DSCL:已开源,北京大学提出解耦对比损失 | AAAI 2024
监督对比损失(
SCL
)在视觉表征学习中很流行。但在长尾识别场景中,由于每类样本数量不平衡,对两类正样本进行同等对待会导致类内距离的优化出现偏差。此外,
SCL
忽略了负样本之间的相似关系的语义线索。为了提高长尾识别的性能,论文通过解耦训练目标来解决
SCL
的这两个问题,将
SCL
中的原正样本和增强正样本解耦并针对不同目标来优化他们的关系,从而减轻数据集不平衡的影响。论文进一步提出了一种基于块的自蒸馏方法,将知识从头类转移到尾类,以缓解尾类表征不足的问题。该方法挖掘不同实例之间共享的视觉模式,并利用自蒸馏过程来传输此类知识来源:晓飞的算法工程笔记 公众号
论文: Decoupled Contrastive Learning for Long-Tailed Recognition

Introduction
在实际应用中,训练样本通常呈现长尾分布,其中少数头类贡献了大部分观察结果,而许多尾类仅与少数样本相关。长尾分布给视觉识别带来了两个挑战:
- 为平衡数据集设计的损失函数很容易偏向头部类别。
- 每个尾部类别包含的样本太少,无法表示视觉差异,导致尾部类别的代表性不足。
通过优化类内和类间距离,监督对比损失(
SCL
)在平衡数据集上取得了很不错的性能。给定锚定图像,
SCL
将两种正样本聚在一起,即(a)由数据增强生成的锚定图像的不同视图,以及(b)来自同一类的其他图像。这两种类型的正样本监督模型学习不同的表征:(a)来自相同类别的图像强制学习语义线索,而(b)通过外观差异增强的样本主要导致低级外观线索的学习。

如图 1(a)所示,
SCL
有效地学习了头类的语义特征,例如,学习到的语义“蜜蜂”对于杂乱的背景具有鲁棒性。而如图 1 (b) 所示,
SCL
学习的尾部类别表征对于形状、纹理和颜色等低级外观线索更具辨别力。
通过对
SCL
的梯度进行分析后,论文提出了解耦监督对比损失(
DSCL
)来处理这个问题。具体来说,
DSCL
解耦了两种正样本,重新制定了类内距离的优化策略,缓解了两种正样本的梯度不平衡。如在图 1(b)所示,
DSCL
学习到的特征对语义线索具有区分性,并且大大提高了尾部类别的检索性能。
为了进一步缓解长尾分布的挑战,论文提出了基于图像块的自蒸馏(
PBSD
),利用头类来促进尾类中的表征学习。
PBSD
采用自蒸馏策略,通过挖掘不同类之间的共享视觉模式并将知识从头类迁移到尾类,更好地优化类间距离。论文引入块特征来表示目标的视觉模式,计算块特征和实例级特征之间的相似度以挖掘共享视觉模式。如果实例与基于块特征共享视觉模式,则它们将具有很高的相似性,然后利用自蒸馏损失来维持样本之间的相似关系,并将知识融入到训练中。
Analysis of SCL
后面的分析有点长,总结起来,论文发现了
SCL
的三个问题:
- 过于关注头类的训练。
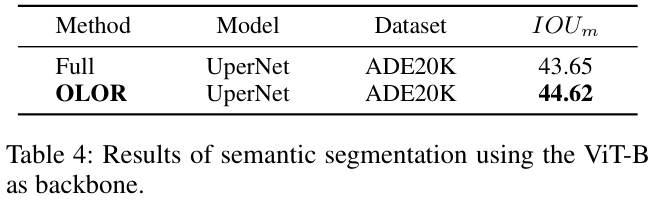
- 原样本和增强样本之间的梯度存在差异。
- 负样本可以更好地处理。
给定训练数据集
\(D=\lbrace x_{i},y_{i}\rbrace_{i=1}^{n}.\)
,其中
\(x_{i}\)
表示图像,
\(y_{i}\ \in\ \left\{1,\cdot\cdot\cdot,\ K\right\}\)
是其类标签。假设
\({n}^k\)
表示
\({\mathcal{D}}\)
中
\(k\)
类的数量,并且类的索引按数量降序排序,即如果
\(a < b\)
,则
\(n^{a}\geq n^{b}\)
。在长尾识别中,训练数据集是不平衡的,即
\(n^1\gg n^{K}\)
,不平衡比的计算为
\(n^{1}/n^{K}\)
。
对于图像分类任务,算法旨在学习特征提取主干
\(\mathrm{v}_{i} = \mathrm{f}_\theta(\mathrm{x}_i)\)
和线性分类器,先将图像
\(\mathrm{x}_{i}\)
映射为全局特征图
\(\mathrm{u}_{i}\)
并使用全局池化来获取
\(d\)
维特征向量,随后将特征向量分为
\(k\)
维分类分数。通常来说,测试数据集是平衡的。
特征提取主干一般采用监督对比学习(
SCL
)来训练。给定锚定图像
\(\mathrm{x}_{i}\)
,定义
\(\mathrm{z}_{i}=\mathrm{g}_{\gamma}({v}_{i})\)
为用主干和额外投影头
\(\mathrm{g}_{\gamma}\)
提取的归一化特征,
\(\mathrm{z}^{+}_{i}\)
为正样本
\(\mathrm{x}_{i}\)
通过数据增强生成的图片的归一化特征。定义
\(M\)
为可通过内存队列获取的一组样本特征,
\(P_{i}=\{\mathrm{z}_t\in M:y_t=y_i\}\)
为从
\(M\)
中抽取的
\(\mathrm{x}_{i}\)
的正样本特征集。
SCL
通过拉近锚定图像与其它正样本来减小类间距离,同时通过将具有不同类别标签的图像推开来扩大类间距离,即
\[
\mathcal{L}_{s c l}=\frac{-1}{|P_{i}|+1}\sum\limits_{\mathrm{z}_{t}\in\{\mathrm{z}_{i}^{+}\cup P_{i}\}}\log p(\mathrm{z}_{t}|\mathrm{z}_{i}),
\quad\quad(1)
\]
其中
\(|P_{i}|\)
是
\(P_{i}\)
的数量。使用
\(\tau\)
来表示预定义的温度参数,条件概率
\(p(\mathrm{z}_{t}\vert\mathrm{z}_{i})\)
的计算如下:
\[p(\mathrm{z}_{t}\vert\mathrm{z}_{i})={\frac{\exp(\mathrm{z}_{t}\cdot\mathrm{z}_{i}/\tau)}{\sum\limits_{\mathbf{z}_{m}\epsilon(\mathrm{z}_{i}^{+}\cup M)}\exp(\mathrm{z}_{m}\cdot\mathrm{z}_{i}/\tau)}}.
\quad\quad(2)
\]
公式 1 可以表示为分布对齐任务,
\[
\mathcal{L}_{align}={\sum\limits_{\mathrm{z}_t\in\{\mathrm{z}_{i}^{+}\cup M\}}}-\hat{p}({\mathrm{z}_t|\mathrm{z}_i})\log\hat{p}({\mathrm{z}_t|\mathrm{z}_i}).
\quad\quad(3)
\]
其中
\(\hat{p}({\mathrm{z}_t|\mathrm{z}_i})\)
是目标分布的概率。对于增强
\(\mathrm{z}^+_i\)
和原
\(\mathrm{z}_{t}\in P_{i}\)
,
SCL
将它们同等地视为正样本,并将其目标概率设置为
\(1/(|P_{i}|+1)\)
。对于
\(M\)
中其它具有不同类标签的图像,
SCL
将它们视为负样本,并将其目标概率设置为 0。
对于锚定图像
\(\mathrm{z}_{i}\)
的特征
\(\mathrm{x}_{i}\)
,
SCL
的梯度为:
\[
\begin{align}
\frac{\partial\mathcal{L}_{scl}}{\partial{{\mathrm{z}_{i}}}} = \frac{1}{\tau} &
\{
\sum\limits_{\mathrm{z}_j\in N_i}p(\mathrm{z}_j|\mathrm{z}_i)+\mathrm{z}_i^{+}(p(\mathrm{z}_i^{+}|\mathrm{z}_i))-\frac{1}{|P_i|+1}) \notag
\\
& +\sum\limits_{\mathrm{z}_t\in P_i}\mathrm{z}_t(p(\mathrm{z}_t|\mathrm{z}_i)-\frac{1}{|P_i|}+1)\} \notag
\end{align}
\quad\quad(4)
\]
其中
\(N_{i}\)
是
\(\mathrm{x}_{i}\)
的负集,包含从
\(\{\mathrm{z}_{j}\ \in\ M\ : \mathrm{y}_{j}\ \ne\ \mathrm{y}_{i}\}\)
中提取的特征。
SCL
包含两种类型的正样本
\(\mathrm{z}_i^{+}\)
和
\(z_{t}\in P_{i}\)
,锚定图像对于两种正样本的梯度计算分别为:
\[\begin{align}
& \left.\frac{\partial\mathcal{L}_{scl}}{\partial{\mathrm{z}_{i}}}\right|_{\mathrm{z}_i^{+}}={{\mathrm{z}_{i}}^{+}}(p(\mathrm{z}_{i}^{+}\vert\mathrm{z}_{i})-\frac{1}{{\vert{P_{i}}\vert}+1}), \notag
\\
& \left.\frac{\partial\mathcal{L}_{scl}}{\partial{\mathrm{z}_{i}}}\right|_{\mathrm{z}_i}={{\mathrm{z}_{i}}}(p(\mathrm{z}_{i}\vert\mathrm{z}_{i})-\frac{1}{{\vert{P_{i}}\vert}+1}),\mathrm{z}_t\in P_i. \notag
\end{align}
\quad\quad(5)
\]
训练开始时,两种正样本的梯度
L2
范数之比为,
\[
\frac{\left\Vert\left.\frac{\partial\mathcal{L}_{scl}}{\partial{\mathrm{z}_{i}}}\right|_{\mathrm{z}_i^{+}}\right\Vert_2}{\sum\limits_{\mathrm{z}_t\in P_i}\left\Vert\left.\frac{\partial\mathcal{L}_{scl}}{\partial{\mathrm{z}_{i}}}\right|_{\mathrm{z}_i}\right\Vert_2}
\approx
\frac{1}{P_i}.
\quad\quad(6)
\]
当
SCL
收敛时,
\(\mathrm{z}_{i}^{+}\)
的最优条件概率为:
\[
p(\mathrm{z}_{i}^{+}|\mathrm{z}_{i})={\frac{1}{|P_{i}|+1}}.
\quad\quad(7)
\]
在
SCL
中,内存队列
\(M\)
是从训练集中均匀采样的,这导致
\(|P_{i}|\approx{\frac{n^{y_{i}}}{n}}|M|\)
。在平衡数据集中,
\(n^{1}\;\approx\;n^{2}\;\approx\cdots\;\approx\;n^{K}\)
,不同类别的
\(|P_{i}|\)
数量是平衡的。对于具有不平衡
\(|P_{i}|\)
的长尾数据集,
SCL
则会更加关注将头部类的锚点
\({\mathrm{z}}_{i}\)
与从
\(P_{i}\)
得到的特征拉在一起,因为梯度由公式 4 中的第三项主导。
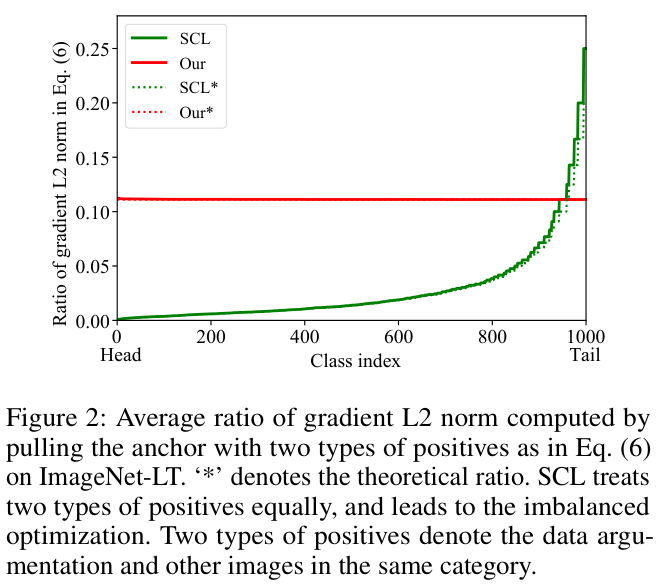
另外,
SCL
还存在两种正样本的梯度的
L2
范数的比例不平衡的问题,如图 2 所示。当
SCL
的训练收敛时,
\({p}({\mathrm{z}_{i}^{+}|\mathrm{z}_{i})}\)
的最优值也受到
\(\left|{{P}}_{i}\right|\)
的影响,如公式 7 所示。此外,如图 1(a) 和 (b) 所示,跨类别学习到的特征也不一致。
等式 4 还表明,
SCL
均匀地推开所有负样本,从而扩大了类间距离。这种策略忽略了不同类别之间有价值的相似性线索。为了寻求更好的方法来优化类内和类间距离,论文提出了解耦监督对比损失(
DSCL
)来解耦两种正样本以防止有偏差的优化,以及基于补丁的自蒸馏(
PBSD
)来利用类之间的相似性线索。
Decoupled Supervised Contrastive Loss
DSCL
的提出是为了确保不同类别的类内距离进行更平衡的优化,将两种正样本解耦并添加不同的权重,使梯度
L2
范数比和
\(p(z_{i}^{+}|z_{i})\)
的最优值不受类别的样本数量影响。
DSCL
可表示为:
\mathcal{L}_{dscl}=\frac{-1}{|P_{i}|+1}\sum\limits_{\mathrm{z}_{i}\in\{\mathrm{z}_{i}^{+}\cup P_{i}\}}\log \frac{\exp w_{t}(\mathrm{z}_{t}\cdot \mathrm{z}_{i}/\tau)}{\sum\limits_{\mathrm{z}_{m}\in \{ \mathrm{z}_{i}^{+}\cup M \}}\exp (\mathrm{z}_{m}\cdot \mathrm{z}_{i}/\tau)},
\quad\quad(8)
\]
w_{t}=\left\{\begin{array}{l l}{{\alpha(|P_{i}|+1),}}&{{\mathrm{z}_{t}=\mathrm{z}_{i}^{+}}}
\\
{{{\frac{(1-\alpha)(|P_{i}|+1)}{|P_{i}|}},}}&{{\mathrm{z}_{t}\in P_{i}}}\end{array}\right.
\quad\quad (9)
\]
其中
\(\alpha\in[0,1]\)
是预定义的超参数。
DSCL
是
SCL
在平衡环境和不平衡环境的统一范式。如果数据集是平衡的,通过设置
\(\alpha = 1/(|P_{i}|\,+\,{\bf1})\)
可以使得
DSCL
与
SCL
相同。
训练开始时,两种正样本的梯度
L2
范数比为:
\frac{\left\Vert\left.\frac{\partial\mathcal{L}_{dscl}}{\partial{\mathrm{z}_{i}}}\right|_{\mathrm{z}_i^{+}}\right\Vert_2}{\sum\limits_{\mathrm{z}_t\in P_i}\left\Vert\left.\frac{\partial\mathcal{L}_{dscl}}{\partial{\mathrm{z}_{i}}}\right|_{\mathrm{z}_i}\right\Vert_2}
\approx
\frac{\alpha}{1-\alpha}.
\quad\quad(10)
\]
当
DSCL
收敛时,
\(\mathrm{z}\)
的最优条件概率为
\(p(\mathrm{z}_{i}^{+}|{\mathrm{z}_i})=\alpha\)
。
如公式 10 可以看出,两种正样本的梯度比不受
\(|P_{i}|\)
的影响。
DSCL
也保证了
\(p(\mathrm{z}_{i}^{+}|{\mathrm{z}_i})\)
的最优值不受
\(|P_{i}|\)
的影响,从而缓解了头部类和尾部类之间特征学习不一致的问题。
Patch-based Self Distillation
视觉模式可以在不同的类之间共享,例如视觉模式“车轮”在“卡车”、“汽车”和“公共汽车”共享。因此,尾类中的许多视觉特征也可以从共享这些视觉模式的头类中学习,从而降低了尾类表征学习的难度。
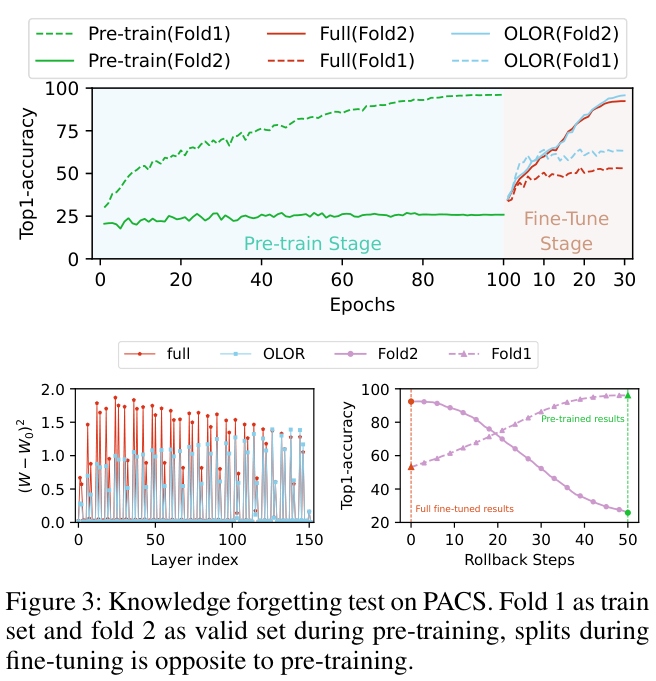
SCL
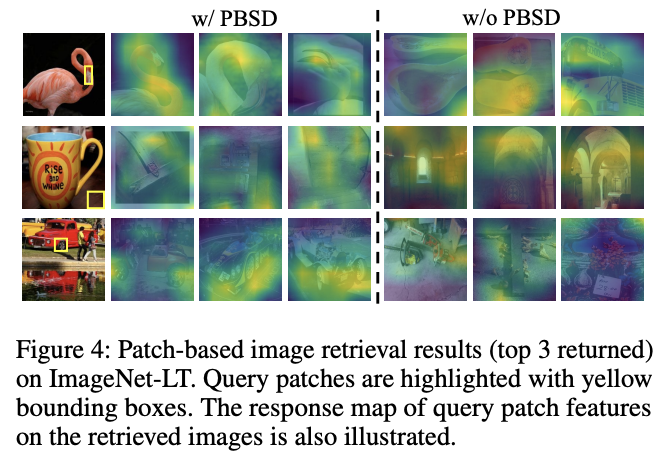
将来自不同类的两个实例在特征空间中推开,不管它们是否共享有意义的视觉模式。如图 4 所示,从黄色边界框中提取查询块特征,并从数据集中检索前 3 个相似样本。由
w/o PBSD
标记的
SCL
检索结果在语义上与查询块无关,表明
SCL
在学习和利用图像块级语义线索方面无效。
受细粒度图像识别中基于图像块的方法的启发,论文引入了基于图像块的特征来编码视觉模式。给定主干提取的图像
\(\mathrm{x}_{i}\)
的全局特征图
\(\mathrm{u}_{i}\)
,首先随机生成块
\(\{B_i[j]\}^L_{j=1}\)
,其中
\(L\)
是块的数量。根据这些块的坐标应用
ROI
池化并将池化特征发送到投影头中,得到归一化的嵌入特征
\(\{c_i[j]\}^L_{j=1}\)
:
c_i[j]=\mathrm{g}_{\gamma}(\mathrm{ROI}(\mathrm{u}_i,\mathrm{B}_i[j])).
\quad\quad(11)
\]
然后,类似于公式 2 利用条件概率计算实例之间的相似关系:
p(\mathrm{z}_{t}|\mathrm{c}_{i}^{j})=\frac{\exp(\mathrm{z}_{t}\cdot\mathrm{c}_{i}[j]/\tau)}{\sum\limits_{\mathrm{z}_{m}\in \{ \mathrm{z}_{i}^{+}\cup M \}}\mathrm{exp}(\mathrm{z}_{m}\cdot\mathrm{c}_{i}[j]/\tau)}.
\quad\quad(12)
\]
如果
\(\mathrm{z}_{t}\)
对应的图像与基于块的特征共享视觉模式,则
\(\mathrm{z}_{t}\)
和
\(\mathrm{c}_{i}\left[j\right]\)
将具有很高的相似度。因此,使用公式 12 可对每对实例之间的相似性线索进行编码。
基于上述定义,将相似性线索作为知识来监督训练过程。为了保持这些知识,论文还根据
\(\{B_i[j]\}^L_{j=1}\)
额外从图像中裁剪多个图像块(前面直接从整图的全局特征做
ROI
,这里剪图过网络),并使用主干网络提取其特征嵌入
\(\{s_i[j]\}^L_{j=1}\)
:
\quad\quad(13)
\]
PBSD
强制图像块的特征嵌入通过以下损失,产生与基于块的特征相同的相似度分布,
\quad\quad(14)
\]
请注意,
\(p(\mathrm{z}_{t}|\mathrm{c}_{i}[j])\)
与计算图分离以阻止梯度。
物体的局部视觉模式可以由不同类共享,因此可以使用基于块的特征来表示视觉模式。
\({p}(\mathrm{z}_{t}|\mathrm{c}_{i}[j])\)
是为了挖掘图像之间共享模式的关系而计算的,通过最小化公式 14 来传递知识给
\({p}(\mathrm{z}_{t}|\mathrm{s}_{i}[j])\)
,缓解尾类表征性不足的问题。图 4 所示的检索结果表明,
PBSD
有效地加强了块级特征和图像块与图像相似性的学习,使得挖掘不同类别的共享视觉模式成为可能。
Multi-crop
技巧通常用于自监督学习中以生成更多锚图像的增强样本,采用低分辨率截图以降低计算复杂性。与
Multi-crop
策略不同,
PBSD
的动机是利用头类和尾类之间的共享模式来帮助尾类的学习,通过
ROI
池化得到基于块的特征来获得共享模式。公式 14 执行自蒸馏以维持共享模式。论文通过用
Multi-crop
技巧代替
PBSD
进行了对比实验,
ImageNet-LT
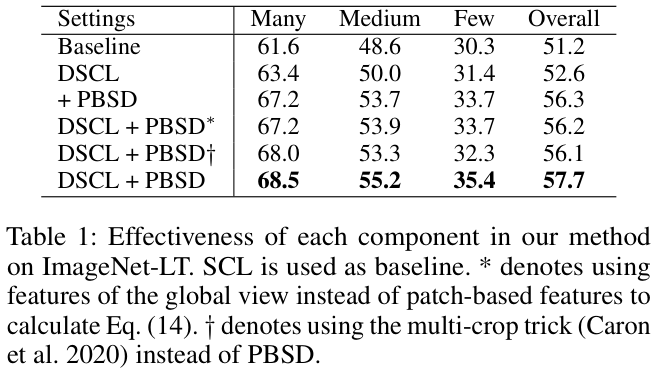
上的性能从 57.7% 下降到 56.1% ,表明
PBSD
比
Multi-crop
策略更有效。
Training Pipeline
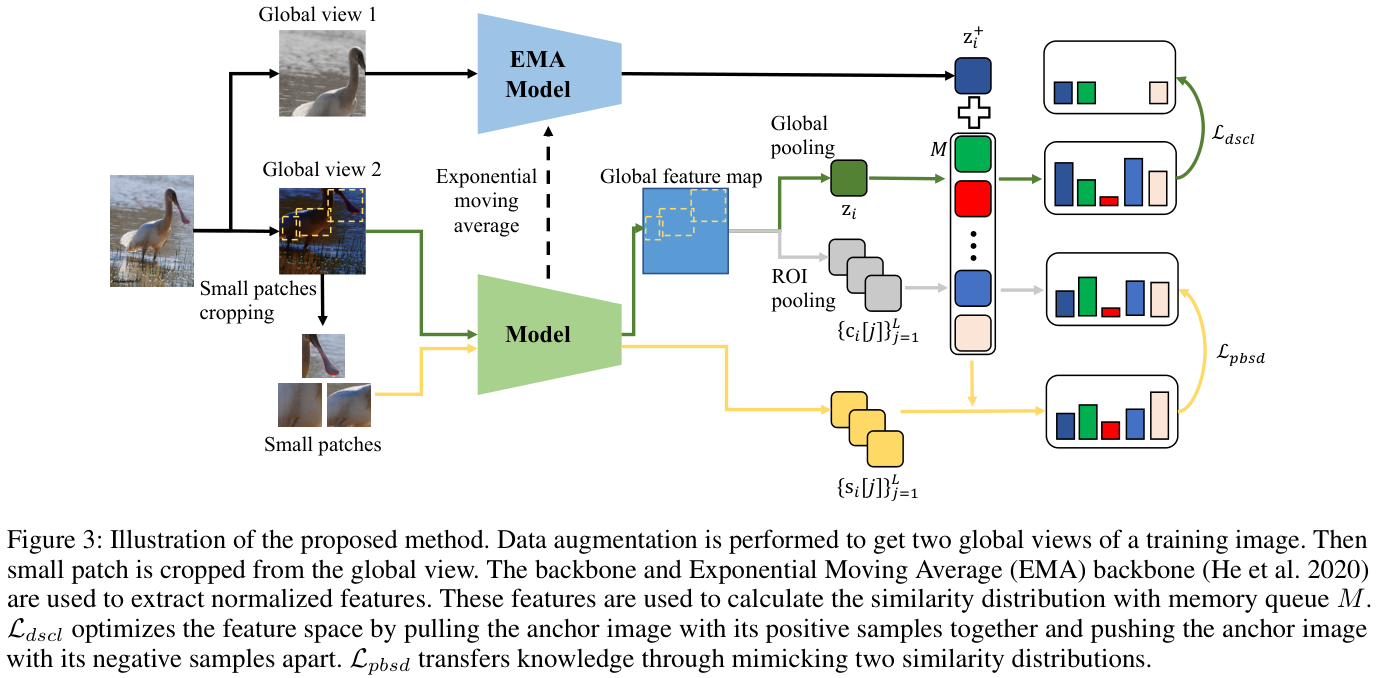
整体训练逻辑如图 3 所示,为了维护内存队列,使用动量更新模型。训练由两个损失来监督,即解耦监督对比损失和基于块的自蒸馏损失:
\quad\quad(15)
\]
论文的方法专注于表征学习,并且可以通过添加对应的损失来在不同的任务中使用。在主干训练之后,丢弃学习的投影头
\(\mathrm{g}_\gamma(\cdot)\)
并使用标准交叉熵损失在预训练的主干之上基于类平衡抽样策略训练线性分类器。
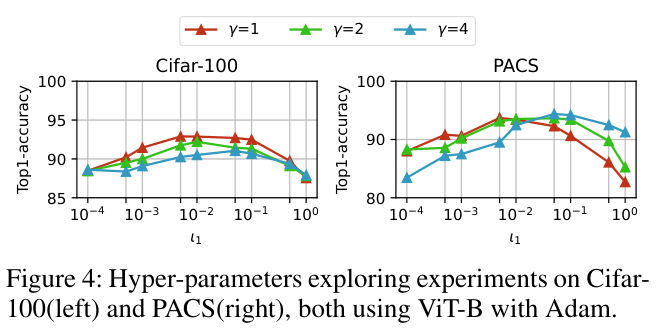
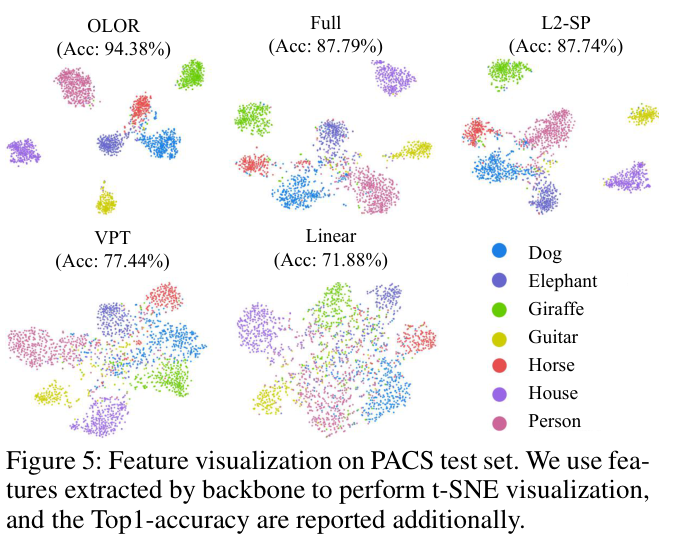
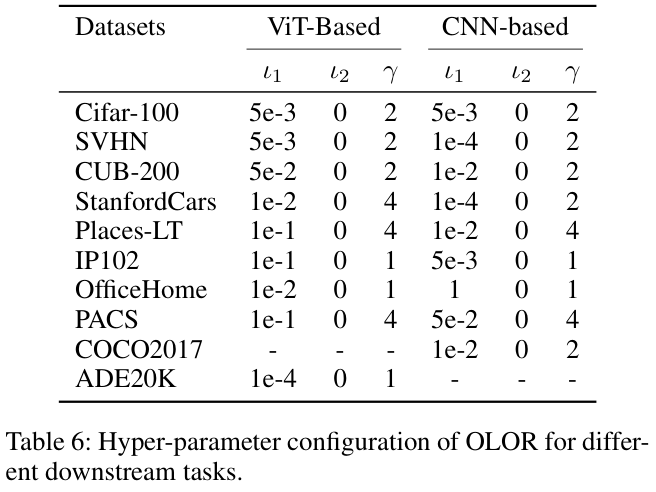
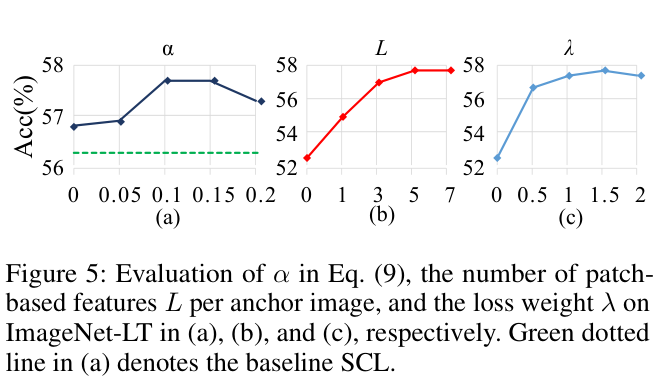
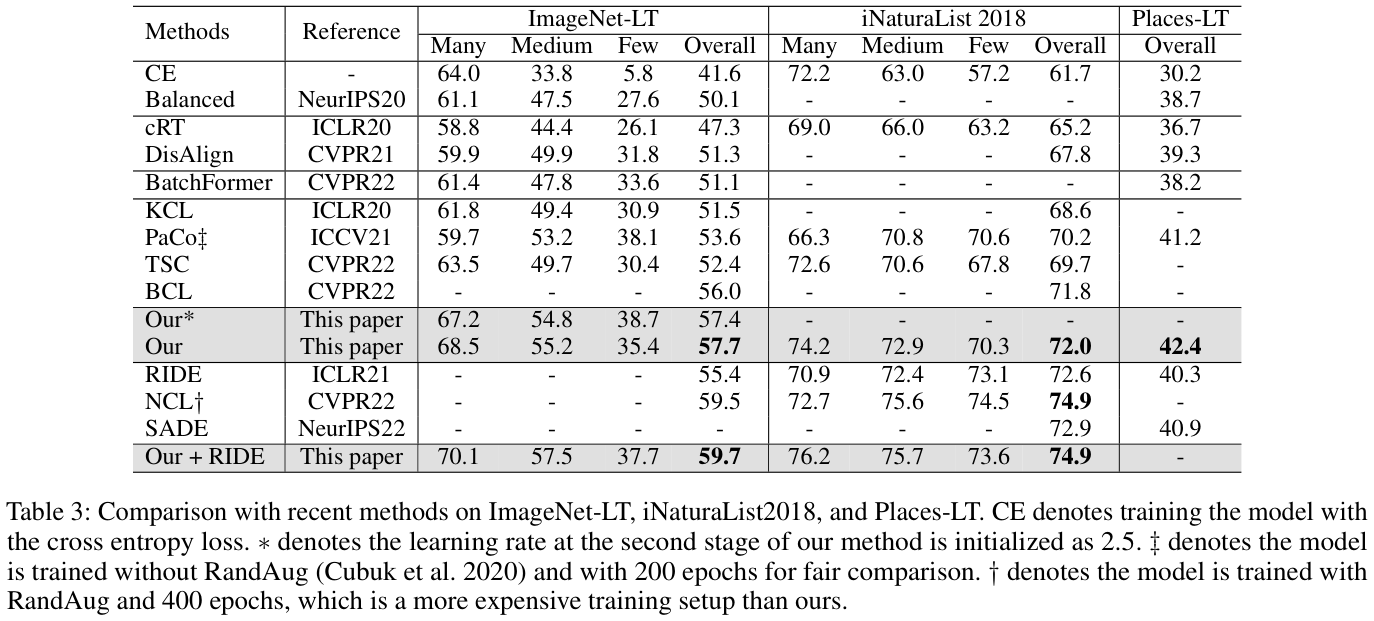
Experiments
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】