全球电子制造主要集中在中国,面向未来工业4.0、中国制造2025的战略转型升级,互联互通是基础、数据是核心,如何从用户角度来定义设备加工数据的内容完整性、有效性、可扩展性将是工厂通讯连接交换的工作重点。

IPC-CFX下设备如何通信?
在IPC-CFX的标准下,设备的数据被定义为
制造主题(Topic)
和
消息结构(Message)
。设备不太需要关注数据发送到哪里,数据来源于哪里,只需要知道在什么时机下发送什么数据,收到什么数据执行什么操作即可。
CFX都定义了哪些标准的Topic呢,如下图所示:

以一个Topic "WorkOrdersScheduled"为例,顾名思义:工单已排程。这个Topic代表会发出一个已经排好执行计划的工单,该工单即将在稍后某个特定时间某条生产线如SMT Line 1开始执行生产,其定义的消息数据体如下所示,还是比较完善的:
{"ScheduledWorkOrders": [
{"WorkOrderIdentifier": {"WorkOrderId": "WO1122334455","Batch": null},"Scheduler": {"OperatorIdentifier": "BADGE4486","ActorType": "Human","LastName": "Doe","FirstName": "John","LoginName": "john.doe@domain1.com"},"WorkArea": "SMT Line 1","StartTime": "2018-08-02T11:00:00","EndTime": "2018-08-02T15:00:00","ReservedResources": ["L1PRINTER1","L1PLACER1","L1PLACER2","L1OVEN1"],"ReservedTools": [
{"UniqueIdentifier": "UID23890430","Name": "TorqueWrench_123"}
],"ReservedOperators": [
{"OperatorIdentifier": "BADGE489435","ActorType": "Human","LastName": "Smith","FirstName": "Joseph","LoginName": "joseph.smith@abcdrepairs.com"}
],"ReservedMaterials": [
{"UniqueIdentifier": "UID23849854385","InternalPartNumber": "PN4452","Quantity": 0.0},
{"UniqueIdentifier": "UID23849854386","InternalPartNumber": "PN4452","Quantity": 0.0},
{"UniqueIdentifier": "UID23849854446","InternalPartNumber": "PN3358","Quantity": 0.0}
]
}
]
}又如 "WorkOrdersUnschedule" 这个Topic,代表SMT Line 1的某个工单即将被取消,其数据格式就简单很多:
{"ScheduledWorkOrderIdentifiers": [
{"WorkOrderIdentifier": {"WorkOrderId": "WO1122334455","Batch": null},"WorkArea": "SMT Line 1"}
]
}除此之外,CFX还用一个统一的消息信封来包裹这个消息体,我们可以理解为定义了一个如下所示的统一消息格式:
public classCFXEnvelope
{public string MessageName {get;set;} //eg. CFX.Produciton.Application.MaterialsApplied
public string Version {get;set;} //eg. 1.7
......public T MessageBody {get;set;} //消息体内容:泛型
}
Anyway,这个对于我们IT工程师是比较好理解的,这就跟我们的系统和系统之间通过消息队列(如Kafka)进行发布订阅模式的异步通信一模一样。不过这里呢,是机器与机器,机器与企业之间的通信。
但是,
IPC-CFX标准下是基于AMQP协议做消息传输的,每台设备都可以看作是一个AMQP端点
,通过发布和订阅实现数据的交互。此外,IPC-CFX
还支持点对点(Point-to-Point)
的消息模式(请求/响应模式)。
我们都知道,Kafka是不支持AMQP协议的,因此,要使用IPC-CFX就不能直接使用Kafka作为Message Broker,而IPC-CFX官方的案例也都是使用RabbitMQ来写的,虽然我觉得在设备数据交换场景Kafka的性能会更好。
如何开发机台程序?
如何让一台台的设备变成符合IPC-CFX标准的AMQP节点呢?常规做法就是在机台侧开发一个程序,这里IPC-CFX组织为我们提供了一个SDK,其实是一个.NET开发包(Nuget安装即可),所以对咱们.NET开发者是十分友好的。
这个SDK提供了以下功能:
将所有CFX消息的用Class/Object表示。
能够将CFX消息对象序列化和反序列化为JSON格式。
能够通过AMQP传输协议将CFX消息发布到一个或多个目的地。
能够通过AMQP传输协议从一个或多个订阅源接收CFX消息。
完全自动化的网络连接故障管理(即使在网络宕机或其他不可靠的情况下保持AMQP连接)。
CFX消息“假脱机”。维护由于网络条件错误而无法传输的CFX消息的持久队列。一旦网络服务恢复,消息将自动按原来的顺序传输。
点对点CFX端点命令(请求/响应)支持。
支持AMQP 1.0 SASL认证和TLS加密。
官方SDK文档传送门:
SDK文档
不过,通过学习发现,这个SDK主要还是提供了统一的Topic和Message的数据结构,至于和RabbitMQ的连接,个人感觉不太方便使用,我们完全可以使用其他成熟的RabbitMQ API组件来完成发布和订阅。
接下来,我们来快速实践一下CFX的两种通信方式:发布订阅 和 点对点。
快速开始:搭建一个RabbitMQ
既然IPC-CFX是基于AMQP协议来的,那我们就搭一个RabbitMQ吧。这里我们快速用docker-compose安装一个RabbitMQ。
version: '3'services:
rabbitmq1:
image: rabbitmq:3.8-management
container_name: rabbit-mq-service
hostname: rabbit-mq-server
ports:
-"5672:5672"-"15672:15672"restart: always
environment:
- RABBITMQ_DEFAULT_USER=rabbit # user account
- RABBITMQ_DEFAULT_PASS=EdisonTalk2024 # password
volumes:
- rabbitmq_data:/var/lib/rabbitmq
volumes:
rabbitmq_data:
driver: local
然后,通过下面的命令把RabbitMQ Run起来:需要注意的点就是需要手动开启AMQP1.0协议!
docker-compose up -d
#进入RabbitMQ容器
docker exec -it rabbit-mq-service /bin/bash
#开启AMQP1.0协议
rabbitmq-plugins enable rabbitmq_amqp1_0
成功运行起来后,能够成功打开RabbitMQ管理界面:

快速开始:实现基于CFX标准的发布订阅通信
发布者
这里我们通过Visual Studio创建一个控制台应用程序,基于.NET Framework 4.8来实现。
首先,安装Nuget包:
其次,完成联接Broker 和 发布Message 的代码:
namespaceAMQP.MachineA
{/// <summary>
///MachineA: SEWC.SMT.001/// </summary>
public classProgram
{private const string _machineName = "SDC.SMT.001";private const string _amqpBroker = "rabbit-mq-server"; //RabbitMQ-Host
private const string _amqpUsername = "rabbit"; //RabbitMQ-User
private const string _amqpPassword = "rabbit-password"; //RabbitMQ-Password
public static void Main(string[] args)
{
Console.WriteLine($"Current Machine: {_machineName}");
Console.Write($"Current Role: Publisher {Environment.NewLine}");var connStr = $"host={_amqpBroker};username={_amqpUsername};password={_amqpPassword}";using (var amqpBus =RabbitHutch.CreateBus(connStr))
{while (true)
{
Console.WriteLine($"[Info] Starting to send a message to AMQP broker.");//Build a CFX Message of MaterialsApplied
var message = new CFXEnvelope(newMaterialsApplied()
{
TransactionId=Guid.NewGuid(),
AppliedMaterials= new List<InstalledMaterial>{newInstalledMaterial()
{
QuantityInstalled= 1,
QuantityNonInstalled= 2}
}
});
amqpBus.PubSub.Publish(message);
Console.WriteLine($"[Info] Finished to send a message to AMQP broker.");
Console.WriteLine("-------------------------------------------------------------------");
Thread.Sleep(1000 * 3);
}
}
}
}
}
Note:
这里只是为了快速演示,实际中账号密码以及Broker地址建议写到配置文件中,并使用AMQPS协议联接,否则你的账号密码会被明文在网络中传输。
订阅者
参考发布者,仍然创建一个控制台应用程序,安装两个NuGet包。
然后,实现消费者逻辑:
namespaceAMQP.MachineB
{/// <summary>
///MachineB: SEWC.SMT.002/// </summary>
public classProgram
{private const string _machineName = "SDC.SMT.002";private const string _amqpBroker = "rabbit-mq-server"; //RabbitMQ-Host
private const string _amqpUsername = "rabbit"; //RabbitMQ-User
private const string _amqpPassword = "rabbit-password"; //RabbitMQ-Password
public static void Main(string[] args)
{
Console.WriteLine($"Current Machine: {_machineName}");
Console.WriteLine($"Current Role: Subscriber {Environment.NewLine}");var connStr = $"host={_amqpBroker};username={_amqpUsername};password={_amqpPassword}";using (var amqpBus =RabbitHutch.CreateBus(connStr))
{
amqpBus.PubSub.Subscribe<CFXEnvelope>(_machineName, message =>{if (message.MessageBody isMaterialsApplied)
{
Console.WriteLine($"[Info] Got a message with topic {message.MessageName} :{Environment.NewLine}{message.ToJson(true)}");
Console.WriteLine("-------------------------------------------------------");
}
});
Console.WriteLine("Press any key to exit.");
Console.ReadLine();
}
}
}
}
最终的Demo效果如下图所示:
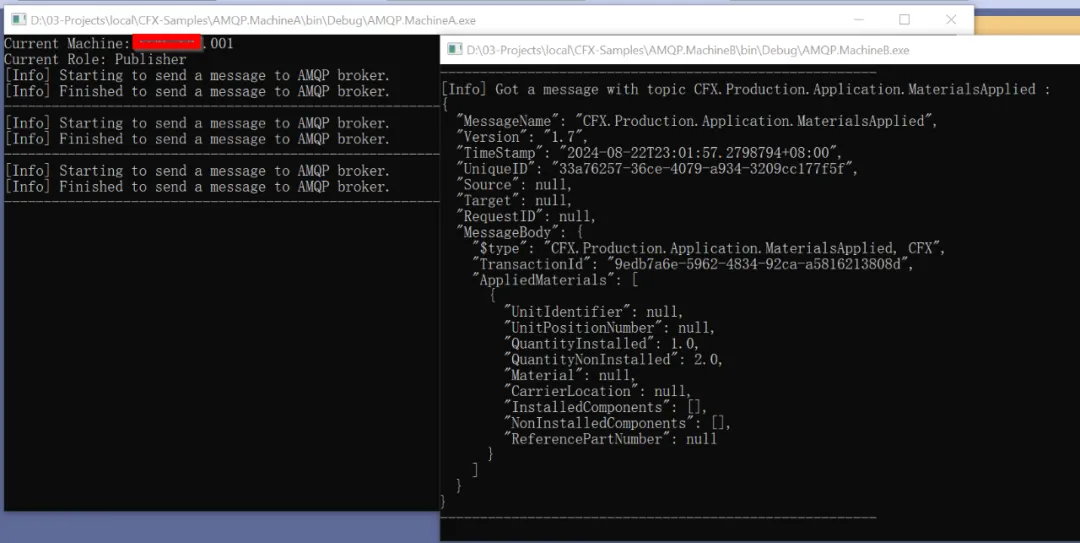
两个控制台应用程序模拟两个机台程序,实现了基于AMQP协议和CFX标准格式的异步通信。但是整体来讲,实现异步通信并不是重点,而是两个机台采用了所谓的“
统一语言
”。
快速开始:实现基于CFX标准的点对点通信
基于上面的了解,我们知道基于CFX我们还可以让设备之间实现点对点的通信,也可以不通过Broker转发,而且它仍然是基于AMQP协议的。
在点对点模式下,基于CFX SDK,会自动帮你创建一个基于Socket的通信进程,机台程序之间可以互相应答。
(1)机台A
namespaceP2P.MachineA
{/// <summary>
///MachineA: SEWC.SMT.001/// </summary>
public classProgram
{private const string _sendCfxHandle = "SDC.SMT.001"; //Sender
private const string _receiveCfxHandle = "SDC.SMT.002"; //Receiver
private const string _sendRequestUri = "amqp://127.0.0.1:8234"; //Sender
private const string _receiveRequestUri = "amqp://127.0.0.1:8235"; //Receiver
public static void Main(string[] args)
{
Console.WriteLine($"Current Machine: {_sendCfxHandle}");
Console.WriteLine($"Current Uri: {_sendRequestUri}");
OpenRequest();
Console.WriteLine("Press Enter Key to start the CFX Sender");
Console.ReadKey();while (true)
{
SendRequest();
Thread.Sleep(1000 * 5); //Send message every 5 seconds
}
}#region AMQP Sender
private staticAmqpCFXEndpoint _sendRequestEndpoint;private static voidOpenRequest()
{if (_sendRequestEndpoint != null)
{
_sendRequestEndpoint.Close();
_sendRequestEndpoint= null;
}
_sendRequestEndpoint= newAmqpCFXEndpoint();
Console.WriteLine($"[Debug] SendCFXEndpoint.IsOpen : {_sendRequestEndpoint.IsOpen.ToString()}");
_sendRequestEndpoint.Open(_sendCfxHandle,newUri(_sendRequestUri));
Console.WriteLine($"[Debug] SendCFXEndpoint.IsOpen : {_sendRequestEndpoint.IsOpen.ToString()}");
AmqpCFXEndpoint.RequestTimeout= TimeSpan.FromSeconds(10 * 2);
}private static voidSendRequest()
{var message = CFXEnvelope.FromCFXMessage(newMaterialsApplied()
{
TransactionId=Guid.NewGuid(),
AppliedMaterials= new List<InstalledMaterial>{newInstalledMaterial()
{
QuantityInstalled= 1,
QuantityNonInstalled= 2}
}
});
message.Source=_sendCfxHandle;
message.Target=_receiveCfxHandle;
message.TimeStamp=DateTime.Now;try{
Console.WriteLine($"[Info] Starting to send a message to Target Machine {_receiveCfxHandle}.");var response =_sendRequestEndpoint.ExecuteRequest(_receiveRequestUri, message);
Console.WriteLine($"[Info] Target Machine {_receiveCfxHandle} returns : {Environment.NewLine}{response.ToJson(true)}");
}catch(Exception ex)
{
Console.WriteLine($"[Error] Exception message: {ex.Message}");
}finally{
Console.WriteLine("-------------------------------------------------------");
}
}#endregion}
}
Note:
既然是点对点,那发送者就必须要知道接收者的位置。
(2)机台B
namespaceP2P.MachineB
{/// <summary>
///MachineB: SEWC.SMT.002/// </summary>
public classProgram
{private const string _receiveCfxHandle = "SDC.SMT.002";private const string _receiveRequestUri = "amqp://127.0.0.1:8235";public static void Main(string[] args)
{
Console.WriteLine($"Current Machine: {_receiveCfxHandle}");
Console.WriteLine($"Current Uri: {_receiveRequestUri}");
OpenListener();
Console.WriteLine("Press Entery Key to end the CFX Listener");
Console.ReadKey();
}#region AMQP Receiver
private staticAmqpCFXEndpoint _receiveRequestEndpoint;private static voidOpenListener()
{if (_receiveRequestEndpoint != null)
{
_receiveRequestEndpoint.Close();
_receiveRequestEndpoint= null;
}
_receiveRequestEndpoint= newAmqpCFXEndpoint();
_receiveRequestEndpoint.OnRequestReceived-=CFXMessageOnRequestReceived;
_receiveRequestEndpoint.OnRequestReceived+=CFXMessageOnRequestReceived;
Console.WriteLine($"[Debug] SendCFXEndpoint.IsOpen: {_receiveRequestEndpoint.IsOpen.ToString()}");
_receiveRequestEndpoint.Open(_receiveCfxHandle,newUri(_receiveRequestUri));
Console.WriteLine($"[Debug] SendCFXEndpoint.IsOpen: {_receiveRequestEndpoint.IsOpen.ToString()}");
AmqpCFXEndpoint.RequestTimeout= TimeSpan.FromSeconds(10 * 2);
}private staticCFXEnvelope CFXMessageOnRequestReceived(CFXEnvelope message)
{
Console.WriteLine($"[Info] Got a message from Source Machine {message.Source} :{Environment.NewLine}{message.ToJson(true)}");
Console.WriteLine("-------------------------------------------------------");var result = (CFXEnvelope)null;if (message.MessageBody isWhoIsThereRequest)
{
result= CFXEnvelope.FromCFXMessage(newWhoIsThereResponse()
{
CFXHandle=_receiveCfxHandle,
RequestNetworkUri=_receiveRequestUri,
RequestTargetAddress= "..."});
}else if (message.MessageBody isMaterialsApplied)
{
result= CFXEnvelope.FromCFXMessage(newWhoIsThereResponse()
{
CFXHandle=_receiveCfxHandle,
RequestNetworkUri=_receiveRequestUri,
RequestTargetAddress= "..."});
}else{return null;
}
result.Source=_receiveCfxHandle;
result.Target=result.Source;
result.TimeStamp=DateTime.Now;returnresult;
}#endregion}
}
点对点Demo效果:

小结
本文我们了解了IPC-CFX标准产生的背景 和 用途,它是机器设备之间通信的“
统一语言
”,是大家都懂的“普通话”而不是“方言”。
首先,IPC-CFX使用AMQP v1.0传输协议实现安全的连接,使用JSON进行数据编码,提供了明确的消息结构和数据内容,确保即插即用。
其次,我们通过两个Demo快速了解了如何实现一个基于CFX标准的机台端应用程序,来实现“统一语言”的设备间通信。
最后,就目前互联网上的资料来看,国内社区对于CFX的应用来看整体都还是不多的,我们也还处于学习阶段,希望未来或许有新的更新分享。
参考资料
IPC CFX 官方文档:Getting Started with SDK
齐开得科技:IPC-CFX在SMT领域的应用
MQTT vs AMQP:物联网通信协议对比