攻坚克难岁月长,自主腾飞世界强——回顾近代中国数据库的发展与飞跃
前言
最近看了
《中国数据库前世今生》纪录片
,感触颇深,也是一直在思考到底该用何种方式起笔*回顾这段筚路蓝缕却又充满民族自豪感的历程。大概构思了一*左右吧,我想,或许还是应该从那个计算机技术在国内刚刚萌芽的年代开始讲起,那时的一切都显得那么原始而纯粹,一群怀揣梦想的科研人员,在资源匮乏、条件艰苦的环境中,凭借着对知识的渴望和对国家的忠诚,开启了中国数据库从无到有的艰难探索。
资料有限,未尽之处,敬请谅解。
萌芽阶段—信息技术的曙光与基础建设(50~70年代)
或许有朋友会很奇怪,为何我要从50年代开始写起呢?我给出的答案是”
虽然这个时代看似与数据库技术的起步相隔甚远,但是,却早已悄然埋下了中国信息技术革命的种子,奠定了后*数据库发展的基础土壤。
“
根据目前收集到的资料,中国的信息化最早应该起步于
1956
年。
1956年,在***总理的亲自主持下,制定了我国《十二年科学技术发展规划》,选定计算机、电子学、半导体、自动化四项,作为科学规划的四项紧急措施。根据《十二年科学技术发展规划》,开始了我国计算机事业的创建工作。罗沛霖院士说:“为什么会成为‘紧急措施’,原因是在科学规划制定中有所忽略,直到***总理发现,首批*华的18位苏联国家级专家中居然有6位是通信、电子、计算机专家,才指出了《十二年规划》偏重传统产业的问题。”1957年7月,清华大学首批计算机专业有杨天行等几十人毕业。同期,北京大学创办了计算数学专业和软件训练班。哈军工、哈工大等相继培养了计算机专业本科生、研究生。总体概括,我国在上世纪50年代,培养计算机学科人才总数达300余人,后*大多成为我国信息化的栋梁之材。
而那时,国内对于计算机的认知几乎是一片空白,不知道什么是计算技术,也不明白何为数据,大部分学者压根就没有见过计算机。
1958
年8月1日,在前苏联的帮助下,第一台计算机
103机
交付使用,据考证,当时这台计算机运行速度仅有每秒30次,但这仍然
标志着我国第一台电子计算机的诞生
。
103机是中国制造的第一种通用数字电子计算机,为电子管小型计算机。该型机是在苏联提供的M-3小型电子计算机图纸的基础上研制的,研制工作由中国科学院计算技术研究所和北京有线电厂(国营738厂)承担。1958年8月,第一台103机在中科院计算所初步调试成功,这标志了中国第一台计算机的诞生。103机最早使用磁鼓存储器,后又增配了磁芯存储器。使用磁鼓存储器时,103机运算速度约为每秒30次;使用磁芯存储器时,运算速度约为每秒1500至2000次。130机研制项目项目负责人为莫根生、张梓昌,骨干有董占球、王行刚等人,另有苏联专家指导。1959年起103机被用于一些科学计算,如人民大会堂主席台的力学结构计算便是由103机完成的。

时隔一年多,
1959
年9月,根据前苏联有关计算机技术资料制成的
104
大型通用电子计算机通过试运算,运算速度提升到每秒1万次,
正式宣告我国第一台大型通用电子计算机试制成功
。
在
1960
年4月,我国第一台
自行设计
的小型通用电子计算机
107机
研制成功;
1964
年,我国第一台自行设计的大型通用数字电子管计算机
119机
研制成功,标志着我国独立自主发展计算机事业进入了一个新阶段。同时,研究人员还自主研制了当时具有国际水平的我国最早的实用高级程序设计语言BCY,并在119机上实现了其编译系统。利用BCY语言及其编译系统,在119机上完成了东方红一号卫星的轨道模拟计算。
在研制第一代电子管计算机的同时,我国也开始着手研制第二代晶体管计算机。
1964
年11月,研制成功我国第一台晶体管通用电子计算机
441-B
机。441-B机是在当时外部条件十分困难的情况下使用国产半导体元器件研制的。
1965
年又研制成功我国第一台大型晶体管通用数字计算机109乙机,广泛应用于国民经济和国防部门。
为服务“两弹一星”工程,在109乙机的基础上,
1967
年又推出在技术上更加先进、更加成熟的109丙机。这台机器服务国防事业长达15年,为我国核武器研制作出了卓越贡献,被誉为“功勋计算机”。
回望从1956年到1966年的社会主义革命和建设时期,在计算机认知几乎为零的背景下,仅仅数年间,我国不仅拥有了自己的计算机,还踏入了自行设计的门槛,不可不谓之“
奇迹
”了,这,也为后续数据库技术的孕育奠定了极为重要的物质与技术基础。
起步阶段—数据库概念的引入及初步探索(70~80年代)
70年代,
国外
数据库的发展可谓是如日中天。
关系型数据库之父埃德加·考特(Edgar Frank Codd)在美国发表《用于大型共享数据库的关系数据模型》这篇划时代的论文,不仅彻底颠覆了数据管理的传统模式,还为全球数据库技术的发展指明了新的方向。
到70年代末期,国外的数据库技术基本完成了从实验室到科技商用产品的市场化历程,数据库从网络型和层次型数据库过渡到
关系型
数据库。
但是,由于冷战的余波,西方国家对包括数据库技术在内的高新技术实施严格出口管制,企图遏制社会主义国家的技术进步。
甲骨文的创始人Ellison在1995年初次访华,据说Ellison到中国后的第一项工作就是拍摄一部有关Oracle一体机的宣传片,于是时任甲骨文中国总裁的冯星君就安排了20名北京的小学生共同参与宣传,可本*约好的早上8点正式开机,但直到9点Ellison他老人家都还没有起床。当时北京的冬天格外的寒冷,最低气温达到零下二十度,这些小学生在没有暖气的大巴上急得哇哇大哭,没办法冯星君只好一再催促Ellison赶快*救场,不过直到快到中午十二点钟,这位数据库帝国的掌门人才姗姗*迟,这种无奈的背后,其实也折射出我国当时在数据库是没有任何底气和信心的,就像现在的ASML光刻机一样,被卡着脖子,就只有任人摆布的份了。
在这样的时代背景下,1977年11月,以人民大学
萨师煊教授
为代表的老一辈科学家、教育家以一种强烈的责任心和敏锐的学术洞察力,意识到新兴数据库技术的潜在价值,他们在安徽黄山组织了一次小范围的数据库技术研讨会,拉开了我国数据库研究的序幕。虽然参会人员只有50余位,但这次会议就像一点星星之火,开始在中国的土地上闪烁着数据库的点点光芒。
我国对数据库技术的研究与应用始于20世纪70年代中后期,其标志是1977年11月在安徽省黄山召开的数据库技术研讨会。会议共录用7篇论文。这次会议后*被确认为
第一届全国数据库学术会议(NDBC)
。萨师煊教授参加了这次会议并发表了论文。萨师煊教授担任数据库学组组长期间,在他的领导下自1982年起,每年都要举办一次全国数据库学术会议,为数据库工作者交流学术成就和开发经验,检阅工作成果提供了讲坛。更重要的是形成了一个“团结、执着、和谐、潇洒”的优良学风,为推动我国数据库技术的持续发展打下了基础。
黄山会议上,中国计算机学会软件专业委员会决定下设成立数据库学组,虽然仅仅是一个三级学科组织,但它却迈出了对于中国数据库而言具有里程碑意义的一步。正是这个数据库学组的成立,
被视为国产数据库研究的起源
。

黄山会议召开后的第二年,
1979
年,萨师煊将自己的讲稿汇集成《数据库系统简介》和《数据库方法》并发表。这也是我国
最早的数据库学术论文
,对我国数据库研究和普及起到了启蒙作用,而人民大学也被业界赞誉为“中国数据库的发源地”。
1982
年,萨师煊教授率先在中国人民大学开设“
数据库系统概论
”课程。课程不仅传授了数据库的基本原理、设计方法与管理技术,更重要的是,它激发了一代学子对数据库领域的浓厚兴趣与探索热情,为我国培养了最早一批数据库专业人才。这些学生后*大多成为了中国数据库技术研究与应用领域的中坚力量,对中国数据库产业的发展产生了深远影响。
1983
年,以萨师煊教授、王珊教授等为代表的专家学者出版了我国第一部数据库教材《
数据库系统概论
》。这是国内第一部系统阐明数据库原理、技术和理论的教材,一直被大多数院校计算机专业和信息专业采用。
时至今日,笔者读大学时所用到的数据库课程教材,仍然是萨师煊教授所著。

随着数据库基础理论体系的完善,中国的数据库领域也逐渐从理论探索迈向实践应用的新阶段。
然而,由于技术能力有限,自主研发受到了较大阻力,所以最初的方向是偏向于直接
外*引进
的。
据笔者考证,在80年代初期,我国开始尝试引进
DBASE II
,这是有明确记录的较早引入的数据库系统之一。DBASE II在当时因其易用性和适应个人电脑环境的能力而被广泛采纳,对中国的数据库技术应用和发展起到了推动作用,但
这也标志着中国数据库市场即将步入一个以外企产品为主导的时期
。

混沌阶段—国外数据库的商战和中国数据库的诞生(80~90年代)
80~90年代,是
混乱但也辉煌的十年
。
混乱是因为在这段时间里,全球数据库市场经历了前所未有的动荡与竞争。随着
1979
年1月1日,中美正式建交,国际上,以Oracle、IBM的DB2等为代表的西方数据库巨头,纷纷涌入中国市场,展开了激烈的商战。这些国际巨头不仅带*了先进的数据库技术,也通过资本运作、市场策略和品牌影响力,对我国市场进行了深度渗透和抢占。本土企业面临巨大的挑战,市场竞争环境变得错综复杂,规则多变,小规模的数据库服务商在技术和资金双重压力下,生存空间被急剧压缩,整个行业处于一种高度不确定和混沌的状态。
而辉煌,则是因为在这样的国际竞争压力之下,国内的科技企业和研究机构并未退缩,反而激发出了前所未有的创新活力和自主发展的决心,在政府项目、金融、电信等关键领域逐步实现了从无到有的突破,为中国信息化建设提供了坚实的基础。
下面,我们按照时间线*依次梳理,
【国外】代表国外数据库,【国内】代表国内数据库
。
【国内】
1988
年,华中科技大学数据库与多媒体技术研究所,成功研发
我国第一个自主版权的国产数据库管理系统原型CRDS
,这可以看作是 DM 的起源,这一里程碑式的成就不仅填补了国内在自主数据库技术研发上的空白,还极大地激励了国内科技界对于信息技术核心领域的自主研发热情。
1984年4月,冯裕才编写的《数据库系统基础》教材出版,这本教材让冯裕才前期积累的理论知识得以沉淀,也为后面设计和研发数据库系统原型奠定了基础。1988年,冯裕才带领团队做出了我国第一个自主版权的国产数据库管理系统原型CRDS,它构建了达梦乃至整个中国数据库的“代码根”。
【国外】
1989
年,*自中国台湾的冯星君将
Oracle
带入到中国,并依靠代理开始售卖Oracle产品,2500元一套,要求客户带软盘现拷,而且没有说明书。
由于技术领先且在国际上有着较好的口碑,Oracle开始疯狂扩大业务规模,可以说几乎所有中国本土的数据库公司背后都曾有过他的身影。
【国内】
1990
年,东软完成OpenBASE 1.0的开发,12月27日通过冶金工业部科学技术司组织的技术鉴定。其后以软件包的形式在日本软件市场上销售,取得了良好的经济效益。
OpenBASE是我国第一个具有自主版权的商品化数据库管理系统
。
OpenBASE是东软集团有限公司软件产品事业部推出的我国第一个自主知识产权的商品化数据库管理系统,该产品由东软集团有限公司软件产品事业部研发并持有版权。10多年*,OpenBASE已逐渐形成了以大型通用关系型数据库管理系统为基础的产品系列,包括: OpenBASE多媒体数据库管理系统,OpenBASE Web应用服务器、OpenBASE Mini嵌入式数据库系统、 OpenBASE Secure安全数据库系统等。
截止目前,OpenBASE系列仍然在不断迭代更新,紧随数据库技术的最新发展趋势,持续融入云计算、大数据、人工智能等前沿技术,以满足日益增长的多元化数据管理和分析需求。

【国外】眼看Oracle赚的盆满钵满,其他数据库巨头自然也是眼馋的紧。
1991
年12月,
Sybase
进入中国大陆,随后投资230万美元正式设立赛贝斯软件。
1992
年,
IBM
正式进入中国,并启动了“发展中国”的大战略,协助中国全面开放。带*了
DB2
和
informix
; 同年,
Microsoft微软
在北京设立代办处,开始了在中国长达三十余年的深植。

【国内】面对国外数据库产商对本土市场的大肆侵占,我国科研人员也并未选择坐以待毙,而是开始了一系列卓有成效的创新行动,亲手创造了属于我们的
辉煌十年
。
1991
年,华中科技大学数据库与多媒体技术研究所团队先后完成了军用地图数据库 MDB、知识数据库 KDB、图形数据库 GDB、以及语言数据库 ADB。
1992
年,华中理工大学
达梦数据库研究所
成立,这也是
国内第一个数据库研究所
。
1993
年,该研究所研制的多用户数据库管理系统通过了鉴定,标志着
达梦数据库 1.0 版本
的诞生。
同年,中国航天科技集团联合浙江大学正式开展工程数据库管理系统(OSCAR)技术攻关和产品研制工作,
航天国产数据库启程
。
1995
年5月,邮电部电信总局提出开发和建设"市内电话业务计算机综合管理系统",即”
九七工程
“,并于同年 7 月下发了一系列的技术和业务规范,要求全国县以上的邮电局在 1997 年底前实施
「九七工程」
。
1996
年,DM2(第二代达梦数据库系统)研制成功;同年,东软正式推出产品OpenBASE 3.0,开始标志着
我国具有自主版权的数据库系统软件产品正式走向市场
。
1997
年,中国电力财务公司华中分公司
财务应用系统首次使用国产数据库 DM2
,随后,在全国 76 家分子公司上线使用;东软开发基于Internet/Intranet多媒体综合信息服务体系结构及其支撑平台的OpenBASE,同时入选国家863计划重大目标产品。
【国外】然而,现实却总是会给我们当头一棒。
1997
年,Oracle拿下东三省邮电管理局“九七工程”5期工程的大单,由此在中国数据库领域,尤其电信领域站稳脚步。
1998
年,自九七工程落下帷幕后,中国数据库的行业格局也就在这一时期形成了:
金融行业用 IBM DB2 数据库,Informix 数据库,在电信行业则是 Oracle 的天下。
至此,
中国数据库市场正式进入被外企产品主导的时期
。

【国内】即便如此,面对围剿,中国本土的数据库企业并没有选择放弃,反而激发出了更强的斗志和创新精神,他们深刻认识到,要在强手如林的市场中脱颖而出,就必须走出一条差异化竞争的道路,
即自主可控,打响品牌第一枪
!
1999
年6月18日,
中国第一家数据库公司北京人大金仓信息技术股份有限公司
创立,他的诞生,不仅填补了国内数据库品牌的空白,更是向世界宣告了中国数据库行业自主发展的决心。
后*,经过数年的学术和研究成果转化,人大金仓研制开发出了具有自主知识产权的大型通用关系型数据库管理系统
KingbaseES
,标志着
数据库科研成果成功从实验室走向市场
。此后多家国产数据库厂商相继问世,开启了我国数据库“产学研用”的可持续发展之路。

1999
年 8月24日,根据数据库领域学术研究和应用发展的需要,在兰州大学召开的第十六届全国数据库学术会议上,
中国计算机学会数据库专业委员会
正式成立,标志着中国数据库领域进入了一个
组织化、专业化
发展的新阶段。
回顾上面这些年,我们不难看出,虽然这个阶段市场是被国外数据库产品所主导,但是我们的先辈们仍然凭借着坚韧不拔的精神和对技术自主的执着追求,依旧坚守着国产数据库的自主创新之路。他们不仅在夹缝中求生存,更是在逆境中寻求创新与突破,从模仿学习到自主研发,每一步都凝聚着汗水与智慧。
正是在这个过程中,涌现出了一批批优秀的国产数据库企业,比如上文说到的人大金仓,以及在下文要提到的达梦数据库、南大通用、神舟通用等,他们不仅仅局限于复制国外成功模式,而是更加注重
结合中国国情和行业需求
,开发出更适合本土应用场景的特色功能和服务,而这,
也吹响了国产数据库企业的第一次反攻号角。
发展阶段—国产数据库的百花齐放与稳健成长(00~10年代)
进入21世纪的头十年,信息技术的全球化浪潮汹涌澎湃,互联网的普及和电子商务的兴起极大地推动了数据量的爆炸式增长,为数据库行业带*了前所未有的机遇与挑战。
面对国际数据库巨头的强势地位,国产数据库企业一方面加快技术引进消化吸收的步伐,缩短与国际先进水平的差距;另一方面,针对国内市场的特定需求,如中文处理、多用户并发、以及特定行业应用等,进行本土化创新,逐步在某些细分领域形成特色优势。
期间,大量优秀的国产数据库企业、数据库产品纷纷涌现。
这个时期的数据库大部分都是依托大学、国有产业之类,研发的数据库也都大部分用在银行,国家政府机关,行政企事业单位等。*满足国家对自研数据库项目使用的一些要求和建议。
2000
年11月13日,武汉华工
达梦数据库
有限公司(武汉达梦数据库股份有限公司)成立,同年推出产品DM3。
2003
年,北京
神舟航天
软件技术有限公司成立,开始承担国家863项目,培育数据库产品,推动了国产数据库在政府、军工等关键领域的应用。
2004
年5月,天津
南大通用
数据技术公司成立,专注于数据库管理系统研发,成为国产数据库领域的又一生力军,主要产品为
GBASE
。
2004
年,人大金仓完成具有自主知识产权的KingbaseES V4版本的发布,进一步提升了国产数据库在企业级应用中的竞争力。
2005
年:“十五”期间,中国航天科技集团的北京神舟航天软件技术有限公司研发成功
神舟数据库管理系统
(OSCAR),神舟OSCAR数据库成功应用神舟六号飞船和长征二号F型运载火箭的研制、生产和管理。
2006
年3月:南大发布GBase 8g通用数据库。
2006
年下,达梦数据库推出DM5,实现了从DM3到DM5的重大技术跨越,支持了更多企业级特性,如高级安全性、高可用性及大数据处理能力,荣获第十届软博会金奖。
2008
年11月:天津
神舟通用
数据技术有限公司成立,主要产品为
神通大型通用数据库
。
在大数据与互联网等的发展推动下,一批新兴国产数据库厂家开始涌现。一些云计算厂商以及部分数据库厂商,也基于MySQL、PostgreSQL等开源数据库做了一些改造。
2007
年,腾讯内部启动了一个7*24高可用服务项目,基于开源体系
MySQL
研发了一款数据库产品,即
TDSQL
前身。
2009
年:随着淘宝、支付宝的用户数量激增,阿里巴巴依托MySQL,研究出MySQL分支
AliSQL
。也是从那时起,
MYSQL
开始走入中国的互联网,并到如今一发不可收拾。
Oracle数据库的一个致命缺点开始暴露出*,贵。不仅Oracle软件贵,要维持Oracle数据库+IBM小型机+EMC的开支也相当庞大,另外对于管理员的能力要求,也非常的高。不仅如此,“第一是Oracle作为商业产品,本身也有性能的上限,第二是黑盒子。对于没碰到过的场景,无论再怎么努力,也是无法预测可能出现的问题的。”当时的淘宝数据库大神余锋告诉记者。
中国的互联网公司大部分都草莽出身,对于性价比极为看中,而这个时候,美国的雅虎公司开始率先使用MySQL数据库,一度在世界上有数以千计的服务器都是用MySQL数据库。当时的雅虎的光环,远高于今天的谷歌,FB,可以说今天中国所有互联网公司的架构,都可以在雅虎找到源头,在雅虎的示范效应下,很快中国的互联网公司就开始自己的MySQL之路。
随着去IOE化的提出,国内企业开始积极探索自主可控的IT基础设施建设路径。这一趋势极大地推动了开源技术,尤其是MySQL的广泛应用。众多厂商选择MySQL作为替代Oracle的解决方案,不仅出于成本考量,更重要的是看到了开源软件在灵活性、可定制性以及社区支持方面的优势。在这一浪潮中,也诞生了许多优秀的DBA,为中国数据库技术生态的建设贡献了宝贵的知识与经验,也
为2010年之后国产数据库的蓬勃发展奠定了人才基础
,自那时以后,国产数据库
开始弯道超车
,国产数据库领域才
真正进入到了茁壮成长、蓬勃发展的时代
。

崛起阶段—国产数据库的技术突破与市场拓展(10年代~至今)
对比上一个十年,从10年代开始,最大的特点是在技术上实现了较大突破。国产数据库厂商不再局限于对现有技术的模仿和优化,而是开始在核心算法、存储引擎、分布式架构等方面进行原创性研发。
2011
年,阿里
Oceanbase
诞生,这是由蚂蚁集团完全自主研发的国产原生分布式数据库,是一个在TPC-C和TPC-H测试上都刷新了世界纪录的国产原生分布式数据库。
2011
年,巨杉数据库成立,专注分布式数据库。总体架构是基于shard-nothing 的方式。
2012
年,腾讯以 “
开源定制化+自研
” 为策略进行定制化,打磨出更加通用的数据库产品,正式命名
TDSQL
。
TDSQL是腾讯云自研企业级分布式数据库,旗下涵盖金融级分布式、云原生、分析型等多引擎融合的完整数据库产品体系,提供业界领先的金融级高可用、计算存储分离、数据仓库、企业级安全等能力,同时具备智能运维平台、Serverless版本等完善的产品服务体系。
截至2021年,腾讯云的数据库已经拥有超过50万客户 ,服务1000多家政府客户和2000多家金融客户 ,每天支撑数十亿笔的交易量 。同时广泛覆盖游戏、电商、移动互联网、云开发等泛互联网业务场景,助力新零售、教育、SaaS、广告等超过4000家行业客户进行数字化升级 。

【转折点】
2013
年,棱镜门事件曝光,将数据安全与隐私保护的问题正式推到了国际社会的聚光灯下,也对国产数据库的发展起到了重要的转折作用。在此之后,国产化数据库如达梦、金仓、神通、南大等得到了广泛关注,这些数据库也开始多应用于央企、国家财政、军事等专用领域。
棱镜计划(PRISM):是一项由美国国家安全局自2007年起开始实施的绝密电子监听计划。该计划的正式名号为“US-984XN”。
根据报道,泄露的文件中描述PRISM计划能够对即时通信和既存资料进行深度的监听。许可的监听对象包括任何在美国以外地区使用参与计划公司服务的客户,或是任何与国外人士通信的美国公民。国家安全局在PRISM计划中可以获得的数据电子邮件、视频和语音交谈、影片、照片、VoIP交谈内容、档案传输、登入通知,以及社交网络细节。综合情报文件“总统每日简报”中在2012年内在1,477个计划使用了*自PRISM计划的资料。
2014
年,国内首家互联网银行-微众银行核心交易数据库采用
腾讯云TDSQL
。
2014
年,腾讯发布TBase数据库,开始在腾讯大数据平台内部使用。
2014
年末,除MySQL外,PostgreSQL、Redis、MongoDB和Hbase等
开源数据库
也活跃起*,在各大数据库大会和社群中一起寻找着中国数据库的新方向。
2015
年,
阿里巴巴的OceanBase
经过内部多年打磨最终对外推出使用。
2015
年,
腾讯TBase数据库
在微信支付商户集群上线,支持每天超过6亿笔的交易。
2016
年,支付宝总账全面用OceanBase替换Oracle。
2017
年,阿里云(阿里巴巴)公布国内首个
自研企业级关系型云数据库
PolarDB技术框架。
2017
年, Gartner 发布数据库系列报告第一次看到国产数据库的身影,
国产数据库-阿里AsparaDB、南大通用GBase、和SequoiaDB
首次入选。
2018
年,腾讯云宣布新一代自研
云原生数据库
CynosDB正式发布。
2018
年11月:Gartner发布数据库报告,
华为云
、
腾讯云
紧接进榜,这一系列的突破标志着国产数据库进入了一个全新的发展阶段。
2019
年,新一代达梦数据库管理系
DM8
发布。
2019
年5月:华为公司发布了
全球首款AI原生(AI-Native)数据库
——
GaussDB
。
2019
年9月:腾讯云TDSQL在张家港农商银行新一代核心业务系统上线。
2019
年9月19日:华为宣布将开源其数据库产品,开源后命名
openGauss
。
2019
年10月2日:国际事务处理性能委员会公布数据库最新性能测试结果,阿里巴巴集团蚂蚁金服的分布式关系数据库
OceanBase
打破了Oracle保持9年的TPC-C基准性能测试世界纪录。

2020
年5月,中信银行与中兴通讯联合研发的
GoldenDB
上线,成功取代了在中信银行核心系统服役了几十年的IBM AS400数据库。
2020
年5月,
OceanBase
再次将自己创造的数据库TPC-C基准性能测试世界记录提升11倍,将甲骨文、IBM 等一众老牌数据库巨头甩在身后。
2020
年11月:达梦发布数据共享集群(DMDSC)、启云数据库(DMCDB)、图数据库(GDM)、新一代分布式数据库四款产品。
2020
年11月:以“自研·智能·新基建——云和数据促创新 生态融合新十年”为主题的第十届数据技术嘉年华大会在北京成功举办,三大云数据库掌门人,三大独立数据库首席,一位云和*墨创始人,共同讲述了国内数据库发展的光辉十年。

2020
年11月16日,腾讯云宣布,旗下国产金融级分布式数据库
TDSQL
在印尼Bank Neo Commerce银行新核心系统正式投入使用。意味着腾讯云自研数据库TDSQL不仅在国内金融级市场应用走在前列,在
国际数据库领域
也具备强有力的竞争优势。
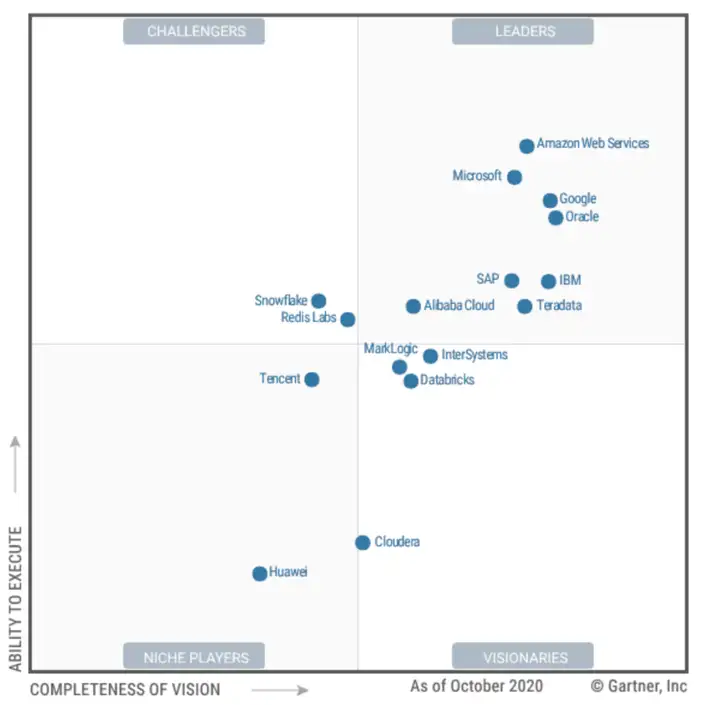
2020
年11月:Gartner公布2020年度全球数据库魔力象限评估结果,阿里云首次挺进全球数据库第一阵营-领导者(LEADERS)象限,这也是中国数据库40年*首次进入全球顶级数据库行列。
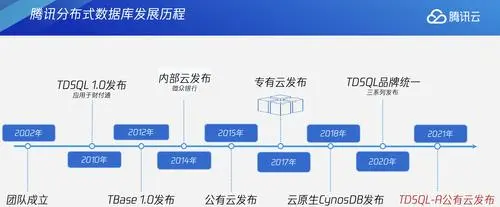
2020
年12月,腾讯云宣布TDSQL、CynosDB、TBase 统一至全新TDSQL品牌。
2020
年底,VLDB 刊登63篇论文,*自中国学者和研究人员的文章23篇,在所有国家中排行第一,占比36.5%;
阿里巴巴和腾讯的成果显著
。
毫无疑问,2020年,是
国产数据库的丰收年
,这一系列标志性事件和成就不仅展示了国产数据库技术的蓬勃生机,也
预示着中国在数据库领域正逐步从追随者转变为领跑者
。此外,国产数据库企业的崛起,不仅体现在市场份额的增长和技术壁垒的突破上,更重要的是,它们开始在全球数据库技术的标准制定、前沿探索以及行业应用上发挥越*越重要的作用。
2024年国产数据库发展现状
根据2024年最新的数据库发展研究报告,我摘出了一些关键细节,在此作为参考。
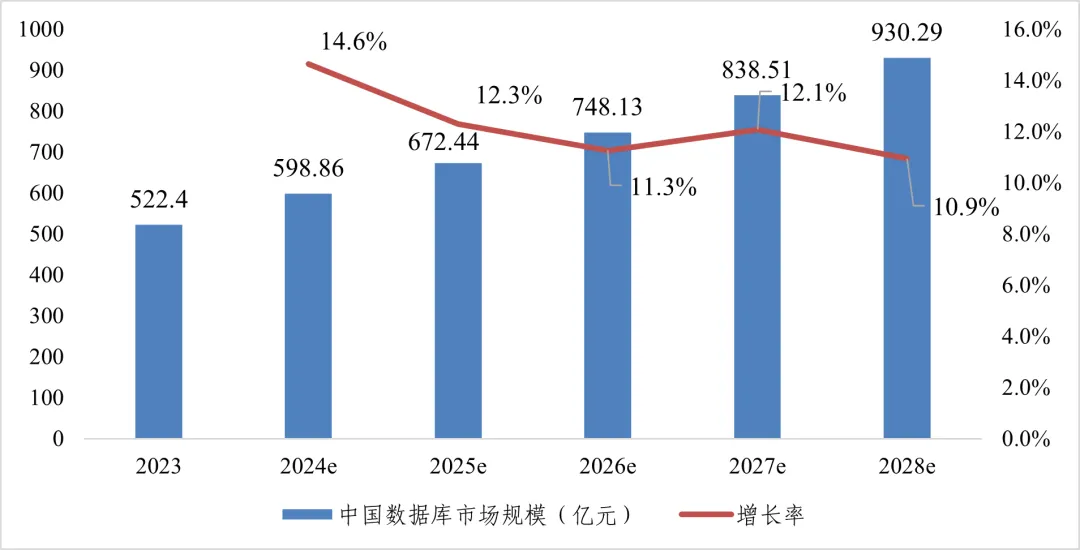
从市场规模看,我国市场规模超500亿元,云上市场超六成
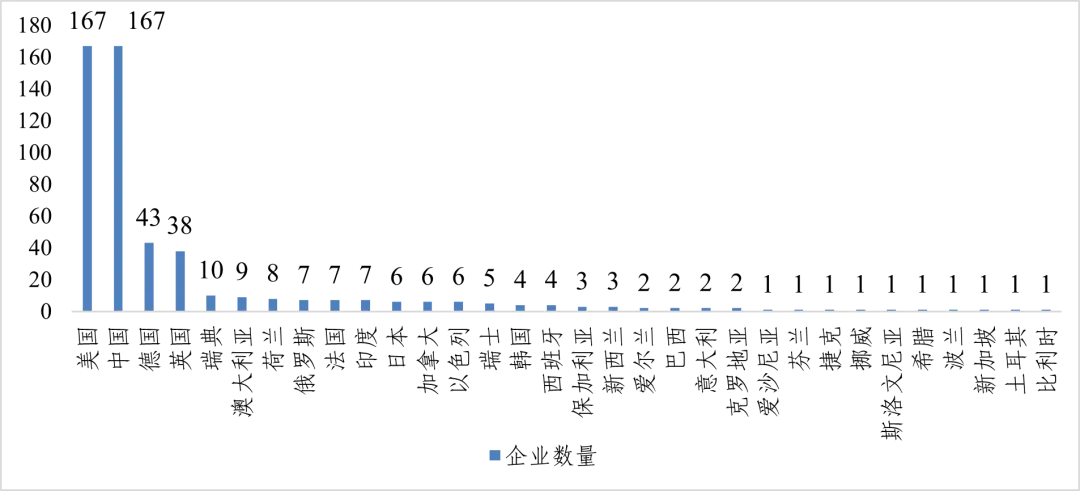
从地域分布看,中美企业数量齐头并进,领跑全球
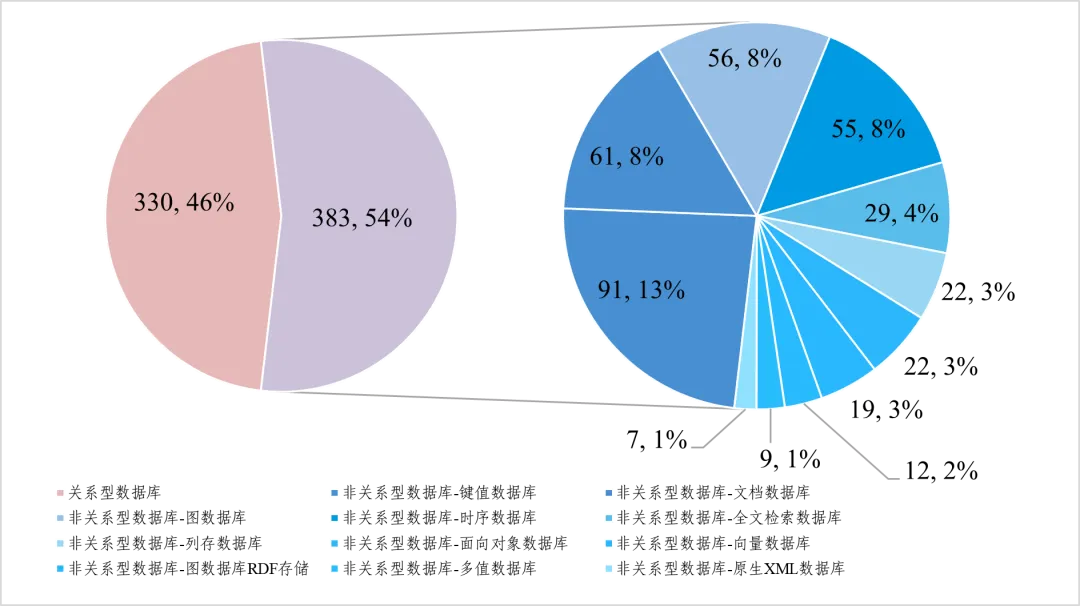
从产品类型看,国内外分布各有侧重,非关系型占比逐步提升
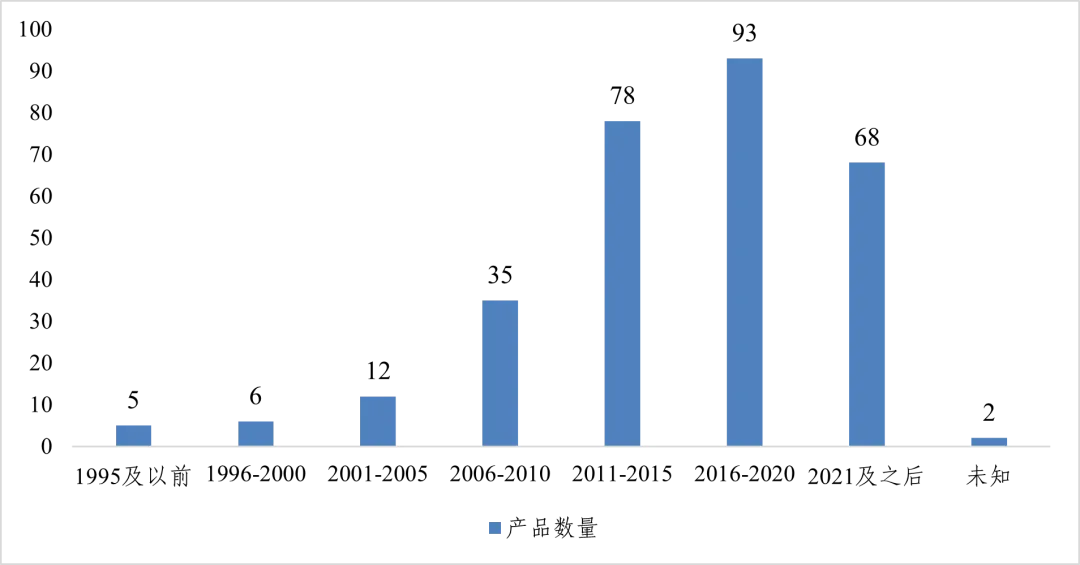
从开源历程看,全球起步于二十年前,我国近十年发展迅速
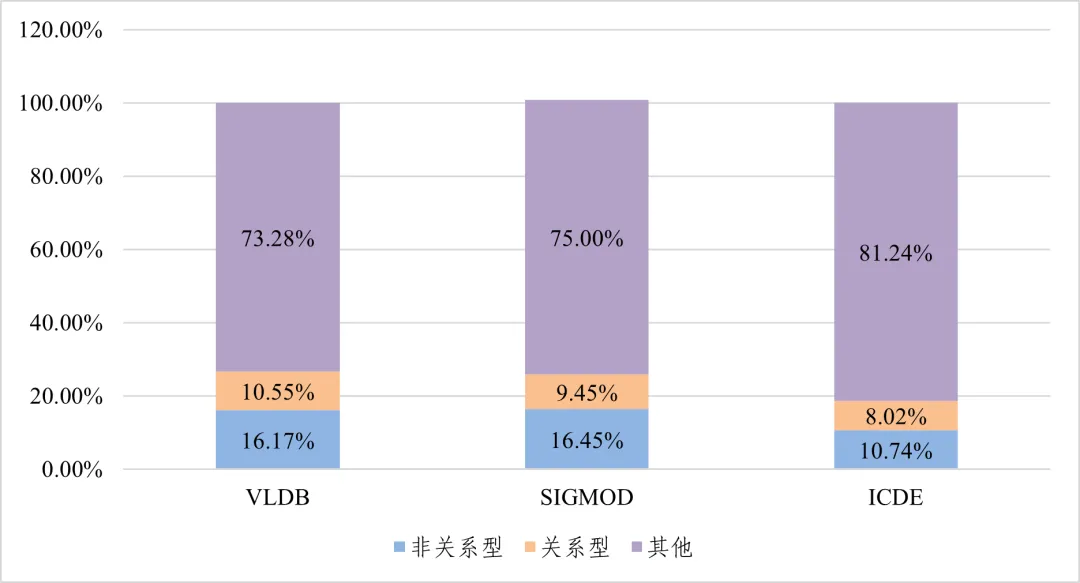
从学术创新看,非关系型成为研究重点,我国创新实力稳步增强
写在结尾的话
中国数据库技术的发展历程是一部波澜壮阔的科技奋斗史,从1958年中国第一台计算机诞生,到1978年萨师煊教授首次将“数据库”概念引入课堂,再到如今中国数据库技术已经在全球范围内崭露头角,实现从技术跟随到创新引领的华丽转身。
这一路走*,凝聚了几代科研人员与企业的不懈努力与智慧结晶,而我作为后辈,在收集整理这篇文章的相关资料史料时,内心无疑是震惊的,震惊于前辈们在资源有限、条件艰苦的环境下,还能凭借着坚韧不拔的意志和对技术的无限热爱,一步步奠基并壮大了中国数据库技术的基础,更震惊于我们能在短短数十年间,就实现了从追赶到并跑,乃至在某些领域实现领跑全球的壮举。
如果不写这篇文章,不读这段历史,我或许永远都无法深刻理解,中国数据库技术蓬勃发展的背后,是无数次的尝试与失败,是无数个日夜的灯火通明,更是无数科研人员与企业的"
留取丹心照汗青
"。这不仅是一场技术的革命,
更是一次民族自信心的重塑
,展现了中国人面对困难时不畏艰难、勇于攀登的精神风貌。
现在的我,正站在这个历史与未*的交汇点上,回望过去,前辈们的足迹清晰可辨,他们的精神如同璀璨星辰,指引着我们前行的方向;展望未*,中国数据库技术正以前所未有的速度向前迈进,每一步跨越都伴随着创新的火花,每一次突破都预示着更加辉煌的明天。
本文历时一*,感谢提供资料的各位前辈大佬,参考文献如下:























