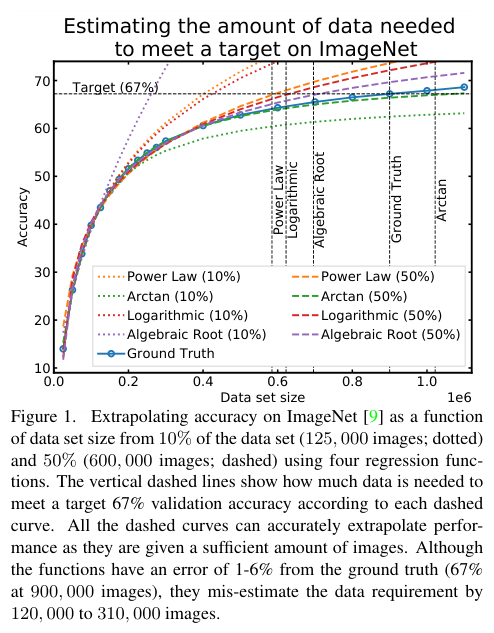
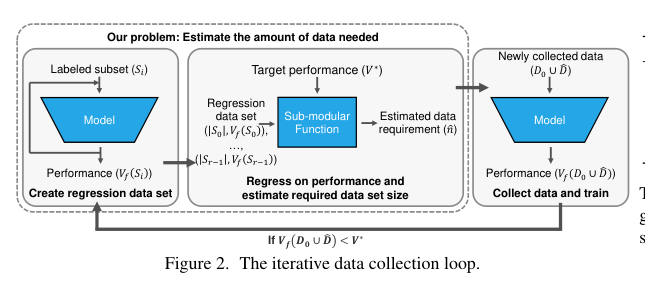
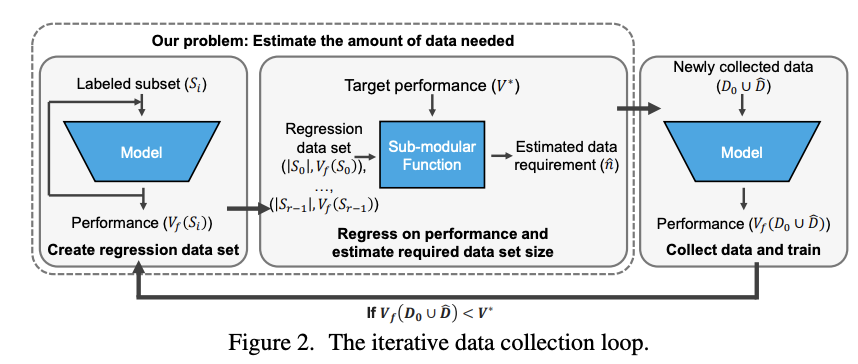
异构数据源数据同步 → 从源码分析 DataX 敏感信息的加解密
开心一刻
出门扔垃圾,看到一大爷摔地上了
过去问大爷:我账户余额 0.8,能扶你起来不
大爷往旁边挪了挪
跟我说到:孩子,快,你也躺下,这个来钱快!
我没理大爷,径直去扔了垃圾
然后飞速的躺在了大爷旁边,说道:感觉大爷带飞!

书接上回
通过
异构数据源同步之数据同步 → DataX 使用细节
,相信大家都知道如何使用
DataX
了
但你们有没有发现一个问题:
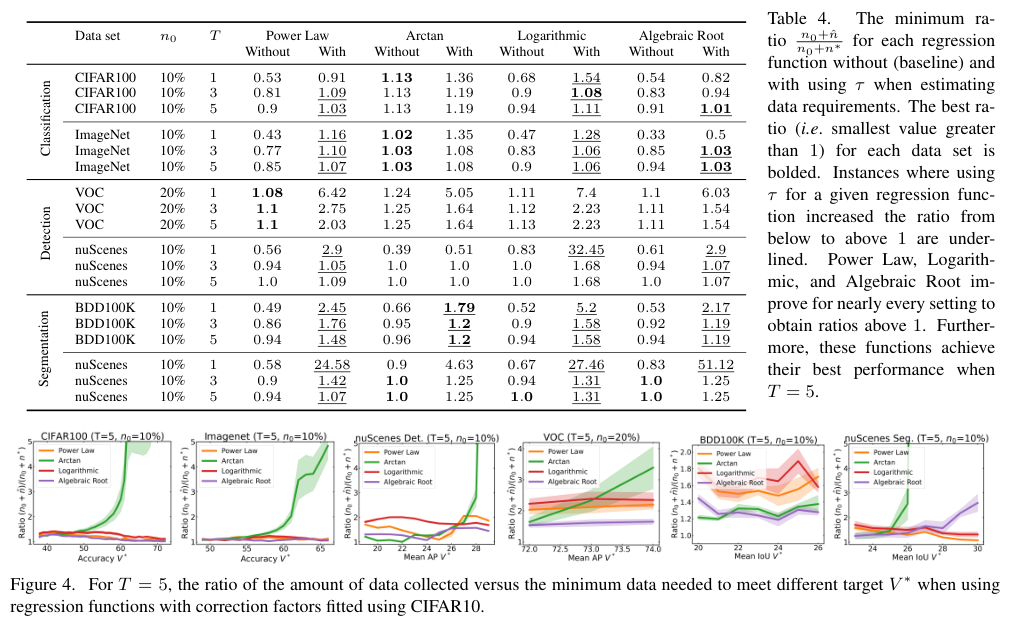
job.json
中
reader
和
writer
的账密都是明文
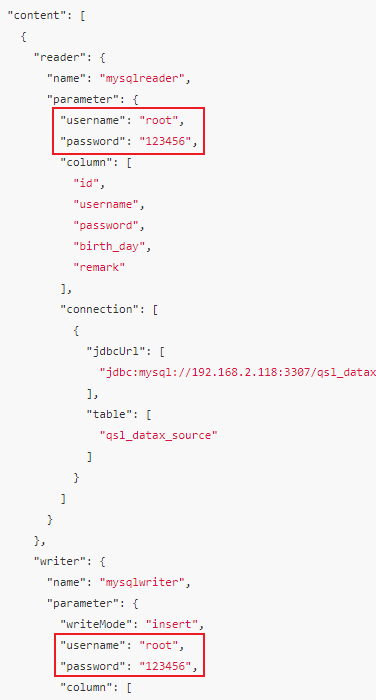
这就犹如在裸奔,是有安全隐患的!
不仅你们喜欢看裸奔,其实我也喜欢看裸奔
但不管是从法律的角度,还是从道德的角度,裸奔都是不允许的!
所以我们应该怎么办,给她穿上衣服?

那就穿嘛,而且给她穿厚点,让她安安全全的!
加密
首先我们得明确,目前
DataX
是支持加解密的,
dataxPluginDev.md
有这样一段说明
DataX
框架支持对特定的配置项进行RSA加密,例子中以
*
开头的项目便是加密后的值。
配置项加密解密过程对插件是透明,插件仍然以不带
*
的key来查询配置和操作配置项
。
从这段话我们可以解析出以下几点信息
采用
RSA
算法进行加密,且暂时只支持这一种!敏感信息配置项的
key
以
*
开头,例如{ "job": { "content": [ { "reader": { "name": "oraclereader", "parameter": { "*username": "加密后的密文", "*password": "加密后的密文", ... } }, "writer": { "name": "oraclewriter", "parameter": { "*username": "加密后的密文", "*password": "加密后的密文", ... } } } ] } }plugin
不参与加密解密,言外之意就是
FrameWork
负责解密,至于加密嘛,你们先想想

除了以上 3 点,你们还能分析出什么?
- 如何获得明文的密文
- 配置了密文,需不需要通过额外的配置告知 DataX 需要解密
这两点能分析出来吗?
关于第 1 点,我把
DataX
的文档翻遍了,没找到给明文加密的说明,莫非就用通用的
RSA
工具加密就行?
关于第 2 点,这个暂时不得而知,但是我们可以去试
获取密文
DataX
只说支持
RSA
加密,但没说如何获取密文,但我们仔细想一下,其实是能找到切入点的。
DataX
肯定有解密过程,而解密与加密往往是成对存在的,找到了解密方法也就找到了加密方法,那上哪去找解密方法了?
源码
肯定是最根本的方式!
源码之下无密码
前面已经说过了,
FrameWork
负责解密,对应的模块就是
datax-core
,从它的
Engine.java
切入
为什么从 Engine.java 切入,可以看看
异构数据源同步之数据同步 → datax 改造,有点意思另外,Engine.java 的描述也说明了
Engine是DataX入口类,该类负责初始化Job或者Task的运行容器,并运行插件的Job或者Task逻辑
从
main
一步一步往下跟
Engine#main > Engine#entry > ConfigParser#parse > ConfigParser#parseJobConfig > SecretUtil#decryptSecretKey
decrypt
大家都知道是什么意思吧,所以
SecretUtil.java
中肯定有我们要找的加密方法
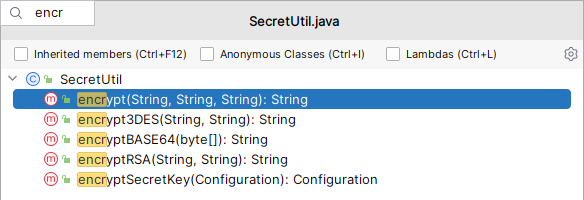
但我们会发现有好几个,我们应该用哪个?凭感觉的话应该是
encryptRSA
,但作为一个开发者,我们不能只凭感觉,我们需要的准确的答案。如何寻找准备的答案了?
从解密处找答案,解密用的哪个方法,可以准确的推出加密方法
那就继续跟进
SecretUtil#decryptSecretKey
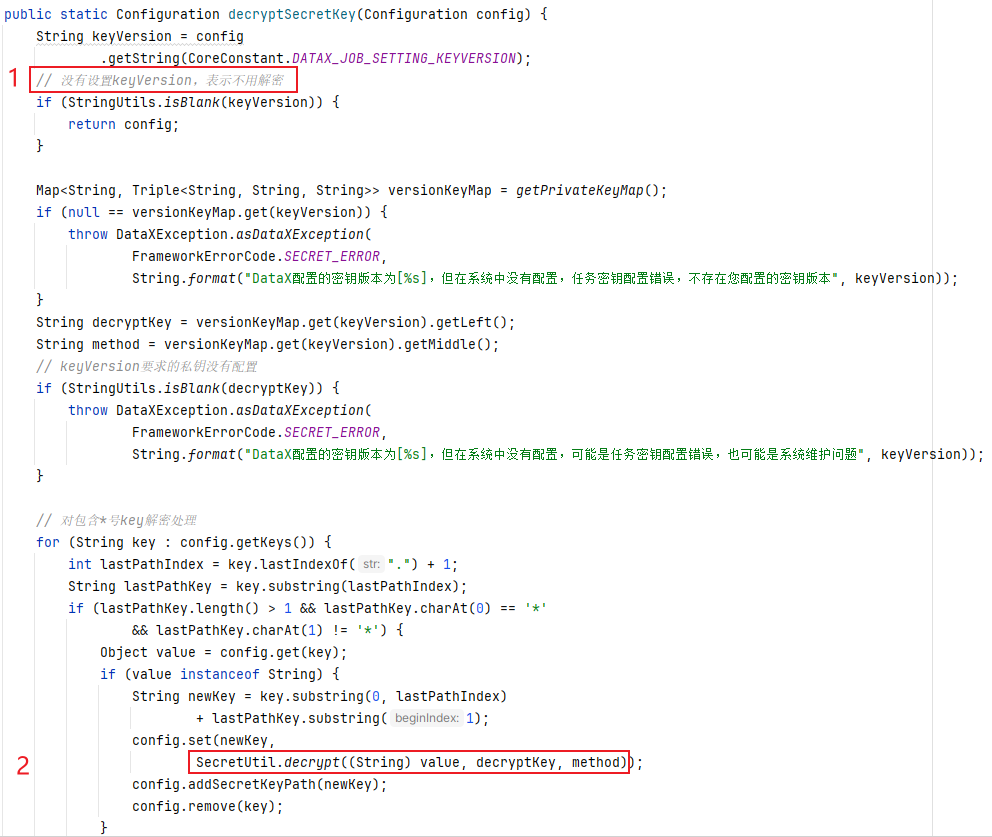
代码不短,但我们暂时只需要关注图中标明的 2 点
是否需要解密
还记得前面提到的问题吗
配置了密文,需不需要通过额外的配置告知 DataX 需要解密
所以
DataX
是通过配置项
job.setting.keyVersion
来判断是否需要解密,得到明确的答案,我们就不用去尝试了对包含
*
号的
key
解密我们跟进
SecretUtil.decryptpublic static String decrypt(String data, String key, String method) { if (SecretUtil.KEY_ALGORITHM_RSA.equals(method)) { return SecretUtil.decryptRSA(data, key); } else if (SecretUtil.KEY_ALGORITHM_3DES.equals(method)) { return SecretUtil.decrypt3DES(data, key); } else { throw DataXException.asDataXException( FrameworkErrorCode.SECRET_ERROR, String.format("系统编程错误,不支持的加密类型", method)); } }
代码并不长,但我们发现除了支持
RSA
解密,还支持
3DES
解密,这与官方文档说的
DataX
框架支持对特定的配置项进行RSA加密
有点不一样,为什么不把
3DES
加进去?这个后面再分析,我们继续看
RSA
所以对应的
RSA
解密方法是:
SecretUtil.decryptRSA
,那对应的加密方法肯定就是
SecretUtil.encryptRSA
,但为了严谨,我们需要验证下,如何验证了,其实很简单,
SecretUtil.encryptRSA
对明文加密得到密文,然后用
SecretUtil.decryptRSA
对密文进行解密,看能否得到最初的明文
但问题又来了,
encryptRSA
需要
公钥
/**
* 加密<br>
* 用公钥加密 encryptByPublicKey
*
* @param data 裸的原始数据
* @param key 经过base64加密的公钥
* @return 结果也采用base64加密
* @throws Exception
*/
public static String encryptRSA(String data, String key) {
try {
// 对公钥解密,公钥被base64加密过
byte[] keyBytes = decryptBASE64(key);
// 取得公钥
X509EncodedKeySpec x509KeySpec = new X509EncodedKeySpec(keyBytes);
KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM_RSA);
Key publicKey = keyFactory.generatePublic(x509KeySpec);
// 对数据加密
Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
cipher.init(Cipher.ENCRYPT_MODE, publicKey);
return encryptBASE64(cipher.doFinal(data.getBytes(ENCODING)));
} catch (Exception e) {
throw DataXException.asDataXException(
FrameworkErrorCode.SECRET_ERROR, "rsa加密出错", e);
}
}
而
decryptRSA
需要
私钥
/**
* 解密<br>
* 用私钥解密
*
* @param data 已经经过base64加密的密文
* @param key 已经经过base64加密私钥
* @return
* @throws Exception
*/
public static String decryptRSA(String data, String key) {
try {
// 对密钥解密
byte[] keyBytes = decryptBASE64(key);
// 取得私钥
PKCS8EncodedKeySpec pkcs8KeySpec = new PKCS8EncodedKeySpec(keyBytes);
KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM_RSA);
Key privateKey = keyFactory.generatePrivate(pkcs8KeySpec);
// 对数据解密
Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
cipher.init(Cipher.DECRYPT_MODE, privateKey);
return new String(cipher.doFinal(decryptBASE64(data)), ENCODING);
} catch (Exception e) {
throw DataXException.asDataXException(
FrameworkErrorCode.SECRET_ERROR, "rsa解密出错", e);
}
}
上哪去获取
公钥
和
私钥
?

假设是我们实现工具类
SecretUtil
,我们要不要提供获取
公钥
和
私钥
的方法?很显然是要的,因为
加密
和
解密
分别需要用到
公钥
和
私钥
,所以从完整性考虑,肯定提供获取
公钥
和
私钥
的方法
自己动手,丰衣足食
同理,
SecretUtil
也提供了获取
公钥
和 私钥的方法
/**
* 初始化密钥 for RSA ALGORITHM
*
* @return
* @throws Exception
*/
public static String[] initKey() throws Exception {
KeyPairGenerator keyPairGen = KeyPairGenerator
.getInstance(KEY_ALGORITHM_RSA);
keyPairGen.initialize(1024);
KeyPair keyPair = keyPairGen.generateKeyPair();
// 公钥
RSAPublicKey publicKey = (RSAPublicKey) keyPair.getPublic();
// 私钥
RSAPrivateKey privateKey = (RSAPrivateKey) keyPair.getPrivate();
String[] publicAndPrivateKey = {
encryptBASE64(publicKey.getEncoded()),
encryptBASE64(privateKey.getEncoded())};
return publicAndPrivateKey;
}
测试代码如下
public static void main(String[] args) throws Exception {
// 获取公钥与私钥
String[] keys = SecretUtil.initKey();
String publicKey = keys[0];
String privateKey = keys[1];
System.out.println("publicKey = " + publicKey);
System.out.println("privateKey = " + privateKey);
// 通过公钥加密
String encryptData = SecretUtil.encryptRSA("hello_qsl", publicKey);
System.out.println("encryptData = " + encryptData);
// 通过私钥解密
String decryptData = SecretUtil.decryptRSA(encryptData, privateKey);
System.out.println("decryptData = " + decryptData);
}
至于结果正确与否,你们自己去执行
我都把饭喂到你们嘴里了,莫非还要我替你们去吃?

使用密文
密文已经获取到了,接下来就是在
DataX
中使用密文了
配置
.secret.properties
的
公钥
与
私钥文件在
DataX
的
home
目录的
conf
目录下#ds basicAuth config auth.user= auth.pass= current.keyVersion=v1 current.publicKey=MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCeBjq0zrij7A6la1y9gONHrC3dV1r8U4HCJ0expJ6K9xeW1/RYUc+s4b4pEQjbeSX2BlmOzCXPcc2s26+UpHLHl9Cy1alix/HGf3tOubuAKsbF+MKOd/sLGtLoFr4iMoCHj+KNVRBHlQN5WsrxehRwQaqWycl2Rd2wY6orL0xZ0QIDAQAB current.privateKey=MIICeAIBADANBgkqhkiG9w0BAQEFAASCAmIwggJeAgEAAoGBAJ4GOrTOuKPsDqVrXL2A40esLd1XWvxTgcInR7Gknor3F5bX9FhRz6zhvikRCNt5JfYGWY7MJc9xzazbr5SkcseX0LLVqWLH8cZ/e065u4AqxsX4wo53+wsa0ugWviIygIeP4o1VEEeVA3layvF6FHBBqpbJyXZF3bBjqisvTFnRAgMBAAECgYEAhtcl7PagUy+wZ7KvFf0O8y+Wi1JpDvpqtLMz1/9yUX36oPpxQ5O7s/eEfiJM/onnvIE6lkDY2qRvLlre/eU9En4f964p6Fl0yWMalDmCv8MYGNEBu8rzn+GKH55xzm+Z5shs7mvzFWYJNeHIHCI8fmHnscFURB8VYEgAvbvtHAECQQDePgz/j4rTyqYeFjzuwZe7wUlQzex2NNdJ/aP4RY2+v+N5lZbT0SomIJZhIf5uqY+Z3lmEEyLWEikiDD6GkAihAkEAtgcLQJ6D4XOujJwD8KWm9m78yKXTrEgk57Qpy0bQq9tF2ygd6m2u8oEo9x+3YpN2J9RaTykjyOP8YwoSW97TMQJBAIgWkRkRCd7E8dHspiVBsKtNIZr0bf64PrjVM0n9NV3/3Mh//Fr6cwfj3pHeIhIbjI6ZJFGG8kcJ2dw6iTMXEeECQD6N6SYJ05SU5rVXoFsA8oHZ3nEt27JnEJe36Gz9JxUIQ9duz+kSTH72OBfFBIaR2pcReP+fSbbt8nwup+R+jOECQQCciE2p6iQcTnJyMuSQFLoTB47qSx0EmdQNIcLdHuAxagWrfphlPJMFPJilWWgaqyoP0GkzmPxak5Jd9T7bv7yR current.service.username= current.service.password=
current.keyVersion
也需要配置,并且后续
job.json
的配置
job.setting.keyVersion
的值与该值一致配置
job.json有 2 种配置,其 1 是需要配置:
job.setting.keyVersion
,其值与
.secret.properties
的
current.keyVersion
值一致,其 2 是
reader
和
writer
的账密
key
需要以
*
开头,并且其值需要置成加密后的密文,完整的
mysql2Mysql.json{ "job": { "setting": { "speed": { "channel": 5 }, "errorLimit": { "record": 0, "percentage": 0.02 }, "keyVersion": "v1" }, "content": [ { "reader": { "name": "mysqlreader", "parameter": { "*username": "HisZeJWc51c+8B54AbJ9wQDTJ49C1kBlc1hKUnDgi1NaTdqsgHwRc3Y4PdM5xf0fCLRoYlLSO/KRZJcy9CGIQt9uvJy3bkbG01RwO4qMoS+nQJ28S8p/I3rVUlAEkI/eE/PFWBnAU2U4xF2XjlMFrCG2yetAlZuwsN4paQaBmj4=", "*password": "Ebh0U200enVevXaJs6M0t4yvPo5upcL8RUBN2j1Xi59a8UF8iSPbCl/m5YcX4N9JcJH6VPdsA9kfDJHv6tArnCsH3f5JDWwapOv03lW6B3Nte89e+7Ex7tE6J5+IkFIxaxeYOGoTFr+NBf5t4DWzK0tvH2xAVTgiPHyL/gisiZI=", "column": [ "id", "username", "password", "birth_day", "remark" ], "connection": [ { "jdbcUrl": [ "jdbc:mysql://192.168.2.118:3307/qsl_datax?useUnicode=true&characterEncoding=utf-8" ], "table": [ "qsl_datax_source" ] } ] } }, "writer": { "name": "mysqlwriter", "parameter": { "writeMode": "insert", "*username": "HisZeJWc51c+8B54AbJ9wQDTJ49C1kBlc1hKUnDgi1NaTdqsgHwRc3Y4PdM5xf0fCLRoYlLSO/KRZJcy9CGIQt9uvJy3bkbG01RwO4qMoS+nQJ28S8p/I3rVUlAEkI/eE/PFWBnAU2U4xF2XjlMFrCG2yetAlZuwsN4paQaBmj4=", "*password": "Ebh0U200enVevXaJs6M0t4yvPo5upcL8RUBN2j1Xi59a8UF8iSPbCl/m5YcX4N9JcJH6VPdsA9kfDJHv6tArnCsH3f5JDWwapOv03lW6B3Nte89e+7Ex7tE6J5+IkFIxaxeYOGoTFr+NBf5t4DWzK0tvH2xAVTgiPHyL/gisiZI=", "column": [ "id", "username", "pw", "birth_day", "note" ], "connection": [ { "jdbcUrl": "jdbc:mysql://192.168.2.118:3306/qsl_datax_sync?useUnicode=true&characterEncoding=utf-8", "table": [ "qsl_datax_target" ] } ] } } } ] } }
然后执行数据同步
datax.py ../job/mysql2Mysql.json
输出日志如下
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2024-07-13 23:49:17.313 [main] INFO MessageSource - JVM TimeZone: GMT+08:00, Locale: zh_CN
2024-07-13 23:49:17.315 [main] INFO MessageSource - use Locale: zh_CN timeZone: sun.util.calendar.ZoneInfo[id="GMT+08:00",offset=28800000,dstSavings=0,useDaylight=false,transitions=0,lastRule=null]
2024-07-13 23:49:17.321 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2024-07-13 23:49:17.323 [main] INFO Engine - the machine info =>
osInfo: Windows 10 amd64 10.0
jvmInfo: Oracle Corporation 1.8 25.251-b08
cpu num: 8
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [PS MarkSweep, PS Scavenge]
MEMORY_NAME | allocation_size | init_size
PS Eden Space | 256.00MB | 256.00MB
Code Cache | 240.00MB | 2.44MB
Compressed Class Space | 1,024.00MB | 0.00MB
PS Survivor Space | 42.50MB | 42.50MB
PS Old Gen | 683.00MB | 683.00MB
Metaspace | -0.00MB | 0.00MB
2024-07-13 23:49:17.331 [main] INFO Engine -
{
"setting":{
"speed":{
"channel":5
},
"errorLimit":{
"record":0,
"percentage":0.02
},
"keyVersion":"v1"
},
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"column":[
"id",
"username",
"password",
"birth_day",
"remark"
],
"connection":[
{
"jdbcUrl":[
"jdbc:mysql://192.168.2.118:3307/qsl_datax?useUnicode=true&characterEncoding=utf-8"
],
"table":[
"qsl_datax_source"
]
}
],
"username":"root",
"password":"******"
}
},
"writer":{
"name":"mysqlwriter",
"parameter":{
"writeMode":"insert",
"column":[
"id",
"username",
"pw",
"birth_day",
"note"
],
"connection":[
{
"jdbcUrl":"jdbc:mysql://192.168.2.118:3306/qsl_datax_sync?useUnicode=true&characterEncoding=utf-8",
"table":[
"qsl_datax_target"
]
}
],
"username":"root",
"password":"******"
}
}
}
]
}
2024-07-13 23:49:17.342 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false
2024-07-13 23:49:17.342 [main] INFO JobContainer - DataX jobContainer starts job.
2024-07-13 23:49:17.343 [main] INFO JobContainer - Set jobId = 0
Sat Jul 13 23:49:17 GMT+08:00 2024 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
2024-07-13 23:49:17.614 [job-0] INFO OriginalConfPretreatmentUtil - Available jdbcUrl:jdbc:mysql://192.168.2.118:3307/qsl_datax?useUnicode=true&characterEncoding=utf-8&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true.
Sat Jul 13 23:49:17 GMT+08:00 2024 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
2024-07-13 23:49:17.635 [job-0] INFO OriginalConfPretreatmentUtil - table:[qsl_datax_source] has columns:[id,username,password,birth_day,remark].
2024-07-13 23:49:17.796 [job-0] INFO OriginalConfPretreatmentUtil - table:[qsl_datax_target] all columns:[
id,username,pw,birth_day,note
].
2024-07-13 23:49:17.801 [job-0] INFO OriginalConfPretreatmentUtil - Write data [
insert INTO %s (id,username,pw,birth_day,note) VALUES(?,?,?,?,?)
], which jdbcUrl like:[jdbc:mysql://192.168.2.118:3306/qsl_datax_sync?useUnicode=true&characterEncoding=utf-8&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&rewriteBatchedStatements=true&tinyInt1isBit=false]
2024-07-13 23:49:17.801 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2024-07-13 23:49:17.802 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do prepare work .
2024-07-13 23:49:17.802 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do prepare work .
2024-07-13 23:49:17.803 [job-0] INFO JobContainer - jobContainer starts to do split ...
2024-07-13 23:49:17.803 [job-0] INFO JobContainer - Job set Channel-Number to 5 channels.
2024-07-13 23:49:17.806 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] splits to [1] tasks.
2024-07-13 23:49:17.807 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] splits to [1] tasks.
2024-07-13 23:49:17.825 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2024-07-13 23:49:17.826 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2024-07-13 23:49:17.828 [job-0] INFO JobContainer - Running by standalone Mode.
2024-07-13 23:49:17.834 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2024-07-13 23:49:17.836 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2024-07-13 23:49:17.836 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2024-07-13 23:49:17.844 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2024-07-13 23:49:17.848 [0-0-0-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,username,password,birth_day,remark from qsl_datax_source
] jdbcUrl:[jdbc:mysql://192.168.2.118:3307/qsl_datax?useUnicode=true&characterEncoding=utf-8&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].
Sat Jul 13 23:49:17 GMT+08:00 2024 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
2024-07-13 23:49:17.869 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,username,password,birth_day,remark from qsl_datax_source
] jdbcUrl:[jdbc:mysql://192.168.2.118:3307/qsl_datax?useUnicode=true&characterEncoding=utf-8&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].
2024-07-13 23:49:18.247 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[403]ms
2024-07-13 23:49:18.247 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2024-07-13 23:49:27.842 [job-0] INFO StandAloneJobContainerCommunicator - Total 4 records, 80 bytes | Speed 8B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.012s | Percentage 100.00%
2024-07-13 23:49:27.842 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2024-07-13 23:49:27.843 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do post work.
2024-07-13 23:49:27.843 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do post work.
2024-07-13 23:49:27.843 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2024-07-13 23:49:27.844 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: F:\datax\hook
2024-07-13 23:49:27.845 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 1 | 1 | 1 | 0.014s | 0.014s | 0.014s
PS Scavenge | 1 | 1 | 1 | 0.006s | 0.006s | 0.006s
2024-07-13 23:49:27.845 [job-0] INFO JobContainer - PerfTrace not enable!
2024-07-13 23:49:27.846 [job-0] INFO StandAloneJobContainerCommunicator - Total 4 records, 80 bytes | Speed 8B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.012s | Percentage 100.00%
2024-07-13 23:49:27.846 [job-0] INFO JobContainer -
任务启动时刻 : 2024-07-13 23:49:17
任务结束时刻 : 2024-07-13 23:49:27
任务总计耗时 : 10s
任务平均流量 : 8B/s
记录写入速度 : 0rec/s
读出记录总数 : 4
读写失败总数 : 0
数据同步成功,我们注意看日志中的
job.json
{
"setting": {
"speed": {
"channel": 5
},
"errorLimit": {
"record": 0,
"percentage": 0.02
},
"keyVersion": "v1"
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"username",
"password",
"birth_day",
"remark"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.2.118:3307/qsl_datax?useUnicode=true&characterEncoding=utf-8"
],
"table": [
"qsl_datax_source"
]
}
],
"username": "root",
"password": "******"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"column": [
"id",
"username",
"pw",
"birth_day",
"note"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.2.118:3306/qsl_datax_sync?useUnicode=true&characterEncoding=utf-8",
"table": [
"qsl_datax_target"
]
}
],
"username": "root",
"password": "******"
}
}
}
]
}
可以看出
FrameWork
完成解密后,带
*
号的
key
(
username
、
password
)已经不带
*
号,其值也已经被解密成了明文
"password": "**********",只是进行日志打印的时候,一个明文字符被替换成一个
*
,而实际传给插件的是明文密码
所以插件并不感知加密解密过程,这就是官方文档说的
配置项加密解密过程对插件是透明,插件仍然以不带
*
的key来查询配置和操作配置项
解密
官方文档只提到了
RSA
,但实际代码中还提供了
3DES
,为什么官方文档中不提及
3DES
了,我们得从解密中找答案
还记得前面讲到的
SecretUtil#decryptSecretKey
吗,我们得继续看这个方法,但只需要分析其中部分代码
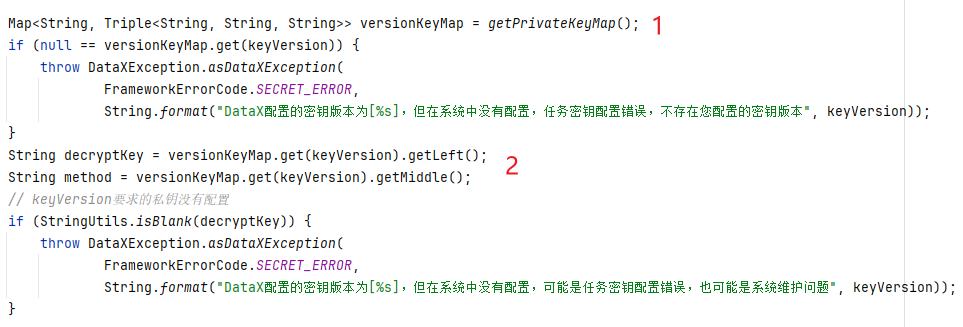
主要分两块
getPrivateKeyMap
获取
密钥方法代码比较长,就不展示代码了,我直接给你们梳理下流程
本地缓存
versionKeyMap
类型是
Map<String, Triple<String, String, String>>
,
key
是就是
.secret.properties
中
current.keyVersion
的值,对应到我们案例中,就是
v1
,
value
是
Triple
类型,含有三个字段,
left
、
middle
、
right
,值分别对应
privateKey
、
加密算法
、
publicKey如果
versionKeyMap
是
null
,则读取
.secret.properties
内容,放入
versionKeyMap
中;如果不是
null
,则直接返回。重点代码来了,大家注意看
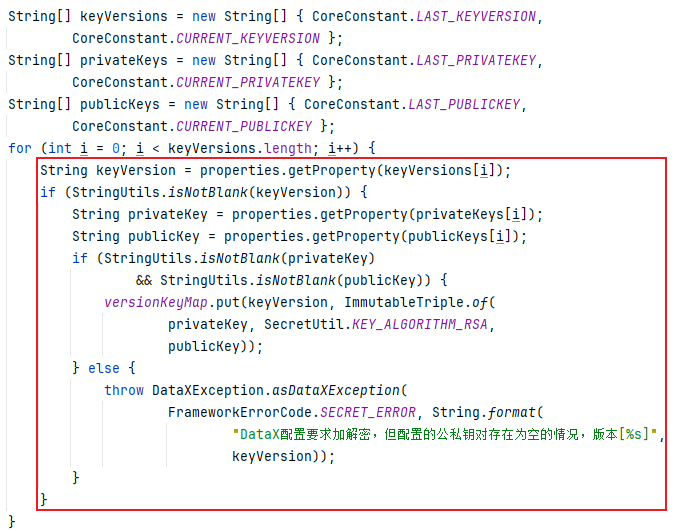
红框框住的代码,相信大家都能看懂,
keyVersion
的值就是配置项
current.keyVersion
的值,
privateKey
的值就是配置项
current.privateKey
的值,
publicKey
的值就是配置项
current.publicKey
的值大家注意看
versionKeyMap.put(keyVersion, ImmutableTriple.of( privateKey, SecretUtil.KEY_ALGORITHM_RSA, publicKey))
这里直接将加密算法固定成
RSA
了,根本就没有
if
分支去指定
3DES
算法,所以了?
DataX 暂时确实不支持
3DES
加解密,只支持
RSA
加解密
或者说
3DES
加解密只实现了部分,未实现全部,最终还是不支持
3DES
,所以官方文档只说了
RSA
,并未提及
3DES
是对的!获取
私钥
和
加密算法decryptKey
就是
privateKey
,而
method
就是
加密算法
,其值就是
RSA
。然后就是对
job.json
中
*
开头的
key
的值做解密处理// 对包含*号key解密处理 for (String key : config.getKeys()) { int lastPathIndex = key.lastIndexOf(".") + 1; String lastPathKey = key.substring(lastPathIndex); if (lastPathKey.length() > 1 && lastPathKey.charAt(0) == '*' && lastPathKey.charAt(1) != '*') { Object value = config.get(key); if (value instanceof String) { String newKey = key.substring(0, lastPathIndex) + lastPathKey.substring(1); config.set(newKey, SecretUtil.decrypt((String) value, decryptKey, method)); config.addSecretKeyPath(newKey); config.remove(key); } } }
这里就对应了为什么加密项的
key
需要以
*
开头
至此,相关的疑惑是不是都得到解答了,你们对
DataX
的敏感信息加解密是不是完全懂了?

总结
DataX
目前只支持
RSA
加解密,不支持
3DES
,也不支持其他加解密算法DataX
的加密算法结合了
RSA
和
BASE64
,而非只用
RSA
,也就是通用的
RSA
工具生成的密码不能用于
DataXFrameWork
有解密过程,但
密钥
和
密文
需要使用者自己生成,配置过程有好几步,大家别漏了2.1 获取
公钥
和
私钥
,并指定
keyVersion
,配置到
.secret.properties2.2 在
job.json
中配置
job.setting.keyVersion
,其值与 2.1 的
keyVersion
值一致2.3
job.json
中敏感配置项,
key
以
*
开头,
value
是
明文
经过
SecretUtil#encryptRSA
得到的密文