初探 Rust 语言与环境搭建
1. Rust 简介
Rust 的历史
- 起源
:Rust 语言最初由 Mozilla 研究员 Graydon Hoare 于 2006 年开始设计,并于 2009 年首次公开。 - 开发
:Rust 是 Mozilla 实验室的一个项目,目的是创建一种能够保证内存安全同时又不牺牲性能的系统编程语言。 - 发布
:Rust 1.0 稳定版于 2015 年发布,标志着语言的成熟和稳定。
设计目标
- 内存安全
:Rust 的设计核心是提供内存安全,通过所有权(ownership)、借用(borrowing)和生命周期(lifetimes)的概念来避免空指针解引用和数据竞争等问题。 - 并发编程
:Rust 旨在简化并发编程,通过所有权和类型系统来帮助开发者编写无数据竞争的多线程代码。 - 性能
:Rust 旨在提供与 C/C++ 相当的性能,没有运行时垃圾收集器,编译为机器码,适合系统编程和性能敏感型应用。 - 表达性
:Rust 提供了丰富的类型系统和模式匹配,使得代码既安全又具有表现力。
Rust 与 C/C++ 的比较
- 内存安全
:与 C/C++ 相比,Rust 通过所有权和借用规则在编译时避免了内存泄漏和野指针问题,而 C/C++ 需要开发者手动管理内存。 - 并发性
:Rust 的所有权模型天然支持无数据竞争的并发,而 C++11 引入了线程库来支持并发编程,但依然需要开发者小心处理数据同步问题。 - 语法
:Rust 的语法类似于 C++,但更简洁,且提供了模式匹配等特性,使得代码更易于编写和理解。 - 错误处理
:Rust 使用
Result
类型来显式处理可能的错误,而 C++ 使用异常处理。 - 编译器友好
:Rust 的编译器提供详尽的错误信息和有用的提示,帮助开发者快速定位和解决问题。
Rust 的应用领域
- 系统编程
:由于其性能和内存安全特性,Rust 适合用于操作系统、文件系统、设备驱动等底层系统开发。 - WebAssembly
:Rust 可以编译为 WebAssembly,用于开发 Web 应用的高性能前端逻辑。 - 嵌入式编程
:Rust 的资源管理特性使其适合用于嵌入式设备编程。 - 工具开发
:Rust 用于开发命令行工具,如
cargo
(Rust 的包管理器和构建工具)。
Rust 的生态系统
- Cargo
:Rust 的包管理器和构建工具,用于依赖管理和项目构建。 - crates.io
:Rust 的包注册表,类似于 npm 或 Maven,用于共享和重用代码。 - 社区
:Rust 拥有一个活跃的社区,提供大量的库和框架,以及持续的技术支持。
学习资源
- The Rust Programming Language
(又称 "The Book"):Rust 官方教程,适合初学者。 - Rust by Example
:通过实例学习 Rust,覆盖了 Rust 的大部分特性。 - Rustlings
:一个练习项目,通过小练习帮助学习 Rust。
Rust 作为一种现代系统编程语言,以其内存安全、并发性和性能优势,正在获得越来越多的关注和应用。随着 Rust 生态的不断发展,我们可以预见它将在未来的软件开发中扮演更重要的角色。
2. 环境搭建
搭建 Rust 编程环境主要包括安装 Rust 编译器和一些辅助工具。以下步骤将引导你完成环境搭建:
步骤 1: 安装 Rust 编译器
Rust 编译器可以通过 Rustup 安装,Rustup 是 Rust 的官方安装程序和版本管理器。
- 访问 Rustup 官网
:打开
rustup.rs
。 - 遵循安装指南
:根据你的操作系统(Windows、macOS、Linux),网页会提供相应的安装指令。 - 自动安装脚本
:对于大多数用户,只需复制网页上提供的命令并在终端或命令提示符中运行即可。例如,在 Linux 或 macOS 上,你可以使用以下命令:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
在终端执行以上命令后的效果:
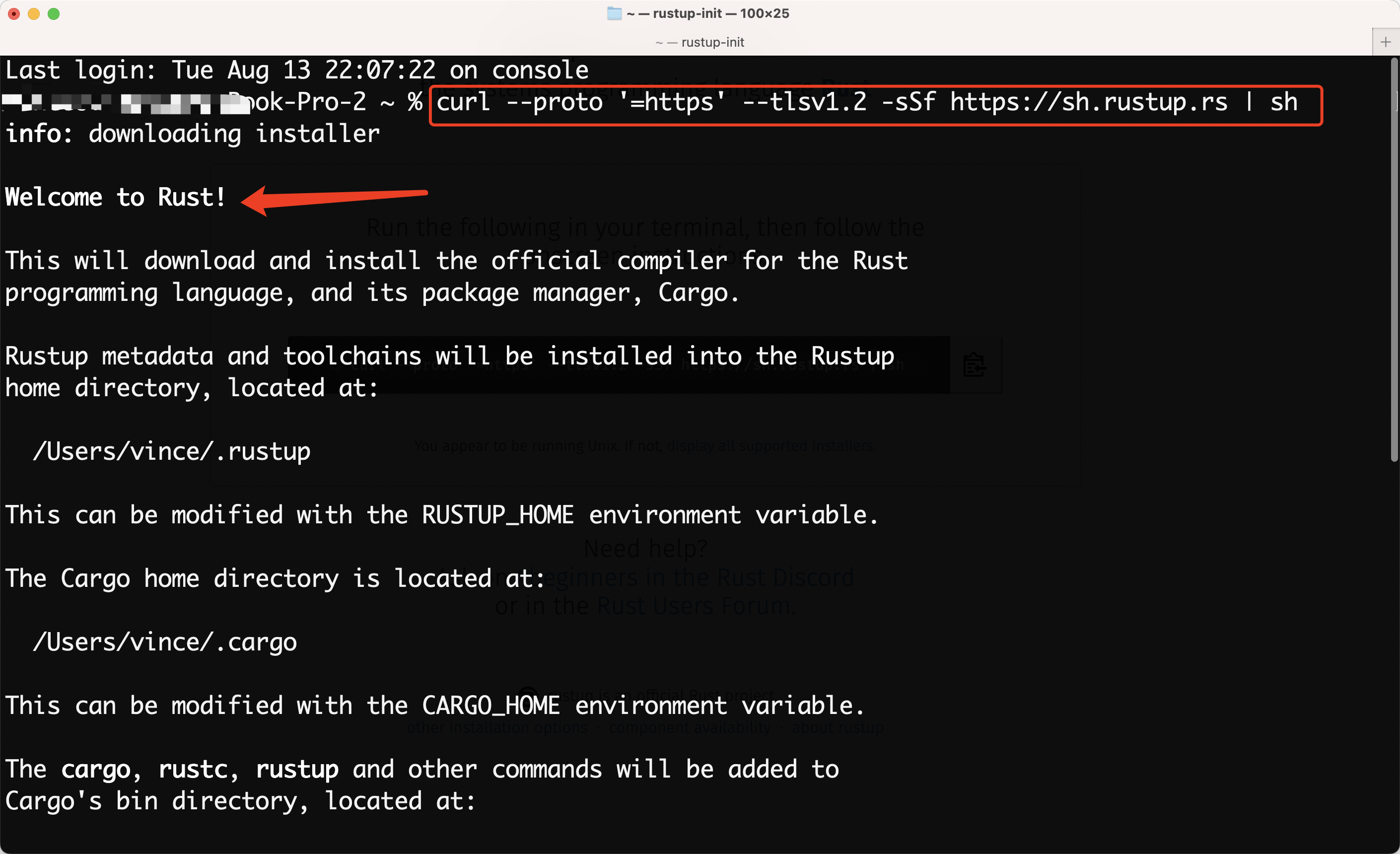
到这个界面,回车继续安装和配置环境变量。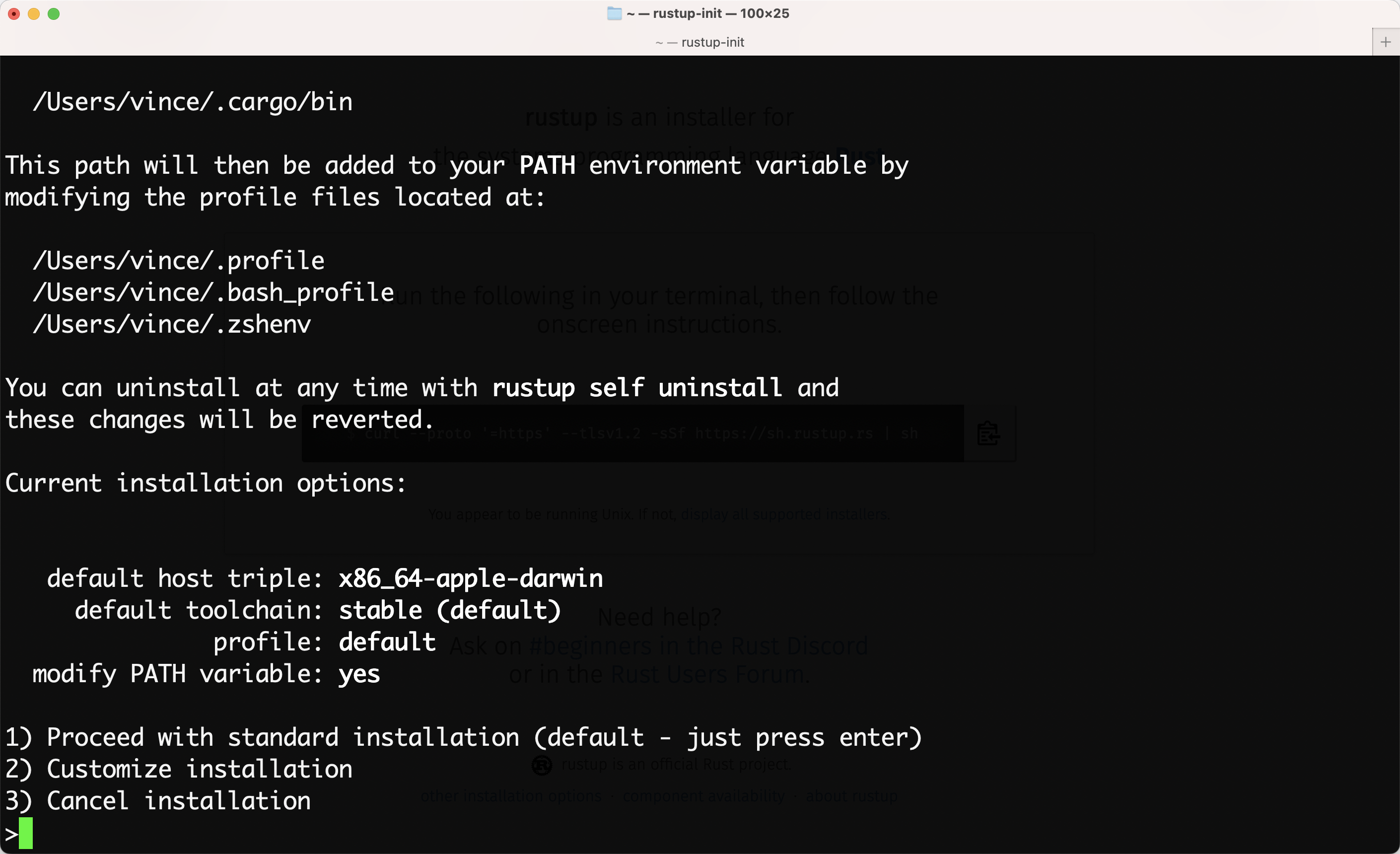
看到这个界面,安装就完成了。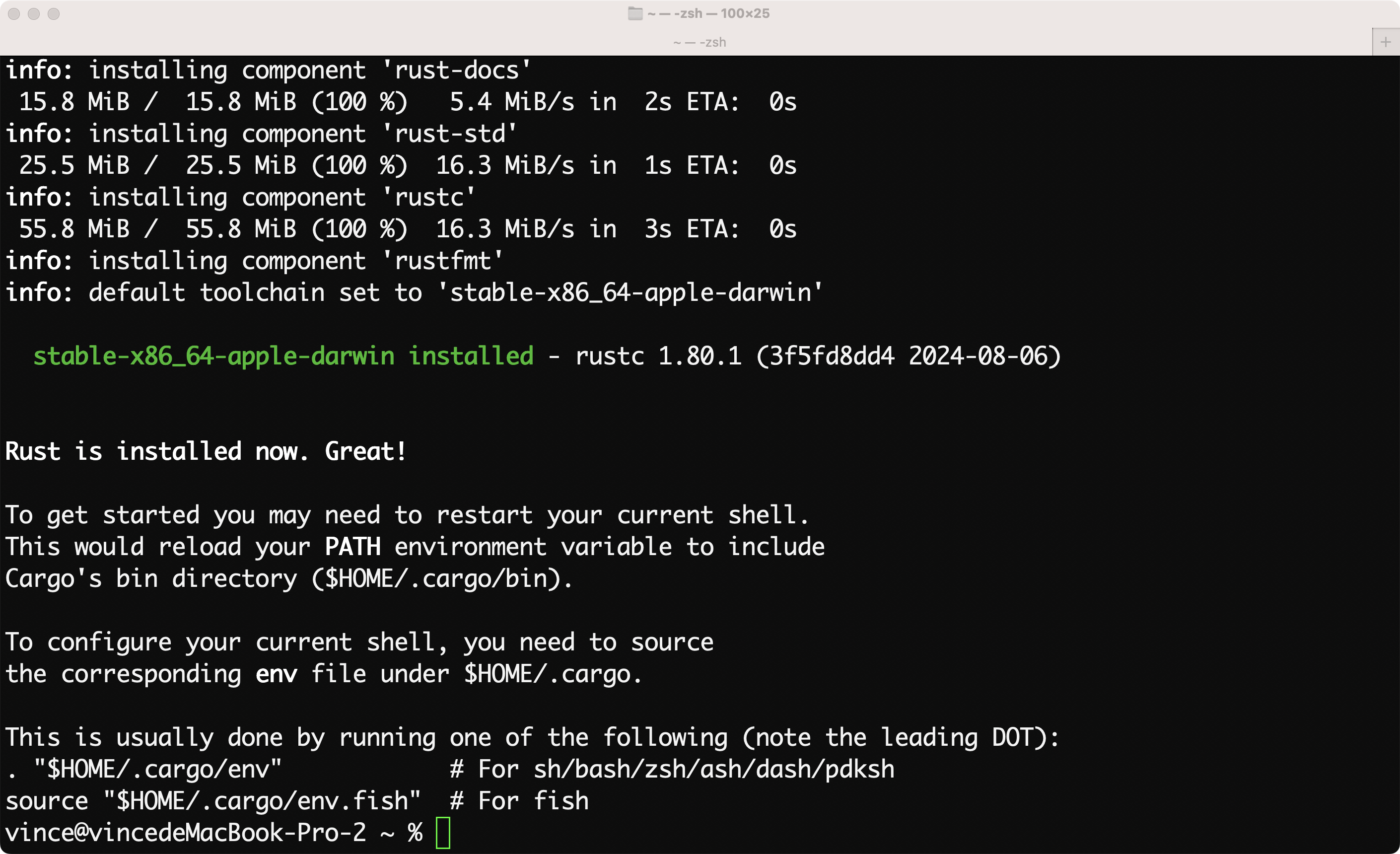
stable-x86_64-apple-darwin installed - rustc 1.80.1
表示安装成功,版本号为1.80.1。
对于 Windows 用户,下载并运行提供的
rustup-init.exe
安装程序。
步骤 2: 检查安装
安装完成后,你可以通过在终端运行以下命令来检查 Rust 编译器是否正确安装(V哥提醒:一定要重启一下终端):
rustc --version
这将显示安装的 Rust 编译器版本。
步骤 3: 安装 Cargo
Cargo 不仅是 Rust 的包管理器,还是构建工具。它与 Rust 编译器一起安装,所以你不需要单独安装。
- 检查 Cargo 安装
:运行以下命令来检查 Cargo 是否已安装:
cargo --version
步骤 4: 更新 Rust
Rust 和 Cargo 会定期更新。使用以下命令来更新到最新版本:
rustup update
步骤 5: 配置环境变量(如果需要)
在某些系统中,可能需要将 Rust 编译器和 Cargo 添加到 PATH 环境变量中。通常,Rustup 会自动处理这一步,但如果没有,你可以手动添加。
- 找到 Rustup 安装目录
:Rustup 通常安装在以下路径:
- Windows:
C:\Users\你的用户名\.cargo\bin - macOS 和 Linux:
~/.cargo/bin
- Windows:
- 添加到 PATH
:根据你的操作系统,将上述路径添加到 PATH 环境变量中。
步骤 6: 创建第一个项目
使用 Cargo 创建一个新项目来测试你的环境。
- 打开终端或命令提示符
。 - 运行以下命令
:
cargo new myproject
这将在当前目录下创建一个名为
myproject
的新文件夹,包含一个新的 Rust 项目模板。
步骤 7: 构建和运行项目
- 进入项目目录
:
cd myproject
- 构建项目
:
cargo build
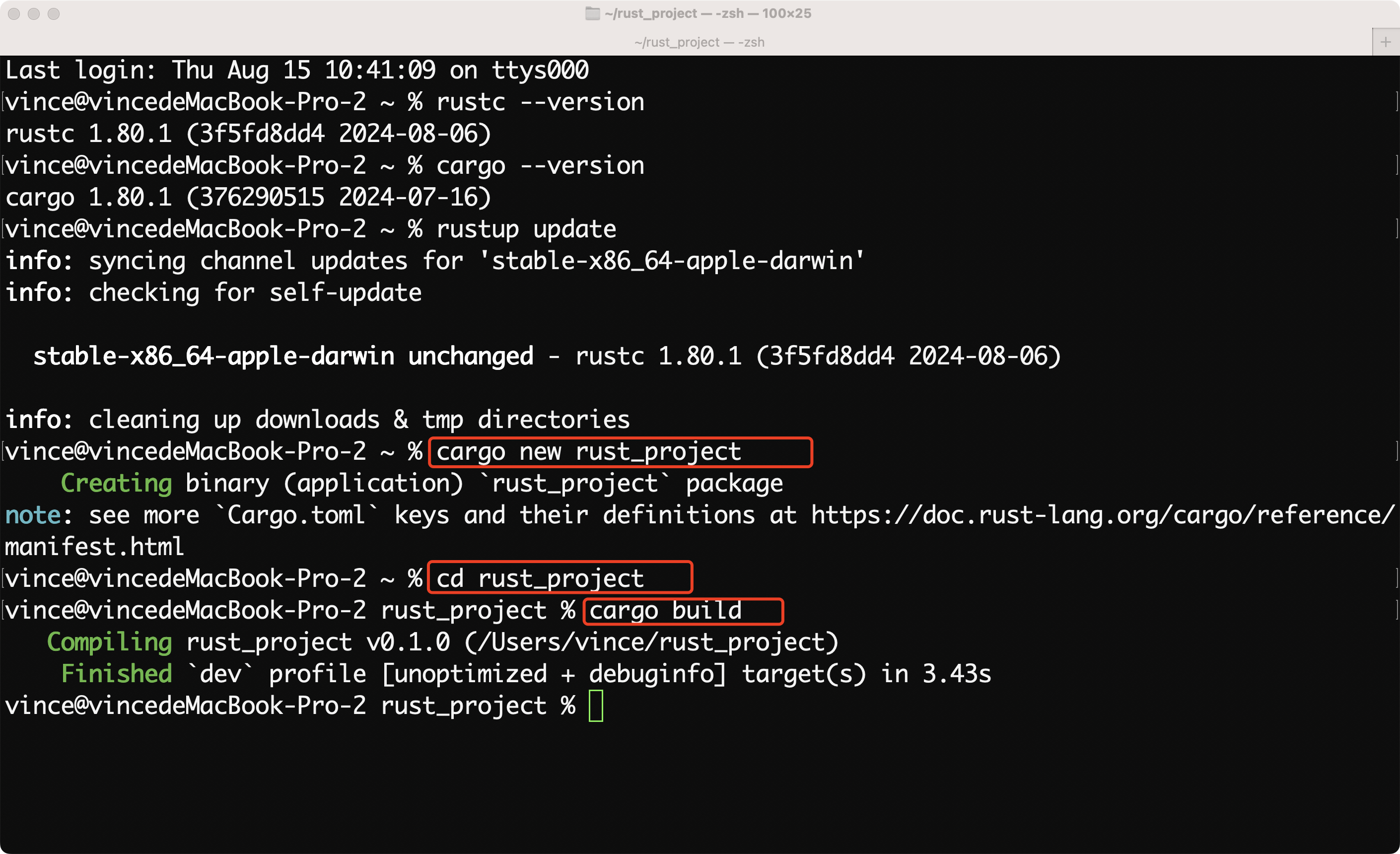
这将编译你的项目,生成的可执行文件在
target/debug/
目录下。
- 运行项目
:
cargo run

运行成功。
步骤 8: 探索项目结构
新创建的 Rust 项目包含以下文件和目录:
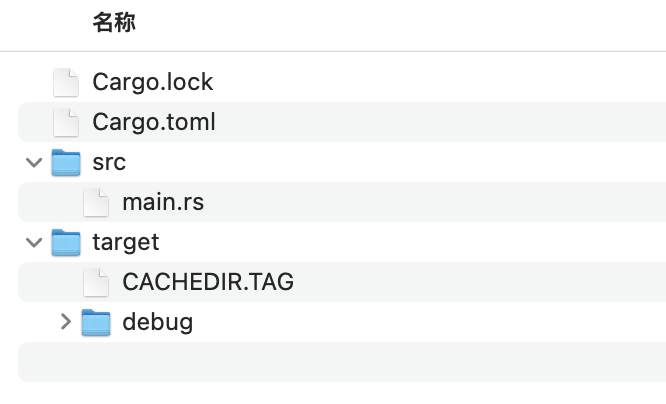
Cargo.toml
:项目的配置文件,包含元数据和依赖信息。src
:源代码目录,包含
main.rs
— 项目的入口点。
按照这些步骤,你将拥有一个基本的 Rust 开发环境,可以开始编写和运行 Rust 程序。如果你在安装过程中遇到任何问题,可以联系 V 哥一对一帮你解决。