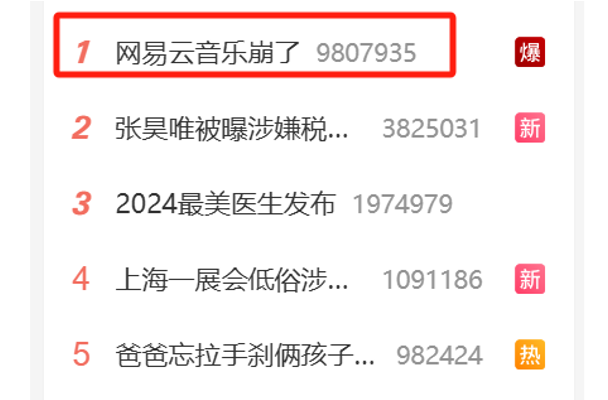
本文基于 Netty 4.1.56.Final 版本进行讨论
在上篇文章
《聊一聊 Netty 数据搬运工 ByteBuf 体系的设计与实现》
中,笔者详细地为大家介绍了 ByteBuf 整个体系的设计,其中笔者觉得 Netty 对于引用计数的设计非常精彩,因此将这部分设计内容专门独立出来。
Netty 为 ByteBuf 引入了引用计数的机制,在 ByteBuf 的整个设计体系中,所有的 ByteBuf 都会继承一个抽象类 AbstractReferenceCountedByteBuf , 它是对接口 ReferenceCounted 的实现。

public interface ReferenceCounted {
int refCnt();
ReferenceCounted retain();
ReferenceCounted retain(int increment);
boolean release();
boolean release(int decrement);
}
每个 ByteBuf 的内部都维护了一个叫做 refCnt 的引用计数,我们可以通过
refCnt()
方法来获取 ByteBuf 当前的引用计数 refCnt。当 ByteBuf 在其他上下文中被引用的时候,我们需要通过
retain()
方法将 ByteBuf 的引用计数加 1。另外我们也可以通过
retain(int increment)
方法来指定 refCnt 增加的大小(increment)。
有对 ByteBuf 的引用那么就有对 ByteBuf 的释放,每当我们使用完 ByteBuf 的时候就需要手动调用
release()
方法将 ByteBuf 的引用计数减 1 。当引用计数 refCnt 变成 0 的时候,Netty 就会通过
deallocate
方法来释放 ByteBuf 所引用的内存资源。这时
release()
方法会返回 true , 如果 refCnt 还不为 0 ,那么就返回 false 。同样我们也可以通过
release(int decrement)
方法来指定 refCnt 减少多少(decrement)。
1. 为什么要引入引用计数
”在其他上下文中引用 ByteBuf “ 是什么意思呢 ? 比如我们在线程 1 中创建了一个 ByteBuf,然后将这个 ByteBuf 丢给线程 2 进行处理,线程 2 又可能丢给线程 3, 而每个线程都有自己的上下文处理逻辑,比如对 ByteBuf 的处理,释放等操作。这样就使得 ByteBuf 在事实上形成了在多个线程上下文中被共享的情况。
面对这种情况我们就很难在一个单独的线程上下文中判断一个 ByteBuf 该不该被释放,比如线程 1 准备释放 ByteBuf 了,但是它可能正在被其他线程使用。所以这也是 Netty 为 ByteBuf 引入引用计数的重要原因,每当引用一次 ByteBuf 的时候就需要通过
retain()
方法将引用计数加 1,
release()
释放的时候将引用计数减 1 ,当引用计数为 0 了,说明已经没有其他上下文引用 ByteBuf 了,这时 Netty 就可以释放它了。
另外相比于 JDK DirectByteBuffer 需要依赖 GC 机制来释放其背后引用的 Native Memory , Netty 更倾向于手动及时释放 DirectByteBuf 。因为 JDK DirectByteBuffer 的释放需要等到 GC 发生,由于 DirectByteBuffer 的对象实例所占的 JVM 堆内存太小了,所以一时很难触发 GC , 这就导致被引用的 Native Memory 的释放有了一定的延迟,严重的情况会越积越多,导致 OOM 。而且也会导致进程中对 DirectByteBuffer 的申请操作有非常大的延迟。
而 Netty 为了避免这些情况的出现,选择在每次使用完毕之后手动释放 Native Memory ,但是不依赖 JVM 的话,总会有内存泄露的情况,比如在使用完了 ByteBuf 却忘记调用
release()
方法来释放。
所以为了检测内存泄露的发生,这也是 Netty 为 ByteBuf 引入了引用计数的另一个原因,当 ByteBuf 不再被引用的时候,也就是没有任何强引用或者软引用的时候,如果此时发生 GC , 那么这个 ByteBuf 实例(位于 JVM 堆中)就需要被回收了,这时 Netty 就会检查这个 ByteBuf 的引用计数是否为 0 , 如果不为 0 ,说明我们忘记调用
release()
释放了,近而判断出这个 ByteBuf 发生了内存泄露。
在探测到内存泄露发生之后,后续 Netty 就会通过
reportLeak()
将内存泄露的相关信息以
error
的日志级别输出到日志中。
看到这里,大家可能不禁要问,不就是引入了一个小小的引用计数嘛,这有何难 ? 值得这里大书特书吗 ? 不就是在创建 ByteBuf 的时候将引用计数 refCnt 初始化为 1 , 每次在其他上下文引用的时候将 refCnt 加 1, 每次释放的时候再将 refCnt 减 1 吗 ?减到 0 的时候就释放 Native Memory ,太简单了吧~~
事实上 Netty 对引用计数的设计非常讲究,绝非如此简单,甚至有些复杂,其背后隐藏着大大的性能考究以及对复杂并发问题的全面考虑,在性能与线程安全问题之间的反复权衡。
2. 引用计数的最初设计
所以为了理清关于引用计数的整个设计脉络,我们需要将版本回退到最初的起点 —— 4.1.16.Final 版本,来看一下原始的设计。
public abstract class AbstractReferenceCountedByteBuf extends AbstractByteBuf {
// 原子更新 refCnt 的 Updater
private static final AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> refCntUpdater =
AtomicIntegerFieldUpdater.newUpdater(AbstractReferenceCountedByteBuf.class, "refCnt");
// 引用计数,初始化为 1
private volatile int refCnt;
protected AbstractReferenceCountedByteBuf(int maxCapacity) {
super(maxCapacity);
// 引用计数初始化为 1
refCntUpdater.set(this, 1);
}
// 引用计数增加 increment
private ByteBuf retain0(int increment) {
for (;;) {
int refCnt = this.refCnt;
// 每次 retain 的时候对引用计数加 1
final int nextCnt = refCnt + increment;
// Ensure we not resurrect (which means the refCnt was 0) and also that we encountered an overflow.
if (nextCnt <= increment) {
// 如果 refCnt 已经为 0 或者发生溢出,则抛异常
throw new IllegalReferenceCountException(refCnt, increment);
}
// CAS 更新 refCnt
if (refCntUpdater.compareAndSet(this, refCnt, nextCnt)) {
break;
}
}
return this;
}
// 引用计数减少 decrement
private boolean release0(int decrement) {
for (;;) {
int refCnt = this.refCnt;
if (refCnt < decrement) {
// 引用的次数必须和释放的次数相等对应
throw new IllegalReferenceCountException(refCnt, -decrement);
}
// 每次 release 引用计数减 1
// CAS 更新 refCnt
if (refCntUpdater.compareAndSet(this, refCnt, refCnt - decrement)) {
if (refCnt == decrement) {
// 如果引用计数为 0 ,则释放 Native Memory,并返回 true
deallocate();
return true;
}
// 引用计数不为 0 ,返回 false
return false;
}
}
}
}
在 4.1.16.Final 之前的版本设计中,确实和我们当初想象的一样,非常简单,创建 ByteBuf 的时候将 refCnt 初始化为 1。 每次引用 retain 的时候将引用计数加 1 ,每次释放 release 的时候将引用计数减 1,在一个 for 循环中通过 CAS 替换。当引用计数为 0 的时候,通过
deallocate()
释放 Native Memory。
3. 引入指令级别上的优化
4.1.16.Final 的设计简洁清晰,在我们看来完全没有任何问题,但 Netty 对性能的考究完全没有因此止步,由于在 x86 架构下 XADD 指令的性能要高于 CMPXCHG 指令, compareAndSet 方法底层是通过 CMPXCHG 指令实现的,而 getAndAdd 方法底层是 XADD 指令。
所以在对性能极致的追求下,Netty 在 4.1.17.Final 版本中用 getAndAdd 方法来替换 compareAndSet 方法。
public abstract class AbstractReferenceCountedByteBuf extends AbstractByteBuf {
private volatile int refCnt;
protected AbstractReferenceCountedByteBuf(int maxCapacity) {
super(maxCapacity);
// 引用计数在初始的时候还是为 1
refCntUpdater.set(this, 1);
}
private ByteBuf retain0(final int increment) {
// 相比于 compareAndSet 的实现,这里将 for 循环去掉
// 并且每次是先对 refCnt 增加计数 increment
int oldRef = refCntUpdater.getAndAdd(this, increment);
// 增加完 refCnt 计数之后才去判断异常情况
if (oldRef <= 0 || oldRef + increment < oldRef) {
// Ensure we don't resurrect (which means the refCnt was 0) and also that we encountered an overflow.
// 如果原来的 refCnt 已经为 0 或者 refCnt 溢出,则对 refCnt 进行回退,并抛出异常
refCntUpdater.getAndAdd(this, -increment);
throw new IllegalReferenceCountException(oldRef, increment);
}
return this;
}
private boolean release0(int decrement) {
// 先对 refCnt 减少计数 decrement
int oldRef = refCntUpdater.getAndAdd(this, -decrement);
// 如果 refCnt 已经为 0 则进行 Native Memory 的释放
if (oldRef == decrement) {
deallocate();
return true;
} else if (oldRef < decrement || oldRef - decrement > oldRef) {
// 如果释放次数大于 retain 次数 或者 refCnt 出现下溢
// 则对 refCnt 进行回退,并抛出异常
refCntUpdater.getAndAdd(this, decrement);
throw new IllegalReferenceCountException(oldRef, decrement);
}
return false;
}
}
在 4.1.16.Final 版本的实现中,Netty 是在一个 for 循环中,先对 retain 和 release 的异常情况进行校验,之后再通过 CAS 更新 refCnt。否则直接抛出 IllegalReferenceCountException。采用的是一种悲观更新引用计数的策略。
而在 4.1.17.Final 版本的实现中 , Netty 去掉了 for 循环,正好和 compareAndSet 的实现相反,而是先通过 getAndAdd 更新 refCnt,更新之后再来判断相关的异常情况,如果发现有异常,则进行回退,并抛出 IllegalReferenceCountException。采用的是一种乐观更新引用计数的策略。
比如在 retain 增加引用计数的时候,先对 refCnt 增加计数 increment,然后判断原来的引用计数 oldRef 是否已经为 0 或者 refCnt 是否发生溢出,如果是,则需要对 refCnt 的值进行回退,并抛异常。
在 release 减少引用计数的时候,先对 refCnt 减少计数 decrement,然后判断 release 的次数是否大于 retain 的次数防止 over-release ,以及 refCnt 是否发生下溢,如果是,则对 refCnt 的值进行回退,并抛异常。
4. 并发安全问题的引入
在 4.1.17.Final 版本的设计中,我们对引用计数的 retain 以及 release 操作都要比 4.1.16.Final 版本的性能要高,虽然现在性能是高了,但是同时引入了新的并发问题。
让我们先假设一个这样的场景,现在有一个 ByteBuf,它当前的 refCnt = 1 ,线程 1 对这个 ByteBuf 执行
release()
操作。

在 4.1.17.Final 的实现中,Netty 会首先通过 getAndAdd 将 refCnt 更新为 0 ,然后接着调用
deallocate()
方法释放 Native Memory ,很简单也很清晰是吧,让我们再加点并发复杂度上去。
现在我们在上图步骤一与步骤二之间插入一个线程 2 , 线程 2 对这个 ByteBuf 并发执行
retain()
方法。

在 4.1.17.Final 的实现中,线程 2 首先通过 getAndAdd 将 refCnt 从 0 更新为 1,紧接着线程 2 就会发现 refCnt 原来的值 oldRef 是等于 0 的,也就是说线程 2 在调用
retain()
的时候,ByteBuf 的引用计数已经为 0 了,并且线程 1 已经开始准备释放 Native Memory 了。
所以线程 2 需要再次调用 getAndAdd 方法将 refCnt 的值进行回退,从 1 再次回退到 0 ,最后抛出 IllegalReferenceCountException。这样的结果显然是正确的,也是符合语义的。毕竟不能对一个引用计数为 0 的 ByteBuf 调用
retain()
。
现在看来一切风平浪静,都是按照我们的设想有条不紊的进行,我们不妨再加点并发复杂度上去。在上图步骤 1.1 与步骤 1.2 之间在插入一个线程 3 , 线程 3 对这个 ByteBuf 再次并发执行
retain()
方法。

由于引用计数的更新(步骤 1.1)与引用计数的回退(步骤 1.2)这两个操作并不是一个原子操作,如果在这两个操作之间不巧插入了一个线程 3 ,线程 3 在并发执行
retain()
方法的时候,首先会通过 getAndAdd 将引用计数 refCnt 从 1 增加到 2 。
注意,此时线程 2 还没来得及回退 refCnt , 所以线程 3 此时看到的 refCnt 是 1 而不是 0
。
由于此时线程 3 看到的 oldRef 是 1 ,所以线程 3 成功调用
retain()
方法将 ByteBuf 的引用计数增加到了 2 ,并且不会回退也不会抛出异常。在线程 3 看来此时的 ByteBuf 完完全全是一个正常可以被使用的 ByteBuf。
紧接着线程 1 开始执行步骤 2 ——
deallocate()
方法释放 Native Memory,此后线程 3 在访问这个 ByteBuf 的时候就有问题了,因为 Native Memory 已经被线程1 释放了。
5. 在性能与并发安全之间的权衡
接下来 Netty 就需要在性能与并发安全之间进行权衡了,现在有两个选择,第一个选择是直接回滚到 4.1.16.Final 版本,放弃 XADD 指令带来的性能提升,之前的设计中采用的 CMPXCHG 指令虽然性能相对差一些,但是不会出现上述的并发安全问题。
因为 Netty 是在一个 for 循环中采用悲观的策略来更新引用计数,先是判断异常情况,然后在通过 CAS 来更新 refCnt。即使多个线程看到了 refCnt 的中间状态也没关系,因为接下来进行的 CAS 也会跟着失败。
比如上边例子中的线程 1 对 ByteBuf 进行 release 的时候,在线程 1 执行 CAS 将 refCnt 替换为 0 之前的这个间隙中,refCnt 是 1 ,如果在这个间隙中,线程 2 并发执行 retain 方法,此时线程 2 看到的 refCnt 确实为 1 ,它是一个中间状态,线程 2 执行 CAS 将 refCnt 替换为 2。
此时线程 1 执行 CAS 就会失败,但会在下一轮 for 循环中将 refCnt 替换为 1,这是完全符合引用计数语义的。
另外一种情况是线程 1 已经执行完 CAS 将 refCnt 替换为 0 ,这时候线程 2 去 retain ,由于 4.1.16.Final 版本中的设计是先检查异常后 CAS 替换,所以线程 2 首先会在 retain 方法中检查到 ByteBuf 的 refCnt 已经为 0 ,直接抛出 IllegalReferenceCountException,并不会执行 CAS 。这同样符合引用计数的语义,毕竟不能对一个引用计数已经为 0 的 ByteBuf 执行任何访问操作。
第二个选择是既要保留 XADD 指令带来的性能提升,也要解决 4.1.17.Final 版本中引入的并发安全问题。毫无疑问,Netty 最终选择的是这种方案。
在介绍 Netty 的精彩设计之前,我想我们还是应该在回顾下这个并发安全问题出现的根本原因是什么 ?
在 4.1.17.Final 版本的设计中,Netty 首先是通过 getAndAdd 方法先对 refCnt 的值进行更新,如果出现异常情况,在进行回滚。而更新,回滚的这两个操作并不是原子的,之间的中间状态会被其他线程看到。
比如,线程 2 看到了线程 1 的中间状态(refCnt = 0),于是将引用计数加到 1
, 在线程 2 进行回滚之前,这期间的中间状态(refCnt = 1,oldRef = 0)又被线程 3 看到了,于是线程 3 将引用计数增加到了 2 (refCnt = 2,oldRef = 1)。 此时线程 3 觉得这是一种正常的状态,但在线程 1 看来 refCnt 的值已经是 0 了,后续线程 1 就会释放 Native Memory ,这就出问题了。
问题的根本原因其实是这里的 refCnt 不同的值均代表不同的语义,比如对于线程 1 来说,通过 release 将 refCnt 减到了 0 ,这里的语义是 ByteBuf 已经不在被引用了,可以释放 Native Memory 。
随后线程 2 通过 retain 将 refCnt 加到了 1 ,这就把 ByteBuf 语义改变了,表示该 ByteBuf 在线程 2 中被引用了一次。最后线程 3 又通过 retain 将 refCnt 加到了 2 ,再一次改变了 ByteBuf 的语义。
只要用到 XADD 指令来实现引用计数的更新,那么就不可避免的出现上述并发更新 refCnt 的情况,关键是 refCnt 的值每一次被其他线程并发修改之后,ByteBuf 的语义就变了。这才是 4.1.17.Final 版本中的关键问题所在。
如果 Netty 想在同时享受 XADD 指令带来的性能提升之外,又要解决上述提到的并发安全问题,就要重新对引用计数进行设计。首先我们的要求是继续采用 XADD 指令来实现引用计数的更新,但这就会带来多线程并发修改所引起的 ByteBuf 语义改变。
既然多线程并发修改无法避免,那么我们能不能重新设计一下引用计数,让 ByteBuf 语义无论多线程怎么修改,它的语义始终保持不变。也就是说只要线程 1 将 refCnt 减到了 0 ,那么无论线程 2 和线程 3 怎么并发修改 refCnt,怎么增加 refCnt 的值,refCnt 等于 0 的这个语义始终保持不变呢 ?
6. 奇偶设计的引入
这里 Netty 有一个极奇巧妙精彩的设计,引用计数的设计不再是逻辑意义上的
0 , 1 , 2 , 3 .....
,而是分为了两大类,要么是偶数,要么是奇数。
偶数代表的语义是 ByteBuf 的 refCnt 不为 0 ,也就是说只要一个 ByteBuf 还在被引用,那么它的 refCnt 就是一个偶数,具体被引用多少次,可以通过
refCnt >>> 1
来获取。
奇数代表的语义是 ByteBuf 的 refCnt 等于 0 ,只要一个 ByteBuf 已经没有任何地方引用它了,那么它的 refCnt 就是一个奇数,其背后引用的 Native Memory 随后就会被释放。
ByteBuf 在初始化的时候,refCnt 不在是 1 而是被初始化为 2 (偶数),每次 retain 的时候不在是对 refCnt 加 1 而是加 2 (偶数步长),每次 release 的时候不再是对 refCnt 减 1 而是减 2 (同样是偶数步长)。这样一来,只要一个 ByteBuf 的引用计数为偶数,那么多线程无论怎么并发调用 retain 方法,引用计数还是一个偶数,语义仍然保持不变。
public final int initialValue() {
return 2;
}
当一个 ByteBuf 被 release 到没有任何引用计数的时候,Netty 不在将 refCnt 设置为 0 而是设置为 1 (奇数),对于一个值为奇数的 refCnt,无论多线程怎么并发调用 retain 方法和 release 方法,引用计数还是一个奇数,ByteBuf 引用计数为 0 的这层语义一直会保持不变。
我们还是以上图中所展示的并发安全问题为例,在新的引用计数设计方案中,首先线程 1 对 ByteBuf 执行 release 方法,Netty 会将 refCnt 设置为 1 (奇数)。
线程 2 并发调用 retain 方法,通过 getAndAdd 将 refCnt 从 1 加到了 3 ,refCnt 仍然是一个奇数,按照奇数所表示的语义 —— ByteBuf 引用计数已经是 0 了,那么线程 2 就会在 retain 方法中抛出 IllegalReferenceCountException。
线程 3 并发调用 retain 方法,通过 getAndAdd 将 refCnt 从 3 加到了 5,看到了没 ,在新方案的设计中,无论多线程怎么并发执行 retain 方法,refCnt 的值一直都只会是一个奇数,随后线程 3 在 retain 方法中抛出 IllegalReferenceCountException。这完全符合引用计数的并发语义。
这个新的引用计数设计方案是在 4.1.32.Final 版本引入进来的,仅仅通过一个奇偶设计,就非常巧妙的解决了 4.1.17.Final 版本中存在的并发安全问题。现在新方案的核心设计要素我们已经清楚了,那么接下来笔者将以 4.1.56.Final 版本来为大家继续介绍下新方案的实现细节。
Netty 中的 ByteBuf 全部继承于 AbstractReferenceCountedByteBuf,在这个类中实现了所有对 ByteBuf 引用计数的操作,对于 ReferenceCounted 接口的实现就在这里。
public abstract class AbstractReferenceCountedByteBuf extends AbstractByteBuf {
// 获取 refCnt 字段在 ByteBuf 对象内存中的偏移
// 后续通过 Unsafe 对 refCnt 进行操作
private static final long REFCNT_FIELD_OFFSET =
ReferenceCountUpdater.getUnsafeOffset(AbstractReferenceCountedByteBuf.class, "refCnt");
// 获取 refCnt 字段 的 AtomicFieldUpdater
// 后续通过 AtomicFieldUpdater 来操作 refCnt 字段
private static final AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> AIF_UPDATER =
AtomicIntegerFieldUpdater.newUpdater(AbstractReferenceCountedByteBuf.class, "refCnt");
// 创建 ReferenceCountUpdater,对于引用计数的所有操作最终都会代理到这个类中
private static final ReferenceCountUpdater<AbstractReferenceCountedByteBuf> updater =
new ReferenceCountUpdater<AbstractReferenceCountedByteBuf>() {
@Override
protected AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> updater() {
// 通过 AtomicIntegerFieldUpdater 操作 refCnt 字段
return AIF_UPDATER;
}
@Override
protected long unsafeOffset() {
// 通过 Unsafe 操作 refCnt 字段
return REFCNT_FIELD_OFFSET;
}
};
// ByteBuf 中的引用计数,初始为 2 (偶数)
private volatile int refCnt = updater.initialValue();
}
其中定义了一个 refCnt 字段用于记录 ByteBuf 被引用的次数,由于采用了奇偶设计,在创建 ByteBuf 的时候,Netty 会将 refCnt 初始化为 2 (偶数),它的逻辑语义是该 ByteBuf 被引用一次。后续对 ByteBuf 执行 retain 就会对 refCnt 进行加 2 ,执行 release 就会对 refCnt 进行减 2 ,对于引用计数的单次操作都是以 2 为步长进行。
由于在 Netty 中除了 AbstractReferenceCountedByteBuf 这个专门用于实现 ByteBuf 的引用计数功能之外,还有一个更加通用的引用计数抽象类 AbstractReferenceCounted,它用于实现所有系统资源类的引用计数功能(ByteBuf 只是其中的一种内存资源)。
由于都是对引用计数的实现,所以在之前的版本中,这两个类中包含了很多重复的引用计数相关操作逻辑,所以 Netty 在 4.1.35.Final 版本中专门引入了一个 ReferenceCountUpdater 类,将所有引用计数的相关实现聚合在这里。
ReferenceCountUpdater 对于引用计数 refCnt 的操作有两种方式,一种是通过 AtomicFieldUpdater 来对 refCnt 进行操作,我们可以通过
updater()
获取到 refCnt 字段对应的 AtomicFieldUpdater。
另一种则是通过 Unsafe 来对 refCnt 进行操作,我们可以通过
unsafeOffset()
来获取到 refCnt 字段在 ByteBuf 实例对象内存中的偏移。
按理来说,我们采用一种方式就可以对 refCnt 进行访问或者更新了,那为什么 Netty 提供了两种方式呢 ?会显得有点多余吗 ?这个点大家可以先思考下为什么 ,后续在我们剖析到源码细节的时候笔者在为大家解答。
好了,下面我们正式开始介绍新版引用计数设计方案的具体实现细节,第一个问题,在新的设计方案中,我们如何获取 ByteBuf 的逻辑引用计数 ?
public abstract class ReferenceCountUpdater<T extends ReferenceCounted> {
public final int initialValue() {
// ByteBuf 引用计数初始化为 2
return 2;
}
public final int refCnt(T instance) {
// 通过 updater 获取 refCnt
// 根据 refCnt 在 realRefCnt 中获取真实的引用计数
return realRefCnt(updater().get(instance));
}
// 获取 ByteBuf 的逻辑引用计数
private static int realRefCnt(int rawCnt) {
// 奇偶判断
return rawCnt != 2 && rawCnt != 4 && (rawCnt & 1) != 0 ? 0 : rawCnt >>> 1;
}
}
由于采用了奇偶引用计数的设计,所以我们在获取逻辑引用计数的时候需要判断当前 rawCnt(refCnt)是奇数还是偶数,它们分别代表了不同的语义。
realRefCnt 函数其实就是简单的一个奇偶判断逻辑,但在它的实现中却体现出了 Netty 对性能的极致追求。比如,我们判断一个数是奇数还是偶数其实很简单,直接通过
rawCnt & 1
就可以判断,如果返回 0 表示 rawCnt 是一个偶数,如果返回 1 表示 rawCnt 是一个奇数。
但是我们看到 Netty 在奇偶判断条件的前面又加上了
rawCnt != 2 && rawCnt != 4
语句,这是干嘛的呢 ?
其实 Netty 这里是为了尽量用性能更高的
==
运算来代替
&
运算,但又不可能用
==
运算来枚举出所有的偶数值(也没这必要),所以只用
==
运算来判断在实际场景中经常出现的引用计数,一般经常出现的引用计数值为 2 或者 4 , 也就是说 ByteBuf 在大部分场景下只会被引用 1 次或者 2 次,对于这种高频出现的场景,Netty 用
==
运算来针对性优化,低频出现的场景就回退到
&
运算。
大部分性能优化的套路都是相同的,我们通常不能一上来就奢求一个大而全的针对全局的优化方案,这是不可能的,也是十分低效的。往往最有效的,可以立竿见影的优化方案都是针对局部热点进行专门优化。
对引用计数的设置也是一样,都需要考虑奇偶的转换,我们在
setRefCnt
方法中指定的参数 refCnt 表示逻辑上的引用计数 ——
0, 1 , 2 , 3 ....
,但要设置到 ByteBuf 时,就需要对逻辑引用计数在乘以 2 ,让它始终是一个偶数。
public final void setRefCnt(T instance, int refCnt) {
updater().set(instance, refCnt > 0 ? refCnt << 1 : 1); // overflow OK here
}
有了这些基础之后,我们下面就来看一下在新版本的 retain 方法设计中,Netty 是如何解决 4.1.17.Final 版本存在的并发安全问题。首先 Netty 对引用计数的奇偶设计对于用户来说是透明的。引用计数对于用户来说仍然是普通的自然数 ——
0, 1 , 2 , 3 ....
。
所以每当用户调用 retain 方法试图增加 ByteBuf 的引用计数时,通常是指定逻辑增加步长 —— increment(用户视角),而在具体的实现角度,Netty 会增加两倍的 increment (rawIncrement)到 refCnt 字段中。
public final T retain(T instance) {
// 引用计数逻辑上是加 1 ,但实际上是加 2 (实现角度)
return retain0(instance, 1, 2);
}
public final T retain(T instance, int increment) {
// all changes to the raw count are 2x the "real" change - overflow is OK
// rawIncrement 始终是逻辑计数 increment 的两倍
int rawIncrement = checkPositive(increment, "increment") << 1;
// 将 rawIncrement 设置到 ByteBuf 的 refCnt 字段中
return retain0(instance, increment, rawIncrement);
}
// rawIncrement = increment << 1
// increment 表示引用计数的逻辑增长步长
// rawIncrement 表示引用计数的实际增长步长
private T retain0(T instance, final int increment, final int rawIncrement) {
// 先通过 XADD 指令将 refCnt 的值加起来
int oldRef = updater().getAndAdd(instance, rawIncrement);
// 如果 oldRef 是一个奇数,也就是 ByteBuf 已经没有引用了,抛出异常
if (oldRef != 2 && oldRef != 4 && (oldRef & 1) != 0) {
// 如果 oldRef 已经是一个奇数了,无论多线程在这里怎么并发 retain ,都是一个奇数,这里都会抛出异常
throw new IllegalReferenceCountException(0, increment);
}
// don't pass 0!
// refCnt 不可能为 0 ,只能是 1
if ((oldRef <= 0 && oldRef + rawIncrement >= 0)
|| (oldRef >= 0 && oldRef + rawIncrement < oldRef)) {
// 如果 refCnt 字段已经溢出,则进行回退,并抛异常
updater().getAndAdd(instance, -rawIncrement);
throw new IllegalReferenceCountException(realRefCnt(oldRef), increment);
}
return instance;
}
首先新版本的 retain0 方法仍然保留了 4.1.17.Final 版本引入的 XADD 指令带来的性能优势,大致的处理逻辑也是类似的,一上来先通过 getAndAdd 方法将 refCnt 增加 rawIncrement,对于
retain(T instance)
来说这里直接加 2 。
然后判断原来的引用计数 oldRef 是否是一个奇数,如果是一个奇数,那么就表示 ByteBuf 已经没有任何引用了,逻辑引用计数早已经为 0 了,那么就抛出 IllegalReferenceCountException。
在引用计数为奇数的情况下,无论多线程怎么对 refCnt 并发加 2 ,refCnt 始终是一个奇数,最终都会抛出异常。解决并发安全问题的要点就在这里,一定要保证 retain 方法的并发执行不能改变原来的语义。
最后会判断一下 refCnt 字段是否发生溢出,如果溢出,则进行回退,并抛出异常。下面我们仍然以之前的并发场景为例,用一个具体的例子,来回味一下奇偶设计的精妙之处。

现在线程 1 对一个 refCnt 为 2 的 ByteBuf 执行 release 方法,这时 ByteBuf 的逻辑引用计数就为 0 了,对于一个没有任何引用的 ByteBuf 来说,新版的设计中它的 refCnt 只能是一个奇数,不能为 0 ,所以这里 Netty 会将 refCnt 设置为 1 。然后在步骤 2 中调用 deallocate 方法释放 Native Memory。
线程 2 在步骤 1 和步骤 2 之间插入进来对 ByteBuf 并发执行 retain 方法,这时线程 2 看到的 refCnt 是 1,然后通过 getAndAdd 将 refCnt 加到了 3 ,仍然是一个奇数,随后抛出 IllegalReferenceCountException 异常。
线程 3 在步骤 1.1 和步骤 1.2 之间插入进来再次对 ByteBuf 并发执行 retain 方法,这时线程 3 看到的 refCnt 是 3,然后通过 getAndAdd 将 refCnt 加到了 5 ,还是一个奇数,随后抛出 IllegalReferenceCountException 异常。
这样一来就保证了引用计数的并发语义 —— 只要一个 ByteBuf 没有任何引用的时候(refCnt = 1),其他线程无论怎么并发执行 retain 方法都会得到一个异常。
但是引用计数并发语义的保证不能单单只靠 retain 方法,它还需要与 release 方法相互配合协作才可以,所以为了并发语义的保证 , release 方法的设计就不能使用性能更高的 XADD 指令,而是要回退到 CMPXCHG 指令来实现。
为什么这么说呢 ?因为新版引用计数的设计采用的是奇偶实现,refCnt 为偶数表示 ByteBuf 还有引用,refCnt 为奇数表示 ByteBuf 已经没有任何引用了,可以安全释放 Native Memory 。对于一个 refCnt 已经为奇数的 ByteBuf 来说,无论多线程怎么并发执行 retain 方法,得到的 refCnt 仍然是一个奇数,最终都会抛出 IllegalReferenceCountException,这就是引用计数的并发语义 。
为了保证这一点,就需要在每次调用 retain ,release 方法的时候,以偶数步长来更新 refCnt,比如每一次调用 retain 方法就对 refCnt 加 2 ,每一次调用 release 方法就对 refCnt 减 2 。
但总有一个时刻,refCnt 会被减到 0 的对吧,在新版的奇偶设计中,refCnt 是不允许为 0 的,因为一旦 refCnt 被减到了 0 ,多线程并发执行 retain 之后,就会将 refCnt 再次加成了偶数,这又会出现并发问题。
而每一次调用 release 方法是对 refCnt 减 2 ,如果我们采用 XADD 指令实现 release 的话,回想一下 4.1.17.Final 版本中的设计,它首先进来是通过 getAndAdd 方法对 refCnt 减 2 ,这样一来,refCnt 就变成 0 了,就有并发安全问题了。所以我们需要通过 CMPXCHG 指令将 refCnt 更新为 1。
这里有的同学可能要问了,那可不可以先进行一下 if 判断,如果 refCnt 减 2 之后变为 0 了,我们在通过 getAndAdd 方法将 refCnt 更新为 1 (减一个奇数),这样一来不也可以利用上 XADD 指令的性能优势吗 ?
答案是不行的,因为 if 判断与 getAndAdd 更新这两个操作之间仍然不是原子的,多线程可以在这个间隙仍然有并发执行 retain 方法的可能,如下图所示:

在线程 1 执行 if 判断和 getAndAdd 更新这两个操作之间,线程 2 看到的 refCnt 其实 2 ,然后线程 2 会将 refCnt 加到 4 ,线程 3 紧接着会将 refCnt 增加到 6 ,在线程 2 和线程 3 看来这个 ByteBuf 完全是正常的,但是线程 1 马上就会释放 Native Memory 了。
而且采用这种设计的话,一会通过 getAndAdd 对 refCnt 减一个奇数,一会通过 getAndAdd 对 refCnt 加一个偶数,这样就把原本的奇偶设计搞乱掉了。
所以我们的设计目标是一定要保证在 ByteBuf 没有任何引用计数的时候,release 方法需要原子性的将 refCnt 更新为 1 。 因此必须采用 CMPXCHG 指令来实现而不能使用 XADD 指令。
再者说, CMPXCHG 指令是可以原子性的判断当前是否有并发情况的,如果有并发情况出现,CAS 就会失败,我们可以继续重试。但 XADD 指令却无法原子性的判断是否有并发情况,因为它每次都是先更新,后判断并发,这就不是原子的了。这一点,在下面的源码实现中会体现的特别明显
。
7. 尽量避免内存屏障的开销
public final boolean release(T instance) {
// 第一次尝试采用 unSafe nonVolatile 的方式读取 refCnf 的值
int rawCnt = nonVolatileRawCnt(instance);
// 如果逻辑引用计数被减到 0 了,那么就通过 tryFinalRelease0 使用 CAS 将 refCnf 更新为 1
// CAS 失败的话,则通过 retryRelease0 进行重试
// 如果逻辑引用计数不为 0 ,则通过 nonFinalRelease0 将 refCnf 减 2
return rawCnt == 2 ? tryFinalRelease0(instance, 2) || retryRelease0(instance, 1)
: nonFinalRelease0(instance, 1, rawCnt, toLiveRealRefCnt(rawCnt, 1));
}
这里有一个小的细节再次体现出 Netty 对于性能的极致追求,refCnt 字段在 ByteBuf 中被 Netty 申明为一个 volatile 字段。
private volatile int refCnt = updater.initialValue();
我们对 refCnt 的普通读写都是要走内存屏障的,但 Netty 在 release 方法中首次读取 refCnt 的值是采用 nonVolatile 的方式,不走内存屏障,直接读取 cache line,避免了屏障开销。
private int nonVolatileRawCnt(T instance) {
// 获取 REFCNT_FIELD_OFFSET
final long offset = unsafeOffset();
// 通过 UnSafe 的方式来访问 refCnt , 避免内存屏障的开销
return offset != -1 ? PlatformDependent.getInt(instance, offset) : updater().get(instance);
}
那有的同学可能要问了,如果读取 refCnt 的时候不走内存屏障的话,读取到的 refCnt 不就可能是一个错误的值吗 ?
事实上确实是这样的,但 Netty 不 care , 读到一个错误的值也无所谓,因为这里的引用计数采用了奇偶设计,我们在第一次读取引用计数的时候并不需要读取到一个精确的值,既然这样我们可以直接通过 UnSafe 来读取,还能剩下一笔内存屏障的开销。
那为什么不需要一个精确的值呢 ?因为如果原来的 refCnt 是一个奇数,那无论多线程怎么并发 retain ,最终得到的还是一个奇数,我们这里只需要知道 refCnt 是一个奇数就可以直接抛 IllegalReferenceCountException 了。具体读到的是一个 3 还是一个 5 其实都无所谓。
那如果原来的 refCnt 是一个偶数呢 ?其实也无所谓,我们可能读到一个正确的值也可能读到一个错误的值,如果恰好读到一个正确的值,那更好。如果读取到一个错误的值,也无所谓,因为我们后面是用 CAS 进行更新,这样的话 CAS 就会更新失败,我们只需要在一下轮 for 循环中更新正确就可以了。
如果读取到的 refCnt 恰好是 2 ,那就意味着本次 release 之后,ByteBuf 的逻辑引用计数就为 0 了,Netty 会通过 CAS 将 refCnt 更新为 1 。
private boolean tryFinalRelease0(T instance, int expectRawCnt) {
return updater().compareAndSet(instance, expectRawCnt, 1); // any odd number will work
}
如果 CAS 更新失败,则表示此时有多线程可能并发对 ByteBuf 执行 retain 方法,逻辑引用计数此时可能就不为 0 了,针对这种并发情况,Netty 会在 retryRelease0 方法中进行重试,将 refCnt 减 2 。
private boolean retryRelease0(T instance, int decrement) {
for (;;) {
// 采用 Volatile 的方式读取 refCnt
int rawCnt = updater().get(instance),
// 获取逻辑引用计数,如果 refCnt 已经变为奇数,则抛出异常
realCnt = toLiveRealRefCnt(rawCnt, decrement);
// 如果执行完本次 release , 逻辑引用计数为 0
if (decrement == realCnt) {
// CAS 将 refCnt 更新为 1
if (tryFinalRelease0(instance, rawCnt)) {
return true;
}
} else if (decrement < realCnt) {
// 原来的逻辑引用计数 realCnt 大于 1(decrement)
// 则通过 CAS 将 refCnt 减 2
if (updater().compareAndSet(instance, rawCnt, rawCnt - (decrement << 1))) {
return false;
}
} else {
// refCnt 字段如果发生溢出,则抛出异常
throw new IllegalReferenceCountException(realCnt, -decrement);
}
// CAS 失败之后调用 yield
// 减少无畏的竞争,否则所有线程在高并发情况下都在这里 CAS 失败
Thread.yield();
}
}
从 retryRelease0 方法的实现中我们可以看出,CAS 是可以原子性的探测到是否有并发情况出现的,如果有并发情况,这里的所有 CAS 都会失败,随后会在下一轮 for 循环中将正确的值更新到 refCnt 中。这一点 ,XADD 指令是做不到的。
如果在进入 release 方法后,第一次读取的 refCnt 不是 2 ,那么就不能走上面的 tryFinalRelease0 逻辑,而是在 nonFinalRelease0 中通过 CAS 将 refCnt 的值减 2 。
private boolean nonFinalRelease0(T instance, int decrement, int rawCnt, int realCnt) {
if (decrement < realCnt
&& updater().compareAndSet(instance, rawCnt, rawCnt - (decrement << 1))) {
// ByteBuf 的 rawCnt 减少 2 * decrement
return false;
}
// CAS 失败则一直重试,如果引用计数已经为 0 ,那么抛出异常,不能再次 release
return retryRelease0(instance, decrement);
}
总结
到这里,Netty 对引用计数的精彩设计,笔者就为大家完整的剖析完了,一共有四处非常精彩的优化设计,我们总结如下:
使用性能更优的 XADD 指令来替换 CMPXCHG 指令。
引用计数采用了奇偶设计,保证了并发语义。
采用性能更优的
==
运算来替换
&
运算。
能不走内存屏障就尽量不走内存屏障。