ThinkPHP一对一关联模型的运用(ORM)
一、序言
最近在写ThinkPHP关联模型的时候一些用法总忘,我就想通过写博客的方式复习和整理下一些用法。
具体版本:
- topthink/framework:6.1.4
- topthink/think-orm:2.0.61
二、实例应用
1、一对一关联
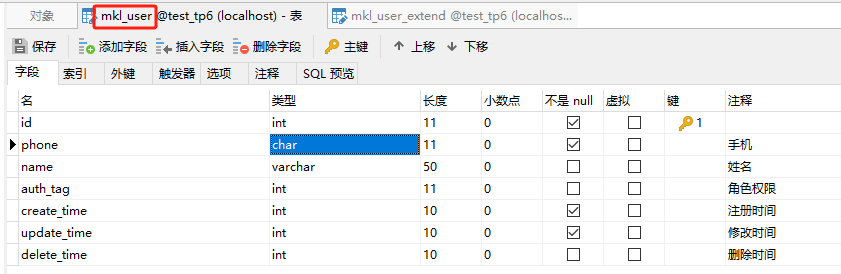
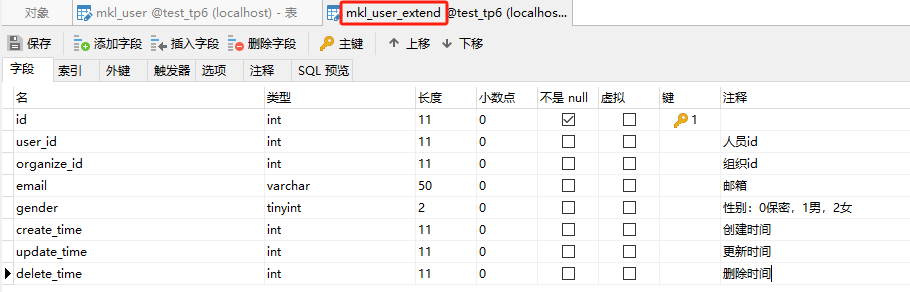
1.1、我先设计了两张表,分别为用户表(user),用户扩展表(user_extend)
1.2、分别给两个表建立模型
<?php/**
* Created by PhpStorm
* Author: fengzi
* Date: 2023/12/19
* Time: 14:50*/namespace app\common\model;/**
* 用户模型*/ class UserModel extendsComBaseModel
{protected $name='user';/**
* 关联的用户扩展表
* hasOne的第一个参数是要关联的模型类名,第二个参数是关联的外键名,第三个参数是当前模型(userModel)的主键名
* @return \think\model\relation\HasOne
* @Author: fengzi
* @Date: 2024/6/27 17:38*/ public functionuserExtend()
{return $this->hasOne(UserExtendModel::class,'user_id','id');
}
}
<?php/**
* Created by PhpStorm
* Author: fengzi
* Date: 2023/12/19
* Time: 14:50*/namespace app\common\model;/**
* 用户扩展表*/ class UserExtendModel extendsComBaseModel
{protected $name='user_extend';/**
* 用户模型的相对关联
* belongsTo的第一个参数是关联模型类名,第二个参数是当前模型(UserExtendModel)的外键,第三个参数是关联表的主键
* @return \think\model\relation\BelongsTo
* @Author: fengzi
* @Date: 2024/6/27 17:41*/ public functionuser()
{return $this->belongsTo(UserModel::class,'user_id','id');
}
}
1.3、with() 关联查询
一对一关联查询,user表对user_extend表使用的hasOne,使用hasWhere查询user_extend表时,相当于把user_extend表中符合查询条件的user_id集合作为user表的查询条件。
因为使用的一对一关联,所以当user_extend没找到对应查询数据时,user表也不会有数据。
注意:
- hasWhere() 的第一个参数一定是user模型中关联用户扩展表的方法名称。
- with预载入查询中的关联模型中的名称是user模型中关联用户扩展表的方法名称,如果方法名是驼峰写法,也可以转换成下划线。如:userExtend => user_extend
<?php/**
* Created by PhpStorm
* Author: fengzi
* Date: 2024/6/26
* Time: 17:13*/namespace app\admin\controller\orm;useapp\common\model\UserModel;classOrmController
{/**
* @var UserModel|object|\think\App*/ private UserModel $userModel;public function__construct()
{$this->userModel = app(UserModel::class);
}public functionindex()
{/**
* with 关联查询一对一
* hasWhere第四个参数joinType的值:LEFT、RIGHT 或 INNER
* user表对user_extend表使用的hasOne
* 使用hasWhere查询user_extend表时,相当于把user_extend表中符合查询条件的user_id集合作为user表的查询条件。
* 因为使用的一对一关联,所以当user_extend没找到对应查询数据时,user表也不会有数据*/ $lists = $this->userModel->with(['user_extend'])->hasWhere('userExtend', function ($query){$query->where('organize_id', 1);
}, '*', 'LEFT')->select()->toArray();//输出打印 dd($lists);
}
}
1.3.1、查询结果展示
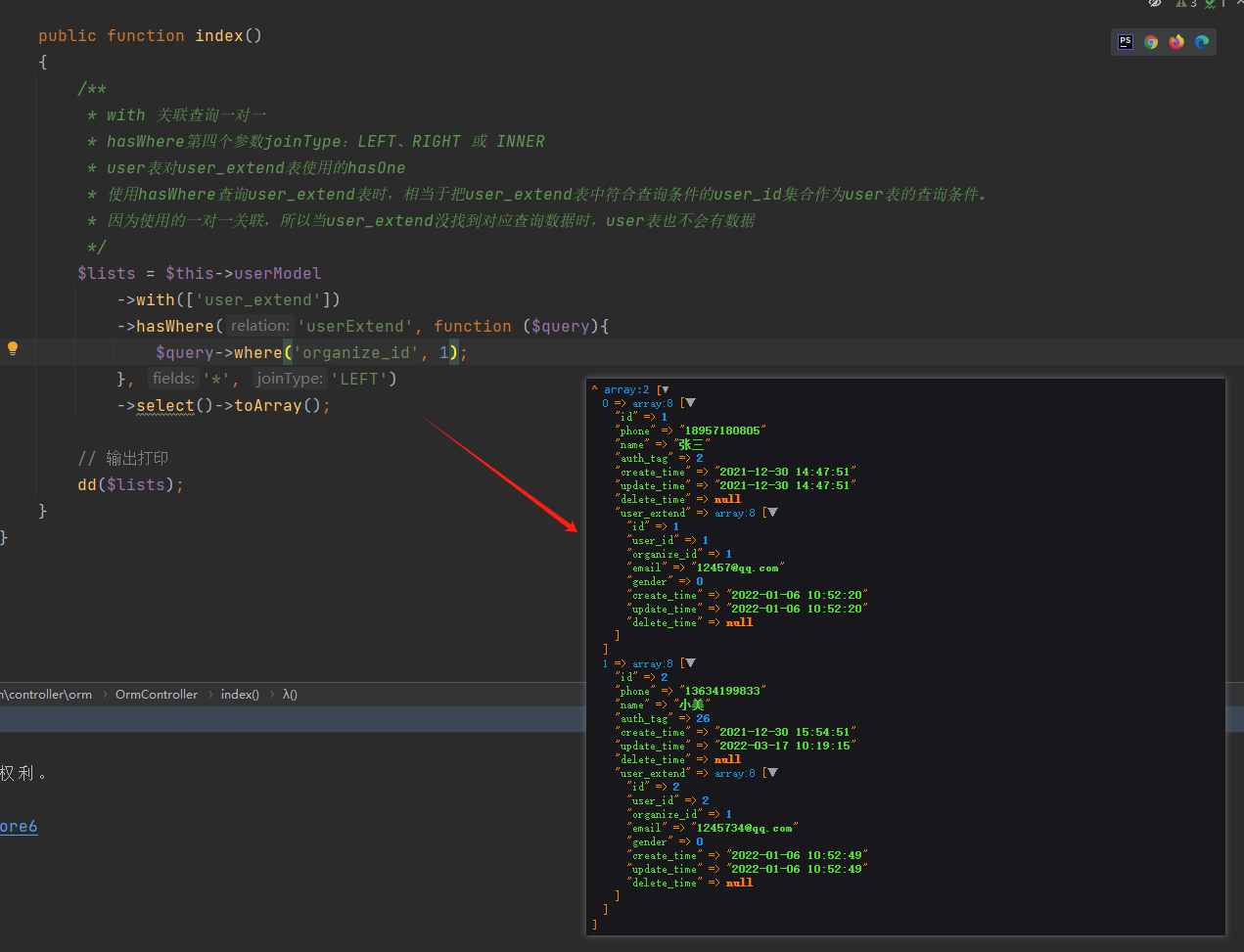
1.4、withJoin() 的查询( 我在user模型中定义的user_extend表的关联方法名称为userExtend ):
- withJoin(['user_extend”]):这种写法查询出来的关联表数据会和主表数据在同一层级。而关联表数据的展现方式会以user模型中定义的关联方法名称为前缀+下划线+表字段的形式呈现。
- 注意:【userExtend__xxx】中的下划线是两个,并不是一个下划线(一个下划线 _ ;两个下划线 __ )。所以在查询结果对象转换成数组后去获取字段数据时要注意,避免报错。
- 这个写法同级中还多了一个【user_extend】字段,其值为null。这个字段在两个数据表中都是不存在的。
- withJoin(['userExtend”]):这种写法査询出来的关联表数据与主表数据是有父子级关系。以withJoin中定义的模型名称“userExtend”作为主表的一个字段,把关联表的数据放入这个字段中。
public functionindex()
{//实例化模型 $userModel = app(UserModel::class);/**
* 联表数据和主表数据在同一级*/ $info = $userModel->withJoin(['user_extend'])->find(1);
dump($info->toArray());/**
* 联表数据是主表数据的一个子级,主/联表数据呈现父子级关系*/ $info = $userModel->withJoin(['userExtend'])->find(1);
dd($info->toArray());
}

1.4.1、withJoin的条件查询注意事项:
- 使用 withJoin() 做关联,进行条件查询的时候,只要使用 where() 方法进行条件筛选即可。
- 如果主/联表中有相同的字段且筛选条件就是相同的字段,使用 hasWhere() 方法进行条件筛选会报错。
- 如果主/联表中有相同的字段且筛选条件是
主表
中的字段,那么where条件应该这么写【where(['mkl_user.role_id'=>2])】。同时参数中的role_id要写明是哪个表,且带上表前缀。 - 如果主/联表中有相同的字段且筛选条件是
联表
中的字段,那么where条件应该这么写【where(['userExtend.role_id'=>3])】。同时参数中的role_id要写明是哪个关联表,关联名称跟【withJoin('userExtend')】的一样。
public functionindex()
{//实例化模型 $userModel = app(UserModel::class);/**
* where(['organize_id'=>3])
* 可以根据条件查询出结果
*
*
* hasWhere('userExtend', function ($query){
* $query->where('organize_id', 3);
* }, '*', 'LEFT')
* 不能查询出结果,报错“Illegal offset type”*/ $info = $userModel->withJoin(['user_extend'])->where(['organize_id'=>3])/*->hasWhere('user_extend', function ($query){
$query->where('organize_id', 3);
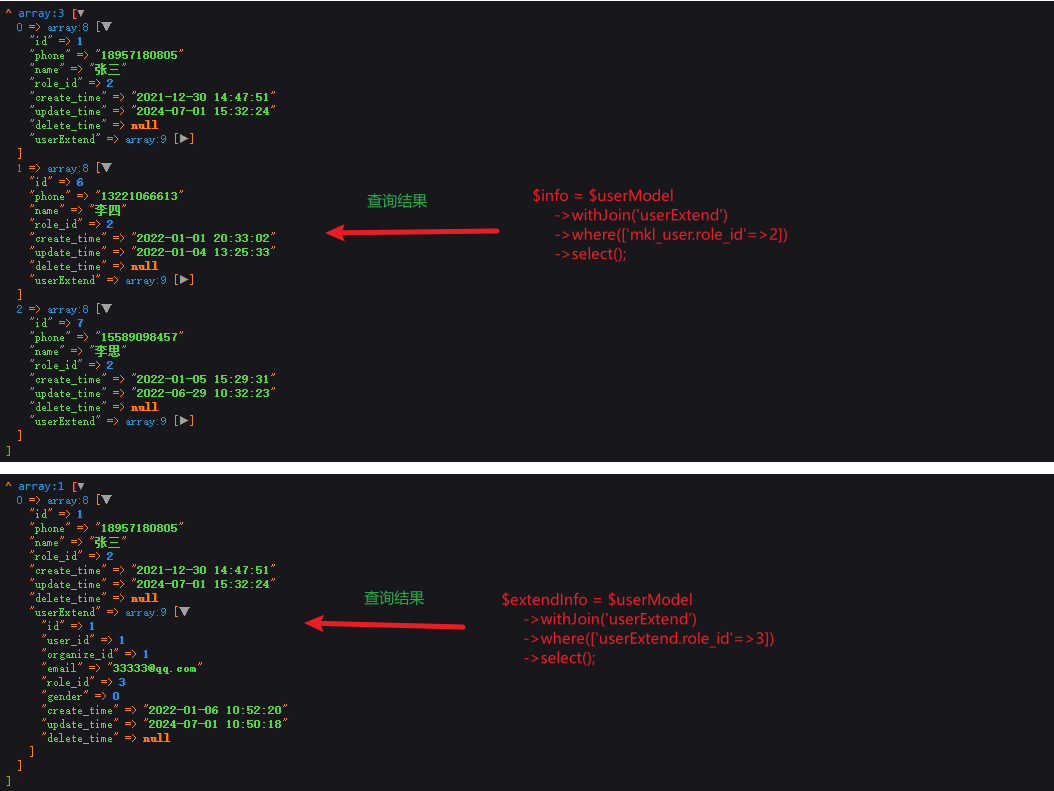
})*/ ->select();/*********** 以下是主/联表有相同字段(role_id字段相同)时的查询方式 ***********/
//要筛选主表(user表)中的相同字段时 $info = $userModel ->withJoin('userExtend')->where(['mkl_user.role_id'=>2])->select();//输出打印 dump($info->toArray());//要筛选关联表(user_extend表)中的相同字段时 $extendInfo = $userModel ->withJoin('userExtend')->where(['userExtend.role_id'=>3])->select();//输出打印 dd($extendInfo->toArray());
}
1.5、with 关联修改
关联修改的常见形式有两种:
- 方式一:把关联表要修改的数据写入一个数组中,使用save方法直接修改。
- 方式二:单独字段一个个赋值后,最后使用save方法进行修改。
注意:
- 不管是上面哪种,查询出来的对象不能转换成数组后进行关联表的修改,不然就会报错。
- with中的关联名称一般要与修改时一致。当然,不一致也可以,写模型中关联方法的名称也行。如:with使用user_extend,修改时使用userExtend也是可以的。
public functionindex()
{//关联查询 $info = $this->userModel->with(['user_extend'])->find(1);//输出打印 dump($info->toArray());//关联修改:方式一 /*$userExtend = [
'email' => '88888888@qq.com',
'gender' => 1,
];
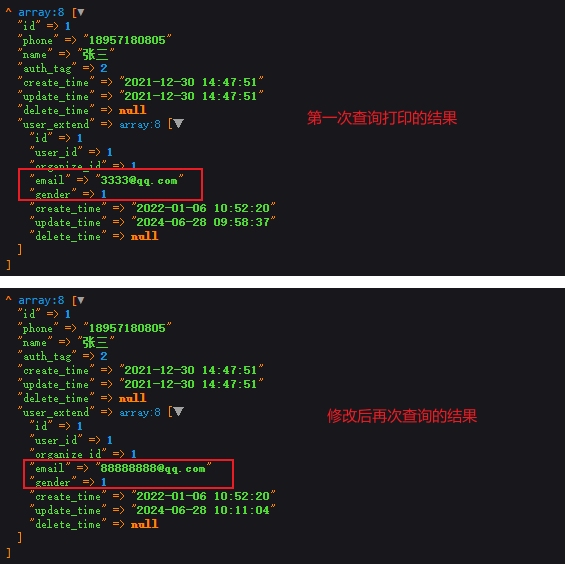
$info->user_extend->save($userExtend);*/ //关联修改:方式二 $info->userExtend->email = '88888888@qq.com';$info->userExtend->gender = 0;$info->userExtend->save();//再次关联查询 $newInfo = $this->userModel->with(['user_extend'])->find(1);//输出打印 dd($newInfo->toArray());
}
1.5.1、with关联修改后的结果
1.6、关联删除
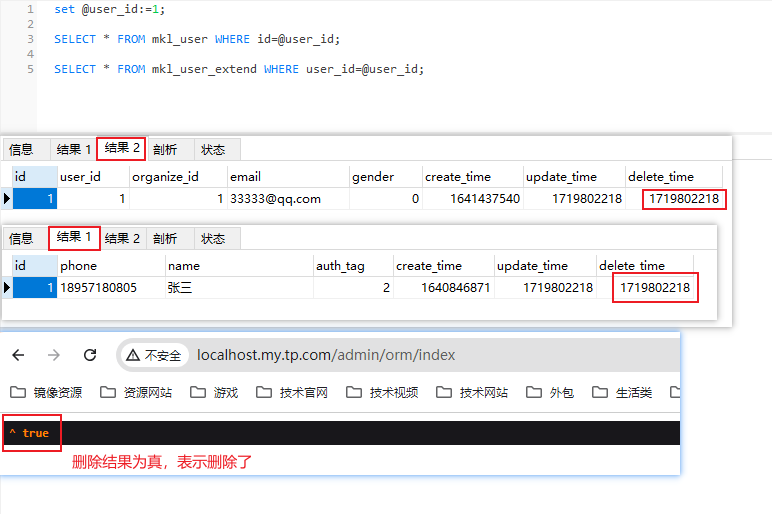
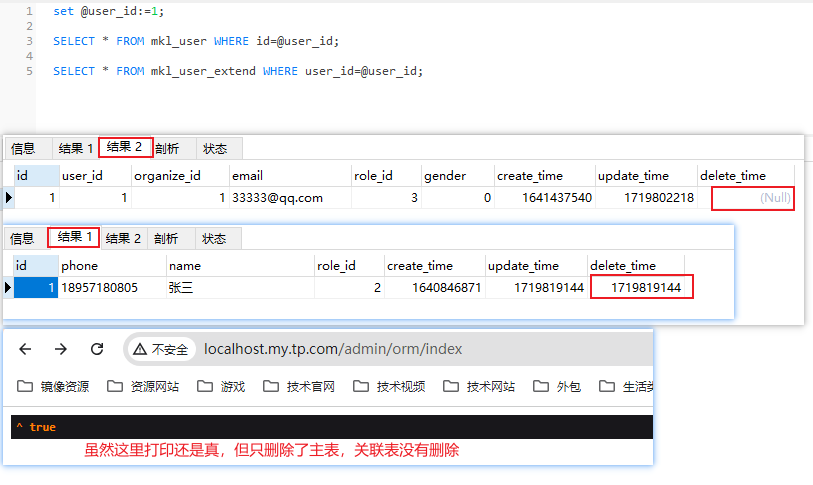
关联删除这里有一些小细节需要注意,下面我们用user_id=1的用户来试验。下图user_id=1的用户数据目前是没有删除的。

1.6.1、with 的关联删除
(1)这种写法能正确的删除主表和关联表的数据,需要注意的是【 with(['userExtend']) 】和【 together(['userExtend']) 】中的参数名称要一样,不能一个驼峰【userExtend】写法,另一个下划线【user_extend】写法。要么都写【userExtend】,要么都写【user_extend】。
public functionindex()
{//实例化模型 $userModel = app(UserModel::class);//查询用户ID=1的数据 $info = $userModel->with(['userExtend'])->find(1);//删除主表和关联表 $del = $info->together(['userExtend'])->delete();}
(2)这种写法在查询的时候没有带 with() 方法,那么在删除数据的时候,只能删除主表数据,关联表数据不会删除。
public functionindex()
{//实例化模型 $userModel = app(UserModel::class); //查询用户ID=1的数据 $info = $userModel->find(1);//删除主表和关联表 $del = $info->together(['userExtend'])->delete();// 输出打印 dd($del);
}
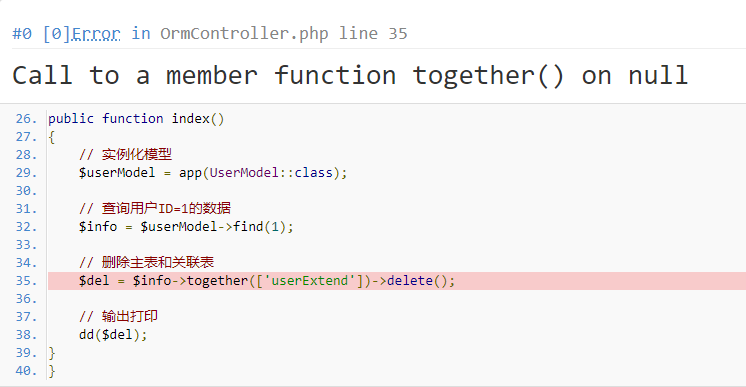
注意:当主表的数据已经被删除后,还调用 together() 进行主/联表的数据删除就会报错。
(3)当前代码中的方式一和方式二其实跟上面介绍的没什么区别,只是上面几个写法的链式操作。
- 方式一:只能删除主表数据,关联表数据不会删除。
- 方式二:可以同时删除主表和关联表的数据。
public functionindex()
{//实例化模型 $userModel = app(UserModel::class);//删除主表和关联表
// 方式一 $del = $userModel->find(1)->together(['userExtend'])->delete();//方式二 $del = $userModel->with(['userExtend'])->find(1)->together(['userExtend'])->delete();
}
1.6.2、withJoin 的关联删除
注意:
- 如果要主/联表的数据都删除,那么在查询的时候必须带 withJoin() 方法。
- 带 withJoin() 方法查询后,删除时 together() 和 withJoin() 方法的参数必须是 UserModel 模型中关联的方法名称,即本文1.2处的userExtend() 方法的名称。
- 如果不带 withJoin() 方法查询后,想要删除主/联表的数据是不可行的,这时删除只会删主表数据,联表数据是不会删除。
public functionindex()
{//实例化模型 $userModel = app(UserModel::class);/**
* withJoin(['user_extend']) together(['userExtend']) 主表数据删除,联表数据不会删除
* withJoin(['user_extend']) together(['user_extend']) 主表数据删除,联表数据不会删除
* withJoin(['userExtend']) together(['userExtend']) 主表数据删除,联表数据删除
* withJoin(['userExtend']) together(['user_extend']) 主表数据删除,联表数据不会删除*/ //查询用户ID=1的数据 $info = $userModel->withJoin(['userExtend'])->find(1);//删除主表和关联表 $del = $info->together(['userExtend'])->delete();
/**
* together(['user_extend']) 主表数据删除,联表数据不会删除
* together(['userExtend']) 主表数据删除,联表数据不会删除*/ //查询用户ID=1的数据 $info = $userModel->find(1);//删除主表和关联表 $del = $info->together(['userExtend'])->delete();}