我跟你说@RefreshScope跟Spring事件监听一起用有坑!
本文记录一下我在 Spring 自带的事件监听类添加 @RefreshScope 注解时遇到的坑,原本这两个东西单独使用是各自安好,但当大家将它们组合在一起时,会发现我们的事件监听代码被重复执行。希望大家引以为鉴,避免重复踩坑。耐心看完,你一定会有所收获!
前置描述
最近有一个用户拉新的需求,需要在新用户注册时判断用户是否有对应的邀请关系,如果有则需要给新用户赠送系统资源。
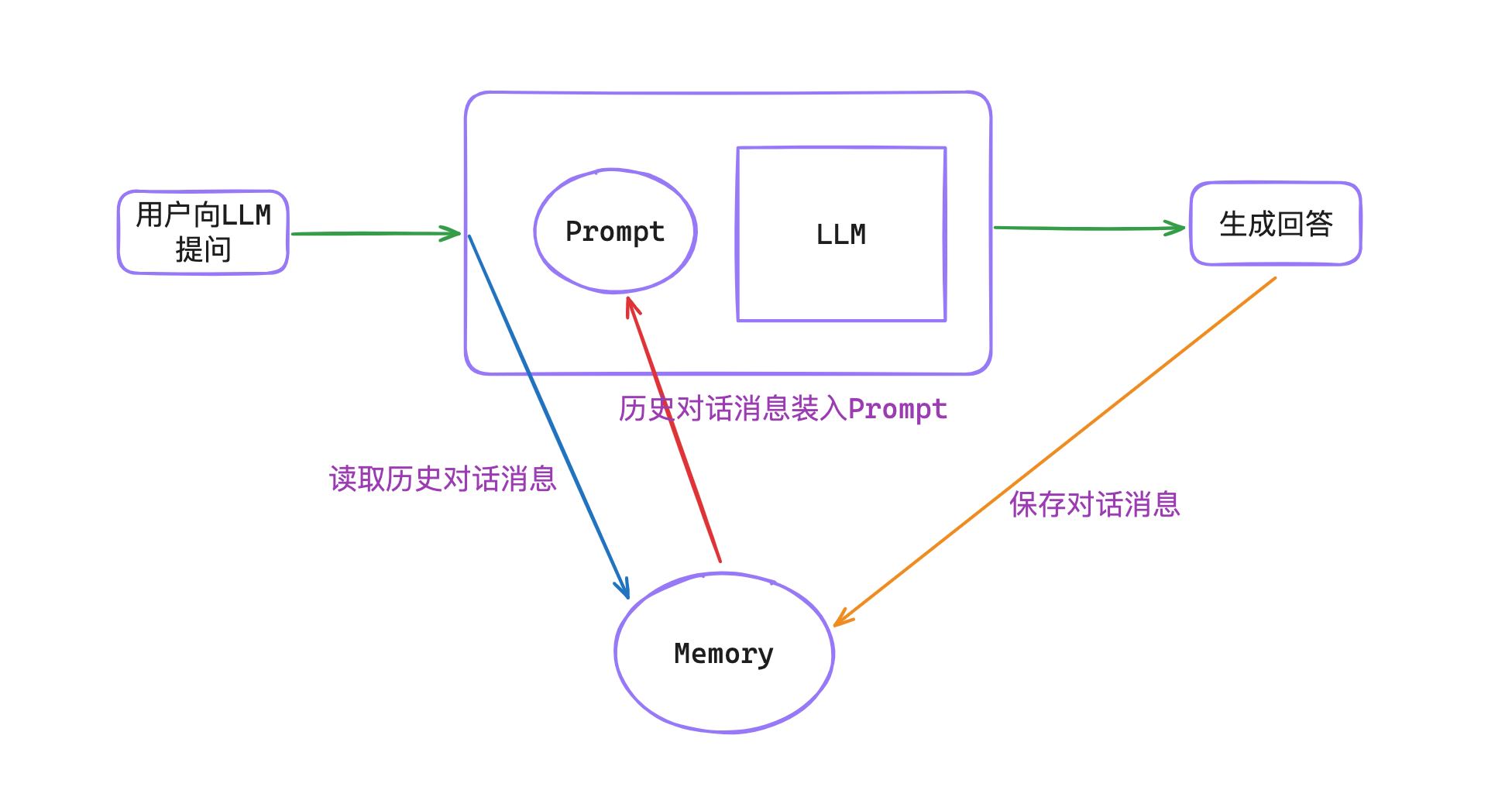
原有的用户注册逻辑里使用了 Spring 自带的事件监听工具,也就是 applicationEventPublisher(事件发布类)以及 ApplicationListener(事件监听类),在用户注册完毕写入用户记录并生成 token 后,会触发 RegisterEvent(注册事件)的发布。伪代码如下,
// 1. 用户注册,写入数据库
RegisterResponseVO registerResponseVO = memberRegisterService.register(new RegisterRequestVO(request);
// 2. 生成token
String token = getToken(memberEntity.getId(), request.getSource());
log.info("login mobile {} login token {}", request.getMobile(), token);
// 3. 发布注册事件,会触发登录日志监听、优惠券赠送监听等
applicationEventPublisher.publishEvent(new RegisterEvent(request, memberEntity, token));
由于之前代码已经使用事件监听逻辑,所以这里我们的
新用户注册判断邀请关系
的逻辑就直接新建一个 NewUserInvitedListener 监听类即可。伪代码如下,
@Slf4j
@RefreshScope
@AllArgsConstructor
@Component
public class NewUserInvitedListener implements ApplicationListener<RegisterEvent> {
@Async("asyncServiceExecutor")
@Override
public void onApplicationEvent(RegisterEvent registerEvent) {
UserLoginRequestVO requestVO = registerEvent.getRequestVO();
MemberEntity memberEntity = registerEvent.getMemberEntity();
log.info("================ NewUserInvitedListener =============== registerEvent is {}", registerEvent);
// 1. 校验逻辑
validateUser(memberEntity);
// 2. 判断用户是否有邀请关系
// 3. 如果有则赠送系统资源
...
}
}
OK,代码逻辑也不复杂,写完提测交给测试下班(周五下午写完)。

发现问题
周一一来,测试就在群里 @ 后端人员说是新用户赠送的系统资源送了两次,说实话我一开始是不太信的,直到我去查了日志,发现 NewUserInvitedListener 监听类的日志确实被打印了两次,也就是说我们的 NewUserInvitedListener 监听类被触发了两次。
OK,到这里我们的问题就确确实实产生了,接下来就是解决问题。

解决思路
问题产生通常都有很多种解决方法,我们如何选择一个最适合我们当前场景的方法才能体现出我们对业务、技术的理解。
在这个监听类重复触发的场景里,就有多种解决方式,我简单列举几个,
- 添加幂等处理,防止重复执行
- 加锁,防止重复执行
- 解决下为什么监听类会重复触发
这三个解决方案各有优劣,通过对监听类的业务逻辑添加幂等逻辑或者加锁逻辑都是可以解决的,但是这不是问题根源,问题根源是在于监听类为什么会被重复触发。
在本文中,我也将带着大家一步一步探索并解决这个问题。
检查下之前的事件监听类是否也有重复触发的问题
因为这个代码是照着之前的逻辑写的,新加的 NewUserInvitedListener 被发现重复触发,那以前的 MemberLoginLogListener 是否也有重复触发的问题。伪代码如下,
@Slf4j
@Component
@AllArgsConstructor
public class MemberLoginLogListener implements ApplicationListener<RegisterEvent> {
private MemberLoginLogService memberLoginLogService;
@Async("asyncServiceExecutor")
@Override
public void onApplicationEvent(RegisterEvent event) {
MemberEntity memberEntity = event.getMemberEntity();
log.info("================ MemberLoginLogListener ===============, mobile is {}", memberEntity.getMobile());
MemberLoginLogEntity memberLoginLogEntity = MemberLoginLogConvertor.buildLoginLogEntity(event.getRequestVO(),
event.getMemberEntity());
memberLoginLogEntity.setToken(event.getToken());
memberLoginLogService.save(memberLoginLogEntity);
}
}
查询 MemberLoginLogListener 监听类的日志,发现只有一次打印,说明之前写的 MemberLoginLogListener 监听类没有重复触发的问题,那这里就很奇怪了。对比一下 NewUserInvitedListener 监听类与 MemberLoginLogListener 监听类的差别,很明显我们发现 NewUserInvitedListener 监听类上多了一个 @RefreshScope 注解。
OK,问题有可能就是 @RefreshScope 注解导致,我们去掉 @RefreshScope 注解在看看日志打印。
去掉 @RefreshScope 注解
当我们去掉 @RefreshScope 注解后,神奇的事情发生了,NewUserInvitedListener 监听类的日志打印正常了,只触发了一次!
OK,到这里我们也就发现了问题出在 @RefreshScope 注解上。
如何搜索问题
虽然我们知道了问题出在 @RefreshScope 注解上,但是我们怎么向搜索引擎描述这个问题嘞?
很多人发现了问题,但是不知道如何描述问题,怎么描述问题才能让别人一听就懂,从而能给你提供帮助。你需要把问题的重点描述出来,搜索引擎才能给予精准帮助。
在我们这个
新用户注册判断邀请关系
的场景里,很显然我们的搜索词可以是
“spring 事件监听重复触发 @RefreshScope”
可以看到我的搜索关键词有 3 个,分别是 spring、事件监听重复触发以及 @RefreshScope。让我们来看看搜索结果。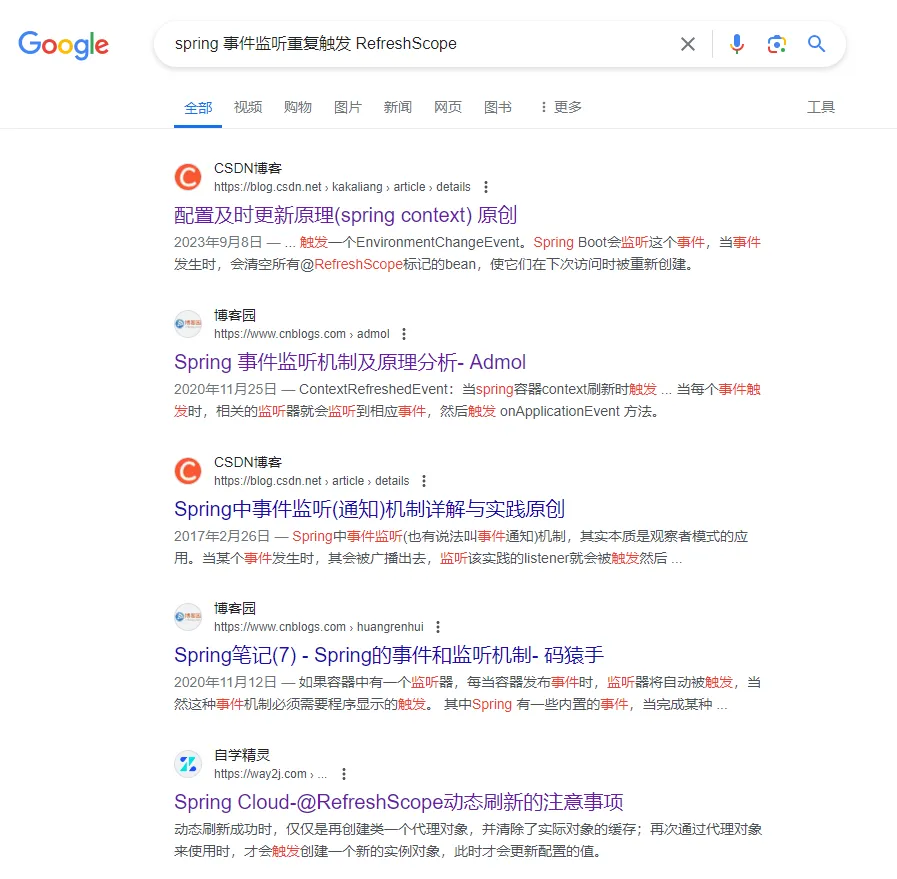
前 5 个搜索结果中,只有第五个的标题可能符合我们的搜索内容,我们点进去看一看。

很遗憾,跟我们的问题场景并不相符,我们并没有搜索到我们想要的东西。在这里我们的搜索关键词
“spring 事件监听重复触发 @RefreshScope”
并没有给予我们帮助。
回到问题本身
既然我们的问题已经定位到了,在于 @RefreshScope 会导致监听类的重复触发,可是这个关键词并没有相关搜索结果,那么我们只能换个角度。
为什么会重复触发?
在 NewUserInvitedListener 监听类中,我们使用 @Component 注解,默认注册了一个单例 bean,这个 bean 用于接收用户注册事件。既然 bean 是单一的,那就是说 Spring 发送了 2 次 RegisterEvent 事件吗?结合上文提到的 MemberLoginLogListener 监听类只触发一次的日志,很显然,Spring 只会发送了 1 次 RegisterEvent 事件。
难道说问题在于 Spring 里出现了两个 NewUserInvitedListener 类型的 bean?
那么到这里恭喜我们终于定位到了重复触发问题的根源。
如果大家了解 @RefreshScope 的原理相信大家已经猜出来了。
@RefreshScope 原理
Spring 中 @scope 注解的原理就是在创建 Scope=singleton 的 Bean 时,IOC 会保存实例在一个 Map 中,保证这个 Bean 在一个 IOC 上下文有且仅有一个实例。
SpringCloud 新增了一个自定义的作用域:refresh(可以理解为“动态刷新”),同样用了一种独特的方式改变了 Bean 的管理方式,使得其可以通过外部化配置(.properties)的刷新,在应用不需要重启的情况下热加载新的外部化配置的值。
这个 scope 是如何做到热加载的呢?RefreshScope 主要做了以下动作:
单独管理 Bean 生命周期创建 Bean 的时候如果是 RefreshScope 就缓存在一个专门管理的 ScopeMap 中,这样就可以管理 Scope 是 Refresh 的 Bean 的生命周期了(所以含 RefreshScope 的其实一共创建了两个 bean)。
重新创建 Bean
外部化配置刷新之后,会触发一个动作,这个动作将上面的 ScopeMap 中的 Bean 清空,这样这些 Bean 就会重新被 IOC 容器创建一次,使用最新的外部化配置的值注入类中,达到热加载新值的效果。
看完 @RefreshScope 的原理相信大家已经知道了出现两个 NewUserInvitedListener 类型 bean 的原因是在于 @RefreshScope 导致。这是由于 @RefreshScope 注解的内部实现创建了另外一个相同类型的 NewUserInvitedListener bean,导致我们的新用户监听逻辑被重复执行。
回到搜索关键词
假如我是说假如,假如我们不知道 @RefreshScope 的原理,自然不知道项目中出现了两个 NewUserInvitedListener 类型的 bean 是 @RefreshScope 导致。 那么我们怎么通过搜索关键词来找到这个问题嘞?
到这里也就是本文的重点所在,怎么通过搜索关键词来解决我们的问题。
先定义问题
在这个场景里我们使用的是 Spring 项目,问题本质是 @RefreshScope 在 Spring 自带的事件监听类搭配使用时,会导致 bean 重复进而导致监听类逻辑被重复执行,当我们去掉 @RefreshScope 后,也就没有这种情况。
也就是说这句话我们换个说话:
“@RefreshScope 在 Spring 自带的事件监听类搭配使用时,会生成另外一个相同的 bean 导致监听类被重复触发”
总结关键词
在上面的先定义问题中,我们提炼一下关键词,
- Spring:这个关键词在 Spring 项目中必带,大家应该没有意见把
- @RefreshScope:我们的问题根源,搜索也得带上
- 生成同一个 bean:这是一个描述语句,简要描述一下我们发现的问题
看一看搜索结果,
点进第一个结果,

OK,大功告成,看到我们框选中的地方了吗,上文的 @RefreshScope 原理解释,就是复制与这里。
贴一下原文地址:
https://blog.csdn.net/m0_71777195/article/details/127223544
一些思考
实话实说,我在测试给我上报问题,到发现这个问题来自于 @RefreshScope 注解只用了 10 分钟,如上文所说,我通过对比以前写的 MemberLoginLogListener 监听类,早早的定位到问题来自于 @RefreshScope 注解。可是到我完整修复这个问题,提交到测试环境,却花了 2 个半小时,原因是因为我在研究这个问题的根源,这也是这篇文章的由来。
假如说这个问题发生在线上,那么我根本不可能花这么多时间来研究,我需要的就是迅速解决这个问题并修复上线,避免影响更多用户。
一样的,大家在遇到这种相似问题时,如果境况紧急出现在生产环境,大家本着对工作负责的态度,应该迅速解决并做故障复盘。如果是出现在测试环境我们可以本着对技术执着可以认真专研下这个问题。
其实我还想说的是在这个问题里,我能 10 分钟定位到问题来自于 @RefreshScope 注解,可能也有运气成分。但是很多情况下当我们照驴子画马写代码,发现出了问题时,这种情况大部分还是我们“画蛇添足”导致。大家可以通过对比以前代码迅速找出问题原因。
找出了问题后是如何解决问题。这篇文章里,我给大家讲了讲我的搜索关键词心得。第一是讲重点、第二是找到问题本质,这样才能从搜索引擎嘴里找出我们想要的答案。
如果觉得这篇文章写的不错的话,可以关注我的公众号【程序员wayn】,我会更新更多技术干货、项目教学、经验分享的文章。