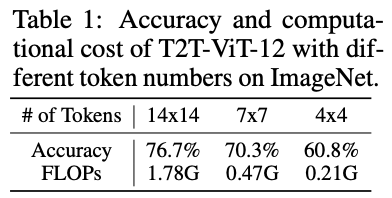
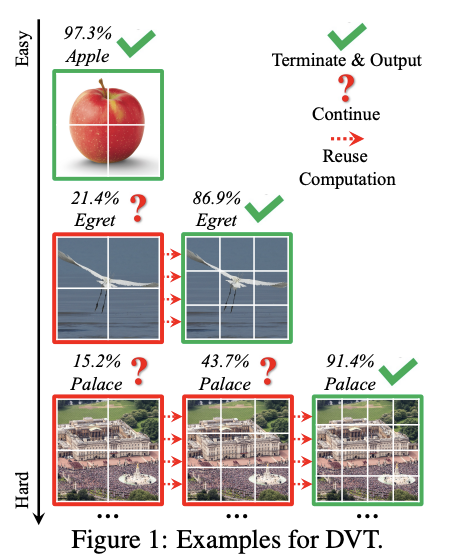
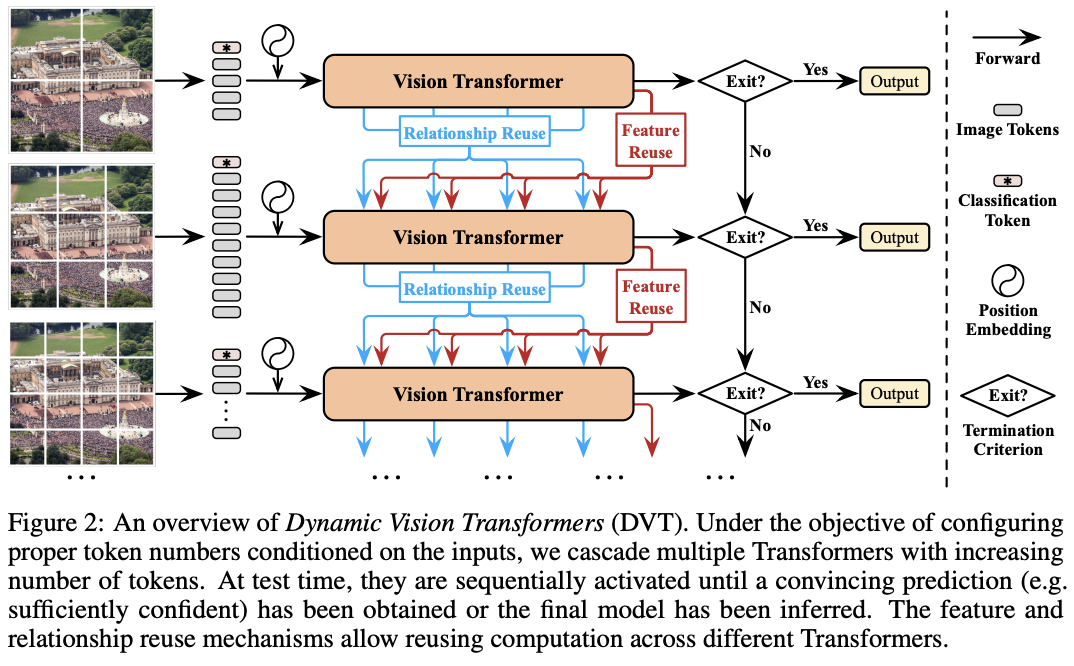
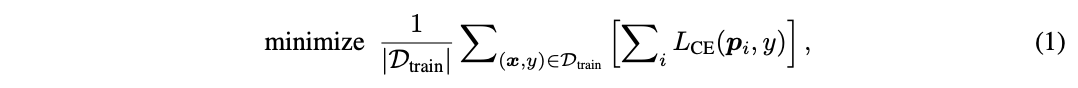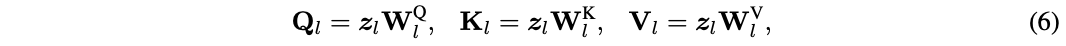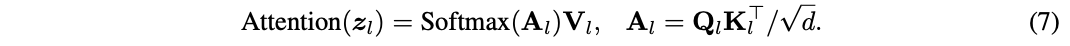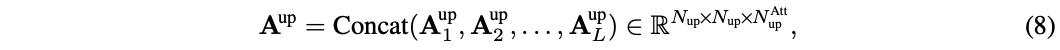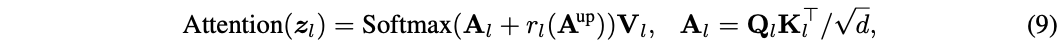随机数对程序设计来说很重要,今天就从几方面探讨下一些常见的随机数相关的问题。
本文只讨论整数相关的随机数,另外需要你对概率论有最基本的了解(至少知道古典概型是什么)。
本文索引
如何从rand7生成rand5
首先是和某个知名算法题相反的问题。
这里给定一个可以概率均等地生成0到6的随机数生成器,要求用这个生成器创造出能概率均等地生成0到4的随机数生成器。
有人可能会立刻给出这样的答案:
func rand5() int {
return rand7() % 5
}
然而这个答案只满足了输出的范围在0到4,不满足概率均等,所以不正确。这种时候列表法的作用就显现出来了:
|
rand7的输出
|
rand7 % 5
|
| 0 |
0 |
| 1 |
1 |
| 2 |
2 |
| 3 |
3 |
| 4 |
4 |
| 5 |
0 |
| 6 |
1 |
发现问题了吗,0和1出现了两次,它们出现的概率是其他数字的两倍,因此概率分布并不均等。
通过列表法我们其实也发现了这个问题真正的解法:除掉5和6的话剩下的输出不仅符合要求概率也是均等的,所以代码会变成这样:
func rand5() int {
n := rand7()
for n >= 5 {
n = rand7()
}
return n
}
上面的代码其实就是随机采样算法中非常重要的一种:拒绝采样。同样上面的rand7生成rand5也可以归类成一大类问题:给定一组满足规律或者特征是
g(x)
的样本,现在需要从这些样本中筛选出或者生成另一组满足特征是
f(x)
的样本。解决这类问题的算法很多,而拒绝采样是比较直观的:判断
g(x)
的样本是否符合要求,不符合的就排除取下一个样本,符合要求的就归类到满足
f(x)
的样本集合中。
按照这个角度来看,上面的问题可以划分为几个基本元素:
- g(x):rand7
- f(x): rand5
- 需要拒绝的样本:大于等于5的整数
拒绝采样在大多数时间都能获得理想的结果,但还有采样率需要注意。采样率就是
g(x)
的样本中有多少可以被接受,采样率太低的时候意味着算法的效率也会非常低。所以我们简单算算rand5的采样率,是七分之五,大约70%。这个概率不大不小,勉强合适。
当采样率过低的时候要么得改变拒绝采样的标准或范围,要么就不能再使用拒绝采样了。
go标准库的做法
标准库里当然不会有rand5和rand7,但它提供了一个叫
Int63n
的函数,它解决的问题是如何从均匀分布在
[0, 2⁶⁴)
范围上的随机整数中生成均匀分布在范围
[0, n)
上的随机整数。换句话说,虽然范围不一样了,但还是同一个问题。
我们肯定不能像上面那样把大于等于n的样本全丢了,因为2⁶⁴包含至少1844京(1E16)个整数样本,这会带来低得无法接受的采样率。
但因为我们是用mod来选择范围内的随机数的,因此我们可以选择n的倍数,这个证明太简单了,列表法加归纳就行。或者还可以这么想,有一个整数常数C,
x % n
和
Cx % n
能产生的输出的种类和它们的数量都是完全相同的,所以如果样本能均匀分布在
[0, n)
的范围上,那么范围
[0, C·n]
只不过是
[0, n)
重复了C次,所以样本在每一段上都是均匀分布的,整个合起来的区间上也是均匀的。
有了常数C,这样使得我们可以尽可能地让更多的样本被采样,这样能降低重试的次数。
C其实也很好选择,取一个2⁶⁴内的n的最大的倍数就行,如果C本身能被2⁶⁴整除,那么C就是
2⁶⁴/n
。
所以标准库是这样写的:
func (r *Rand) Int63n(n int64) int64 {
if n <= 0 {
panic("invalid argument to Int63n")
}
if n&(n-1) == 0 { // n is power of two, can mask
return r.Int63() & (n - 1)
}
max := int64((1 << 63) - 1 - (1<<63)%uint64(n))
v := r.Int63()
for v > max {
v = r.Int63()
}
return v % n
}
代码还是很简单的,超过
C·n
的样本全部拒绝采样,剩下的样本就能保证在
mod n
的时候获得分布均匀的随机整数了。
采样率是多少?我们可以利用拒绝率来反推,这里拒绝率还挺好算的,就是
(1<<63)%uint64(n)
,算下来拒绝了少的时候是百亿分之一,多的时候是数千万分之一——都很低,基本上大多数时间最多两次重试就能获得想要的结果了。
但作为标准库,它的性能还不够,尤其是go的编译优化非常弱的现实下,更需要高效的算法弥补。问题出在哪?首先不是采样率,这个采样率是足够的,问题出在它需要两次64位除法,除法运算相比其他运算比如右移要慢很多,何况还是两次,别的语言中的标准库采用的算法只需要0到1次除法就够了。
好在go提供了
math/rand/v2
,采用了更高效的算法。
新算法依旧基于拒绝采样,但对采样的范围进行了变更,具体是这样的:
- 依然用概率均等的rand64生成一个随机整数x
- 现在把
x*n
,这样生成的值的范围是
[0, n·2⁶⁴)
- 因为是对已有范围的等比扩大,所以
x*n
在
[0, n·2⁶⁴)
依旧是均匀分布的(不过要注意,范围扩展了,但样本的总量不变还是2⁶⁴个)
[0, n·2⁶⁴)
可以均等分成n个范围,分别是
[0, 2⁶⁴)
,
[2⁶⁴, 2*2⁶⁴)
,
[2*2⁶⁴, 3*2⁶⁴)
...
[(n-1)*2⁶⁴, n*2⁶⁴)
- 这样每一个均等分割的范围整除以2⁶⁴就可以得到一个整数k,k一定在
[0, n)
内
- k可以当作符合要求的结果,而整除以2⁶⁴实际上可以转换成位运算,这样除法运算可以减少一次。
新算法有几个问题,第一个是
x*n
在大多数情况下会超过2⁶⁴,但这不用担心,因为go提供了高性能128位整数运算。
第二个是
x*n
虽然在
[0, n·2⁶⁴)
均匀分布,但我们怎么保证在均等分割的每个
[(k-1)*2⁶⁴, k*2⁶⁴)
上也是均等分布的呢?
答案是如果只有上面写的六个步骤,我们保证不了。原因是因为要想保证
x*n
均匀分布在每个
[(k-1)*2⁶⁴, k*2⁶⁴)
上,我们就要保证x本身要均匀分布在
[(k-1)*(2⁶⁴/n), k*(2⁶⁴/n))
上,换人话说,就是把2⁶⁴分割成n份,每份里的样本数量都要一致。因为我们的样本都是整数而不是实数,所以动动脚趾就能想到很多数是不能整除2⁶⁴的,因此会留下“余数”。但我们的新算法实际上假设了x均匀分布在2⁶⁴分割出来的均等的范围内。不能整除的情况下意味着即使按最均匀的办法分割,也会存在一部分范围比其他的范围多几个样本或者少几个样本,会多还是会少取决与你对
2⁶⁴/N
取整的方式。
但这问题不大,通常分段直接的数量差异对概率产生的误差非常小,比如我们把n取6,按尽可能均匀的分割,就存在4个分段比剩下的分段里的样本总数多1个,但每个分段的样本数量都有超过3E18个,多一个还是多两个带来的影响几乎可以忽略不计。
然而标准库最重要的是要保证结果的正确性,即使可能性是3E18分之一,它依旧不是0,函数的实现是不正确的,更何况根据n的选择,n越大分段的样本数量越少,分段之间数量差异带来的影响就会越来越大,总有一个n能让结果的误差大到无法忽略。
问题其实也好解决,因为我们知道始终会有一些分组的样本是多余的,我们只要保证分组里的样本数量一致就行,不需要关心具体剔除的样本是什么。假设我们采用向下取整的办法,那么会存在一些理论上应该在分段k上的样本跑到k+1的分组上,这些样本通常分布在分段的起始位置上,我们可以把这些样本拒绝采样,这样比较容易实现。这些样本乘以n之后会落在
[k*2⁶⁴, k*2⁶⁴+(2⁶⁴%n))
上。
剔除这些样本后,我们就能保证
x*n
在每个
[(k-1)*(2⁶⁴/n), k*(2⁶⁴/n))
上都是均匀分布的了。
思路理解了看代码也就不难了:
func (r *Rand) uint64n(n uint64) uint64 {
if is32bit && uint64(uint32(n)) == n {
return uint64(r.uint32n(uint32(n)))
}
if n&(n-1) == 0 { // n is power of two, can mask
return r.Uint64() & (n - 1)
}
hi, lo := bits.Mul64(r.Uint64(), n)
if lo < n {
thresh := -n % n // 2⁶⁴ % n 的简化形式
for lo < thresh {
hi, lo = bits.Mul64(r.Uint64(), n)
}
}
return hi
}
精髓在于利用
(x*n) >> 64
来避免了
x % n
带来的除法运算。而且新算法不用一开始就算余数,因此运气好的时候可以一次除法都不做。
还有一个小疑问,128位乘法够了吗?肯定够了,因为n最大也只能取到2⁶⁴,这意味这
x*n
的范围最大也只到
[0, 2⁶⁴·2⁶⁴)
,128位乘法刚好够用。
最后做下性能测试,标准库里已经提供了,在我的10代i5上旧算法一次调用需要18ns,新算法只需要5ns,两者使用的随机数发生器是一样的,因此可以说新算法快了3倍,提升还是很可观的。
从rand5生成rand7
上一节讨论了从更大的样本空间里筛选出特定特征的子集,这一节我们反过来:从范围更小的样本空间里派生出有某一特征的超集。
同时,这也是一道常见的中等难度的算法题。
首先要考虑的是如何把受限的样本空间尽量扩张。上一节我们用乘法来扩展了样本分布的范围,然而乘法尤其是乘以常数是没法增加样本数量的,因此这个做法只能pass。加法可以平移样本的范围,但也不能增加样本总量,而且我们需要样本空间是
[0, x)
平移之后起点都变了,因此也不行。
那剩下的可行的也最稳定的办法是
rand5() * rand5()
。它像乘法一样能扩张样本的范围,同时因为不是乘以常数因此还有机会产生新的样本。我们列个表看看:
|
rand5
|
rand5
|
rand5 * rand5
|
| 0 |
0 |
0 |
| 0 |
1 |
0 |
| 0 |
2 |
0 |
| 0 |
3 |
0 |
| 0 |
4 |
0 |
| 1 |
0 |
0 |
| 1 |
1 |
1 |
| 1 |
2 |
2 |
| 1 |
3 |
3 |
| 1 |
4 |
4 |
| 2 |
0 |
0 |
| 2 |
1 |
2 |
| 2 |
2 |
4 |
| 2 |
3 |
6 |
| 2 |
4 |
8 |
| 3 |
0 |
0 |
| 3 |
1 |
3 |
| 3 |
2 |
6 |
| 3 |
3 |
9 |
| 3 |
4 |
12 |
| 4 |
0 |
0 |
| 4 |
1 |
4 |
| 4 |
2 |
8 |
| 4 |
3 |
12 |
| 4 |
4 |
16 |
确实有新样本出现了,但不够连续,比如没有7和10。因此这条路是不通的。
这时候就要上原汁原味的拒绝采样算法了,我们使用
5 * rand5 + rand5
:
|
rand5
|
rand5
|
5 * rand5 + rand5
|
| 0 |
0 |
0 |
| 0 |
1 |
1 |
| 0 |
2 |
2 |
| 0 |
3 |
3 |
| 0 |
4 |
4 |
| 1 |
0 |
5 |
| 1 |
1 |
6 |
| 1 |
2 |
7 |
| 1 |
3 |
8 |
| 1 |
4 |
9 |
| 2 |
0 |
10 |
| 2 |
1 |
11 |
| 2 |
2 |
12 |
| 2 |
3 |
13 |
| 2 |
4 |
14 |
| 3 |
0 |
15 |
| 3 |
1 |
16 |
| 3 |
2 |
17 |
| 3 |
3 |
18 |
| 3 |
4 |
19 |
| 4 |
0 |
20 |
| 4 |
1 |
21 |
| 4 |
2 |
22 |
| 4 |
3 |
23 |
| 4 |
4 |
24 |
没错,正好产生了均等分布的0到24的整数。很神奇吧,其实想明白为什么不难。我们先看
5 * rand5
,这样或产生0、5、10、15、20这五个数字,我们要想有机会生成连续的整数,就一定需要把缺少的1到4,11到14这些数字补上。这时候正巧一个
+ rand5
就可以把这些缺的空洞全部填上。当然用进位来理解会更简单。
总结:
n * randn + randn
可以产生连续的范围在
[0, n*n)
的均匀分布的整数。注意这里没有结合律,因为randn每次的结果都是不一样的
这个样本空间是远超rand7的要求的,因此现在问题回到了第一节:如何从rand25生成rand7?现在大家都知道了:
func rand7() int {
x := 5*rand5() + rand5()
max := 25 - 25%7
for x >= max {
x = 5*rand5() + rand5()
}
return x % 7
}
你也可以改写成上一节说的更高效的做法。
充分利用每一个bit
rand.Uint64()
返回的随机数有足足64bits,而我们通常不需要这么大的随机数,举个例子,假如我们只需要0到15的随机数,这个数字只需要4bits就够了,如果用
rand.Uint64N(16)
来生成,我们会浪费掉60bits的数据。
为啥这么说?因为
rand.Uint64()
保证能概率均等的生成
[0, 2⁶⁴)
范围内的整数,这其实说明了两件事,第一是这个随机数的每一个bit也都是随机的,这个很明显;第二个是每个bits是0还是1的概率也是均等的,这个可以靠列表加归纳法得出。我们来看看第二点这么证明。
先假设我们有一个能均匀生成
[0, 8)
范围内数字的随机数发生器,现在我们看看所有可能的情况:
|
生成的数字
|
二进制表示
|
从左到右第一位
|
从左到右第二位
|
从左到右第三位
|
| 0 |
000 |
0 |
0 |
0 |
| 1 |
001 |
0 |
0 |
1 |
| 2 |
010 |
0 |
1 |
0 |
| 3 |
011 |
0 |
1 |
1 |
| 4 |
100 |
1 |
0 |
0 |
| 5 |
101 |
1 |
0 |
1 |
| 6 |
110 |
1 |
1 |
0 |
| 7 |
111 |
1 |
1 |
1 |
不难注意到,三个bit各有八种输出,0占四种,1占剩下四种,0和1的概率均等。这个结论能推广到任意的
[0, 2^n)
范围上。
同样,基于这个结论,我们还能得到这样一个结论,任意连续的n个bit,都能产生均匀分布在
[0, 2^n)
上的随机数,这个证明太简单了,所以我们集中注意力就行了。
现在回头看看为什么我说会浪费60bits,因为根据上面的结论,我们64位的随机整数完全可以按每四位划分一次,这样可以分成16组,而每组正好能产生
[0, 16)
范围内的随机数,且概率同样的均等的。也就是说一次
rand.Uint64()
理论上应该可以产生16个我们需要的随机数,但实际上我们只生成了一个。这里就有很大的提升空间了。
怎么做呢?我们需要一点位运算,把64位整数分组四位一组:
n := rand.Uint64()
mask := uint64(0xf) // 0b1111
for i := range 10 {
a[i] = int(n & mask) // 只让最右边四位有效(书写顺序的右边,这里不讨论大小端了因为说明起来太麻烦)
n >>= 4 // 把刚刚使用过的四位去掉
}
代码很简单,下面看看性能测试:
// 不要这样写代码
// 我这么做是为了避免内存分配和回收会对测试产生不必要的杂音
func getRand(a []int) {
if len(a) < 10 {
panic("length wrong")
}
for i := range 10 {
a[i] = int(rand.Int32N(16))
}
}
// 不要这样写代码
// 我这么做是为了避免内存分配和回收会对测试产生不必要的杂音
func getRandSplit(a []int) {
if len(a) < 10 {
panic("length wrong")
}
n := rand.Uint64()
mask := uint64(0xf)
for i := range 10 {
// 这里不需要mod
a[i] = int(n & mask)
n >>= 4
}
}
func BenchmarkGetRand(b *testing.B) {
var a [10]int
for range b.N {
getRand(a[:])
}
}
func BenchmarkGetRandSplit(b *testing.B) {
var a [10]int
for range b.N {
getRandSplit(a[:])
}
}
测试结果:
goos: windows
goarch: amd64
pkg: benchrand
cpu: Intel(R) Core(TM) i5-10200H CPU @ 2.40GHz
BenchmarkGetRand-8 15623799 79.31 ns/op 0 B/op 0 allocs/op
BenchmarkGetRandSplit-8 100000000 11.18 ns/op 0 B/op 0 allocs/op
充分利用每一个bit之后我们的性能提升了
整整6倍
。
到目前为止还不错,如果你不在乎生成的随机数的概率分布或者你只想生成
[0, 2^n)
范围的随机数且这个n可以整除64,那么可以直接跳到下一节继续看了。
接着往下看的人肯定是希望不管在什么范围内都能生成概率均匀的随机数且尽量多利用已生成的随机bits的。但事情往往不尽人意,比如,
[0, 13)
和
[0, 7)
就是两个例子。前者右边界不是2的幂,后者虽然是2的幂但3不能整除64。
我们先从简单的问题开始解决,
[0, 13)
。受先表示数字12至少得用4个bit,4能整除64,所以我们还可以每4个连续的bit分割成一组,但这时概率分布均匀的条件是满足不了的。无法保证的原因很简单,和我们第一节里说的“rand7生成rand5”的情况一样,每个均匀分割出来的一组连续的bits的组合里有我们不需要的样本存在。处理这个情况的方法在第一节里已经有表述了,那就是拒绝采样。确定拒绝的范围也使用第一节说到的办法,注意到每一组bits能生成
[0, 16)
的随机数,再考虑到13本身是素数,这里只需要简单地把≥13的样本全部剔除即可。
所以代码变成了下面这样:
func getRandSplit(a []int) {
if len(a) < 10 {
panic("length wrong")
}
mask := uint64(0xf)
count := 0
for {
n := rand.Uint64()
for i := 0; i < 16; i++ {
sample := int(n & mask)
n >>= 4
// 不符合要求后直接跳到下一组去
if sample >= 13 {
continue
}
// 这里也不需要mod
a[count] = sample
count++
if count >= 10 {
return
}
}
}
}
如果一组不满足采样要求,我们就跳过直接去下一组,因此有可能16组里无法获得足够的随机数,因此我们得重新获取一次64位的随机数,然后再次进入分割计算。这么做会对性能产生一点点负面影响,但依旧很快:
goos: linux
goarch: amd64
pkg: benchrand
cpu: Intel(R) Core(TM) i5-10200H CPU @ 2.40GHz
BenchmarkGetRand-8 16242730 72.22 ns/op 0 B/op 0 allocs/op
BenchmarkGetRandSplit-8 37794038 31.81 ns/op 0 B/op 0 allocs/op
这时候性能就只提升了一倍。
上面那种情况还是最简单的,但
[0, 7)
就不好办了。首先表示6需要至少3个bit,而3不能整除64,其次6也不是2的幂。这个怎么处理呢?
有两个办法,核心思想都是拒绝采样,但拒绝的范围有区别。
第一个想法是,既然3不能整除64,那我们选个能被3整除的,这里是63,也就是说超过
2⁶³-1
的样本全部丢弃,然后把符合要求的样本按每连续的3bits进行分割。这样我们先保证了3bits分割出来的每一组都能均等的生成
[0, 8)
范围内的随机整数。现在问题转化成了“rand8怎么生成rand7”,这题我们会做而且做了好多回了,最终代码会是这样:
func getRandSplit(a []int) {
if len(a) < 10 {
panic("length wrong")
}
// 注意,mask现在只要三位也就是0b111了
mask := uint64(0x7)
count := 0
for {
n := rand.Uint64()
// 先拒绝大于2⁶³-1的样本
if n > 1<<63-1 {
continue
}
for i := 0; i < 21; i++ {
sample := int(n & mask)
n >>= 3
// 一组bits如果组合出来的数大于等于7也拒绝采样
if sample > 6 {
continue
}
// 这里是不用mod的,因为产生的sample本身只会在0-6之间
a[count] = sample
count++
if count >= 10 {
return
}
}
}
}
代码变得很长也很复杂,而且需要两步拒绝采样,相对的我们一次也能分割出21组,比4bits的时候多了5组,所以难说性能下降还是不变,因此我们看看测试:
goos: linux
goarch: amd64
pkg: benchrand
cpu: Intel(R) Core(TM) i5-10200H CPU @ 2.40GHz
BenchmarkGetRand-8 16500700 73.77 ns/op 0 B/op 0 allocs/op
BenchmarkGetRandSplit-8 31098928 39.54 ns/op 0 B/op 0 allocs/op
确实慢了一些,但总体上还是提速了85%。
第二种想法只需要一步拒绝采样,既然3不能整除64,那么就找到一个离3最近的可以整除64且大于3的整数。在这里我们可以直接注意到4符合条件,实际开发中如果要找到任意符合条件的数,可以依赖一下线性探测。现在我们按连续的4位把64位随机整数分割,这样分割出来的每一组可以生成均匀分布在
[0, 16)
上的整数。然后问题变成了“从rand16生成rand7”。代码这样写:
func getRandSplit2(a []int) {
if len(a) < 10 {
panic("length wrong")
}
mask := uint64(0xf)
count := 0
for {
n := rand.Uint64()
for i := 0; i < 16; i++ {
sample := int(n & mask)
n >>= 4
if sample > 13 {
continue
}
// mod不能漏了,因为我们会产生大于等于7的结果
a[count] = sample % 7
count++
if count >= 10 {
return
}
}
}
}
代码简单了,也只需要一步拒绝采样就行,但问题在于每一组的生成范围变大导致我们不得不使用取模操作。看看性能怎么样:
goos: linux
goarch: amd64
pkg: benchrand
cpu: Intel(R) Core(TM) i5-10200H CPU @ 2.40GHz
BenchmarkGetRand-8 16451838 75.86 ns/op 0 B/op 0 allocs/op
BenchmarkGetRandSplit-8 30802065 39.15 ns/op 0 B/op 0 allocs/op
BenchmarkGetRandSplit2-8 38995390 30.75 ns/op 0 B/op 0 allocs/op
想法2比想法1快了近20%,看来两步拒绝采样成了硬伤,不仅仅是因为多获取几次64位随机数更慢,多出来的一个if还可能会影响分支预测,即便最后我们多了5组可以采样也无济于事了。
所以,当你需要的随机数范围比较有限的时候,充分利用每一个bit是非常理想的性能提升手段。
带有权重的随机数
讨论了半天概率均匀分布的情况,但业务中还有一种常见场景:一组样本进行采样,既要有随机性,又要样本之间在统计上尽量满足某些比例关系。
这个场景我想大家最先想到的应该是抽奖。是的没错,这是带权重随机数的常见应用。但还有一个场景,一个负载均衡器连接着一组权重不同的服务器硬件,现在想要尽量按权重来分配链接,这时候带权重随机数就有用武之地了。
假设我们有样本
(1, 2, 3, 4)
四个整数,然后要按
1:2:3:4
的比例来随机生成样本,该怎么做呢?
按比例,我们可以得到1,2,3,4生成的概率是0.1,0.2,0.3,0.4,这些概率加起来是一定等于1的,所以我们不妨来想象有一个数轴上的0到1的区间,然后我们把这些比例“塞进”数轴里:
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|
|_______________________|
4
|_____|
1
|_________________|
3
|___________|
2
我故意打乱了顺序,实际上顺序并不影响结果。每个样本可以有一个数轴上的范围,范围的长度之间也是符合比重的,因此当存在一个可以均匀生成
[0, 1)
之间所有实数的随机数生成器时,这个生成器生成的数落在哪个范围里,我们就选择生成这个范围对应的样本,举个例子,如果生成的实数落在
[0.0, 0.4)
这个区间里,那么就生成样本“4”,如果落在
[0.8, 1.0)
这个区间,就生成“2”。这样带权重的随机数就生成了。这个看上面那个图还是挺好理解的,我就不费笔墨去证明了。
但我不是很想用这个方法。为啥呢,因为你看到了,区间的左边是闭合的,这意味着要做浮点数的等值比较,虽然很简单,但我很懒不想多写,而且浮点数没法精确表示所有情况的比例导致我们区间的两端都有精度损失,这就需要考虑误差率,虽然通常这点精度损失带来的误差可以忽略不记(尤其是在统计意义上)但只是考虑到这点我就浑身难受了。
所以我要找一种不需要浮点数的解决方案。想出来其实不难,假设我们有0到9的整数,正好10个,现在样本“1”按比例需要占用其中1个样本,样本“4”按比例要占用其中四个样本,现在我们获得了一个能均匀生成0到9的整数的随机数生成器,那只要生成的随机数正好是样本“4”占用的那几个随机数我们就生成“4”,生成的随机数是样本“1”占用的那就生成“1”。可以看到只要占够一定数量的不同的样本,那么我们一样能生成带权重的随机数。
下面有几个问题,一是样本总数怎么确定,这个简单,每个比例当成整数相加即可,比如
1:2:3:4
就是
1+2+3+4=10
,
2:2:3:5
就是
2+2+3+5=12
,依此类推。如果比例是实数呢?
2.3 : 3.4 : 4.7
怎么办?这就要用到比例的性质了,等比扩大后比例不变,所以我们每个实数都乘以10,然后去掉小数点后的0全部当成整数,所以
23+34+47=104
,理论上任意比例都能这么整,不过整数最终有大小限制的,你总不能生成个随机数还用
big.Int
吧,所以注意总和别超过整数范围限制。
二是样本的范围怎么算,虽然我们只需要不相同的满足1里总数的离散的点就行,但为了方便计算我们还是选择连续的整数比较好,所以范围限定为
[0, sum-1]
。这样我们能直接利用
rand.Uint64N()
来生成需要的随机数生成器。
最后我们只要让样本按比例随机占领一些连续的整数就行了。而且我们只需要记录右边界就够了,我们从范围是
[0, n]
的第一个样本开始比较,如果生成器给出的随机数小于等于某个右边界,那它一定落在边界代表的样本上(因为是从最小的边界开始比较的,所以随机数必然不可能落在前一个范围的样本上)。
其实就是把连续的实数换成了离散的整数点罢了,换汤不换药。
搞明白思路后代码写起来就是快:
type WeightRandom[T comparable] struct {
entries []entry[T]
upperBoundary uint64
}
type entry[T comparable] struct {
value T
end uint64
}
首先是数据结构,
WeightRandom
是我们的带权重随机数生成器,
upperBoundary
是样本数量的总和,
entries
则是各个样本和样本占领的连续整数的右边界。
接着来看构造
WeightRandom
对象的方法:
func NewWeightRandom[T comparable](rndMap map[T]uint64) *WeightRandom[T] {
var lowerBoundary uint64
entries := make([]entry[T], 0, len(rndMap))
for k, v := range rndMap {
if v == 0 {
panic("weight cannot be zero")
}
if lowerBoundary+v < lowerBoundary {
panic("overflow")
}
lowerBoundary += v
entries = append(entries, entry[T]{
value: k,
end: lowerBoundary,
})
}
slices.SortFunc(entries, func(a, b entry[T]) int {
return cmp.Compare(a.end, b.end)
})
if len(entries) == 0 {
panic("no valid sample")
}
return &WeightRandom[T]{
entries: entries,
upperBoundary: lowerBoundary,
}
}
lowerBoundary
用来统计有多少样本,我们最终选择了左闭右开的区间,这样方便算。
rndMap
的key是样本,value则是比例。当样本的范围计算并保存结束之后,我们需要按照右边界从小到大排序这些样本,因为后面的查找范围到样本的对应关系需要右边界满足从小到大的顺序。
最后是查找函数:
func (w *WeightRandom[T]) RandomGet() T {
x := rand.Uint64N(w.upperBoundary)
for i := range w.entries {
if x < w.entries[i].end {
return w.entries[i].value
}
}
panic("not possible")
}
查找时先生成一个范围在
[0, upperBoundary)
之间的随机数,然后我们从最小的边界开始逐一比较,一旦发现比自己大的边界,那么就说明需要生成边界对应的样本。底部那句panic如字面意思,理论上是执行不到的,但go不知道,我们要么返回个空值要么panic,考虑到能走到这里那说明我们的程序或者标准库的代码有重大bug,panic了去调试才是比较好的办法。
根据upperBoundary的大小,实际上我们还能复用上一节充分利用每一个bit的办法,不需要每次都生成新的随机数,等分割出来的分组都消耗完了再生成,这样可以大大加速这个函数。不过为了通用性和尽量简化代码,我就不这样写了。
最后附加一个用例:
func main() {
w := NewWeightRandom(map[string]uint64{
"a": 15,
"b": 30,
"c": 45,
"d": 60,
})
m := make(map[string]int, 4)
const limit = 100_0000_0000
for range limit {
m[w.RandomGet()]++
}
for k, v := range m {
fmt.Printf("key: %s, count: %d, p: %g\n", k, v, float64(v)/limit)
}
}
我们按权重生成“abcd”四个字母,比例是
15:30:45:60
,简化一下就是
1:2:3:4
,所以理论上概率应该接近10%,20%,30%和40%。不过统计上的概率总是有点误差的,只要大致趋势接近于这个比例就行了。我们运行100亿次来看看结果:
$ go run main.go
key: b, count: 2000011606, p: 0.2000011606
key: a, count: 1000058297, p: 0.1000058297
key: d, count: 3999943022, p: 0.3999943022
key: c, count: 2999987075, p: 0.2999987075
非常符合预期。作为一项优化措施,我们可以利用类似二分查找的办法来定位样本,因为右边界本身是有序的,这可以显著改善在有大量样本时的性能表现。不过如果你的样本不超过10个的话我觉得现在这样的线性查找就足够了。
怎么说呢,简单粗暴但有效解决了问题。只是和浮点数的方案比还是有缺点的:
- 因为整数有范围限制,这导致了样本总量会被限制在一个比浮点数方案更小的范围内
- 同样因为整数大小限制,比例的选择范围会比浮点数更小
因为限制更少,所以在通用的工具库里用浮点数方案的人更多,但业务场景和通用工具库是不一样的,很多时候选整数方案也没啥问题,最终你应该选择一个符合业务需求并且自己和同事都看得懂的方案。
至于性能怎么样,浮点数方案的查找过程和整数方案是一样的,性能需要做一次完整的测试才能看出孰高孰低,我不好在这凭空幻想。当然测试我就不做了,我偷个懒。
随机数种子
“种子”其实是指一些伪随机数生成算法需要的一些初始状态,这些算法会根据初始状态来生成一系列有随机性的数值序列。
所以相同的种子通常会带来相同的序列,这时候虽然每个序列都有随机性,但两个序列之间是没有随机性的——有了其中一个序列就可以精准预测另一个序列的排列。具体表现很可能会是你编写了一个游戏,其中敌人会随机采取一些行动,然而因为种子没设置好,导致每次见到这个敌人的时候它都会采取一模一样的行动步骤,这样的游戏是极其无聊的。
不仅如此,产生相同的数值序列后还会带来无数安全问题。
种子通常只用设置一次,并且在程序第一次需要随机数的地方设置——理想情况是这样的,然而总是有倒霉蛋忘记了这一点,于是随机算法经常只能使用默认的低质量且相同的种子。所以比较现代的语言,比如go1.22和python3都选择了在程序刚开始运行的时候帮你自动设置种子。
此外我们还得担心一下种子的质量。
“种子”的值需要每次获取都不一样,符合要求的常见种子来源有以下几种:
- 使用系统时间。这个确实每次获取都不一样,获取速度也很快,是很多开发者和库的默认选项。但是系统时间是可以修改的,而且世界上还有闰秒这个麻烦东西,你意外得到相同的系统时间的概率其实不低。
- 使用随机设备,这些是软件模拟出来的随机数生成器,以Linux为例,有
random
和
urandom
两种,其中
random
以操作系统及外部环境的噪音为数据源产生随机值,要求不高时我们可以认为这是“真随机”,当然它的生成速率是比较低的;另一个是
urandom
,它会用外部噪音生成一个初始状态,然后基于这个状态用伪随机数算法快速产生随机值,因此它的生成速率高但质量低。一般使用urandom生成种子是够用的。
- 使用产生真实随机数的硬件,原理和软件模拟的类似,和大多数软件实现转硬件实现后会性能提升不同,TRNG反而可能会有更低的性能,但相比软件实现它可以更精细地收集环境里的杂音从而生成实验证明的不可预测的高质量的随机数。常见的TRNG生成速率从数百k/s到数兆/s的都有,但像
/dev/random
通常速率可以有数兆到数十兆/s。除了性能上的不稳定,不是所有设备都包含TRNG,这导致了适用面受限,所以直接用它的人不多。不过很多依赖高质量随机数的场景就不得不考虑TRNG了。
- 利用地址空间布局随机化。现代操作系统在加载程序后都会给程序的内存地址加点随机的偏移量,所以程序每次运行的时候获取的变量地址基本都是不同的。这个是成本极低的获取随机值的方法,几乎不花费运行时代价,谷歌的abseil库里就有很多用这个方法获取随机数种子的代码。然而,使用这个方法的前提是你的系统要支持地址空间布局随机化,其次系统加的随机偏移量质量要尚可,这两个我们都控制不了,我们只能相信常用操作系统都做到这几点了。另外,高权限的程序和用户始终能把一些代码写进有固定地址的地方,虽然这种操作正变得越来越难,但还不是完全不可能,所以需要高质量种子的时候这个方案通常不会被考虑(另一个原因是有的系统可以配置关闭随机化布局甚至根本不支持随机化)。
- auxiliary vector。Linux特有的,可以通过
/proc/<pid>/auxv
或者glibc的函数
getauxval
来获取。这个数组包含一系列操作系统和当前进程的信息,全部是操作系统在程序加载时写入的,Windows有类似的东西。这些数据中有些是不变的比如硬件信息和平台信息,有些则是完全随机的,比如其中有程序的入口地址和vDSO的地址,这些因为ASLR的缘故都是完全随机的,另外auxv里还有专门的随机值字段,这些信息加一起比单纯依赖ASLR能带来更强的不可预测。
原则就是尽量让预测结果的难度增加,最好是能做到完全不可预测。
那作为开发者我用啥呢?一般来说系统时间是够用了,自己写着完或者做些简单工具可以用这个,不过要记住系统时间是可修改的不可靠的。如果是库或者对随机性依赖比较重的比如游戏,
/dev/urandom
是个比较理想的选择。追求极致性能并且对种子质量要求没那么高时,像谷歌那样利用ASLR带来的随机值也是可以的。
实在有选择困难症的话,我们来看看别人是怎么做的。
golang和python3选择了那些源作为种子
golang实际上是先利用auxv,如果系统不支持,就回退到从urandom之类的随机设备读取随机值,这个也出问题了就使用系统时间:
// runtime/rand.go
// OS-specific startup can set startupRand if the OS passes
// random data to the process at startup time.
// For example Linux passes 16 bytes in the auxv vector.
var startupRand []byte
func randinit() {
lock(&globalRand.lock)
if globalRand.init {
fatal("randinit twice")
}
seed := &globalRand.seed
// 查看是否有auxv信息被系统写入
if startupRand != nil {
for i, c := range startupRand {
seed[i%len(seed)] ^= c
}
clear(startupRand)
startupRand = nil
} else {
// 先从urandom读取
if readRandom(seed[:]) != len(seed) {
// readRandom should never fail, but if it does we'd rather
// not make Go binaries completely unusable, so make up
// some random data based on the current time.
readRandomFailed = true
readTimeRandom(seed[:])
}
}
globalRand.state.Init(*seed)
clear(seed[:])
globalRand.init = true
unlock(&globalRand.lock)
}
这个是全局函数的设置,go还能自己创建
rand.Source
,这个的种子只能显式传进去,这时候传什么go就没法管了,灵活的同时牺牲了一定的安全性。
Python3则是先读取urandom,失败后会结合系统时间加当前进程pid来生成种子,这样比单使用系统时间要强:
// https://github.com/python/cpython/blob/main/Modules/_randommodule.c#L293
static int
random_seed(RandomObject *self, PyObject *arg)
{
int result = -1; /* guilty until proved innocent */
PyObject *n = NULL;
uint32_t *key = NULL;
size_t bits, keyused;
int res;
// 参数为空的时候
if (arg == NULL || arg == Py_None) {
if (random_seed_urandom(self) < 0) {
PyErr_Clear();
/* Reading system entropy failed, fall back on the worst entropy:
use the current time and process identifier. */
if (random_seed_time_pid(self) < 0) {
return -1;
}
}
return 0;
}
// 参数不为空的时候根据参数生成种子
Done:
Py_XDECREF(n);
PyMem_Free(key);
return result;
}
然后这个函数会被Random对象的
__init__
方法调用,如果初始化一个Random对象但不传seed参数,那么就会进行默认设置。而random模块里所有的方法其实都是由一个全局的
Random()
对象提供的,因为没传seed进去,所以代码里会自动设置seed:
# https://github.com/python/cpython/blob/main/Lib/random.py#L924
_inst = Random()
seed = _inst.seed
random = _inst.random
uniform = _inst.uniform
triangular = _inst.triangular
randint = _inst.randint
choice = _inst.choice
randrange = _inst.randrange
sample = _inst.sample
shuffle = _inst.shuffle
choices = _inst.choices
normalvariate = _inst.normalvariate
lognormvariate = _inst.lognormvariate
expovariate = _inst.expovariate
vonmisesvariate = _inst.vonmisesvariate
gammavariate = _inst.gammavariate
gauss = _inst.gauss
betavariate = _inst.betavariate
binomialvariate = _inst.binomialvariate
paretovariate = _inst.paretovariate
weibullvariate = _inst.weibullvariate
getstate = _inst.getstate
setstate = _inst.setstate
getrandbits = _inst.getrandbits
randbytes = _inst.randbytes
这样python就防止了用户忘记设置seed的问题。
总结
关于随机数要讲的暂时就这么多了,除了一丁点数值算法之外都是些比较浅显易懂的东西。
概率和统计对程序设计的影响是很大的,所以我觉得与其花时间看最近比较火的微分方程,稍微抽出点时间看看概率统计对自己的帮助可能更大。
最后,其实标准库还有各种第三方库已经贴心准备了几乎全套功能了,看懂文档就能放心用,而且我也更推荐用这些库,开源的且久经检验的代码始终是比自己闭门造车来的强。
参考
https://stackoverflow.com/questions/18394733/generating-a-random-number-between-1-7-by-rand5
https://en.wikipedia.org/wiki/Rejection_sampling
https://www.linuxquestions.org/questions/linux-kernel-70/what-does-proc-pid-auxv-mean-exactly-4175421876/