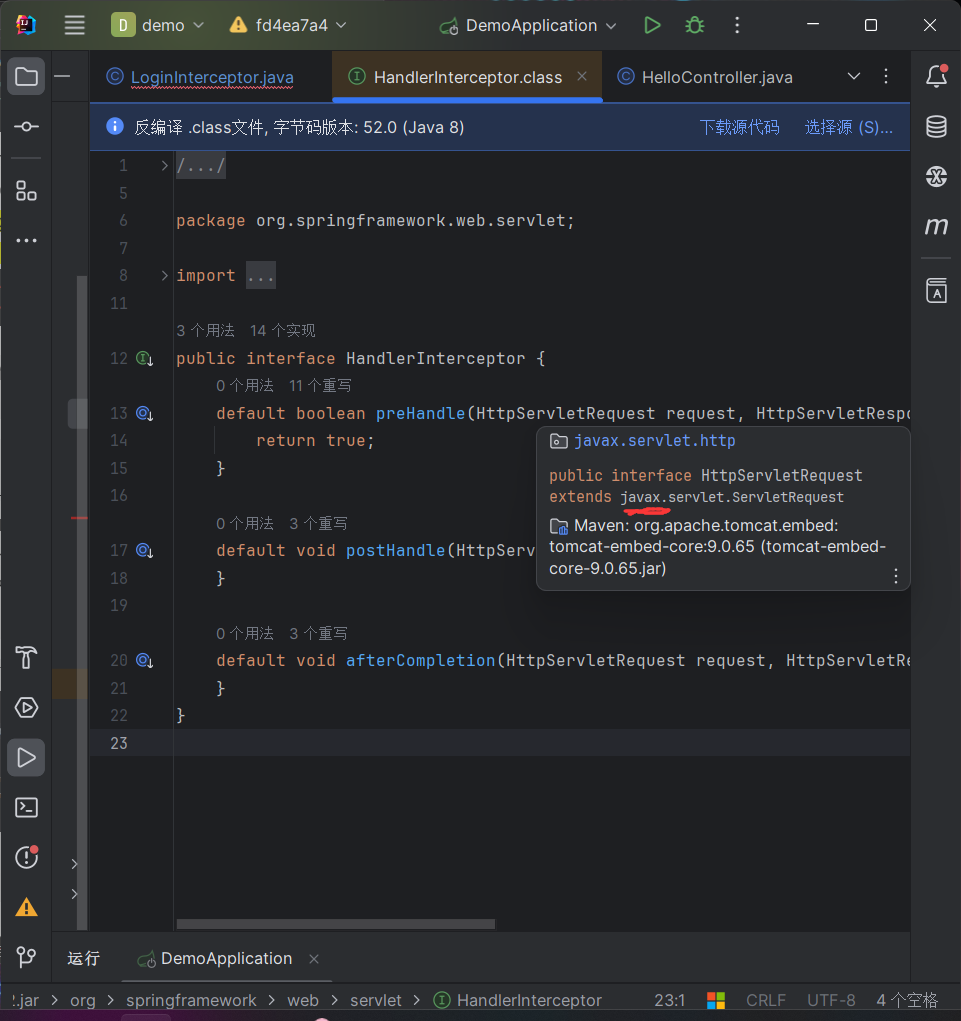
用StabilityMatrix一键安装Stable Diffusion
Stable Diffusion是2022年发布的深度学习文字到图像生成模型,它既能免费使用,又能部署在本地端,又有非常多的模型可以直接套用,在使用体验上比Midjourney和DALL-E更加强大。
Stable Diffusion使用的模型有下列几大类,对照模型网站
https://civitai.com
以形成更直观的认识:
- Base Model: Stable Diffusion的基底模型(Base models),由StableAI公司开源而来的最基础模型
- 常见的基底模型有SD 1.5、SD2.0、SDXL 1.0等
- Checkpoint: 当做图像生成的基础模型,通称为大模型
- 由Base Model为基础微调而形成的模型,可生成质量更高的图像
- 形成图像的基本风格,例如真实风格或卡通风格等,分别使用不同的两种Checkpoint
- 合并多个Checkpoint而成的形成Checkpoint Merge
- 选项模型:附加在Checkpoint上的微调模型,可视为修补+滤镜功能的模型,增强或改变图像的风格
- Textual Inversion(文本反转,embedding): 用新的关键词来产生新的特征
- LoRA(Low-Rank Adaptation,低秩调整): Checkpoint就像是AI画家的「基本画功」,而LoRA则是要求AI画家「照这个风格」产生图片
- VAE(Value Auto Encoder): 用来调整亮度或饱和度的微调模型
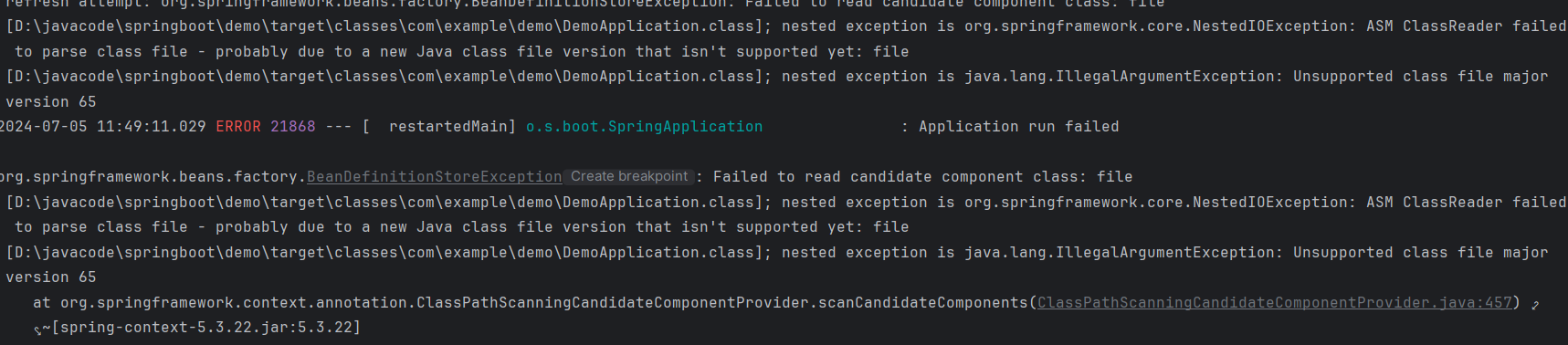
不过Stable Diffusion的部署步骤有点繁复,必须安装Python相关环境、Git执行环境等等,但现在通过采用AvanloniaUI编写的跨平台桌面应用StabilityMatrix只要执行一个StabilityMatrix.exe就可以了,它会自动下载需要的文件与模型,并提供了图形界面让我们可以方便的控制多达 10几个Web UI(支持Automatic 1111、Comfy UI、SD.Next (Vladmandic)、VoltaML、InvokeAI、Fooocus 和Fooocus MRE), 可以说StabilityMatrix大幅降低了Stable Diffusion的使用门槛。
本次介绍完整的StabilityMatrix安装步骤,Stablility 支持Linux、Mac和Windows,下面的安装是Windows 11下进行的。
1. 安装步骤
- 解压缩 StabilityMatrix-win-x64.zip 后执行StabilityMatrix.exe。 在检查到NVIDIA显卡后,勾选同意授权协议再按【Continue】

- 勾选【Portable Mode】以建立便携环境,运行环境会建立在执行文件相同位置的Data文件夹里

- 选择Web UI,先使用最常见的Stable Diffusion WebUI,点击【Install】

开始安装并下载需要的文件...,它将在安装过程中显示推荐的型号(检查点)。 它分为最流行的常规型号“SD1.5系列”和“SDXL系列”,具有高性能而不是较大的VRAM负载。 每个都有几GB的大容量,因此下载时间会增加,但是如果有您想要的模型,请在此处查看并下载。
- 安装完成后会显示《Package》页面
- 点击三横线显示完整的侧边栏菜单
- 点击绿色的【Package】就能启动安装好的SwarmUI
- 【启动】按钮右侧的齿轮可设定启动参数

关于启动选项
更高级一点。 SDwebUI 可以通过填写写成“--◯◯”的“命令行参数”来启动,以启用各种可选功能。 例如,有一个功能可以生成具有少量 VRAM 的 grabo,并加快生成速度。
在 StabilityMatrix 中,您可以在按下“启动”按钮之前按旁边的齿轮“⚙”按钮来调用启动选项屏幕,并且可以通过选中它通过“启动”来激活它。

请参阅官方网站了解每个启动选项的含义。 您还可以通过自己填写参数来添加菜单中没有的内容。这里只是您应该记住的默认菜单中的选项。
-xformers:有望提高图像生成速度并显著减少 VRAM 使用。 请注意,它只能与 NVIDIA Gravo 一起使用。 几乎每个人都使用它
-autolaunch:webUI加载完毕后在浏览器中自动启动的功能,但在v1.6.0及以上版本中,可以在webui上设置,所以没有用。
-lowvram:用于低 VRAM 抓取。 性能可能是灾难性的,因此能够生成图像。
–medvram — 以牺牲速度为代价减少VRAM的使用。
-medvram_sdxl:仅当使用 SDXL 模型时才激活 medvram。
5.点击【Packages】→【Add Package】可再新增其他的WebUI套件

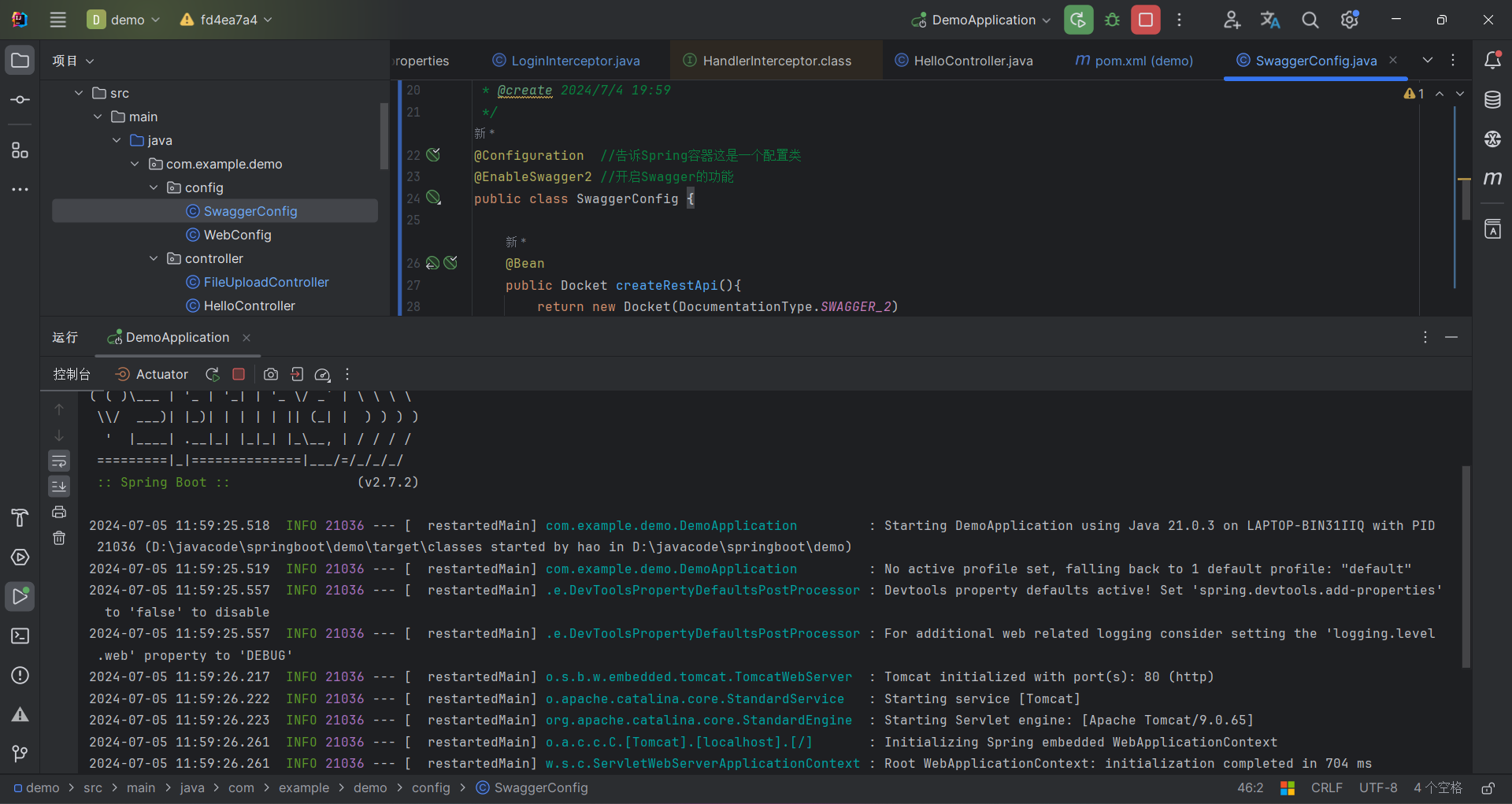
6. 第一次启动(启动)时会自动复制需要的档案,其中默认的模型主档 v1-5-pruned-emaonly.safetensors 有3.97GB,需要花点时间下载。下载完成并启动后,会自动开启浏览器浏览网址
http://127.0.0.1:7801

2. 初次测试
- State Diffusion checkpoint(大模型)选用预设的v1-5-pruned-emaonly.safetensors
,学习模型(检查点)通常主要以扩展名“.safetensors”和“.ckpt”分发,如果您将它们扔到指定的文件夹中,它们将起作用。 除了 StabilityAI 的每个版本的 StableDiffusion 之外,网络上还分享了无数的衍生模型,有些带有插图,有些带有逼真的色调,有些介于两者之间,有些擅长柔和的表达,等等。 - 在txt2img分页的【Prompt】(正面提示词)输入
a cute kitten - 【Negative Prompt】(负面提示词)输入
(worst quality:2),(low quality:2),(normal quality:2),lowres
- 负面提示词指示避免产生的属性,括号里可额外设定权重
- 点击【Generate】开始生成图片。 产生时StabilityMatrix.exe窗口会显示执行记录
2.1. 生成结果

3.总结
目前 ComfyUI 对于新模型与新应用支持更好,已经有超越 Stable Diffusion web UI的趋势,SwarmUI 同时支持ComfyUI和SDWebUI,Fooocus由于简洁、占用资源低的原因,也越来越受欢迎,如果你是多个软件的用户,那么不妨考虑使用Stability Matrix 进行集中化管理。