SpringBoot2.7还是任性的,就是不支持Logback1.3,你能奈他何
开心一刻
今天上午,同事群中的刘总私聊我
刘总:你来公司多久了
我:一年了,刘总
刘总:你还年轻,机会还很多,年底了,公司要裁员
刘总语重心长的继续说到:以后我们常联系,无论以后你遇到什么困难,找我,我会尽量帮你!
我:所以了,我是被裁了吗,呵,我爸知道吗?
刘总:知道,今天上午保安部已经出名单了,你爸也在里面
我:我妈知道吗?
刘总:保洁也裁
我:刘总,你做这些事情问过我爷爷吗?
刘总:门卫也裁
我心里咯噔一下,这它妈哒团灭了呀

安全漏洞
公司的测试部门会定期扫描代码,检测出安全漏洞,导出
Excel
放到群里,各个项目的负责人针对性去修复(升级组件版本),因为某些原因不能修复的,需要给出原因(有些组件版本依赖更高的
JDK
版本,而
JDK
又不能升)。而我负责的项目是基于
Spring Boot 2.7.18
,它依赖的
logback
版本是
1.2.12
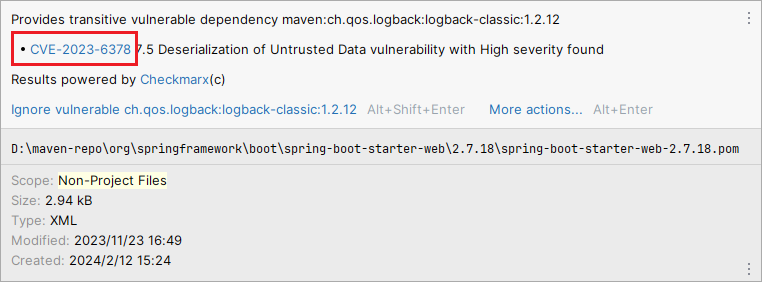
,存在安全漏洞
CVE-2023-6378
我本意是非常拒绝修这玩意的,修的时候得评估影响点,测的时候需要都覆盖到;核心组件的升级不亚于一次重构,开发和测试都得全量测。重点是,修好不算产出,修坏了可是要背锅的,我可是经历过血的教训的:
都说了能不动就别动,非要去调整,出生产事故了吧
,总之还是那句话
能不动就不要动,改好没绩效,改出问题要背锅,吃力不讨好,又不是不能跑
纵使我有万般的不愿,但也不得不修,公司对安全漏洞这一块非常重视,毕竟要给客户留下非常专业的形象。既然避无可避,那就坦然接受,充分评估影响点,做好全面的测试

漏洞修复
如何修复,想必大家都知道,剔除掉
spring-boot-starter-logging
依赖,引入新版本依赖,如下所示
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<artifactId>spring-boot-starter-logging</artifactId>
<groupId>org.springframework.boot</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
升级到哪个版本,就值得仔细斟酌一番了。反正都要升级,那何不升级到最新版?安全漏洞少,甚至暂时没漏洞。那也不是,因为
logback
依赖
JDK
版本,
官方
说明如下

因为项目依赖的
JDK
版本是 8,所以我们将
logback
升级到 1.3 的最新版是最合适的;
logback 1.3.x
依赖的
SLF4J
版本是
2.0.x
,所以最终
pom.xml
调整成如下
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<logback.version>1.3.14</logback.version>
<slf4j.version>2.0.7</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<artifactId>spring-boot-starter-logging</artifactId>
<groupId>org.springframework.boot</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
</dependencies>
貌似挺简单的,对吧?编译也不报错,一切都很顺利;一旦你运行,最烦人的
bug
就来了
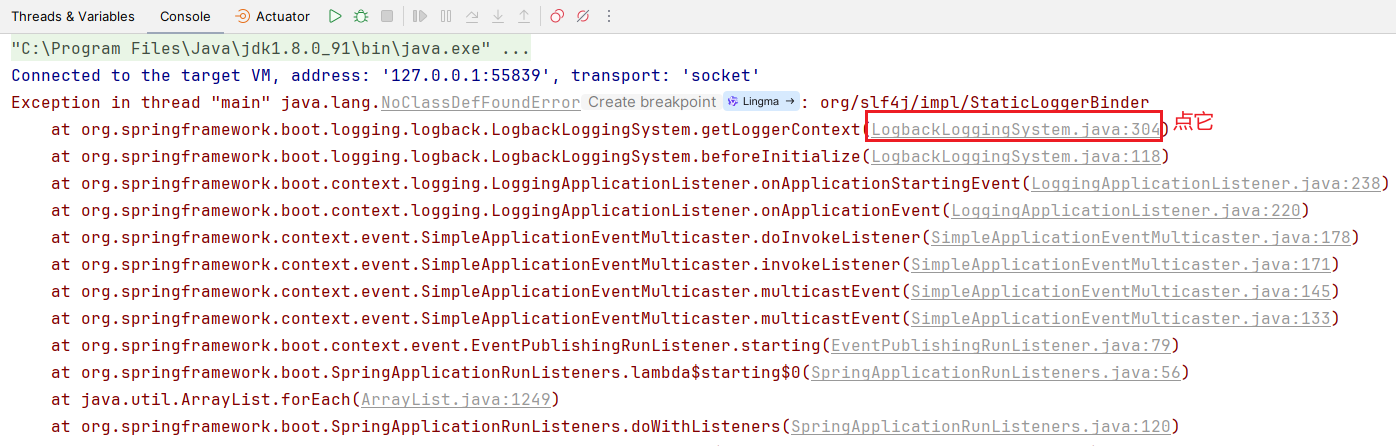
Exception in thread "main" java.lang.NoClassDefFoundError: org/slf4j/impl/StaticLoggerBinder
at org.springframework.boot.logging.logback.LogbackLoggingSystem.getLoggerContext(LogbackLoggingSystem.java:304)
at org.springframework.boot.logging.logback.LogbackLoggingSystem.beforeInitialize(LogbackLoggingSystem.java:118)
at org.springframework.boot.context.logging.LoggingApplicationListener.onApplicationStartingEvent(LoggingApplicationListener.java:238)
at org.springframework.boot.context.logging.LoggingApplicationListener.onApplicationEvent(LoggingApplicationListener.java:220)
at org.springframework.context.event.SimpleApplicationEventMulticaster.doInvokeListener(SimpleApplicationEventMulticaster.java:178)
at org.springframework.context.event.SimpleApplicationEventMulticaster.invokeListener(SimpleApplicationEventMulticaster.java:171)
at org.springframework.context.event.SimpleApplicationEventMulticaster.multicastEvent(SimpleApplicationEventMulticaster.java:145)
at org.springframework.context.event.SimpleApplicationEventMulticaster.multicastEvent(SimpleApplicationEventMulticaster.java:133)
at org.springframework.boot.context.event.EventPublishingRunListener.starting(EventPublishingRunListener.java:79)
at org.springframework.boot.SpringApplicationRunListeners.lambda$starting$0(SpringApplicationRunListeners.java:56)
at java.util.ArrayList.forEach(ArrayList.java:1249)
at org.springframework.boot.SpringApplicationRunListeners.doWithListeners(SpringApplicationRunListeners.java:120)
at org.springframework.boot.SpringApplicationRunListeners.starting(SpringApplicationRunListeners.java:56)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:299)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1300)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1289)
at com.qsl.Application.main(Application.java:15)
Caused by: java.lang.ClassNotFoundException: org.slf4j.impl.StaticLoggerBinder
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 17 more
此时,你们会怎么办?本着快速解决
bug
的原则,我们也只能上网查问题
java.lang.ClassNotFoundException: org.slf4j.impl.StaticLoggerBinder
看能不能找到解决办法;可一通查下来,各种尝试,该问题都得不到解决,除非将
logback
版本降到
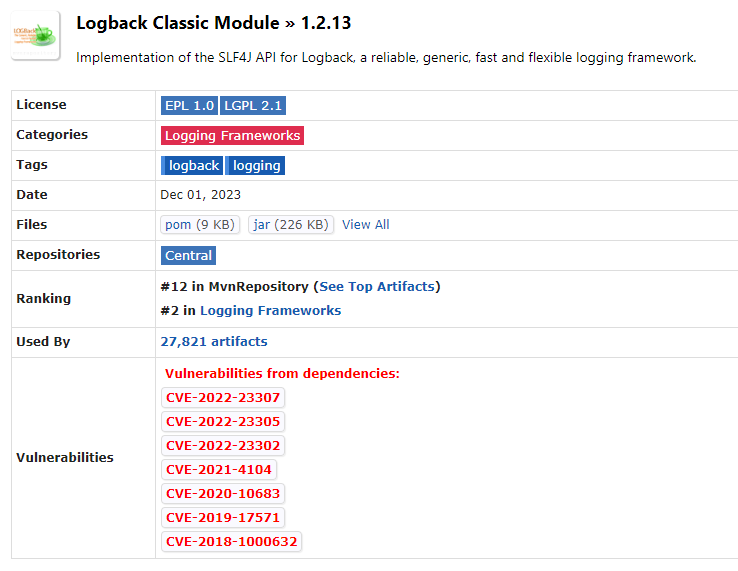
1.2.x
,可最新的
1.2.13
是有不少安全漏洞的
那没别的办法了,只能去追查问题产生的原因了,找到原因就好对症下药了。问题又来了,如何去查原因了,最直接、最有效的办法就是从异常堆栈信息入手
鼠标左击
LogbackLoggingSystem.java:304
,然后就来到
spring-boot-2.7.18
的源码
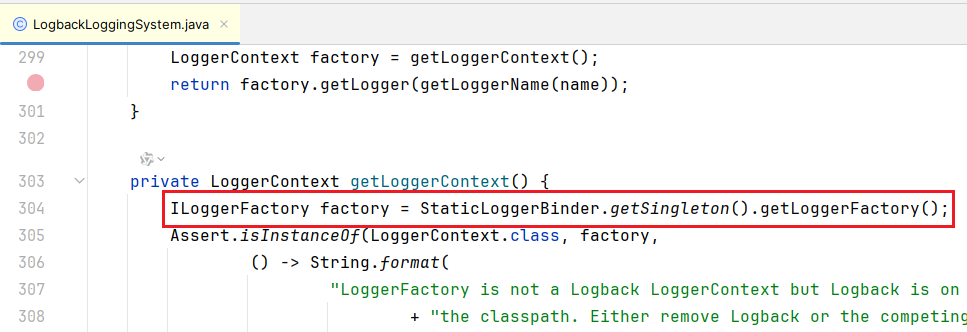
这里用到了
StaticLoggerBinder
,在往上滑到
LogbackLoggingSystem
的
import
部分,
StaticLoggerBinder
的全类路径是
org.slf4j.impl.StaticLoggerBinder
logback 1.2.12
是有这个类的
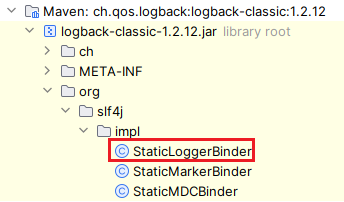
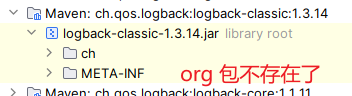
但
logback 1.3.14
不仅没有该类,连
org
包都不存在了
所以,原因是不是找到了?
spring-boot-2.7.18 依赖 org.slf4j.impl.StaticLoggerBinder,而 logback 1.3.14 没有该类
那如何对症下药了?不仅你们懵,我也懵

调整下思路,这个问题我们肯定不是第一个遇到的,对吧,肯定有人在
spring-boot
的官方提问,我们去搜搜
org/slf4j/impl/StaticLoggerBinder
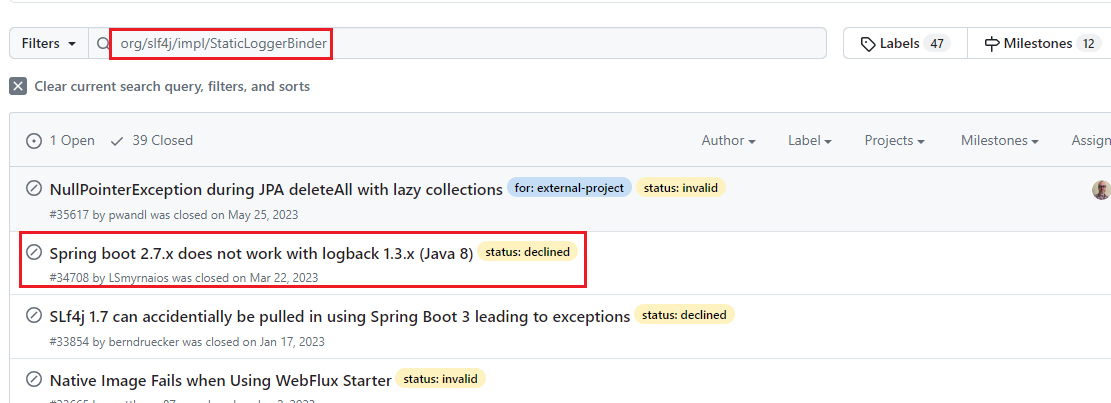
点进去
,里面有官方人员给出的答复,我给大家翻译一下;提问者是
LSmyrnaios
,他做了一下背景介绍
logback 1.3.x 基于 Java 8,1.4.x 基于 Java-11,而 Spring Boot 只在 3.x.x 中集成了 logback 1.4.x(基于 Java-11)
Java-8 用户被遗忘了
根据 logback 文档说明,logback 同时维护 1.3.x 和 1.4.x,也就是说,logback 1.3.x 是 '活跃的',Spring Boot 2.7.x 应该集成它
请考虑以下案例:
我有一个Java-8应用程序,使用 logback v.1.3.6,运行没问题
现在,我想将该应用程序集成到 Spring Boot v.2.7.9,运行的时候胞如下错误:
(异常堆栈跟我们遇到的一样,不展示了)
看起来像是 Spring Boot 用的 slf4j 1.7.x,但是 logback 1.3.x 用的 slf4j 2.0.x,所以 StaticLoggerBinder 类不见了
所以,你们能够在 Spring Boot >= 2.7.x and < 3 的版本中支持 logback 1.3.x 吗
先谢谢了.
这么看来,这哥们遇到的问题跟我们的一样,提出的诉求也跟我们一样,是不是看到了希望?
官方人员
scottfrederick
给出了回复
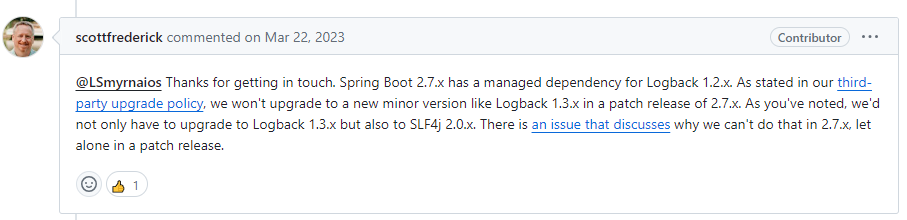
翻译过来就是
LSmyrnaios 感谢你的联系。 Spring Boot 2.7.x 依赖 Logback 1.2.x。 已经在
第三方升级政策
中说明过了,我们不会在 2.7.x 的版本中升级 Logback到 1.3.x。正如你提到的,我们不仅仅要升级 Logback 到 1.3.x,还需要将 SLF4J 升级到 2.0.x,这有一个关于我们为什么不在 2.7.x 升级的
讨论
,所以我们做补丁发布
第三方依赖升级说明如下

简单点来说就是:第三方依赖的补丁级别的修复,可以在
Spring Boot
的补丁版本中升级,而第三方依赖的次要或者主要版本的升级,则只能在
Spring Boot
的次要或主要版本中升级。不能在
Spring Boot
的补丁版本中升级第三方依赖的次要或者主要版本。这里的补丁版本可以理解成小版本,也就是
1.2.x
中的
x
,而次要或者重要版本,则是
1.x.x
中的第一个
x
,也就是我们所说的大版本
关于
scottfrederick
,他可不是
Spring Boot
的普通
Contributor
,人家可是榜六大哥
他说的还是很有权威的;关于他提到的
讨论
,我们后面在看,先把当前的看完。提问者
LSmyrnaios
又说了
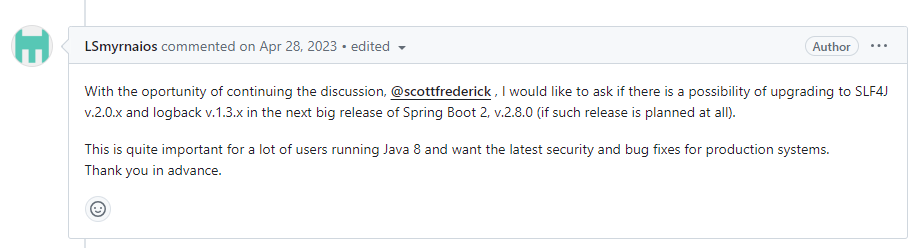
翻译过来就是
scottfrederick,我们接着刚刚的讨论,我想问的是,是否有可能在 Spring Boot 的下一个大版本(比如 2.8.0,如果在计划中的话)将 SLF4J 升级到 2.0.x,logback 升级到 1.3.x
这对于大量的 Java 8 用户来说非常重要,他们希望为生产系统提供最新的安全和错误修复
先谢谢了
scottfrederick
说的就很符合我们的期望,我们接着往下看。
wilkinsona
给出了回复

翻译过来就是
目前没有 Spring Boot 2.8 的计划
言简意赅,弦外之音就是
Spring Boot 2.x.x
就是不支持
Logback 1.3.x
,满满的任性感。你们是不是很好奇这任性的哥们是谁?人家可是
Spring Boot
的榜一大哥!!!
是不是觉得他任性的理所当然了?我们继续往下看,
ASarco
说了一句

翻译过来就是
现在的问题是 logback 1.2.12 存在安全漏洞 cve-2023-6378,对于 2.7.x 的煞笔用户却没有一个结论
这哥们表达了自己得愤懑,都直接飙国粹(
SB
)了,那是相当的气愤呀
SB 是 Spring Boot 的简写,并非国粹,大家别被误导了!!!
针对
ASarco
的问题,后面有人给了回复,可以升级
Logback
到
1.2.13
来修复漏洞
cve-2023-6378
,而我们也没得选了,只能将
Logback
从
1.3.14
降到
1.2.13
,最终的
pom.xml
如下所示
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<logback.version>1.2.13</logback.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<artifactId>spring-boot-starter-logging</artifactId>
<groupId>org.springframework.boot</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
</dependencies>
所以,
1.2.13
的安全漏洞仍是存在的,下次扫描出来后我们直接说明如下
修复不了,Spring Boot 2.7.x 官方不打算支持 Logback 1.3.x,除非升级 Spring Boot 到 3.x.x(集成的是 Logback 1.4.x),但同时需要将 JDK 升级到 11
讨论
还记得前面提到的那个
讨论
吗,因为比较长,我挑一些重点给大家翻译下
1、
wilkinsona
提到了
Logback
的一次
commit
,这次提交移除了
StaticLoggerBinder

从
1.3.0-alpha0
版本就移除了
StaticLoggerBinder
,所以
Spring Boot 2.7.x
不能集成
Logback 1.3.x
的任何一个版本
2、
snicoll
(榜二大哥) 提到了一个很重要的点
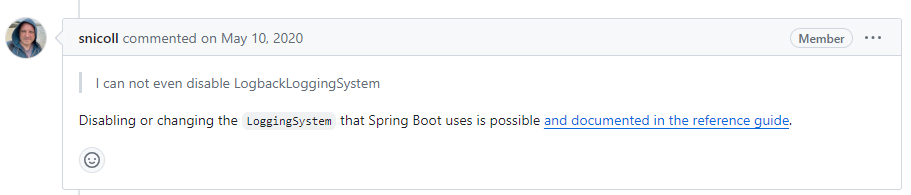
Spring Boot
的
LoggingSystem
是可以禁用或者改变的
-Dorg.springframework.boot.logging.LoggingSystem=none
3、
wilkinsona
提到了
spring.factories
中的
ApplicationListener
,其优先级高于
org.springframework.boot.context.logging.LoggingApplicationListener
,可以用来设置系统属性以响应
ApplicationStartingEvent
4、
wilkinsona
针对
cmuchinsky
提出的
对于 spring boot 2.7,是否有可能更新 ogbackLoggingSystemlogback 来兼容 Logback 1.3 与 1.2,例如反射
给出了回答,他认为这不太可能,支持
Logback 1.4
所需的更改范围太广,无法通过反射并行支持 1.2 和 1.3/1.4
5、
zhaolj214
通过读源代码,找到了一种解决方案
@SpringBootApplication
public class Spring5Application {
public static void main(String[] args) {
System.setProperty("org.springframework.boot.logging.LoggingSystem", "none");
SpringApplication.run(Spring5Application.class, args);
}
}
至于正确与否,我们下篇再试
6、
wilkinsona
说明了可以自定义日志:
howto.logging
总结下来就是:针对
Spring Boot 2.7.x
,官方不会支持
Logback 1.3.x
,但还是可以通过自定义的方式去支持
Logback 1.3.x
,具体如何自定义,以及效果如何,且听下回分解
总结
Logback
1.3 依赖 JDK 8,1.4 依赖 JDK 11;
Spring Boot
2.7.x 依赖
Logback 1.2.x
,而 3.x.x 依赖
Logback 1.4.x
。也就说
Spring Boot
跳过了
Logback 1.3.xSpring Boot
官方也给出了答复,根据第三方依赖政策(小版本升级小版本,大版本升级大版本),2.7.x 不会支持
Logback 1.3.x
,而 3.x.x 索性直接支持
Logback 1.4.x- 非要
Spring Boot 2.7.x
支持
Logback 1.3.x
也不是不可以,需要调整配置,还存在一些限制,具体细节请看下篇