园子周边第3季—设计初稿预览:2024夏天穿上博客园T恤 show your code
随着大小鼠标垫完成
上架
,园子周边的下一季,园子周边的重头戏,也拉开了帷幕,开始进行创意设计。
周边第3季是博客园T恤,暂定主题是:「2024夏天穿上博客园T恤 show your code」
今天我们将设计的第1版初稿发出来给大家预览,欢迎大家点评、反馈、多提宝贵建议。
款式1

款式2

款式3

款式4

相关链接:
随着大小鼠标垫完成
上架
,园子周边的下一季,园子周边的重头戏,也拉开了帷幕,开始进行创意设计。
周边第3季是博客园T恤,暂定主题是:「2024夏天穿上博客园T恤 show your code」
今天我们将设计的第1版初稿发出来给大家预览,欢迎大家点评、反馈、多提宝贵建议。
款式1
款式2
款式3
款式4
相关链接:
经过前面几篇的学习,我们了解到指令的大概分类,如:
参数加载指令,该加载指令以 Ld 开头,将参数加载到栈中,以便于后续执行操作命令。
参数存储指令,其指令以 St 开头,将栈中的数据,存储到指定的变量中,以方便后续使用。
创建实例指令,其指令以 New 开头,用于在运行时动态生成并初始化对象。
本篇介绍方法调用指令,该指令以 Call 开头,用于在运行时调用其它方法。
在.NET Emit 中,方法调用指令是一种关键的操作,它允许我们在运行时动态地调用各种方法。
这些指令提供了一种灵活的方式,可以在程序执行期间创建、修改和调用方法,从而实现了动态代码生成和操作的功能。
方法调用指令包括了一系列不同的操作码,每个操作码都代表了一种不同的调用方式,比如调用实例方法、静态方法或委托。
通过理解和应用这些方法调用指令,我们可以实现诸如动态代理、AOP(面向切面编程)、方法重写等高级功能,从而扩展了.NET平台的能力和灵活性。
在本文中,我们将深入探讨ILGenerator 指令方法中与方法调用相关的内容,包括不同调用指令的详细解释、示例和实践应用场景。
以下是两种常见的方法调用指令及其详细说明:
//调用静态方法 IL.Emit(OpCodes.Call, typeof(Console).GetMethod("WriteLine", new Type[] { typeof(string) }));//调用实例方法 IL.Emit(OpCodes.Call, typeof(MyClass).GetMethod("InstanceMethod"));
//调用虚方法 IL.Emit(OpCodes.Callvirt, typeof(BaseClass).GetMethod("VirtualMethod"));
这些指令提供了灵活的方法调用功能,可以在动态生成的代码中使用,也可以用于实现诸如反射、AOP等功能。
通过深入理解这些指令的工作原理和使用方法,我们可以更加灵活地操作.NET平台上的方法调用行为。
在面向对象的编程语言中,"Call" 和 "CallVirt" 通常用于描述方法(函数)的调用方式,它们之间的区别在于是否进行虚拟方法调用(Virtual Method Invocation)。
Call(直接调用):当使用 "Call" 调用方法时,编译器会在编译时确定要调用的方法,这意味着它会直接调用指定类的方法,而不考虑实际运行时对象的类型。这种方式通常用于非虚方法(non-virtual method)或静态方法(static method),因为这些方法在编译时就已经确定了调用的目标。
CallVirt(虚拟方法调用):而当使用 "CallVirt" 调用方法时,编译器会生成一段代码,在运行时根据实际对象的类型来确定要调用的方法。这意味着即使在编译时使用的是基类的引用或指针,但在运行时实际上调用的是子类的方法(如果子类重写了该方法)。这种方式通常用于虚方法(virtual method),以实现多态性(polymorphism)。
总的来说,"Call" 是在编译时确定调用的方法,而 "CallVirt" 则是在运行时根据对象的实际类型确定调用的方法,从而实现了多态性。
在多数实例方法的调用,使用 Call 方法调用,会有更优的性能(实例方法时:它减少了对象的Null检查与虚方法重写的寻找)。
看一下说明:

从参数的说明中,可以看出,它提供了基于Call、Callvirt、Newobj 三类指令的封装调用。
在使用过程中,对使用者容易造成混乱,代码也不美观,可以无视它。
在C#语法中,除了 unsafe 方法可以操作指针外,其它涉及指针(引用地址)的被封装后提供给使用的安全类型只有 ref、out、委托。
而涉及调用的只有委托,因此,下面来一个调用委托的示例代码:
单独的使用 Emit 的Calli 指令无法直接调用委托方法,我们需要使用它封装的辅助方法来使用。
看一下说明:

该方法提供基于 Calli 指令的封装,提供针对委托的调用,下面看一组示例代码。
调用示例:
public static voidPrintHello()
{
Console.WriteLine("Hello, world!");
}//...... ILGenerator il=methodBuilder.GetILGenerator();//加载一个委托实例到栈上 il.Emit(OpCodes.Ldftn, typeof(AssMethodIL_Call).GetMethod("PrintHello"));//使用 Calli 指令调用委托所指向的方法 il.EmitCalli(OpCodes.Calli, CallingConventions.Standard, typeof(void), null, null);
il.Emit(OpCodes.Ret);//返回该值
生成的对照代码:

有点偏离我们理解的代码了,好在它能正常执行。
我们在动态方法中运行它:

说明:
Ldftn 指令:Load Function 的简写,加载方法的引用地址。
本文探讨了.NET Emit 入门教程的第六部分,聚焦于ILGenerator中的方法调用指令。
通过详细分析 ILGenerator 的使用方法和方法调用指令,读者可以更深入地了解.NET平台下动态生成代码的实现机制。
通过本文的阅读,读者可以更加熟练地使用 ILGenerator 来动态生成高效、灵活的代码,为.NET应用程序的开发和优化提供更多可能性。
下一篇,我们继续探讨其它 IL 指令。
论文提出SFR模块,直接重新激活一组浅层特征来提升其在后续层的复用效率,而且整个重激活模式可端到端学习。由于重激活的稀疏性,额外引入的计算量非常小。从实验结果来看,基于SFR模块提出的CondeseNetV2性能还是很不错的,值得学习
来源:晓飞的算法工程笔记 公众号
论文: CondenseNet V2: Sparse Feature Reactivation for Deep Networks

目前大多数SOTA卷积网络都只能应用于算力充足的场景,而低算力场景往往是多数算法落地的实际场景,所以轻量级网络的研究是十分重要的。近期有研究认为DenseNet的长距离连接是低效的,较深的层往往将早期特征认定为过时并在生成新特征时将其忽略,造成了额外的内存和计算消耗。
为了缓解这一低效的设计,CondenseNet在训练过程中根据权重动态逐步裁剪不重要的层间连接,而ShuffleNetV2则通过分支和shuffle的设计使得层间连接随着层间距离增大而减少。对于这两个网络的具体介绍,可以看看公众号之前发的两篇解读:
《CondenseNet:可学习分组卷积,原作对DenseNet的轻量化改进 | CVPR 2018》
和
《ShuffleNetV1/V2简述 | 轻量级网络》
。
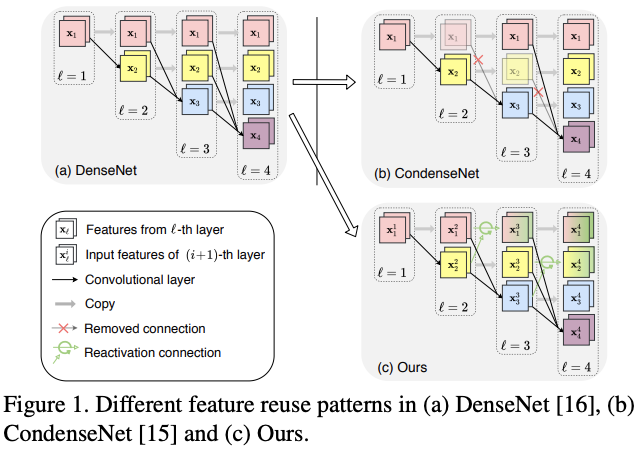
尽管上面的两个改进网络都有其提升,但论文认为直接淘汰浅层特征做法过于激进,浅层特征还是可能包含对生成深层特征有用的信息。在仔细研究后,论文提出了特征重激活(feature reactivation)的概念。整体思路如图1c所示,更新浅层特征从而可以更高效地被深层特征复用。
但需要注意的是,如果直接更新全部特征会带来过度的计算量,影响整体的效率。实际上,从DenseNet的成功可以看出,大部分的特征是不需要每次都更新的。为此,论文提出可学习的SFR(sparse feature reactivation)模块,通过学习的方式选择浅层特征进行重新激活,仅引入少量计算量就可以保持特征的"新鲜"。在应用时,SFR模块可转换分组卷积,复用当前的加速技术保证实践性能。
论文基于SFR模块和CondeseNet提出了CondenseNetV2,在性能和特征复用程度上都有很不错的表现,能媲美当前SOTA轻量级网络。实际上,SFR模块可简单地嵌入到任意卷积网络中,论文也将SFR模块嵌入ShuffleNetV2进行了相关实验,效果也是杠杠的。
先定义DenseNet中的特征复用机制。假设block共
\(L\)
层,每层的特征输出为
\(x_{l}\)
,
\(x_0\)
为block输入。由于当前层会以稠密连接的形式复用前面所有层的输出,
\(l\)
层的复合函数会接受所有的前层特征作为输入:
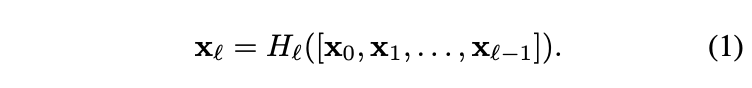
在CondenseNet中,
\(H_l\)
为可学习分组卷积(LGC),用于自动学习输入的分组以及去掉不重要的连接。而在ShuffleNet中,
\(H_l\)
的输入会根据与当前层的距离进行丢弃。上面的两种网络设计倾向于丢弃冗余的长距离连接,取得了很不错的性能提升,然而这样的设计可能会阻碍高效的特征复用机制的探索。实际上,导致深层不再使用浅层特征的主要原因是特征
\(x_l\)
一旦产生就不再改变。为此,论文提出计算消耗少的SFR模块,使得过时的特征可以被廉价地复用。
对第
\(l\)
层引入重激活模块
\(G_l(\cdot)\)
,该模块将层输入
\(x_l\)
转换为
\(y_l\)
,用于激活前面的层输出特征。定义激活操作
\(U(\cdot, \cdot)\)
为与
\(y_l\)
相加,稠密层的输入重激活可公式化为:

\(x_l^{out}\)
为重激活的输出特征,
\(l\)
层的可学习分组卷积操作
\(H(\cdot)\)
输出新特征
\(x_l\)
。此外,旧特征
\((x_i, i=1,\cdots,l-1)\)
会被重新激活以提高其作用。
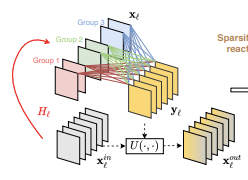
显然,重激活所有的特征是不必要的,DenseNet的成功说明大部分特征是不需要重新激活的,而且过多的重激活也会带来过多的额外计算。为此,论文希望能自动找到需要重激活的特征,只对这部分特征进行重激活。于是,论文提出了SFR(sparse feature reactivation)模块,如图2所示,基于剪枝的方法逐步达到这个目标。
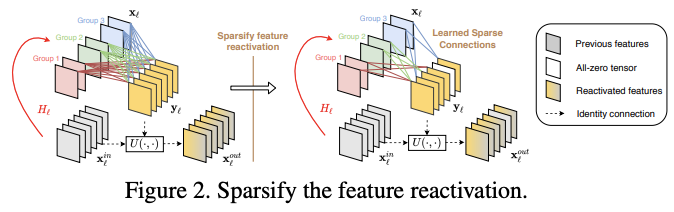
重激活模块
\(G_l(\cdot)\)
包含卷积层、BN层和ReLU层,卷积核的权值矩阵
\(F\)
的大小表示为
\((O, I)\)
,
\(O\)
和
\(I\)
分别表示输出维度和输入维度。将
\(G_l(\cdot)\)
模块的输入
\(x_l\)
分成
\(G\)
组,权值矩阵
\(F\)
也随之分为
\(G\)
组
\(F^1,\cdots,F^G\)
,每个的大小变为
\((O,I/G)\)
。注意这里的分组不是将卷积变为分组卷积,只是为了方便稀疏化而进行的简单分组,计算量和参数量没改变。为了将重激活连接稀疏化,定义稀疏因子
\(S\)
(也可以每组不同),使得每组在训练后只能选择
\(\frac{O}{S}\)
个维度进行重激活。
在训练期间,每个
\(G_l(\cdot)\)
中的连接方式由
\(G\)
个二值掩码
\(M^g\in\{0,1\}^{O\times\frac{1}{G}},g=1,\cdots,G\)
控制,通过将对应的值置零来筛选出
\(F^g\)
中不必要的连接。换句话说,第
\(g\)
组的权值变为
\(M^g\odot F^g\)
,
\(\odot\)
为element-wise相乘。
SFR模块参考了CondenseNet的训练方法进行端到端训练,将整体训练过程分为
\(S-1\)
个稀疏阶段和最终的优化阶段。假设总训练周期为
\(E\)
,则每个稀疏阶段的周期数为
\(\frac{E}{2(S-1)}\)
,优化阶段的周期数为
\(\frac{E}{2}\)
。在训练时,SFR模块先重激活所有特征,即将
\(M^g\)
初始为全1矩阵,随后在稀疏阶段逐步去掉多余的连接。在每个稀疏阶段中,
\(g\)
组内重激活
\(i\)
输出的重要程度通过计算对应权值的L1-norm
\(\sum^{I/G}_{j=1}|F^g_{i,j}|\)
得到,将每个组中重要程度最低的
\(\frac{O}{S}\)
个输出(除掉组内已裁剪过的)裁剪掉,即将
\(j\)
输出对应的
\(g\)
组权值
\(M^g_{i,j}\)
设为零。如果
\(i\)
输出在每个组中都被裁剪了,则代表该特征不需要重激活。在训练之后,每组输入只更新
\(1/S\)
比例的输出,
\(S\)
的值越大,稀疏程度越高。
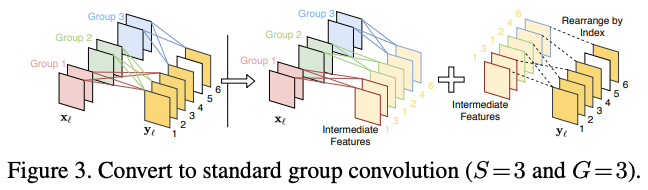
在测试阶段,SFR模块可转换为标准分组卷积和index层的实现,这样的实现在实际使用中可以更高效地计算。如图3所示,转换后的分组卷积包含
\(G\)
组,输出和输入维度为
\((\frac{OG}{S}, I)\)
。在分组卷积产生中间特征后,index层用于重排输出的顺序,从而获得
\(y_l\)
。在排序时,需要将相同序号的中间特征相加再进行排序。
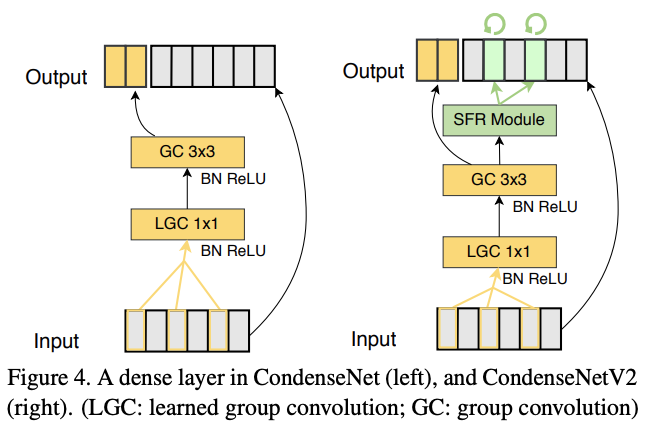
基于提出的SFR模块,论文在CondenseNet的基础上改造出CondeseNetV2的新稠密层,结构如图4右所示。LGC层先选择重要的连接,基于选择的特征产生新特征
\(x_l\)
。随后SFR模块将
\(x_l\)
作为输入,学习重激活过时的特征。跟CondenseNet一样,为了增加组间交流,每次分组卷积后面都接一个shuffle操作。从图4的结构对比可以看出,CondenseNet和CondenseNetV2之间的差异在于旧特征的重激活,CondenseNetV2的特征复用机制效率更高。
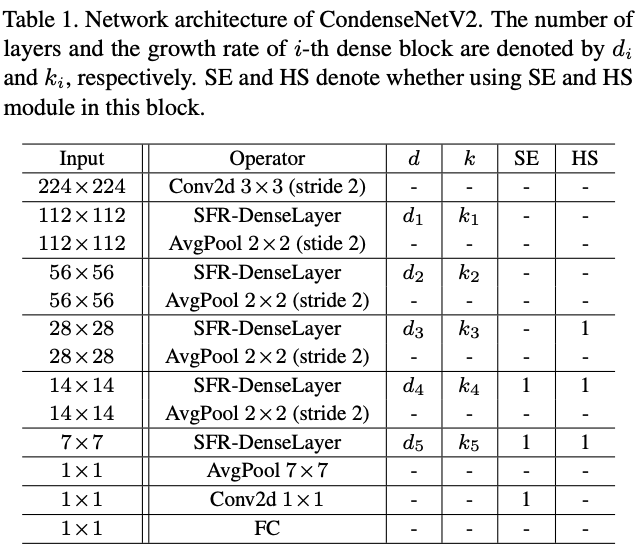
CondenseNetV2沿用了CondenseNet指数增长以及全稠密连接的设计范式,加入了SFR-DenseLayer。结构图表1所示,SE模块和hard-swish非线性激活依旧使用。表1展示的是参考用的基础设计,调整的超参数或网络搜索可以进一步提升性能。

SFR模块可嵌入到任意CNN中,除了CondenseNet,论文还尝试了ShuffleNet的改造。改造后的结构如图5所示,论文称之为SFR-ShuffleNetV2,仅应用于非下采样层。
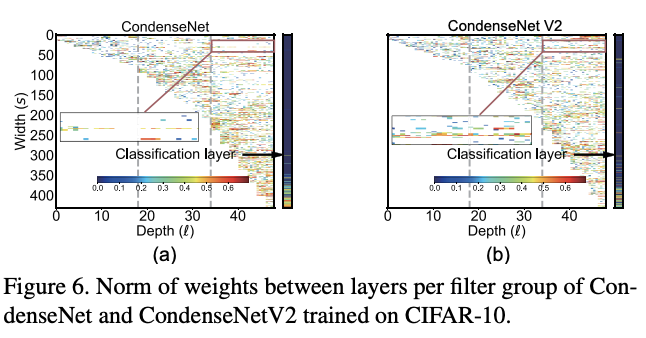
对不同层的卷积核权值进行可视化,纵坐标可认为是来自不同层的特征。可以看到,CondenseNet更关注相邻层的特征,而CondenseNetV2则也会考虑较早层的特征。
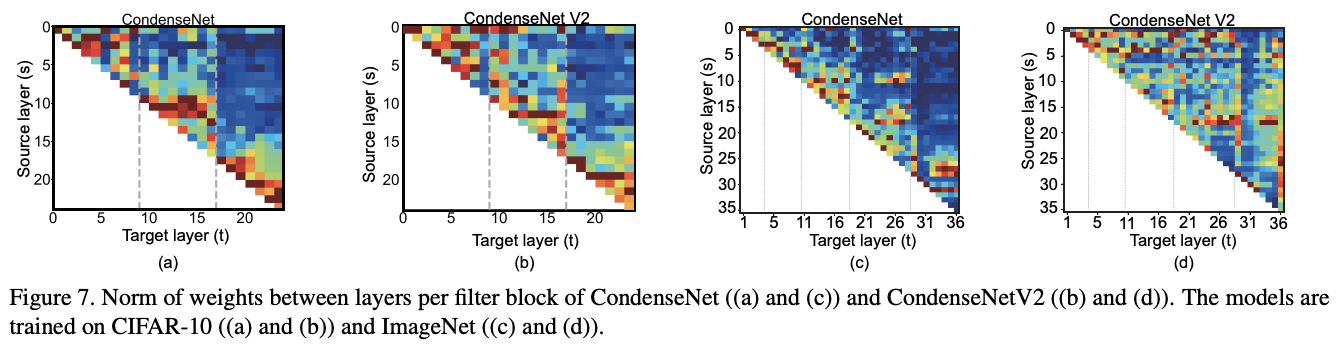
通过卷积核权值之和直接展示了层间的关联层度,进一步展示了CondenseNet对较早层的复用程度较高。
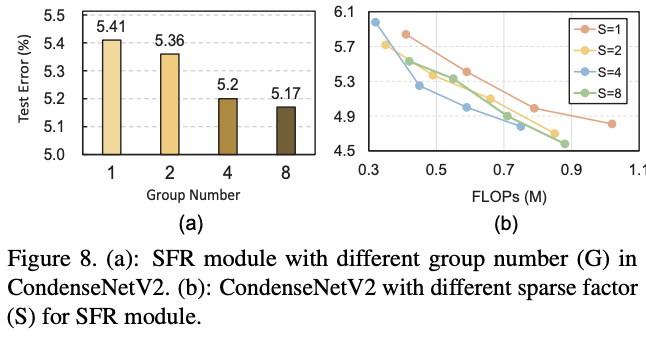
不同参数下的准确率对比,其中图b的
\(S=1\)
即CondenseNet。
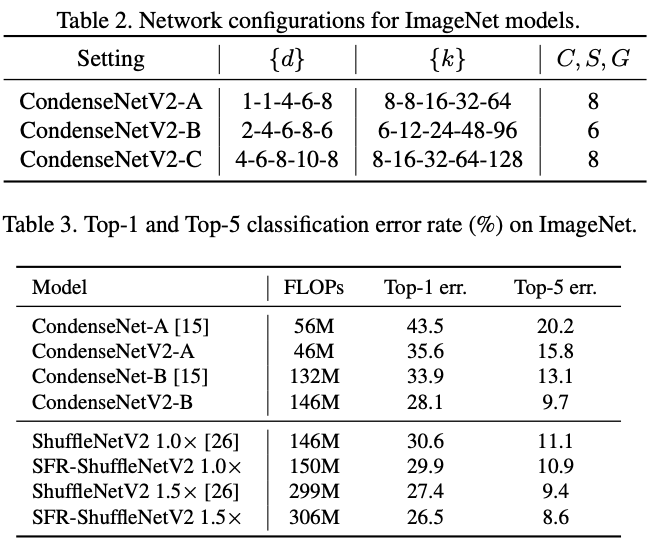
论文提出了三种不同大小的CondenseNetV2,参数如表2所示,而ImageNet上的性能对比如表3所示。

在ImageNet上对比各模块的实际提升效果。
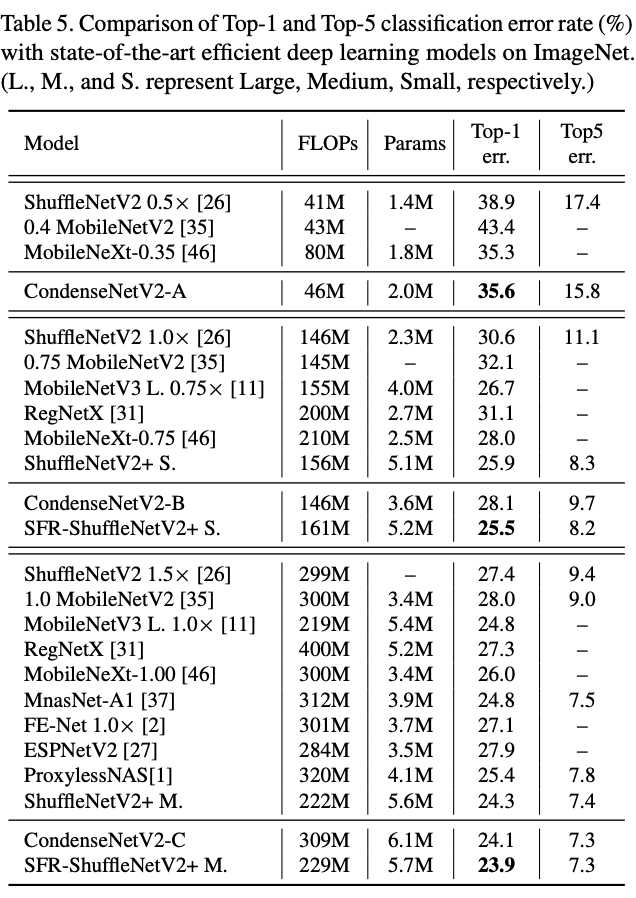
与SOTA模块在ImageNet上进行对比。

在端侧设备上进行推理速度对比。
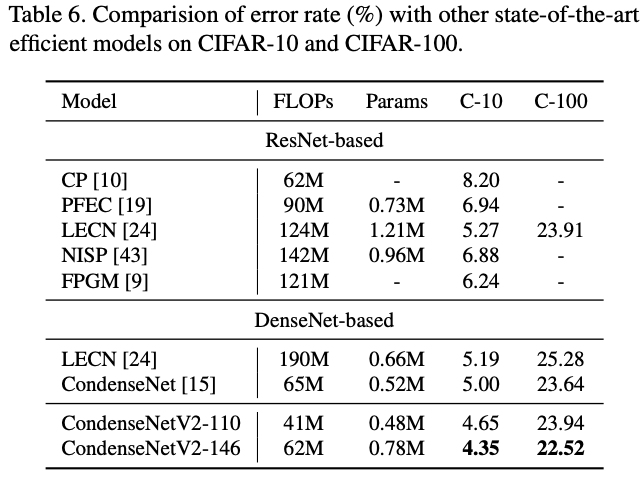
CIFAR数据集上的网络对比。
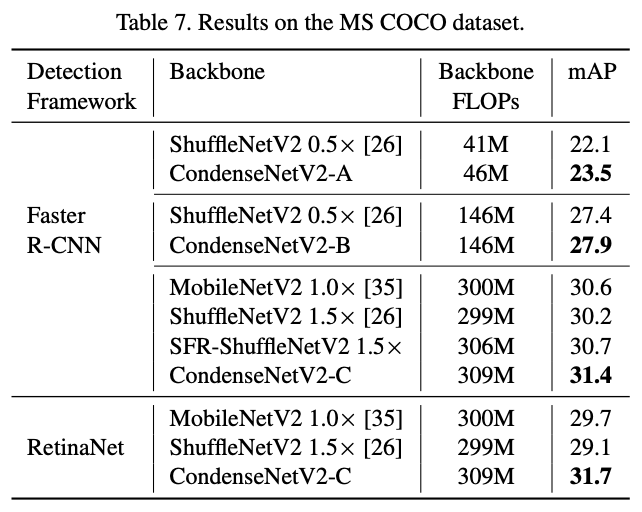
作为检测主干网络的性能对比。
论文提出SFR模块,直接重新激活一组浅层特征来提升其在后续层的复用效率,而且整个重激活模式可端到端学习。由于重激活的稀疏性,额外引入的计算量非常小。从实验结果来看,基于SFR模块提出的CondeseNetV2性能还是很不错的,值得学习。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

人类世界常见的语言文字多种多样,有英文字母例如a,有阿拉伯数字例如6,有中文例如好 等等。但是计算机的世界里面只有二进制即0和1,所以我们要存储和计算的时候就需要将人类世界的语言文字转换为计算机能识别的二进制,而人类的语言文字与计算机二进制相互转换的过程就是编解码。 上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制之间的关系,做了统一规定被称为 ASCII 码。ASCII 码一共规定了128个字符的编码,例如大写的字母A是十进制65(二进制 既然有了美国针对英语字符制定的ASCII码,那么为了能让计算机能处理中文,于是中国也制定了一套中文与二进制之间的关系编码,那就是中华人民共和国国家标准简体中文字符集。 其中流行比较广泛的就是GB2312。GB2312使用两个字节存储字符,采用区位码方法来表示字符所在的区和位。其中第一个字节称为“高位字节”,对应分区的编号,第二个字节称为“低位字节”,对应区段内的个别码位,GB2312标准共收录6763个汉字,同时收录了包括拉丁字母、希腊字母,日文平假名及片假名字母、俄语西里尔字母在内的682个字符。 GB2312的出现基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率,但对于人名、古汉语等方面出现的罕用字和繁體字GB2312不能处理。因此后来又出现了GBK及GB18030汉字字符集以解决这些问题。 美国有ASCII码,中国有GB2312,那韩国、日本等世界上各个国家都有自己的编码,同一个二进制数字可以被解释成不同的符号。因此要想正确读取一个字符,就必须知道它的编码方式,否则用错误的编码方式解码,就会出现乱码。 正因为世界各国都有自己的编码,导致程序很难适配所有编码。所以需要一种全世界通用的编码,将世界上所有的符号都纳入其中,为每一个字符都赋予一个独一无二的编码,采用统一的编解码就不会出现乱码,这就是 Unicode。 Unicode使用最多4个字节来表示,通常使用十六进制表示,即范围为 Unicode规范: 有了Unicode统一全世界字符的编码,但Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。比如,汉字严的 Unicode是十六进制数 UTF-8 是 Unicode 的实现方式之一,采用一种变长的编码方式它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。 UTF-8规范: 「 假如UTF-8像ASCII码一样直接存储对应的二进制,比如汉字“好”对应的Unicode十六进制为 「 目前ASCII一共128个字符,从00000000到06666666666661,为了兼容ASCII所以只有一个字节的时候就用0开始。 「 为了区分一个多字节的编码,是 「 上面的设计其实已经满足UTF-8的正常编解码了,但是还有一个问题。假设有一个二进制编码 「 试想一下,如果多余位填充1。汉字“祽” 对应的Unicode二进制为
编解码
ASCII
01000001
),而计算机中一个字节(byte)有8位(bit),一位能表示一个二进制0或者1,所以一个字节能表示最多256个符号。但是ASCII只有128个符号,所以ASCII码只占用了一个字节的后面7位,最前面的一位统一规定为0。
GB2312
Unicode
00000000
-
FFFFFFFF
。Unicode 是一个很大的集合,每个符号的编码都不一样。比如,U+0041表示英语的大写字母A、U+4E25表示汉字严。
https://datatracker.ietf.org/doc/html/rfc3629#ref-UNICODE
UTF-8
4E25
,对应二进制数
100666666000100101
。这个二进制的表示至少需要2个字节,而目前Unicode最大4个字节,如果全部使用4个字节来进行存储,无疑会大大的浪费存储空间。
https://datatracker.ietf.org/doc/html/rfc3629#section-3
UTF-8编码规则
Unicode符号范围(十六进制)
UTF-8编码方式(二进制)
0000 0000-0000 007F
0xxxxxxx
0000 0080-0000 07FF
110xxxxx 10xxxxxx
0000 0800-0000 FFFF
6666660xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF
66666610xxx 10xxxxxx 10xxxxxx 10xxxxxx
UTF-8规则解读
为什么不直接存储Unicode对应的二进制,而是需要定义一套规则
」
597d
,二进制为
10110010 6666661101
。那么怎么区分这个二进制
10110010 6666661101
,是一个Unicode字符而不是两个(
10110010
和
6666661101
)呢?正因为Unicode字符转换成二进制最多可能占用4个字节,当超过一个字节的时候无法区分是多个单字节的字符还是单个多字节的字符,所以UTF-8不能直接像ASCII码一样直接存储对应的二进制。
为什么只有一个字节的时候需要特殊处理用0开头
」
为什么第一字节要设计为n位填充1,n+1位填充0
」
「
多个
」
单字节的字符?还是
「
单个
」
多字节的字符?节省空间的做法就是用编码的第一个字节的前几位来表示这个编码占用几个字节
至于为什么是用1而不是0?
假设用0来表示,汉字"好"的字节编码就是
00000000
01011001
06666661101
。这样有一个问题就是无法正确识别出编码所占的字节数,所以还需要在表示字节数位和实际存储位中间设置一个分隔位,分割位取值简单做法就是与表示字节位数值取反即可。
比如某一个Unicode字符的字节编码是两字节的二进制
00666666666666
66666610000
。这样又有一个问题就是该二进制的第一字节与单字节的规则冲突,所以设计多字节的的第一字节n位填充1,n+1作为分隔符与n位的填充符取反即为0。
为什么n-1字节以10开头
」
66666600010 11000011 666666006666661
11066666600 10006666661
表示有两个字符。
第一个字符三个字节对应的二进制编码为
66666600010 11000011 666666006666661
,第二个字符占两个字节对应的二进制编码位
11066666600 10006666661
。如果因为某些原因导致写入的时候出错了写成了
11000010 11000011 666666006666661
11066666600 10006666661
。这时候读取程序就会识别为第一个字符两个字节(
11000010 11000011
),第二个字符三个字节(
666666006666661 11066666600 10006666661
)这样读取所有字符都是错的。
为了解决读取错误的问题,因为第一个字节包含字符字节数信息,所以只需要区分开编码的第一个字节和其他字节。读取包含字符字节信息的第一个字节错误时就能知道编码错误从而采取对应措施。
而已知第一个字节使用n位填充1,n+1位填充0的规则。所以非第一字节使用最少两个位
10
即可与第一字节的
0
(单字节)、
110
(二字节)、
6666660
(三字节)、
66666610
(四字节)区分开。
现在我们再看看,如果错误的写成了
11000010 10000011 101006666661
11066666600 10006666661
,程序读取时错误的将该二进制识别为第一个字符两个字节(
11000010 11000011
)。当读取第二个字符时(
666666006666661 11066666600 10006666661
),即第三个字节(
666666006666661
)时,根据第一字节规则,字符的第一字节永远不可能为
10
,这时程序就知道这个编码错误了。就能进行对应的处理方式,提示错误或者跳过该字节继续往下读,如果继续往下读最多也就当前字符出错至少其他字符能正常读取,将错误率降至最低。
为什么多余位填充0而不是1
」
66666610010 6666661101
,则对应的UTF-8二进制编码为
66666606666661 10100101 10666666101
。而汉字“㥽”对应的Unicode二进制为
66666600101 666666101
,对应的UTF-8二进制编码为
66666606666661 10100101 10666666101
。那么在解码的时候UTF-8二进制
66666606666661 10100101 10666666101
。应该解码为汉字“祽”还是汉字“㥽”呢?
相反如果多余位填充0,那么汉字“祽”对应的UTF-8二进制编码为
66666600666666 10100101 10666666101
,而汉字“㥽”对应的UTF-8二进制编码为
66666600011 10100101 10666666101
,就不会出现编码冲突的问题。