Supervisor 安装与使用
一、Supervisor 介绍
Supervisor 是一个用 Python 编写的进程管理工具,它可以用于监控和控制类 UNIX 操作系统上的多个进程。它是一个客户端/服务器系统,其中 Supervisor 的服务器端称为 supervisord,负责启动管理的子进程、响应客户端命令、重启崩溃或退出的子进程、记录子进程的 stdout 和 stderr 输出,以及处理子进程生命周期中的事件。客户端则称为 supervisorctl,它提供了一个类 shell 的接口,允许用户通过命令行与 supervisord 服务器进程通信,以控制子进程的状态、启动和停止进程,并获取正在运行的进程列表。
Supervisor官网地址:
http://supervisord.org/
二、安装环境介绍
Linux:CentOS Linux release 7.6.1810 (Core)
Supervisor:supervisor-4.2.5
Python:Python 2.7.5
三、安装 Supervisor
1、下载 supervisor 源码包【supervisor-4.2.5.tar.gz】
2、在根目录新建一个名为【service】的目录,并把【supervisor-4.2.5.tar.gz】包移入进去
#新建目录 mkdirservice#解压supervisor源码包 tar -zxvf supervisor-4.2.5.tar.gz
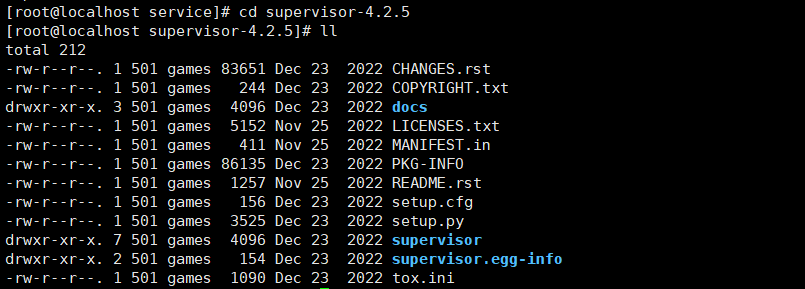
3、进入supervisor目录,内容如下图:
#进入目录 cd supervisor-4.2.5 #查看目录下的文件 ll
4、安装 supervisor
#安装 supervisor python setup.py install
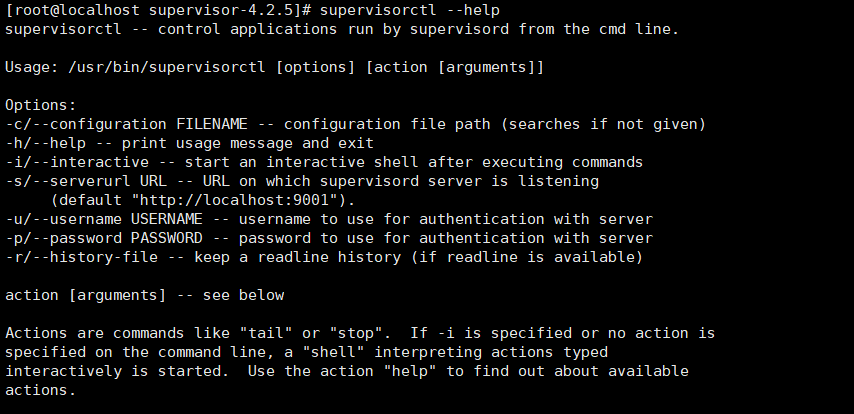
5、使用帮助命令来检测是否安装成功,结果如下图:
supervisorctl --help
四、配置 Supervisor
1、创建一个文件夹,用于存储相关配置文件
mkdir /etc/supervisor2、使用命令,创建一个【Supervisor】配置文件。
#符合(>)右侧的是配置文件的路径 echo_supervisord_conf > /etc/supervisor/supervisord.conf
3、找到 supervisord.conf 文件,修改里面的配置参数
#原配置 [unix_http_server]file=/tmp/supervisor.sock ; the path to the socket file;chmod=0700 ; socket file mode (default 0700)
;chown=nobody:nogroup ; socket file uid:gid owner
;username=user ; defaultis no username (open server)
;password=123 ; defaultis no password (open server)#修改后的配置,原先的/tmp目录下的内容容易被系统删除,导致启动失败 [unix_http_server]file=/var/run/supervisor.sock ; the path to the socket file;chmod=0700 ; socket file mode (default 0700)
;chown=nobody:nogroup ; socket file uid:gid owner
;username=user ; defaultis no username (open server)
;password=123 ; defaultis no password (open server)------------------------------------------------------------------------------ #原配置 [supervisord]
logfile=/tmp/supervisord.log ; main log file; default $CWD/supervisord.loglogfile_maxbytes=50MB ; max main logfile bytes b4 rotation; default50MB
logfile_backups=10 ; #of main logfile backups; 0 means none, default 10 loglevel=info ; log level; default info; others: debug,warn,trace
pidfile=/tmp/supervisord.pid ; supervisord pidfile; default supervisord.pid
nodaemon=false ; start in foreground if true; default falsesilent=false ; no logs to stdout if true; default falseminfds=1024 ; min. avail startup file descriptors; default 1024minprocs=200 ; min. avail process descriptors;default 200 #修改后的配置,修改了服务的日志文件目录,修改了supervisord.pid的存放位置 [supervisord]
logfile=/etc/supervisor/log/supervisord.log; 避免被系统删除
logfile_maxbytes=50MB ; max main logfile bytes b4 rotation; default50MB
logfile_backups=10 ; #of main logfile backups; 0 means none, default 10 loglevel=info ; log level; default info; others: debug,warn,trace
pidfile=/var/run/supervisord.pid ; 避免被系统删除
nodaemon=false ; start in foreground if true; default falsesilent=false ; no logs to stdout if true; default falseminfds=1024 ; min. avail startup file descriptors; default 1024minprocs=200 ; min. avail process descriptors;default 200 ------------------------------------------------------------------------------ #原配置 [supervisorctl]
serverurl=unix:///tmp/supervisor.sock ; use a unix:// URL for a unix socket ;serverurl=http://127.0.0.1:9001 ; use an http:// url to specify an inet socket ;username=chris ; should be same as in [*_http_server] ifset
;password=123 ; should be same as in [*_http_server] ifset
;prompt=mysupervisor ; cmd line prompt (default "supervisor")
;history_file=~/.sc_history ; use readline history ifavailable#修改后的配置,修改supervisor.sock的存放位置,避免被系统删除 [supervisorctl]
serverurl=unix:///var/run/supervisor.sock ;serverurl=http://127.0.0.1:9001 ; use an http:// url to specify an inet socket ;username=chris ; should be same as in [*_http_server] ifset
;password=123 ; should be same as in [*_http_server] ifset
;prompt=mysupervisor ; cmd line prompt (default "supervisor")
;history_file=~/.sc_history ; use readline history ifavailable------------------------------------------------------------------------------ #原配置 ;[include]
;files= relative/directory/*.ini
# 修改后的配置,设置子任务的配置文件目录
[include]
files = /etc/supervisor/conf.d/*.ini
4、保存退出后更新配置文件,如果之前没启动过服务可以不用更新
supervisorctl -c /etc/supervisor/supervisord.conf update
五、配置 Supervisor 的子任务
进入到【/etc/supervisor/conf.d】目录,创建名为【test.ini】的子任务,并写入如下内容:
#进入子任务配置文件目录 cd /etc/supervisor/conf.d#创建子任务配置文件 touch test.ini#编辑配置文件 vi test.ini#配置文件中的具体内容 [program:test] ;要和文件名称相同
command=/usr/local/php74/bin/php think testJob ;启动该程序时将运行的命令,我这用的是TP框架中的think命令
directory=/www/school-task ;表示command命令的执行目录,本文用的时候TP框架,school-task为项目名称
autorestart=true;自动重启
startsecs=3;启动后程序需要保持运行的总秒数,以认为启动成功(将进程从STARTING状态移动到running状态)。设置为0表示程序不需要在任何特定的时间内保持运行
startretries=3;启动失败时的最多重试次数
stdout_logfile=/etc/supervisor/log/test.out.log ;输出日志文件路径stderr_logfile=/etc/supervisor/log/test.err.log;错误日志文件路径
stdout_logfile_maxbytes=2MB ;设置stdout_logfile的文件大小
stderr_logfile_maxbytes=2MB ;设置stderr_logfile的文件大小
user=root ;指定运行的用户
priority=999;程序在启动和关闭顺序中的相对优先级
numprocs=1process_name=%(program_name)s_%(process_num)02d
六、supervisord相关操作命令
#启动supervisord supervisord -c /etc/supervisor/supervisord.conf#关闭supervisord supervisorctl -c /etc/supervisor/supervisord.conf shutdown#查看supervisord管理的进程,【all】是可选参数,表示查看所有的子任务 supervisorctl -c /etc/supervisor/supervisord.conf status all#重新加载配置 supervisorctl -c /etc/supervisor/supervisord.conf update#重新启动supervisord supervisorctl -c /etc/supervisor/supervisord.conf reload
#停止supervisord管理的进程,【process_name】表示子任务名称 supervisorctl -c /etc/supervisor/supervisord.conf stop process_name#启动supervisord管理的进程,【process_name】表示子任务名称 supervisorctl -c /etc/supervisor/supervisord.conf start process_name
七、添加supervisord的systemctl服务命令和开机自启
1、新建一个服务文件【/usr/lib/systemd/system/supervisord.service】,写入以下内容:
[Unit]
Description=Supervisor daemon
[Service]#表示systemd应该以forking模式启动服务。在此模式下,systemd会启动一个父进程,然后父进程会fork出一个或者多个子进程。 Type=forking
ExecStart=/usr/bin/supervisord -c /etc/supervisor/supervisord.conf
ExecStop=/usr/bin/supervisorctl -c /etc/supervisor/supervisord.conf shutdown
ExecReload=/usr/bin/supervisorctl -c /etc/supervisor/supervisord.conf reload
ExecStatus=/usr/bin/supervisorctl -c /etc/supervisor/supervisord.conf status
ExecRestart=/usr/bin/supervisorctl -c /etc/supervisor/supervisord.conf restart#表示当systemd需要停止服务时,它会发送信号到服务的主进程。如果服务有子进程,那么子进程不会收到这个信号。 KillMode=process#表示当服务非正常退出时(例如收到SIGKILL信号),systemd会尝试重启服务。 Restart=on-failure#如果服务失败了,systemd会在尝试重启服务前等待30秒 RestartSec=30s#指定运行服务的用户 User=root
[Install]
WantedBy=multi-user.target
2、重新加载配置文件
systemctl daemon-reload
3、配置系统开机启动
systemctl enable supervisord.service
4、systemctl 操作命令
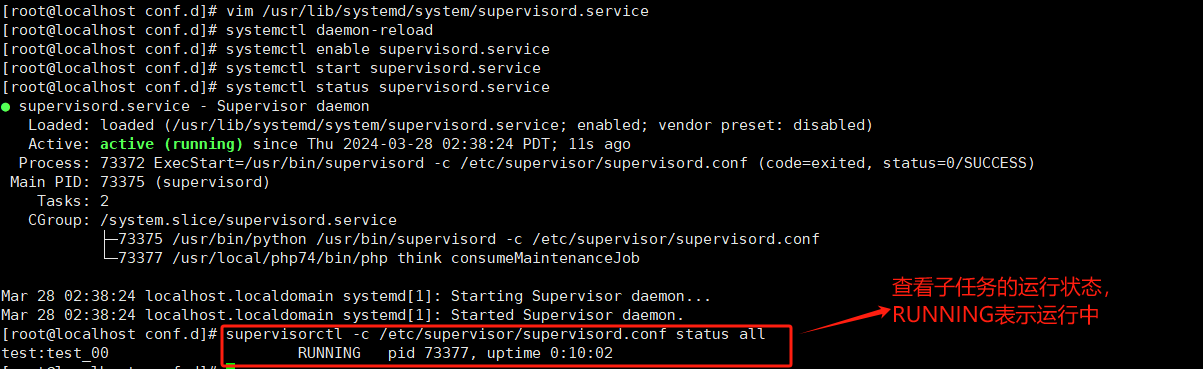
#启动supervisord systemctl start supervisord.service#查看supervisord状态 systemctl status supervisord.service#重启supervisord systemctl restart supervisord.service#停止supervisord systemctl stop supervisord.service#重载配置 systemctl reload supervisord.service
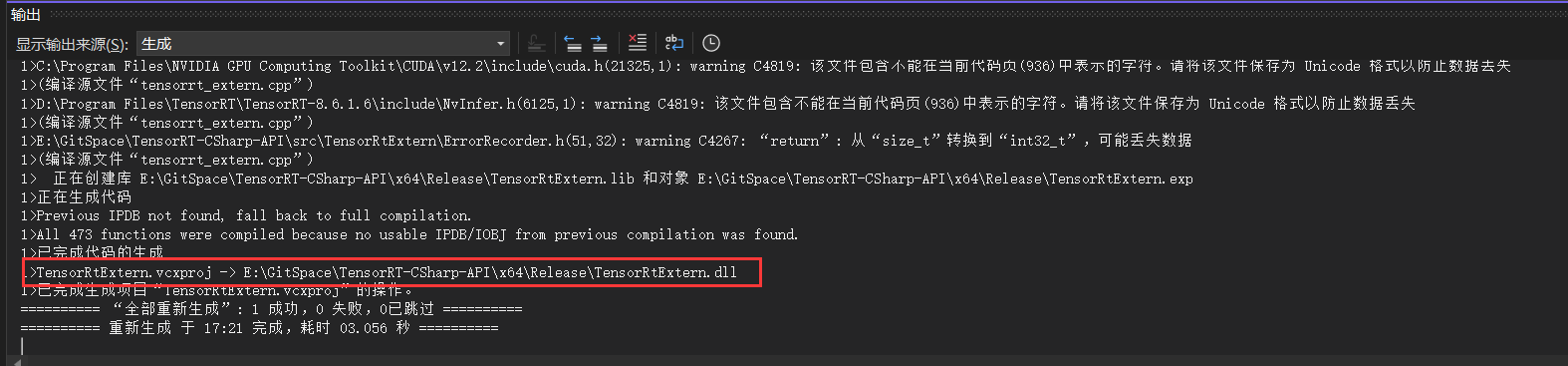
八、结果展示