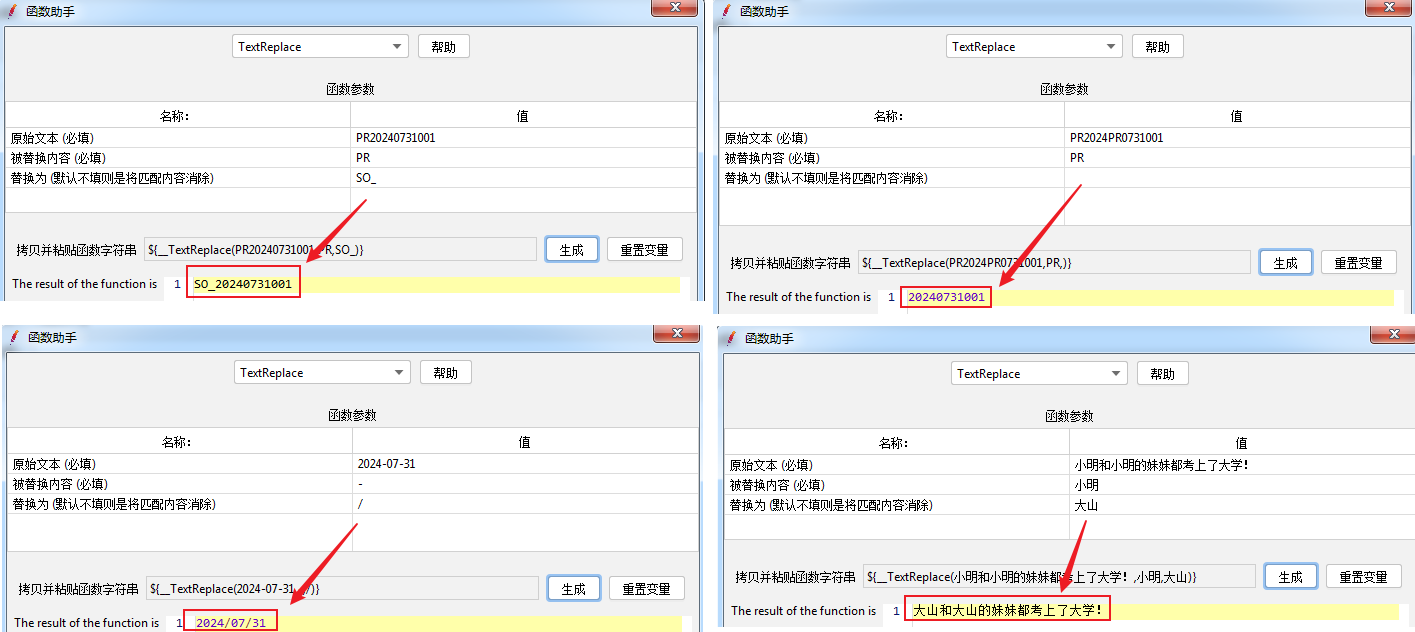
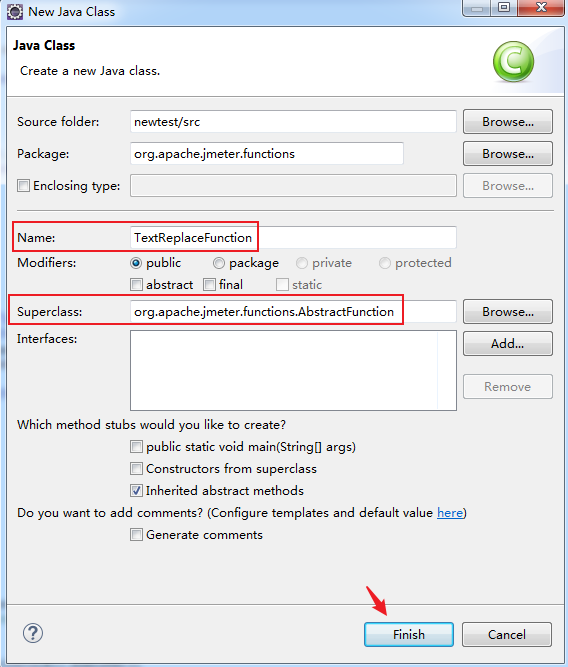
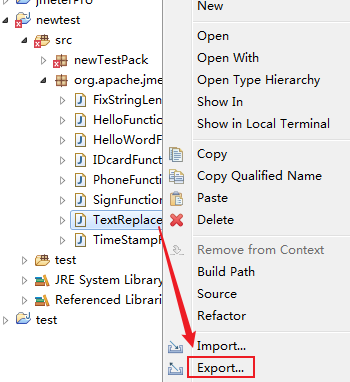
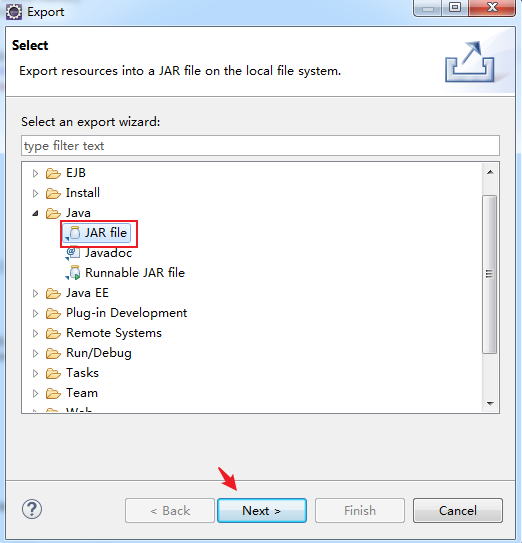
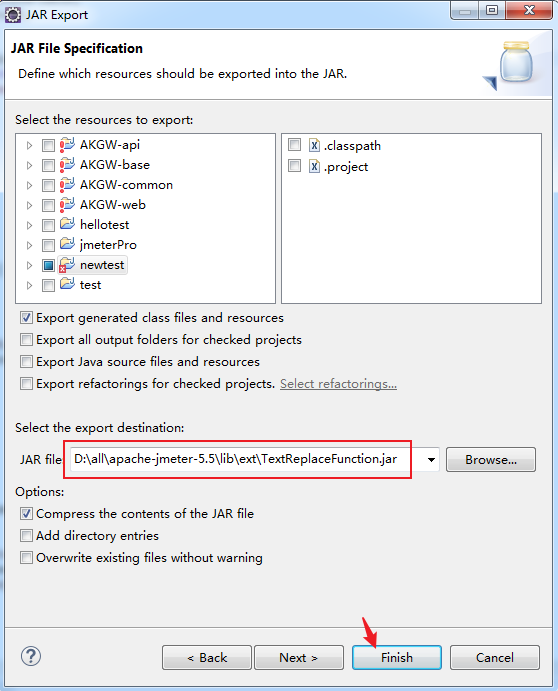
探索Amazon S3:存储解决方案的基石
本文为上一篇minio使用的衍生版
相关链接:1.
https://www.cnblogs.com/ComfortableM/p/18286363
2.
https://blog.csdn.net/zizai_a/article/details/140796186?spm=1001.2014.3001.5501
引言
云存储已经成为现代信息技术不可或缺的一部分,它为企业和个人提供了诸多便利。以下是几个关键点,说明云存储为何如此重要:
1. 数据安全与备份
- 数据加密
:云存储服务商通常提供高级加密技术,确保数据在传输过程中和存储时的安全。
- 备份与恢复
:云存储能够自动备份数据,并且在发生灾难性事件时,可以迅速恢复数据,保证业务连续性不受影响。
2. 成本效益
- 按需付费
:用户可以根据实际使用的存储空间支付费用,避免了传统存储方式中预购大量存储空间的成本浪费。
- 运维成本降低
:云存储减少了企业在硬件采购、维护和升级方面的开销,同时也降低了电力和冷却成本。
3. 灵活性与可扩展性
- 无限扩展
:随着数据量的增长,云存储可以轻松地扩展存储容量,无需用户手动增加硬件资源。
- 多租户模型
:用户可以轻松地管理不同的项目或部门的数据隔离,而不会受到物理限制的影响。
4. 访问与协作
- 远程访问
:无论用户身处何处,只要有互联网连接,就可以访问存储在云端的数据。
- 文件共享
:通过简单的链接分享机制,团队成员之间可以轻松共享文件,促进协作。
5. 灾难恢复
- 多地域复制
:云存储服务通常提供数据的多地域复制功能,确保即使某个数据中心发生故障,数据依然可用。
- 快速恢复
:当遇到意外情况时,云存储可以迅速恢复数据,减少数据丢失的风险。
6. 技术创新与支持
- 最新技术
:云存储服务商会持续更新技术栈,确保用户能够获得最新的存储技术和安全措施。
- 技术支持
:专业的技术支持团队可以及时响应用户的疑问和技术难题。
7. 法规遵从
- 合规性
:许多云存储服务提供商遵循严格的法规标准,确保数据存储符合地区法律法规要求。
8. 对智慧城市的贡献
- 城市管理
:云存储对于收集、处理和分析智慧城市中产生的大量数据至关重要,有助于提高城市管理效率和服务质量。
综上所述,云存储不仅改变了企业和个人管理数据的方式,还推动了整个社会向着更加高效、可持续的方向发展。随着技术的进步,我们可以期待云存储在未来扮演更加重要的角色。
Amazon Simple Storage Service (S3) 是 Amazon Web Services (AWS) 中最成熟且广泛使用的对象存储服务之一。自从2006年推出以来,S3 已经成为云计算领域的一个标志性产品,它不仅为AWS奠定了基础,而且在全球范围内成为了云存储的标准之一。
关键点:
- 成熟度与可靠性
:经过多年的运营,S3 已经证明了其极高的可靠性和稳定性。它能够处理大量的数据存储需求,并保持高可用性和持久性,平均故障时间(MTTF)达到了数百年。
- 广泛的采用率
:S3 被成千上万的企业所使用,包括初创公司、大型企业和政府机构,这些组织依赖于 S3 来存储各种类型的数据,从小文件到PB级别的数据集。
- 丰富的功能集
:S3 提供了一系列强大的功能,如版本控制、生命周期管理、数据加密、访问控制等,这些功能使得 S3 成为了一个灵活且全面的存储解决方案。
- 集成与兼容性
:S3 与其他 AWS 服务紧密集成,比如 Amazon Elastic Compute Cloud (EC2)、Amazon Redshift 和 AWS Lambda,使得用户可以在 AWS 生态系统内部构建复杂的应用程序和服务。此外,S3 还支持多种第三方工具和服务,使其成为数据处理管道的核心组成部分。
- 成本效益
:S3 提供了多种存储类别的选择,允许用户根据数据访问频率和存储需求来优化成本。例如,Standard 类别适用于频繁访问的数据,而 Infrequent Access (IA) 或 Glacier 类别则适用于长期存档数据。
- 技术创新
:S3 不断推出新的特性和改进,以满足不断变化的市场需求。例如,Intelligent-Tiering 存储类别能够自动将数据移动到最合适的存储层,从而帮助用户节省成本。
- 行业认可
:S3 获得了多个行业奖项和认证,这反映了它在云存储领域的领导地位。
Amazon S3 作为 AWS 的旗舰级服务之一,在过去十几年里已经成为了全球云存储领域的标杆。无论是从成熟度、可靠性还是功能丰富性来看,S3 都是企业和开发者信赖的选择。随着 AWS 继续在其基础上进行创新和发展,我们有理由相信 S3 将继续引领云存储的发展趋势。
Amazon S3简介
Amazon Simple Storage Service (S3) 是亚马逊 Web Services (AWS) 提供的一种对象存储服务。自2006年推出以来,S3 已经成为了云存储领域的一个标志性产品,它为开发者和企业提供了一种简单、高效的方式来存储和检索任意数量的数据。
核心特点:
- 高可用性和持久性
:S3 被设计为能够承受严重的系统故障,确保数据的高度持久性。其设计目标是每年的数据丢失率为0.000000000001(11个9),这意味着数据几乎不会丢失。S3 使用多副本冗余存储来保护数据免受组件故障的影响,并且数据被自动分布在多个设施中,以防止区域性的灾难影响数据的可用性。
- 无限的可扩展性
:S3 的架构允许无缝扩展,无需预先规划存储容量。企业可以根据需要存储从GB到EB级别的数据,而无需担心存储限制。这种自动扩展能力意味着企业不必担心在数据量快速增长时需要手动调整基础设施。
- 成本效益
:S3 提供了多种存储类别,使企业可以根据数据的访问频率选择最适合的选项,从而优化成本。例如,S3 Standard 适合频繁访问的数据,而 S3 Standard-Infrequent Access (S3 Standard-IA) 和 S3 One Zone-Infrequent Access (S3 One Zone-IA) 适用于不经常访问的数据。S3 智能分层能够自动检测数据的访问模式,并将数据移动到最经济的存储层,以进一步降低成本。
- 安全性和合规性
:S3 支持多种安全功能,如服务器端加密、客户端加密、访问控制策略等,以保护数据免受未经授权的访问。它还支持多种合规标准,如 HIPAA、FedRAMP、PCI DSS 等,帮助企业遵守行业法规要求。
- 易于管理和集成
:S3 提供了一个直观的管理控制台,使用户能够轻松地上传、下载和管理数据。它还提供了丰富的 API 和 SDK,以便开发者可以轻松地将 S3 集成到他们的应用程序和服务中。
- 数据生命周期管理
:通过 S3 生命周期策略,企业可以自动将数据从一个存储类别迁移到另一个存储类别,或者在指定的时间后删除数据。这种自动化的过程有助于减少管理负担,并确保数据始终处于最经济的存储层。
- 高性能和全球覆盖
:S3 的全球边缘位置网络确保了低延迟的数据访问,无论用户位于世界哪个角落。这种分布式的架构有助于提高数据的可用性和响应速度。
使用场景:
- 网站托管
:S3 可以用来托管静态网站,包括HTML页面、CSS样式表、JavaScript脚本和图片。
- 数据备份与恢复
:企业可以使用 S3 作为数据备份和灾难恢复策略的一部分,确保数据的安全性和可恢复性。
- 大数据处理
:S3 可以作为大数据分析的数据湖,存储原始数据,供后续处理和分析使用。
- 媒体存储与分发
:S3 适用于存储和分发视频、音频和其他多媒体文件。
- 应用程序数据存储
:S3 可以存储应用程序生成的日志文件、缓存数据、数据库备份等。
快速使用
Spring boot集成
添加依赖
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
</dependency>
创建配置类
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import software.amazon.awssdk.auth.credentials.AwsBasicCredentials;
import software.amazon.awssdk.auth.credentials.StaticCredentialsProvider;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.S3Configuration;
import software.amazon.awssdk.services.s3.presigner.S3Presigner;
import java.net.URI;
@Configuration
public class AmazonS3Config {
@Value("${aws.s3.accessKey}")
private String accessKeyId;
@Value("${aws.s3.secretKey}")
private String secretKey;
@Value("${aws.s3.endPoint}")
private String endPoint;//接入点,未设置可以注释
@Bean
public S3Client s3Client() {
AwsBasicCredentials credentials = AwsBasicCredentials.create(accessKeyId, secretKey);
return S3Client.builder()
.credentialsProvider(StaticCredentialsProvider.create(credentials))
.region(Region.US_EAST_1)//区域
.endpointOverride(URI.create(endPoint))//接入点
.serviceConfiguration(S3Configuration.builder()
.pathStyleAccessEnabled(true)
.chunkedEncodingEnabled(false)
.build())
.build();
}
//S3Presigner是用来获取文件对象预签名url的
@Bean
public S3Presigner s3Presigner() {
AwsBasicCredentials credentials = AwsBasicCredentials.create(accessKeyId, secretKey);
return S3Presigner.builder()
.credentialsProvider(StaticCredentialsProvider.create(credentials))
.region(Region.US_EAST_1)
.endpointOverride(URI.create(endPoint))
.build();
}
}
基本操作介绍
创建桶
public boolean ifExistsBucket(String bucketName) {
// 尝试发送 HEAD 请求来检查存储桶是否存在
try {
HeadBucketResponse headBucketResponse = s3Client.headBucket(HeadBucketRequest.builder().bucket(bucketName).build());
} catch (S3Exception e) {
// 如果捕获到 S3 异常且状态码为 404,则说明存储桶不存在
if (e.statusCode() == 404) {
return false;
} else {
// 打印异常堆栈跟踪
e.printStackTrace();
}
}
// 如果没有抛出异常或状态码不是 404,则说明存储桶存在
return true;
}
public boolean createBucket(String bucketName) throws RuntimeException {
// 检查存储桶是否已经存在
if (ifExistsBucket(bucketName)) {
// 如果存储桶已存在,则抛出运行时异常
throw new RuntimeException("桶已存在");
}
// 创建新的存储桶
S3Response bucket = s3Client.createBucket(CreateBucketRequest.builder().bucket(bucketName).build());
// 检查存储桶是否创建成功
return ifExistsBucket(bucketName);
}
public boolean removeBucket(String bucketName) {
// 如果存储桶不存在,则直接返回 true
if (!ifExistsBucket(bucketName)) {
return true;
}
// 删除存储桶
s3Client.deleteBucket(DeleteBucketRequest.builder().bucket(bucketName).build());
// 检查存储桶是否已被删除
return !ifExistsBucket(bucketName);
}
上传
public boolean uploadObject(String bucketName, String targetObject, String sourcePath) {
// 尝试上传本地文件到指定的存储桶和对象键
try {
s3Client.putObject(PutObjectRequest.builder()
.bucket(bucketName)
.key(targetObject)
.build(), RequestBody.fromFile(new File(sourcePath)));
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 false
e.printStackTrace();
return false;
}
// 如果上传成功则返回 true
return true;
}
public boolean putObject(String bucketName, String object, InputStream inputStream, long size) {
// 尝试从输入流上传数据到指定的存储桶和对象键
try {
s3Client.putObject(PutObjectRequest.builder()
.bucket(bucketName)
.key(object)
.build(), RequestBody.fromInputStream(inputStream, size));
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 false
e.printStackTrace();
return false;
}
// 如果上传成功则返回 true
return true;
}
public boolean putObject(String bucketName, String object, InputStream inputStream, long size, Map<String, String> tags) {
// 尝试从输入流上传数据到指定的存储桶和对象键,并设置标签
try {
// 将标签映射转换为标签集合
Collection<Tag> tagList = tags.entrySet().stream().map(entry ->
Tag.builder().key(entry.getKey()).value(entry.getValue()).build())
.collect(Collectors.toList());
// 上传对象并设置标签
s3Client.putObject(PutObjectRequest.builder()
.bucket(bucketName)
.key(object)
.tagging(Tagging.builder()
.tagSet(tagList)
.build())
.build(), RequestBody.fromInputStream(inputStream, size));
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 false
e.printStackTrace();
return false;
}
// 如果上传成功则返回 true
return true;
}
分片上传
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.*;
import software.amazon.awssdk.core.sync.RequestBody;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class S3MultipartUploader {
private static final S3Client s3Client = S3Client.create();
/**
* 开始一个新的分片上传会话。
*
* @param bucketName 存储桶名称
* @param objectKey 对象键
* @return 返回的 UploadId 用于后续操作
*/
public static InitiateMultipartUploadResponse initiateMultipartUpload(String bucketName, String objectKey) {
InitiateMultipartUploadRequest request = InitiateMultipartUploadRequest.builder()
.bucket(bucketName)
.key(objectKey)
.build();
return s3Client.initiateMultipartUpload(request);
}
/**
* 上传一个分片。
*
* @param bucketName 存储桶名称
* @param objectKey 对象键
* @param uploadId 上传会话的 ID
* @param partNumber 分片序号
* @param file 文件
* @param offset 文件偏移量
* @param length 文件长度
* @return 返回的 Part ETag 用于完成上传时验证
*/
public static UploadPartResponse uploadPart(String bucketName, String objectKey, String uploadId,
int partNumber, File file, long offset, long length) {
try (FileInputStream fis = new FileInputStream(file)) {
UploadPartRequest request = UploadPartRequest.builder()
.bucket(bucketName)
.key(objectKey)
.uploadId(uploadId)
.partNumber(partNumber)
.build();
RequestBody requestBody = RequestBody.fromInputStream(fis, length, offset);
return s3Client.uploadPart(request, requestBody);
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
/**
* 完成分片上传。
*
* @param bucketName 存储桶名称
* @param objectKey 对象键
* @param uploadId 上传会话的 ID
* @param parts 已上传的分片列表
*/
public static CompleteMultipartUploadResponse completeMultipartUpload(String bucketName, String objectKey,
String uploadId, List<CompletedPart> parts) {
CompleteMultipartUploadRequest request = CompleteMultipartUploadRequest.builder()
.bucket(bucketName)
.key(objectKey)
.uploadId(uploadId)
.multipartUpload(CompletedMultipartUpload.builder()
.parts(parts)
.build())
.build();
return s3Client.completeMultipartUpload(request);
}
/**
* 取消分片上传会话。
*
* @param bucketName 存储桶名称
* @param objectKey 对象键
* @param uploadId 上传会话的 ID
*/
public static void abortMultipartUpload(String bucketName, String objectKey, String uploadId) {
AbortMultipartUploadRequest request = AbortMultipartUploadRequest.builder()
.bucket(bucketName)
.key(objectKey)
.uploadId(uploadId)
.build();
s3Client.abortMultipartUpload(request);
}
public static void main(String[] args) {
String bucketName = "your-bucket-name";
String objectKey = "path/to/your-object";
File fileToUpload = new File("path/to/your/local/file");
// 开始分片上传会话
InitiateMultipartUploadResponse initResponse = initiateMultipartUpload(bucketName, objectKey);
String uploadId = initResponse.uploadId();
// 计算文件大小和分片数量
long fileSize = fileToUpload.length();
int partSize = 5 * 1024 * 1024; // 假设每个分片大小为 5MB
int numberOfParts = (int) Math.ceil((double) fileSize / partSize);
// 上传每个分片
List<CompletedPart> completedParts = new ArrayList<>();
try (FileInputStream fis = new FileInputStream(fileToUpload)) {
for (int i = 1; i <= numberOfParts; i++) {
long startOffset = (i - 1) * partSize;
long currentPartSize = Math.min(partSize, fileSize - startOffset);
// 上传分片
UploadPartResponse partResponse = uploadPart(bucketName, objectKey, uploadId, i, fileToUpload, startOffset, currentPartSize);
if (partResponse != null) {
// 保存已完成分片的信息
CompletedPart completedPart = CompletedPart.builder()
.partNumber(i)
.eTag(partResponse.eTag())
.build();
completedParts.add(completedPart);
}
}
} catch (IOException e) {
e.printStackTrace();
}
// 完成分片上传
CompleteMultipartUploadResponse completeResponse = completeMultipartUpload(bucketName, objectKey, uploadId, completedParts);
if (completeResponse != null) {
System.out.println("分片上传成功!");
} else {
System.out.println("分片上传失败。");
}
}
}
下载
public boolean downObject(String bucketName, String objectName, String targetPath) {
// 尝试下载对象到指定路径
try {
s3Client.getObject(GetObjectRequest.builder()
.bucket(bucketName)
.key(objectName)
.build(), new File(targetPath).toPath());
} catch (Exception e) {
// 如果出现异常则打印异常堆栈跟踪并返回 false
e.printStackTrace();
return false;
}
// 如果下载成功则返回 true
return true;
}
public InputStream getObject(String bucketName, String object) {
InputStream objectStream = null;
// 尝试获取指定存储桶和对象键的输入流
try {
objectStream = s3Client.getObject(GetObjectRequest.builder()
.bucket(bucketName)
.key(object)
.build());
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 null
e.printStackTrace();
return null;
}
// 返回对象的输入流
return objectStream;
}
public ResponseBytes<GetObjectResponse> getObjectAsBytes(String bucketName, String object) {
ResponseBytes<GetObjectResponse> objectAsBytes = null;
// 尝试获取指定存储桶和对象键的内容作为字节
try {
objectAsBytes = s3Client.getObjectAsBytes(GetObjectRequest.builder()
.bucket(bucketName)
.key(object)
.build());
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 null
e.printStackTrace();
return null;
}
// 返回对象的内容作为字节
return objectAsBytes;
}
获取对象预签名url
public String presignedURLofObject(String bucketName, String object, int expire) {
URL url = null;
// 尝试生成预签名 URL
try {
url = s3Presigner.presignGetObject(GetObjectPresignRequest.builder()
.signatureDuration(Duration.ofMinutes(expire))
.getObjectRequest(GetObjectRequest.builder()
.bucket(bucketName)
.key(object)
.build())
.build()).url();
} catch (Exception e) {
// 如果出现异常则打印异常堆栈跟踪并返回 null
e.printStackTrace();
return null;
} finally {
// 关闭预签名客户端
s3Presigner.close();
}
// 返回预签名 URL 的字符串表示形式
return url.toString();
}
获取到的url是可以直接在浏览器预览的,但是要用其他插件(如 pdf.js)预览的话会出现跨域的错误,这个时候就需要给要访问的桶添加一下cors规则。
代码添加cors规则:
CORSRule corsRule = CORSRule.builder()
.allowedOrigins("http://ip:端口")//可以设置多个
//.allowedOrigins("*")
.allowedHeaders("Authorization")
.allowedMethods("GET","HEAD")
.exposeHeaders("Access-Control-Allow-Origin").build();
// 设置 CORS 配置
s3Client.putBucketCors(PutBucketCorsRequest.builder()
.bucket(bucketName)
.corsConfiguration(CORSConfiguration.builder()
.corsRules(corsRule)
.build())
.build());
S3控制台添加CORS规则:
点击你的桶选择权限,下拉找到这个设置,编辑添加下面的规则:

[
{
"AllowedHeaders": [
"Authorization"
],
"AllowedMethods": [
"GET",
"HEAD"
],
"AllowedOrigins": [
"http://ip:端口"
],
"ExposeHeaders": [
"Access-Control-Allow-Origin"
],
"MaxAgeSeconds": 3000
}
]
用S3 Browser添加

S3 Browser 是一款用于管理 Amazon S3 存储服务的第三方工具。它提供了一个图形用户界面(GUI),让用户能够更方便地上传、下载、管理和浏览存储在 Amazon S3 中的对象和存储桶。也可以用来连接minio或者其他存储。
添加你的配置等待扫描出桶名后,右击桶名选择CORS Configuration添加你的规则,点击apply使用。
<?xml version="1.0" encoding="UTF-8"?>
<CORSConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/">
<CORSRule>
<AllowedOrigin>http://ip:端口</AllowedOrigin>
<AllowedMethod>GET</AllowedMethod>
<AllowedMethod>HEAD</AllowedMethod>
<MaxAgeSeconds>3000</MaxAgeSeconds>
<ExposeHeader>Access-Control-Allow-Origin</ExposeHeader>
<AllowedHeader>Authorization</AllowedHeader>
</CORSRule>
</CORSConfiguration>
部分方法集
因为是另一个项目的延伸版,所以有些方法反而改的更繁琐的一些。
S3Service
import org.springframework.stereotype.Service;
import software.amazon.awssdk.core.ResponseBytes;
import software.amazon.awssdk.services.s3.model.Bucket;
import software.amazon.awssdk.services.s3.model.GetObjectResponse;
import software.amazon.awssdk.services.s3.model.HeadObjectResponse;
import software.amazon.awssdk.services.s3.model.S3Object;
import java.io.InputStream;
import java.util.List;
import java.util.Map;
/**
* 定义与 AWS S3 客户端交互的一般功能。
*/
@Service
public interface S3Service {
/**
* 判断指定的存储桶是否存在。
*
* @param bucketName 存储桶名称。
* @return 如果存储桶存在返回 true,否则返回 false。
*/
boolean ifExistsBucket(String bucketName);
/**
* 创建一个新的存储桶。如果存储桶已存在,则抛出运行时异常。
*
* @param bucketName 新建的存储桶名称。
* @return 如果存储桶创建成功返回 true。
* @throws RuntimeException 如果存储桶已存在。
*/
boolean createBucket(String bucketName) throws RuntimeException;
/**
* 删除一个存储桶。存储桶必须为空;否则不会被删除。
* 即使指定的存储桶不存在也会返回 true。
*
* @param bucketName 要删除的存储桶名称。
* @return 如果存储桶被删除或不存在返回 true。
*/
boolean removeBucket(String bucketName);
/**
* 列出当前 S3 服务器上所有存在的存储桶。
*
* @return 存储桶列表。
*/
List<Bucket> alreadyExistBuckets();
/**
* 列出存储桶中的对象,可选地通过前缀过滤并指定是否包括子目录。
*
* @param bucketName 存储桶名称。
* @param predir 前缀过滤条件。
* @param recursive 是否包括子目录。
* @return S3 对象列表。
*/
List<S3Object> listObjects(String bucketName, String predir, boolean recursive);
/**
* 列出存储桶中的对象,通过前缀过滤。
*
* @param bucketName 存储桶名称。
* @param predir 前缀过滤条件。
* @return S3 对象列表。
*/
List<S3Object> listObjects(String bucketName, String predir);
/**
* 复制一个对象文件从一个存储桶到另一个存储桶。
*
* @param pastBucket 源文件所在的存储桶。
* @param pastObject 源文件在存储桶内的路径。
* @param newBucket 将要复制进的目标存储桶。
* @param newObject 将要复制进的目标存储桶内的路径。
* @return 如果复制成功返回 true。
*/
boolean copyObject(String pastBucket, String pastObject, String newBucket, String newObject);
/**
* 下载一个对象。
*
* @param bucketName 存储桶名称。
* @param objectName 对象路径及名称(例如:2022/02/02/xxx.doc)。
* @param targetPath 目标路径及名称(例如:/opt/xxx.doc)。
* @return 如果下载成功返回 true。
*/
boolean downObject(String bucketName, String objectName, String targetPath);
/**
* 返回对象的签名 URL。
*
* @param bucketName 存储桶名称。
* @param object 对象路径及名称。
* @param expire 过期时间(分钟)。
* @return 签名 URL。
*/
String presignedURLofObject(String bucketName, String object, int expire);
/**
* 返回带有额外参数的对象签名 URL。
*
* @param bucketName 存储桶名称。
* @param object 对象路径及名称。
* @param expire 过期时间(分钟)。
* @param map 额外参数。
* @return 签名 URL。
*/
String presignedURLofObject(String bucketName, String object, int expire, Map<String, String> map);
/**
* 删除一个对象。
*
* @param bucketName 存储桶名称。
* @param object 对象名称(路径)。
* @return 如果删除成功返回 true。
*/
boolean deleteObject(String bucketName, String object);
/**
* 上传一个对象,使用本地文件作为源。
*
* @param bucketName 存储桶名称。
* @param targetObject 目标对象的名称。
* @param sourcePath 本地文件路径(例如:/opt/1234.doc)。
* @return 如果上传成功返回 true。
*/
boolean uploadObject(String bucketName, String targetObject, String sourcePath);
/**
* 上传一个对象,使用输入流作为源。
*
* @param bucketName 存储桶名称。
* @param object 对象名称。
* @param inputStream 输入流。
* @param size 对象大小。
* @return 如果上传成功返回 true。
*/
boolean putObject(String bucketName, String object, InputStream inputStream, long size);
/**
* 上传一个带有标签的对象。
*
* @param bucketName 存储桶名称。
* @param object 对象名称。
* @param inputStream 输入流。
* @param size 对象大小。
* @param tags 标签集合。
* @return 如果上传成功返回 true。
*/
boolean putObject(String bucketName, String object, InputStream inputStream, long size, Map<String, String> tags);
/**
* 获取一个对象。
*
* @param bucketName 存储桶名称。
* @param object 对象名称。
* @return GetObjectResponse 类型的输入流。
*/
InputStream getObject(String bucketName, String object);
/**
* 获取一个对象的内容作为字节流。
*
* @param bucketName 存储桶名称。
* @param object 对象名称。
* @return 包含对象内容的字节流。
*/
ResponseBytes<GetObjectResponse> getObjectAsBytes(String bucketName, String object);
/**
* 判断一个文件是否存在于存储桶中。
*
* @param bucketName 存储桶名称。
* @param filename 文件名称。
* @param recursive 是否递归搜索。
* @return 如果文件存在返回 true。
*/
boolean fileifexist(String bucketName, String filename, boolean recursive);
/**
* 获取一个对象的标签。
*
* @param bucketName 存储桶名称。
* @param object 对象名称。
* @return 标签集合。
*/
Map<String, String> getTags(String bucketName, String object);
/**
* 为存储桶内的对象添加标签。
*
* @param bucketName 存储桶名称。
* @param object 对象名称。
* @param addTags 要添加的标签。
* @return 如果添加成功返回 true。
*/
boolean addTags(String bucketName, String object, Map<String, String> addTags);
/**
* 获取对象的对象信息和元数据。
*
* @param bucketName 存储桶名称。
* @param object 对象名称。
* @return HeadObjectResponse 类型的对象信息和元数据。
*/
HeadObjectResponse statObject(String bucketName, String object);
/**
* 判断一个对象是否存在。
*
* @param bucketName 存储桶名称。
* @param objectName 对象名称。
* @return 如果对象存在返回 true。
*/
boolean ifExistObject(String bucketName, String objectName);
/**
* 从其他对象名称中获取元数据名称。
*
* @param objectName 对象名称。
* @return 元数据名称。
*/
String getMetaNameFromOther(String objectName);
/**
* 更改对象的标签。
*
* @param object 对象名称。
* @param tag 新的标签。
* @return 如果更改成功返回 true。
*/
boolean changeTag(String object, String tag);
/**
* 设置存储桶为公共访问。
*
* @param bucketName 存储桶名称。
*/
void BucketAccessPublic(String bucketName);
}
S3ServiceImpl
import com.xagxsj.erms.model.BucketName;
import com.xagxsj.erms.model.ObjectTags;
import com.xagxsj.erms.service.S3Service;
import com.xagxsj.erms.utils.FileUtil;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Service;
import software.amazon.awssdk.core.ResponseBytes;
import software.amazon.awssdk.core.sync.RequestBody;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.*;
import software.amazon.awssdk.services.s3.presigner.S3Presigner;
import software.amazon.awssdk.services.s3.presigner.model.GetObjectPresignRequest;
import java.io.File;
import java.io.InputStream;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLEncoder;
import java.time.Duration;
import java.util.*;
import java.util.logging.Logger;
import java.util.stream.Collectors;
@Service
public class S3ServiceImpl implements S3Service {
private final Logger log = Logger.getLogger(this.getClass().getName());
@Qualifier("s3Client")
@Autowired
S3Client s3Client;
@Qualifier("s3Presigner")
@Autowired
S3Presigner s3Presigner;
@Override
public boolean ifExistsBucket(String bucketName) {
// 尝试发送 HEAD 请求来检查存储桶是否存在
try {
HeadBucketResponse headBucketResponse = s3Client.headBucket(HeadBucketRequest.builder().bucket(bucketName).build());
} catch (S3Exception e) {
// 如果捕获到 S3 异常且状态码为 404,则说明存储桶不存在
if (e.statusCode() == 404) {
return false;
} else {
// 打印异常堆栈跟踪
e.printStackTrace();
}
}
// 如果没有抛出异常或状态码不是 404,则说明存储桶存在
return true;
}
@Override
public boolean createBucket(String bucketName) throws RuntimeException {
// 检查存储桶是否已经存在
if (ifExistsBucket(bucketName)) {
// 如果存储桶已存在,则抛出运行时异常
throw new RuntimeException("桶已存在");
}
// 创建新的存储桶
S3Response bucket = s3Client.createBucket(CreateBucketRequest.builder().bucket(bucketName).build());
// 检查存储桶是否创建成功
return ifExistsBucket(bucketName);
}
@Override
public boolean removeBucket(String bucketName) {
// 如果存储桶不存在,则直接返回 true
if (!ifExistsBucket(bucketName)) {
return true;
}
// 删除存储桶
s3Client.deleteBucket(DeleteBucketRequest.builder().bucket(bucketName).build());
// 检查存储桶是否已被删除
return !ifExistsBucket(bucketName);
}
@Override
public List<Bucket> alreadyExistBuckets() {
// 列出所有存在的存储桶
List<Bucket> buckets = s3Client.listBuckets().buckets();
return buckets;
}
@Override
public boolean fileifexist(String bucketName, String filename, boolean recursive) {
// 初始化一个布尔值用于标记文件是否存在
boolean flag = false;
// 构建第一次的 ListObjectsV2 请求
ListObjectsV2Request request = ListObjectsV2Request.builder().bucket(bucketName).build();
ListObjectsV2Response response;
// 循环处理直到所有分页的数据都被检索
do {
// 发送请求并获取响应
response = s3Client.listObjectsV2(request);
// 遍历响应中的内容
for (S3Object content : response.contents()) {
// 如果找到匹配的文件名,则设置标志位为真
if (content.key().equals(filename)) {
flag = true;
break;
}
}
// 构建下一次请求,如果响应被截断,则继续获取下一页的数据
request = ListObjectsV2Request.builder()
.bucket(bucketName)
.continuationToken(response.nextContinuationToken())
.build();
} while (response.isTruncated());
// 返回文件是否存在
return flag;
}
@Override
public List<S3Object> listObjects(String bucketName, String predir, boolean recursive) {
// 构建 ListObjects 请求以列出具有指定前缀的文件
List<S3Object> contents = s3Client.listObjects(ListObjectsRequest.builder()
.bucket(bucketName)
.prefix(predir)
.maxKeys(1000)
.build()).contents();
return contents;
}
@Override
public List<S3Object> listObjects(String bucketName, String predir) {
// 构建 ListObjects 请求以列出具有指定前缀的文件
List<S3Object> contents = s3Client.listObjects(ListObjectsRequest.builder()
.bucket(bucketName)
.prefix(predir)
.maxKeys(1000)
.build()).contents();
return contents;
}
@Override
public boolean copyObject(String pastBucket, String pastObject, String newBucket, String newObject) {
// 尝试复制对象
try {
CopyObjectResponse copyObjectResponse = s3Client.copyObject(CopyObjectRequest.builder()
.sourceBucket(pastBucket)
.sourceKey(pastObject)
.destinationBucket(newBucket)
.destinationKey(newObject)
.build());
} catch (Exception e) {
// 如果出现异常则打印异常堆栈跟踪并返回 false
e.printStackTrace();
return false;
}
// 如果复制成功则返回 true
return true;
}
@Override
public boolean downObject(String bucketName, String objectName, String targetPath) {
// 尝试下载对象到指定路径
try {
s3Client.getObject(GetObjectRequest.builder()
.bucket(bucketName)
.key(objectName)
.build(), new File(targetPath).toPath());
} catch (Exception e) {
// 如果出现异常则打印异常堆栈跟踪并返回 false
e.printStackTrace();
return false;
}
// 如果下载成功则返回 true
return true;
}
@Override
public String presignedURLofObject(String bucketName, String object, int expire) {
URL url = null;
// 尝试生成预签名 URL
try {
url = s3Presigner.presignGetObject(GetObjectPresignRequest.builder()
.signatureDuration(Duration.ofMinutes(expire))
.getObjectRequest(GetObjectRequest.builder()
.bucket(bucketName)
.key(object)
.build())
.build()).url();
} catch (Exception e) {
// 如果出现异常则打印异常堆栈跟踪并返回 null
e.printStackTrace();
return null;
} finally {
// 关闭预签名客户端
s3Presigner.close();
}
// 返回预签名 URL 的字符串表示形式
return url.toString();
}
@Override
public String presignedURLofObject(String bucketName, String object, int expire, Map<String, String> map) {
URL url = null;
// 尝试生成预签名 URL
try {
url = s3Presigner.presignGetObject(GetObjectPresignRequest.builder()
.signatureDuration(Duration.ofMinutes(expire))
.getObjectRequest(GetObjectRequest.builder()
.bucket(bucketName)
.key(object)
.build())
.build()).url();
} catch (Exception e) {
// 如果出现异常则打印异常堆栈跟踪并返回 null
e.printStackTrace();
return null;
} finally {
// 关闭预签名客户端
s3Presigner.close();
}
// 返回预签名 URL 的字符串表示形式
return url.toString();
}
@Override
public boolean deleteObject(String bucketName, String object) {
// 尝试删除对象
try {
s3Client.deleteObject(DeleteObjectRequest.builder()
.bucket(bucketName)
.key(object)
.build());
} catch (Exception e) {
// 如果出现异常则打印异常堆栈跟踪并返回 false
e.printStackTrace();
return false;
}
// 如果删除成功则返回 true
return true;
}
@Override
public boolean uploadObject(String bucketName, String targetObject, String sourcePath) {
// 尝试上传本地文件到指定的存储桶和对象键
try {
s3Client.putObject(PutObjectRequest.builder()
.bucket(bucketName)
.key(targetObject)
.build(), RequestBody.fromFile(new File(sourcePath)));
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 false
e.printStackTrace();
return false;
}
// 如果上传成功则返回 true
return true;
}
@Override
public boolean putObject(String bucketName, String object, InputStream inputStream, long size) {
// 尝试从输入流上传数据到指定的存储桶和对象键
try {
s3Client.putObject(PutObjectRequest.builder()
.bucket(bucketName)
.key(object)
.build(), RequestBody.fromInputStream(inputStream, size));
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 false
e.printStackTrace();
return false;
}
// 如果上传成功则返回 true
return true;
}
@Override
public boolean putObject(String bucketName, String object, InputStream inputStream, long size, Map<String, String> tags) {
// 尝试从输入流上传数据到指定的存储桶和对象键,并设置标签
try {
// 将标签映射转换为标签集合
Collection<Tag> tagList = tags.entrySet().stream().map(entry ->
Tag.builder().key(entry.getKey()).value(entry.getValue()).build())
.collect(Collectors.toList());
// 上传对象并设置标签
s3Client.putObject(PutObjectRequest.builder()
.bucket(bucketName)
.key(object)
.tagging(Tagging.builder()
.tagSet(tagList)
.build())
.build(), RequestBody.fromInputStream(inputStream, size));
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 false
e.printStackTrace();
return false;
}
// 如果上传成功则返回 true
return true;
}
@Override
public InputStream getObject(String bucketName, String object) {
InputStream objectStream = null;
// 尝试获取指定存储桶和对象键的输入流
try {
objectStream = s3Client.getObject(GetObjectRequest.builder()
.bucket(bucketName)
.key(object)
.build());
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 null
e.printStackTrace();
return null;
}
// 返回对象的输入流
return objectStream;
}
@Override
public ResponseBytes<GetObjectResponse> getObjectAsBytes(String bucketName, String object) {
ResponseBytes<GetObjectResponse> objectAsBytes = null;
// 尝试获取指定存储桶和对象键的内容作为字节
try {
objectAsBytes = s3Client.getObjectAsBytes(GetObjectRequest.builder()
.bucket(bucketName)
.key(object)
.build());
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 null
e.printStackTrace();
return null;
}
// 返回对象的内容作为字节
return objectAsBytes;
}
@Override
public Map<String, String> getTags(String bucketName, String object) {
Map<String, String> tags = null;
// 尝试获取指定存储桶和对象键的标签
try {
List<Tag> tagList = s3Client.getObjectTagging(GetObjectTaggingRequest.builder()
.bucket(bucketName)
.key(object)
.build()).tagSet();
// 将标签集合转换为标签映射
tags = tagList.stream().collect(Collectors.toMap(Tag::key, Tag::value));
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 null
e.printStackTrace();
return null;
}
// 返回标签映射
return tags;
}
@Override
public boolean addTags(String bucketName, String object, Map<String, String> addTags) {
Map<String, String> oldTags = new HashMap<>();
Map<String, String> newTags = new HashMap<>();
// 获取现有标签
try {
oldTags = getTags(bucketName, object);
if (oldTags.size() > 0) {
newTags.putAll(oldTags);
}
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并提示没有旧标签
e.printStackTrace();
System.out.println("原存储桶无老旧标签");
}
// 添加新标签
if (addTags != null && addTags.size() > 0) {
newTags.putAll(addTags);
}
// 将新标签集合转换为标签列表
Collection<Tag> tagList = newTags.entrySet().stream().map(entry ->
Tag.builder().key(entry.getKey()).value(entry.getValue()).build())
.collect(Collectors.toList());
// 设置新标签
try {
s3Client.putObjectTagging(PutObjectTaggingRequest.builder()
.bucket(bucketName)
.key(object)
.tagging(Tagging.builder()
.tagSet(tagList).build())
.build());
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 false
e.printStackTrace();
return false;
}
// 如果设置成功则返回 true
return true;
}
@Override
public HeadObjectResponse statObject(String bucketName, String object) {
HeadObjectResponse headObjectResponse = null;
// 尝试获取指定存储桶和对象键的元数据
try {
headObjectResponse = s3Client.headObject(HeadObjectRequest.builder()
.bucket(bucketName)
.key(object)
.build());
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 null
e.printStackTrace();
return null;
}
// 返回对象的元数据
return headObjectResponse;
}
@Override
public boolean ifExistObject(String bucketName, String objectName) {
// 检查指定存储桶和对象键的对象是否存在
return listObjects(bucketName, objectName, true).size() >= 1;
}
@Override
public String getMetaNameFromOther(String objectName) {
String metaObject = "";
// 获取元数据存储桶中特定前缀的对象列表
List<S3Object> s3Objects = listObjects(BucketName.METADATA, FileUtil.getPreMeta(objectName), true);
if (s3Objects.size() == 1) {
try {
// 获取第一个对象的键并获取其标签
metaObject = s3Objects.get(0).key();
Map<String, String> tags = getTags(BucketName.METADATA, metaObject);
// 编码文件名标签
String fileName = tags.get(ObjectTags.FILENAME);
return URLEncoder.encode(fileName, "UTF-8");
} catch (UnsupportedEncodingException e) {
// 如果出现异常,则打印异常堆栈跟踪
e.printStackTrace();
}
}
// 如果未找到对象或编码失败,则返回原始文件名
return FileUtil.getFileName(metaObject);
}
@Override
public boolean changeTag(String object, String tag) {
// 尝试更改指定对象的标签
try {
s3Client.putObjectTagging(PutObjectTaggingRequest.builder()
.bucket(BucketName.METADATA)
.key(object)
.tagging(Tagging.builder()
.tagSet(Tag.builder()
.key(ObjectTags.FILENAME)
.value(tag)
.build())
.build())
.build());
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪并返回 false
e.printStackTrace();
return false;
}
// 如果更改成功则返回 true
return true;
}
@Override
public void BucketAccessPublic(String bucketName) {
// 设置存储桶策略为公共访问
String config = "{\"Version\":\"2012-10-17\",\"Statement\":[{\"Effect\":\"Allow\",\"Principal\":{\"AWS\":[\"*\"]},\"Action\":[\"s3:ListBucketMultipartUploads\",\"s3:GetBucketLocation\",\"s3:ListBucket\"],\"Resource\":[\"arn:aws:s3:::" + bucketName + "\"]},{\"Effect\":\"Allow\",\"Principal\":{\"AWS\":[\"*\"]},\"Action\":[\"s3:ListMultipartUploadParts\",\"s3:PutObject\",\"s3:AbortMultipartUpload\",\"s3:DeleteObject\",\"s3:GetObject\"],\"Resource\":[\"arn:aws:s3:::" + bucketName + "/*\"]}]}";
try {
// 应用存储桶策略
s3Client.putBucketPolicy(PutBucketPolicyRequest.builder()
.bucket(bucketName)
.policy(config).build());
} catch (Exception e) {
// 如果出现异常,则打印异常堆栈跟踪
e.printStackTrace();
}
}
}