解密prompt系列34. RLHF之训练另辟蹊径:循序渐进 & 青出于蓝
前几章我们讨论了RLHF的样本构建优化和训练策略优化,这一章我们讨论两种不同的RL训练方案,分别是基于过程训练,和使用弱Teacher来监督强Student
循序渐进:PRM & ORM
- Solving math word problems with processand
outcome-based feedback- PRM:Let's verify step by step
- https://github.com/openai/prm800k
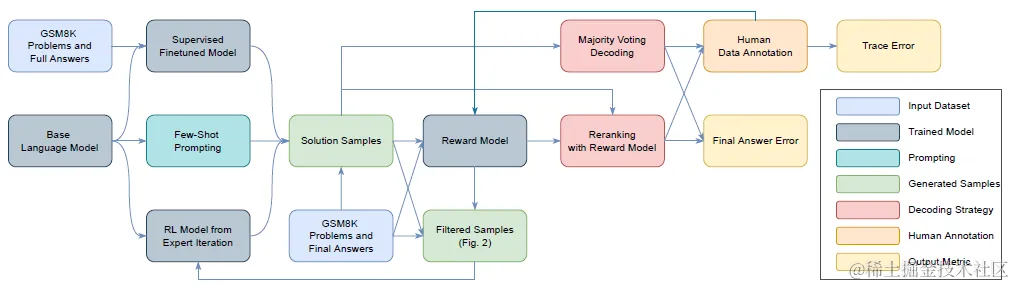
### 数据标注
想要获得过程监督所需的标注样本,其实是一件成本很高事情,因为需要对解题的每一个步骤是否正确进行标注。论文选择了3分类的label,positive是推理正确合理,negative是步骤错误或逻辑错误,neural是模糊或者存在误导。如下

为了让高昂的标注过程产生最大的价值,这里需要保证生成解题样本的格式规范(容易拆分成多个解题步骤),以及样本不能全是easy negative或者easy positive。也就是我们需要解决
推理格式
和
样本筛选
问题。
为了保证稳定的推理格式,这里论文训练了Generator,使用'\n'来分割每一步解题步骤。为了避免这一步微调导致样本信息泄露,论文使用few-shot构建格式正确的推理样本后,过滤了答案正确的样本,只使用答案错误但格式正确的样本训练Generator。更大程度保证微调只注入推理格式,不注入额外数学知识和推理信息。
在样本筛选步骤,论文使用当前最优的PRM模型筛选打分高,但是答案错误的
Convincing wrong answer
答案,来构建更难,过程监督信号更多,且PRM对当前解题过程一定存在至少一步判断错误的样本,来进行人工标注。
既然看到这里是使用PRM打分筛选样本来训练PRM,自然使用到了Iterated Training,也就是会先构建一波样本训练一个PRM,用新训练好的PRM,对问题的N个回答进行打分,再筛选Top K的Convincing wrong answer去进行人工标注,再训练PRM,这个过程总共迭代了10次。最终得到了
PRM800K解题步骤
的训练样本,包括从12K问题中采样得到的75K答案。
ORM的训练样本就简单很多,只需要用到问题的答案即可。不过考虑到上面PRM对样本进行了有偏筛选得到的大多是答案错误的样本,因此ORM的样本是在相同问题上用Generator重新随机生成的。所以ORM和PRM的回答样本并不相同。
训练和推理
训练阶段,ORM是预测最终答案正确与否的positive/negative分类目标;PRM的目标是预测每一个解题步骤的positive/neural/negative,这里论文没有做任何解题步骤前后关联,单纯
把每个解题步骤独立作为一个分类样本进行训练
,因此和ORM一样是分类任务。论文同时提到因为预训练LM和分类CLM的目标差异巨大,因此
低LR的训练得到的PRM更加稳定,不论模型大小都只训练2个Epoch
这里虽然感觉PRM这个每个解题步骤条件独立的假设有一些强,但确实如果按不独立来标注,那标注成本会再高一个数量级,也是不太现实~
推理阶段,论文给出了两种PRM的推理方案。一种是使用PRM计算每一步推理正确的概率,再把多个推理步骤的得分求积,得到每个答案唯一的打分,用来比较同一个问题多个回答之间的优劣。一种是预测第一个错误的步骤,这样PRM和ORM会先对可比,对于对的回答二者的预测都是全对,对于错的回答,二者的预测都是存在有错误的步骤,只不过PRM会进一步给出错误的具体位置。
效果
效果上论文使用Best-of-N的Major Voting作为基准,来对比PRM和ORM筛选答案的正确率,如下图,随着采样答案N的数量增加,PRM相比ORM和Major-Voting的相对优势会越来越显著。
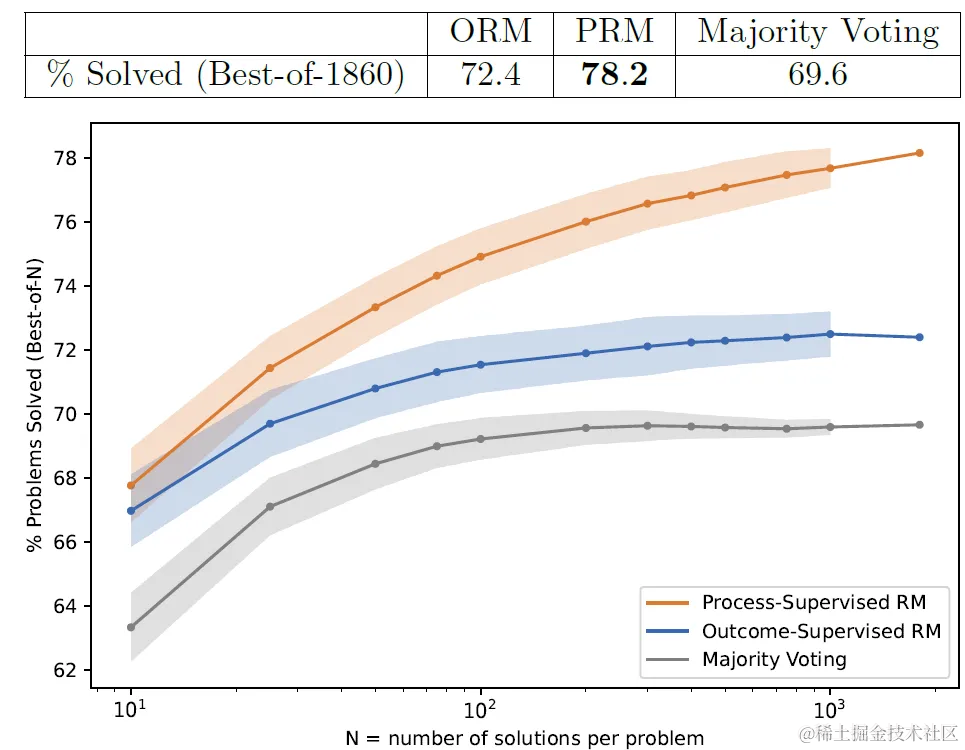
考虑以上ORM和PRM训练数据集并不相同,不算严格的对比实验,之后论文还做了相对可比的消融实验,这里不再赘述。
除了直观的效果对比,PRM相比ORM还有几个对齐优势
- redit Assignment
:针对复杂问题PRM能提供错误具体产生的位置使得进一步的迭代修改,变得更加容易,因此PRM的奖励打分的边际价值更高 - Safer
:PRM针对COT的过程进行对齐,相比只对齐结果(可能存在过程错误)的一致性更高,个人感觉是reward hacking的概率会相对更低,因为对齐的颗粒度更细 - negative Alignment Tax
: 论文发现PRM似乎不存在对齐带来的效果下降,甚至还有效果提升。
青出于蓝:weak-to-strong
- WEAK-TO-STRONG GENERALIZATION: ELICITING STRONG CAPABILITIES WITH WEAK SUPERVISION
- https://github.com/openai/weak-to-strong
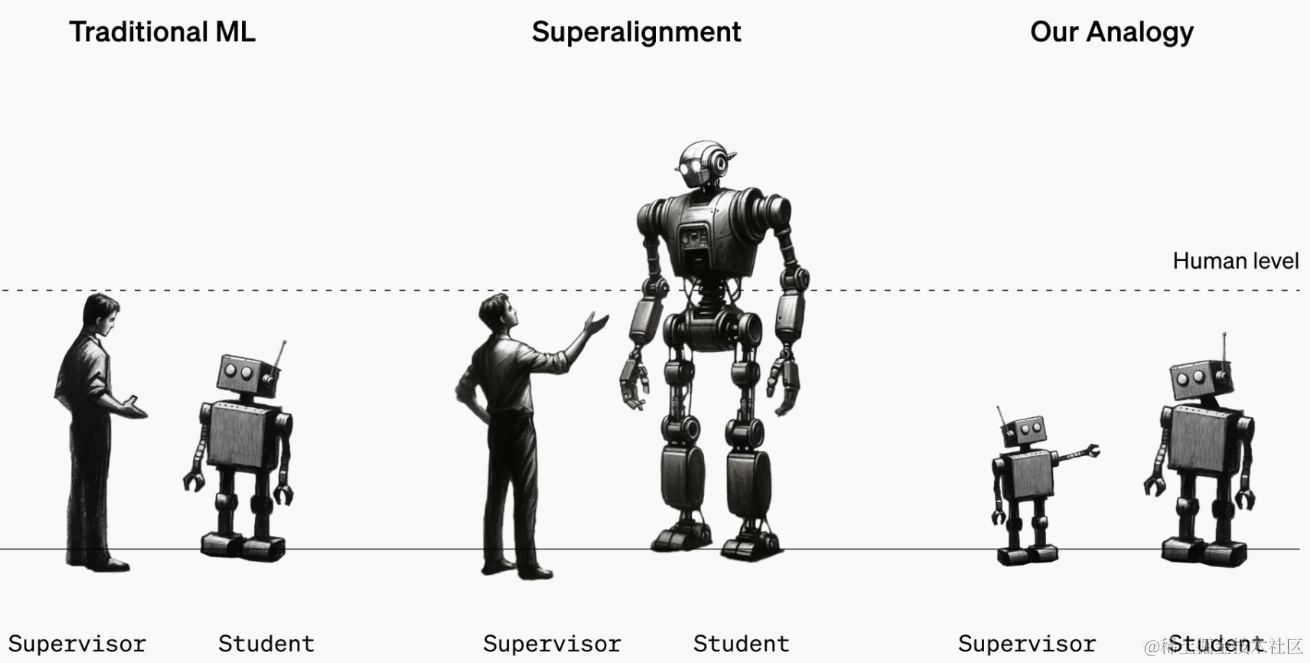
weak-to-strong是openAI对齐团队在23年年终交出的答卷。论文的本质是对超级对齐问题进行一个简化的讨论,也就是当大模型的能力越来越强甚至超越人类的时候,人类的监督是否还能有效指导模型行为,保证模型的安全性和指令遵从性。以及这种弱监督该如何进行?
所以超级对齐本质是一个“弱-监督-强”的问题,而论文进行的简化,就是把人类监督超级模型的问题,类比简化成一个弱模型监督强模型的过程,即所谓“Weak-to-Strong Generalization”
论文的思路其实和前几年曾经火过的弱监督,半监督,带噪学习的思路非常相似。就是在任务标签上训练弱模型,然后使用训练后的弱模型进行打标,再使用模型打标的标签来训练强模型,看强模型的效果能否超越弱模型。逻辑上弱监督半监督,其实是提高模型在unseen样本上的泛化能力,而OpenAI这里研究的Weak-to-Strong更多是模型能的泛化。
论文可以分成两个部分,使用常规微调测试weak-to-strong的泛化效果,以及探索如何提升weak-to-strong的泛化,下面我们来分别说下
Experiment
首先论文选择了三种任务类型来测试模型泛化效果
- NLP分类任务: 22个包括NLI,分类,CR,SA在内的NLP分类任务。这类任务可能大小模型表现都不错,模型越大效果会有提升但不明显
- Chees Puzzles:象棋挑战预测下一步最佳下法的。这类任务可能有比较明显的模型规模效应,小模型做不了,得模型大到一定程度后效果会越来越好
- ChatGPT Reward Model: 预测pair-wise的人类更偏好的模型回答。这类任务现在没啥模型效果好,大的小的都一般
其次就是在以上数据集上,分别进行以下训练
- weak supervisor:使用以上数据训练小模型得到Teacher模型
- Weak-to-strong:使用以上弱模型在held-out数据集上预测得到label,并使用这些弱监督的标签来训练一个更大更强的模型
- strong ceiling:使用以上任务的样本直接训练强模型得到模型能力上限
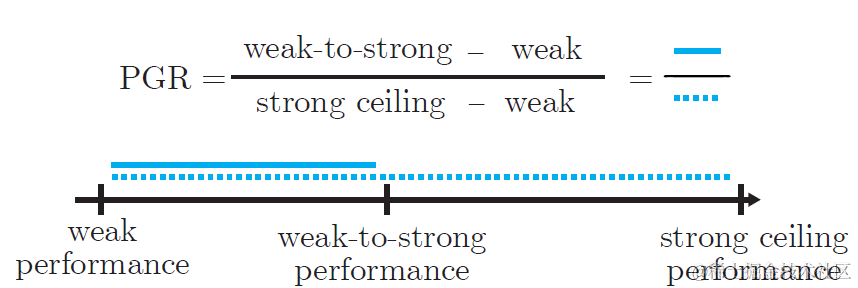
以上得到的三个模型效果理论上应该是weak-supervisor < weak-to-strong < strong-ceiling,最后论文通过计算弱监督训练帮助强模型恢复的能力占比来衡量weak-to-strong监督的泛化效果,既Performance-Gap-Recovered(PGR)
以下为直接微调的实验结果,下图分别展示了不同模型大小的strong student(横轴),weak teacher(颜色),在以上三个任务上的任务准确率,和对应的PGR用来衡量weak-to-strong的泛化效果。
- NLP任务:最小的Teacher训练大许多倍的Student也能恢复20%以上的能力,随Teacher和Student的大小增大,PGR都会有提升
- Chess Puzzle任务上,当Teacher模型较小的时候,Student几乎学不到任何信息。而随着Teacher变大,PGR会有显著提升,但是随着Student变大任务准确率和PGR反而会有下降。可能存在inverse scaling
- ChatGPT Reward任务上,随着Teacher增大,Student的任务准确率会有提升,但泛化PGR几乎都不会超过20%。
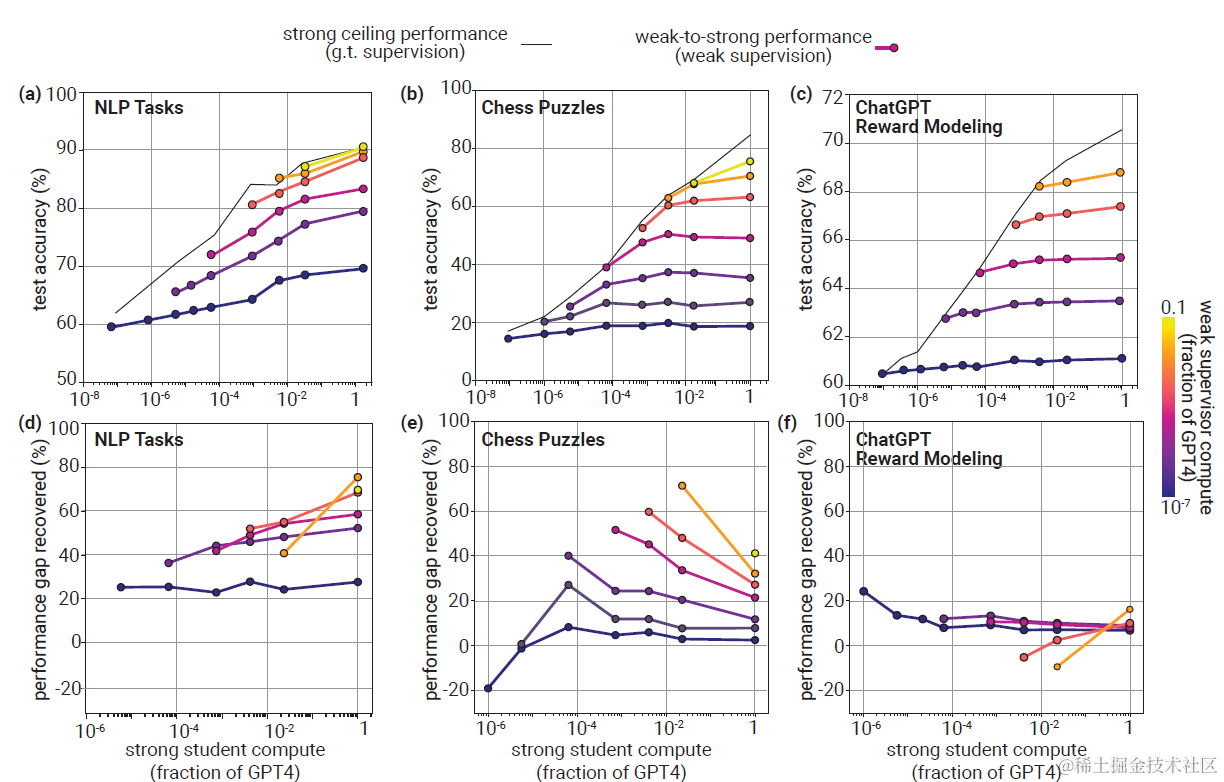
这里三种任务的泛化差异,其实和前面提到的三种任务本身难度,以及和模型大小的相关性有关。如果从噪声学习的角度来讨论的话,NLP任务和模型大小相关性低,且标签噪声较小;Chess Puzzle和单模型大小以及stduent-teacher之间的gap相关性都很大,teacher标签噪声,以及student-teacher预测的一致性都随模型scale变化;reward任务都很一般,和模型大小没啥关系。
整体上通过直接微调,能稳定获得一定的能力泛化(PGR>0),但泛化效果并不好。于是下面论文讨论了能否通过改变训练方案来提高weak-to-strong的泛化效果。
Improvement
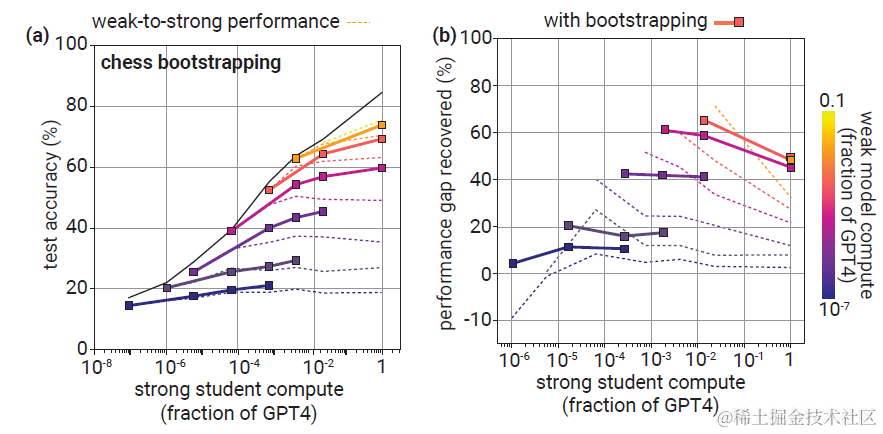
方案一:Bootstraping
采用渐进训练的方案,也就是我们可以先用小模型对齐略大一些的模型,再用略大一些的模型来对齐更大一些的模型,然后逐步迭代下去。这种训练方式可能更适合上面Chess Puzzle的任务,考虑该任务存在Inverse Scaling,既当Student比Teacher大的越多,weak-to-strong的泛化效果越差,那我们可以逐步放大Student模型的大小,保持Teacher和Student之间的gap不要太大。
效果上不难发现对比以上的inverse scaling的PGR变化,在相同的Teacher模型上,我们可以获得几乎持平的PGR泛化效果,也就意味着更小的模型可以帮助更大的模型恢复相同比例(但绝对值更大) 的能力。这里论文统一采用了3次迭代,也就是会训练两个中间大小的模型。
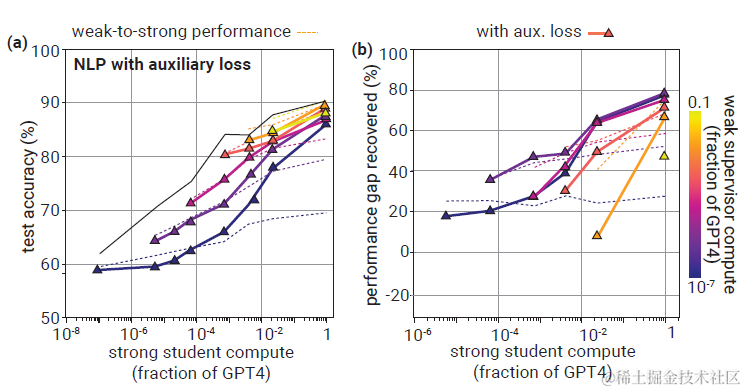
方案二:Regularization
如果我们想让大模型学习的时候,只学习小模型在任务上获得的Insight,而不是简单的去模仿小模型,可以通过加入正则项的方法。用的是半监督学习里面的最小熵原则,和Pseudo Label的损失函数是近似的,不熟悉的同学看这里
小样本利器3. 半监督最小熵正则
也就是在原始的交叉熵(左)的基础上,加上了student模型的预测熵值,这里f(x)是训练中的大模型,而t是一个动态阈值,是batch内样本预测概率的中位数,这样大模型即便不去学习Teacher模型,通过提高自己对预测样本的置信度(自信一点!你是对的),也可以降低损失函数。
\]
以上损失函数还可以改写为噪声损失函数中的Bootstrap Loss, 不熟悉的同学看这里
聊聊损失函数1. 噪声鲁棒损失函数
。也就是Student学习的label是由Teacher的预测label,和student模型自己预测的label混合得到的。逻辑也是一样,如果这个问题你对自己的预测很自信,那请继续自信下去!
\]
以上正则项的加入在NLP任务上,当student和teacher之间的gap较大时,能显著提高weak-to-strong的泛化效果,即便最小的Teacher也能恢复近80%的大模型效果,说明降低student无脑模仿teacher的概率是很有效的一种学习策略。
Why Generalization
最后论文讨论了为何存在weak-to-strong泛化,以及在什么场景下存在。这是一个很大的问题,论文不可能穷尽所有的场景,因此有针对性的讨论了模仿行为和student模型本身对该任务是否擅长。这里简单说下主要的结论吧
Imitation
这里论文分别通过过拟合程度,以及student和teacher的预测一致性来衡量大模型是否无脑拟合了teacher模型。并提出了合适的正则项,以及early stopping机制可以降低模仿,提高泛化Sailency
论文提出当强模型本身通过预训练对该任务已经有很好的任务学习(表征)的情况下,泛化会更好。这里个人感觉有些像DAPT,TAPT(domain/taskadaptive pretraining)的思路,不熟悉的同学看这里
预训练不要停!Continue Pretraining
。从文本表征空间分布的角度来说,就是当模型对该任务文本所在空间分布本身表征更加高维
线性可分,边界更加清晰平滑
时,模型更容易泛化到该任务上。
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >>
DecryPrompt










