最近在用next写一个多语言的项目,找了好久没找到简单实现的教程,实践起来感觉都比较复杂,最后终于是在官方文档找到了,结合网上找到的代码demo,终于实现了,在这里简单总结一下。
此教程适用于比较简单的项目实现,如果你是刚入门next,并且不想用太复杂的方式去实现一个多语言项目,那么这个教程就挺适合你的。
此教程适用于app目录的next项目。
先贴一下参阅的连接:
官方教程: next i18n 文档
可参阅的代码demo
实现思路
结合文件结构解说一下大致逻辑:
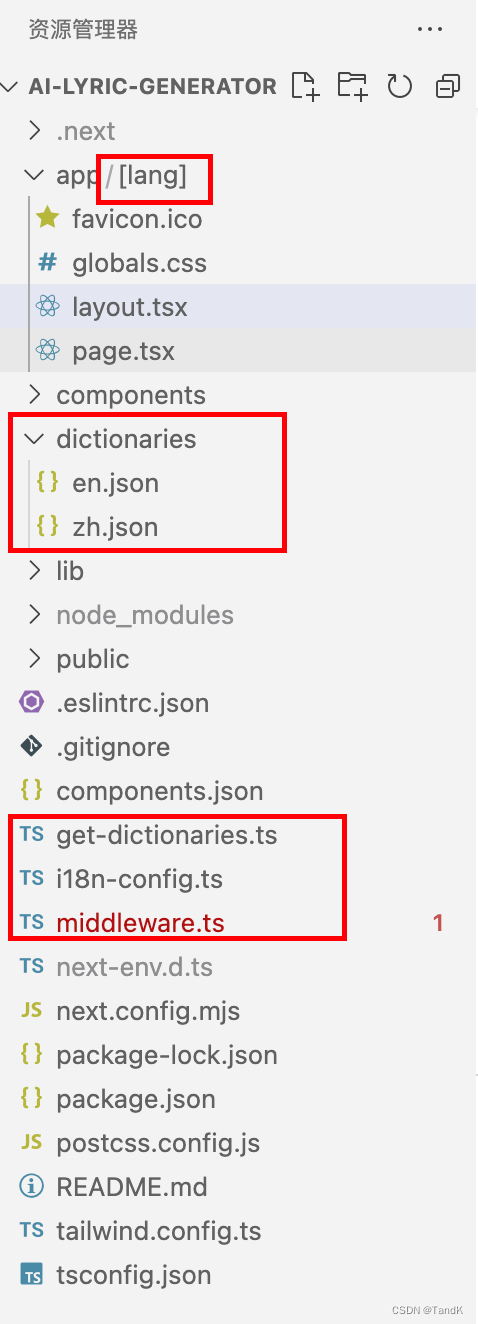
i18n-config.ts
只是一个全局管理多语言简写的
枚举
文件,其他文件可以引用这个文件,这样就不会出现不同文件对不上的情况。
middleware.ts
做了一层拦截,在用户访问
localhost:3000
的时候能通过请求头判断用户常用的语言,配合app目录多出来的
[lang]
目录,从而实现跳转到
localhost:3000/zh
这样。
dictionaries
文件夹下放各语言的json字段,通过字段的引用使页面呈现不同的语种。
事实上每个页面的
layout.tsx
和
page.tsx
都会将语言作为参数传入,在对应的文件里,再调用
get-dictionaries.ts
文件里的方法就能读取到对应的json文件里的内容了。
大致思路是这样,下面贴对应的代码。
/i18n-config.ts
export const i18n = {
defaultLocale: "en",
// locales: ["en", "zh", "es", "hu", "pl"],
locales: ["en", "zh"],
} as const;
export type Locale = (typeof i18n)["locales"][number];
/middleware.ts
,需要先安装两个依赖,这两个依赖用于判断用户常用的语言:
npm install @formatjs/intl-localematcher
npm install negotiator
然后才是
/middleware.ts
的代码:
import { NextResponse } from "next/server";
import type { NextRequest } from "next/server";
import { i18n } from "./i18n-config";
import { match as matchLocale } from "@formatjs/intl-localematcher";
import Negotiator from "negotiator";
function getLocale(request: NextRequest): string | undefined {
// Negotiator expects plain object so we need to transform headers
const negotiatorHeaders: Record<string, string> = {};
request.headers.forEach((value, key) => (negotiatorHeaders[key] = value));
// @ts-ignore locales are readonly
const locales: string[] = i18n.locales;
// Use negotiator and intl-localematcher to get best locale
let languages = new Negotiator({ headers: negotiatorHeaders }).languages(
locales,
);
const locale = matchLocale(languages, locales, i18n.defaultLocale);
return locale;
}
export function middleware(request: NextRequest) {
const pathname = request.nextUrl.pathname;
// // `/_next/` and `/api/` are ignored by the watcher, but we need to ignore files in `public` manually.
// // If you have one
// if (
// [
// '/manifest.json',
// '/favicon.ico',
// // Your other files in `public`
// ].includes(pathname)
// )
// return
// Check if there is any supported locale in the pathname
const pathnameIsMissingLocale = i18n.locales.every(
(locale) =>
!pathname.startsWith(`/${locale}/`) && pathname !== `/${locale}`,
);
// Redirect if there is no locale
if (pathnameIsMissingLocale) {
const locale = getLocale(request);
// e.g. incoming request is /products
// The new URL is now /en-US/products
return NextResponse.redirect(
new URL(
`/${locale}${pathname.startsWith("/") ? "" : "/"}${pathname}`,
request.url,
),
);
}
}
export const config = {
// Matcher ignoring `/_next/` and `/api/`
matcher: ["/((?!api|_next/static|_next/image|favicon.ico).*)"],
};
/dictionaries
下的因项目而异,可以看个参考:
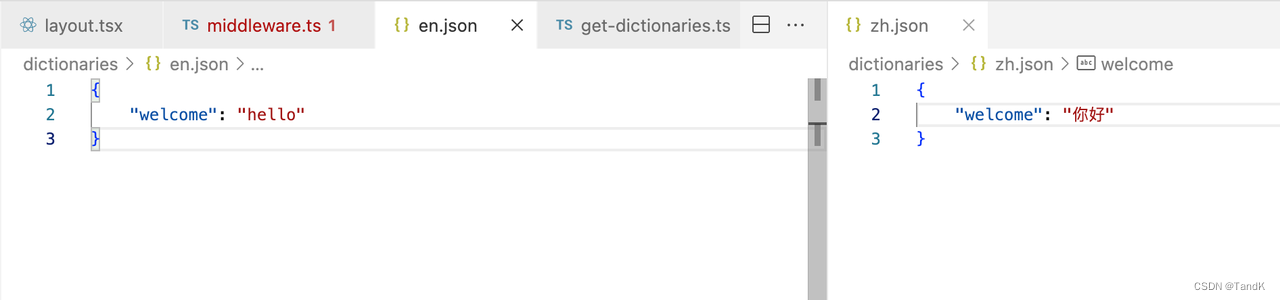
文件以语言简写命名,
/i18n-config.ts
里的
locales
有什么语言,这里就有多少个对应的文件就行了。
/get-dictionaries.ts
import "server-only";
import type { Locale } from "./i18n-config";
// We enumerate all dictionaries here for better linting and typescript support
// We also get the default import for cleaner types
const dictionaries = {
en: () => import("./dictionaries/en.json").then((module) => module.default),
zh: () => import("./dictionaries/zh.json").then((module) => module.default),
};
export const getDictionary = async (locale: Locale) => dictionaries[locale]?.() ?? dictionaries.en();
实际使用可以做个参考:
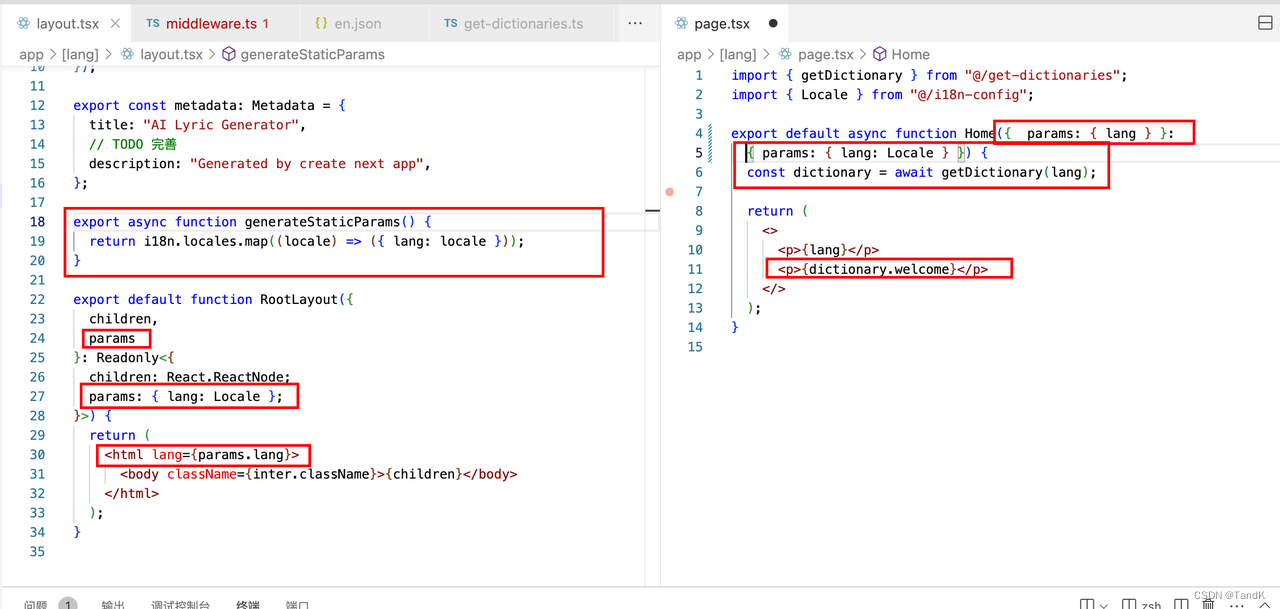
到这里其实就实现了,但是下面的事情需要注意:
如果你的项目有集成了第三方需要配知道middleware的地方,比如clerk,需要调试一下是否冲突。
如果你不知道clerk是什么,那么下面可以不用看,下面将以clerk为例,描述一下可能遇到的问题和解决方案。
Clerk适配
clerk是一个可以快速登录的第三方库,用这个库可以快速实现用户登录的逻辑,包括Google、GitHub、邮箱等的登录。
clerk允许你配置哪些页面是公开的,哪些页面是需要登录之后才能看的,如果用户没登录,但是却访问了需要登录的页面,就会返回401,跳转到登录页面。
就是这里冲突了,因为我们实现多语言的逻辑是,用户访问
localhost:3000
的时候判断用户常用的语言,从而实现跳转到
localhost:3000/zh
这样。
这两者实现都在
middleware.ts
文件中,上面这种配置会有冲突,这两者只有一个能正常跑通,而我们想要的效果是两者都能跑通,既能自动跳转到登录页面,也能自动跳转到常用语言页面。
技术问题定位:这是因为你重写了middleware方法,导致不会执行Clerk的authMiddleware方法,视觉效果上,就是多语言导致了Clerk不会自动跳转登录。
所以要把上面的middleware方法写到authMiddleware方法里的beforeAuth里去,Clerk官方有说明:
Clerk authMiddleware说明
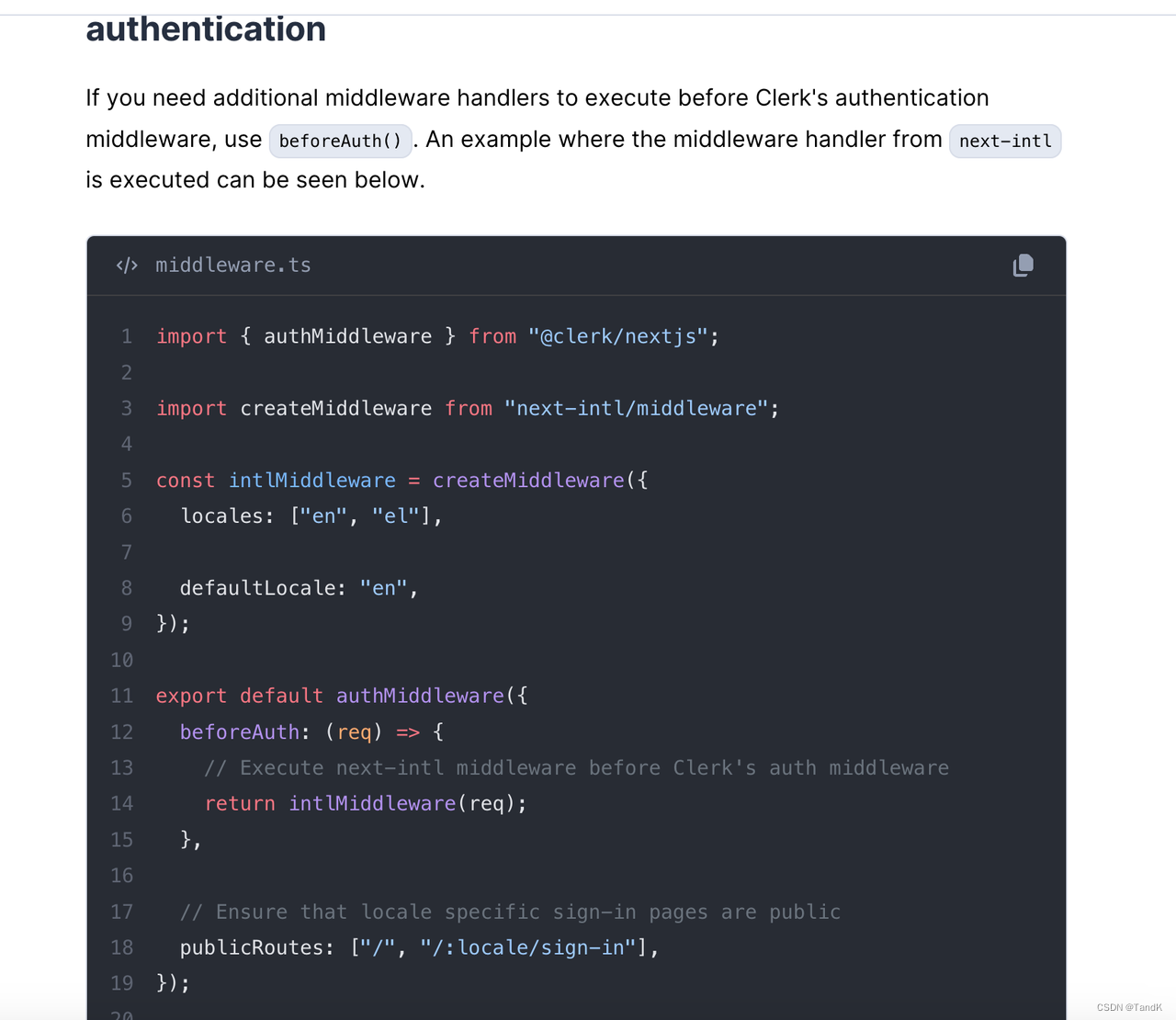
所以现在/middleware.ts文件内的内容变成了:
import { NextResponse } from "next/server";
import type { NextRequest } from "next/server";
import { authMiddleware } from "@clerk/nextjs";
import { i18n } from "./i18n-config";
import { match as matchLocale } from "@formatjs/intl-localematcher";
import Negotiator from "negotiator";
function getLocale(request: NextRequest): string | undefined {
// Negotiator expects plain object so we need to transform headers
const negotiatorHeaders: Record<string, string> = {};
request.headers.forEach((value, key) => (negotiatorHeaders[key] = value));
// @ts-ignore locales are readonly
const locales: string[] = i18n.locales;
// Use negotiator and intl-localematcher to get best locale
let languages = new Negotiator({ headers: negotiatorHeaders }).languages(
locales,
);
const locale = matchLocale(languages, locales, i18n.defaultLocale);
return locale;
}
export const config = {
// Matcher ignoring `/_next/` and `/api/`
matcher: ["/((?!api|_next/static|_next/image|favicon.ico).*)"],
// matcher: ["/((?!.+\\.[\\w]+$|_next).*)", "/", "/(api|trpc)(.*)"],
};
export default authMiddleware({
publicRoutes: ['/anyone-can-visit-this-route'],
ignoredRoutes: ['/no-auth-in-this-route'],
beforeAuth: (request) => {
const pathname = request.nextUrl.pathname;
// // `/_next/` and `/api/` are ignored by the watcher, but we need to ignore files in `public` manually.
// // If you have one
if (
[
'/manifest.json',
'/favicon.ico',
'/serviceWorker.js',
'/en/sign-in'
// Your other files in `public`
].includes(pathname)
)
return
// Check if there is any supported locale in the pathname
const pathnameIsMissingLocale = i18n.locales.every(
(locale) =>
!pathname.startsWith(`/${locale}/`) && pathname !== `/${locale}`,
);
// Redirect if there is no locale
if (pathnameIsMissingLocale) {
const locale = getLocale(request);
// e.g. incoming request is /products
// The new URL is now /en-US/products
return NextResponse.redirect(
new URL(
`/${locale}${pathname.startsWith("/") ? "" : "/"}${pathname}`,
request.url,
),
);
}
}
});
这样就OK了,大功告成。