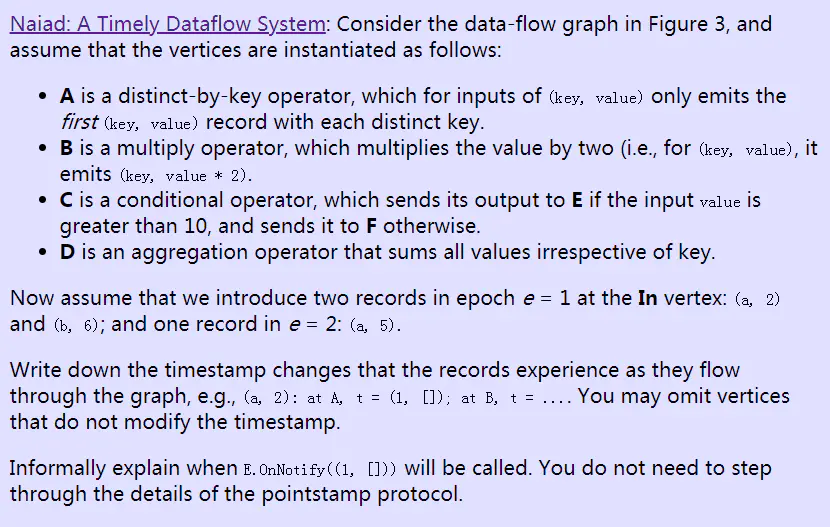
一转眼go1.23都快发布了,时间过得真快。
不过今天我们把时间倒流回三年半之前,来关注一个在go1.16引入的关于处理目录时的优化。
对于go1.16的新变化,大家印象最深的可能是io包的大规模重构,但这个重构实际上还引进了一个优化,这篇文章要说的就是这个优化。
本文默认Linux环境,不过这个优化在BSD系统上也是通用的。
遍历目录时的优化
遍历目录是个很常见的需求,尤其是对于有大量文件的目录来说,遍历的性能直接关系到了整体程序的性能。
go1.16对于遍历目录增加了几个新接口:
os.ReadDir
,
(*os.File).ReadDir
,
filepath.WalkDir
。
这几个接口最大的特征是对目录项使用
fs.DirEntry
表示而不是
os.FileInfo
。
fs.DirEntry
是一个接口,它提供了类似
os.FileInfo
的方法:
type DirEntry interface {
Name() string
IsDir() bool
Type() FileMode
Info() (FileInfo, error)
}
它还提供了一个叫Info的方法以便获得
os.FileInfo
。
这个接口有什么神奇的呢?我们看下性能测试:
func IterateDir(path string) int {
// go1.16 的 os.ReadDir 就是这么实现的,为了测试我们把它展开成对(*os.File).ReadDir的调用
f, err := os.Open(path)
if err != nil {
panic(err)
}
defer f.Close()
files, err := f.ReadDir(-1)
if err != nil {
panic(err)
}
length := 0
for _, finfo := range files {
length = max(length, len(finfo.Name()))
}
return length
}
func IterateDir2(path string) int {
// 1.16之前遍历目录的常用方法之一
f, err := os.Open(path)
if err != nil {
panic(err)
}
defer f.Close()
files, err := f.Readdir(-1)
if err != nil {
panic(err)
}
length := 0
for _, finfo := range files {
length = max(length, len(finfo.Name()))
}
return length
}
func BenchmarkIter1(b *testing.B) {
for range b.N {
IterateDir("../test")
}
}
func BenchmarkIter2(b *testing.B) {
for range b.N {
IterateDir2("../test")
}
}
test目录是一个有5000个文件的位于Btrfs文件系统上的目录,我们的测试用例会遍历目录并找出名字最长的文件的文件名长度。
这是测试结果:

可以看到优化后的遍历比原先的快了480%。换了个函数为什么就会有这么大的提升?想知道答案的话就继续看吧。
优化的原理
继续深入前我们先看看老的接口是怎么获取到目录里的文件信息的。答案是遍历目录拿到路径,然后调用
os.Lstat
获取完整的文件信息:
func (f *File) Readdir(n int) ([]FileInfo, error) {
if f == nil {
return nil, ErrInvalid
}
_, _, infos, err := f.readdir(n, readdirFileInfo)
if infos == nil {
// Readdir has historically always returned a non-nil empty slice, never nil,
// even on error (except misuse with nil receiver above).
// Keep it that way to avoid breaking overly sensitive callers.
infos = []FileInfo{}
}
return infos, err
}
这个
f.readdir
会根据第二个参数的值来改变自己的行为,根据值不同它会遵循1.16前老代码的行为或者采用新的优化方法。这个函数不同系统上的实现也不同,我们选则*nix系统上的实现看看:
func (f *File) readdir(n int, mode readdirMode) (names []string, dirents []DirEntry, infos []FileInfo, err error) {
...
for n != 0 {
// 使用系统调用获得目录项的数据
// 目录项的元信息一般是存储在目录本身的数据里的,所以读这些信息和读普通文件很类似
if d.bufp >= d.nbuf {
d.bufp = 0
var errno error
d.nbuf, errno = f.pfd.ReadDirent(*d.buf)
runtime.KeepAlive(f)
if errno != nil {
return names, dirents, infos, &PathError{Op: "readdirent", Path: f.name, Err: errno}
}
if d.nbuf <= 0 {
break // EOF
}
}
buf := (*d.buf)[d.bufp:d.nbuf]
reclen, ok := direntReclen(buf)
if !ok || reclen > uint64(len(buf)) {
break
}
// 注意这行
rec := buf[:reclen]
if mode == readdirName {
names = append(names, string(name))
} else if mode == readdirDirEntry {
// 这里的代码后面再看
} else {
info, err := lstat(f.name + "/" + string(name))
if IsNotExist(err) {
// File disappeared between readdir + stat.
// Treat as if it didn't exist.
continue
}
if err != nil {
return nil, nil, infos, err
}
infos = append(infos, info)
}
}
if n > 0 && len(names)+len(dirents)+len(infos) == 0 {
return nil, nil, nil, io.EOF
}
return names, dirents, infos, nil
}
ReadDirent对应的是Linux上的系统调用
getdents
,这个系统调用会把目录的目录项信息读取到一块内存里,之后程序可以解析这块内存里的数据来获得目录项的一些信息,这些信息一般包括了文件名,文件的类型,文件是否是目录等信息。
老代码在读取完这些信息后会利用文件名再次调用lstat,这个也是系统调用,可以获取更完整的文件信息,包括了文件的拥有者,文件的大小,文件的修改日期等。
老的代码有啥问题呢?大的问题不存在,接口也算易用,但有些小瑕疵:
- 大多数时间遍历目录主要是要获得目录中文件的名字或者类型等属性,显然
os.FileInfo
返回的信息过多了。这些用不着的信息会浪费不少内存,获取这些信息也需要额外花时间——lstat需要去进行磁盘io才能得到这些信息,而目录里的文件不像目录项信息那样紧密的存储在一起,它们是分散的,所以一一读取它们的元信息带来的负担会很大。
- 使用的系统调用太多了。由于我们测试目录的文件很多,但getdents可能要调用多次,这里假设为两次好了。对于每一个目录项,都需要用lstat去获取文件的详细信息,这样又有5000次系统调用,加起来是5002次。系统调用的开销是很大的,积累到5000多次则会带来肉眼可见的性能下降。实际上linux本身对lstat有优化,不会真的出现要反复进入系统调用5000次的情况,但几十到上百次还是需要的。
优化的代码其实只改了一行,是
f.readdir(n, readdirDirEntry)
,第二个参数变了。新代码会走上面注释掉的那段逻辑:
// rec := buf[:reclen] 防止你忘了rec是哪来的
de, err := newUnixDirent(f.name, string(name), direntType(rec))
if IsNotExist(err) {
// File disappeared between readdir and stat.
// Treat as if it didn't exist.
continue
}
if err != nil {
return nil, dirents, nil, err
}
dirents = append(dirents, de)
取代lstat的是函数newUnixDirent,这个函数可以不依赖额外的系统调用获取文件的一部分元数据:
type unixDirent struct {
parent string
name string
typ FileMode
info FileInfo
}
func newUnixDirent(parent, name string, typ FileMode) (DirEntry, error) {
ude := &unixDirent{
parent: parent,
name: name,
typ: typ,
}
// 检测文件类型信息是否有效
if typ != ^FileMode(0) && !testingForceReadDirLstat {
return ude, nil
}
info, err := lstat(parent + "/" + name)
if err != nil {
return nil, err
}
ude.typ = info.Mode().Type()
ude.info = info
return ude, nil
}
文件名和类型都是在解析目录项时就得到的,因此直接设置就行。不过不是每个文件系统都支持在目录项数据里存储文件类型,所以代码里做了回退,一旦发现文件类型是无效数据就会使用lstat重新获取信息。
如果只使用文件名和文件的类型这两个信息,那么整个遍历的逻辑流程到这就结束了,文件系统提供支持的情况下不需要调用lstat。所以整个遍历只需要两次系统调用。这就是为什么优化方案会快接近五倍的原因。
对于要使用其他信息比如文件大小的用户,优化方案实际上也有好处,因为现在lstat是延迟且按需调用的:
func (d *unixDirent) Info() (FileInfo, error) {
if d.info != nil {
return d.info, nil
}
// 只会调用一次
return lstat(d.parent + "/" + d.name)
}
这样也能尽量减少不必要的系统调用。
所以整体优化的原理是:尽量充分利用文件系统本身提供的信息+减少系统调用。要遍历的目录越大优化的效果也越明显。
优化的支持情况
上面也说了,能做到优化需要文件系统把文件类型信息存储在目录的目录项数据里。这个需要文件系统的支持。
如果文件系统不支持的话最后还是需要依赖lstat去读取具体文件的元数据。
不同文件系统的信息实在太分散,还有不少过时的,所以我花了几天看代码+查文档做了下整理:
- btrfs,ext2,ext4:这个几个文件系统支持优化,man pages加文件系统代码都能证实这一点
- OpenZFS:这个文件系统不在Linux内核里,所以man pages里没提到,但也支持优化
- xfs:支持优化,但得在创建文件系统时使用类似
mkfs.xfs -f -n ftype=1
的选项才行
- F2FS,EROFS:文档没提过,但看内核的代码里是支持的,代码的位置在
xxx_readdir
这个函数附近。
- fat32,exfat:文档没提过,但看内核代码发现是支持的,不过fat家族的文件类型没有那么多花样,只有目录和普通文件这两种,所以代码里很粗暴的判断目录项是否设置了dir标志,有就是目录没有统统算普通文件。这么做倒是正常的,因为fat本来就不支持别的文件类型,毕竟这个文件系统连软链接都不支持,更不用指望Unix Domain Socket和命名管道了。
- ntfs:支持,然而如
注释
所说,因为ntfs和其他文件系统处理type的方式不一样,导致虽然文件系统本身支持大部分文件类型,但type信息里只能获得文件是不是目录。所以它后面对于不是目录的文件会去磁盘上读取文件的inode然后再从inode里获取文件类型——实际上相当于执行了一次lstat,相比lstat减少了进入系统调用时的一次上下文切换,所以ntfs上优化效果会不如其他文件系统。
这么一看的话基本上主流的常见的文件系统都支持这种优化。
这也是为什么go1.16会引入这个优化,不仅支持广泛而且提升很大,免费的加速谁不爱呢。
别的语言里怎么利用这个优化
看到这里,你应该发现这个优化其实是系统层面的,golang只不过是适配了一下而已。
确实是这样的,所以这个优化不光golang能吃到,c/c++/python都行。
先说说c里怎么利用:直接用系统提供的readdir函数就行,这个函数会调用getdents,然后就能自然吃到优化了。注意事项和go的一样,需要检测文件系统是否支持设置d_type。
c++:和c一样,另外libstdc++的filesystem就是拿readdir实现的,所以用filesystem标准库也能获得优化:
// https://github.com/gcc-mirror/gcc/blob/master/libstdc++-v3/src/filesystem/dir-common.h#L270
inline file_type
get_file_type(const std::filesystem::__gnu_posix::dirent& d [[gnu::unused]])
{
#ifdef _GLIBCXX_HAVE_STRUCT_DIRENT_D_TYPE
switch (d.d_type)
{
case DT_BLK:
return file_type::block;
case DT_CHR:
return file_type::character;
case DT_DIR:
return file_type::directory;
case DT_FIFO:
return file_type::fifo;
case DT_LNK:
return file_type::symlink;
case DT_REG:
return file_type::regular;
case DT_SOCK:
return file_type::socket;
case DT_UNKNOWN:
return file_type::unknown;
default:
return file_type::none;
}
#else
return file_type::none;
#endif
}
// 如果操作系统以及文件系统不支持,则回退到lstat
// https://github.com/gcc-mirror/gcc/blob/master/libstdc++-v3/include/bits/fs_dir.h#L342
file_type
_M_file_type() const
{
if (_M_type != file_type::none && _M_type != file_type::symlink)
return _M_type;
return status().type();
}
唯一的区别在于如果目标文件是软连接,也会调用stat。
python:使用os.scandir可以获得优化,底层和c一样使用readdir:
https://github.com/python/cpython/blob/main/Modules/posixmodule.c#L16211,实现方法甚至类名都和golang很像,代码就不贴了。
总结
go虽然性能上一直被诟病,但在系统编程上倒是不含糊,基本常见的优化都有做,可以经常关注下新版本的release notes去看看go在这方面做的努力。
看着简单的优化,背后的可行性验证确实很复杂的,尤其是不同文件系统在怎么存储额外的元数据上很不相同,光是看代码就花了不少时间。
前面提到的ntfs在优化效果上会打点折扣,所以我特意拿Windows设备测试了下,测试条件不变:

可以看到几乎没什么区别。如果不是看了linux的ntfs驱动,我是不知道会产生这样的结果的。所以这个优化Windows上效果不理想,但在Linux和MacOS上是适用的。
大胆假设,小心求证,系统编程和性能优化的乐趣也正在于此。
参考
exfat的fuse驱动填充d_type的逻辑:
https://github.com/relan/exfat/blob/master/libexfat/utils.c#L28
Linux的ntfs驱动需要获取文件的inode才能得到正确的file type:
https://github.com/torvalds/linux/blob/master/fs/ntfs3/dir.c#L337