方法的三种调用形式
在《
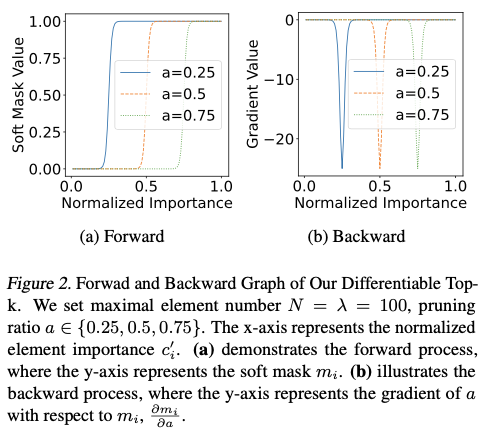
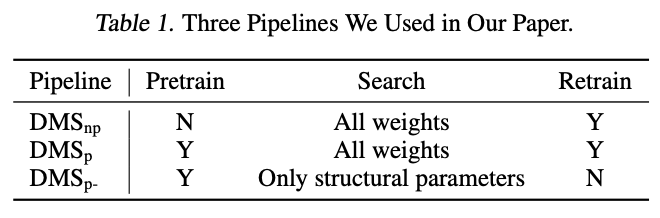
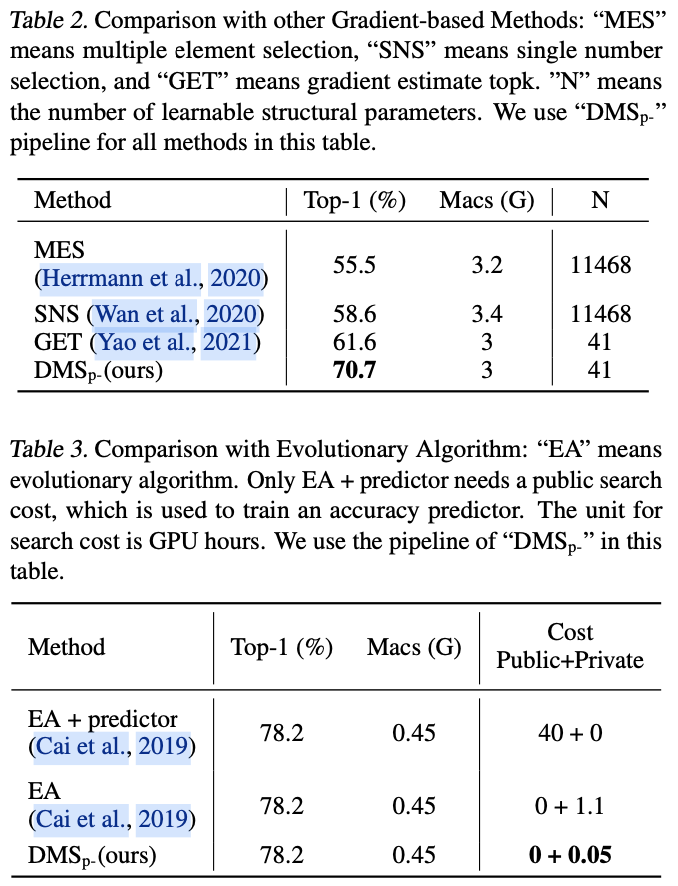
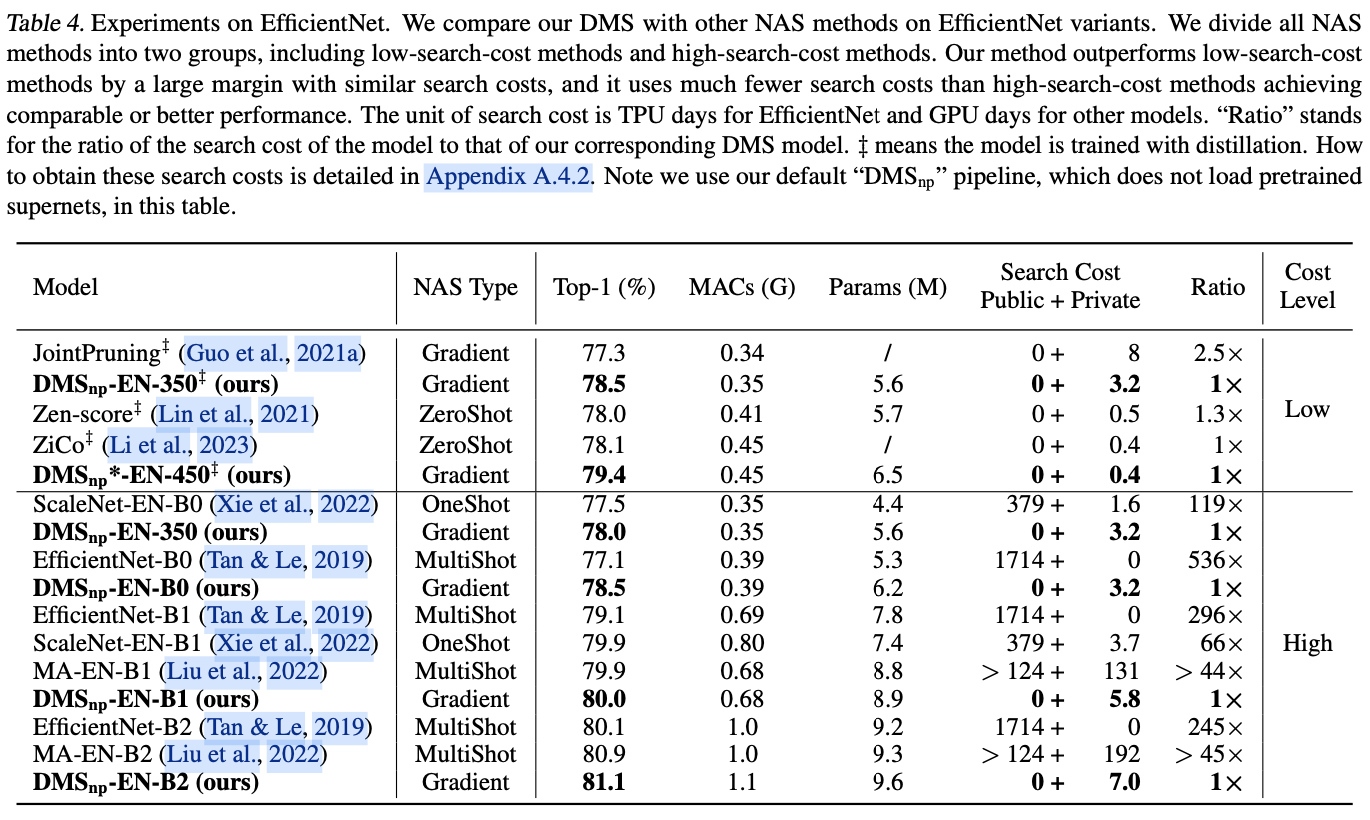
可以调用Null的实例方法吗?
》一文中,我谈到.NET方法的三种调用形式,现在我们就来着重聊聊这个话题。具体来说,这里所谓的三种方法调用形式对应着三种IL指令:Call、CallVirt和Calli。
一、三个方法调用指令
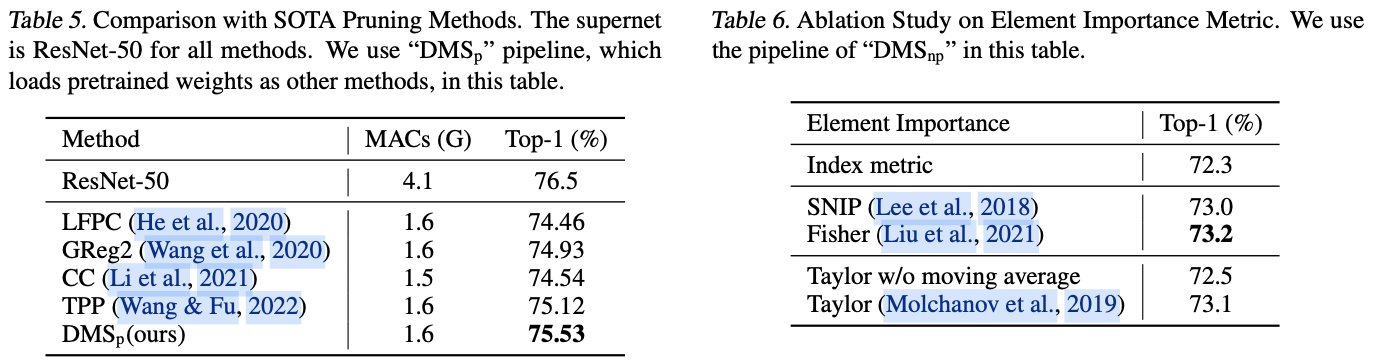
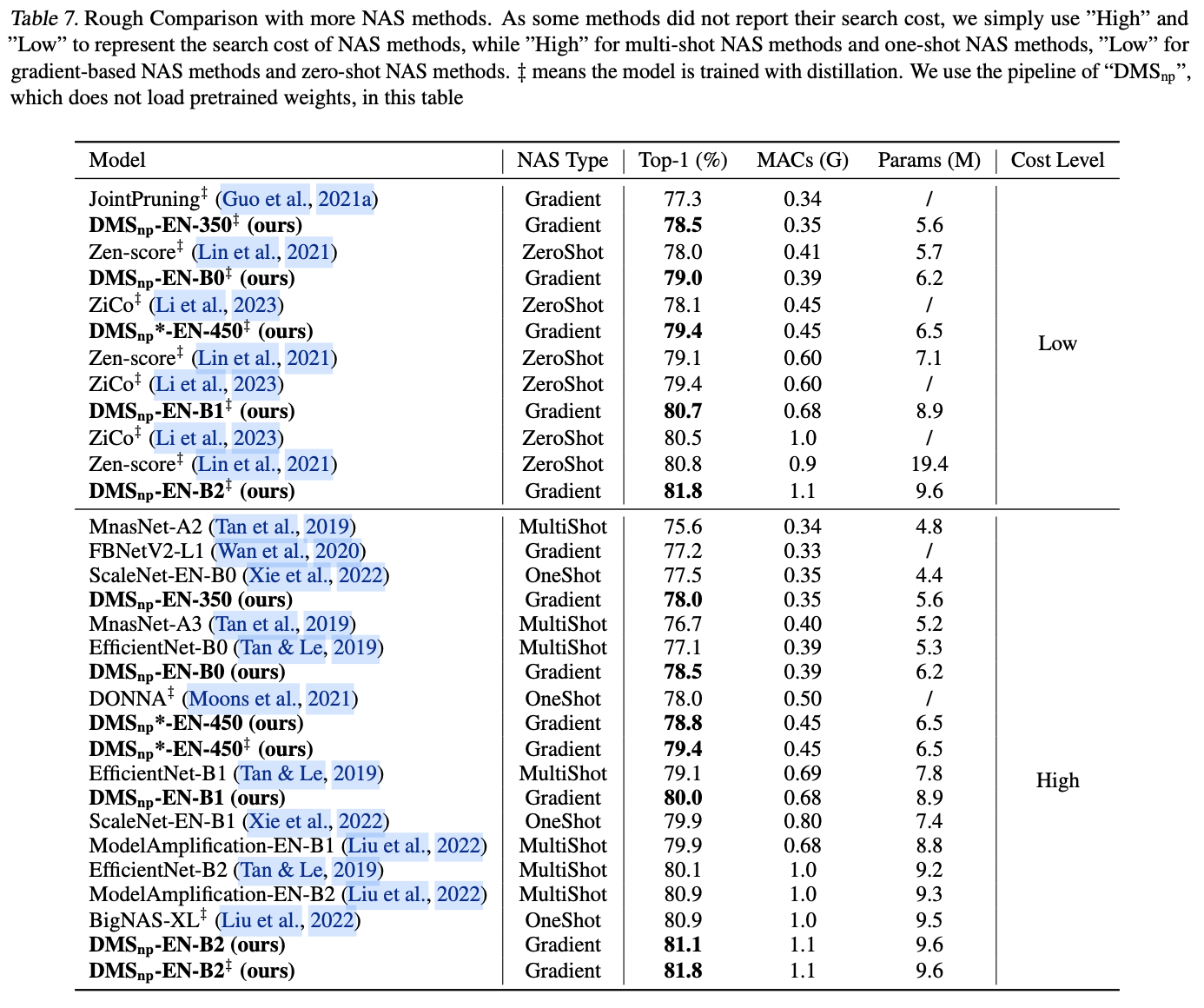
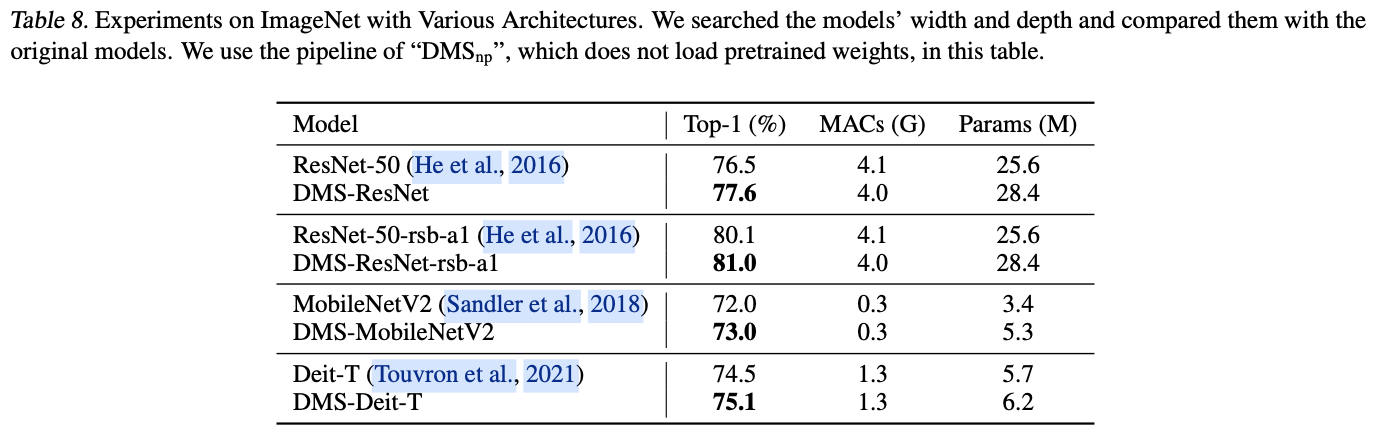
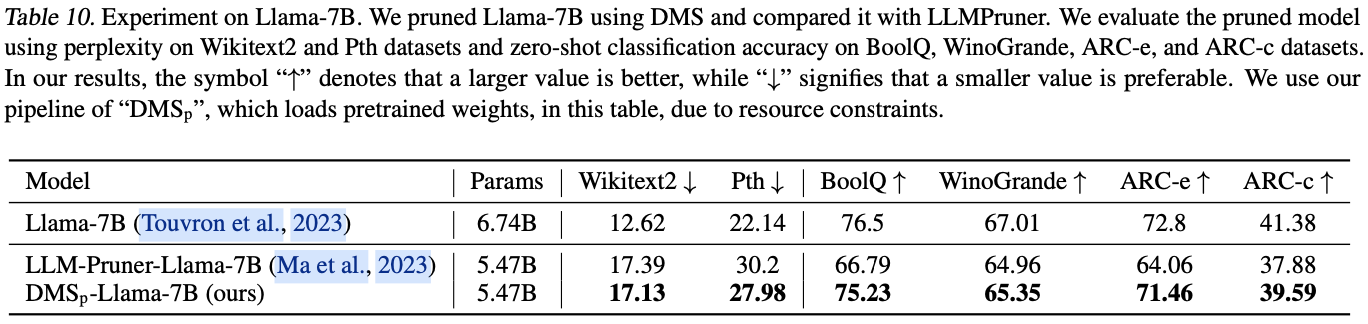
二、三种方法调用形式
三、虚方法的分发(virtual dispatch)
四、性能差异
一、三个方法调用指令
虽然C#的方法具有静态方法和实例方法之分,但是在IL层面,它们之间并没有什么不同,就是单纯的“函数”而已,而且这个函数的第一个参数的类型永远是方法所在的类型。所以在IL层面,方法总是“静态”的,调用实例方法的本质就是将目标实例作为第一个参数,对于静态方法,第一个参数永远是Null/Default(值类型)。我在《
实例方法和静态方法有区别吗?
》中曾经着重谈到过这个问题。
Call和CallVirt指令执行方法的流程只有两步:
将所有参数压入栈中 + 执行方法
。它们之间的不同之处在于:Call指令编译时就已经确定了执行的方法,而CallVirt则是在运行时根据作为第一个参数的实例类型决定最终执行的方法。Calli指令则有所不同,我们执行该指令时需要指定目标方法的指针,整个流程包括三步:
将所有参数压入栈中 + 将目标方法指针压入栈中+执行方法
。
二、三种方法调用形式
接下来我们使用动态方法的形式演示上述三种方法调用指令的使用。具体来说,我们采用三种方式调用定义在Calculator中用来进行加法运算的Add方法,为此我们利用CreateInvoker方法根据指定的指令生成一个对应的Func<Calculator,
int
,
int
,
int
>委托。在CreateInvoker方法中,我们创建一个与Func<Calculator,
int
,
int
,
int
>委托匹配的动态方法。在IL Emit过程中,我们先将三个参数(Calculator对象和Add方法的参数a和b)压入栈中。如果指定的是Call和CallVirt指令,我们直接执行它们就可以了。如果指定的是Calli指令,我们得执行
Ldftn
指令将Add方法的指针压入栈中(方法指针通过指定的MethodInfo对象提供),然后再执行Calli指令。
var calculator = new Calculator(); var invoker = CreateInvoker(OpCodes.Call); Console.WriteLine($"1 + 2 = {invoker(calculator, 1, 2)} [Call]"); invoker = CreateInvoker(OpCodes.Callvirt); Console.WriteLine($"1 + 2 = {invoker(calculator, 1, 2)} [Callvirt]"); invoker = CreateInvoker(OpCodes.Calli); Console.WriteLine($"1 + 2 = {invoker(calculator, 1, 2)} [Calli]"); static Func<Calculator, int, int, int> CreateInvoker(OpCode opcode) { var method = typeof(Calculator).GetMethod("Add")!; var dynamicMethod = new DynamicMethod("Add", typeof(int), [typeof(Calculator), typeof(int), typeof(int)]); var il = dynamicMethod.GetILGenerator(); il.Emit(OpCodes.Ldarg_0); il.Emit(OpCodes.Ldarg_1); il.Emit(OpCodes.Ldarg_2); if (opcode == OpCodes.Call) { il.Emit(OpCodes.Call, method); } else if (opcode == OpCodes.Callvirt) { il.Emit(OpCodes.Callvirt, method); } else if (opcode == OpCodes.Calli) { il.Emit(OpCodes.Ldftn, method); il.EmitCalli(OpCodes.Calli, CallingConvention.ThisCall, typeof(int), [typeof(Calculator), typeof(int), typeof(int)]); } il.Emit(OpCodes.Ret); return (Func<Calculator, int, int, int>)dynamicMethod.CreateDelegate(typeof(Func<Calculator, int, int, int>)); } public class Calculator { public virtual int Add(int a, int b) => a + b; }
演示程序利用指定的三种方法指令创建了对应的Func<Calculator,
int
,
int
,
int
>,然后指定相同的参数(Calculator实例、整数1、2)执行它们,我们最终会在控制台上得到如下的输出结果。

三、虚方法的分发(virtual dispatch)
虽然Calculator的Add是个虚方法,由于Call指令执行的目标方法在编译时就确定,Calli则是我们以指针的形式指定了执行的方法,不论我们指定的目标对象具体是何类型,执行的永远是定义在Calculator类型的那个Add方法。面向对象“
多态
”的能力只能通过CallVirt指令来实现。
var calculator = new FakeCalculator(); var invoker = CreateInvoker(OpCodes.Call); Console.WriteLine($"1 + 2 = {invoker(calculator, 1, 2)} [Call]"); invoker = CreateInvoker(OpCodes.Callvirt); Console.WriteLine($"1 + 2 = {invoker(calculator, 1, 2)} [Callvirt]"); invoker = CreateInvoker(OpCodes.Calli); Console.WriteLine($"1 + 2 = {invoker(calculator, 1, 2)} [Calli]"); public class FakeCalculator : Calculator { public override int Add(int a, int b) => a - b; }
以如上的程序为例,我们定义了Calculator的派生类FakeCalculator,在重写的Add方法中执行“减法运算”。我们将这个FakeCalculator对象作为参数调用三个委托,会得到如下所示的输出结果,可以看出CallVirt指令才能得到我们希望的结果。
四、性能差异
既然Call、CallVirt和Calli都是能帮助我们完成方法的执行,我们自然会进一步关系它们的性能差异了,为此我们来做一个简单的性能测试。
BenchmarkRunner.Run<Test>(); public class Test { private static readonly Func<Calculator, int, int, int> _call = CreateInvoker(OpCodes.Call); private static readonly Func<Calculator, int, int, int> _callvirt = CreateInvoker(OpCodes.Callvirt); private static readonly Func<Calculator, int, int, int> _calli = CreateInvoker(OpCodes.Calli); private static readonly Calculator _calculator = new FakeCalculator(); [Benchmark] public int Call() => _call(_calculator, 1, 2); [Benchmark] public int Callvirt() => _callvirt(_calculator, 1, 2); [Benchmark] public int Calli() => _calli(_calculator, 1, 2); }
如上所示的测试程序很简单,我们调用CreateInvoker方法将针对三种指令的Func<Calculator,
int
,
int
,
int
>委托和目标对象FakeCalculator创建出来,并在三个Benchmark方法中执行它们。从如下的测试结果可以看出,Call由于不需要进行”虚方法分发(Virtual Dispatch)”性能会比Callvirt执行好一些,但总体来说差别不大,但是
Calli指令调用方法的性能会差很多
。