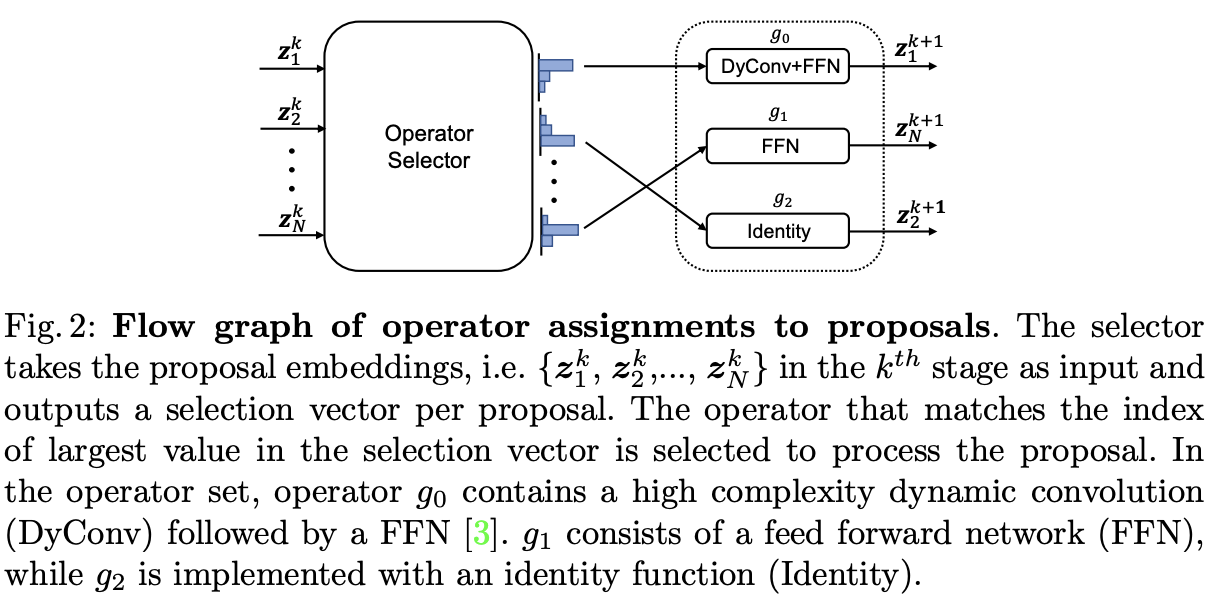
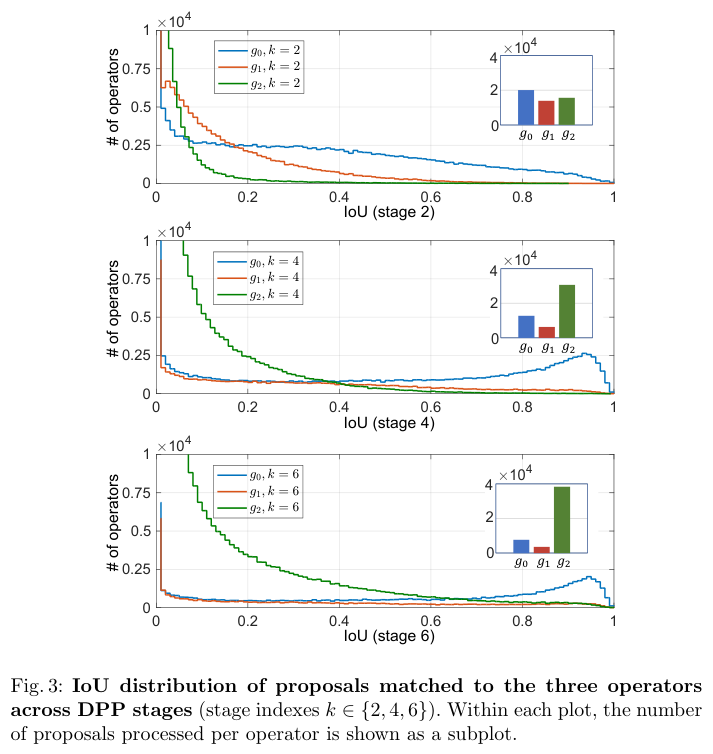
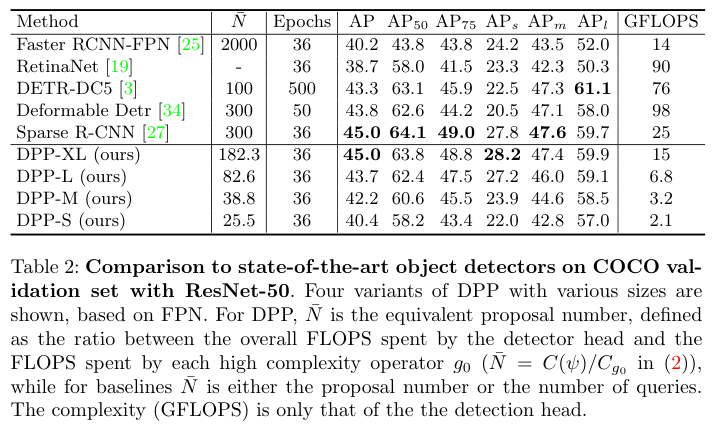
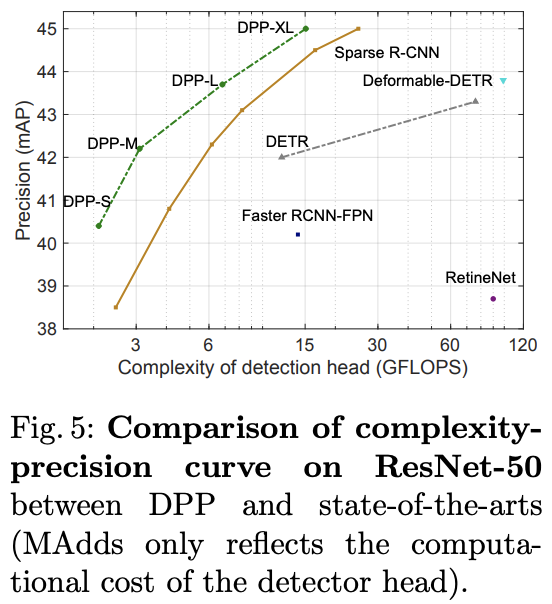
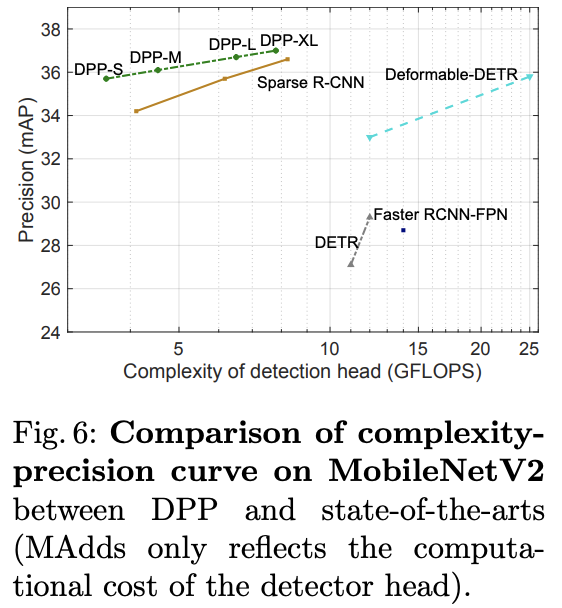
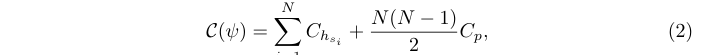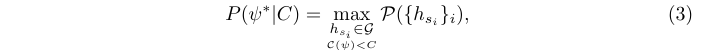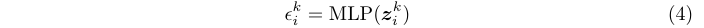在audio DSP中如何做软件固化
在audio DSP中, 软件的code和data主要放在3种不同的memory上,分别是片内的ITCM、DTCM和片外的memory(比如DDR)上。ITCM只能放code,DTCM只能放data,片外的memory既能放code也能放data。在写代码时要规划好哪些放片内,哪些放片外。上面说的这三种memory都属于RAM(random access memory, 随机访问存储器),可读可写。与之相对应的是ROM(read only memory,只读存储器),只能读。ROM相对RAM的优点之一是相同存储容量的情况下ROM的面积要比RAM小很多,在芯片上面积小就意味着成本低。为了降成本,有必要将部分audio的code放在ROM里,通常称为将软件固化。哪些code可以放进ROM呢?从ROM的只读特性知道放进ROM的code就不能改动了,因此放进ROM的code是经过充分验证的不会再改的代码,在音频领域主要是一些非常成熟的算法的代码,比如MP3解码算法的代码就适合放进ROM里。本文就以把MP3解码算法的代码放进ROM为例来讲讲是怎么一步步做的。
1,确定好哪些放进ROM里,即把哪些做固化。通常是一些非常成熟且不会再改的代码,多数是成熟算法的代码。确定前先要跟ASIC定好ROM的大小,比如128K或者256K。还要算好要放软件模块的code size和data size。要放进ROM的模块最好能把ROM塞满,充分利用ROM。本文就是把MP3解码算法的代码放进ROM里。
2,ROM在memory里是独立的一块。在芯片tape out 前软件工程师把用于ROM的二进制文件给ASIC工程师,ASIC工程师再将ROM文件里面的二进制数据放进ROM里。 开发ROM文件时,芯片还处于设计阶段,没法直接拿来用,只能在要设计芯片的相似芯片上去开发,用RAM中的一块独立的区域来模拟ROM。通常在片外memory上找一块独立的区域,因为内部memory的空间相对较小,不适合做。我在固化MP3解码code时就在DDR上找了一块独立的区域来放MP3解码算法的code和data。 即以前MP3解码的code和其他的code是放在一起的,以前MP3解码的data和其他的data是放在一起的,现在要把它们拿出来放在一个独立的区域。放在独立区域后开始调试,要确保MP3播放功能正常。调试时主要是修改LD(link descriptor)文件,改后用新生成的adsp.bin文件去播放MP3,正常播放就说明改对了。
3,ROM里的函数有可能调用其他函数,如libc里的库函数memset等。这些函数如果不放在ROM里,而是放在其他地方,它们的地址随着软件的开发就有可能发生变化(放进RAM的函数的地址是动态变化的)。而ROM里这些函数的地址还是先前做ROM时的地址,这些地址已经对应不上那些函数了,就不会得到正确的执行。因此要把这些函数排查出来,并放进ROM里。怎么排查呢?方法是在LD文件里定义一个rom_check_shift的变量,放在RAM上的code/data section的头部,好让code/data的地址产生偏移。刚开始设rom_check_shift为零,会生成ROM上code的一个反汇编文件。 然后不断增大rom_check_shift的值(比如从0到16、32、64、128等),同样会生成ROM上code的一个反汇编文件,将其与rom_check_shift为0时的反汇编文件进行比较,要确保代码的完全一样。如果不一样,看比较后不一样的地方,把找到的函数放进ROM里,直至完全一样。修改后也要确保播放MP3音乐功能完全正常。下图是比较反汇编文件时一处不一样的地方。

从上图看出,库函数memcpy()原先是放在RAM上的,由于rom_check_shift的改变,函数memcpy()的地址就不一样了。ROM里的函数调用函数memcpy()时,函数地址还是做ROM时的,可是后面随着软件的开发,memcpy()在RAM上的地址变了。ROM里的函数再去访问memcpy()原先的地址已经不能正确调用memcpy()了。因此要把memcpy()放进ROM里,确保它的地址永远不变。
4,ASIC的同学会告诉ROM的起始地址。先前是把要放在ROM上的先放在RAM里方便调试。现在调试OK了,就要把这部分放到ROM上去了。由于这部分放在ROM里就不能再包含在adsp.bin里,因此要修改生成adsp.bin的应用程序的代码,把放到ROM的部分生成单独的二进制文件,而不是放到adsp.bin里,这样adsp.bin就变小了。
5,得到用于ROM的二进制文件后,需要做格式转换,转成ASIC需要的格式。下图列出了软件生成的二进制格式以及ASIC需要的格式。

从上图看出,ASIC需要的格式是一行放8个字节,同时放在ROM里的数据是小端放的。知道怎么转换后,写个小应用程序,把我们生成的二进制文件转成ASIC需要的文件格式。
6,ASIC拿到需要的文件后,将数据放进ROM里,生成bitfile,让我们在FPGA上做验证,确保正确无误,如果有错误,这块ROM就废掉了。在FPGA上验证的通常是跟硬件相关的,如IPC通信等。要验证MP3解码功能不太方便,因此验证就变成了做数据内容的check,即ROM地址上的数据跟我们做ROM时生成的反汇编相同地址上的数据完全一致。做完FPGA验证后,ASIC就可以放心的把要做ROM的二进制数据放进ROM里了。
上面六步就是把软件模块固化的过程。