使用归一化盒过滤器对图像进行平滑处理
前言
在OpenCV中提供了一些函数将不同的线性滤波器应用于平滑图像:
- Normalized Box Filter 归一化盒过滤器
- Gaussian Filter 高斯滤波器
- Median Filter 中值滤波器
- Bilateral Filter 双边过滤器
其中归一化盒过滤器是最简单的,我们就从归一化盒过滤器开始我们的图像平滑之旅吧。
Normalized Box Filter原理介绍
为了执行平滑操作,我们将对图像应用滤镜。最常见的滤波器类型是线性滤波器,其中输出像素的值(即 g(i,j) )被确定为输入像素值的加权和(即 f(i+k,j+l) ):
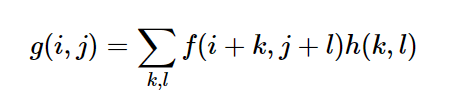
h(k,l) 称为核,无非是滤波器的系数。
Normalized Box Filter,也被称为归一化的盒形滤波器,是一种简单的图像滤波器,主要用于实现图像的平滑效果。
盒形滤波器的工作原理是将每个像素的值替换为其邻域内所有像素值的平均值。这种操作可以有效地消除图像中的噪声,但是它也会使图像变得模糊,因为它没有考虑像素之间的距离。
内核如下:
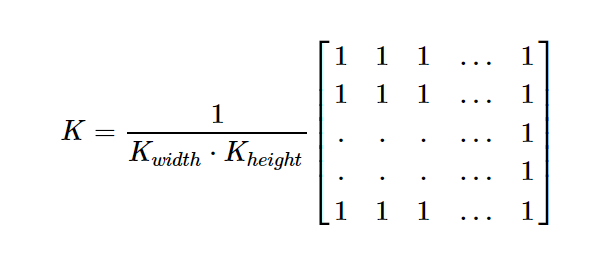
动手做一个3*3核的查看效果
OpenCV中提供了函数,本来我们只要用那个函数就行了,但是自己动手会让自己对原理理解的更清楚,等自己真的理解了原理,再直接使用OpenCV提供的函数也不迟。
在维基百科上有3*3核的伪代码:
Box blur (image)
{
set newImage to image;
For x /*row*/, y/*column*/ on newImage do:
{
// Kernel would not fit!
If x < 1 or y < 1 or x + 1 == width or y + 1 == height then:
Continue;
// Set P to the average of 9 pixels:
X X X
X P X
X X X
// Calculate average.
Sum = image[x - 1, y + 1] + // Top left
image[x + 0, y + 1] + // Top center
image[x + 1, y + 1] + // Top right
image[x - 1, y + 0] + // Mid left
image[x + 0, y + 0] + // Current pixel
image[x + 1, y + 0] + // Mid right
image[x - 1, y - 1] + // Low left
image[x + 0, y - 1] + // Low center
image[x + 1, y - 1]; // Low right
newImage[x, y] = Sum / 9;
}
Return newImage;
}
我们现在试着去用C#写一下:
public Mat BoxFilter(Mat src)
{
Mat mat = src.Clone();
for(int i = 1; i < mat.Width -1;i++)
{
for(int j = 1; j < mat.Height -1; j++)
{
int sumBlue = 0;
int sumGreen = 0;
int sumRed = 0;
for (int n = -1; n <= 1; n++)
{
for(int m = -1; m <= 1; m++)
{
Vec3b pixel = mat.At<Vec3b>(j+m, i+n);
sumBlue += pixel[0];
sumGreen += pixel[1];
sumRed += pixel[2];
}
}
int Blue = sumBlue / 9;
int Green = sumGreen / 9;
int Red = sumRed / 9;
Vec3b pixel2 = new Vec3b();
pixel2[0] = (byte)Blue;
pixel2[1] = (byte)Green;
pixel2[2] = (byte)Red;
// 将修改后的像素值写回图像
mat.Set(j, i, pixel2);
}
}
return mat;
}
现在看看我们写的与OpenCV中提供的效果对比:
// 加载图片
using (Mat src = new Mat("测试图片, ImreadModes.Color))
{
// 显示图片
Cv2.ImShow("原图", src);
Cv2.WaitKey(0);
Mat dst = new Mat();
dst = BoxFilter(src);
// 显示图片
Cv2.ImShow("MyBlur", dst);
Cv2.WaitKey(0);
Mat dst2 = new Mat();
Cv2.Blur(src, dst2, new OpenCvSharp.Size(3, 3));
// 显示图片
Cv2.ImShow("OpenCVBlur", dst2);
Cv2.WaitKey(0);
}
效果如下所示:
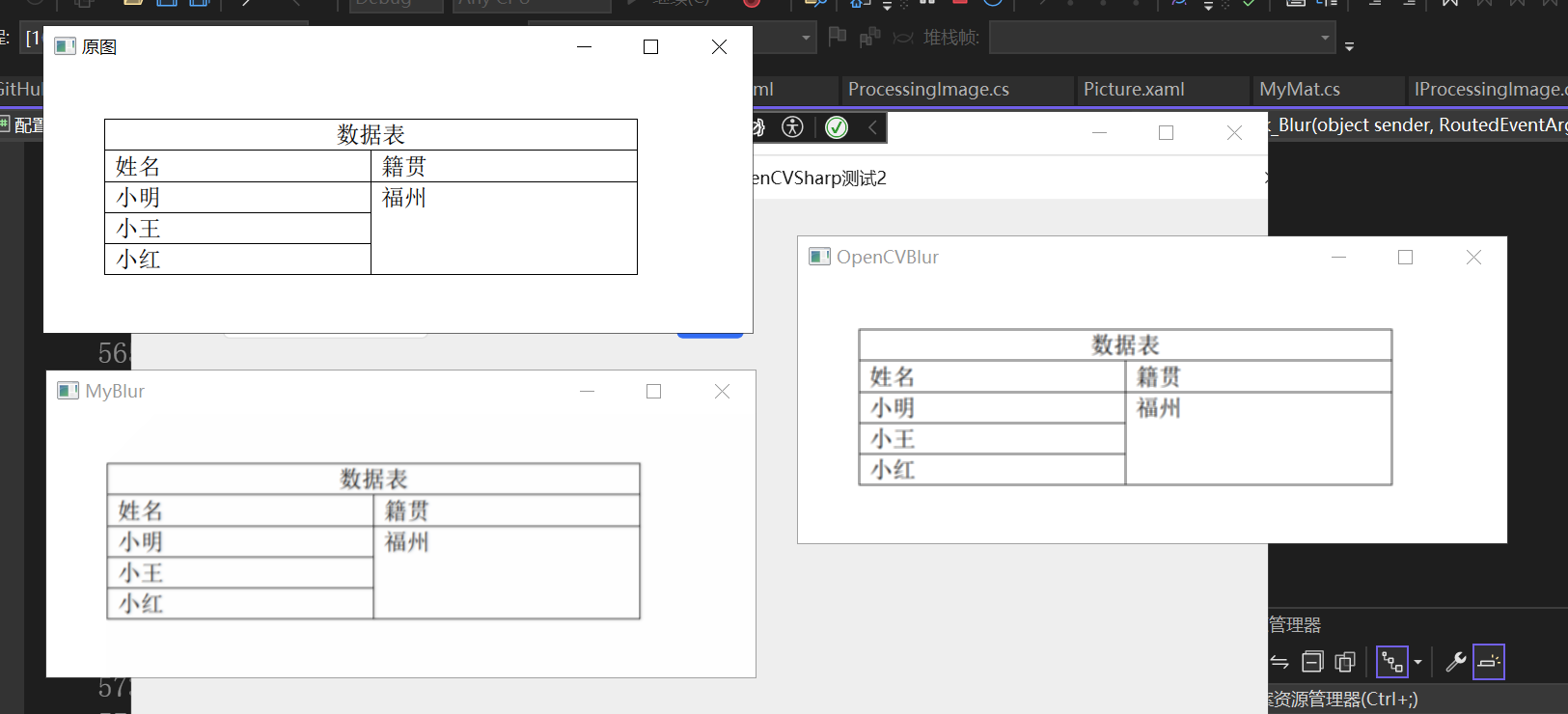
会发现实现了差不多的效果。
进行扩展适应其他大小的内核
现在我们学会了3*3大小的核的写法,能不能再进行扩展使之满足其他大小的核呢?
如果是5*5这样的我们也是可以进行扩展的。
用一个3*3的核去扫图像中的每一个像素,如果我们的锚点是在中心点,那么第一行第一列与最后一行最后一列上的像素就没法扫到。
什么是锚点?
在计算机图形学和图像处理中,"锚点"通常指的是一个参考点,用于确定图像或图形对象的位置、旋转和缩放。
那么现在如果是5*5的核去扫图像中的每一点,如果锚点是中心点的话,就是前两行前两列后两行后两列扫不到了。
根据这个规律我们就可以进行改写:
public Mat BoxFilter2(Mat src,OpenCvSharp.Size size)
{
Mat mat = src.Clone();
int x = (size.Width - 1) / 2;
for (int i = x; i < mat.Width - x; i++)
{
for (int j = x; j < mat.Height - x; j++)
{
int sumBlue = 0;
int sumGreen = 0;
int sumRed = 0;
for (int n = -x; n <= x; n++)
{
for (int m = -x; m <= x; m++)
{
Vec3b pixel = mat.At<Vec3b>(j + m, i + n);
sumBlue += pixel[0];
sumGreen += pixel[1];
sumRed += pixel[2];
}
}
int Blue = sumBlue / (size.Width * size.Height);
int Green = sumGreen / (size.Width * size.Height);
int Red = sumRed / (size.Width * size.Height);
Vec3b pixel2 = new Vec3b();
pixel2[0] = (byte)Blue;
pixel2[1] = (byte)Green;
pixel2[2] = (byte)Red;
// 将修改后的像素值写回图像
mat.Set(j, i, pixel2);
}
}
return mat;
}
现在再看一下效果:
// 加载图片
using (Mat src = new Mat("测试图片, ImreadModes.Color))
{
// 显示图片
Cv2.ImShow("原图", src);
Cv2.WaitKey(0);
Mat dst = new Mat();
dst = BoxFilter2(src, new OpenCvSharp.Size(5, 5));
// 显示图片
Cv2.ImShow("MyBlur", dst);
Cv2.WaitKey(0);
Mat dst2 = new Mat();
Cv2.Blur(src, dst2, new OpenCvSharp.Size(3, 3));
// 显示图片
Cv2.ImShow("OpenCVBlur", dst2);
Cv2.WaitKey(0);
}
实现的效果如下所示:

OpenCV是非常强大的,它考虑了很多情况,如何核是5 * 7的呢?我们这样写就又要修改了。如何锚点不是中心点呢?我们这样写就不行了。我们这样写的目的只是为了让我们更熟悉一下原理,后面需要用到的时候直接使用OpenCV提供的函数就好了。
使用OpenCV函数
经过前面自己的练习,对于原理也更加了解了,以后就可以直接使用OpenCV提供的函数了。
先来介绍一下OpenCvSharp中的
Cv2.Blur
函数:
public static void Blur(InputArray src, OutputArray dst, Size ksize, Point? anchor = null, BorderTypes borderType = BorderTypes.Reflect101)
|
参数名
|
类型
|
含义
|
| src |
InputArray |
输入的图像 |
| dst |
OutputArray |
与输入图像同样大小同样类型的输出图像 |
| ksize |
Size |
平滑内核大小 |
| anchor |
Point |
锚点,默认在内核中心 |
| borderType |
BorderTypes |
用于外推图像外部像素的边界模式 |
平常使用时一般这样使用就可以了:
Cv2.Blur(src, dst, new OpenCvSharp.Size(5, 5));
再来介绍一下OpenCvSharp中的
Cv2.BoxFilter
函数:
public static void BoxFilter(InputArray src, OutputArray dst, MatType ddepth, Size ksize, Point? anchor = null, bool normalize = true, BorderTypes borderType = BorderTypes.Reflect101)
|
参数名
|
类型
|
含义
|
| src |
InputArray |
输入的图像 |
| dst |
OutputArray |
与输入图像同样大小同样类型的输出图像 |
| ddepth |
MatType |
输出图像的深度 ,
-1
表示输出图像和输入图像有相同的深度。 |
| ksize |
Size |
平滑内核大小 |
| anchor |
Point |
锚点,默认在内核中心 |
| normalize |
bool |
表示是否对滤波器核进行归一化 |
| borderType |
BorderTypes |
用于外推图像外部像素的边界模式 |
平常使用时一般这样使用就可以了:
Cv2.BoxFilter(src, dst, -1,new OpenCvSharp.Size(5, 5));
总结
本文向大家介绍了
Normalized Box Filter 归一化盒过滤器
的基本原理,以及在OpenCVSharp中如何使用,希望对你有所帮助。
参考
1、
OpenCV: Smoothing Images
2、
框模糊 - 维基百科,自由的百科全书 --- Box blur - Wikipedia