将传统应用带入浏览器的开源先锋「GitHub 热点速览」

现代浏览器已经不再是简单的浏览网页的工具,其潜能正在通过技术不断地被挖掘和扩展。得益于 WebAssembly 等技术的出现,让浏览器能够以接近原生的速度执行非 JavaScript 语言编写的程序,从而打开了浏览器的“潘多拉魔盒”。

开源组织 Leaning Technologies 正是这一方面的先锋,他们开发的 Cheerp、CheerpJ 和 CheerpX 等开源项目,使 C/C++、Java、Flash 和 x86 程序能够在浏览器中流畅地运行,它们正在逐步打破传统桌面应用程序和 Web 应用之间的“壁垒”。
- Cheerp:运行在浏览器里的 C/C++ 编译器
- CheerpJ:运行在浏览器里的 Java 虚拟机和运行时环境
- CheerpX:运行在浏览器里的 x86 虚拟机
比如本周的开源热搜项目,基于 CheerpX 引擎的 WebVM 开源项目,它支持用户在浏览器中运行完整的 Linux 环境,无需下载和安装。开源的 Web 应用防火墙 BunkerWeb,让你的 Web 默认配置变得安全。极小的 fetch 封装库 Wretch,让前端请求数据更加轻松惬意。在浏览器里控制多台 Android 设备的平台 stf,优化 React 组件性能的工具 million 也是让人眼前一亮。
最后是一周涨了近 1w Star 微软开源的新型 RAG 框架 GraphRAG 和 LLM 一站式开发和部署工具 LitGPT。
- 本文目录
- 1. 开源热搜项目
- 1.1 在浏览器中运行 Linux 虚拟机:WebVM
- 1.2 开源的 Web 应用防火墙:BunkerWeb
- 1.3 轻量且直观的 fetch 库:Wretch
- 1.4 一站式的 LLM 开发和部署工具:LitGPT
- 1.5 微软开源的 RAG 框架:GraphRAG
- 2. HelloGitHub 热评
- 2.1 浏览器控制多台 Android 设备的平台:stf
- 2.2 优化 React 组件性能的工具:million
- 3. 结尾
- 1. 开源热搜项目
1. 开源热搜项目
1.1 在浏览器中运行 Linux 虚拟机:WebVM

主语言:JavaScript
,
Star:3.5k
,
周增长:600
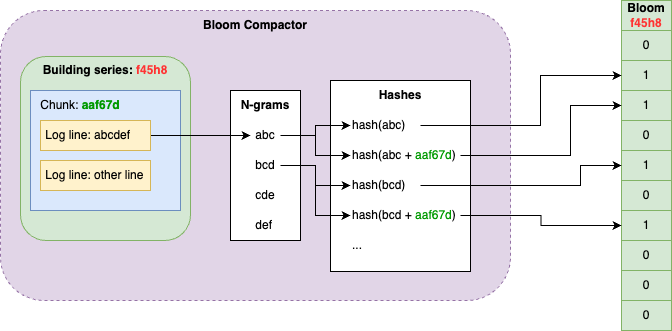
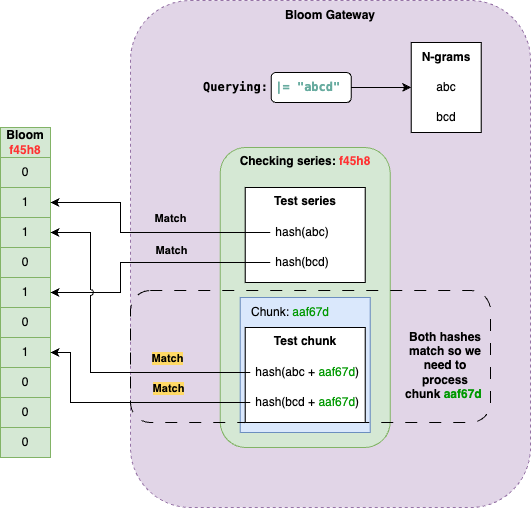
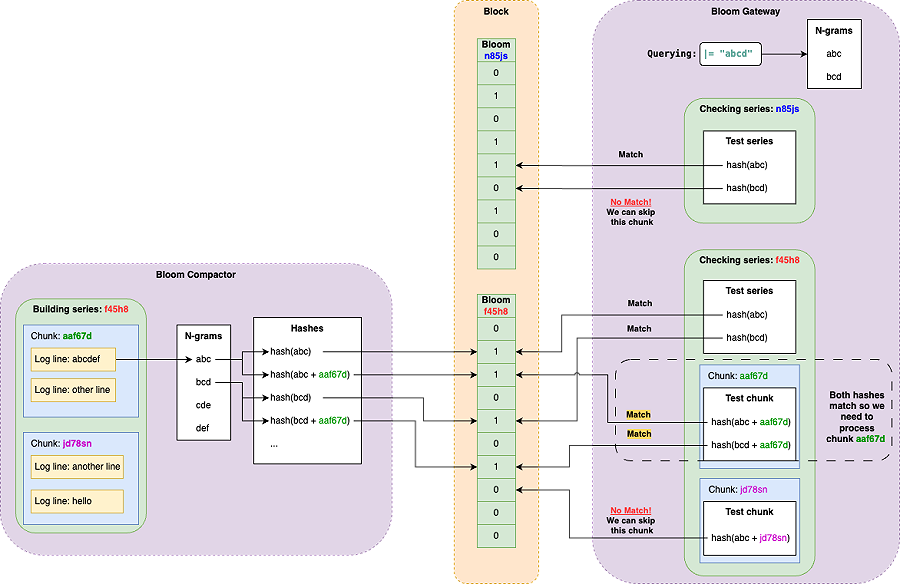
该项目可以让用户在浏览器中运行 Linux 虚拟机,无需服务器、完全客户端的虚拟环境。它基于 CheerpX 虚拟化引擎,提供了一个安全、沙盒的 x86 虚拟环境,可运行二进制文件、命令行工具、文本编辑器、编译 C/C++ 程序和 Python 等语言的脚本,登录后还能访问互联网,适用于演示和快速访问 Linux 开发环境等场景。
GitHub 地址→
github.com/leaningtech/webvm
1.2 开源的 Web 应用防火墙:BunkerWeb

主语言:Python
,
Star:4.9k
,
周增长:1.1k
该项目是用 Python 开发的 Web 应用防火墙,可以无缝集成至现有环境(Linux、Docker、K8s 等)。它基于 Nginx 构建、默认配置安全,拥有简单易用的 Web 界面,支持自动配置 HTTPS A+ 评级、安全 Header 和丰富的插件系统,可检测常见的攻击模式、限制访问、防止机器人和爬虫等恶意访问,保护你的网站、API 和 Web 应用。
GitHub 地址→
github.com/bunkerity/bunkerweb
1.3 轻量且直观的 fetch 库:Wretch

主语言:TypeScript
,
Star:4.6k
这是一个极小、类型安全、围绕 fetch API 构建的网络请求封装库。它提供了通俗易懂的网络请求 API,简化了网络请求错误处理和序列化,同时压缩后仅 2KB 大小,支持主流浏览器并兼容 Node.js,适用于各种前端 HTTP 请求的场景。
wretch("anything")
.get()
.notFound(error => { /* ... */ })
.unauthorized(error => { /* ... */ })
.error(418, error => { /* ... */ })
.res(response => /* ... */)
.catch(error => { /* uncaught errors */ })
GitHub 地址→
github.com/elbywan/wretch
1.4 一站式的 LLM 开发和部署工具:LitGPT

主语言:Python
,
Star:8.6k
,
周增长:300
该项目是一款用 Python 编写的提供了 20 多种 LLMs 的预训练、微调和部署的工具。它可以通过 Pyhton 库或者命令行的方式使用,对模型进行微调、预训练、评估和部署服务等操作,支持自动从 HF 下载模型、自定义数据集、性能优化、降低内存要求(precision)等功能,以及 LoRA、QLoRA、Adapter 等多种微调方法。
from litgpt import LLM
llm = LLM.load("microsoft/phi-2")
text = llm.generate("Fix the spelling: Every fall, the familly goes to the mountains.")
print(text)
# Corrected Sentence: Every fall, the family goes to the mountains.
GitHub 地址→
github.com/Lightning-AI/litgpt
1.5 微软开源的 RAG 框架:GraphRAG

主语言:Python
,
Star:10k
,
周增长:9k
该项目是由微软开源的基于知识图谱的检索增强型生成(RAG)系统,它利用大型语言模型生成知识图谱,将非结构化的文本转换为具有标签的知识图谱数据,从而增强 LLMs 的输出结果。相较于基准 RAG(向量相似性),基于知识图谱的 GraphRAG 在回答更抽象(关系)和总结性问题时表现更好。
GitHub 地址→
github.com/microsoft/graphrag
2. HelloGitHub 热评
在这个章节,将会分享下本周 HelloGitHub 网站上的热门开源项目,欢迎与我们分享你上手这些开源项目后的使用体验。
2.1 浏览器控制多台 Android 设备的平台:stf

主语言:JavaScript
这是一个用 Node.js 开发的安卓智能设备群测工具,它提供了一个可远程调试多台 Android 设备的 Web 平台,支持 Android 手机和手表等设备。
项目详情→
hellogithub.com/repository/af0868c1e3ea4d608e92849b405a8ddb
2.2 优化 React 组件性能的工具:million

主语言:TypeScript
该项目是专为 React 应用设计的优化编译器,它通过优化虚拟 DOM 和直接更新 DOM 节点,来减少页面更新的耗时,从而提升 React 组件性能,最高可达 70%,支持 VSCode 插件和命令行的使用方式。
项目详情→
hellogithub.com/repository/406d03f678a64294b6c7e763a783b972
3. 结尾
我最近正全身心投入 HelloGitHub 官网的国际化工作中,这使得其他一些事情(HelloStar 等)不得不暂停。我之所以如此专注于国际化,是因为我深信这将提升 HelloGitHub 的全球影响力:它不仅能够让国内的开源项目通过一个国际化的平台被世界看到,也能让国外的开源项目作者理解并知道 HelloGitHub 在做的事情。
虽然这项工作充满挑战、进展缓慢,但我希望能够在「第100期」特别版发布之前完成它,让这一里程碑时刻更加有意义。
在此,我要向所有参与这个项目的朋友们(@雪峰、@塔咖...)表达感谢。正是因为有了你们的无私奉献和坚定支持,让这一切才得以可能。
一个人或许可以走得很快,但一群人定会走得更远
。HelloGitHub 渴望成为每位开源爱好者旅程中的伙伴,让我们一起穿越难关,共同迎接乌云背后的阳光!
以上就是本期「GitHub 热点速览」的全部内容,希望你能够在这里找到自己感兴趣的开源项目,如果你有其他好玩、有趣的 GitHub 开源项目想要分享,欢迎来
HelloGitHub
与我们交流和讨论。
往期回顾