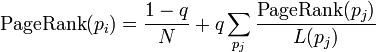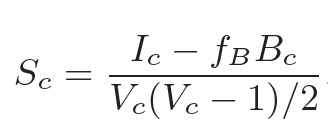SSL,https(HTTP over SSL), X.509, SSL 证书 ,证书申请 /导入/签发, 等名词,想必有一定工作经验的小伙伴,一定都会略有耳闻,或者至少也听神边大神念叨过。虽然司空见惯,但是能够比较系统理清其中关系,能够从整体到局部深入浅出讲解下的人,估计至少也是十里挑一。反正没人给我讲,我只好自己梳理下。(注意本文不涉及密码学原理以及SSL协议具体细节,但具备密码学基础,会有助于愉快阅读)
起因是公司最近在搞安全加固,想起了历史原因用了很久的FTP服务,这东西众所周知是明文的,裸奔的用户名密码,被监听是分分钟的事儿。于是寻思加个密吧,搜了下发现有个FTPS( FTP over SSL),很容易联想到一个更常用的https(http over。SSL), 展开一搜还有各种 XXXX - over - SSL。 如SMTPS,POP3S, LDAPS等,于是问题来了,SSL到底是个啥东西,为啥可以被各种over。
我们从大家比较熟悉的http协议角度说起,HTTP这个协议(就是header,body,post get这些)是在大概1991年附近发布,其设计初衷就是用来传输显示网页内容。这协议是明文的,明文的含义——就是你阅读的网页内容以及提交的,经过的每一个网络节点都可以知道传输的具体是啥内容。我猜早期的网页既不动态,也不私密,也没有个人相册:-),所以为了简单,http协议本身并没有考虑加密机制。
后来,WWW就火了,网络时代正式来临,页面功能越来越强大,支持动态化,可以为不同用户提供不同内容,已经可以发个悄悄话,照片啥的了。这时自然就产生了加密需求。于是1994年有一个叫网景(Netscape)的公司,做浏览器的,开始琢磨怎么加密http协议传输的网页内容。琢磨着,琢磨着,就琢磨出了
SSL协议
,后来历经完善,变成了标准,改了名字 目前叫TLS,至今广泛使用。
网景已乘黄鹤去,但对互联网的发展和安全起了重要贡献。
SSL协议的制定目标是解决http传输的安全问题,目前仍在广泛应用,可见网景制定的这个协议还是比较科学的。所谓天下文章一大抄,SSL也是借鉴了前人基础,融会贯通而成。
大约1976年,大洋彼岸的大壮,提出了非对称加密,数字证书的概念。1977年,同样远在彼岸的小明,发明了实用的非对称加密RSA算法,标志着公开密钥加密的诞生(就是现在常提的公钥,私钥,非对称啥的)。
有了天才的大壮和小明,数字证书以及非对称加密的相关理论已经完备,只待应用。于是在一些安全需求较高的专用内部网络(军事,金融,企业)中,一些系统开始根据大壮和小明提供的思路,实现基于数字证书和非对称加密算法的身份认证与通信加密功能。
凡事都是先发明,再应用,再有标准(参照电池,先发明,再使用,再规定5号 ,7号电池啥规格)。基于数字证书和RSA算法的加密机制,因为缺乏标准,导致出现各系统实现间的不兼容,证书互不认可等问题。
于是1988年诞生了一个叫做X.509的标准,定义了数字证书的字段内容,比如应该有持有者的名称、公钥、有效期、序列号以及证书颁发机构(CA)的签名等。这个标准的产生,也推动了CA的标准化和普及。
X.509 标准仅定义了证书的字段内容,而另外的一些文件格式标准,则具体定义了证书文件的存储格式。如.pem .der .p12 .p7b等,这些就是我们在系统中可见的证书和私钥的存在形式。
基于以上,网景公司定义了在互联网中,客户端和服务器进行网络通信时,类似 发送ABC 表示 请求证书,发DEF ,表示协商双方都支持的密码套件的,发XYZ,表示XXX。 这样一个网络协议,
将其命名为SSL/TLS。
SSL(Secure Sockets Layer )为啥可以被各种over,Layer 顾名思义,SSL协议的作用主要是加解密,与具体传输数据无关,应用把数据扔给 SSL层后,细节就不太需要关心了。他自然会帮你加密好,传送到目的地,解密好,再送达应用。所以所有的应用层协议,都是可以over SSL的。如http,FTP等。
通信的过程,大致都是先建立SSL通道,证书验证好,对称密钥交换好。这个建立SSL通道的过程,概念上称为——SSL协商握手。握手完成后,后续的通信内容就都是加密的了。你应用层需要传个 GET ,POST,Header,body 之类,还是按你应用层的协议来,该咋咋滴。所以你应用层是http 那就是 http over SSL. 如果是 ftp 就是FTP over ssl。
举一反三: 如果你自己写了个聊天客户端和服务器,是否可以用你的自定义聊天协议来 LAOWANG over SSL 呢?
如何实践应用 XXX over SSL。
1. 向CA申请服务器端ssl证书(x.509证书)——通过上面我门可以知道,x.509证书适用于,各种的 https ftps pop3s laowangs . 以及其他依赖于x509证书的领域,如电子签章。
注意,我门有时候会说 https 证书,ssl证书,ftps证书,本质都是x509证书,习惯称为ssl证书,不要混淆。
2. 在服务器端将申请到的证书及对应私钥放置好,并配置启动SSL支持——这是ssl协议通信的基础。证书虽然都是x.509证书,但具体的证书文件可能需要格式转换,nginx倾向于使用PEM文件格式的证书(.pem)和私钥。
3. 申请客户端证书(可选)——我也是刚知道不久,原来
ssl协议是支持双向认证的
。Web浏览器模式使用的是单向认证,但在一些安全需求较高的应用,可能会需要进行双向认证,服务器可以验证客户端的证书是否有效,并且根据证书信息如持有人,决定是否可以进行连接。
4.客户端对应使用支持SSL的客户端进行通信。
ok
,写到这里拜了个拜~
*关于密码学基础,在我的其他网络安全相关文章中,有简要介绍,欢迎参考