%。
小结:
虽然 ab 压测不够力,但从单线程的测试结果可以看出,新电脑的cpu运行效率是旧电脑性能的3倍左右,效率拉满。
以此看出,平时在采购云服务器时,也得顺带关注一下CPU的型号,好的型号,能提升运行效率,提高并发。2、测试 Window 11 下,虚拟机wrk工具压测:(简单接口,控制台无日志输出)
虚拟机环境:
CPU 13th Gen Intel(R) Core(TM) i5-13600KF内核: 2逻辑处理器: 2内存:4G先给虚拟机2核,本机剩下 12 核了,可以好好压一下了。
wrk -t 1 -c 1 -d 10s http://192.168.100.101:51996/api/hello
测试结果:1并发,qps = 14084
Running 10s test @ http://192.168.100.101:51996/api/hello 1 threads and 1connections
Thread Stats Avg Stdev Max+/-Stdev
Latency6.43ms 29.09ms 218.31ms 95.10%Req/Sec 14.43k 3.27k 17.98k 91.84% 141377 requests in 10.04s, 21.71MB read
Requests/sec: 14084.98Transfer/sec: 2.16MB
和 ab 一样,一个链接并发压不出什么效果,加大效果看看。
wrk -t 8 -c 2048 -d 10s http://192.168.100.101:51996/api/hello
测试结果:qps = 84306
Running 10s test @ http://192.168.100.101:51996/api/hello 28 threads and 2048connections
Thread Stats Avg Stdev Max+/-Stdev
Latency11.40ms 10.81ms 222.31ms 86.60%Req/Sec 5.35k 3.03k 18.81k 69.09% 850042 requests in 10.08s, 130.52MB read
Socket errors: connect1051, read 0, write 100, timeout 0Requests/sec: 84306.38Transfer/sec: 12.94MB
压测试过程,观察两个cpu,虚拟机(110%-130%,2核还没跑满),程序只跑16%-20%,整体40-50%左右,感觉还能往上跑。
估计是压力不够,试着分给虚拟机多2核,看看有没有效果。
虚拟机环境:
CPU 13th Gen Intel(R) Core(TM) i5-13600KF 内核: 4 逻辑处理器: 4 内存:8G
继续压测试:
wrk -t18 -c 1400 -d 60s http://192.168.100.101:51996/api/hello
测试结果:qps = 105462
Running 1m test @ http://192.168.100.101:51996/api/hello 18 threads and 1400connections
Thread Stats Avg Stdev Max+/-Stdev
Latency10.02ms 10.05ms 267.70ms 90.26%Req/Sec 6.68k 3.31k 17.16k 62.65% 6339226 requests in 1.00m, 0.95GB read
Socket errors: connect383, read 0, write 25, timeout 0Requests/sec: 105462.01Transfer/sec: 16.19MB
之前压测时间在10s-20s,qps 都在9万多,把压测时间拉长到1分钟,超过了10万了。
看来把压测时间拉长,qps 会高一点。
测试过程中,虚拟机CPU(在180%左右,给了4核,也不顶用,没能跑满),程序占用CPU(20%左右)。
还是跑不满,没办法,压力上不去了,只好换个口味测试。
重新压测 CYQ.Data 读数据库转Json输出的接口(数据库mssql2012 安装在Window 11 本机):
接口的调用输出:

进行压测:
wrk -t18 -c 1200 -d 60s http://192.168.100.101:51996/api/hellodb
测试结果:qps = 73122
Running 1m test @ http://192.168.100.101:51996/api/hellodb 18 threads and 1200connections
Thread Stats Avg Stdev Max+/-Stdev
Latency47.62ms 86.25ms 1.15s 85.85%Req/Sec 4.61k 2.10k 17.56k 68.95% 4394613 requests in 1.00m, 4.51GB read
Socket errors: connect185, read 0, write 24, timeout 1Requests/sec: 73122.19Transfer/sec: 76.85MB
再换一个,直接压 MVC 界面,看看效果。
这是压测试的 Taurus.MVC 的主界面:
修改压测路径:
wrk -t18 -c 1200 -d 60s http://192.168.100.101:51996/home/index
测试结果:qps = 39349
Running 1m test @ http://192.168.100.101:51996/home/index 18 threads and 1200connections
Thread Stats Avg Stdev Max+/-Stdev
Latency82.78ms 160.41ms 1.94s 87.98%Req/Sec 2.33k 0.94k 7.67k 67.93% 2364614 requests in 1.00m, 8.75GB read
Socket errors: connect185, read 0, write 0, timeout 918Requests/sec: 39349.00Transfer/sec: 149.13MB
这时候观察,虽然取得了不错的结果,但 CPU 跑满100%了,也有918个超时,看来呈现的加载与呈现,很消耗计算量。
到了最后的步骤了,.NET Core 程序,还是得放到 Linux 系统下跑看看效果 ,复制一台虚拟机,用来部署 .NET Core 程序。
3、测试 CentOS 7 下,虚拟机 wrk 工具压测:
新的虚拟机环境:
CPU 13th Gen Intel(R) Core(TM) i5-13600KF 内核: 8 逻辑处理器: 8 内存:8G
1、测试接口:直接压测 CYQ.Data 读数据库转Json输出的接口(数据库mssql2012安装在Window 11 系统):
wrk -t18 -c 1600 -d 60s http://192.168.100.666666:51996/api/hellodb
测试结果:qps = 80831
Running 1m test @ http://192.168.100.666666:51996/api/hellodb 18 threads and 1600connections
Thread Stats Avg Stdev Max+/-Stdev
Latency35.63ms 74.47ms 1.03s 87.97%Req/Sec 4.83k 2.67k 18.55k 69.03% 4856997 requests in 1.00m, 4.98GB read
Socket errors: connect581, read 0, write 0, timeout 0Requests/sec: 80831.35Transfer/sec: 84.95MB
观察CPU:压测虚拟机(130%左右,用了1.3个核左右),应用程序虚拟机(450%左右,用了4.5个核左右)
2、测试接口:直接测试简单接口
wrk -t18 -c 1600 -d 60s http://192.168.100.666666:51996/api/hello
测试结果:qps = 105994
Running 1m test @ http://192.168.100.666666:51996/api/hello 18 threads and 1600connections
Thread Stats Avg Stdev Max+/-Stdev
Latency9.16ms 4.84ms 212.60ms 79.65%Req/Sec 6.32k 3.65k 27.06k 57.03% 6424281 requests in 1.00m, 0.95GB read
Socket errors: connect581, read 0, write 0, timeout 0Requests/sec: 106908.28Transfer/sec: 16.21MB
观察CPU:和上一个结果差不多,只用了虚拟机的50%左右,就是部署在Linux 上,随便调整参数,都轻松10万+。
总结:
对于 API 压测:
旧电脑轻松就打满CPU,主要是被ab和其它应用吃了资源,所以压测上不去,去掉虚拟机两核后,在读数据库转Json输出的情况下,压出了2万3的qps。
新电脑上限太高,wrk 都压不住,上10万+了,CPU也才20%左右,可见一个高效的CPU对并发的提升是多么明显。
新电脑在读数据库转Json输出的情况下,也有8万+的qps,这个3倍左右的效率,明显的有点明显了。
最后部署在 Linux,可以感觉性能明显比 Window 运行高一些,Window 需要小小调优参数才10万+,而 Linux 上随便调都10万+。
但因wrk给的压力也有限,10万+后无法再测试了,听说 ulimit -n 命令可以解锁,发起更大的并发,这个下次再试了。
对于 MVC 压测:
明显感觉 MVC 的计算量大了很多,wrk 提供的压力已足够跑满CPU,极限跑出近4万的qps,感觉后续应该还能小优化一下。
整体来说,今天的压力测试结果,除了压测试MVC界面,CPU 压满了,而压测试API,CPU 都没能跑满整机的30%,心累啊,先就到这里了。
附本文的运行程序:
TaurusMVC运行程序下载
- 解压后可直接运行 Taurus.View.exe,欢迎下载自行测试【需要.NET 8 运行环境】