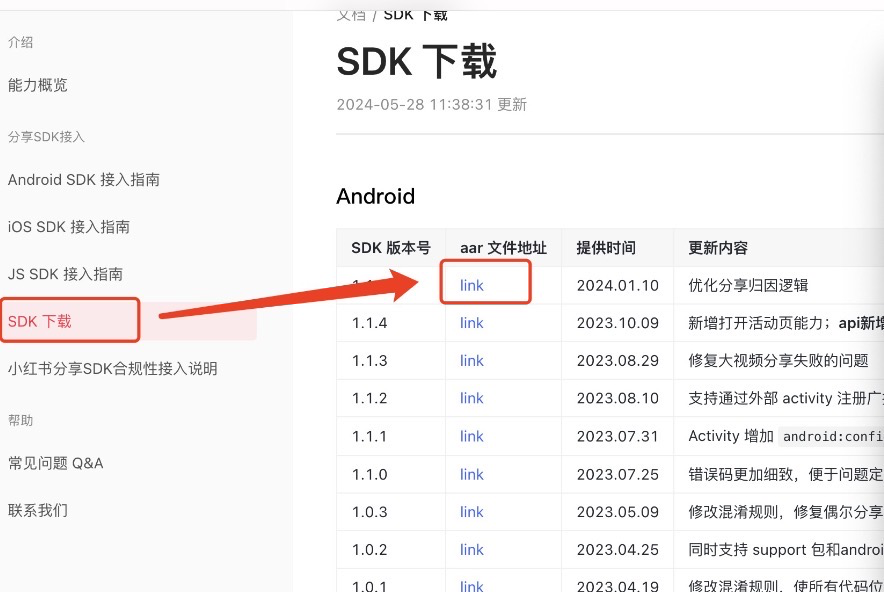
用GDI+旋转多边形来绘制一个时钟摸拟小程序
效果图

在头文件类中声明变量
TCHAR m_dayStr[4]; // 日期
TCHAR m_weekStr[4]; // 星期
Gdiplus::Font*m_pFont; // 字体
Gdiplus::StringFormat m_strFormat; // 格式化字符串
Gdiplus::Pen*m_pPen; // 画笔
Gdiplus::SolidBrush*m_pBrush; // 画刷
Gdiplus::RectF m_dayRect; // 日期矩形
Gdiplus::RectF m_weekRect; // 星期矩形
Gdiplus::PointF m_orgPointF;//圆点坐标 float m_rColok; //圆半径
Gdiplus::PointF hourPts[4]; //时针多边形数组
Gdiplus::PointF mimPts[4]; //分针多边形数组
Gdiplus::PointF scrPts[2]; //秒针数组
在初始化函数中初始变量的值
//获得系统时间 SYSTEMTIME sysTime;
GetLocalTime(&sysTime);//格式化日期和星期字符串 _stprintf_s(m_dayStr,TEXT("%02d"),sysTime.wDay);
TCHAR weekStrs[7][4]={L"日",L"一",L"二",L"三",L"四",L"五",L"六"};
_stprintf_s(m_weekStr,TEXT("%s"),weekStrs[sysTime.wDayOfWeek]);//启动时间计时器 SetTimer(m_hWnd,11,1000,NULL);
在WM_SIZE中计算圆点,半径,多边形分针,时针,秒针的顶点坐标数组值
float cx=LOWORD(lParam);float cy=HIWORD(lParam);//计算圆点 m_orgPointF.X=cx/2;
m_orgPointF.Y=cy/2;//计算半径 m_rColok=min(cx,cy)/2;
m_rColok-=10;float r=m_rColok;//秒针数组赋值 scrPts[0].X=0;
scrPts[0].Y=-r*9/10;
scrPts[1].X=0;
scrPts[1].Y=r*2/10;//分针多边形坐标数组 mimPts[0].X=(float)(-r*0.7 / 10);
mimPts[0].Y=0;
mimPts[1].X=0;
mimPts[1].Y=-r * 8/ 10;
mimPts[2].X=(float)(r*0.7 / 10);
mimPts[2].Y=0;
mimPts[3].X=0;
mimPts[3].Y=r * 2/ 10;//时针多边形数组 hourPts[0].X=-r / 10;
hourPts[0].Y=0;
hourPts[1].X=0;
hourPts[1].Y=-r * 6/ 10;
hourPts[2].X=r / 10;
hourPts[2].Y=0;
hourPts[3].X=0;
hourPts[3].Y=r * 2/ 10;//日期矩形 m_dayRect.X=r-16;
m_dayRect.Y=-10;
m_dayRect.Width=20;
m_dayRect.Height=20;//日期矩形 m_weekRect.X=r-36;
m_weekRect.Y=-10;
m_weekRect.Width=20;
m_weekRect.Height=20;
用旋转图片来绘制多边形,
图片旋转是以圆点为中心来旋转的,
所以要重新设置坐标系圆点为表盘中心点
自定义函数RotatePolygon来计算多边形的旋转,和绘制
// 旋转多边形,并绘制
// (绘制对象,多边形顶点坐标数组,顶点个数,旋转角度)
void RotatePolygon(Gdiplus::Graphics* graphics, Gdiplus::PointF* points, int numPoints, floatangle) {//创建旋转矩阵 Gdiplus::Matrix matrix;
matrix.Rotate(angle);//旋转多边形的每个点 Gdiplus::PointF* rotatedPoints = newGdiplus::PointF[numPoints];for (int i = 0; i < numPoints; i++) {
Gdiplus::PointF point=points[i];
matrix.TransformPoints(&point, 1);
rotatedPoints[i]=point;
}
Gdiplus::Pen pen(Color(255,0,0,0),(numPoints==2) ? 2.0f:1.0f);//绘制旋转后的多边形 graphics->DrawPolygon(&pen, rotatedPoints, numPoints);
// 用线性渐变画刷填充多边形
graphics->FillPolygon(&Gdiplus::LinearGradientBrush(rotatedPoints[0],rotatedPoints[2],
Color(255,0,0,255),Color(255,255,255,0)),rotatedPoints,numPoints);delete[] rotatedPoints;
}
最后在WM_PAINT消息中绘制
voidMyMainWnd::OnPaint(){
PAINTSTRUCT ps;
HDC hdc=BeginPaint(m_hWnd,&ps);//创建内存dc,创建内存位图,并将内存位图选入内存dc中 HDC hmdc=CreateCompatibleDC(hdc);;
HBITMAP hBitmap=CreateCompatibleBitmap(hdc,ps.rcPaint.right,ps.rcPaint.bottom);
HGDIOBJ hOldMap=SelectObject(hmdc,hBitmap);//创建在内存dc中绘图对象 Gdiplus::Graphics g(hmdc);
g.SetSmoothingMode(SmoothingModeAntiAlias);//设置抗锯齿模式//用指定颜色填充整个内存位图 m_pBrush->SetColor(Color(255,128,128,129));
g.FillRectangle(m_pBrush,0,0,ps.rcPaint.right,ps.rcPaint.bottom);//设置新的坐标系原点为表盘中心点 Gdiplus::Matrix transform;
transform.Translate(m_orgPointF.X, m_orgPointF.Y);
g.SetTransform(&transform);floatxBegin,yBegin;float rClock=m_rColok; //圆的半径//用指定颜色的画刷,绘制表盘上的刻度 m_pBrush->SetColor(Color(255,217,222,18));for(int i=0;i<60;i++)
{
xBegin= (float)( rClock * sin(2 * PI*i / 60));
yBegin= (float)(rClock * cos(2 * PI*i / 60));if (i % 5)
{//填充小圆点表示小刻度 g.FillEllipse(m_pBrush,xBegin-2,yBegin-2,4.0f,4.0f);
}else{//填充大圆点表示大刻度 g.FillEllipse(m_pBrush,xBegin-4,yBegin-4,8.0f,8.0f);
}
}//获取系统时间 SYSTEMTIME x;
GetLocalTime(&x);//绘制显示日期和星期的矩形区域 m_pPen->SetColor(Color::Black);
m_pBrush->SetColor(Color::YellowGreen);
g.DrawRectangle(m_pPen,m_dayRect);
g.DrawRectangle(m_pPen,m_weekRect);
g.FillRectangle(m_pBrush,m_dayRect);
g.FillRectangle(m_pBrush,m_weekRect);//绘制日期和星期的字符串文本 m_pBrush->SetColor(Color::Black);
g.DrawString(m_dayStr,-1,m_pFont,m_dayRect,&m_strFormat,m_pBrush);
g.DrawString(m_weekStr,-1,m_pFont,PointF(m_weekRect.X+1,m_weekRect.Y+4),m_pBrush);//绘制时针 float tem=(float)((float)x.wMinute/60);float fHour=x.wHour+tem;float sita=float(fHour*30);
RotatePolygon(&g,hourPts,4,(float)sita); //计算时针旋转角度并绘制//绘制分针 sita=float(x.wMinute*6);
RotatePolygon(&g,mimPts,4,(float)sita);//绘制秒针 sita = float(x.wSecond*6);
RotatePolygon(&g,scrPts,2,sita);//绘制圆心 m_pBrush->SetColor(Color(255,0,0,255));
g.FillEllipse(m_pBrush,-6,-6,12,12);//将内存dc中绘制的图片复制到当前dc中 BitBlt(hdc,0,0,(int)ps.rcPaint.right,(int)ps.rcPaint.bottom,hmdc,0,0,SRCCOPY);//释放内存位图,内存dc SelectObject(hmdc,hOldMap);
DeleteObject(hBitmap);
DeleteObject(hmdc);
EndPaint(m_hWnd,&ps);
}