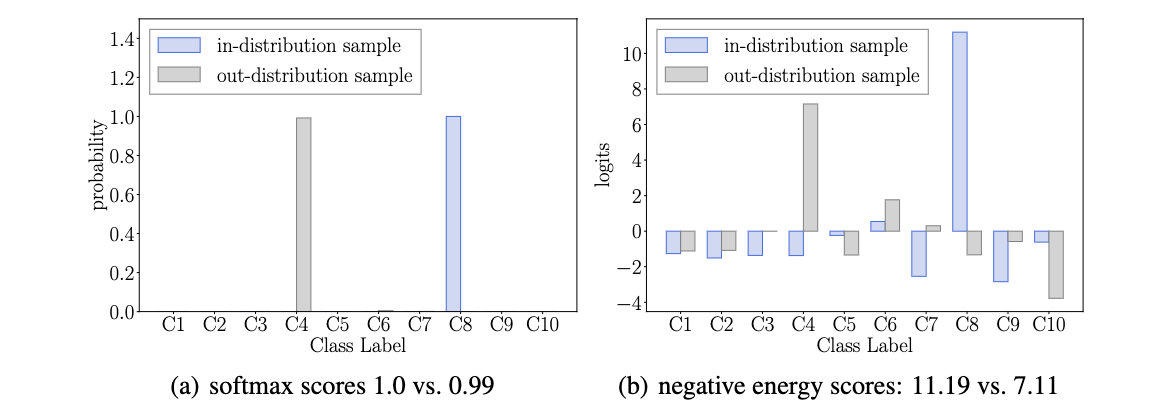
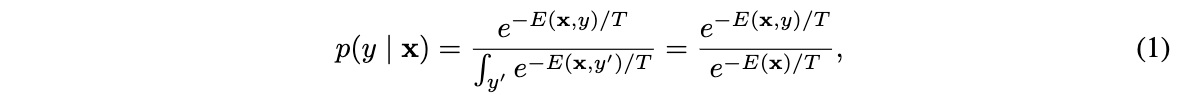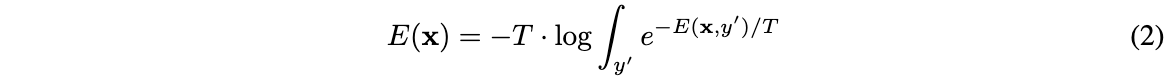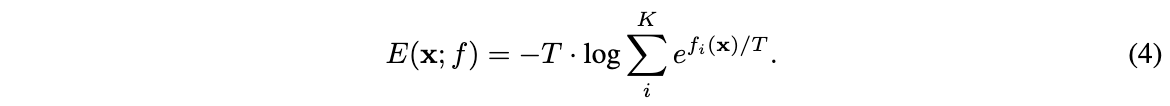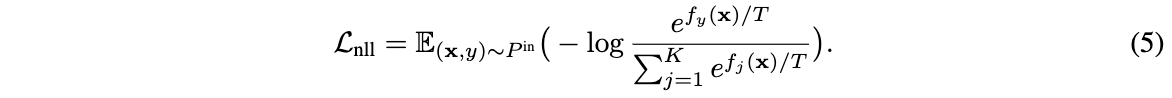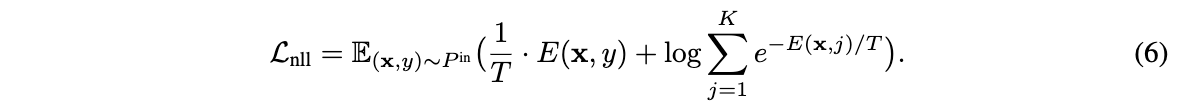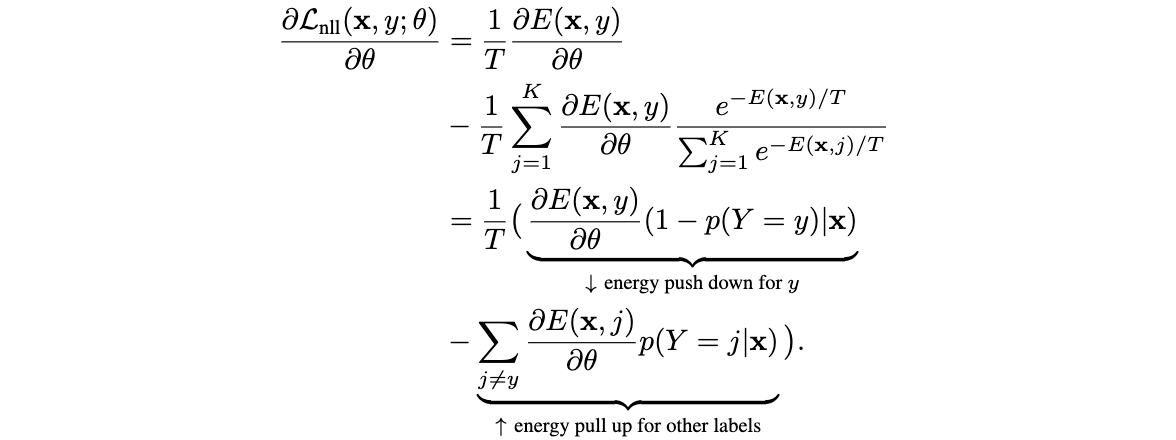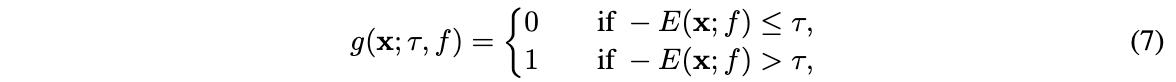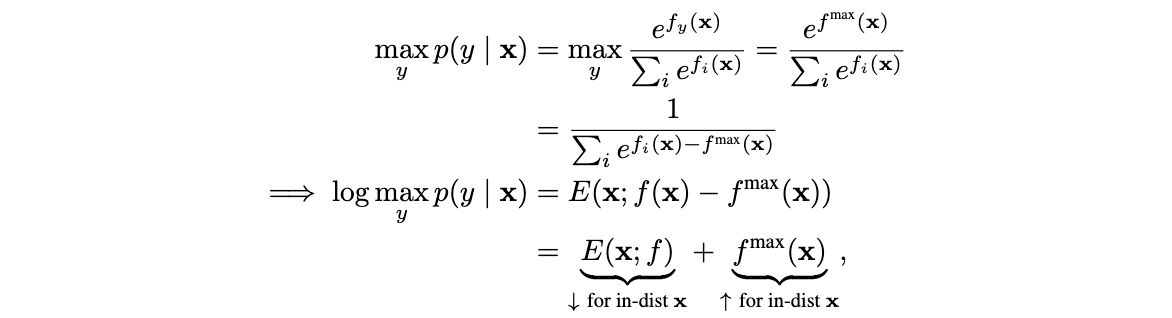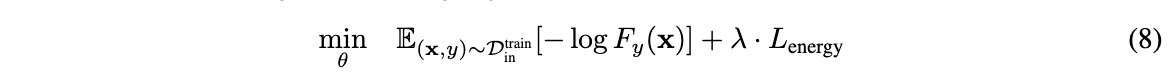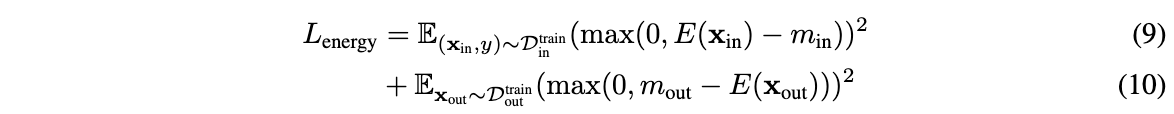WPF中动画教程(DoubleAnimation的基本使用)
实现效果
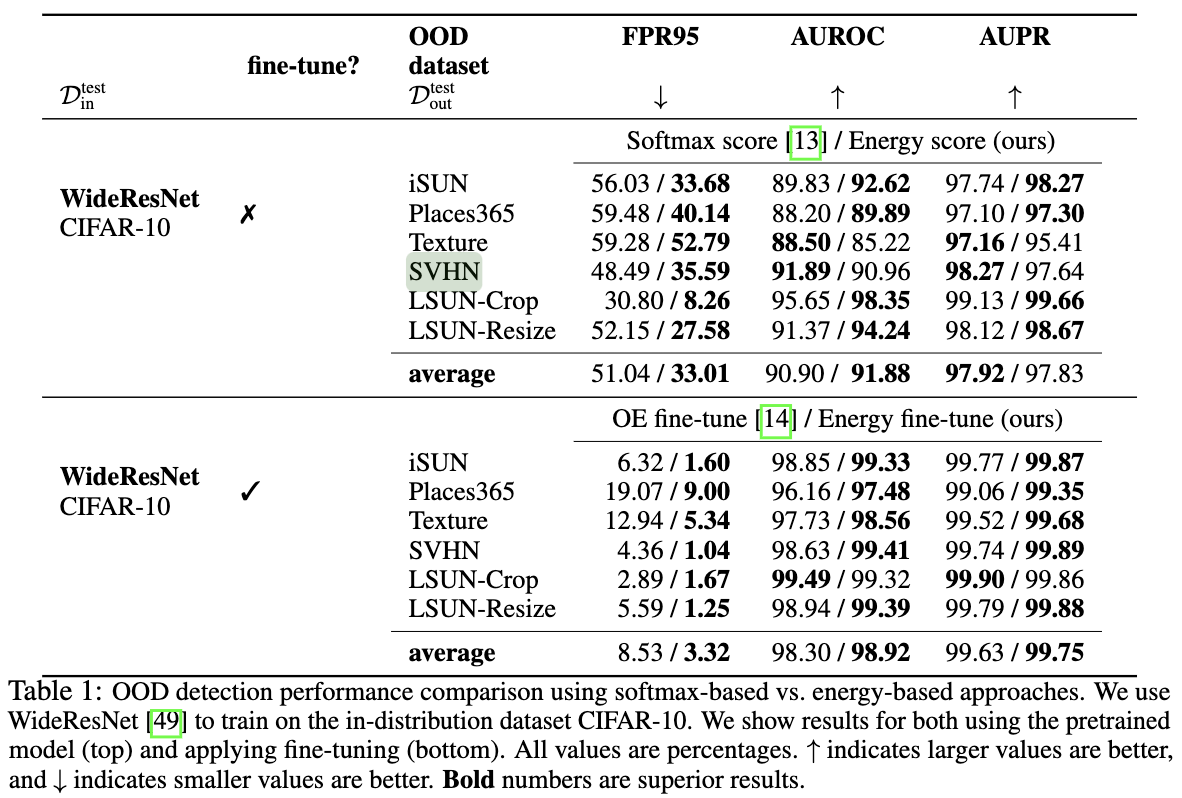
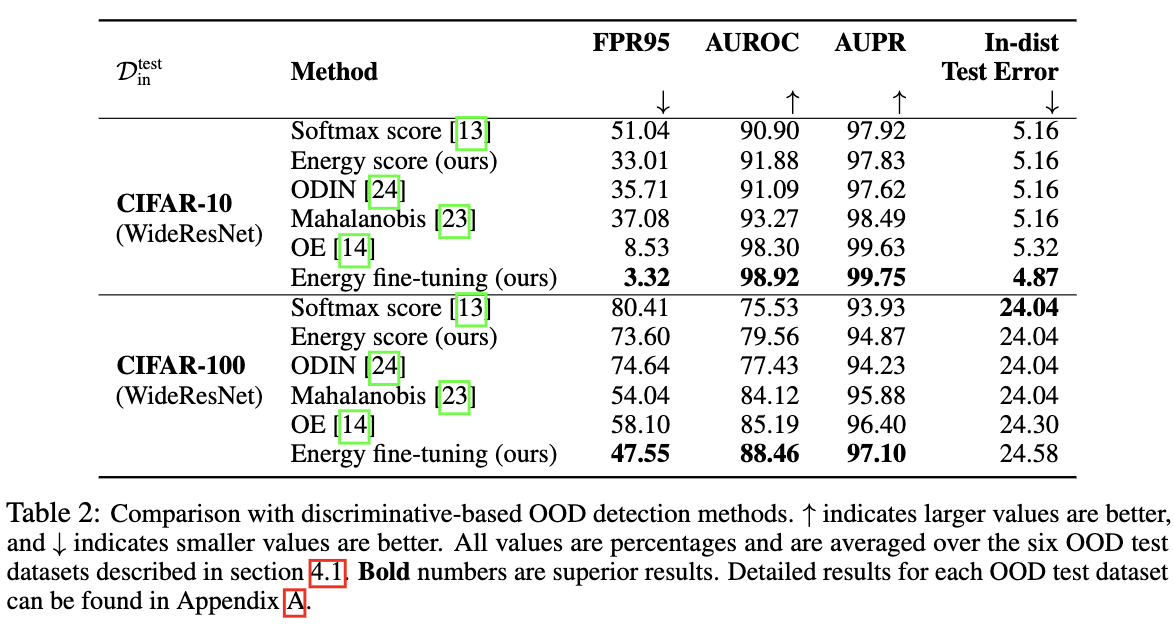
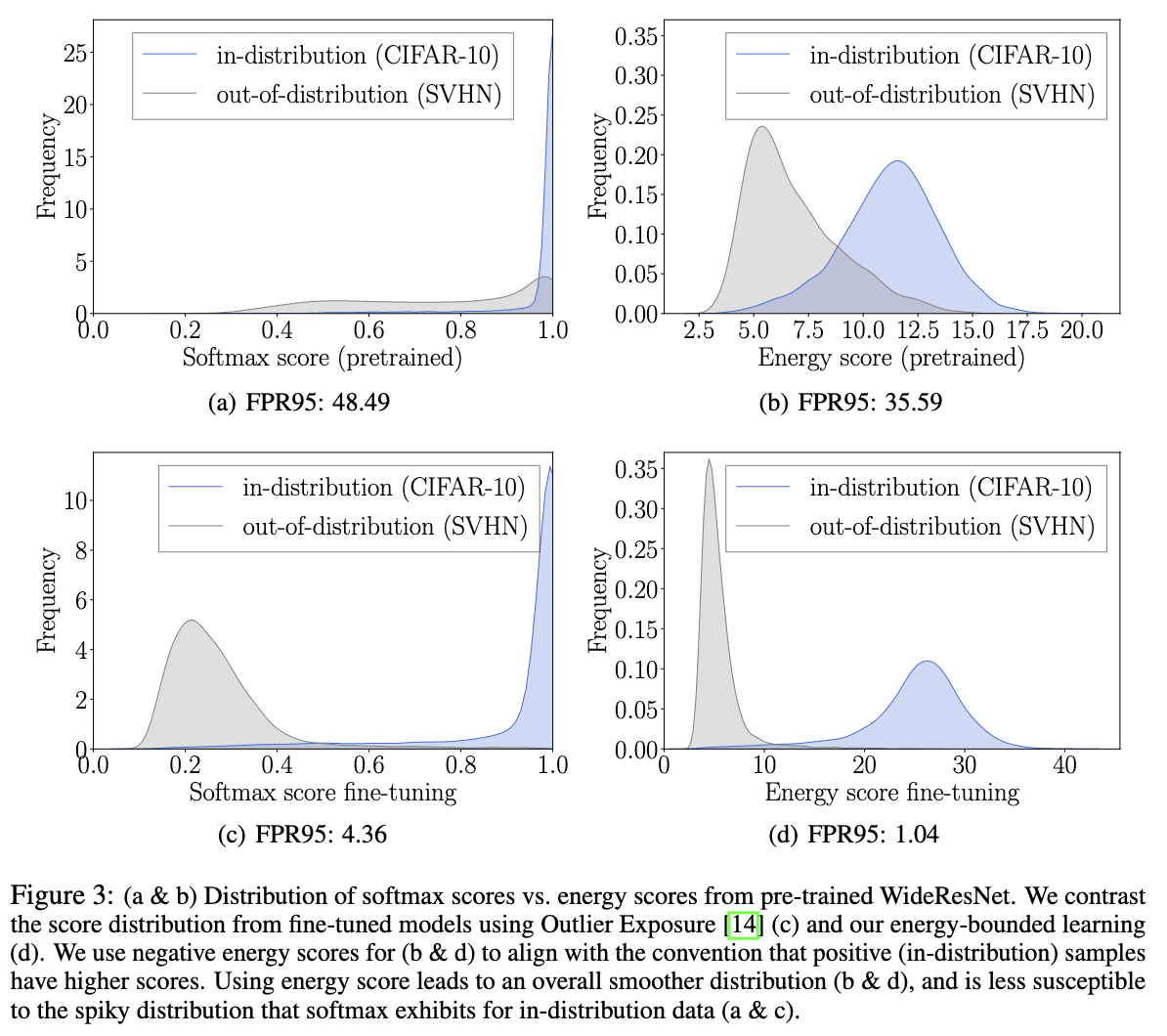
今天以一个交互式小球的例子跟大家分享一下wpf动画中
DoubleAnimation
的基本使用。该小球会移动到我们鼠标左键或右键点击的地方。
该示例的实现效果如下所示:
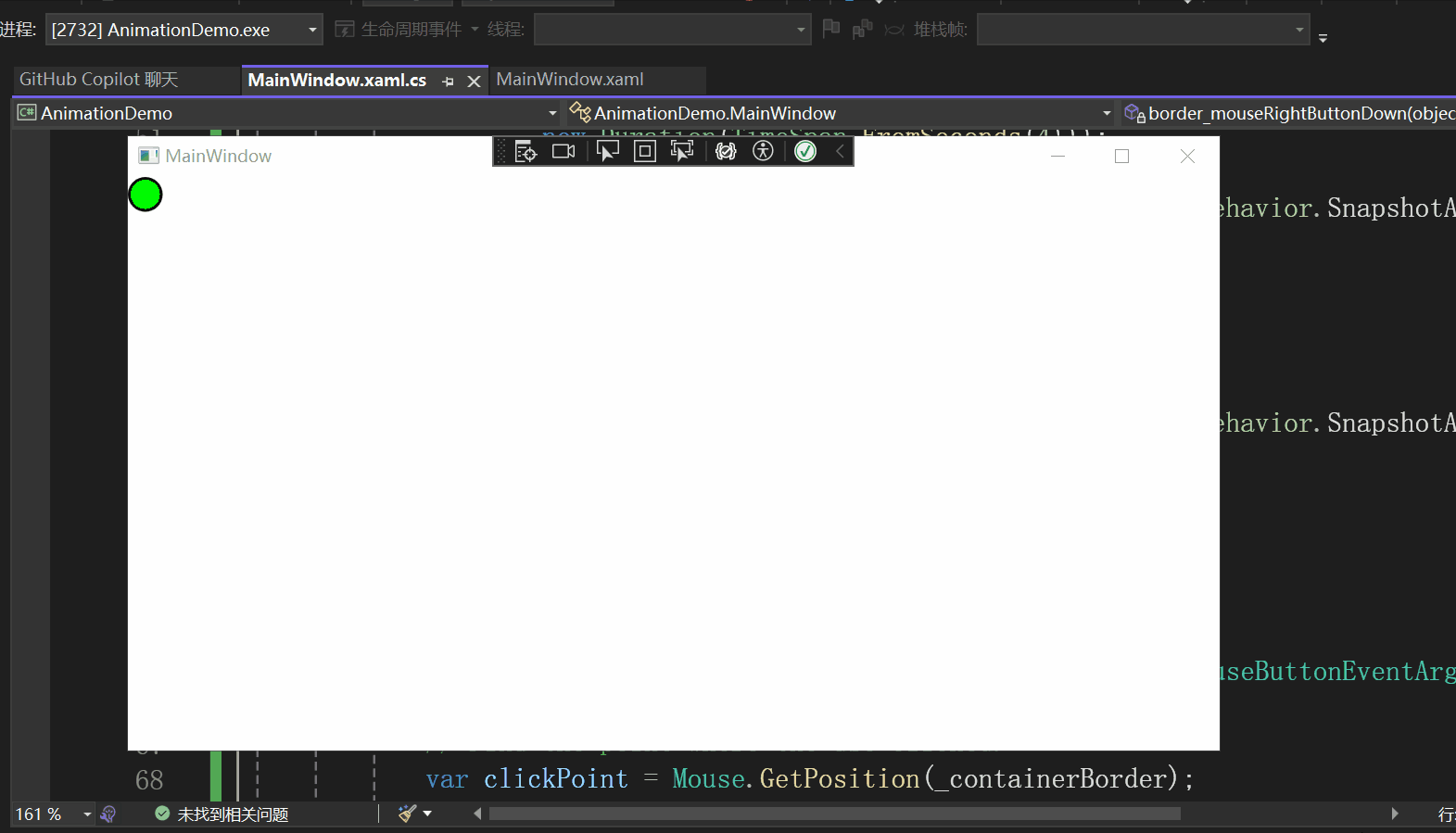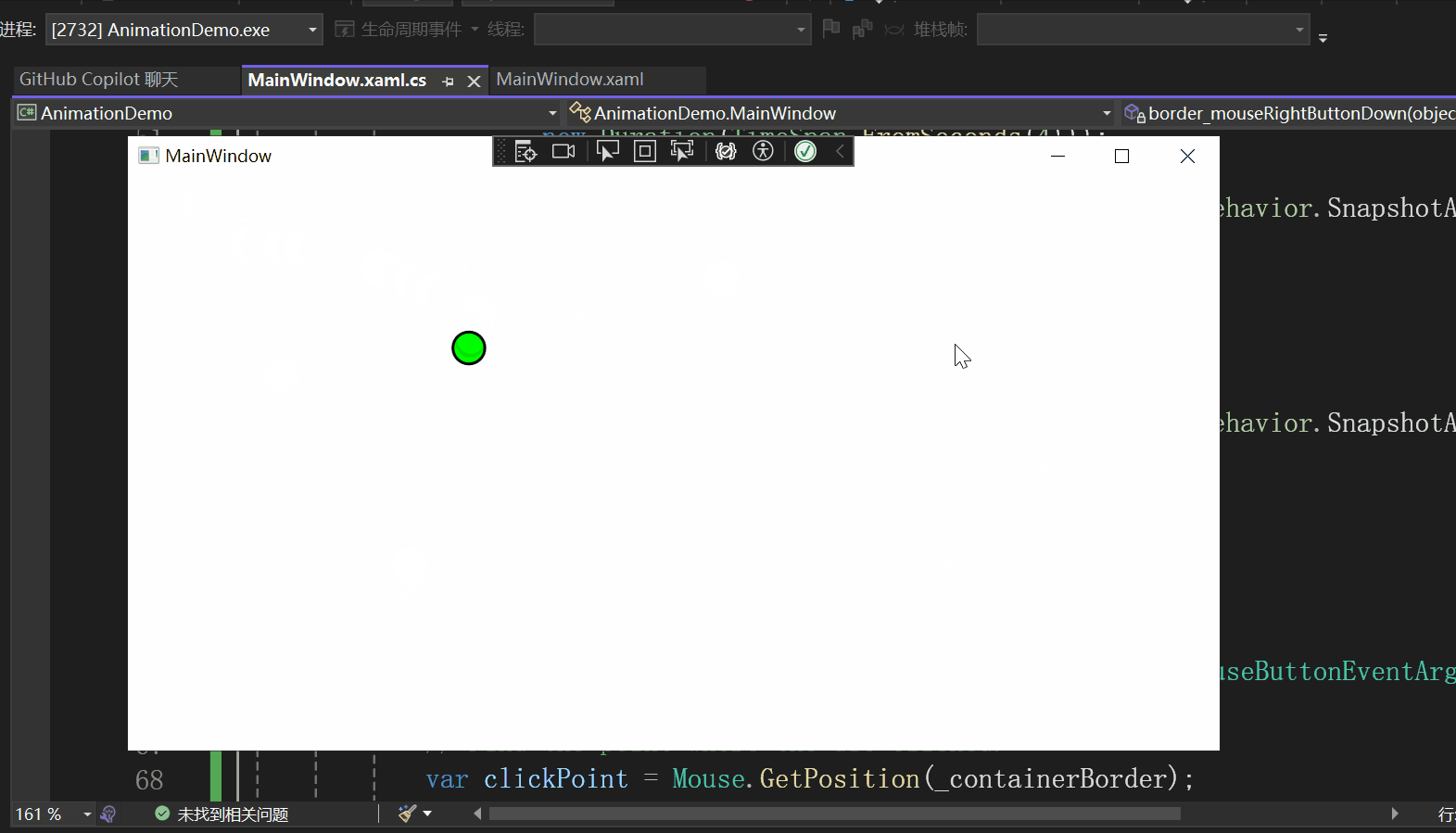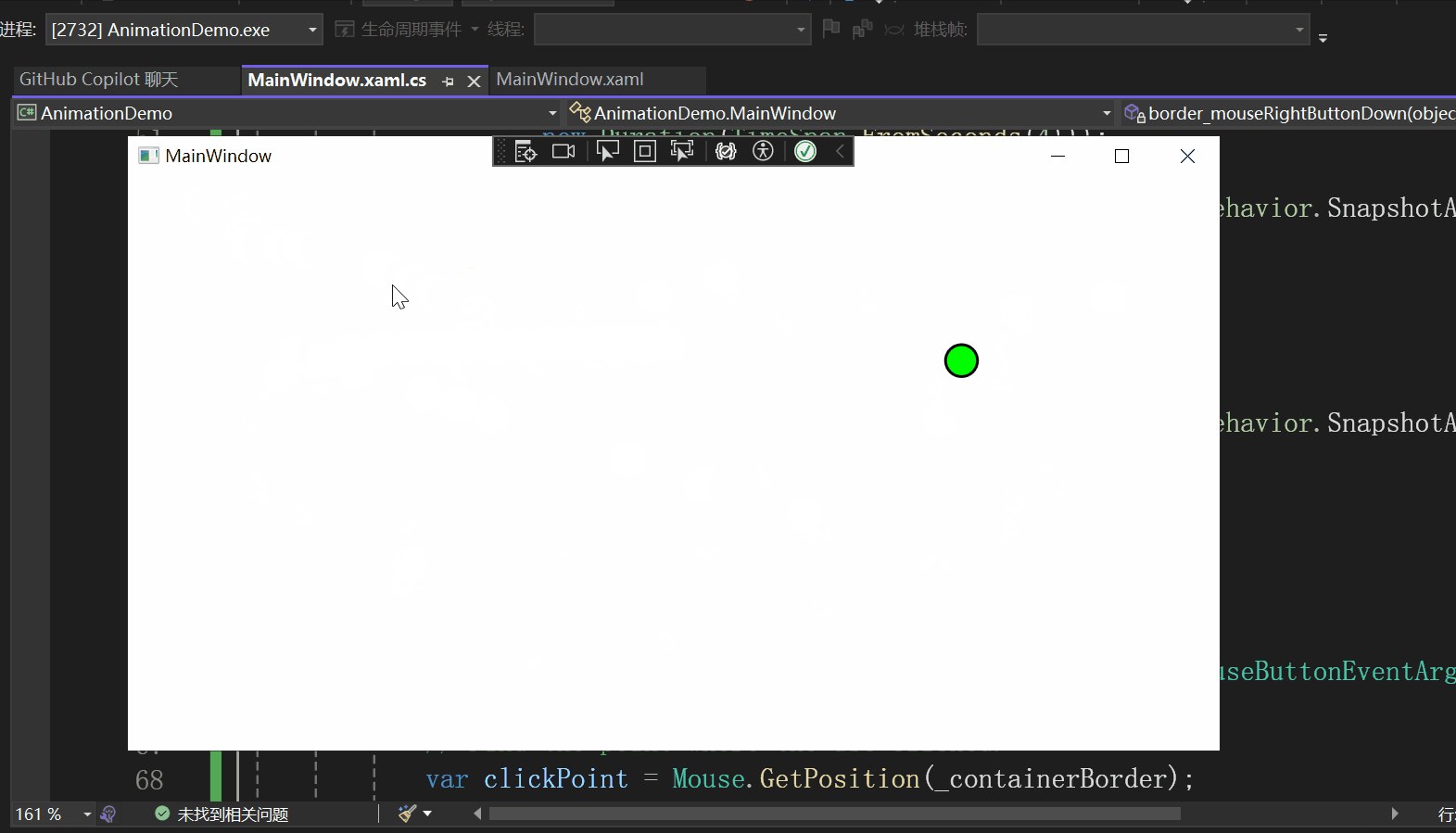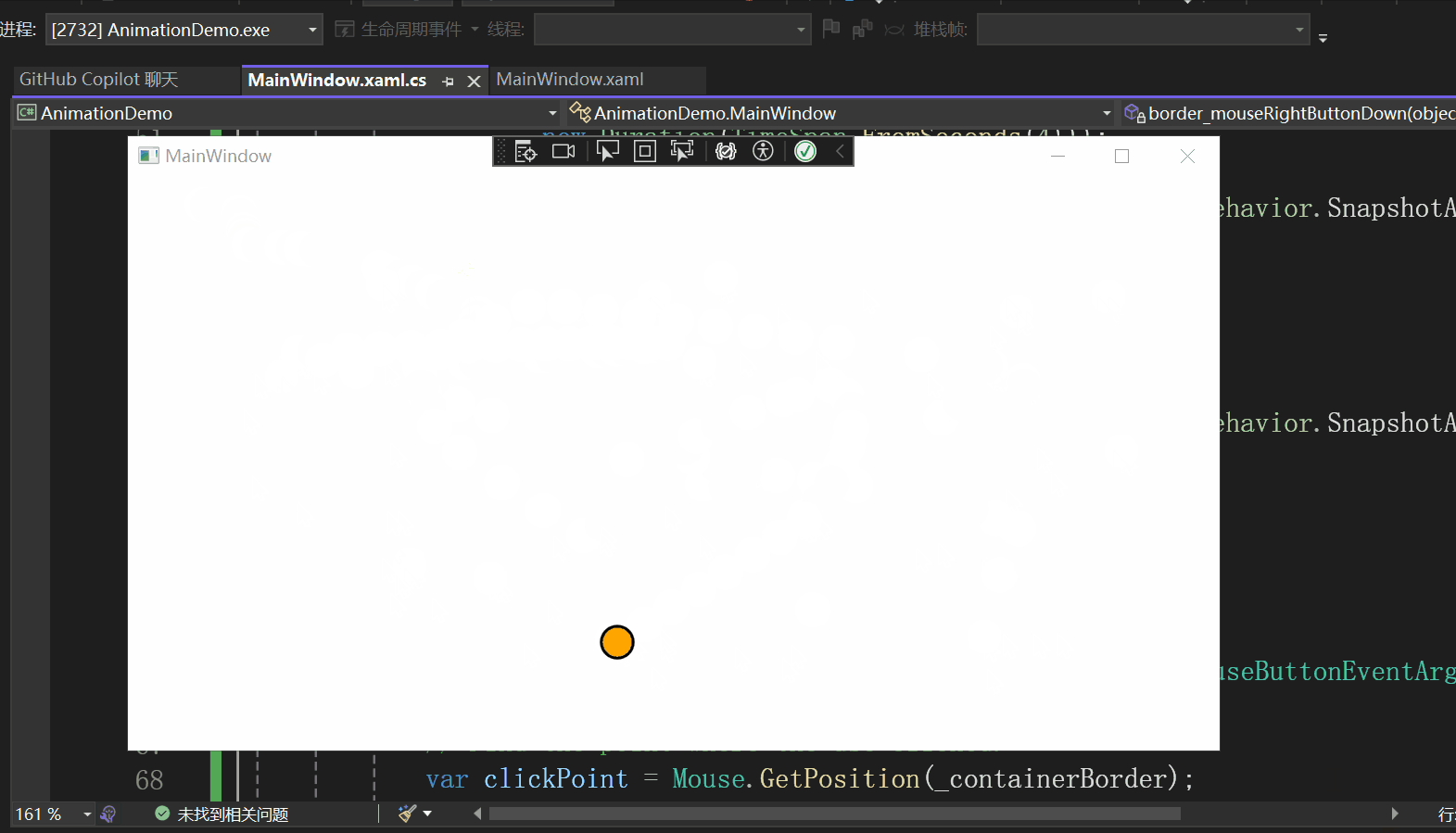
页面设计
xaml如下所示:
<Window x:Class="AnimationDemo.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:local="clr-namespace:AnimationDemo"
mc:Ignorable="d"
Title="MainWindow" Height="450" Width="800">
<DockPanel>
<Border x:Name="_containerBorder" Background="Transparent">
<Ellipse x:Name="_interactiveEllipse"
Fill="Lime"
Stroke="Black"
StrokeThickness="2.0"
Width="25"
Height="25"
HorizontalAlignment="Left"
VerticalAlignment="Top" />
</Border>
</DockPanel>
</Window>
就是在
DockPanel
中包含一个
Border
,在
Border
中包含一个圆形。
页面设计的效果如下所示:
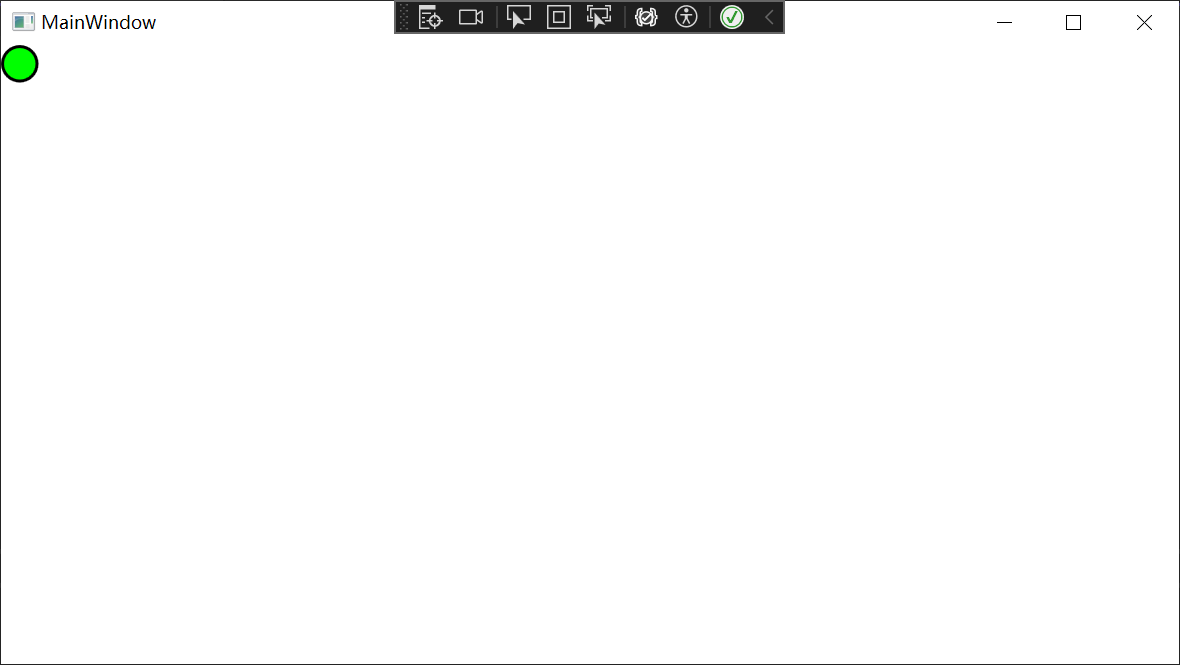
一些设置
相关设置的cs代码如下所示:
public partial class MainWindow : Window
{
private readonly TranslateTransform _interactiveTranslateTransform;
public MainWindow()
{
InitializeComponent();
_interactiveTranslateTransform = new TranslateTransform();
_interactiveEllipse.RenderTransform =
_interactiveTranslateTransform;
_containerBorder.MouseLeftButtonDown +=
border_mouseLeftButtonDown;
_containerBorder.MouseRightButtonDown +=
border_mouseRightButtonDown;
}
private readonly TranslateTransform _interactiveTranslateTransform;
首先声明了一个私有的只读的
TranslateTransform
类型的对象
_interactiveTranslateTransform
,然后在MainWindow的构造函数中赋值。
_interactiveTranslateTransform = new TranslateTransform();
TranslateTransform
是什么?有什么作用呢?
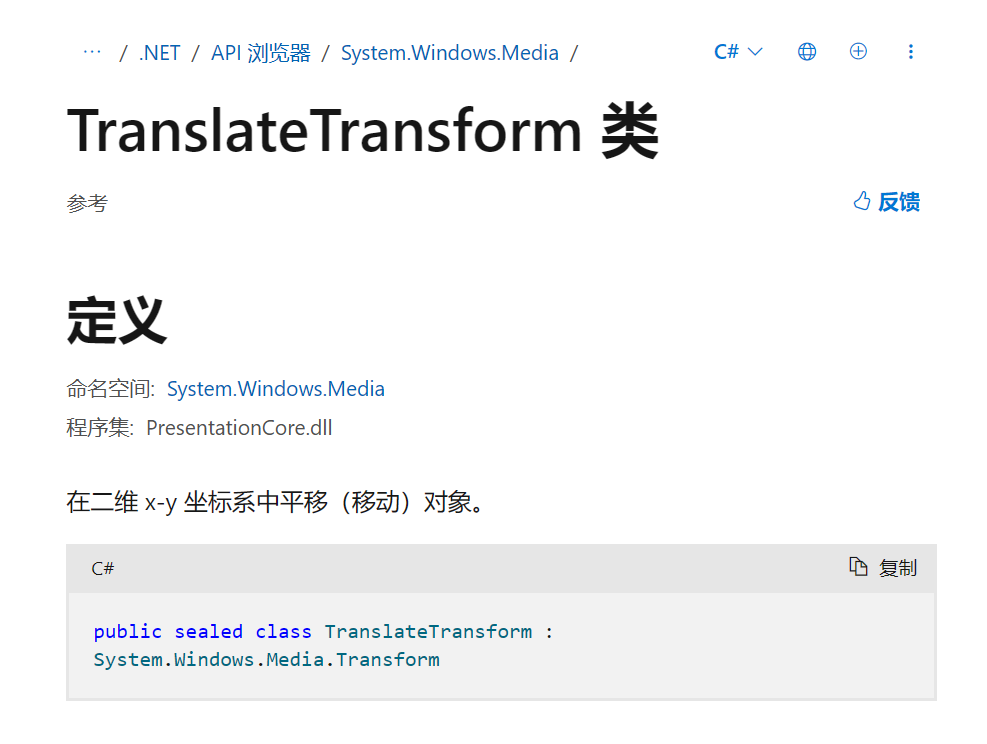
它的基本结构:
//
// 摘要:
// Translates (moves) an object in the 2-D x-y coordinate system.
public sealed class TranslateTransform : Transform
{
public static readonly DependencyProperty XProperty;
public static readonly DependencyProperty YProperty;
public TranslateTransform();
public TranslateTransform(double offsetX, double offsetY);
public override Matrix Value { get; }
public double X { get; set; }
public double Y { get; set; }
public TranslateTransform Clone();
public TranslateTransform CloneCurrentValue();
protected override Freezable CreateInstanceCore();
}
TranslateTransform 是 WPF 中的一个类,它表示一个 2D 平移变换。这个类是 Transform 类的派生类,用于在 2D 平面上移动(平移)对象。
TranslateTransform 类有两个主要的属性:X 和 Y,它们分别表示在 X 轴和 Y 轴上的移动距离。例如,如果你设置 X 为 100 和 Y 为 200,那么应用这个变换的元素将会向右移动 100 像素,向下移动 200 像素。
_interactiveEllipse.RenderTransform =
_interactiveTranslateTransform;
将
_interactiveEllipse
元素的
RenderTransform
属性设置为
_interactiveTranslateTransform
。

RenderTransform
属性用于获取或设置影响
UIElement
呈现位置的转换信息。
_containerBorder.MouseLeftButtonDown +=
border_mouseLeftButtonDown;
_containerBorder.MouseRightButtonDown +=
border_mouseRightButtonDown;
这是在注册
_containerBorder
的鼠标左键点击事件与鼠标右键点击事件。
注意当Border这样写时,不会触发鼠标点击事件:
<Border x:Name="_containerBorder">
这是因为在 WPF 中,Border 控件的背景默认是透明的,这意味着它不会接收鼠标事件。当你设置了背景颜色后,Border 控件就会开始接收鼠标事件,因为它现在有了一个可见的背景。
如果你希望 Border 控件在没有背景颜色的情况下也能接收鼠标事件,你可以将背景设置为透明色。这样,虽然背景看起来是透明的,但它仍然会接收鼠标事件。
可以这样设置:
<Border x:Name="_containerBorder" Background="Transparent">
鼠标点击事件处理程序
以鼠标左键点击事件处理程序为例,进行说明:
private void border_mouseLeftButtonDown(object sender, MouseButtonEventArgs e)
{
var clickPoint = Mouse.GetPosition(_containerBorder);
// Set the target point so the center of the ellipse
// ends up at the clicked point.
var targetPoint = new Point
{
X = clickPoint.X - _interactiveEllipse.Width / 2,
Y = clickPoint.Y - _interactiveEllipse.Height / 2
};
// Animate to the target point.
var xAnimation =
new DoubleAnimation(targetPoint.X,
new Duration(TimeSpan.FromSeconds(4)));
_interactiveTranslateTransform.BeginAnimation(
TranslateTransform.XProperty, xAnimation, HandoffBehavior.SnapshotAndReplace);
var yAnimation =
new DoubleAnimation(targetPoint.Y,
new Duration(TimeSpan.FromSeconds(4)));
_interactiveTranslateTransform.BeginAnimation(
TranslateTransform.YProperty, yAnimation, HandoffBehavior.SnapshotAndReplace);
// Change the color of the ellipse.
_interactiveEllipse.Fill = Brushes.Lime;
}
重点是:
// Animate to the target point.
var xAnimation =
new DoubleAnimation(targetPoint.X,
new Duration(TimeSpan.FromSeconds(4)));
_interactiveTranslateTransform.BeginAnimation(
TranslateTransform.XProperty, xAnimation, HandoffBehavior.SnapshotAndReplace);
var yAnimation =
new DoubleAnimation(targetPoint.Y,
new Duration(TimeSpan.FromSeconds(4)));
_interactiveTranslateTransform.BeginAnimation(
TranslateTransform.YProperty, yAnimation, HandoffBehavior.SnapshotAndReplace);
DoubleAnimation
类的介绍:
DoubleAnimation 是 WPF 中的一个类,它用于创建从一个 double 值到另一个 double 值的动画。这个类是 AnimationTimeline 类的派生类,它可以用于任何接受 double 类型的依赖属性。
DoubleAnimation 类有几个重要的属性:
• From:动画的起始值。
• To:动画的结束值。
• By:动画的增量值,用于从 From 值增加或减少。
• Duration:动画的持续时间。
• AutoReverse:一个布尔值,指示动画是否在到达 To 值后反向运行回 From 值。
• RepeatBehavior:定义动画的重复行为,例如,它可以设置为无限重复或重复特定的次数。
var xAnimation =
new DoubleAnimation(targetPoint.X,
new Duration(TimeSpan.FromSeconds(4)));
我们使用的是这种形式的重载:

设置了一个要达到的double类型值与达到的时间,这里设置为了4秒。
_interactiveTranslateTransform.BeginAnimation(
TranslateTransform.XProperty, xAnimation, HandoffBehavior.SnapshotAndReplace);

• _interactiveTranslateTransform.BeginAnimation:这是 BeginAnimation 方法的调用,它开始一个动画,该动画会改变一个依赖属性的值。在这个例子中,改变的是 _interactiveTranslateTransform 对象的 X 属性。
• TranslateTransform.XProperty:这是 TranslateTransform 类的 X 依赖属性。这个属性表示在 X 轴上的移动距离。
• xAnimation:这是一个 DoubleAnimation 对象,它定义了动画的目标值和持续时间。在这个例子中,动画的目标值是鼠标点击的位置,持续时间是 4 秒。
• HandoffBehavior.SnapshotAndReplace:这是 HandoffBehavior 枚举的一个值,它定义了当新动画开始时,如何处理正在进行的动画。SnapshotAndReplace 表示新动画将替换旧动画,并从旧动画当前的值开始。
全部代码
xaml:
<Window x:Class="AnimationDemo.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:local="clr-namespace:AnimationDemo"
mc:Ignorable="d"
Title="MainWindow" Height="450" Width="800">
<DockPanel>
<Border x:Name="_containerBorder" Background="Transparent">
<Ellipse x:Name="_interactiveEllipse"
Fill="Lime"
Stroke="Black"
StrokeThickness="2.0"
Width="25"
Height="25"
HorizontalAlignment="Left"
VerticalAlignment="Top" />
</Border>
</DockPanel>
</Window>
cs:
using System.Text;
using System.Windows;
using System.Windows.Controls;
using System.Windows.Data;
using System.Windows.Documents;
using System.Windows.Input;
using System.Windows.Media;
using System.Windows.Media.Animation;
using System.Windows.Media.Imaging;
using System.Windows.Navigation;
using System.Windows.Shapes;
namespace AnimationDemo
{
/// <summary>
/// Interaction logic for MainWindow.xaml
/// </summary>
public partial class MainWindow : Window
{
private readonly TranslateTransform _interactiveTranslateTransform;
public MainWindow()
{
InitializeComponent();
_interactiveTranslateTransform = new TranslateTransform();
_interactiveEllipse.RenderTransform =
_interactiveTranslateTransform;
_containerBorder.MouseLeftButtonDown +=
border_mouseLeftButtonDown;
_containerBorder.MouseRightButtonDown +=
border_mouseRightButtonDown;
}
private void border_mouseLeftButtonDown(object sender, MouseButtonEventArgs e)
{
var clickPoint = Mouse.GetPosition(_containerBorder);
// Set the target point so the center of the ellipse
// ends up at the clicked point.
var targetPoint = new Point
{
X = clickPoint.X - _interactiveEllipse.Width / 2,
Y = clickPoint.Y - _interactiveEllipse.Height / 2
};
// Animate to the target point.
var xAnimation =
new DoubleAnimation(targetPoint.X,
new Duration(TimeSpan.FromSeconds(4)));
_interactiveTranslateTransform.BeginAnimation(
TranslateTransform.XProperty, xAnimation, HandoffBehavior.SnapshotAndReplace);
var yAnimation =
new DoubleAnimation(targetPoint.Y,
new Duration(TimeSpan.FromSeconds(4)));
_interactiveTranslateTransform.BeginAnimation(
TranslateTransform.YProperty, yAnimation, HandoffBehavior.SnapshotAndReplace);
// Change the color of the ellipse.
_interactiveEllipse.Fill = Brushes.Lime;
}
private void border_mouseRightButtonDown(object sender, MouseButtonEventArgs e)
{
// Find the point where the use clicked.
var clickPoint = Mouse.GetPosition(_containerBorder);
// Set the target point so the center of the ellipse
// ends up at the clicked point.
var targetPoint = new Point
{
X = clickPoint.X - _interactiveEllipse.Width / 2,
Y = clickPoint.Y - _interactiveEllipse.Height / 2
};
// Animate to the target point.
var xAnimation =
new DoubleAnimation(targetPoint.X,
new Duration(TimeSpan.FromSeconds(4)));
_interactiveTranslateTransform.BeginAnimation(
TranslateTransform.XProperty, xAnimation, HandoffBehavior.Compose);
var yAnimation =
new DoubleAnimation(targetPoint.Y,
new Duration(TimeSpan.FromSeconds(4)));
_interactiveTranslateTransform.BeginAnimation(
TranslateTransform.YProperty, yAnimation, HandoffBehavior.Compose);
// Change the color of the ellipse.
_interactiveEllipse.Fill = Brushes.Orange;
}
}
}
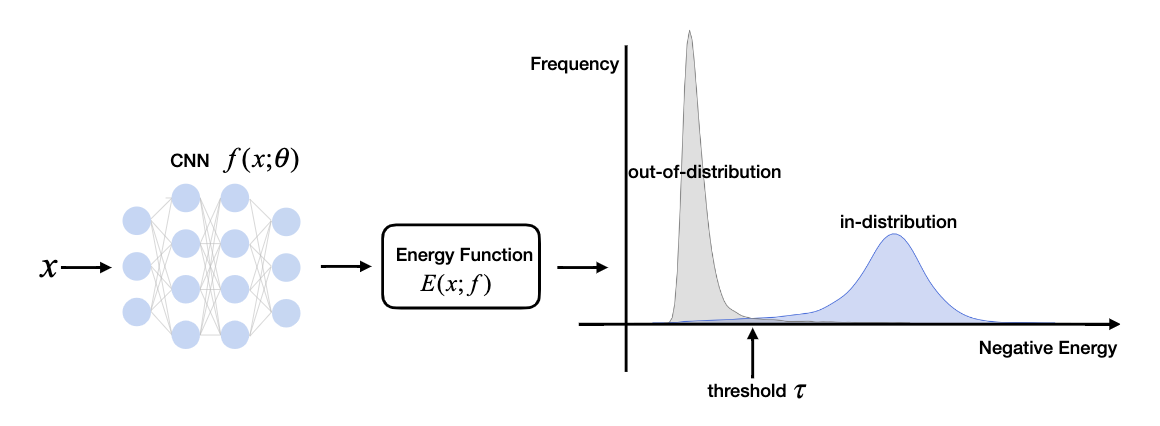
实现效果: