@
创建和插入代码片段
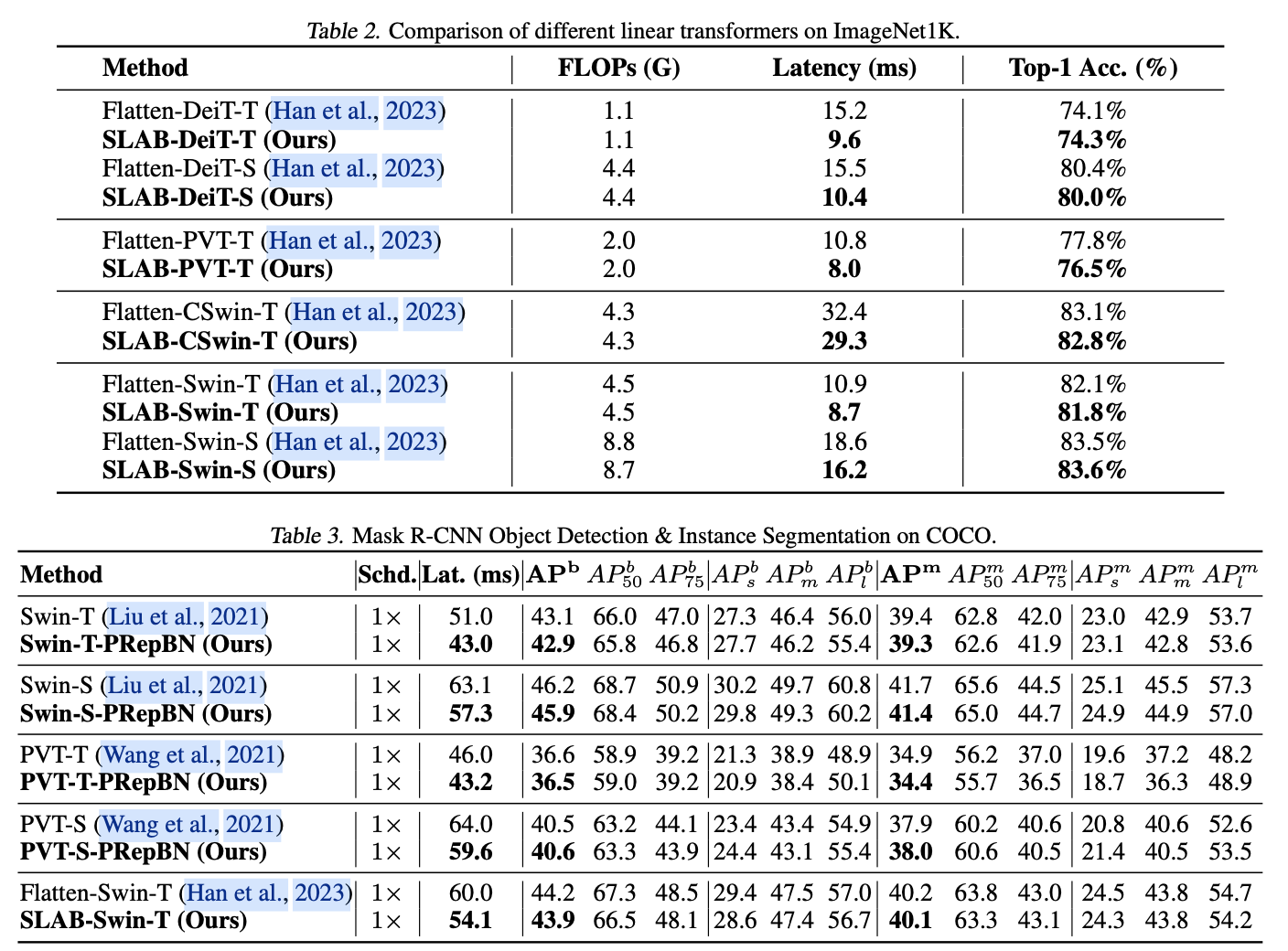
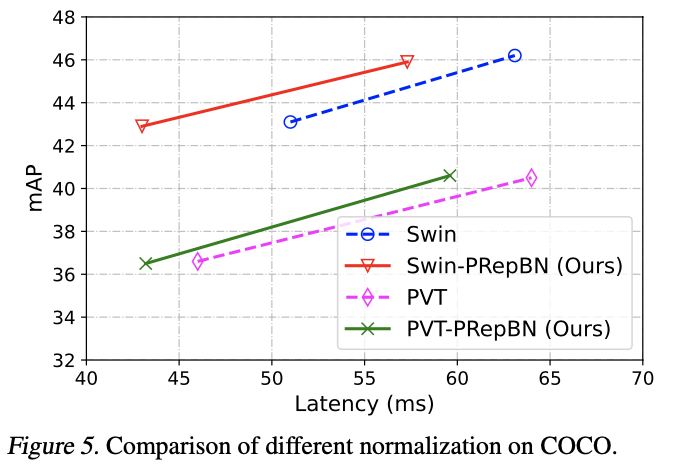
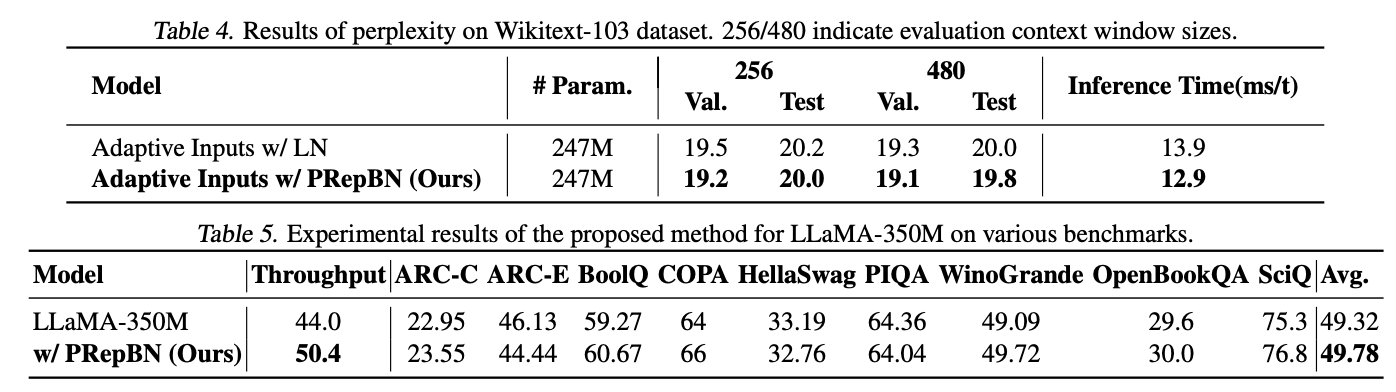
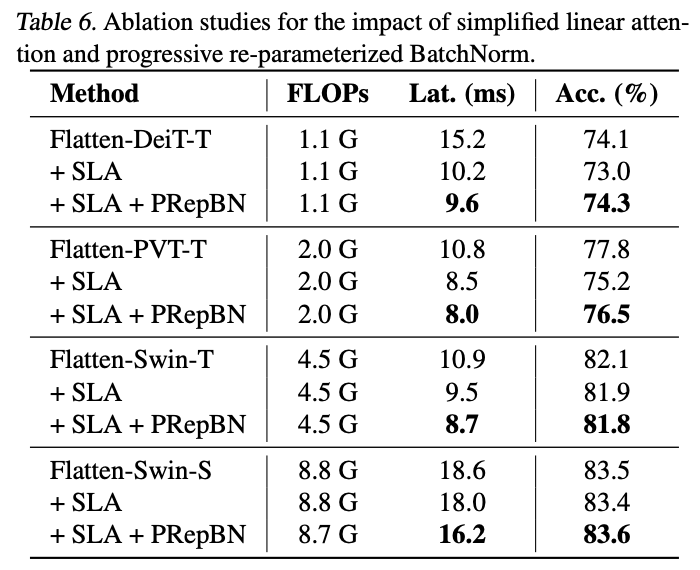
VS Code扩展提供了数据存储,其中globalState是使用全局存储的Key-Value方式来保存用户状态,支持在不同计算机上保留某些用户状态,详情请参考
官方文档
若在编辑器区域有选中的文本,点击右键菜单中点击创建Snippet,则调用
extension.snippetCraft.createSnipp
命令,执行创建代码片段。

创建服务类
SnippService.ts
,代码如下
export async function AddSnipp(context: ExtensionContext, state: Partial<ISnipp>) {
const content = await getSnippText();
const trimmedName = content?.text?.trim().substring(0, 20) || '';
await _addOrUpdateSnipp(context, { ...state, name: trimmedName }, content)
}
在
_addOrUpdateSnipp
方法中对
snipps
进行更新操作
async function _addOrUpdateSnipp(context: ExtensionContext, state: Partial<ISnipp>, content?: {
text: string | undefined;
type: string | undefined;
}, snippIndex?: number) {
...
context.globalState.update("snipps", updatedSnipps);
若在编辑器区域右键菜单中点击插入Snippet,或在代码片段视图中点击条目,则调用
extension.snippetCraft.insertSnipps
命令,它会调用
InsertSnipp
方法执行插入代码片段操作。
在服务类
SnippService.ts
,插入如下代码
export async function InsertSnipp(context: ExtensionContext, snipp: ISnipp) {
const editor = window.activeTextEditor;
if (editor && SnippDataProvider.isSnipp(snipp)) {
const position = editor?.selection.active;
editor.edit(async (edit) => {
edit.insert(position, snipp.content || '');
});
}
}
代码片段列表
代码片段显示为一个树形结构,根据创建时的文件内容类型,分组显示代码片段条目

创建代码片段和分组条目的接口类型
import * as vscode from "vscode";
export interface ISnipp {
name: string;
content: string;
contentType: string;
created: Date;
lastUsed: Date;
}
export interface IGroup {
name: string;
contentType: string | undefined;
}
在SnippItem中创建获取所有分组类型的get访问器,和获取分组下的条目getChildren方法
export class SnippItem {
constructor(
readonly view: string,
private context: vscode.ExtensionContext
) { }
public get roots(): Thenable<IGroup[]> {
const snipps = this.context?.globalState?.get("snipps", []);
const types = snipps
.map((snipp: ISnipp) => snipp.contentType)
.filter((value, index, self) => self.indexOf(value) === index)
.map((type) => ({ name: type, contentType: undefined }));
return Promise.resolve(types);
}
public getChildren(node: IGroup): Thenable<ISnipp[]> {
const snipps = this.context?.globalState
?.get("snipps", [])
.filter((snipp: ISnipp) => {
return snipp.contentType === node.name;
})
.sort((a: ISnipp, b: ISnipp) => a.name.localeCompare(b.name));
return Promise.resolve(snipps);
}
export class GroupItem { }
VS Code扩展的侧边栏中显示内容需为树形结构,通过实现
TreeDataProvider
为内容提供数据,请参考
官方说明
实现getChildren方法
export class SnippDataProvider
implements
vscode.TreeDataProvider<ISnipp | IGroup>
{
public getChildren(
element?: ISnipp | IGroup
): ISnipp[] | Thenable<ISnipp[]> | IGroup[] | Thenable<IGroup[]> {
return element ? this.model.getChildren(element) : this.model.roots;
}
}
代码片段预览
实现getTreeItem方法,显示预览
点击时调用
extension.snippetCraft.insertEntry
命令实现插入代码片段,command部分在上一章节有介绍。
鼠标移动到代码片段条目上时,显示tooltip预览

代码如下:
public getTreeItem(element: ISnipp | IGroup): vscode.TreeItem {
const t = element.name;
const isSnip = SnippDataProvider.isSnipp(element);
const snippcomm = {
command: "extension.snippetCraft.insertEntry",
title: '',
arguments: [element],
};
let snippetInfo: string = `[${element.contentType}] ${element.name}`;
return {
// @ts-ignore
label: isSnip ? element.name : element.name,
command: isSnip ? snippcomm : undefined,
iconPath:isSnip ? new ThemeIcon("code"):new ThemeIcon("folder"),
tooltip: isSnip
? new vscode.MarkdownString(
// @ts-ignore
`**标题:**${snippetInfo}\n\n**修改时间:**${element.created}\n\n**最近使用:**${element.lastUsed}\n\n**预览:**\n\`\`\`${element.contentType}\n${element.content}\n\`\`\``
)
: undefined,
collapsibleState: !isSnip
? vscode.TreeItemCollapsibleState.Collapsed
: undefined,
};
}
代码片段编辑
编辑器是一个输入框,由于VS Code的输入框不支持多行输入,所以需要使用webview实现多行输入。同时需要提交按钮与取消按钮

首先创建一个多行文本框的WebView,
在服务类
SnippService.ts
,创建一个函数
getWebviewContent
,返回一个HTML字符串,用于创建一个多行输入框。
function getWebviewContent(placeholder: string, initialValue: string): string {
return `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Multiline Input</title>
</head>
<body>
<textarea id="inputBox" rows="10" cols="50" placeholder="${placeholder}">${initialValue}</textarea>
<br>
<button onclick="submitText()">提交</button>
<button onclick="cancel()">取消</button>
<script>
const vscode = acquireVsCodeApi();
function submitText() {
const text = document.getElementById('inputBox').value;
vscode.postMessage({ command: 'submit', text: text });
}
function cancel() {
vscode.postMessage({ command: 'cancel' });
}
</script>
</body>
</html>
`;
}
添加处理函数,当用户点击“提交“时,将文本输入框中的内容返回,同时关闭输入框窗口。
async function showInputBoxWithMultiline(context: ExtensionContext, placeholder: string, initialValue: string): Promise<string | undefined> {
const panel = window.createWebviewPanel(
'multilineInput',
'Multiline Input',
ViewColumn.One,
{
enableScripts: true
}
);
panel.webview.html = getWebviewContent(placeholder, initialValue);
return new Promise<string | undefined>((resolve) => {
panel.webview.onDidReceiveMessage(
message => {
switch (message.command) {
case 'submit':
resolve(message.text);
panel.dispose();
return;
case 'cancel':
resolve(undefined);
panel.dispose();
return;
}
},
undefined,
context.subscriptions
);
});
}
在添加代码片段和编辑代码片段时触发函数
export async function AddSnippFromEditor(context: ExtensionContext, state: Partial<ISnipp>) {
const content = await showInputBoxWithMultiline(context, '请输入Snippet内容', '');
if (content) {
_addOrUpdateSnipp(context, state, { text: content, type: "TEXT" })
}
}
export async function EditSnipp(context: ExtensionContext, state: Partial<ISnipp>, snippIndex: number) {
const content = await showInputBoxWithMultiline(context, '请输入Snippet内容', state.content ?? '');
if (content) {
_addOrUpdateSnipp(context, state, { text: content, type: state.contentType ?? "TEXT" }, snippIndex)
}
}
自定义映射
映射是插入代码片段时,自动替换的变量,他们通过Key-Value形式存储于globalState中。
代码片段中通过设置占位符(如
${AUTHOR}
),在插入代码片段时,将自动替换为全局变量中的值。
当自定义映射值未设置或者不可用时,将直接显示变量占位符
扩展初始化时,插入了三个常用的自定义映射,你可以自由更改或添加自定义映射。
${AUTHOR}
: 作者姓名
${COMPANY}
: 公司名称
${MAIL}
: 邮箱地址
扩展中所有的自定义映射,呈现于“映射表”树视图中。

示例:
代码片段内容
value of 'AUTHOR' is: ${AUTHOR}
value of 'COMPANY' is: ${COMPANY}
value of 'MAIL' is: ${MAIL}
value of 'FOOBAR' (non-exist) is: ${FOOBAR}
插入代码片段后,显示如下:
value of 'AUTHOR' is: 林晓lx
value of 'COMPANY' is: my-company
value of 'MAIL' is: jevonsflash@qq.com
value of 'FOOBAR' (non-exist) is: ${FOOBAR}
首先定义KVItem类:
export class KVItem extends vscode.TreeItem {
constructor(
public readonly key: string,
public readonly value: string | undefined
) {
super(key, vscode.TreeItemCollapsibleState.None);
this.tooltip = `${this.key}: ${this.value}`;
this.description = this.value;
this.contextValue = 'kvItem';
}
}
“映射表”树视图中显示内容需为树形结构,同样需要定义
KVTreeDataProvider
,在此实现刷新、添加、删除、获取子节点等方法。
export class KVTreeDataProvider implements vscode.TreeDataProvider<KVItem> {
private _onDidChangeTreeData: vscode.EventEmitter<KVItem | undefined> = new vscode.EventEmitter<KVItem | undefined>();
readonly onDidChangeTreeData: vscode.Event<KVItem | undefined> = this._onDidChangeTreeData.event;
constructor(private globalState: vscode.Memento) {}
getTreeItem(element: KVItem): vscode.TreeItem {
return element;
}
getChildren(element?: KVItem): Thenable<KVItem[]> {
if (element) {
return Promise.resolve([]);
} else {
const kvObject = this.globalState.get<{ [key: string]: string }>('key-value', {});
const keys = Object.keys(kvObject);
return Promise.resolve(keys.map(key => new KVItem(key, kvObject[key])));
}
}
refresh(): void {
this._onDidChangeTreeData.fire(undefined);
}
addOrUpdateKey(key: string, value: string): void {
const kvObject = this.globalState.get<{ [key: string]: string }>('key-value', {});
kvObject[key] = value;
this.globalState.update('key-value', kvObject);
this.refresh();
}
deleteKey(key: string): void {
const kvObject = this.globalState.get<{ [key: string]: string }>('key-value', {});
delete kvObject[key];
this.globalState.update('key-value', kvObject);
this.refresh();
}
}
默认映射
默认映射是扩展内置的映射功能,可用的映射如下
文件和编辑器相关:
- TM_SELECTED_TEXT: 当前选定的文本或空字符串
- TM_CURRENT_LINE: 当前行的内容
- TM_CURRENT_WORD: 光标下的单词或空字符串的内容
- TM_LINE_INDEX: 基于零索引的行号
- TM_LINE_NUMBER: 基于一个索引的行号
- TM_FILENAME: 当前文档的文件名
- TM_FILENAME_BASE: 当前文档的文件名(不含扩展名)
- TM_DIRECTORY: 当前文档的目录
- TM_FILEPATH: 当前文档的完整文件路径
- RELATIVE_FILEPATH: 当前文档的相对文件路径(相对于打开的工作区或文件夹)
- CLIPBOARD: 剪贴板的内容
- WORKSPACE_NAME: 打开的工作区或文件夹的名称
- WORKSPACE_FOLDER: 打开的工作区或文件夹的路径
- CURSOR_INDEX: 基于零索引的游标编号
- CURSOR_NUMBER: 基于单索引的游标编号
时间相关:
- CURRENT_YEAR: 本年度
- CURRENT_YEAR_SHORT: 当年的最后两位数字
- CURRENT_MONTH: 两位数字的月份(例如“02”)
- CURRENT_MONTH_NAME: 月份的全名(例如“July”)
- CURRENT_MONTH_NAME_SHORT: 月份的简短名称(例如“Jul”)
- CURRENT_DATE: 以两位数字表示的月份中的某一天(例如“08”)
- CURRENT_DAY_NAME: 日期的名称(例如“星期一”)
- CURRENT_DAY_NAME_SHORT: 当天的简短名称(例如“Mon”)
- CURRENT_HOUR24: 小时制格式的当前小时
- CURRENT_MINUTE: 两位数的当前分钟数
- CURRENT_SECOND: 当前秒数为两位数
- CURRENT_SECONDS_UNIX: 自 Unix 纪元以来的秒数
- CURRENT_TIMEZONE_OFFSET当前 UTC 时区偏移量为 +HH:MM 或者 -HH:MM (例如“-07:00”)。
其他:
- RANDOM6: 个随机 Base-10 数字
- RANDOM_HEX6: 个随机 Base-16 数字
- UUID: 第四版UUID
这些项目参考至VS Code 代码片段变量,请查看
VSCode官方文档
与自定义映射一样,当默认映射值未设置或者不可用时,将直接显示变量占位符
实现方法如下:
export async function ReplacePlaceholders(text: string, context: ExtensionContext): Promise<string> {
const editor = window.activeTextEditor;
const clipboard = await env.clipboard.readText();
const workspaceFolders = workspace.workspaceFolders;
const currentDate = new Date();
const kvObject = context.globalState.get<{ [key: string]: string }>('key-value', {});
const replacements: { [key: string]: string } = {
'${TM_SELECTED_TEXT}': editor?.document.getText(editor.selection) || '',
'${TM_CURRENT_LINE}': editor?.document.lineAt(editor.selection.active.line).text || '',
'${TM_CURRENT_WORD}': editor?.document.getText(editor.document.getWordRangeAtPosition(editor.selection.active)) || '',
'${TM_LINE_INDEX}': (editor?.selection.active.line ?? 0).toString(),
'${TM_LINE_NUMBER}': ((editor?.selection.active.line ?? 0) + 1).toString(),
'${TM_FILENAME}': editor ? path.basename(editor.document.fileName) : '',
'${TM_FILENAME_BASE}': editor ? path.basename(editor.document.fileName, path.extname(editor.document.fileName)) : '',
'${TM_DIRECTORY}': editor ? path.dirname(editor.document.fileName) : '',
'${TM_FILEPATH}': editor?.document.fileName || '',
'${RELATIVE_FILEPATH}': editor && workspaceFolders ? path.relative(workspaceFolders[0].uri.fsPath, editor.document.fileName) : '',
'${CLIPBOARD}': clipboard,
'${WORKSPACE_NAME}': workspaceFolders ? workspaceFolders[0].name : '',
'${WORKSPACE_FOLDER}': workspaceFolders ? workspaceFolders[0].uri.fsPath : '',
'${CURSOR_INDEX}': (editor?.selections.indexOf(editor.selection) ?? 0).toString(),
'${CURSOR_NUMBER}': ((editor?.selections.indexOf(editor.selection) ?? 0) + 1).toString(),
'${CURRENT_YEAR}': currentDate.getFullYear().toString(),
'${CURRENT_YEAR_SHORT}': currentDate.getFullYear().toString().slice(-2),
'${CURRENT_MONTH}': (currentDate.getMonth() + 1).toString().padStart(2, '0'),
'${CURRENT_MONTH_NAME}': currentDate.toLocaleString('default', { month: 'long' }),
'${CURRENT_MONTH_NAME_SHORT}': currentDate.toLocaleString('default', { month: 'short' }),
'${CURRENT_DATE}': currentDate.getDate().toString().padStart(2, '0'),
'${CURRENT_DAY_NAME}': currentDate.toLocaleString('default', { weekday: 'long' }),
'${CURRENT_DAY_NAME_SHORT}': currentDate.toLocaleString('default', { weekday: 'short' }),
'${CURRENT_HOUR}': currentDate.getHours().toString().padStart(2, '0'),
'${CURRENT_MINUTE}': currentDate.getMinutes().toString().padStart(2, '0'),
'${CURRENT_SECOND}': currentDate.getSeconds().toString().padStart(2, '0'),
'${CURRENT_SECONDS_UNIX}': Math.floor(currentDate.getTime() / 1000).toString(),
'${CURRENT_TIMEZONE_OFFSET}': formatTimezoneOffset(currentDate.getTimezoneOffset()),
'${RANDOM}': Math.random().toString().slice(2, 8),
'${RANDOM_HEX}': Math.floor(Math.random() * 0xffffff).toString(16).padStart(6, '0'),
'${UUID}': generateUUID()
};
Object.keys(kvObject).forEach(key => {
replacements[`$\{${key}\}`] = kvObject[key];
});
return text.replace(/\$\{(\w+)\}/g, (match, key) => {
return replacements[match] || match;
});
}
自动完成
自动完成是VS Code编辑器提供的一个功能,用于在编辑器中显示自动提示和补全内容。扩展提供了基于代码片段的自动完成功能。

CompletionItemProvider
用于注册自动完成的规则,提供者约定了在指定的文档类型下,当输入的字符匹配时,将出现自动完成上下文菜单。
上下文菜单中列出所有可用的自动完成条目,每个条目由
CompletionItem
定义,点击对应条目后,将处理后的字符串返回,填写到编辑器当前光标处。
languages.registerCompletionItemProvider用于注册自动完成的规则提供者。
在
extension.ts
中注册初始化时,所有的自动完成条目
const providers = contentTypes
.filter((value, index, self) => self.indexOf(value) === index)
.map(type =>
languages.registerCompletionItemProvider(type, {
provideCompletionItems(
document: TextDocument,
position: Position,
token: CancellationToken,
context: CompletionContext
) {
return new Promise<CompletionItem[]>((resolve, reject) => {
var result = snipps
.filter((snipp: ISnipp) => {
return snipp.contentType === type;
})
.map(async (snipp: ISnipp) => {
const replacedContentText = await ReplacePlaceholders(snipp.content, extensionContext);
const commandCompletion = new CompletionItem(snipp.name);
commandCompletion.insertText = replacedContentText || '';
return commandCompletion;
});
Promise.all(result).then(resolve);
});
}
})
);
context.subscriptions.push(...providers);
SnippService.ts
_addOrUpdateSnipp方法中配置修改或新增的自动完成条目
if (content?.type && state.name) {
languages.registerCompletionItemProvider(content.type, {
provideCompletionItems(
document: TextDocument,
position: Position,
token: CancellationToken,
context: CompletionContext
) {
return new Promise<CompletionItem[]>((resolve, reject) => {
ReplacePlaceholders(state.content || '', extensionContext).then(res => {
const replacedContentText = res;
const commandCompletion = new CompletionItem(state.name || '');
commandCompletion.insertText = replacedContentText || '';
resolve([commandCompletion]);
});
});
}
});
}
项目地址
Github:snippet-craft