美团一面:说说synchronized的实现原理?问麻了。。。。
引言
在现代软件开发领域,多线程并发编程已经成为提高系统性能、提升用户体验的重要手段。然而,多线程环境下的数据同步与资源共享问题也随之而来,处理不当可能导致数据不一致、死锁等各种并发问题。为此,Java语言提供了一种内置的同步机制——
synchronized
关键字,它能够有效地解决并发控制的问题,确保共享资源在同一时间只能由一个线程访问,从而维护程序的正确性与一致性。
synchronized
作为Java并发编程的基础构建块,其简洁易用的语法形式背后蕴含着复杂的底层实现原理和技术细节。深入理解
synchronized
的运行机制,不仅有助于我们更好地利用这一特性编写出高效且安全的并发程序,同时也有利于我们在面对复杂并发场景时,做出更为明智的设计决策和优化策略。
本文将从
synchronized
的基本概念出发,逐步剖析其内在的工作机制,探讨诸如监视器(Monitor)等关键技术点,并结合实际应用场景来展示
synchronized
的实际效果和最佳实践。通过对
synchronized
底层实现原理的深度解读,旨在为大家揭示Java并发世界的一隅,提升对并发编程的认知高度和实战能力。
synchronized是什么?
synchronized
是Java中实现线程同步的关键字,主要用于保护共享资源的访问,确保在多线程环境中同一时间只有一个线程能够访问特定的代码段或方法。它提供了互斥性和可见性两个重要特性,确保了线程间操作的原子性和数据的一致性。
synchronized的特性
synchronized
关键字具有三个基本特性,分别是互斥性、可见性和有序性。
互斥性
synchronized
关键字确保了在其控制范围内的代码在同一时间只能被一个线程执行,实现了资源的互斥访问。当一个线程进入了
synchronized
代码块或方法时,其他试图进入该同步区域的线程必须等待,直至拥有锁的线程执行完毕并释放锁。
可见性
synchronized
还确保了线程间的数据可见性。一旦一个线程在
synchronized
块中修改了共享变量的值,其他随后进入同步区域的线程可以看到这个更改。这是因为
synchronized
的解锁过程包含了将工作内存中的最新值刷新回主内存的操作,而加锁过程则会强制从主内存中重新加载变量的值。
有序性
synchronized
提供的第三个特性是有序性,它可以确保在多线程环境下,对于同一个锁的解锁操作总是先行于随后对同一个锁的加锁操作。这就意味着,通过
synchronized
建立起了线程之间的内存操作顺序关系,有效地解决了由于编译器和处理器优化可能带来的指令重排序问题。
synchronized可以实现哪锁?
有上述synchronized的特性,我们可以知道synchronized可以实现这些锁:
- 可重入锁(Reentrant Lock)
:
synchronized
实现的锁是可重入的,这意味着同一个线程可以多次获取同一个锁,而不会被阻塞。这种锁机制允许线程在持有锁的情况下再次获取相同的锁,避免了死锁的发生。 - 排它锁/互斥锁/独占锁
:
synchronized
实现的锁是互斥的,也就是说,在同一时间只有一个线程能够获取到锁,其他线程必须等待该线程释放锁才能继续执行。这确保了同一时刻只有一个线程可以访问被锁定的代码块或方法,从而保证了数据的一致性和完整性。 - 悲观锁
:
synchronized
实现的锁属于悲观锁,因为它默认情况下假设会发生竞争,并且会导致其他线程阻塞,直到持有锁的线程释放锁。悲观锁的特点是对并发访问持保守态度,认为会有其他线程来竞争共享资源,因此在访问共享资源之前会先获取锁。 - 非公平锁:
synchronized
在早期的Java版本中,默认实现的是非公平锁,也就是说,线程获取锁的顺序并不一定按照它们请求锁的顺序来进行,而是允许“插队”,即已经在等待队列中的线程可能被后来请求锁的线程抢占。
有关Java中的锁的分类,请参考:
阿里二面:Java中锁的分类有哪些?你能说全吗?
synchronized使用方式
synchronized
关键字可以修饰方法、代码块或静态方法,用于确保同一时间只有一个线程可以访问被
synchronized
修饰的代码片段。
修饰实例方法
当
synchronized
修饰实例方法时,锁住的是当前实例对象(this)。这意味着在同一时刻,只能有一个线程访问此方法,所有对该对象实例的其他同步方法调用将会被阻塞,直到该线程释放锁。
public class SynchronizedInstanceMethod implements Runnable{
private static int counter = 0;
// 修饰实例方法,锁住的是当前实例对象
private synchronized void add() {
counter++;
}
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
add();
}
}
public static void main(String[] args) throws Exception {
SynchronizedInstanceMethod sim = new SynchronizedInstanceMethod();
Thread t1 = new Thread(sim);
Thread t2 = new Thread(sim);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Final counter value: " + counter);
}
}
像上述这个例子,大家在接触多线程时一定会看过或者写过类似的代码,
i++
在多线程的情况下是线程不安全的,所以我们使用
synchronized
作用在累加的方法上,使其变成线程安全的。上述打印结果为:
Final block counter value: 2000
而对于
synchronized
作用于实例方法上时,锁的是当前实例对象,但是如果我们锁住的是不同的示例对象,那么
synchronized
就不能保证线程安全了。如下代码:
public class SynchronizedInstanceMethod implements Runnable{
private static int counter = 0;
// 修饰实例方法,锁住的是当前实例对象
private synchronized void add() {
counter++;
}
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
add();
}
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(new SynchronizedInstanceMethod());
Thread t2 = new Thread(new SynchronizedInstanceMethod());
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Final counter value: " + counter);
}
}
执行结果为:
Final counter value: 1491
修饰静态方法
若
synchronized
修饰的是静态方法,那么锁住的是类的Class对象,因此,无论多少个该类的实例存在,同一时刻也只有一个线程能够访问此静态同步方法。针对修饰实例方法的线程不安全的示例,我们只需要在
synchronized
修饰的实例方法上加上
static
,将其变成静态方法,此时
synchronized
锁住的就是类的class对象。
public class SynchronizedStaticMethod implements Runnable{
private static int counter = 0;
// 修饰实例方法,锁住的是当前实例对象
private static synchronized void add() {
counter++;
}
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
add();
}
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(new SynchronizedStaticMethod());
Thread t2 = new Thread(new SynchronizedStaticMethod());
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Final counter value: " + counter);
}
}
执行结果为:
Final counter value: 2000
修饰代码块
通过指定对象作为锁,可以更精确地控制同步范围。这种方式允许在一个方法内部对不同对象进行不同的同步控制。可以指定一个对象作为锁,只有持有该对象锁的线程才能执行被
synchronized
修饰的代码块。
public class SynchronizedBlock implements Runnable{
private static int counter = 0;
@Override
public void run() {
// 这个this还可以是SynchronizedBlock.class,说明锁住的是class对象
synchronized (this){
for (int i = 0; i < 1000; i++) {
counter++;
}
}
}
public static void main(String[] args) throws Exception {
SynchronizedBlock block = new SynchronizedBlock();
Thread t1 = new Thread(block);
Thread t2 = new Thread(block);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Final counter value: " + counter);
}
}
synchronized
内置锁作为一种对象级别的同步机制,其作用在于确保临界资源的互斥访问,实现线程安全。它本质上锁定的是对象的监视器(Object Monitor),而非具体的引用变量。这种锁具有可重入性,即同一个线程在已经持有某对象锁的情况下,仍能再次获取该对象的锁,这显著增强了线程安全代码的编写便利性,并在一定程度上有助于降低因线程交互引起的死锁风险。
关于如何避免死锁,请参考:
阿里二面:如何定位&避免死锁?连着两个面试问到了!
synchronized的底层原理
在JDK 1.6之前,
synchronized
关键字所实现的锁机制确实被认为是重量级锁。这是因为早期版本的Java中,synchronized的实现依赖于操作系统的互斥量(Mutexes)来实现线程间的同步,这涉及到了从用户态到内核态的切换以及线程上下文切换等相对昂贵的操作。一旦一个线程获得了锁,其他试图获取相同锁的线程将会被阻塞,这种阻塞操作会导致线程状态的改变和CPU资源的消耗,因此在高并发、低锁竞争的情况下,这种锁机制可能会成为性能瓶颈。
而在JDK 1.6中,对synchronized进行了大量优化,其中包括引入了偏向锁(Biased Locking)、轻量级锁(Lightweight Locking)的概念。接下来我们先说一下JDK1.6之前
synchronized
的原理。
对象的组成结构
在JDK1.6之前,在Java虚拟机中,Java对象的内存结构主要有
对象头(Object Header)
,
实例数据(Instance Data)
,
对齐填充(Padding)
三个部分组成。
对象头(Object Header)
:
对象头主要包含了两部分信息:Mark Word(标记字段)和指向类元数据(Class Metadata)的指针。Mark Word 包含了一些重要的标记信息,比如对象是否被锁定、对象的哈希码、GC相关信息等。类元数据指针指向对象的类元数据,用于确定对象的类型信息、方法信息等。实例数据(Instance Data)
:
实例数据是对象的成员变量和实例方法所占用的内存空间,它们按照声明的顺序依次存储在对象的实例数据区域中。实例数据包括对象的所有非静态成员变量和非静态方法。填充(Padding)
:
在JDK 1.6及之前的版本中,为了保证对象在内存中的存储地址是8字节的整数倍,可能会在对象的实例数据之后添加一些填充字节。这些填充字节的目的是对齐内存地址,提高内存访问效率。填充字节通常不包含任何实际数据,只是用于占位。

对象头
在JDK 1.6之前的Java HotSpot虚拟机中,对象头的基本组成依然包含Mark Word和类型指针(Klass Pointer),但当时对于锁的实现还没有引入偏向锁和轻量级锁的概念,因此对象头中的Mark Word在处理锁状态时比较简单,主要是用来存储锁的状态信息以及与垃圾收集相关的数据。在一个32位系统重对象头大小通常约为32位,而在64位系统中大小通常为64位。
对象头组成部分:
- Mark Word(标记字)
:
在早期版本的HotSpot虚拟机中,Mark Word主要存储的信息包括:
- 对象的hashCode(在没有锁定时)。
- 对象的分代年龄(用于垃圾回收算法)。
- 锁状态信息,如无锁、重量级锁状态(在使用
synchronized
关键字时)。 - 对象的锁指针(Monitor地址,当对象被重量级锁锁定时,存储的是指向重量级锁(Monitor)的指针)。
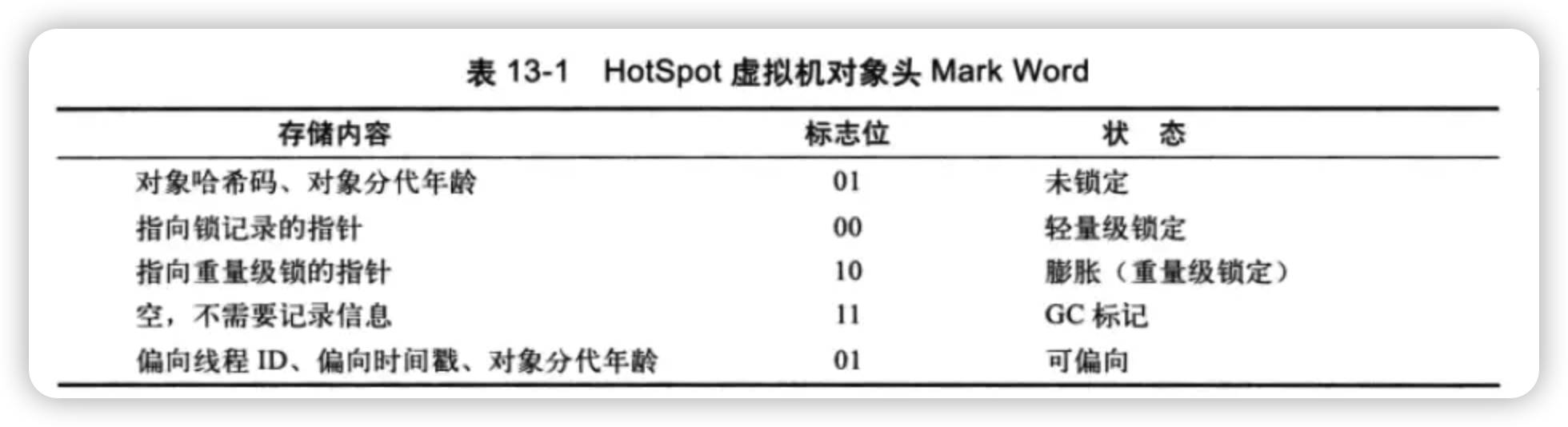
对象头中的Mark Word是一个非固定的数据结构,它会根据对象的状态复用自己的存储空间,存储不同的数据。在Java HotSpot虚拟机中,Mark Word会随着程序运行和对象状态的变化而存储不同的信息。其信息变化如下:
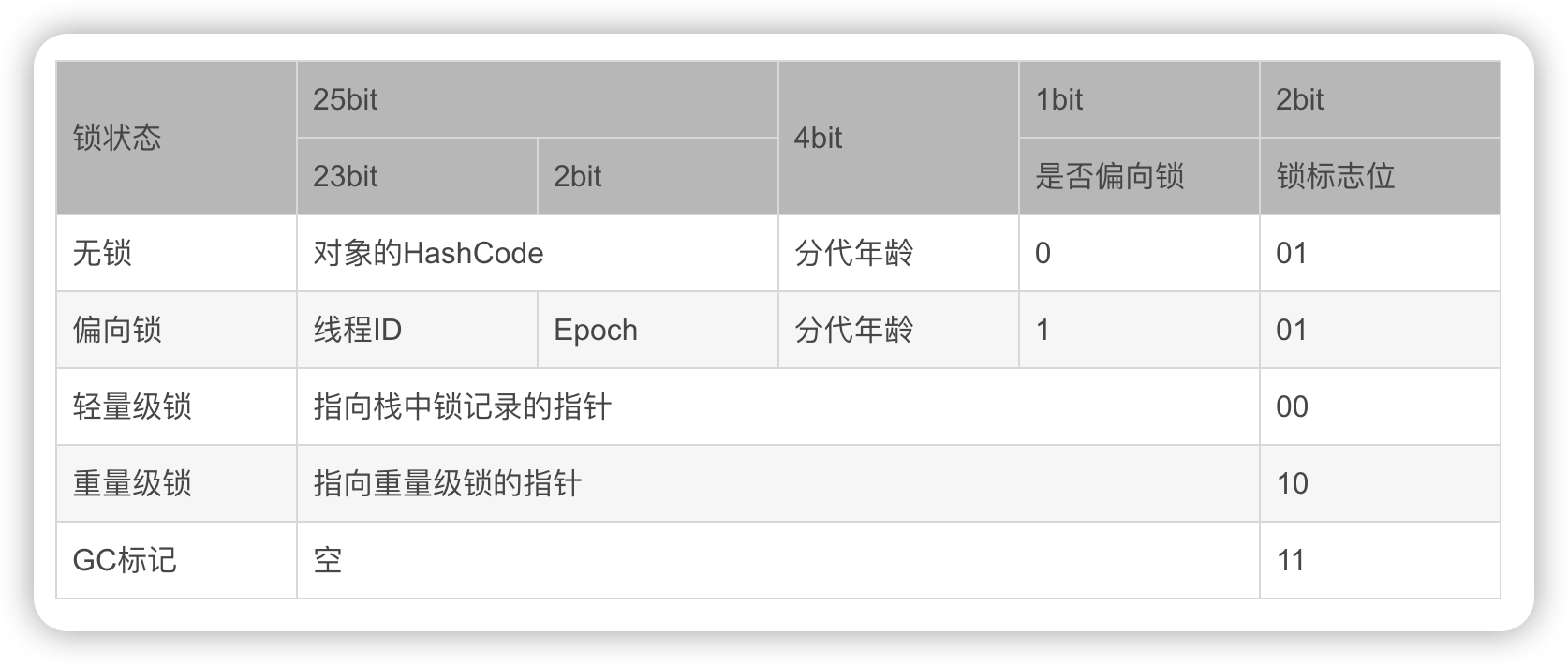
从存储信息的变化可以看出:
- 对象头的最后两位存储了锁的标志位,01表示初始状态,即未加锁。此时,对象头内存储的是对象自身的哈希码。无锁和偏向锁的锁标志位都是01,只是在前面的1bit区分了这是无锁状态还是偏向锁状态。
- 当进入偏向锁阶段时,对象头内的标志位变为01,并且存储当前持有锁的线程ID。这意味着只有第一个获取锁的线程才能继续持有锁,其他线程不能竞争同一把锁。
- 在轻量级锁阶段,标志位变为00,对象头内存储的是指向线程栈中锁记录的指针。这种情况下,多个线程可以通过比较锁记录的地址与对象头内的指针地址来确定自己是否拥有锁。
其中轻量级锁和偏向锁是Java 6 对 synchronized 锁进行优化后新增加的。重量级锁也就是通常说synchronized的对象锁,锁标识位为10,其中指针指向的是monitor对象(也称为管程或监视器锁)的起始地址。
类型指针(Klass Pointer 或 Class Pointer)
:
类型指针指向对象的类元数据(Class Metadata),即对象属于哪个类的类型信息,用于确定对象的方法表和字段布局等。在一个32位系统重大小通常约为32位,而在64位系统中大小通常为64位。数组长度(Array Length)
(仅对数组对象适用):
如果对象是一个数组,对象头中会额外包含一个字段来存储数组的长度。在一个32位系统中大小通常约为32位,而在64位系统中大小通常为64位。
监视器(Monitor)
在Java中,每个对象都与一个Monitor关联,Monitor是一种同步机制,负责管理线程对共享资源的访问权限。当一个Monitor被线程持有时,对象便处于锁定状态。Java的
synchronized
关键字在JVM层面上通过
MonitorEnter
和
MonitorExit
指令实现方法同步和代码块同步。
MonitorEnter
尝试获取对象的Monitor所有权(即获取对象锁),
MonitorExit
确保每个MonitorEnter操作都有对应的释放操作。
在HotSpot虚拟机中,Monitor具体由ObjectMonitor实现,其结构如下:
ObjectMonitor() {
_header = NULL;
_count = 0; //锁计数器,表示重入次数,每当线程获取锁时加1,释放时减1。
_waiters = 0, //等待线程总数,不一定在实际的ObjectMonitor中有直接体现,但在管理线程同步时是一个重要指标。
_recursions = 0; //与_count类似,表示当前持有锁的线程对锁的重入次数。
_object = NULL; // 通常指向关联的Java对象,即当前Monitor所保护的对象。
_owner = NULL; // 持有ObjectMonitor对象的线程地址,即当前持有锁的线程。
_WaitSet = NULL; //存储那些调用过`wait()`方法并等待被唤醒的线程队列。
_WaitSetLock = 0 ; // 用于保护_WaitSet的锁。
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ; //阻塞在EntryList上的单向线程列表,可能用于表示自旋等待队列或轻量级锁的自旋链表。
FreeNext = NULL ; // 在对象Monitor池中可能用于链接空闲的ObjectMonitor对象。
_EntryList = NULL ; // 等待锁的线程队列,当线程请求锁但发现锁已被持有时,会被放置在此队列中等待。
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ; // 标志位,可能用于标识_owner是否指向一个真实的线程对象。
}
其中最重要的就是
_owner
、
_WaitSet
、
_EntryList
和
count
几个字段,他们之间的转换关系:
_owner
:
当一个线程首次成功执行
synchronized
代码块或方法时,会尝试获取对象的Monitor(即
ObjectMonitor
),并将自身设置为
_owner
。该线程此刻拥有了对象的锁,可以独占访问受保护的资源。_EntryList
→
_owner
:
当多个线程同时尝试获取锁时,除第一个成功获取锁的线程外,其余线程会进入
_EntryList
排队等待。一旦
_owner
线程释放锁,
_EntryList
中的下一个线程将有机会获取锁并成为新的
_owner
。_owner
→
_WaitSet
:
当
_owner
线程在持有锁的情况下调用
wait()
方法时,它会释放锁(即
_owner
置为
NULL
),并把自己从
_owner
转变为等待状态,然后将自己添加到
_WaitSet
中。这时,线程进入等待状态,暂停执行,等待其他线程通过
notify()
或
notifyAll()
唤醒。_WaitSet
→
_EntryList
:
当其他线程调用
notify()
或
notifyAll()
方法时,会选择一个或全部在
_WaitSet
中的线程,将它们从
_WaitSet
移除,并重新加入到
_EntryList
中。这样,这些线程就有机会再次尝试获取锁并成为新的
_owner
。
有上述转换关系我们可以发现,当多线程访问同步代码时:
- 线程首先尝试进入_EntryList竞争锁,成功获取Monitor后,将_owner设置为当前线程并将count递增。
- 若线程调用wait()方法,会释放Monitor、清空_owner,并将线程移到_WaitSet中等待被唤醒。
- 当线程执行完毕或调用notify()/notifyAll()唤醒等待线程后,会释放Monitor,使得其他线程有机会获取锁。
在Java对象的对象头(Mark Word)中,存储了与锁相关的状态信息,这使得任意Java对象都能作为锁来使用,同时,notify/notifyAll/wait等方法正是基于Monitor锁对象来实现的,因此这些方法必须在
synchronized
代码块中调用。
我们查看上述同步代码块
SynchronizedBlock
的字节码文件:
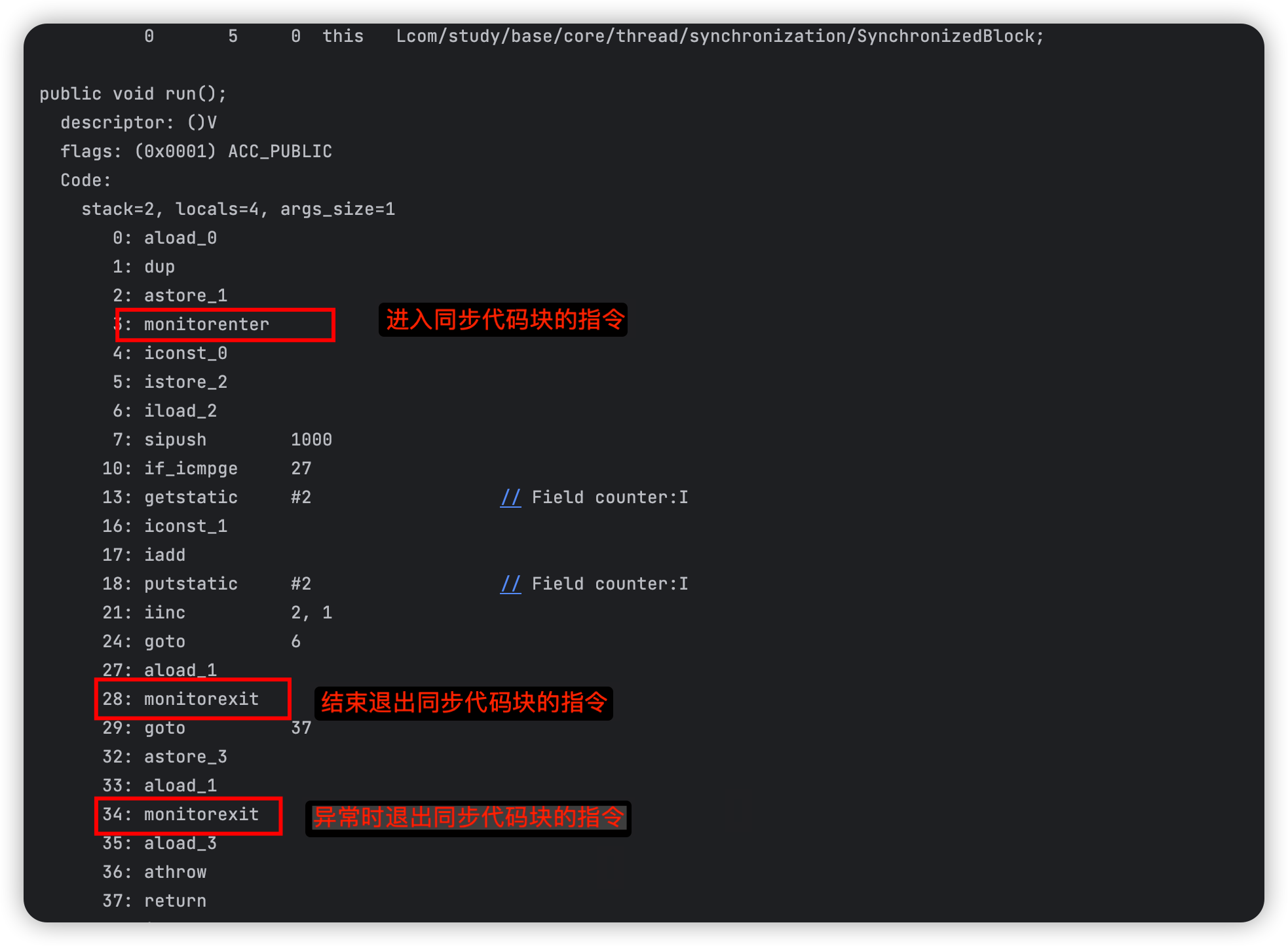
从上述字节码中可以看到同步代码块的实现是由
monitorenter
和
monitorexit
指令完成的,其中
monitorenter
指令所在的位置是同步代码块开始的位置,第一个
monitorexit
指令是用于正常结束同步代码块的指令,第二个
monitorexit
指令是用于异常结束时所执行的释放Monitor指令。
关于查看class文件的字节码文件,有两种方式:1、通过命令: javap -verbose <class路径>/class文件。2、IDEA中通过插件:
jclasslib Bytecode viewer
。
我们再看一下作用于同步方法的字节码:
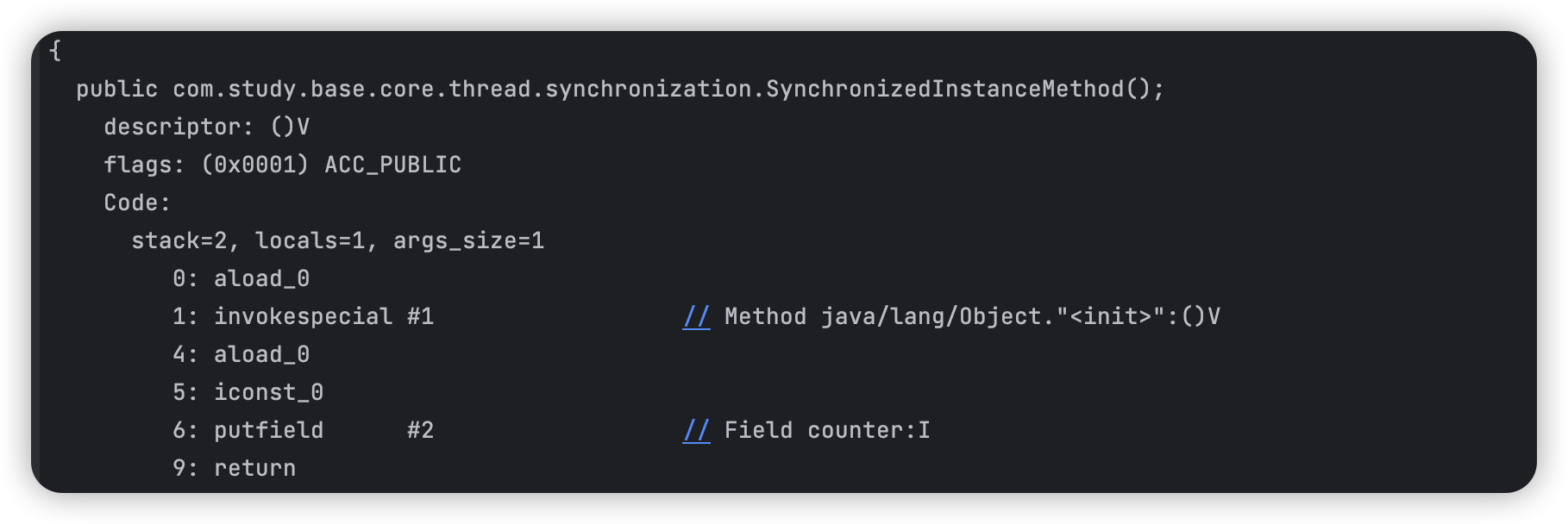
我们可以看出同步方法上没有
monitorenter
和
monitorexit
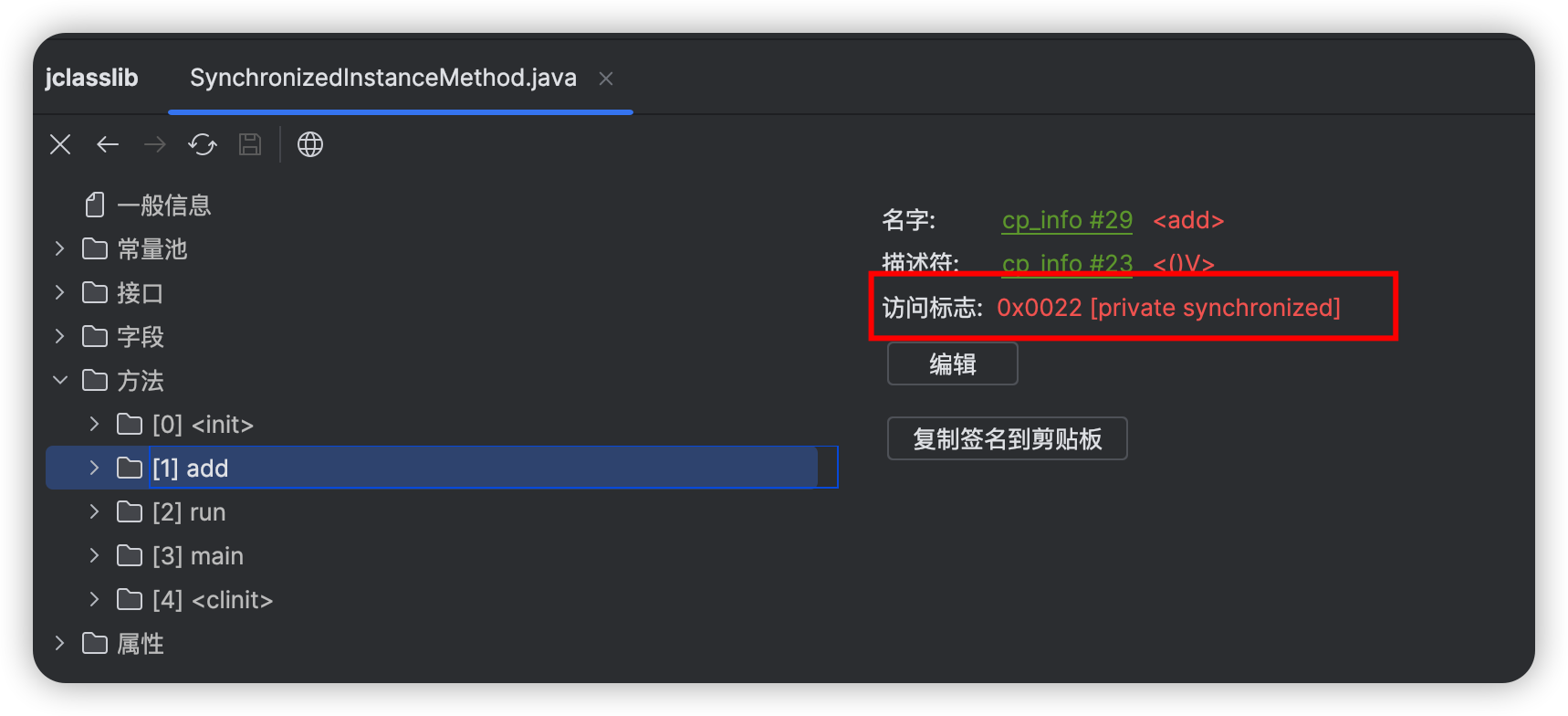
这两个指令了,而在查看该方法的class文件的结构信息时发现了
Access flags
后边的synchronized标识,该标识表明了该方法是一个同步方法。Java虚拟机通过该标识可以来辨别一个方法是否为同步方法,如果有该标识,线程将持有Monitor,在执行方法,最后释放Monitor。
总结
synchronized
作用于同步代码块时的原理:
Java虚拟机使用monitorenter和monitorexit指令实现同步块的同步。monitorenter指令在进入同步代码块时执行,尝试获取对象的Monitor(即锁),monitorexit指令在退出同步代码块时执行,释放Monitor。
而对于方法级别的同步的原理:
Java虚拟机通过在方法的访问标志(Access flags)中设置ACC_SYNCHRONIZED标志来实现方法同步。当一个方法被声明为
synchronized
时,编译器会在生成的字节码中插入monitorenter和monitorexit指令,确保在方法执行前后正确地获取和释放对象的Monitor。
本文已收录于我的个人博客:
码农Academy的博客,专注分享Java技术干货,包括Java基础、Spring Boot、Spring Cloud、Mysql、Redis、Elasticsearch、中间件、架构设计、面试题、程序员攻略等