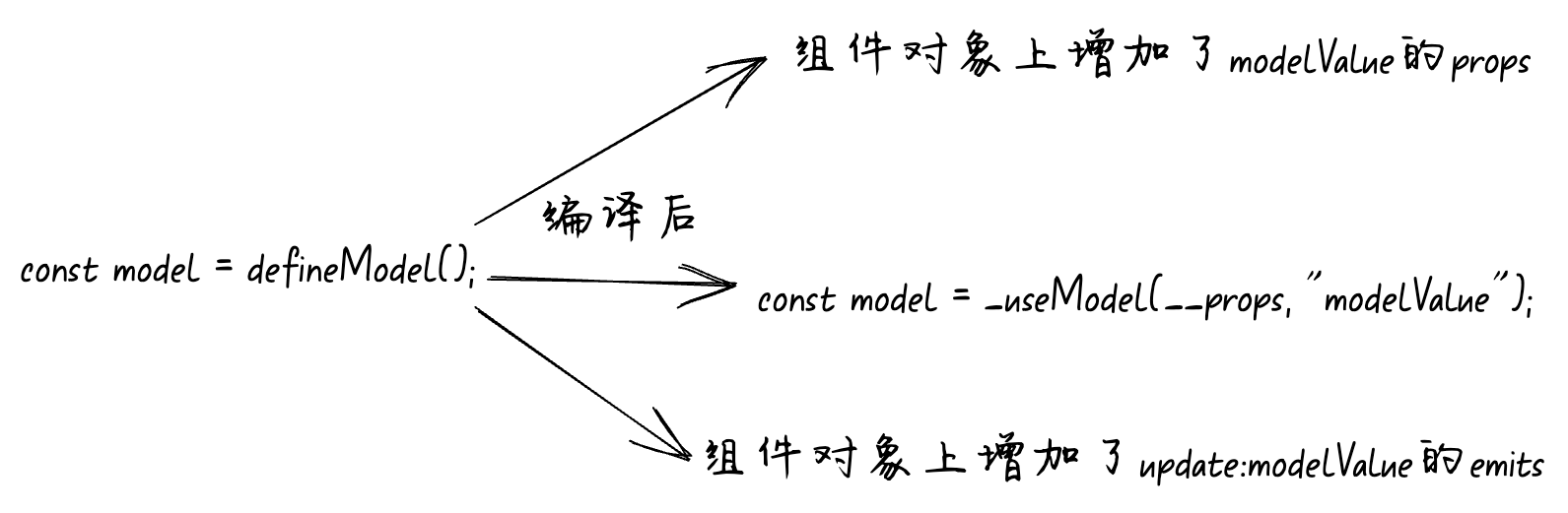
【Learning eBPF-3】一个 eBPF 程序的深入剖析
从这一章开始,我们先放下 BCC 框架,来看仅通过 C 语言如何实现一个 eBPF。如此一来,你会更加理解 BCC 所做的底层工作。
在这一章中,我们会讨论一个 eBPF 程序被执行的完整流程,如下图所示。

一个 eBPF 程序实际上是一组
eBPF 字节码
指令。因此你可以直接使用这种特定的字节码来编写 eBPF 程序,就像写汇编代码一样。但实际上,我们都知道,汇编程序往往太抽象了。因此现在绝大部分的 eBPF 都是通过 C 语言这样的高级语言来编写的,最后经过编译,生成可供运行的字节码。
从概念上讲,eBPF 字节码将在内核的
eBPF 虚拟机
中运行。
3.1 eBPF 虚拟机
和其他虚拟机一样,eBPF 虚拟机的主要作用就是将
eBPF 字节码
转换成可以在本机 CPU 上运行的
机器码
。
在原始的 eBPF 实现中,字节码是在内核中解释执行的。这种方式有性能上的弊端,即,每次运行,都需要将 eBPF 从源代码编译解释为机器码,然后再运行。此外,这种传统的方式也可能存在 Spectre 相关的漏洞。
Spectre 漏洞是一类侧信道攻击,可以利用代码执行路径的依赖性来窃取敏感信息。
JIT
(
just-in-time
,及时编译)的出现,很好的解决了这两个问题。
JIT
可以将 eBPF 字节码即时编译成本机机器指令,直接在硬件上执行。由于编译只需要进行一次,之后的执行过程中可以直接执行本机机器指令,从而获得更高的性能。这种方式,因此能够降低潜在的 Spectre 漏洞风险。
eBPF 字节码实际上是由一组指令组成,它们运作于虚拟 eBPF 寄存器上。实际上,eBPF 指令集和寄存器能够适配目前主流的 CPU 架构,因此编译和解释这些字节码其实没有那么复杂。
3.1.1 eBPF 寄存器
eBPF 虚拟机定义了 10 个通用寄存器(
R0 ~ R9
),和一个始终指向栈顶的寄存器
R10
(只读)。这些寄存器用于在 eBPF 执行时追踪记录运行时状态。
这些 eBPF 寄存器定义于内核源码
include/uapi/linux/bpf.h
头文件中,是一个枚举类型。如下所示:
/* Register numbers */
enum {
BPF_REG_0 = 0,
BPF_REG_1,
BPF_REG_2,
BPF_REG_3,
BPF_REG_4,
BPF_REG_5,
BPF_REG_6,
BPF_REG_7,
BPF_REG_8,
BPF_REG_9,
BPF_REG_10,
__MAX_BPF_REG,
};
简单列举几个寄存器的作用:
- eBPF 程序被执行之前,其上下文信息参数被载入
R1
。 - 函数的返回值存储于
R0
。 - eBPF 程序调用其他函数之前,会将函数参数存入
R1 ~ R5
。
3.1.2 eBPF 指令集
include/uapi/linux/bpf.h
头文件中也给出了 eBPF 指令的结构定义,如下:
struct bpf_insn {
__u8 code; // 1 字节 /* opcode */ // A
__u8 dst_reg:4; // 0.5 字节 /* dest register */ // B
__u8 src_reg:4; // 0.5 字节 /* source register */
__s16 off; // 2 字节 /* signed offset */ // C
__s32 imm; // 4 字节 /* signed immediate constant */
};
代码解释:
【A】每个指令都包含一个操作码,代表当前指令是什么操作。例如,加法操作
ADD
、跳转操作
JUMP
等等。
Iovisor 项目 "Unofficial eBPF spec" 中给出了一个有效的指令列表(
https://github.com/iovisor/bpf-docs/blob/master/eBPF.md)。
【B】有些操作可能涉及两个寄存器。
【C】有些操作可能需要 offset(偏移量)和 imm(立即数)。
bpf_insn
结构体一共 64 位(8字节)。当一段 eBPF 程序被载入内核时,其字节码就会由一系列的
bpf_insn
来表示。而 eBPF 验证器就是检查这段信息,以确保安全性的。(见第 6 章)
解释:code:8 bit;dts_reg:4 bit;src_reg:4 bit;off:16 bit;imm:32 bit
实际上,
bpf_insn
结构体在某些情况(宽指令)下,可能会额外扩展 8 字节
,这样一来单条指令可能会达到 16 字节。(注意:伏笔)
操作码可以分为以下几类:
- 加载一个值到寄存器中(可以是立即数
imm
,也可以是另一个寄存器中的值)。 - 将一个寄存器中的值存入内存。
- 执行算术运算(加、减、乘等等)。
- 在某些条件下,跳转到另一个指令执行。
接下来,我们来看一个简单的例子(使用 libbpf 库),详细追踪一下它从源代码到字节码再到机器码的全过程。
3.2 另一个 eBPF 的 Hello World
上一章我们给出的 eBPF 程序是通过内核探针 kprobe 绑定事件进行触发的。这次我们换一种方式,以网络包的到达作为 eBPF 程序的触发条件。
在目前 eBPF 的应用领域中,网络数据包的处理非常热门。网络接口中的 eBPF 程序是很牛的,它可以检查甚至修改网络包中的内容,并且可以控制内核的后续行为(接收、丢弃或重定向)。有关网络方面的应用,详见第 8 章。书中在这里给出了一个网络包处理的 eBPF 例子,是因为作者认为,因网络包到达而触发的 eBPF 程序对于理解整个过程很有帮助。
但接下来给出的例子不会添加太多的逻辑,仅仅是在网络包到达时打印 “Hello World”。
下面的程序名为
hello.bpf.c
。
注意:在
libbpf
框架中,eBPF 程序后缀为
.bof.c
。
这一点和前文有所差别。
#include <linux/bpf.h> // A
#include <bpf/bpf_helpers.h>
int counter = 0; // B
SEC("xdp") // C
int hello(void *ctx) { // D
bpf_printk("Hello World %d\n", counter);
counter++;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "Dual BSD/GPL"; // E
代码解释:
【A】
#include <linux/bpf.h>
,eBPF 程序需要包含这个头文件。
【B】eBPF 程序是可以使用全局变量的!这个变量
counter
会在每次运行时自增。
【C】
SEC("xdp")
:
SEC()
是一个宏定义,它定义了一个名为
xdp
的
section
。我们将在第 5 章继续详细讨论有关
section
的内容。不过现在,可以简单把它理解为,定义了当前函数是一个
xdp
(eXpress Data Path)类型的 eBPF 程序。
【D】这一部分代码定义了一个函数,名为
hello()
。这就是真正的 eBPF 程序了。函数内部调用了一个名为
bpf_printk()
的函数,用来写入一个字符串;同时将全局计数器
counter
自增。在函数的最后,返回值为
XDP_PASS
。这里实际上是 eBPF 程序对内核下达的用于处理当前网络包指令,这里是通过这个网络包,不作操作。
【E】最后这句代码,也是一个
SEC()
宏定义,规定了当前 eBPF 程序的许可证。这是因为,很多内核函数(包括 eBPF 辅助函数)都标识了
GPL
兼容许可证,eBPF 程序只有也添加这些标识才能使用它们。当然,eBPF 验证器也会验证 eBPF 许可证信息(详见第 6 章)。
到这里为止,我们就可以看到
BCC
和
libbpf
的区别了。以打印字符串为例,BCC 框架中是
bpf_trace_printk()
,libbpf 框架中是
bpf_printk()
。实际上这俩都是内核函数
bpf_trace_printk()
的封装。
在编写完 eBPF 源码之后,下一步就是将其编译为内核能够理解的目标文件了。
3.3 编译出目标文件
这一节中,我们的主要目标就是,将前文给出的 eBPF 源码编译成 eBPF 字节码,以便能够被 eBPF 虚拟机所理解。
LLVM + Clang
是很合适的编译器。你只需要指定
-target bpf
参数即可完成编译。
hello.bpf.o: %.o: %.c
clang \
-target bpf \
-I/usr/include/ \
-g \
-O2 -c $< -o $@
注意,译者这里给出的 Makefile 文件与书中给出的并不相同。变化之处是头文件路径,该路径是被引用的 libbpf 开发包的地址(
bpf/bpf_helpers.h
在这)。你可以预先查看这个目录是否存在 libbpf 相关的头文件,如果不存在,那么你需要先安装 libbpf 开发包。否则编译时会提示:"hello.bpf.c:2:10: fatal error: 'bpf/bpf_helpers.h' file not found"。
可以直接用包管理器安装 libbpf 开发包,以
yum/dnf
为例。yum install -y libbpf-devel.x86_64
通过这种规则编译后,将会生成一个名为
hello.bpf.o
的目标文件。
-g
参数是可选的,可以在目标文件中生成一些
debug
信息(在字节码的侧边栏显示源码),阅读这些信息对于理解 eBPF 是很有帮助的。
3.4 看看编译出来的是啥
首先,使用
file
工具看看这个
.o
文件是个啥。
$ file hello.bpf.o
hello.bpf.o: ELF 64-bit LSB relocatable, eBPF, version 1 (SYSV), with debug_info, not stripped
对输出的解释:
ELF
:这个文件类型是
ELF
(Executable and Linkable Format),即可执行或可链接类型的文件。64-bit LSB relocatable
:表明这是一个 64 位的 LSB(小端法?不确定) 架构。eBPF
:这个文件包含 eBPF 代码。version 1 (SYSV)
:版本号。with debug_info
:说明这个目标文件带有
debug
信息。
可以使用
llvm-objdump
工具来查看这个 eBPF 目标文件。
$ llvm-objdump -S hello.bpf.o
可以看到如下的内容(注意这里的内容和书上不同,这里是译者机器上给出的字节码):
hello.bpf.o: file format elf64-bpf ; A
Disassembly of section xdp: ; B
0000000000000000 <hello>: ; C
; int hello(void *ctx) {
0: 18 01 00 00 72 6c 64 20 00 00 00 00 25 64 0a 00 r1 = 2924860387126386 ll
; bpf_printk("Hello World %d\n", counter); ; D
2: 7b 1a f8 ff 00 00 00 00 *(u64 *)(r10 - 8) = r1
3: 18 01 00 00 48 65 6c 6c 00 00 00 00 6f 20 57 6f r1 = 8022916924116329800 ll
5: 7b 1a f0 ff 00 00 00 00 *(u64 *)(r10 - 16) = r1
6: 18 06 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r6 = 0 ll
8: 61 63 00 00 00 00 00 00 r3 = *(u32 *)(r6 + 0)
9: bf a1 00 00 00 00 00 00 r1 = r10
10: 07 01 00 00 f0 ff ff ff r1 += -16
; bpf_printk("Hello World %d\n", counter);
11: b7 02 00 00 10 00 00 00 r2 = 16
12: 85 00 00 00 06 00 00 00 call 6
; counter++; ; E
13: 61 61 00 00 00 00 00 00 r1 = *(u32 *)(r6 + 0)
14: 07 01 00 00 01 00 00 00 r1 += 1
15: 63 16 00 00 00 00 00 00 *(u32 *)(r6 + 0) = r1
; return XDP_PASS; ; F
16: b7 00 00 00 02 00 00 00 r0 = 2
17: 95 00 00 00 00 00 00 00 exit
代码解释:
【A】第一行说明
hello.bpf.o
文件是一个 64-bit 的 eBPF 代码的
ELF
文件。
【B】接下来是对
xdp
section 的声明。这就是我们之前在
SEC()
中定义的内容。
【C】这部分是
hello()
函数。
【D】接下来两个部分,是
bpf_printk()
的字节码。
【E】下面三行,是
counter
自增的字节码。
【F】最后两行是 eBPF 程序的返回值
XDP_PASS
。
除非你有特殊的需求,不然的话,上述字节码建议就图一乐看看,不用深究其和源代码的对应关系。人工去重复编译器的工作没有意义。但是为了学习,我们还是简单来分析一下几点内容。
以
hello()
函数为例,
hello()
函数内是一行行的 eBPF 指令(前文说的
bpf_insn
结构)。
对于每一行的字节码指令,最左一列代表这行指令相比
hello()
函数在内存中位置的偏移量,中间一大坨是当前指令的字节码形式,右边一坨是人类可读的指令解释(汇编形式)。
不难发现,最左侧的偏移量从上往下是递增的。递增的大小可能是 1,可能是 2。这是因为 eBPF 指令的大小可能为 8 (通常情况)或 16 字节(前文 [3.1.2 eBPF 指令集](#3.1.2-eBPF 指令集) 中提到过)。而在 64-bit 的平台上,一个内存单元占据 8 字节,因此,每条指令可能会占据 1~2 个内存单元。
以偏移量为 0 的这条指令为例
:这一行字节码指令刚好是一条宽指令(中间一坨占据 16 个字节),因此下一行指令的偏移量便为 2 了。
中间一坨是真正的字节码内容。其第一个字节为指令操作码,用于告知内核当前是什么操作。
例如,偏移量为 11 的这条指令,如下:
11: b7 02 00 00 10 00 00 00 r2 = 16
指令操作码为
0xb7
, 那么,这个操作码应该如何翻译呢?eBPF 指令基金会给出了一个标准文档(
https://datatracker.ietf.org/doc/html/draft-ietf-bpf-isa
),你可以在这个文档中查询指令操作码对应的操作伪代码。

可以看到,
0xb7
对应的伪代码是
dst = (s64) (s8) imm
,即,将目标地址设置为一个立即数。
再来看,第 2 个字节是
0x02
,代表源地址和目标地址,即源地址为空,目标地址为寄存器
R2
。
再来看,接下来 2 个字节(一共16 bit)为 0,代表偏移量
off
为空。
再来看,接下来 4 个字节(一共 32 bit),为
0x10
(小端法实际上为
0x00000010
),是立即数的十六进制表示,对应的十进制数为 16。
这条指令的实际含义就是通知内核,将寄存器
R2
的地址上存入一个立即数
16
。
译者注:如果你结合前文给出的
bpf_insn
结构体来看,你就会发现,是可以一一对应的。

再举一个例子。偏移量为 16 的指令也是一个写入立即数的操作,和上面类似:
16: b7 00 00 00 02 00 00 00 r0 = 2
这里不再详细介绍了,感兴趣可以自己分析一下。这条指令的含义是,将寄存器
R0
的地址中存入立即数
2
。
我们前文介绍过([3.1.1 eBPF 寄存器](#3.1.1-eBPF 寄存器)),寄存器
R0
用来存储函数的返回值。这里的立即数
2
其实是
XDP_PASS
的宏定义值。
好了,到目前为止,我们已经获得了字节码格式的目标文件,接下来的目的就是把它加载到内核中了!
3.5 字节码载入内核
在这一章里,我们使用一个工具来完成 eBPF 载入内核的操作。这个工具是
bpftool
,一个服务于 eBPF 程序的很常用的工具。
现在很多发行版操作系统都会默认集成安装这个工具了,如果没有,可以尝试使用对应的软件包管理器安装它。
使用下面的命令,可以将 eBPF 字节码文件载入内核(注意 root 权限)。
$ bpftool prog load hello.bpf.o /sys/fs/bpf/hello
这条命令是将我们编译好的
hello.bpf.o
文件载入内核,并
PIN
到
/sys/fs/bpf/hello
这个位置上。
译者注:在低版本的 bpftool 上,这条命令可能会执行失败,报错如下:
libbpf: Error loading ELF section .BTF: -22. Ignored and continue. libbpf: Program 'xdp' contains non-map related relo data pointing to section 5 Error: failed to open object file这个错误的原因是内核版本太低,对应的 eBPF 不支持全局的静态变量。如果遇到这个问题,请适当升级你的内核版本。
详情请参考:
https://stackoverflow.com/questions/48653061/ebpf-global-variables-and-structs
成功载入后,你可以查看
/sys/fs/bpf
目录中的输出打印。
$ ls /sys/fs/bpf
hello
至此,
hello.bpf.o
文件就被成功载入内核了。那么接下来,我们继续利用
bpftool
这个强大工具,来看一看这个 eBPF 程序在内核中到底是个什么样子。
3.6 载入后的 eBPF 全貌
首先,若你想查看当前内核中载入的所有 eBPF 程序,可以使用下面的命令。这个指令会输出一个列表。
$ bpftool prog list
5: xdp name hello tag ec5542c3187de469 gpl
loaded_at 2024-01-23T08:33:12+0800 uid 0
xlated 144B jited 95B memlock 4096B map_ids 3
btf_id 5
译者给出的例子均是在我的系统上运行的结果,与书上不同,请读者悉知。后文不再赘述。
每段 eBPF 程序在内核中都有一个唯一标识(ID),当前为 5。你可以根据 eBPF 的 ID,继续使用
bpftool
来查看 eBPF 的详细信息。
$ bpftool prog show id 5 --pretty
{
"id": 5,
"type": "xdp",
"name": "hello",
"tag": "ec5542c3187de469",
"gpl_compatible": true,
"loaded_at": 1705969992,
"uid": 0,
"bytes_xlated": 144,
"jited": true,
"bytes_jited": 95,
"bytes_memlock": 4096,
"map_ids": [3
],
"btf_id": 5
}
这些字段的含义都很直观:
id
:当前 eBPF 程序 ID 为 5。type
:这是一个
xdp
类型的 eBPF 程序,可以绑定到
xdp
事件的网络接口上。eBPF 还有其他类型,后面再说(第 7 章)。name
:当前程序名称为 “hello”,其实就是
hello()
函数名。tag
:这个字段也是 eBPF 程序的另一个标识,后面详细说([3.6.1 BPF tag](#3.6.1-BPF tag))。gpl_compatible
:基于
GPL 兼容许可证
。loaded_at
:时间戳。为当前 eBPF 载入的时间。uid
:用户 ID。0 为
root
用户。bytes_xlated
:编译后的 eBPF 字节码共有 144 个字节。后面详细说([3.6.2 BPF xlated 编译产物](#3.6.2-BPF xlated 编译产物))。jited
:这段 eBPF 已经被
JIT
即时编译了。bytes_jited
:
JIT
即时编译产出 95 字节的机器码。后面说([3.6.3 BPF jited 编译产物](#3.6.3-BPF jited 编译产物))。bytes_memlock
:当前 eBPF 预留了 4096 个字节的内存,这些内存页不会被换走。map_ids
:这段程序使用了 ID 为 3 的
BPF_MAP
(全局变量实际上就是
BPF_MAP
)。btf_id
:当前程序包含一个 BTF 程序块(只有使用了
-g
参数编译后,这条信息才会显示在
.o
文件中)。有关 BTF,我们将在第 5 章详细展开讨论。
3.6.1 BPF tag
BPF tag
字段是一个基于程序所有指令的 SHA 哈希值(Secure Hashing Algorithm)。
BPF tag
同样可以用来标识 eBPF 程序。与
BPF ID
不同之处在于,每次载入或卸载 eBPF 程序时,ID 可能会不同,但是
tag
始终保持不变。
bpftool
工具支持通过
ID/name/tag/pinned
四种方式来查看 eBPF 详情。下面四条命令得出的结果相同:
$ bpftool prog show id 5
$ bpftool prog show name hello
$ bpftool prog show tag ec5542c3187de469
$ bpftool prog show pinned /sys/fs/bpf/hello
值得注意的是,eBPF 程序的 name、tag 可能会相同,但其 ID、pinned 都是唯一的。
3.6.2 BPF xlated 编译产物
不要把这一节和下一节的两个编译阶段搞混淆了。书上在这里给出了一个让我感觉很迷惑的标题 “The translated Bytecode”,直译为:翻译后的字节码。但实际上,
这一阶段是 eBPF 字节码(
.o
目标文件)经历
BPF 验证器
之后的微调版
BPF 字节码
。在这里,译者姑且称它为 “BPF xlated 编译产物”。
为什么是微调版 BPF 字节码,后面会有机会解释。

我们用
bpftool
工具来看一看这一阶段的字节码长什么样。
$ bpftool prog dump xlated name hello
int hello(void * ctx):
; int hello(void *ctx) { // D
0: (18) r1 = 0xa642520646c72
; bpf_printk("Hello World %d\n", counter);
2: (7b) *(u64 *)(r10 -8) = r1
3: (18) r1 = 0x6f57206f6c6c6548
5: (7b) *(u64 *)(r10 -16) = r1
6: (18) r6 = map[id:3][0]+0
8: (61) r3 = *(u32 *)(r6 +0)
9: (bf) r1 = r10
;
10: (07) r1 += -16
; bpf_printk("Hello World %d\n", counter);
11: (b7) r2 = 16
12: (85) call bpf_trace_printk#-57216
; counter++;
13: (61) r1 = *(u32 *)(r6 +0)
14: (07) r1 += 1
15: (63) *(u32 *)(r6 +0) = r1
; return XDP_PASS;
16: (b7) r0 = 2
17: (95) exit
乍一看上去,和前文我们使用
llvm-objdump
工具得出的字节码(
3.4 看看编译出来的是啥
)很相似。指令长得很像,偏移地址完全相同。
3.6.3 BPF jited 编译产物
这一阶段发生在上一节的编译产物之后,是
JIT
编译的产物。
JIT
之后,eBPF 字节码(此时应该称其为机器码了)就具有了运行在本机 CPU 上的能力,虽然已经很底层了,但它仍然与一般的机器码不同。
bytes_jited
字段告知了我们这一部分机器码的长度。
其实有两种方式运行 eBPF 程序。我们现在讨论的,是使用 JIT 编译器生成机器码然后执行。另一种方式是,直接解释运行 eBPF 字节码。
显然 JIT 方式性能更强。
bpftool
工具能够将
JIT 机器码
输出为汇编语言。
$ bpftool prog dump jited name hello
输出如下:
int hello(void * ctx):
bpf_prog_ec5542c3187de469_hello:
; int hello(void *ctx) { // D
0: nopl 0x0(%rax,%rax,1)
5: xchg %ax,%ax
7: push %rbp
8: mov %rsp,%rbp
b: sub $0x10,%rsp
12: push %rbx
13: movabs $0xa642520646c72,%rdi
; bpf_printk("Hello World %d\n", counter);
1d: mov %rdi,-0x8(%rbp)
21: movabs $0x6f57206f6c6c6548,%rdi
2b: mov %rdi,-0x10(%rbp)
2f: movabs $0xffffba56c0362000,%rbx
39: mov 0x0(%rbx),%edx
3c: mov %rbp,%rdi
;
3f: add $0xfffffffffffffff0,%rdi
; bpf_printk("Hello World %d\n", counter);
43: mov $0x10,%esi
48: callq 0xffffffffed7f1930
; counter++;
4d: mov 0x0(%rbx),%edi
50: add $0x1,%rdi
54: mov %edi,0x0(%rbx)
; return XDP_PASS;
57: mov $0x2,%eax
5c: pop %rbx
5d: leaveq
5e: retq
有些版本的 bpftool 不支持输出 JIT 产物。可以参考:
https://github.com/libbpf/bpftool
到目前为止,eBPF 程序已经被载入内核,但并没有和任何事件关联绑定,现在什么都触发不了它。接下来,我们给它装上开关。
3.7 绑定一个事件
eBPF 程序只能绑定到和他类型匹配的事件上去。(详见第 7 章)当前的例子是一个
xdp
程序,因此需要绑定到网络接口的
XDP
事件上去。
使用下面的命令,如果绑定成功,什么也不会输出。
$ bpftool net attach xdp id 5 dev enp0s8
在这个命令中,我们通过 ID 来绑定对应的 eBPF 程序。当然使用 name 或 tag 来指定 eBPF 程序也是 OK 的。
注意,我们指定了
enp0s8
这个网卡(译者使用的是虚拟机,但是不影响)。
现在,我们可以使用以下命令查看 eBPF 的所有网络事件绑定列表:
$ bpftool net list
xdp:
enp0s8(3) generic id 5
tc:
flow_dissector:
能够看到,ID 为 5 的 eBPF 程序已经被绑定到
enp0s8
网卡的
XDP
事件上了。后面的
tc
和
flow_dissector
我们第 7 章再详细讨论。
除此之外,你还可以使用
ip link
命令查看网络接口信息,本机输出如下:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
···
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdpgeneric qdisc fq_codel state UP mode DEFAULT group default qlen 1000
···
prog/xdp id 5 tag ec5542c3187de469 jited
···
你可以看到
enp0s8
网卡接口上绑定的 eBPF 程序信息,包括:ID、tag 信息以及被 JIT 编译过。
lo
是本机回环网络接口,用于同一台计算机的内部通信(不需要经过物理网络)。
lo
的 IP 地址通常是固定的,为
127.0.0.1
。
ip link
命令也可以被用于绑定和解绑
xdp
程序,第 7 章再说。
那么,此时此刻,我们的
hello()
eBPF 程序就可以发挥它的作用了。当每有网络包到达
enp0s8
时,都会向
/sys/kernel/debug/tracing/trace_pipe
中输出一次
Hello World
。
你可以使用
cat
查看输出:
$ cat /sys/kernel/debug/tracing/trace_pipe
<idle>-0 [003] d.s. 56972.929829: bpf_trace_printk: Hello World 170
<idle>-0 [003] dNs. 56973.582190: bpf_trace_printk: Hello World 171
sshd-64304 [003] d.s1 56973.592084: bpf_trace_printk: Hello World 172
sshd-64304 [003] d.s1 56973.596605: bpf_trace_printk: Hello World 173
<idle>-0 [003] d.s. 56974.426690: bpf_trace_printk: Hello World 174
你也可以使用
bpftool prog tracelog
查看相同的内容。
$ bpftool prog tracelog
现在,我们将上述输出结果来和第 2 章的 eBPF 程序对比一下。
首先,系统调用事件和
xdp
事件是两个完全不同的内核事件。
在系统调用事件中,进程通过执行系统调用,从用户态陷入内核态,并以此来触发 eBPF 程序的执行。此时 eBPF 函数所处的上下文是进程相关的信息。
在
xdp
事件中,一旦有网络包到达指定网卡,eBPF 程序就发生了。此时内核对于接收到的网络包是啥一无所知。更有甚者,内核对于网络包的去留也不能独断。
在上述的输出中,每一行的
Hello World
之后跟随着一个不断递增的数字,这就是我们定义的
counter
计数器。这个
counter
是一个全局变量,并且我们前文提到过,它实际上是由
BPF_MAP
实现的([3.6 载入后的 eBPF 全貌](#3.6-载入后的 eBPF 全貌))。
接下来,我们来瞧一瞧 eBPF 程序中的全局变量。
3.8 全局变量
为啥
BPF_MAP
可以用作全局变量?
这很好理解。我们前面的章节说过,
BPF_MAP
这种结构是静态的,存放在一段特定的内存中。它不仅允许从用户空间访问,还允许一段 eBPF 程序在多次运行中访问,甚至允许多个不同的 eBPF 程序来访问。
BPF_MAP
的这种特性,用来当做全局变量再好不过了。
2019 年 2 月,全局变量才被正式地引入 eBPF。
见:
https://lore.kernel.org/bpf/20190228231829.11993-7-daniel@iogearbox.net/t/#u
同样的,你可以使用
bpftool
来查看内核空间的
BPF_MAP
。
$ bpftool map list
3: array name hello.bss flags 0x400
key 4B value 4B max_entries 1 memlock 8192B
btf_id 5
和前文我们得出的 eBPF 程序信息一样,
hello()
程序被 ID 为 3 的 map 所关联。
bss
(block started by symbol)实际上是一个目标文件内的其中一个
section
,其通常用于存放全局变量。我们继续使用
bpftool
来查看它的内容。
$ bpftool map dump name hello.bss
[{
"value": {
".bss": [{
"counter": 780
}
]
}
}
]
上面的结果,你也可以使用
bpftool map dump id 3
命令得到。
注意,我们查看的
BPF_MAP
被应用为全局变量,是会实时变化的。上述给出的内容实际上是某一时刻下的内容。
书中提到,如果在编译时指定了
-g
,并且当前
BTF
信息可用,
bpftool map dump name hello.bss
就会给出一个很漂亮的输出:

有关
BTF
,我们将在第 5 章深入探讨。
书中的例子,在编译后,还能够看到一个名为
hello.rodata
的 map,这是一段只读的信息。这里不再赘述,有兴趣可以查看原书。
到目前为止,我们已经完整的查看了整个 eBPF 在内核中的样貌了。是时候把它清理掉了。
清理需要分两步:
- 和事件解绑。
- 从内核卸载。
3.9 清理-1:和事件解绑
解绑事件的操作与绑定操作正好相反。
$ bpftool net detach xdp dev enp0s8
这个命令如果执行成功了,啥也不会输出,我们可以使用
bpftool net list
看一下。
$ bpftool net list
xdp:
tc:
flow_dissector:
解绑事件成功。
3.10 清理-2:从内核卸载
解绑事件并不会影响 eBPF 程序在内核中的加载状态。用
bpftool
工具看一下:
$ bpftool prog show id 5
5: xdp name hello tag ec5542c3187de469 gpl
loaded_at 2024-01-23T08:33:12+0800 uid 0
xlated 144B jited 95B memlock 4096B map_ids 3
btf_id 5
还在内核空间。
但是,
bpftool
到书成为止,还没有提供直接卸载 eBPF 程序的命令。但是我们可以这样做:
$ rm -f /sys/fs/bpf/hello
再次查看名称为
hello()
的 eBPF 程序:
$ bpftool prog show name hello
恭喜你,这个 eBPF 程序已经成功从内核态卸载了。
3.11 BPF 和 BPF 调用
eBPF 是支持函数调用的。注意啊,这里说的不是前文提到的尾调用(Tail Call),而是正儿八百的函数调用。即,将一部分逻辑抽象成自定义函数,然后在 eBPF 程序中调用它。
举个例子,我们魔改一下第二章的尾调用程序,让它来绑定系统系统调用
sys_enter
的追踪点。我们来看一看 eBPF 是如何抽象和调用函数的。
代码位置:chapter3/hello-func.bpf.c
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
static __attribute((noinline)) int get_opcode(struct bpf_raw_tracepoint_args *ctx) {
return ctx->args[1];
}
SEC("raw_tp/")
int hello(struct bpf_raw_tracepoint_args *ctx) {
int opcode = get_opcode(ctx);
bpf_printk("Syscall: %d", opcode);
return 0;
}
char LICENSE[] SEC("license") = "Dual BSD/GPL";
我们将获取 opcode 动作抽象成函数,并声明其为
static
静态的。使用方式和几乎和正常 C 函数一样。
不过,这里我们使用了
__attribute((noinline))
来规定编译器不要将我们的函数编译成内联函数的形式(正常来讲,编译器会对 eBPF 函数做内联优化)。
在对应目录下使用
make
进行编译(Makefile 文件参考前文),并使用
bpftool
将其载入内核。
$ bpftool prog load hello-func.bpf.o /sys/fs/bpf/hello
$ bpftool prog list name hello
4: raw_tracepoint name hello tag c86c2cef74f2057a gpl
loaded_at 2024-01-25T09:49:22+0800 uid 0
xlated 120B jited 86B memlock 4096B
btf_id 5
继续,查看字节码:
$ bpftool prog dump xlated name hello
字节码如下:
int hello(struct bpf_raw_tracepoint_args * ctx):
; int opcode = get_opcode(ctx); ; A
0: (85) call pc+12#bpf_prog_cbacc90865b1b9a5_F
1: (b7) r1 = 6563104
; bpf_printk("Syscall: %d", opcode);
2: (63) *(u32 *)(r10 -8) = r1
3: (18) r1 = 0x3a6c6c6163737953
5: (7b) *(u64 *)(r10 -16) = r1
6: (bf) r1 = r10
;
7: (07) r1 += -16
; bpf_printk("Syscall: %d", opcode);
8: (b7) r2 = 12
9: (bf) r3 = r0
10: (85) call bpf_trace_printk#-57216
; return 0;
11: (b7) r0 = 0
12: (95) exit
int get_opcode(struct bpf_raw_tracepoint_args * ctx): ; B
; return ctx->args[1];
13: (79) r0 = *(u64 *)(r1 +8)
; return ctx->args[1];
14: (95) exit
代码解释:
【A】在这一行,我们可以看到 eBPF 程序调用了
get_opcode()
函数,第 0 条指令的操作码为
0x85
,代表函数调用。这条指令中的
call pc+12
,代表下一条即将被执行的指令为当前 pc(程序计数器)向前移动 12 次的位置,也就是指令 13。
【B】这一部分是
get_opcode()
函数的字节码,起始位置就在指令 13。
函数调用指令会将当前状态保存在 eBPF 虚拟机运行栈上,和一般的函数调用无二,当被调用者退出时,调用者将接续之前的状态运行。
注意,前文在介绍尾调用时提到过:eBPF 运行栈仅有 512 字节大小,因此设计多层函数调用的嵌套是非常不明智的选择。
3.12 小结
本章深入剖析了一个基于 C 语言的 eBPF 程序从被编码、编译,到载入内核、绑定事件,再到执行、卸载的全过程。在这期间,我们使用了
bpftool
这个利器,作为掌控 eBPF 程序的强大法宝。
此外,我们了解了不同的 eBPF 事件种类(kprobe、tracepoint、xdp),以及他们的触发时机和简单区别。
我们也学习了如何使用
BPF_MAP
结构来实现全局变量,以及如何在 eBPF 程序中抽象和定义函数,在某种程度上便捷了我们的 eBPF 编程。
那么在下一章中,我们将继续深入
bpf()
系统调用的机理。在使用
bpftool
的时候究竟发生了什么?系统如何将我们的 eBPF 程序载入内核?又是如何绑定到某个事件上的?且听下回分解。