缓存框架 Caffeine 的可视化探索与实践
作者:vivo 互联网服务器团队- Wang Zhi
Caffeine 作为一个高性能的缓存框架而被大量使用。本文基于Caffeine已有的基础进行定制化开发实现可视化功能。
一、背景
Caffeine缓存是一个高性能、可扩展、内存优化的 Java 缓存库,基于 Google 的 Guava Cache演进而来并提供了接近最佳的命中率。
Caffeine 缓存包含以下
特点
:
高效快速
:Caffeine 缓存使用近似算法和并发哈希表等优化技术,使得缓存的访问速度非常快。内存友好
:Caffeine 缓存使用一种内存优化策略,能够根据需要动态调整缓存的大小,有效地利用内存资源。多种缓存策略
:Caffeine 缓存支持多种缓存策略,如基于容量、时间、权重、手动移除、定时刷新等,并提供了丰富的配置选项,能够适应不同的应用场景和需求。支持异步加载和刷新
:Caffeine 缓存支持异步加载和刷新缓存项,可以与 Spring 等框架无缝集成。清理策略
:Caffeine 使用 Window TinyLFU 清理策略,它提供了接近最佳的命中率。支持自动加载和自动过期
:Caffeine 缓存可以根据配置自动加载和过期缓存项,无需手动干预。统计功能
:Caffeine 缓存提供了丰富的统计功能,如缓存命中率、缓存项数量等,方便评估缓存的性能和效果。
正是因为Caffeine具备的上述特性,Caffeine作为项目中本地缓存的不二选择,越来越多的项目集成了Caffeine的功能,进而衍生了一系列的业务视角的需求。
日常使用的需求之一希望能够实时评估Caffeine实例的内存占用情况并能够提供动态调整缓存参数的能力,但是已有的内存分析工具MAT需要基于dump的文件进行分析无法做到实时,这也是整个事情的起因之一。
二、业务的技术视角
能够对项目中的Caffeine的缓存实例能够做到近实时统计,实时查看缓存的实例个数。
能够对Caffeine的每个实例的缓存配置参数、内存占用、缓存命中率做到实时查看,同时能够支持单个实例的缓存过期时间,缓存条目等参数进行动态配置下发。
能够对Caffeine的每个实例的缓存数据做到实时查看,并且能够支持缓存数据的立即失效等功能。
基于上述的需求背景,结合caffeine的已有功能和定制的部分源码开发,整体作为caffeine可视化的技术项目进行推进和落地。
三、可视化能力
Caffeine可视化项目目前
已支持功能
包括:
项目维度的全局缓存实例的管控。
单缓存实例配置信息可视化、内存占用可视化、命中率可视化。
单缓存实例的数据查询、配置动态变更、缓存数据失效等功能。
3.1 缓存实例的全局管控

说明:
以应用维度+机器维度展示该应用下包含的缓存实例对象,每个实例包含缓存设置中的大小、过期策略、过期时间、内存占用、缓存命中率等信息。
单实例维度的内存占用和缓存命中率支持以趋势图进行展示。
单实例维度支持配置变更操作和缓存查询操作。
3.2 内存占用趋势
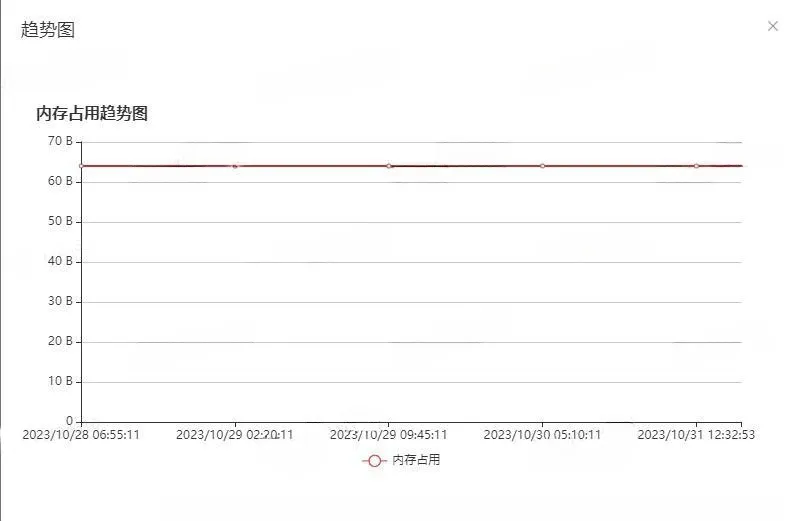
说明:
内存占用趋势记录该缓存实例对象近一段时间内存占用的趋势变化。
时间周期目前支持展示近两天的数据。
3.3 命中率趋势
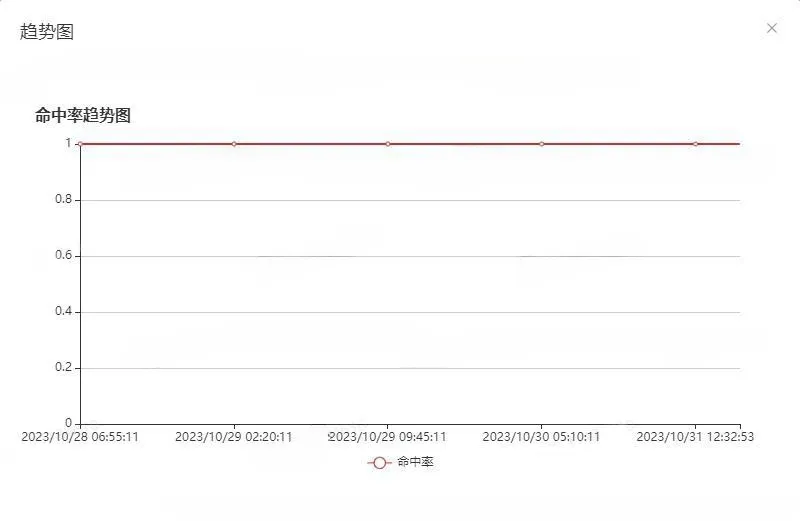
说明:
命中率趋势记录该缓存实例对象近一段时间缓存命中的变化情况。
时间周期目前支持展示近两天的数据。
3.4 配置变更
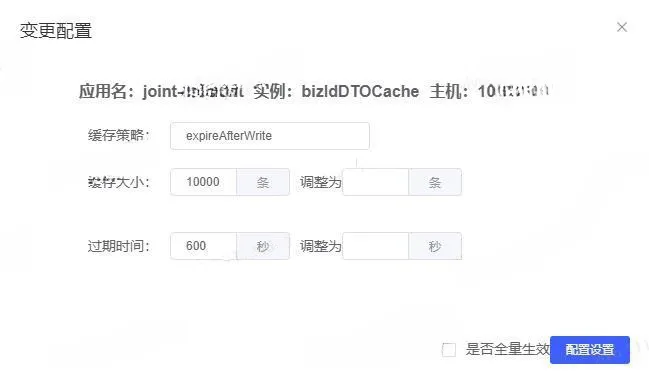
说明:
配置变更目前支持缓存大小和过期时间的动态设置。
目前暂时支持单实例的设置,后续会支持全量生效功能。
3.5 缓存查询
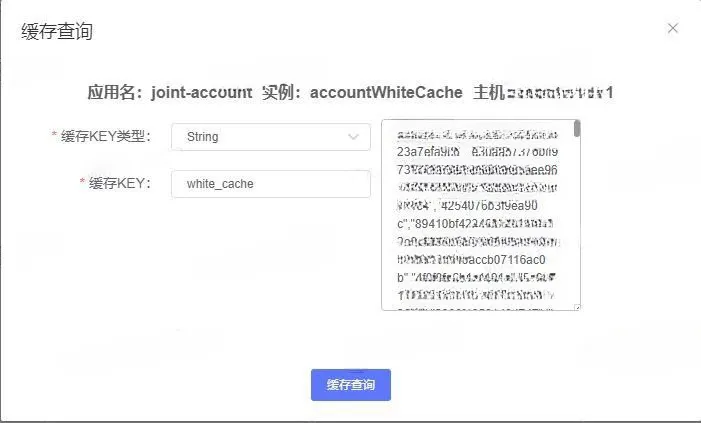
说明:
单实例维度支持缓存数据的查询。
目前支持常见的缓存Key类型包括String类型、Long类型、Int类型。
四、原理实现
4.1 整体设计框架
Caffeine框架功能整合
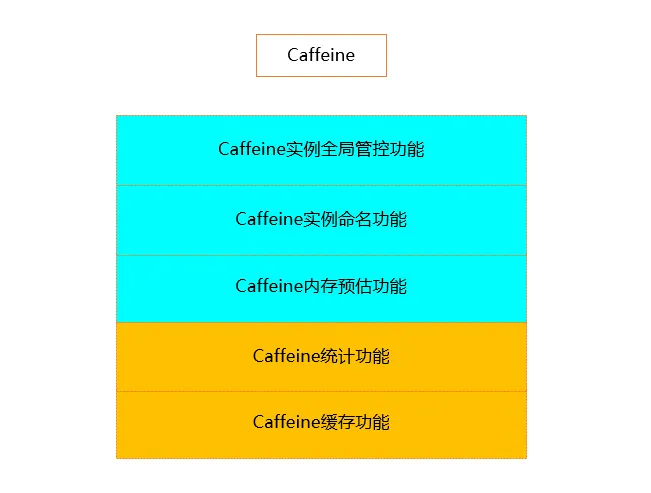
说明:
沿用Caffeine的基础功能包括Caffeine的缓存功能和Caffeine统计功能。
新增
Caffeine内存占用预估功能,该功能主要是预估缓存实例对象占用的内存情况。新增
Caffeine实例命名功能,该功能是针对每个实例对象提供命名功能,是全局管控的基础。新增
Caffeine实例全局管控功能,该功能主要维护项目运行中所有的缓存实例。
Caffeine可视化框架
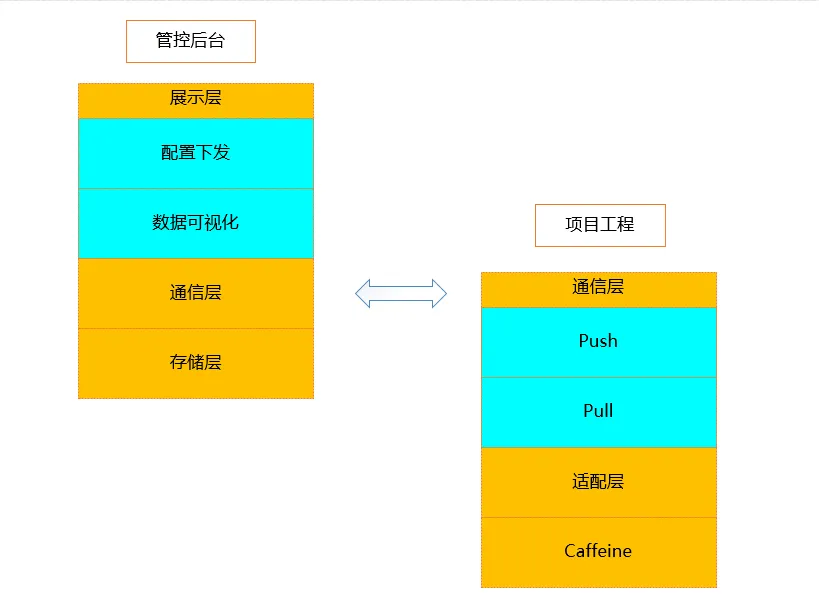
说明:
【项目工程侧】:Caffeine的可视化框架基于Caffeine框架功能整合的基础上增加通信层进行数据数据上报和配置的下发。
【管控平台侧】:负责缓存数据上报的接收展示,配置变更命令的下发。
【通信层支持push和pull两种模式】,push模式主要用于统计数据的实时上报,pull模式主要用于配置下发和缓存数据查询。
4.2 源码实现
业务层-缓存对象的管理
static Cache<String, List<String>> accountWhiteCache = Caffeine.newBuilder()
.expireAfterWrite(VivoConfigManager.getInteger("trade.account.white.list.cache.ttl", 10), TimeUnit.MINUTES)
.recordStats().maximumSize(VivoConfigManager.getInteger("trade.account.white.list.cache.size", 100)).build();
常规的Caffeine实例的创建方式
static Cache<String, List<String>> accountWhiteCache = Caffeine.newBuilder().applyName("accountWhiteCache")
.expireAfterWrite(VivoConfigManager.getInteger("trade.account.white.list.cache.ttl", 10), TimeUnit.MINUTES)
.recordStats().maximumSize(VivoConfigManager.getInteger("trade.account.white.list.cache.size", 100)).build();
支持实例命名的Caffeine实例的创建方式说明:
在Caffeine实例创建的基础上增加了缓存实例的命名功能,通过.applyName("accountWhiteCache")来定义缓存实例的命名。
public final class Caffeine<K, V> {
/**
* caffeine的实例名称
*/
String instanceName;
/**
* caffeine的实例维护的Map信息
*/
static Map<String, Cache> cacheInstanceMap = new ConcurrentHashMap<>();
@NonNull
public <K1 extends K, V1 extends V> Cache<K1, V1> build() {
requireWeightWithWeigher();
requireNonLoadingCache();
@SuppressWarnings("unchecked")
Caffeine<K1, V1> self = (Caffeine<K1, V1>) this;
Cache localCache = isBounded() ? new BoundedLocalCache.BoundedLocalManualCache<>(self) : new UnboundedLocalCache.UnboundedLocalManualCache<>(self);
if (null != localCache && StringUtils.isNotEmpty(localCache.getInstanceName())) {
cacheInstanceMap.put(localCache.getInstanceName(), localCache);
}
return localCache;
}
}说明:
每个Caffeine都有一个实例名称instanceName。
全局通过cacheInstanceMap来维护Caffeine实例对象的名称和实例的映射关系。
通过维护映射关系能够通过实例的名称查询到缓存实例对象并对缓存实例对象进行各类的操作。
Caffeine实例的命名功能是其他功能整合的基石。
业务层-内存占用的预估
import jdk.nashorn.internal.ir.debug.ObjectSizeCalculator;
public abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef<K, V>
implements LocalCache<K, V> {
final ConcurrentHashMap<Object, Node<K, V>> data;
@Override
public long getMemoryUsed() {
// 预估内存占用
return ObjectSizeCalculator.getObjectSize(data);
}
}说明:
通过ObjectSizeCalculator.getObjectSize预估内存的缓存值。
data值是Caffeine实例用来保存真实数据的对象。
业务层-数据上报机制
public static StatsData getCacheStats(String instanceName) {
Cache cache = Caffeine.getCacheByInstanceName(instanceName);
CacheStats cacheStats = cache.stats();
StatsData statsData = new StatsData();
statsData.setInstanceName(instanceName);
statsData.setTimeStamp(System.currentTimeMillis()/1000);
statsData.setMemoryUsed(String.valueOf(cache.getMemoryUsed()));
statsData.setEstimatedSize(String.valueOf(cache.estimatedSize()));
statsData.setRequestCount(String.valueOf(cacheStats.requestCount()));
statsData.setHitCount(String.valueOf(cacheStats.hitCount()));
statsData.setHitRate(String.valueOf(cacheStats.hitRate()));
statsData.setMissCount(String.valueOf(cacheStats.missCount()));
statsData.setMissRate(String.valueOf(cacheStats.missRate()));
statsData.setLoadCount(String.valueOf(cacheStats.loadCount()));
statsData.setLoadSuccessCount(String.valueOf(cacheStats.loadSuccessCount()));
statsData.setLoadFailureCount(String.valueOf(cacheStats.loadFailureCount()));
statsData.setLoadFailureRate(String.valueOf(cacheStats.loadFailureRate()));
Optional<Eviction> optionalEviction = cache.policy().eviction();
optionalEviction.ifPresent(eviction -> statsData.setMaximumSize(String.valueOf(eviction.getMaximum())));
Optional<Expiration> optionalExpiration = cache.policy().expireAfterWrite();
optionalExpiration.ifPresent(expiration -> statsData.setExpireAfterWrite(String.valueOf(expiration.getExpiresAfter(TimeUnit.SECONDS))));
optionalExpiration = cache.policy().expireAfterAccess();
optionalExpiration.ifPresent(expiration -> statsData.setExpireAfterAccess(String.valueOf(expiration.getExpiresAfter(TimeUnit.SECONDS))));
optionalExpiration = cache.policy().refreshAfterWrite();
optionalExpiration.ifPresent(expiration -> statsData.setRefreshAfterWrite(String.valueOf(expiration.getExpiresAfter(TimeUnit.SECONDS))));
return statsData;
}说明:
通过Caffeine自带的统计接口来统计相关数值。
统计数据实例维度进行统计。
public static void sendReportData() {
try {
if (!VivoConfigManager.getBoolean("memory.caffeine.data.report.switch", true)) {
return;
}
// 1、获取所有的cache实例对象
Method listCacheInstanceMethod = HANDLER_MANAGER_CLASS.getMethod("listCacheInstance", null);
List<String> instanceNames = (List)listCacheInstanceMethod.invoke(null, null);
if (CollectionUtils.isEmpty(instanceNames)) {
return;
}
String appName = System.getProperty("app.name");
String localIp = getLocalIp();
String localPort = String.valueOf(NetPortUtils.getWorkPort());
ReportData reportData = new ReportData();
InstanceData instanceData = new InstanceData();
instanceData.setAppName(appName);
instanceData.setIp(localIp);
instanceData.setPort(localPort);
// 2、遍历cache实例对象获取缓存监控数据
Method getCacheStatsMethod = HANDLER_MANAGER_CLASS.getMethod("getCacheStats", String.class);
Map<String, StatsData> statsDataMap = new HashMap<>();
instanceNames.stream().forEach(instanceName -> {
try {
StatsData statsData = (StatsData)getCacheStatsMethod.invoke(null, instanceName);
statsDataMap.put(instanceName, statsData);
} catch (Exception e) {
}
});
// 3、构建上报对象
reportData.setInstanceData(instanceData);
reportData.setStatsDataMap(statsDataMap);
// 4、发送Http的POST请求
HttpPost httpPost = new HttpPost(getReportDataUrl());
httpPost.setConfig(requestConfig);
StringEntity stringEntity = new StringEntity(JSON.toJSONString(reportData));
stringEntity.setContentType("application/json");
httpPost.setEntity(stringEntity);
HttpResponse response = httpClient.execute(httpPost);
String result = EntityUtils.toString(response.getEntity(),"UTF-8");
EntityUtils.consume(response.getEntity());
logger.info("Caffeine 数据上报成功 URL {} 参数 {} 结果 {}", getReportDataUrl(), JSON.toJSONString(reportData), result);
} catch (Throwable throwable) {
logger.error("Caffeine 数据上报失败 URL {} ", getReportDataUrl(), throwable);
}
}说明:
通过获取项目中运行的所有Caffeine实例并依次遍历收集统计数据。
通过http协议负责上报对应的统计数据,采用固定间隔周期进行上报。
业务层-配置动态下发
public static ExecutionResponse dispose(ExecutionRequest request) {
ExecutionResponse executionResponse = new ExecutionResponse();
executionResponse.setCmdType(CmdTypeEnum.INSTANCE_CONFIGURE.getCmd());
executionResponse.setInstanceName(request.getInstanceName());
String instanceName = request.getInstanceName();
Cache cache = Caffeine.getCacheByInstanceName(instanceName);
// 设置缓存的最大条目
if (null != request.getMaximumSize() && request.getMaximumSize() > 0) {
Optional<Eviction> optionalEviction = cache.policy().eviction();
optionalEviction.ifPresent(eviction ->eviction.setMaximum(request.getMaximumSize()));
}
// 设置写后过期的过期时间
if (null != request.getExpireAfterWrite() && request.getExpireAfterWrite() > 0) {
Optional<Expiration> optionalExpiration = cache.policy().expireAfterWrite();
optionalExpiration.ifPresent(expiration -> expiration.setExpiresAfter(request.getExpireAfterWrite(), TimeUnit.SECONDS));
}
// 设置访问过期的过期时间
if (null != request.getExpireAfterAccess() && request.getExpireAfterAccess() > 0) {
Optional<Expiration> optionalExpiration = cache.policy().expireAfterAccess();
optionalExpiration.ifPresent(expiration -> expiration.setExpiresAfter(request.getExpireAfterAccess(), TimeUnit.SECONDS));
}
// 设置写更新的过期时间
if (null != request.getRefreshAfterWrite() && request.getRefreshAfterWrite() > 0) {
Optional<Expiration> optionalExpiration = cache.policy().refreshAfterWrite();
optionalExpiration.ifPresent(expiration -> expiration.setExpiresAfter(request.getRefreshAfterWrite(), TimeUnit.SECONDS));
}
executionResponse.setCode(0);
executionResponse.setMsg("success");
return executionResponse;
}说明:
通过Caffeine自带接口进行缓存配置的相关设置。
业务层-缓存数据清空
/**
* 失效缓存的值
* @param request
* @return
*/
public static ExecutionResponse invalidate(ExecutionRequest request) {
ExecutionResponse executionResponse = new ExecutionResponse();
executionResponse.setCmdType(CmdTypeEnum.INSTANCE_INVALIDATE.getCmd());
executionResponse.setInstanceName(request.getInstanceName());
try {
// 查找对应的cache实例
String instanceName = request.getInstanceName();
Cache cache = Caffeine.getCacheByInstanceName(instanceName);
// 处理清空指定实例的所有缓存 或 指定实例的key对应的缓存
Object cacheKeyObj = request.getCacheKey();
// 清除所有缓存
if (Objects.isNull(cacheKeyObj)) {
cache.invalidateAll();
} else {
// 清除指定key对应的缓存
if (Objects.equals(request.getCacheKeyType(), 2)) {
cache.invalidate(Long.valueOf(request.getCacheKey().toString()));
} else if (Objects.equals(request.getCacheKeyType(), 3)) {
cache.invalidate(Integer.valueOf(request.getCacheKey().toString()));
} else {
cache.invalidate(request.getCacheKey().toString());
}
}
executionResponse.setCode(0);
executionResponse.setMsg("success");
} catch (Exception e) {
executionResponse.setCode(-1);
executionResponse.setMsg("fail");
}
return executionResponse;
}
}业务层-缓存数据查询
public static ExecutionResponse inspect(ExecutionRequest request) {
ExecutionResponse executionResponse = new ExecutionResponse();
executionResponse.setCmdType(CmdTypeEnum.INSTANCE_INSPECT.getCmd());
executionResponse.setInstanceName(request.getInstanceName());
String instanceName = request.getInstanceName();
Cache cache = Caffeine.getCacheByInstanceName(instanceName);
Object cacheValue = cache.getIfPresent(request.getCacheKey());
if (Objects.equals(request.getCacheKeyType(), 2)) {
cacheValue = cache.getIfPresent(Long.valueOf(request.getCacheKey().toString()));
} else if (Objects.equals(request.getCacheKeyType(), 3)) {
cacheValue = cache.getIfPresent(Integer.valueOf(request.getCacheKey().toString()));
} else {
cacheValue = cache.getIfPresent(request.getCacheKey().toString());
}
if (Objects.isNull(cacheValue)) {
executionResponse.setData("");
} else {
executionResponse.setData(JSON.toJSONString(cacheValue));
}
return executionResponse;
}说明:
通过Caffeine自带接口进行缓存信息查询。
通信层-监听服务
public class ServerManager {
private Server jetty;
/**
* 创建jetty对象
* @throws Exception
*/
public ServerManager() throws Exception {
int port = NetPortUtils.getAvailablePort();
jetty = new Server(port);
ServletContextHandler context = new ServletContextHandler(ServletContextHandler.NO_SESSIONS);
context.setContextPath("/");
context.addServlet(ClientServlet.class, "/caffeine");
jetty.setHandler(context);
}
/**
* 启动jetty对象
* @throws Exception
*/
public void start() throws Exception {
jetty.start();
}
}
public class ClientServlet extends HttpServlet {
private static final Logger logger = LoggerFactory.getLogger(ClientServlet.class);
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
super.doGet(req, resp);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
ExecutionResponse executionResponse = null;
String requestJson = null;
try {
// 获取请求的相关的参数
String contextPath = req.getContextPath();
String servletPath = req.getServletPath();
String requestUri = req.getRequestURI();
requestJson = IOUtils.toString(req.getInputStream(), StandardCharsets.UTF_8);
// 处理不同的命令
ExecutionRequest executionRequest = JSON.parseObject(requestJson, ExecutionRequest.class);
// 通过反射来来处理类依赖问题
executionResponse = DisposeCenter.dispatch(executionRequest);
} catch (Exception e) {
logger.error("vivo-memory 处理请求异常 {} ", requestJson, e);
}
if (null == executionResponse) {
executionResponse = new ExecutionResponse();
executionResponse.setCode(-1);
executionResponse.setMsg("处理异常");
}
// 组装相应报文
resp.setContentType("application/json; charset=utf-8");
PrintWriter out = resp.getWriter();
out.println(JSON.toJSONString(executionResponse));
out.flush();
}
}说明:
通信层通过jetty启动http服务进行监听,安全考虑端口不对外开放。
通过定义ClientServlet来处理相关的请求包括配置下发和缓存查询等功能。
通信层-心跳设计
/**
* 发送心跳数据
*/
public static void sendHeartBeatData() {
try {
if (!VivoConfigManager.getBoolean("memory.caffeine.heart.report.switch", true)) {
return;
}
// 1、构建心跳数据
String appName = System.getProperty("app.name");
String localIp = getLocalIp();
String localPort = String.valueOf(NetPortUtils.getWorkPort());
HeartBeatData heartBeatData = new HeartBeatData();
heartBeatData.setAppName(appName);
heartBeatData.setIp(localIp);
heartBeatData.setPort(localPort);
heartBeatData.setTimeStamp(System.currentTimeMillis()/1000);
// 2、发送Http的POST请求
HttpPost httpPost = new HttpPost(getHeartBeatUrl());
httpPost.setConfig(requestConfig);
StringEntity stringEntity = new StringEntity(JSON.toJSONString(heartBeatData));
stringEntity.setContentType("application/json");
httpPost.setEntity(stringEntity);
HttpResponse response = httpClient.execute(httpPost);
String result = EntityUtils.toString(response.getEntity(),"UTF-8");
EntityUtils.consume(response.getEntity());
logger.info("Caffeine 心跳上报成功 URL {} 参数 {} 结果 {}", getHeartBeatUrl(), JSON.toJSONString(heartBeatData), result);
} catch (Throwable throwable) {
logger.error("Caffeine 心跳上报失败 URL {} ", getHeartBeatUrl(), throwable);
}
}说明:
心跳功能上报项目实例的ip和端口用来通信,携带时间戳用来记录上报时间戳。
实际项目中因为机器的回收等场景需要通过上报时间戳定时清理下线的服务。
五、总结
vivo技术团队在Caffeine的使用经验上曾有过多次分享,可参考公众号文章《如何把 Caffeine Cache 用得如丝般顺滑》,此篇文章在使用的基础上基于使用痛点进行进一步的定制。
目前Caffeine可视化的项目已经在相关核心业务场景中落地并发挥作用,整体运行平稳。使用较多的功能包括项目维度的caffeine实例的全局管控,单实例维度的内存占用评估和缓存命中趋势评估。
如通过单实例的内存占用评估功能能够合理评估缓存条目设置和内存占用之间的关系;通过分析缓存命中率的整体趋势评估缓存的参数设置合理性。
期待此篇文章能够给业界缓存使用和监控带来一些新思路。




















