如何用 WinDbg 调试Linux上的 .NET程序
一:背景
1. 讲故事
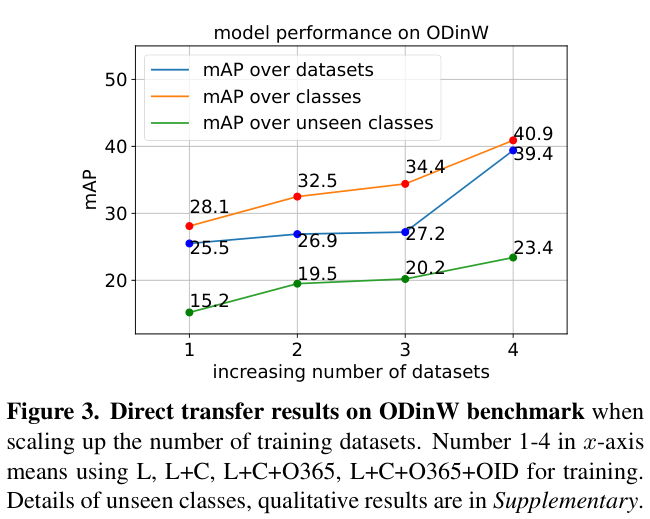
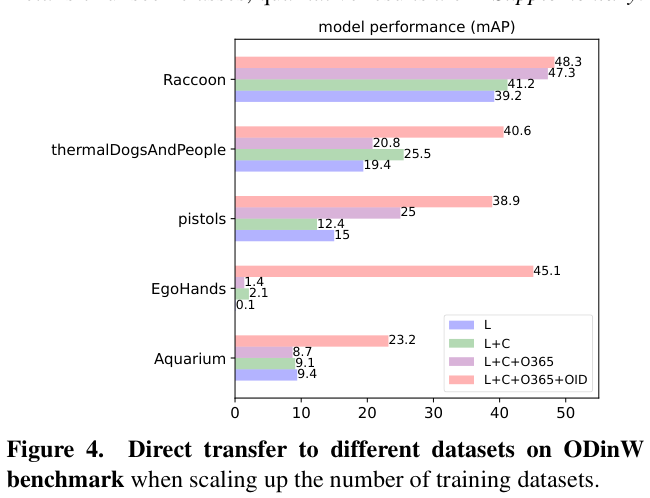
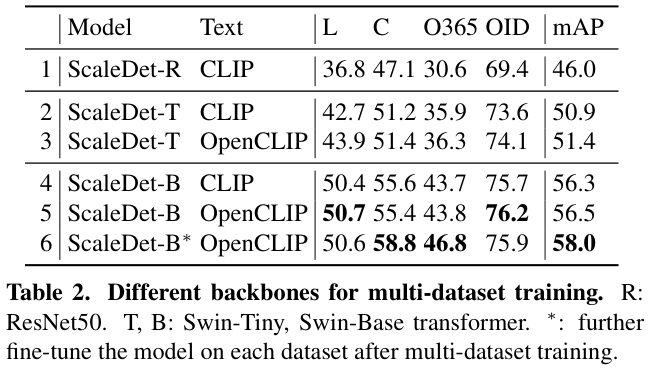
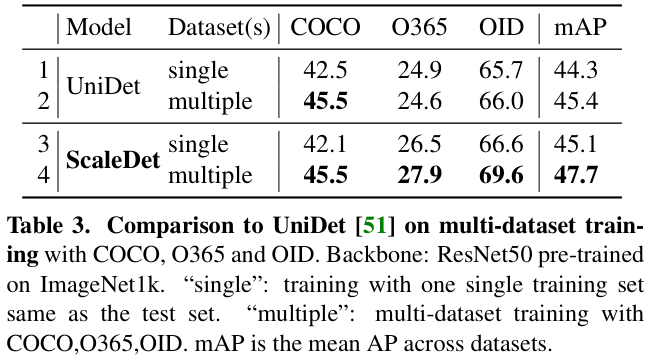
最新版本
1.2402.24001.0
的WinDbg真的让人很兴奋,可以将自己伪装成 GDB 来和远程的 GDBServer 打通来实现对 Linux 上 .NET程序进行调试,这样就可以继续使用熟悉的WinDbg 命令,在这个版本中我觉得 WinDbg 不再是 WinDbg,而是 XDbg 了,画个简图如下:

简图有了,接下来就要付出实践了。
二:实操 Linux 上 .NET调试
1. 测试程序
本想在 CentOS7 上安装 .NET8,不大好装,这里就用一个现存的 .NETCore 3.1 吧,测试代码如下:
internal class Program
{
static void Main(string[] args)
{
while (true)
{
Console.WriteLine($"{DateTime.Now},tid={Thread.CurrentThread.ManagedThreadId}");
Thread.Sleep(1000);
}
}
}
代码非常简单,就是1s输出一条记录,接下来编译成x64部署到 Centos7 上。
[root@localhost data]# ls
ConsoleApp7 ConsoleApp7.deps.json ConsoleApp7.dll ConsoleApp7.pdb ConsoleApp7.runtimeconfig.json
2. 安装GDBServer
在 linux 上安装 gdbserver 比较简单,使用 yum 安装即可
yum install gdb-gdbserver
,输出如下:
[root@localhost data]# yum install gdb-gdbserver
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
* base: mirror-hk.koddos.net
* centos-sclo-rh: ftp.sjtu.edu.cn
* centos-sclo-sclo: ftp.sjtu.edu.cn
* epel: mirror.hoster.kz
* extras: ftp.sjtu.edu.cn
* updates: mirror-hk.koddos.net
Package gdb-gdbserver-7.6.1-120.el7.x86_64 already installed and latest version
Nothing to do
[root@localhost data]# gdbserver –version
Usage: gdbserver [OPTIONS] COMM PROG [ARGS ...]
gdbserver [OPTIONS] --attach COMM PID
gdbserver [OPTIONS] --multi COMM
COMM may either be a tty device (for serial debugging), or
HOST:PORT to listen for a TCP connection.
Options:
--debug Enable general debugging output.
--remote-debug Enable remote protocol debugging output.
--version Display version information and exit.
--wrapper WRAPPER -- Run WRAPPER to start new programs.
--once Exit after the first connection has closed.
安装好之后,接下来用 gdbserver 来启动我们的程序,并启动调试端口为 1234,参考如下:
[root@localhost data]# gdbserver 192.168.128.130:1234 dotnet ConsoleApp7.dll
Process dotnet created; pid = 3643
Listening on port 1234
3. 使用 windbg 连接
打开Windbg后,选择
Connect to remote debugger
选项, 在连接字符串中填入
gdb:server=192.168.128.130,port=1234
即可,截图如下:

连接好之后,会有一个初始中断,直接输入g就好了,输出如下:
64-bit machine not using 64-bit API
************* Path validation summary **************
Response Time (ms) Location
Deferred SRV*C:\mysymbols*https://msdl.microsoft.com/download/symbols
Symbol search path is: SRV*C:\mysymbols*https://msdl.microsoft.com/download/symbols
Executable search path is:
Unknown System Version 0 UP Free x64
System Uptime: not available
Process Uptime: not available
Reloading current modules
ModLoad: 00005555`55554000 00005555`555770cd /usr/share/dotnet/dotnet
ModLoad: 00007fff`f7bbf000 00007fff`f7dda488 /lib64/libpthread.so.0
ModLoad: 00007fff`f79bb000 00007fff`f7bbe130 /lib64/libdl.so.2
ModLoad: 00007fff`f76b3000 00007fff`f79ba420 /lib64/libstdc++.so.6
ModLoad: 00007fff`f73b1000 00007fff`f76b2138 /lib64/libm.so.6
ModLoad: 00007fff`f719b000 00007fff`f73b0400 /lib64/libgcc_s.so.1
ModLoad: 00007fff`f6dcd000 00007fff`f719a200 /lib64/libc.so.6
ModLoad: 00007fff`f7ddb000 00007fff`f7ffe150 /lib64/ld-linux-x86-64.so.2
ModLoad: 00007fff`f7f72000 00007fff`f7fda288 /usr/share/dotnet/host/fxr/6.0.26/libhostfxr.so
ModLoad: 00007fff`f6b7c000 00007fff`f6dcc3b0 /usr/share/dotnet/shared/Microsoft.NETCore.App/3.1.32/libhostpolicy.so
ModLoad: 00007fff`f63e7000 00007fff`f6b7bac8 /usr/share/dotnet/shared/Microsoft.NETCore.App/3.1.32/libcoreclr.so
ModLoad: 00007fff`f61df000 00007fff`f63e6c38 /lib64/librt.so.1
ModLoad: 00007fff`f57d2000 00007fff`f59dd8c0 /lib64/libnuma.so.1
ModLoad: 00007fff`f3142000 00007fff`f3413dac /usr/share/dotnet/shared/Microsoft.NETCore.App/3.1.32/libclrjit.so
ModLoad: 00007fff`f2f31000 00007fff`f3141468 /usr/share/dotnet/shared/Microsoft.NETCore.App/3.1.32/System.Native.so
ModLoad: 00007fff`f2d26000 00007fff`f2f30488 /usr/share/dotnet/shared/Microsoft.NETCore.App/3.1.32/System.Globalization.Native.so
ModLoad: 00007fff`f29ad000 00007fff`f2d25fe0 /lib64/libicuuc.so.50
ModLoad: 00007fff`f13da000 00007fff`f29ac030 /lib64/libicudata.so.50
ModLoad: 00007fff`f0fdb000 00007fff`f13d9340 /lib64/libicui18n.so.50
...................
ReadVirtual() failed in GetXStateConfiguration() first read attempt (error == 0.)
Unable to load image /lib64/libpthread.so.0, Win32 error 0n2
*** WARNING: Unable to verify timestamp for /lib64/libpthread.so.0
Unable to load image /usr/share/dotnet/shared/Microsoft.NETCore.App/3.1.32/libcoreclr.so, Win32 error 0n2
*** WARNING: Unable to verify timestamp for /usr/share/dotnet/shared/Microsoft.NETCore.App/3.1.32/libcoreclr.so
libpthread_so!_pthread_cond_timedwait+0x132:
00007fff`f7bcade2 4989c6 mov r14,rax
0:000> g
有些人可能会好奇,为什么 WinDbg 能伪装成 GDB 来和 GDBServer 来通讯,这其实得益于 WinDbg 是一个宿主,它可以被很多外来的插件无线扩容自己的功能,这和 Linux 的分而治之恰恰相反。。。
接下来可以用
.chain
命令观察插件列表,其中的
GDBServerComposition
和
ELFBinComposition
让这项功能得到实现。
0:000> .chain
Extension DLL chain:
GDBServerComposition: image 10.0.27553.1004, API 0.0.0,
[path: C:\Program Files\WindowsApps\Microsoft.WinDbg_1.2402.24001.0_x64__8wekyb3d8bbwe\amd64\winext\GDBServerComposition.dll]
ELFBinComposition: image 10.0.27553.1004, API 0.0.0,
[path: C:\Program Files\WindowsApps\Microsoft.WinDbg_1.2402.24001.0_x64__8wekyb3d8bbwe\amd64\winext\ELFBinComposition.dll]
dbghelp: image 10.0.27553.1004, API 10.0.6,
[path: C:\Program Files\WindowsApps\Microsoft.WinDbg_1.2402.24001.0_x64__8wekyb3d8bbwe\amd64\dbghelp.dll]
uext: image 10.0.27553.1004, API 1.0.0,
[path: C:\Program Files\WindowsApps\Microsoft.WinDbg_1.2402.24001.0_x64__8wekyb3d8bbwe\amd64\winext\uext.dll]
接下来就可以做验证了,研究 coreclr 源码,你会发现在 Linux 上 .NET 的 Sleep 函数是借助于底层的
pthread_cond_timedwait
函数,Linux并没有提供类似Windows 的SleepEx这样的系统调用,这就比较坑了,参考如下:
PAL_ERROR CPalSynchronizationManager::ThreadNativeWait(
ThreadNativeWaitData* ptnwdNativeWaitData,
DWORD dwTimeout,
ThreadWakeupReason* ptwrWakeupReason,
DWORD* pdwSignaledObject)
{
//...
while (FALSE == ptnwdNativeWaitData->iPred)
{
if (INFINITE == dwTimeout)
{
iWaitRet = pthread_cond_wait(&ptnwdNativeWaitData->cond,
&ptnwdNativeWaitData->mutex);
}
else
{
iWaitRet = pthread_cond_timedwait(&ptnwdNativeWaitData->cond,
&ptnwdNativeWaitData->mutex,
&tsAbsTmo);
}
}
//...
}

不管怎么说,我们用 WinDbg 调试 Linux 的 .NET 程序算是大功告成了。
三:总结
现在的 WinDbg 早已今非昔比,全平台(MacOs,Linux,Windows) 通吃,这也得益于 Windbg 是一个宿主模式的架构体系,给 WinDbg 点赞!