Python 代码混淆工具概述
在保护Python代码安全方面,有多种混淆工具可供选择,包括 Cython, Nuitka, Pyminifier 和 IPA guard。本文将介绍这些工具的特点和适用情况,以及在实际应用中的注意事项。

在保护Python代码安全方面,有多种混淆工具可供选择,包括 Cython, Nuitka, Pyminifier 和 IPA guard。本文将介绍这些工具的特点和适用情况,以及在实际应用中的注意事项。
可以在github看代码,非常方便:
https://github.com/twbs/bootstrap/blob/main/scss/_variables.scss
就是有时候网络差。
@import
@include
@mixin
// 引入`variables.scss`
@import variables;
// 调用`@mixin`创建的sass代码块
// 在调用前必须有 @mixin bsBanner($var) {}
@include bsBanner("");
mixins/_banner.scss
里的
bsBanner()
:
// 作用应该是在被调用处加入这一块头部注释信息
@mixin bsBanner($file) {
/*!
* Bootstrap #{$file} v5.3.3 (https://getbootstrap.com/)
* Copyright 2011-2024 The Bootstrap Authors
* Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)
*/
}
那么,这一段的年份和版本又是怎么自动更新的呢?
在
bootstrap/build/banner.mjs
:
import fs from 'node:fs/promises'
import path from 'node:path'
import { fileURLToPath } from 'node:url'
const __dirname = path.dirname(fileURLToPath(import.meta.url))
const pkgJson = path.join(__dirname, '../package.json')
const pkg = JSON.parse(await fs.readFile(pkgJson, 'utf8'))
const year = new Date().getFullYear()
function getBanner(pluginFilename) {
return `/*!
* Bootstrap${pluginFilename ? ` ${pluginFilename}` : ''} v${pkg.version} (${pkg.homepage})
* Copyright 2011-${year} ${pkg.author}
* Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)
*/`
}
export default getBanner
!default
$gray-100: #f8f9fa !default;
设置默认值,优先级最低;当变量已经存在时,
!default
对应的值被覆盖。
@funciton
mix()
@return
// 使用函数tint-color()
$blue-100: tint-color($blue, 80%) !default;
scss/_functions.scss
里的
tint-color()
:
@function tint-color($color, $weight) {
// mix()是sass的color模块的内置方法
// mix($color1, $color2, $weight)
@return mix(white, $color, $weight);
}
$weight
为混合比例,可以是80%或者0.8,意思是
$color1
占比80%,
$color2
占比20%。
// 格式
// $map: (
// key1: value1,
// key2: value2,
// key3: value3
// );
$grid-breakpoints: (
xs: 0,
sm: 576px,
md: 768px,
lg: 992px,
xl: 1200px,
xxl: 1400px
) !default;
length()
map-values()
nth()
@if
@warn
@include _assert-starts-at-zero($grid-breakpoints, "$grid-breakpoints");
scss/_functions.scss
里的
_assert-starts-at-zero()
:
@mixin _assert-starts-at-zero($map, $map-name: "$grid-breakpoints") {
// 此处的length()是sass的list模块的内置方法
// 返回 $list 的长度
@if length($map) > 0 {
// map-values()是sass的map模块的内置方法
// 返回 $map 中所有值的逗号分隔列表
$values: map-values($map);
// nth()是sass的list模块的内置方法
// nth($list, $n)
// 返回 $list 在 索引 $n 处的元素,从1开始计数。如果 $n 为负数,则从 $list 末尾开始计数
$first-value: nth($values, 1);
@if $first-value != 0 {
// @warn发出警告、堆栈跟踪。相比@error,它不阻止程序继续运行
// 避免使用者传递现在已弃用的旧参数,或者以不太理想的方式调用你的 API
@warn "First breakpoint in #{$map-name} must start at 0, but starts at #{$first-value}.";
}
}
}
#{$text}
CSS变量,也就是
CSS var()
:
--gray: #f7f7f7;
color: var(--gray);
插值:
$link-color: $primary !default;
$variable-prefix: bs- !default; // Deprecated in v5.2.0 for the shorter `$prefix`
$prefix: $variable-prefix !default;
$font-family-base: var(--#{$prefix}font-sans-serif) !default;
$btn-link-color: var(--#{$prefix}link-color) !default;
// 也可以这样用:`background-image: url("/icons/#{$name}.svg");`
那么,
--#{$prefix}link-color
在哪里?
在
scss/_root.scss
:
:root,
[data-bs-theme="light"] {
--#{$prefix}link-color: #{$link-color};
}
type-of()
comparable()
unquote()
if()
calc()
$card-border-radius: var(--#{$prefix}border-radius) !default; // --bs-border-radius: 0.375rem;
$card-border-width: var(--#{$prefix}border-width) !default; // --bs-border-width: 1px;
$card-inner-border-radius: subtract($card-border-radius, $card-border-width) !default;
scss/_functions.scss
里的
subtract()
:
@function subtract($value1, $value2, $return-calc: true) {
@if $value1 == null and $value2 == null {
@return null;
}
@if $value1 == null {
@return -$value2;
}
@if $value2 == null {
@return $value1;
}
// comparable()返回 $number1 和 $number2 是否具有兼容的单位
// 如果返回 true,$number1 和 $number2 可以安全地进行计算和比较
@if type-of($value1) == number and type-of($value2) == number and comparable($value1, $value2) {
@return $value1 - $value2;
}
// unquote($string)删除字符串中的引号
// 此处unquote("(")输出结果为:(
@if type-of($value2) != number {
$value2: unquote("(") + $value2 + unquote(")");
}
// if( expression, value1, value2 )
// expression结果为true时,返回value1,否则返回value2
@return if($return-calc == true, calc(#{$value1} - #{$value2}), $value1 + unquote(" - ") + $value2);
}
在Sass中,
calc()
与
CSS calc()
的语法相同,但具有使用 Sass 变量 和调用 Sass 函数 的附加功能。这意味着
/
始终是计算中的除法运算符!
随着企业对高效传输大型文件的需求不断上升,无论是复杂的设计图纸、丰富的视频素材还是详尽的数据分析报告,这些大型文件的迅速、安全传输对于企业的日常运营和项目的成功完成具有极其重要的意义。然而,在处理传输大文件时,企业经常遭遇传输速度缓慢、稳定性不足、安全隐患等挑战,这就使得选择恰当的传输途径成为企业必须慎重考虑的一项任务。

随着现代传输技术的快速发展,企业数据传输方式经历了革命性的变化。这些技术借助云计算、点对点传输协议和高级加密技术等前沿科技,为企业提供了一系列更高效、安全和经济的传输大文件方案。主要的工具包括:
云存储服务平台:
便捷性:
例如Google Drive、Microsoft OneDrive和Amazon S3等云存储服务平台,它们让用户能够把文件存储在云端,实现无时空限制的访问与共享。这些服务通常提供多级别的权限设置,便于团队合作。
效益:
企业能够减少硬件设施的投资,因为它们无需自建和维护数据中心。同时,云服务供应商一般会提供数据备份和恢复服务,增强了数据的安全性和可靠性。
专业的文件传输服务(例如镭速):
便捷性:
镭速
(私有化部署方案,也可接入公有云,企业、社会组织用户可申请免费试用)
等专业文件传输服务是为满足企业传输大文件的需求而设计,它们提供快速的传输速度,支持多线程传输,极大地提升了传输效率。用户界面简洁友好,易于操作。
效益:
这类服务通常配备有严格的安全措施,例如AES-256加密技术,确保了数据传输过程的安全。镭速等工具的断点续传功能也减少了因网络不稳定导致的传输中断,确保了数据的完整性。
点对点(P2P)文件共享平台:
便捷性:
如BitTorrent这样的P2P文件共享平台允许用户在设备之间直接共享文件,无需通过中心服务器。这种方式在传输大型文件时特别有效,因为它能够充分利用网络的上行带宽。
效益:
P2P平台通过分布式网络架构减少了对单一服务器的依赖,提升了传输大文件的稳定性和抗干扰能力。同时,由于数据是在用户之间直接交换,这也大幅降低了带宽的使用成本。
企业级文件同步与共享(EFSS)解决方案:

便捷性:
如Box、Dropbox Business和Mega等EFSS解决方案,它们提供了集中化的文件管理功能,支持版本管理和自动同步,便于跨设备访问。
效益:
这些解决方案帮助企业实现了大文件的集中存储和管理,提升了工作效率。同时,它们通常具备全球分布的数据中心,确保了数据的高可用性和快速访问。
实际应用案例
现代大文件传输工具的发展为企业带来了极大的便利和价值,它们不仅提升了传输大文件的效率和安全性,还降低了企业的运营成本。技术的持续进步将推动这些工具的进一步发展,为企业带来更多强大和灵活的数据传输解决方案。以镭速为例,在多个企业的实际应用中,它展现出了显著的优势。
案例分析:
一家国际公司需要将一系列大型视频文件从总部发送到海外分支机构。通过使用镭速进行传输,原本需要数天的传输时间被缩短到了数小时。而且,在网络状况不稳定的情况下,镭速的断点续传功能确保了传输的连续性和完整性,减少了因传输失败而产生的额外成本。同时,镭速支持多种集成和存储选项,使得部署变得极为便捷。

总结
综合上述分析,企业在挑选传输大文件方案时,应当全面权衡传输速度、稳定性、安全性和成本等多个因素。对于那些需要快速、安全地传输大文件的企业来说,镭速等专业的文件传输平台无疑是一个值得考虑的选择。企业应根据自身的具体需求和预算,挑选最适合的传输方案,以确保数据传输的高效率和安全性。同时,随着技术的持续演进,企业也应持续关注新兴的传输工具,以便及时采用更高效、更经济的解决方案。
工欲善其事,必先利其器。
今天讲的是编程开发工具Visual Studio 2022的安装。作为手把手系列的开始,需要先对进行编程所使用的工具进行了解。此博文从下面几个步骤入手,对VS 2022这个开发工具IDE进行安装等介绍,让读者们能够从入门开始进行学习。
1、
Visual Studio 2022的下载;
VS 2022的下载有两种方式。打开下面的链接进行下载:
https://www.cnblogs.com/lzhdim/p/15611966.html
1) 在线安装工具;
打开目录里的VisualStudioSetup.exe文件,这个将使用网络下载安装的方式进行安装,一般是通过边下载边安装的方式比较好,提高了速度。这个是直接安装的最新版。
2) 离线包安装;
双击目录里的ISO文件加载到操作系统的光驱形式,然后点击Setup.exe文件进行安装,这个是离线包,直接进行安装,然后再点击更新进行更新到最新版本。
2、
Visual Studio 2022的安装;
运行Setup.exe安装文件,点击继续,到达安装选项界面;
1) 安装ASP.NET;
见截图,右边把Web性能和负载测试工具选上。

2) 安装.Net桌面开发;
见截图,选中右侧的4.8.1那个项。

3) 安装C++开发;
见截图,勾选右侧的“生成加速”和“C++模板”项。

4) 安装位置:
把“安装后保留下载缓存”去掉。

5) 如果有更新;
点击“更新”以更新版本。


3、
Visual Studio 2022的激活;
打开目录里的SN文本文件,然后打开VS 2022,点击帮助菜单里的注册Visual Studio,点击
使用产品密钥解锁
,输入密钥进行激活。
4、
Visual Studio 2022的更新;
点击帮助菜单里的检查更新,打开更新窗体,如果检测到新的版本,点击右下角的更新按钮进行更新到最新版本。建议隔段时间检查一下更新以更新到最新版本,新的功能和版本能够让IDE更加的完善以及更加的强大。

5、
Visual Studio 2022的登录;
点击VS 2022的右上角的登录,输入微软账密进行登录即可。
上面介绍了Visual Studio 2022安装等相关操作,后面的系列文章将对使用其进行编码工作,敬请期待。
本文分享自华为云社区《
CCE XGPU虚拟化的使用
》,作者: 可以交个朋友。
在互联网场景中,用户的AI训练和推理任务对GPU虚拟化有着强烈的诉求。GPU卡作为重要的计算资源不管是在算法训练还是预测上都不可或缺,而对于常见的算法训练业务或智能业务都有往容器迁移演进的趋势,所以如何更好的利用GPU资源成了容器云平台需要解决的问题。云厂商如果提供GPU虚拟化可以为用户带来的如下收益:
CCE GPU虚拟化采用自研xGPU虚拟化技术,能够动态对GPU设备显存与算力进行划分,单个GPU卡最多虚拟化成20个GPU虚拟设备。相对于静态分配来说,虚拟化的方案更加灵活,最大程度保证业务稳定的前提下,可以完全由用户自己定义使用的GPU量,
建议用户在使用GPU资源时,提前创建好对应规格型号的GPU节点资源池,方便后期管理和调度。
GPU的使用需要借助CCE插件能力实现,前往CCE 插件市场进行插件的安装。
安装Volcano调度器插件
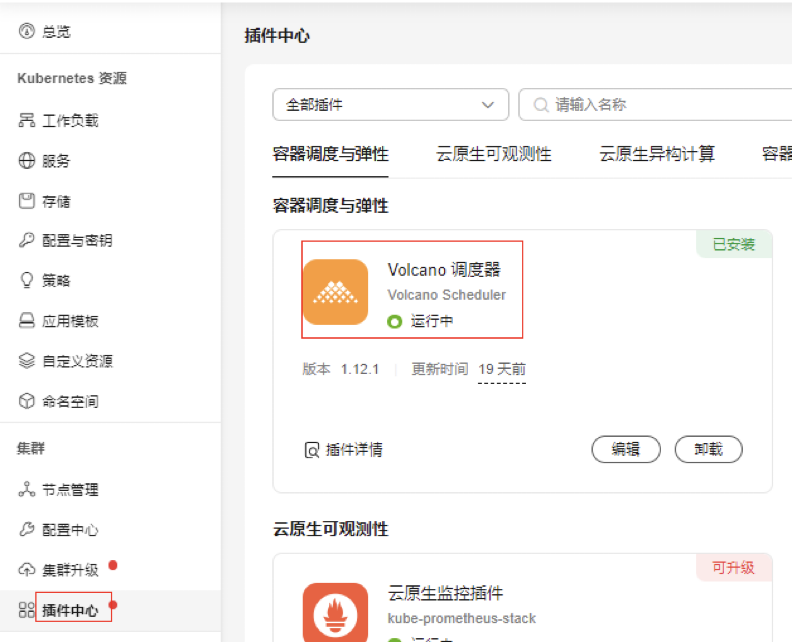
插件安装完成后,可前往配置中心-调度设置,设置默认调度器为Volcano,如果不设置需要在负载yaml中指定调度器
spec.schedulerName: volcano
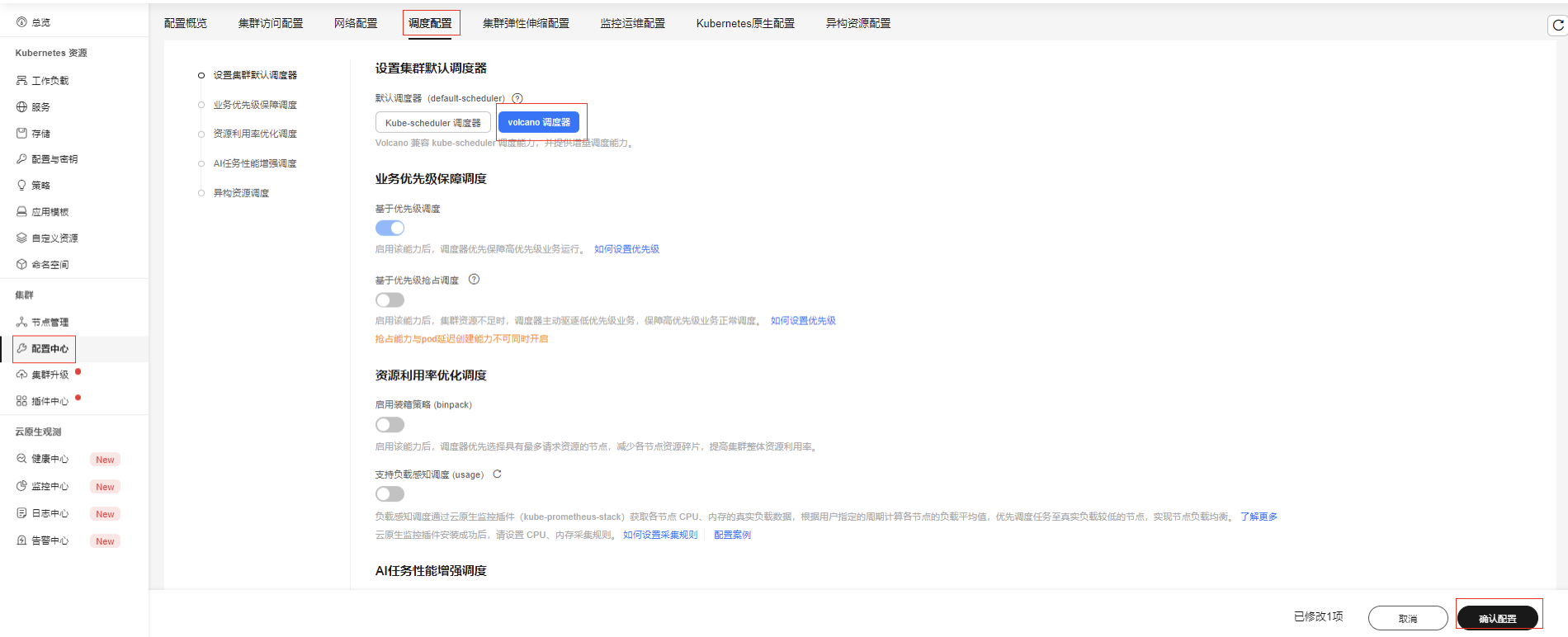
安装GPU插件(CCE AI 套件)
插件中心安装GPU插件,CCE平台已经提供多个版本的驱动,在列出的驱动列表中选择使用即可,支持不同节点池选择不同驱动版本。也支持自行配置其它版本的驱动,需要自行提供驱动下载链接。
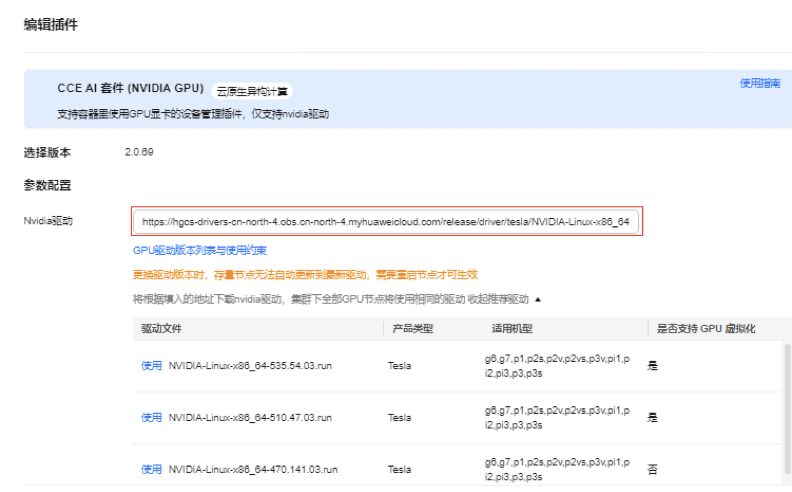
根据xGPU支持虚拟化维度进行操作实践
注意: 未开启volcano作为全局调度器时,需要在yaml指定调度器为volcano
创建负载app01.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: app01
spec:
replicas:1selector:
matchLabels:
app: app01
template:
metadata:
labels:
app: app01
spec:
containers:- name: bert-container
image: swr.cn-north-4.myhuaweicloud.com/container-solution/bert-intent-detection:v1
ports:- containerPort: 80resources:
limits:
volcano.sh/gpu-mem.128Mi: '16'requests:
volcano.sh/gpu-mem.128Mi: '16'schedulerName: volcano
volcano.sh/gpu-mem.128Mi: '16'
: 显存申请量等于 128Mi x 16=2048Mi=2Gi;也当前负载最多只能使用2Gi的显存资源。
查看Pod信息,pod yaml自动生成两条注解,同样也标注了负载使用了2Gi显存
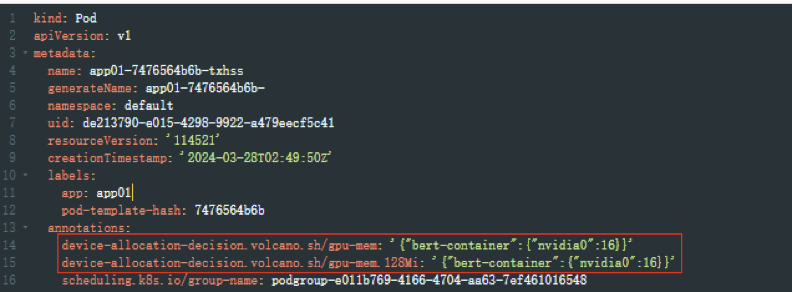
容器内使用nvidia-smi查看显存,表现最大显存为2Gi,显存隔离生效

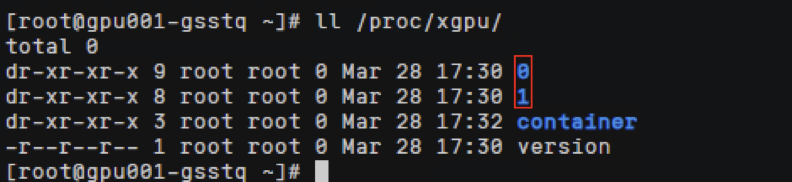
xGPU显存隔离能力通过在HCE2.0上实现,在节点上查看/proc/xgpu目录,0表示使用的物理gpu显卡的序列号(如果是多个卡则有多个目录,文件名从0开始,各个文件对应相关下标的GPU卡),container目录下存放使用gpu虚拟化的 容器信息。
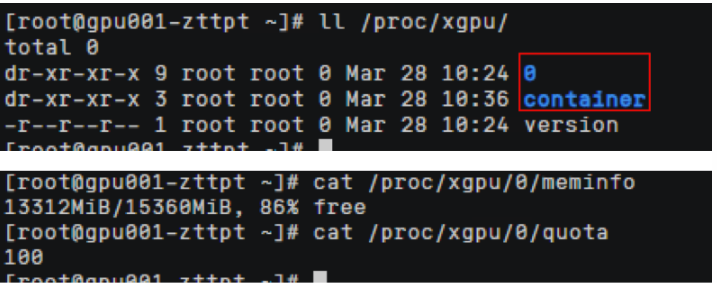
查看容器ID对应命令,查看meminfo和quota文件,可以看到HCE2.0控制给容器GPU卡显存和算力的上限配置。

meminfo
:容器分配显存为2Gi,
quota
:容器分配的算力,0代表不限制算力可以使用到整卡的算力
路径中
xgpu3
: 代表虚拟gpu卡的卡号 每创建一个新的容器都会按次序生成一个新的虚拟gpu卡号
购买多gpu卡机型
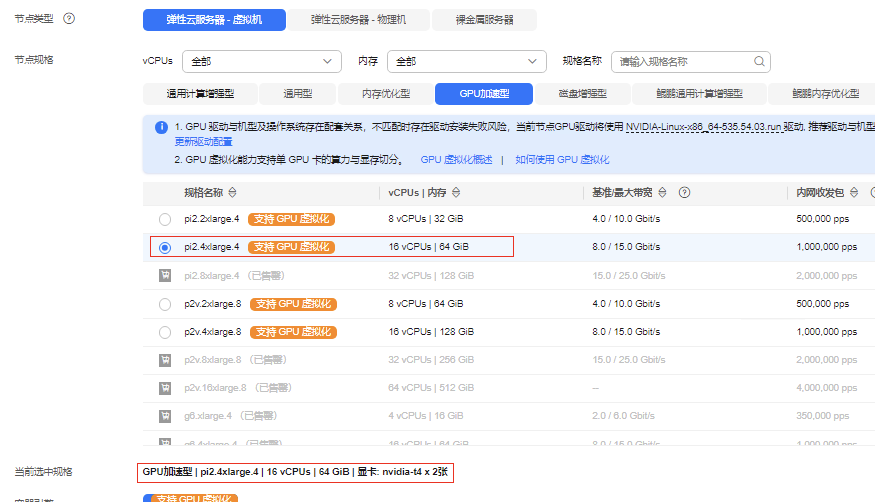
虚拟化模式下不支持单pod申请超过一张卡的gpu资源,如单pod需要使用多卡资源请关闭gpu虚拟化;同时多卡调度,也不支持1.x,2.x 形式,需要为大于1的整数
节点上能看到两张gpu物理卡编号
看到容器资源显存隔离生效,xGPU1是从0号gpu卡上软件连接过来的

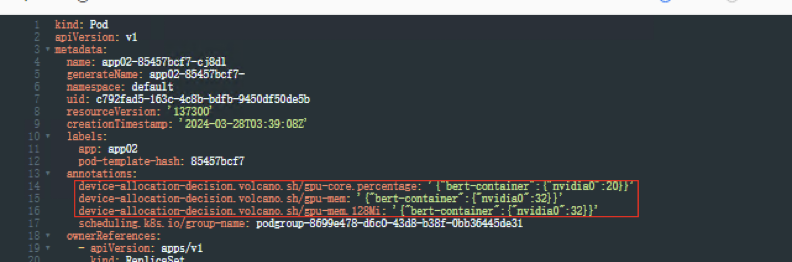
创建负载app02,yaml如下
apiVersion: apps/v1
kind: Deployment
metadata:
name: app02
spec:
replicas:1selector:
matchLabels:
app: app02
template:
metadata:
labels:
app: app02
spec:
containers:- name: bert-container
image: swr.cn-north-4.myhuaweicloud.com/container-solution/bert-intent-detection:v1
ports:- containerPort: 80resources:
limits:
volcano.sh/gpu-mem.128Mi: '32'volcano.sh/gpu-core.percentage: '20'requests:
volcano.sh/gpu-mem.128Mi: '32'volcano.sh/gpu-core.percentage: '20'schedulerName: volcano
volcano.sh/gpu-mem.128Mi: '32'
: 显存申请量等于 128Mi x 32=4096Mi=4Gi
volcano.sh/gpu-core.percentage: '20'
: 算力申请量等于整卡算力的20%
表示当前负载最多只能使用4Gi的显存,算力上限为20%。
查看Pod信息,yaml文件自动生成3条注解,标注了负载使用了4Gi显存,算力可使用整卡算力的20%
容器内执行
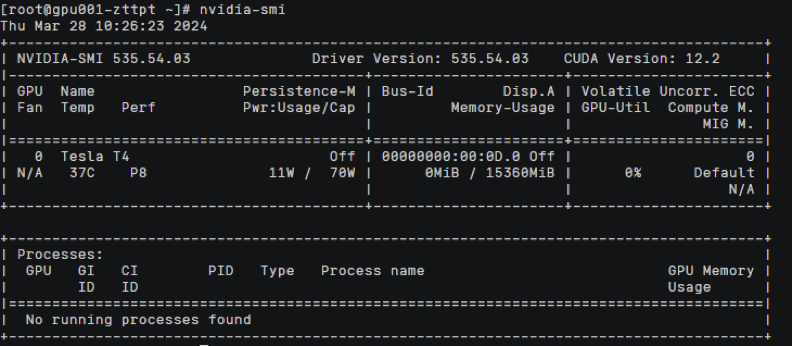
nvidia-smi
命令查看显卡驱动信息也可发现显存为4Gi
前往宿主机查看GPU资源使用状况
节点上
/proc/xgpu/container
目录下查看相关容器的xGPU的配额,发现可用显存为4Gi,可用算力为20%

如果您在集群中已使用
nvidia.com/gpu
资源的工作负载,可在gpu-device-plugin插件配置中选择“虚拟化节点兼容GPU共享模式”选项,即可兼容Kubernetes默认GPU调度能力。
开启该兼容能力后,使用
nvidia.com/gpu
配额时等价于开启虚拟化GPU显存隔离,可以和显存隔离模式的工作负载共用一张GPU卡,但不支持和算显隔离模式负载共用一张GPU卡。
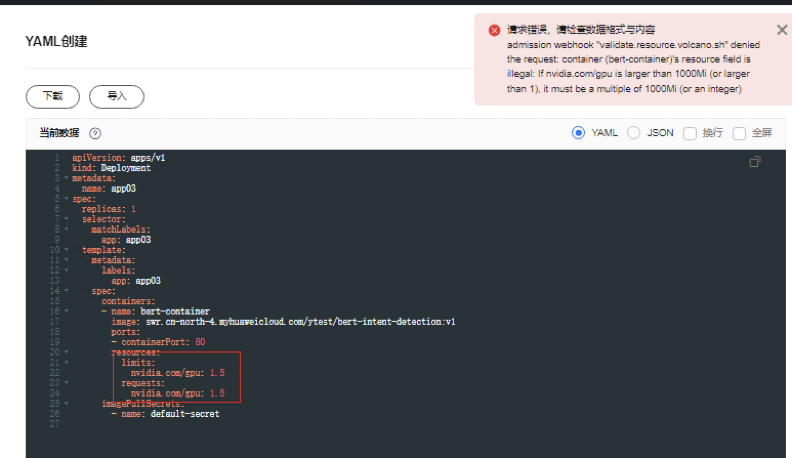
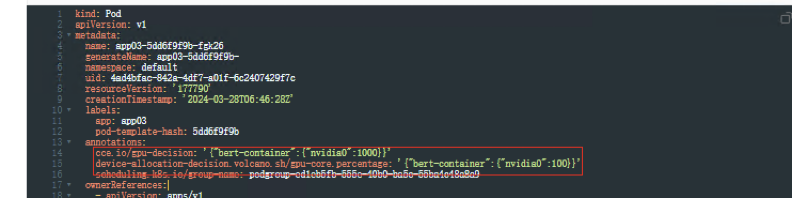
创建工作负载app03,yaml如下,使用整卡调度
apiVersion: apps/v1
kind: Deployment
metadata:
name: app03
spec:
replicas:1selector:
matchLabels:
app: app03
template:
metadata:
labels:
app: app03
spec:
containers:- name: bert-container
image: swr.cn-north-4.myhuaweicloud.com/container-solution/bert-intent-detection:v1
ports:- containerPort: 80resources:
limits:
nvidia.com/gpu: 1requests:
nvidia.com/gpu: 1schedulerName: volcano
查看Pod信息,yaml文件中自动生成2条注解,算力可使用整卡百分之100的算力
容器内执行
nvidia-smi
命令查看显卡驱动信息
可以发现当我们申请1张GPU整卡时,容器里的显存上限为整卡的显存配额
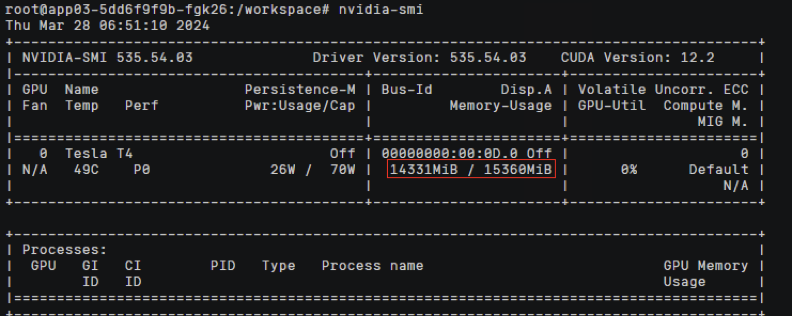
节点上查看
/proc/xgpu/container/
目录下为空,容器使用到整卡的显存和算力资源
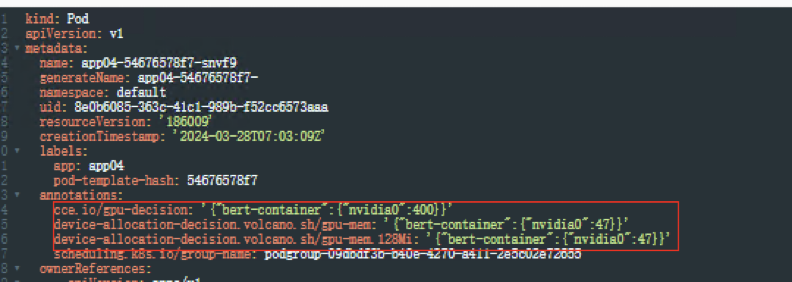
创建工作负载app04, yaml如下,使用分卡共享调度
apiVersion: apps/v1
kind: Deployment
metadata:
name: app04
spec:
replicas:1selector:
matchLabels:
app: app04
template:
metadata:
labels:
app: app04
spec:
containers:- name: bert-container
image: swr.cn-north-4.myhuaweicloud.com/container-solution/bert-intent-detection:v1
ports:- containerPort: 80resources:
limits:
nvidia.com/gpu: 0.4requests:
nvidia.com/gpu: 0.4schedulerName: volcano
注意:兼容Kubernetes默认GPU调度模式时,如使用nvidia.com/gpu: 0.1参数,最终计算后 ,指定的显存值如非128MiB的整数倍时会向下取整,例如:GPU节点上的显存总量为24258MiB,而24258MiB * 0.1 = 2425.8MiB,此时会向下取整至128MiB的18倍,即18 * 128MiB=2304MiB
查看Pod信息,yaml文件自动转换成显存隔离,算力不隔离
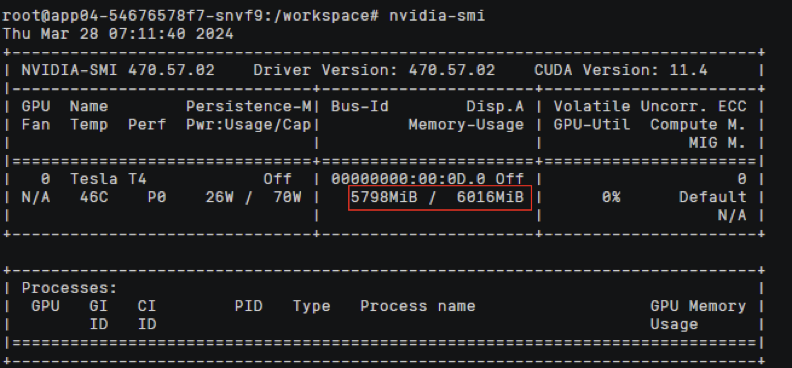
容器内执行
nvidia-smi
命令查看容器中使用的显卡信息
可以发现容器中显存配额为整卡百分之40显存资源
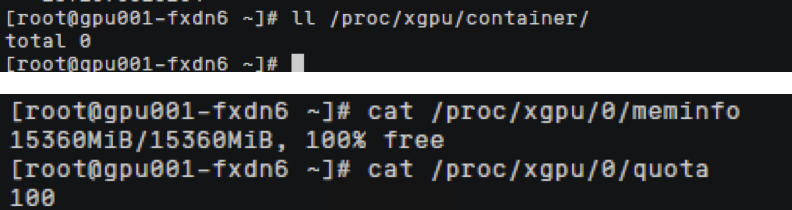
前往节点
/proc/xgpu/container
目录查看分配的xGPU的信息
可以发现对应的容器限制效果为:显存隔离生效算力不进行隔离

创建工作负载app05,yaml如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: app05
spec:
replicas:1selector:
matchLabels:
app: app05
template:
metadata:
labels:
app: app05
spec:
containers:- name: bert-container
image: swr.cn-north-4.myhuaweicloud.com/container-solution/bert-intent-detection:v1
ports:- containerPort: 80resources:
limits:
volcano.sh/gpu-mem.128Mi: '16'requests:
volcano.sh/gpu-mem.128Mi: '16' - name: bert-container2
image: swr.cn-north-4.myhuaweicloud.com/container-solution/bert-intent-detection:v1
command:- /bin/bash
args:- '-c' - while true; do echo hello; sleep 10;done
ports:- containerPort: 81resources:
limits:
volcano.sh/gpu-mem.128Mi: '16'requests:
volcano.sh/gpu-mem.128Mi: '16'schedulerName: volcano
查看Pod信息,yaml文件注解中会有两个容器的资源使用2Gi+2Gi、
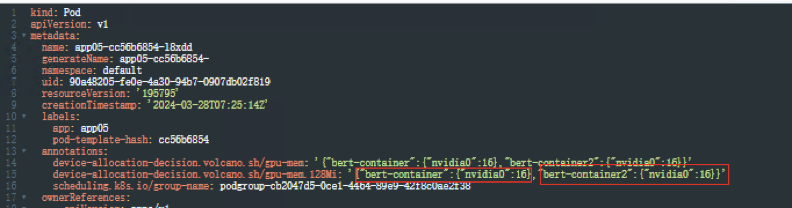
容器中执行
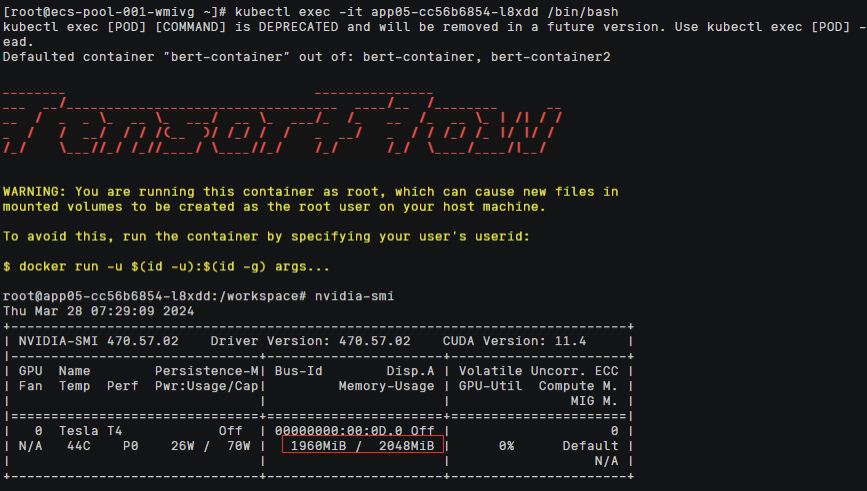
nvidia-smi
命令,查看容器中显存分配信息
两个容器中各自都看到有2Gi显存的资源

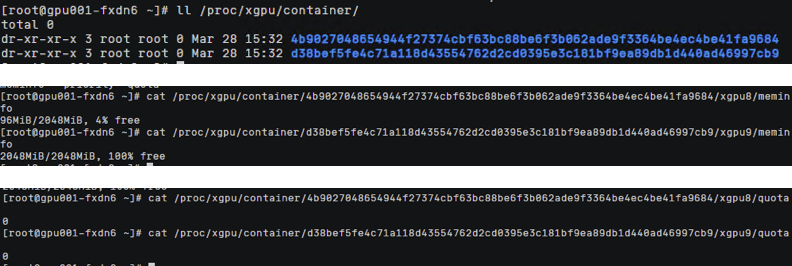
节点查看
/proc/xgpu/congtainer
目录下生成两个容器文件,显存隔离都为2Gi,算力都没有做限制
查看监控指标需要安装kube-prometheus-stack插件的server模式
xGPU核心监控指标
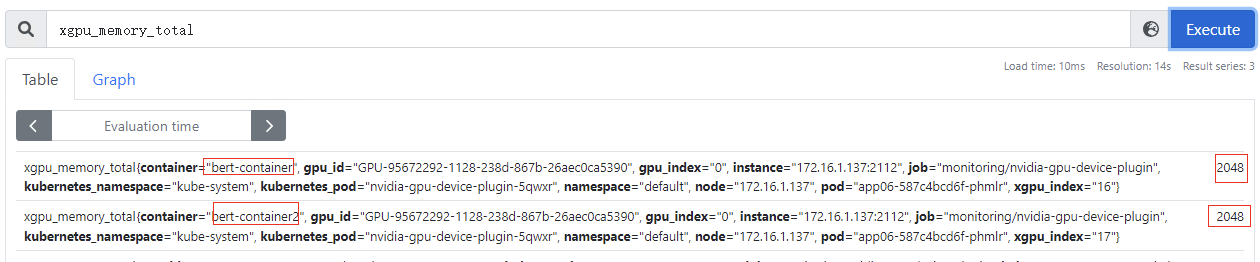
xgpu_memory_total
:容器GPU虚拟化显存总量,该指标为container级别
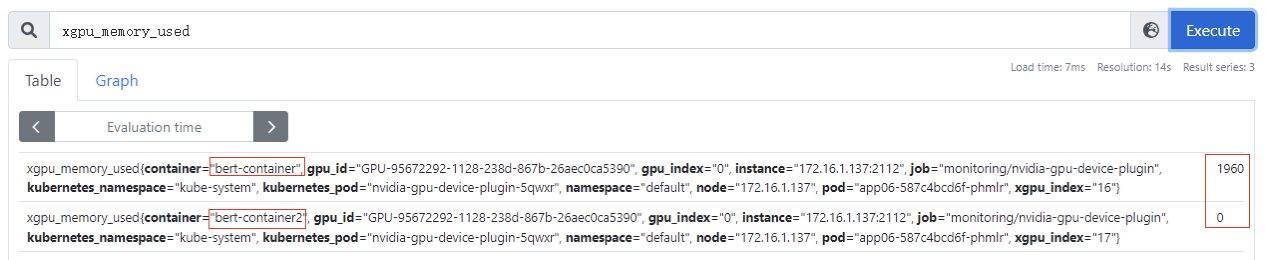
xgpu_memory_used
:容器使用GPU虚拟化显存使用量,该指标为container级别
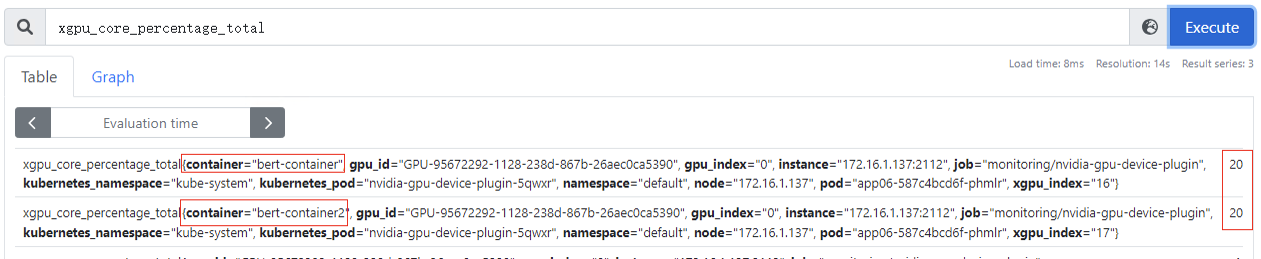
xgpu_core_percentage_total
:容器GPU虚拟化算力总量,该指标为container级别,20代表可以使用整卡算力的20%,该指标为container级别
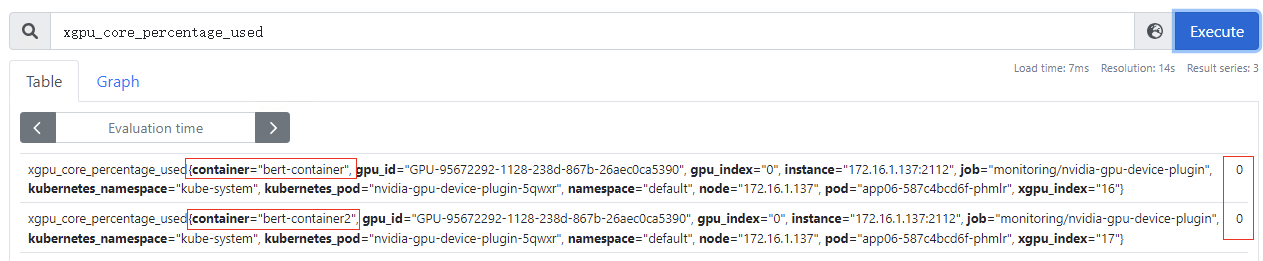
xgpu_core_percentage_used
:容器GPU虚拟化算力使用量,该指标为container级别,目前使用量为0
gpu_schedule_policy
:GPU虚拟化分三种模式(0:显存隔离算力共享模式、1:显存算力隔离模式、2:默认模式,表示当前卡还没被用于GPU虚拟化设备分配),该指标为节点级别
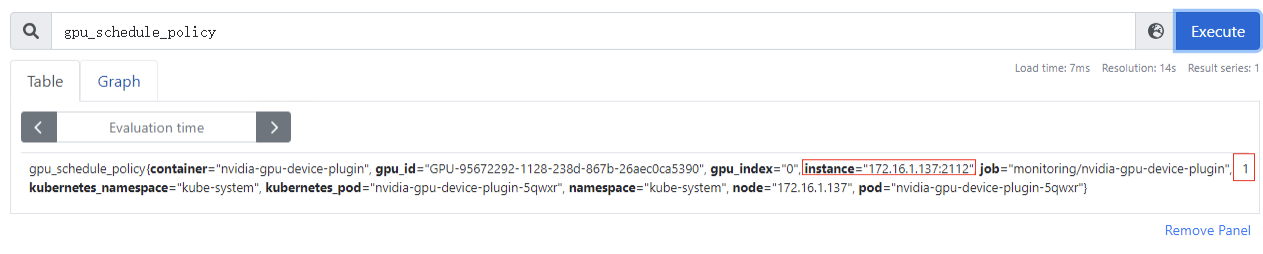
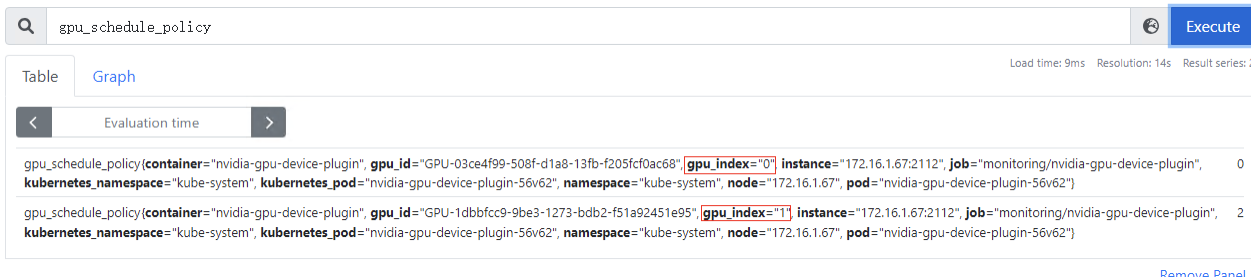
多卡场景,gpu_index字段为gpu物理卡的编号
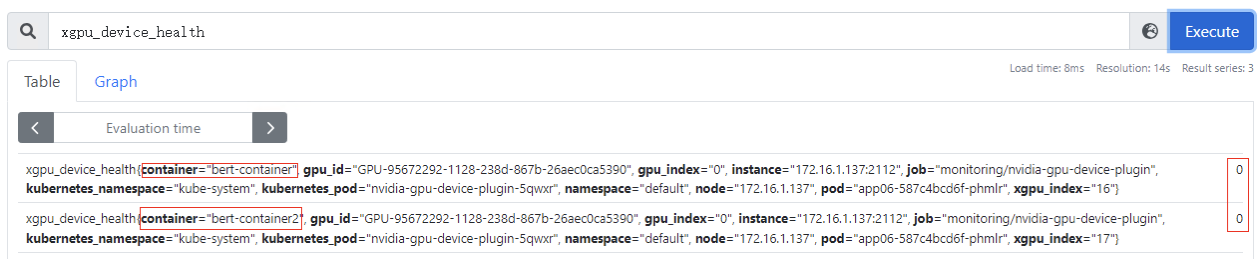
xgpu_device_health
:GPU虚拟化设备的健康情况,0:表示GPU虚拟化设备为健康状态;1:表示GPU虚拟化设备为非健康状态。该指标为container级别
其他监控指标请参考:
https://support.huaweicloud.com/usermanual-cce/cce_10_0741.html
Nvidia driver驱动程序定期会发布新版本,如果负载需要使用新版本驱动,可以通过CCE AI套件的能力进行驱动版本的更新
1.编辑gpu插件 点击使用获取535.54.03版本的驱动下载链接
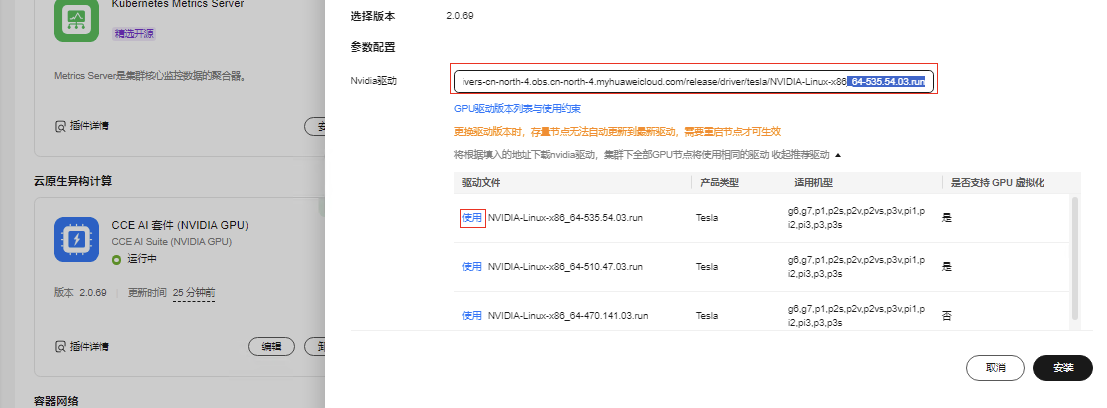
https://hgcs-drivers-cn-north-4.obs.cn-north-4.myhuaweicloud.com/release/driver/tesla/NVIDIA-Linux-x86_64-535.54.03.run
2.更改gpu001节点池的下载驱动链接为535.54.03版本
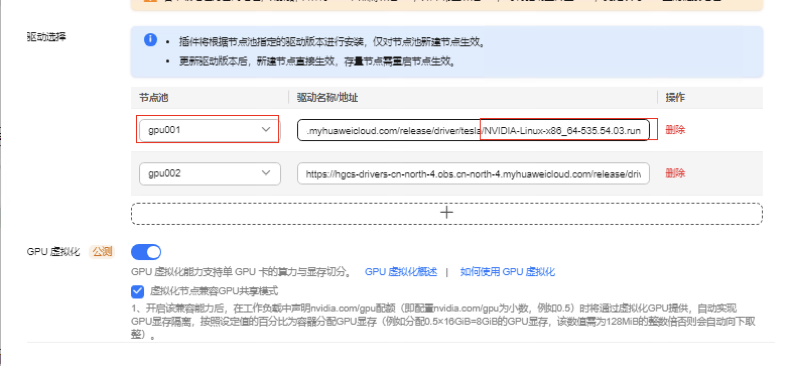
3.插件升级完成后必须手动重启gpu节点才能生效
注意:重启节点会造成该节点上业务中断,需要提前将该节点设置禁止调度,然后扩容该节点上关键业务,再进行驱逐处理,最后重启节点,恢复调度。
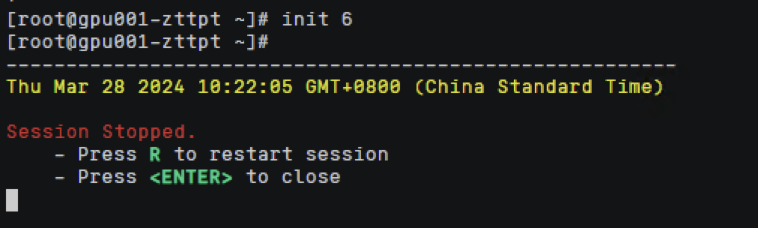
节点重启中

节点驱动升级完成

验证:gpu驱动升级成功到535.54.03版本