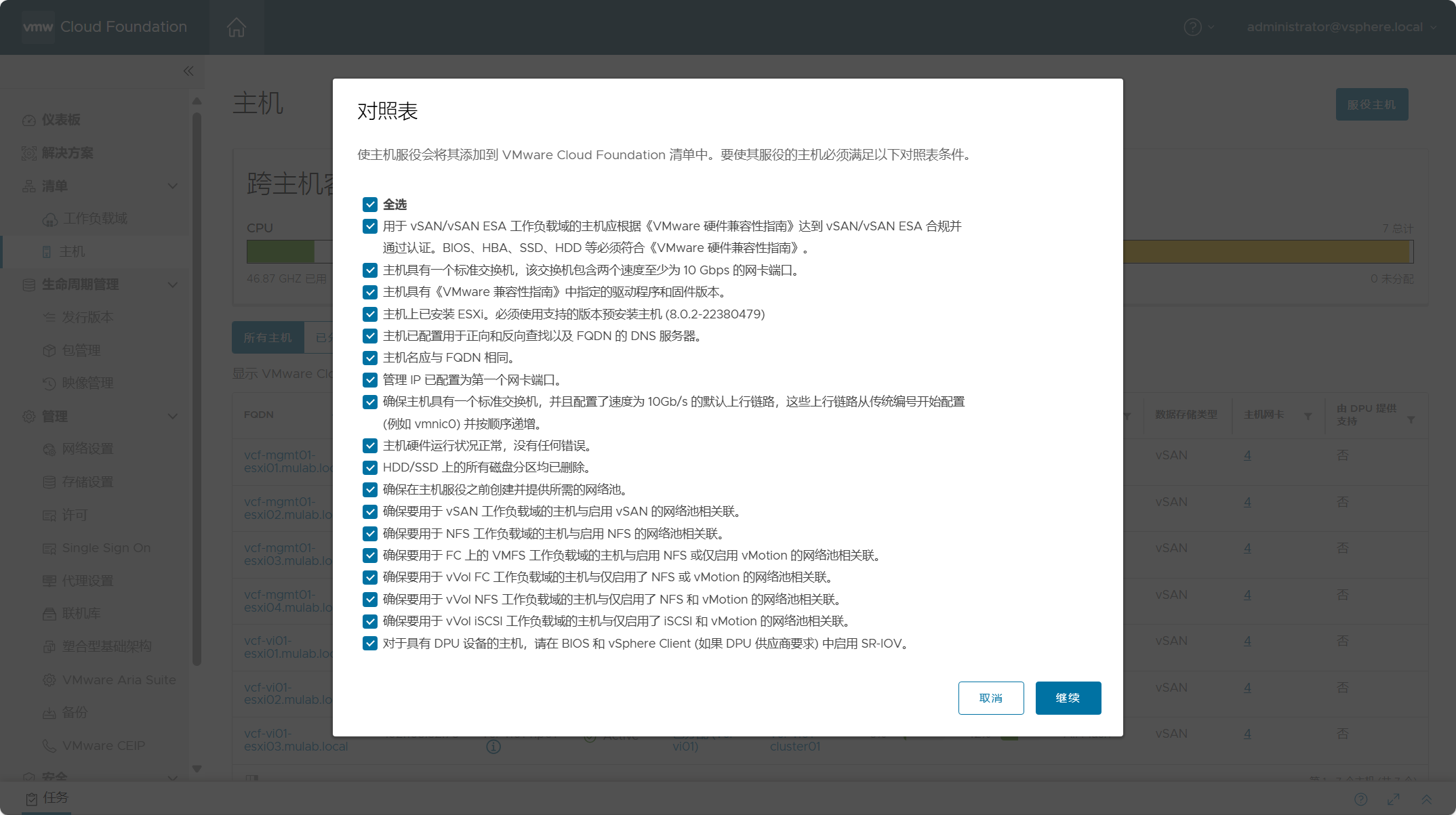
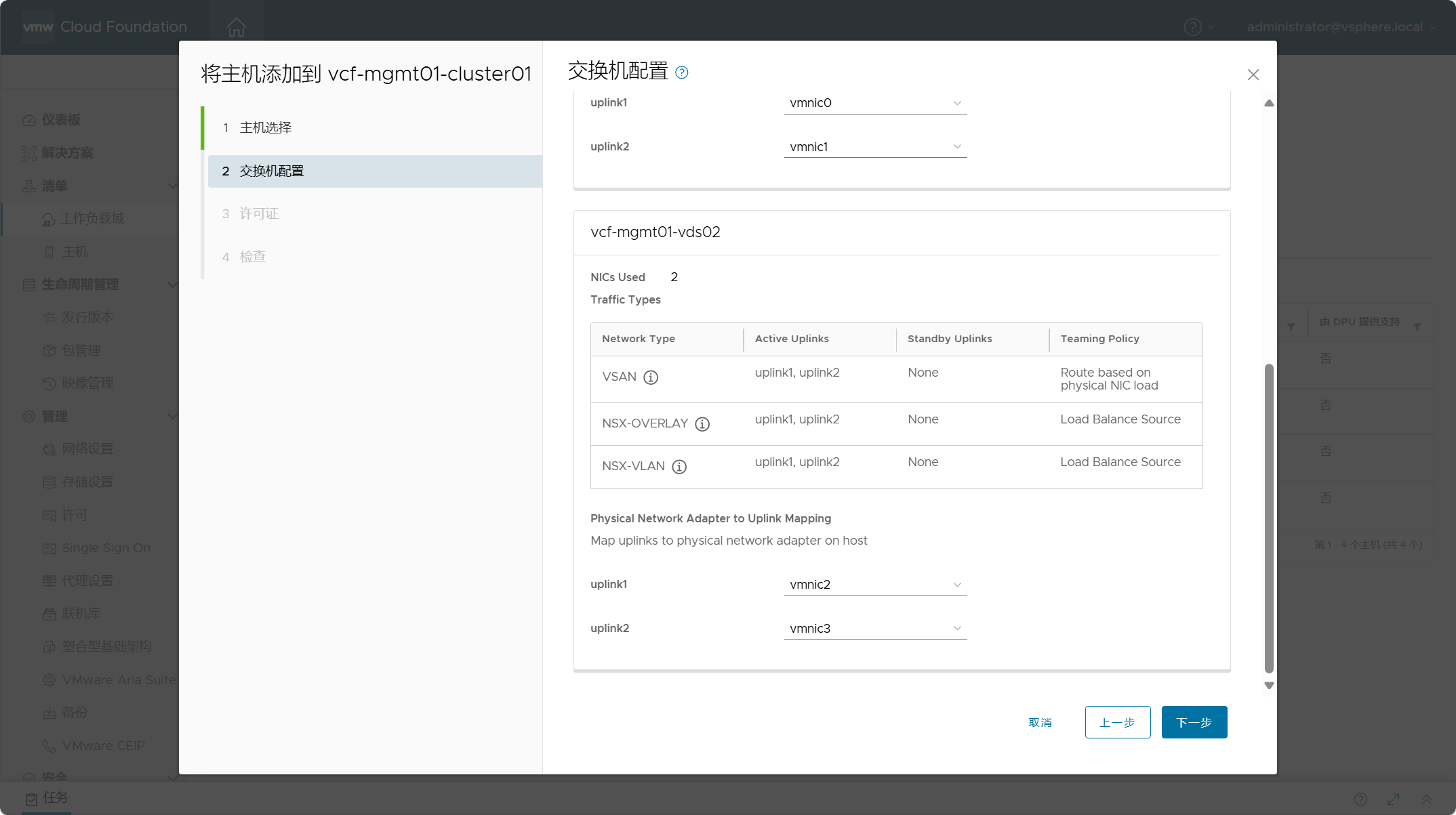
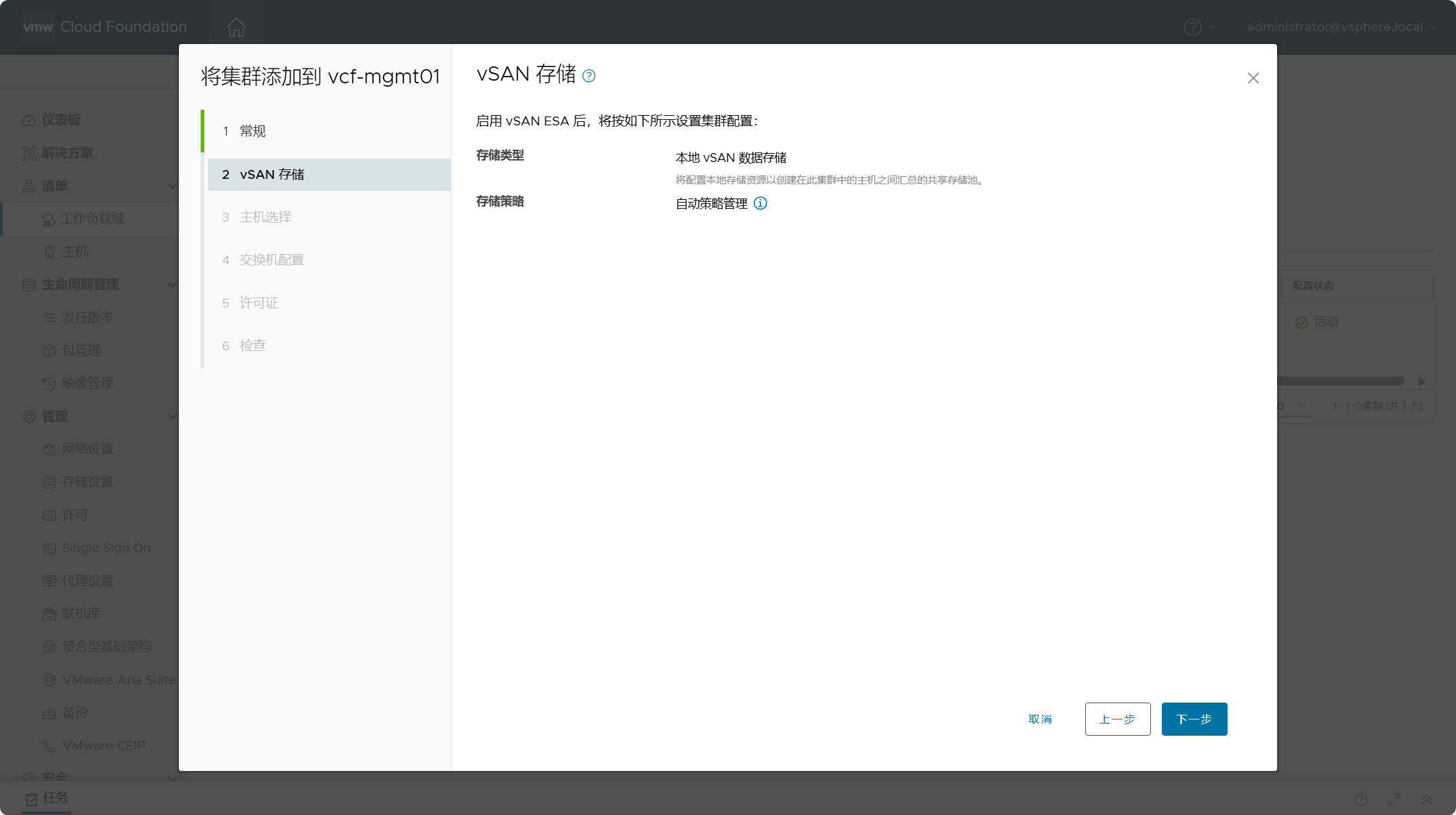
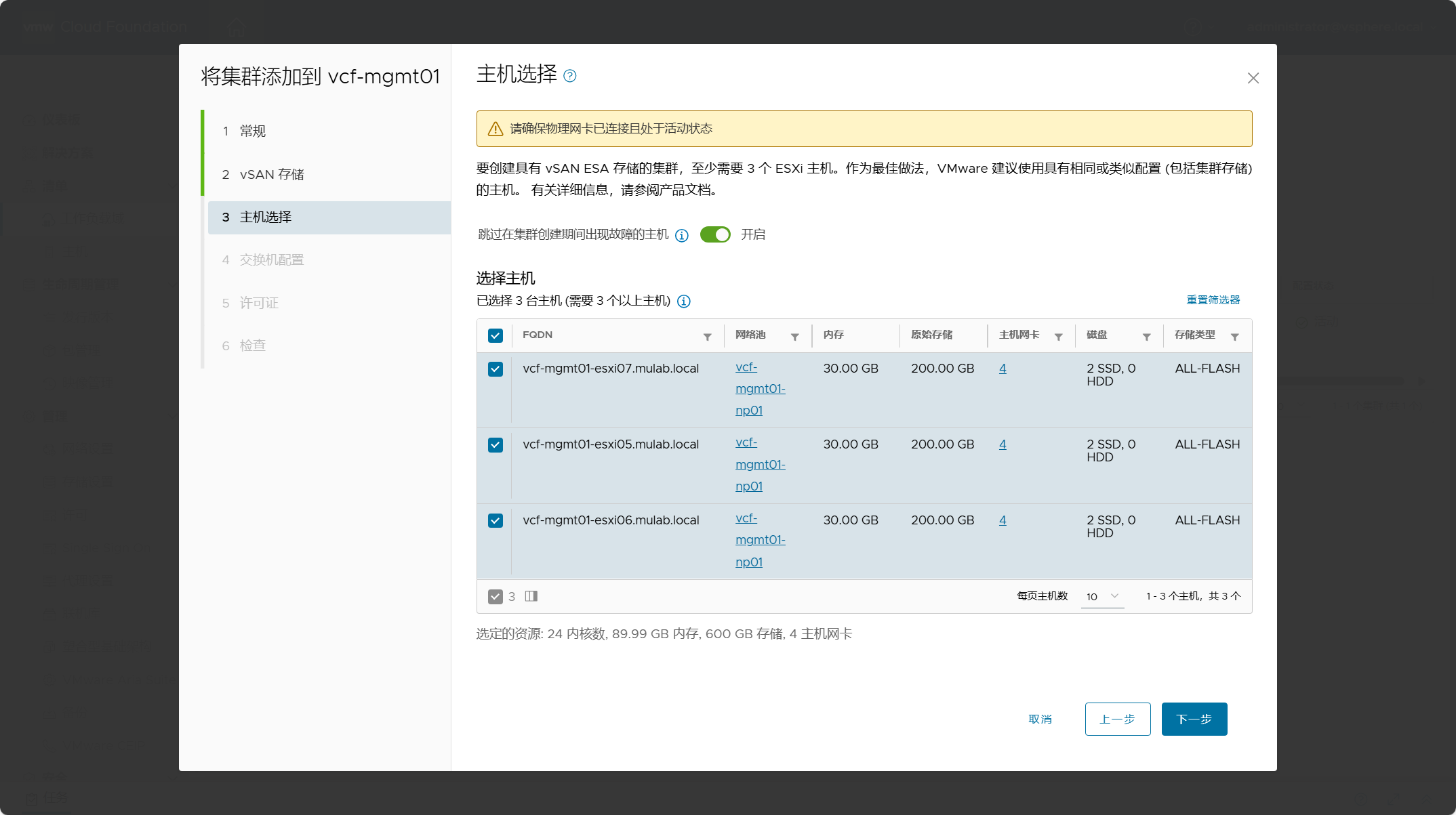
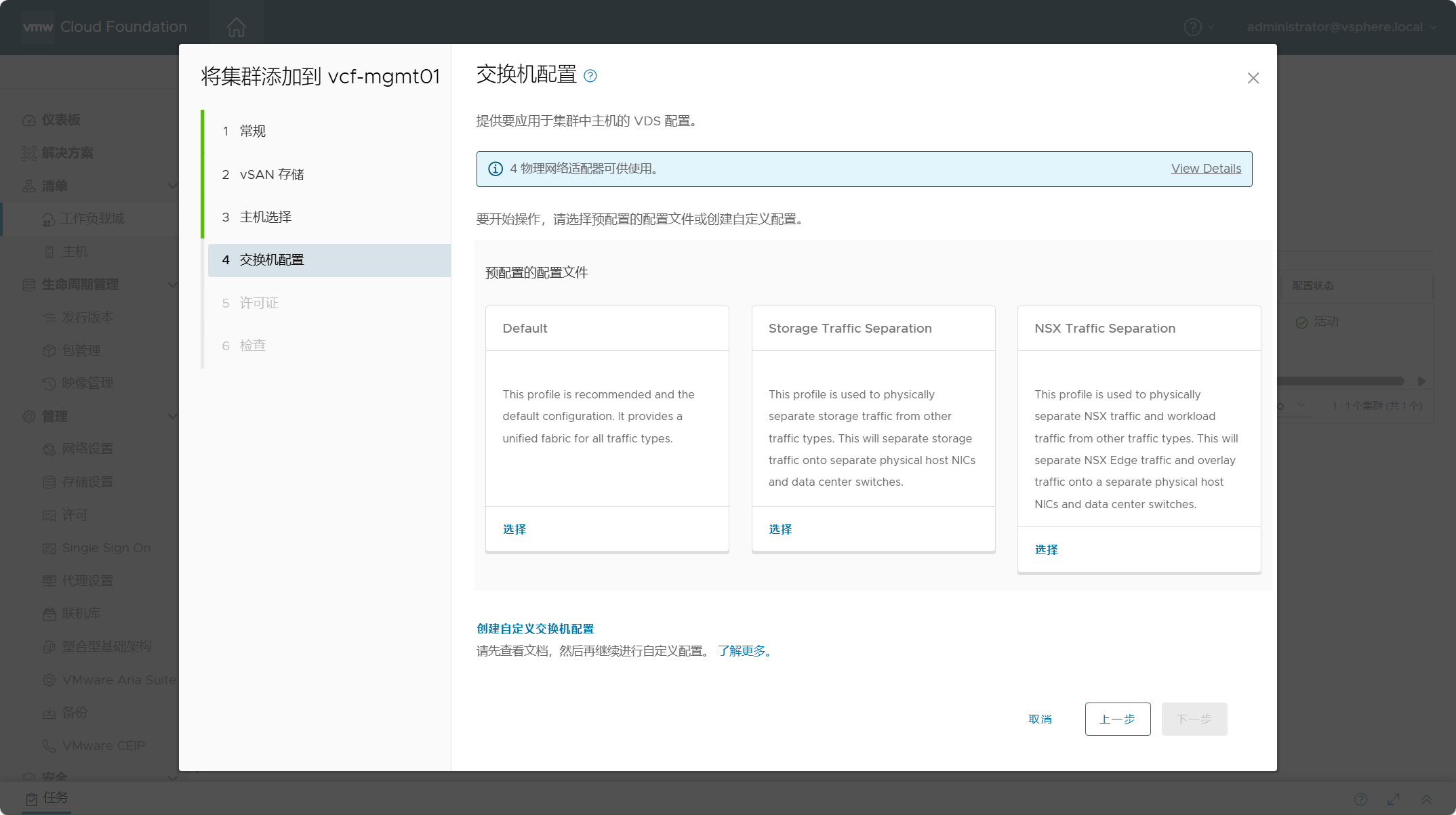
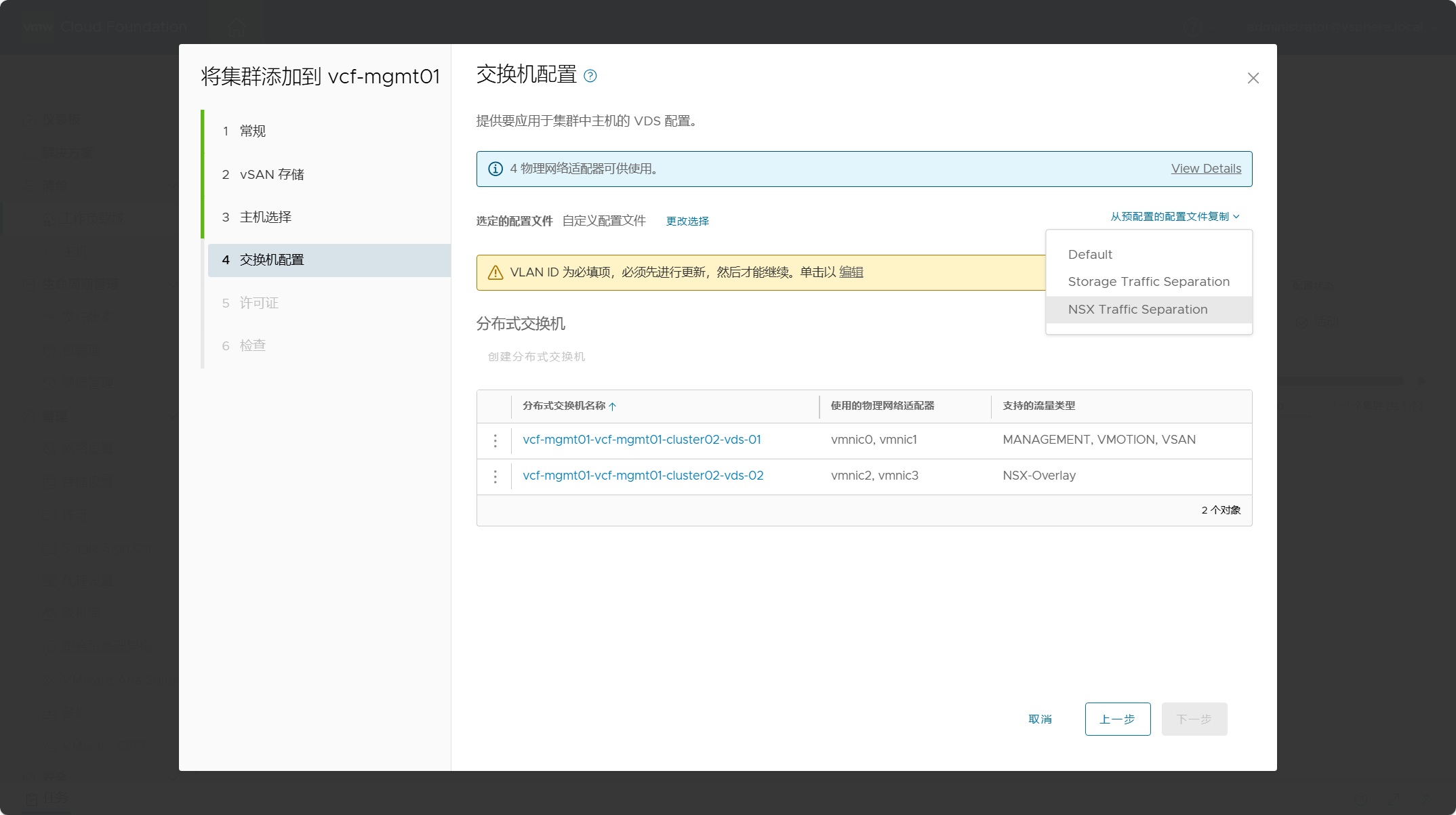
上一章我们聊了标准化的Prompt生成方案DSPy,但DSPy还是更多依赖few-shot的Prompt编写范式,在纯任务描述型指令上的优化效果有限。这一章我们就重点关注描述性指令优化。我们先简单介绍下结构化Prompt编写,再聊聊从结构化多角度进行Prompt最优化迭代的算法方案UniPrompt
1. 结构化Prompt编写
1.1 LangGPT
LangGPT算是最早提出要是用结构化Prompt进行写作的,现在在Coze这种任务流平台上看到的prompt基本上都是这个风格。
结构化Prompt一般使用Markdown和JSON来构建,感觉国内使用markdown更多,早期GPT3.5时使用JSON更多。毕竟现在很多开源模型SFT时也加了大量的Markdown样本,以下是LangGPT提供的Markdown格式的样例如下
# Role: Your_Role_Name
## Profile
- Author: YZFly
- Version: 1.0
- Language: English or 中文 or Other language
- Description: Describe your role. Give an overview of the role's characteristics and skills
### Skill-1
1.skill description 1
2.skill description 2
### Skill-2
1.skill description 1
2.skill description 2
## Rules
1. Don't break character under any circumstance.
2. Don't talk nonsense and make up facts.
## Workflow
1. First, xxx
2. Then, xxx
3. Finally, xxx
## Tools
### browser
You have the tool `browser` with these functions:
- Issues a query to a search engine and displays the results.
- Opens the webpage with the given id, displaying it.
- Returns to the previous page and displays it.
- Scrolls up or down in the open webpage by the given amount.
- Opens the given URL and displays it.
- Stores a text span from an open webpage. Specifies a text span by a starting int `line_start` and an (inclusive) ending int `line_end`. To quote a single line, use `line_start` = `line_end`.
### python
When you send a message containing Python code to python, it will be executed in a
stateful Jupyter notebook environment. python will respond with the output of the execution or time out after 60.0
seconds. The drive at '/mnt/data' can be used to save and persist user files. Internet access for this session is disabled. Do not make external web requests or API calls as they will fail.
### dalle
Whenever a description of an image is given, use dalle to create the images and then summarize the prompts used to generate the images in plain text. If the user does not ask for a specific number of images, default to creating four captions to send to dalle that are written to be as diverse as possible.
### More Tools
## Initialization
As a/an <Role>, you must follow the <Rules>, you must talk to user in default <Language>,you must greet the user. Then introduce yourself and introduce the <Workflow>.
不难发现结构化prompt有以下几个特点和优点
- 使用#,##等标题分隔符来构建层级
: 例如在二级标题profile下面有三级标题skill,让模型理解这里的skill也属于模型资料。而二级标题tools下面有python,browser,dalle等多个三级标题,表示这些都属于模型可调用工具
- 分模块任务描述
: 每个二级标题都是一个主模块,分模块构建的好处,一个是可以复用,一个是便于上手和prompt迭代,常见的模块包括以下
- profile & skills:角色描述,角色有哪些能力,使用啥语言etc
- goal & task: 任务和目标描述,例如负责基于用户指令生成写作大纲
- constraint & requirements:要求和限制,例如RAG要求模型回答必须来自上文,不能自己生成
- workflow:针对复杂任务往往要告诉模型先做什么后做什么,例如打分评估任务要先分析问题再进行1-5分的打分
- example & demos: 提供一些few-shot示例
- style & output format:对回答格式的要求,例如单选题只能输出ABCD其中一个
- Init & prefix: 告诉模型prompt结束,要开始回答的引导词,例如单选题可以是“>>>你认为最合理的选项是:”
- 模块变量引用
:在最后的initialization中,使用了<Rules>来引用对应的变量名称,向模型强调这里的Rules指的是前面提到的规则,而非广义的规则。这类变量引用经常大量用于RAG中约束模型使用上文,以及特定格式输出时进一步限制模型推理格式,例如"你的回答必须是<label>中的一个"
结构化Prompt的缺点也同样很明显
- 对模型能力要求较高,很多复杂指令理解能力较弱的小模型无法使用。其实也很好理解,指令就像是在模型高维空间里切割出的一片空间,指令越复杂空间切割的粒度就越细,而对于本身高维空间可分性较差的模型,切着切着就没了哈哈哈哈
- 越长的prompt上文,越多的constraint,会bias模型输出,导致很多corner case最后归因发现都是某一条requirement的锅。因此个人建议prompt初始都尽量简单,慢慢做加法,不要一上来就写的很复杂。你的每一条要求不一定有用,但都有可能挖坑。
1.2 Pratical Guide
在以上结构化提示器的基础上,新加坡提示词比赛的冠军还给出了更多的结构化prompt编写的tips,这里总结2个亲测好用tips。
- 分隔符的使用:分隔符这里广义指和其他层次化分隔符不同的字符。包括更长的#####,》》》》------之类。在prompt中有几个位置需要特殊分割符,核心是让模型理解分隔符前后存在显著差异,语义要分开。例如在RAG段落续写任务中,需要特殊分割符来分割检索上文【Context】,前面模型推理的段落【paragraph】,来完成后面的段落续写。而在一般回答任务中,建议显著区分回答开始的位置,如下
<Annex>
Give a table of the list of row numbers belonging to each cluster, in order to back up your analysis. Use these table headers: [[CLUSTER_NAME], List of Rows].
#############
# START ANALYSIS #
If you understand, ask me for my dataset.
- XML标签使用:针对一些分类任务,以及输出是可枚举值的任务,使用XML进行标签约束比markdown的输出效果会更加稳定。
Classify the sentiment of the following conversations into one of two classes.Give the sentiment classifications without any other preamble text.
<classes>
Positive
Negative
</classes>
<conversations>
[Agent]: Good morning, how can I assist you today?
[Customer]: This product is terrible, nothing like what was advertised!
[Customer]: I’m extremely disappointed and expect a full refund.
[Agent]: Good morning, how can I help you today?
[Customer]: Hi, I just wanted to say that I’m really impressed with your
product. It exceeded my expectations!
</conversations>
2. 结构化Prompt最优化
- Task Facet Learning: A Structured Approach to Prompt Optimization
有了上面结构化Prompt的铺垫,UniPrompt的优化思路会更容易理解。以上的结构化Prompt编写其实就是把prompt拆分成了多个角度,例如profile,rules,workflow等等进行分别优化。UniPrompt同样采用了结构化prompt的思路,让模型直接生成结构化prompt,并对每个部分进行针对性优化。同时给出了模型在迭代prompt时通用性容易受到个别样本影响的解决方案。相比上一章DSPy里面提到的大模型反思直接优化,以及随机搜索的方案要更加有系统针对性~
Prompt Optimization?
论文前面很有意思,作者先尝试论证定向Prompt最优化这个事它靠不靠谱。
连续性证明
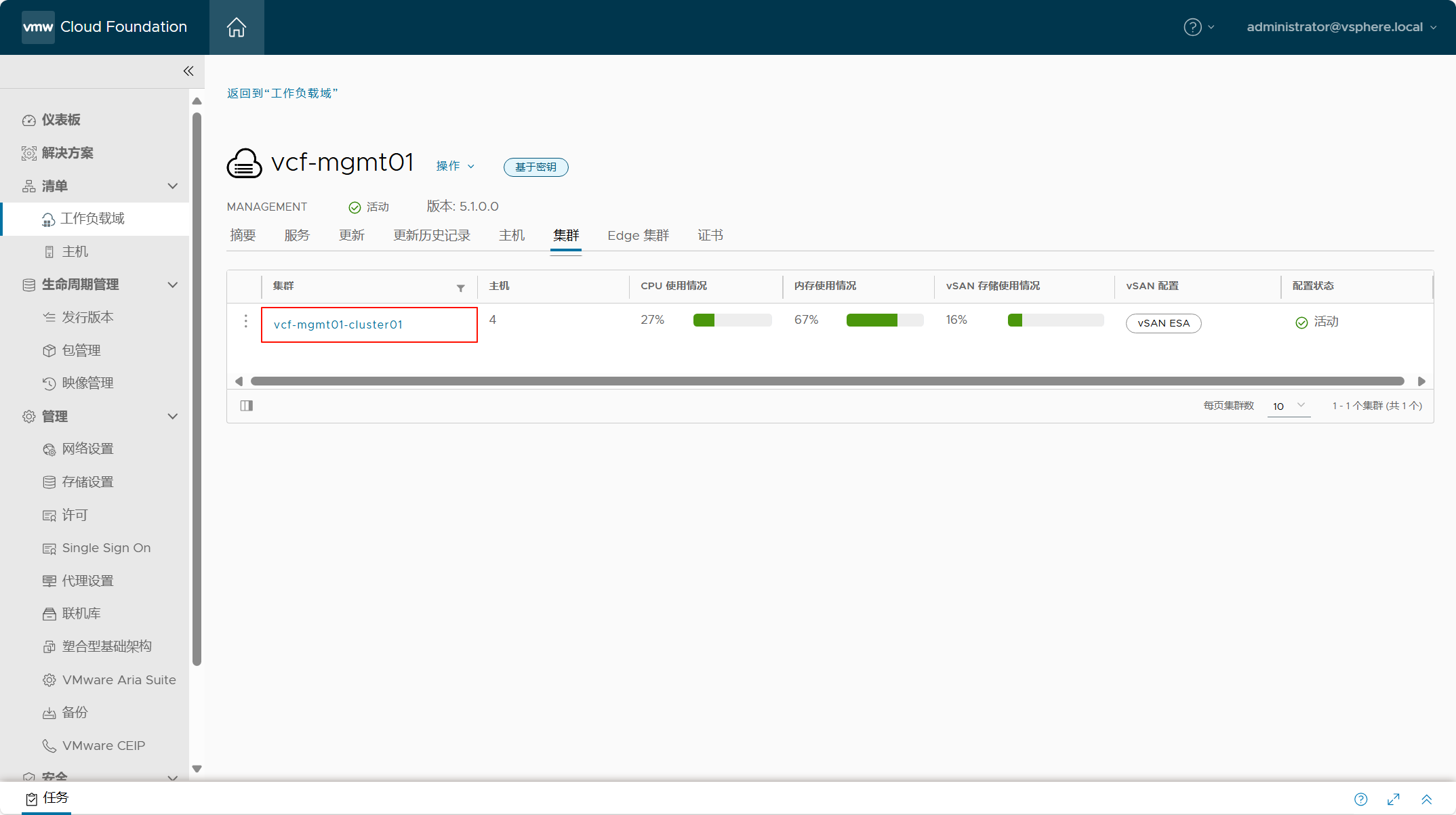
作者先通过指令敏感性,既微小的指令变动对任务效果的影响幅度(利普希茨连续性),来验证最优化的可行性。毕竟如果指令的随便一个微小的变动,就会带来巨大的变化,那随机搜索可能更合适,但如果指令敏感度有上界的话,那最优化方案就可能更合适合。利普希茨连续性的数学定理如下
给定一个概率分布X和一个非负实数r,其中L>=0是利普希茨常数,d是一个距离变量,如果满足如下条件
\[P[ d(f(x),f(x^′)) \leq L \cdot d(x, x^′)| \,d(x,x^′) \leq r] \geq 1 - \epsilon
\]
简单说就是函数变化的斜率被限制在一个有限的范围内。那为了实验prompt的敏感性,论文使用GPT4对初始Prompt进行改写,并计算改写prompt和最初prompt 的cosine距离(Ada-002)作为指令变动幅度的衡量(d(x)),然后使用改写prompt在验证集上进行测试,用指标变化(Acc)作为任务效果变化幅度的衡量(d(f(x))),如下图(a)所示,在95%的概率下,GPT4和GPT3的变化上界<1,而更小的模型Llama2-13B超过2。所以能力越强的模型对指令的微小变动更加鲁棒,在指令最优化上的可行性更高。

子模性证明
有利普希茨连续性做为基础,论文还进一步论证了在有限样本和有限的prompt长度的限制下,通过多角度迭代优化prompt的可行性,以及对比few-shot迭代的更优性。这里论文从子模性角度进行了讨论,submodularity的定义如下,简单说就是同一个元素加到不同的集合中产生的边际收益,随着集合的增大和递减。
对于一个集合V和一个非负实值函数f, 如果对于所有$ A, B \subseteq V$, 且
\(A \subseteq B\)
, 以及对于所有
\(x \in V \setminus B\)
都有:
\[f(A \cup \{x\}) - f(A) \geq f(B \cup \{x\}) - f(B)
\]
那在有限样本和有限prompt长度的限制下,寻找最优Prompt的问题,就变成了求解最大化子模态函数的问题,即寻找集合
\(S \in V\)
,使得
\(f(S)\)
最大化,同时满足
\(|S| \lt K\)
。而满足modularity的函数,可以通过贪婪算法得到最优的近似解,每次迭代都把边际收益最大的元素加到集合中,直到边际收益小于阈值,或者集合大小达到上限。
论文分别计算了few-shot和task-facet使用贪婪算法的边际效益,上面的函数f为验证集指标。few-shot的计算采用随机采样了多个A,B的few-shot集合,其中B集合小于A集合,计算在A,B集合上加入同一个shot,计算验证集指标变化,如下图的概率分布,会发现few-shot的概率集中在[-0.01, 0.01]之间,基本是随机分布,并看不到边际递减效应的存在。

而task-facet部分,对比上面few-shot是加demo,这里是加section,可以类比前面结构化Prompt的一个子模块。这里论文采用了微调模型(Llama2-13B)来生成一个任务多个角度的prompt,下图的Introduction,Task Description,Real-life Application,Background Knowledge, Challenges分别各是一个section,那A和B分别是采样了不同的section,再计算加入一个新的section的边际收益,会发现对比few-shot的虚线,Facet代表的蓝线有更加明显的边际效应递减的趋势。但这和我们如何生成section是高度相关的,下面我们具体说下如何通过模型来生成任务不同角度的描述(section),并使用大模型进行迭代优化的。

UNIPROMPT
UNIPROMPT的整个流程分成以下几个步骤
- 微调LLama2-13B,让模型直接生成结构化的初始prompt
这里论文使用GPT4构建了样本,给定任务描述(使用了tasksrouce样本集的指令), 和section的描述例如Background,description,requirements,让GPT4来生成该section的内容,然后使用该样本微调Llama2-13B。
### Instruction:
You are a prompt engineer, you have to write a structured prompt.
For the given task description, examples and section description,
write the contents of the section that align with section description.
### Task Description:
{data_point[’task_description’]}
### Section Description:
{data_point[’section’]}:{section_descriptions[data_point[’section’]]}
### Response:
{data_point[’prompt’]}
微调后的Llama2,给定任务描述和section描述,会生成该section的prompt。如下是background角度prompt生成的prompt。作为初始化,会采样10个模型生成的prompt,然后选择验证集上效果最优的prompt。
Task: glue qnli
Task Description: With no explanation, label A to B with either entailment or not entailment
Section: background
Prompt:
1. Entailment means that the information in statement B can be inferred directly from statement A.
2. Not entailment means that the information in statement B cannot be inferred directly from statement A or is unrelated.
3. Understanding the context and relationship between the two statements is crucial for accurate classification.
有了初始prompt,下一步就是进行迭代优化。这里为了避免前人使用单样本,随机采样样本进行优化,引入的样本bias,这里论文对样本进行了聚类,认为每一个cluster中的任务表征是相似的。这里论文使用大模型prompt对每个问题进行了主题分类打标,然后按标签划分了cluster。不使用cosine相似度的一个原因,个人感觉是语义相似和任务表征相似这里存在diff,所以个人感觉这里的聚类可能需要case by case来看,不同的任务根据输出的不同需要调整。
基于上面的样本聚类,进一步拆分成mini-batch(3-5),在每个minibatch上基于模型对样本的预测,使用GPT4生成feedback。然后再在batch(5-7个样本)粒度上对各个minibach上的feedback进行共性抽取,并直接生成针对section的增,删,改的具体操作建议。这里两阶段的设计和梯度累计的思路相似,其实还是想要降低个别样本,甚至个别mini-batch在prompt迭代时陷入个性而非共性优化的问题(其实你只要试试用大模型去做过prompt优化就会发现模型非常容易被带偏,因此平滑和共性抽取很重要)。
以下分别是minibach上的返回prompt,和在batch粒度上的总结prompt
You are a teacher and you have to give feedback to your students on their answers.
You are teaching how to solve math problems to your students.
You are given a question, it’s true answer and answer given by student.
You are also given the explanations written by your students while solving the questions.
The questions are answered wrong by the students.
You have to tell why is the solution wrong and what information is can be added to the in the Background Knowledge part that would have helped the student to write better explanations.
## IMPORTANT: You are also given a history of changes you made to the background knowledge part and the change in student’s accuracy after making the change. You have to use this history to make your feedback.
Be explicit and tell the exact information that can be added without further modification / addition.
### IMPORTANT: Give feedback in form of instructions like add a section, add a subsection, set the content of a section, set the content of a subsection, delete a section or delete a subsection in the background knowledge part. Give very granular feedbacks, like if the student has made amistake in the calculation, then tell what is the mistake in the calculation and how to correct it, if the student has made a mistake in the concept, then tell what is the mistake in the concept and how to correct it.
## Background Knowledge
{current_prompt}
## History
{history_string}
Now, it is your turn to give feedbacks to the students.
You can only provide a one line feedback.
You are given a set of feedbacks for some problems. The setfeedbacks for each problem separated by =========== symbol.You have to summarize the feedbacks into a final feedback.You are also given a set of wrong questions.
You need to tell which edit can be applied to aid the student in solving the wrong question.
To achieve your task, try to follow the following steps;
1. Identify the general problem that is being solved by all the feedbacks.
2. Once you have identified the problem, try to make a new feedback that covers most of the feedbacks given.Let’s say the problem in the first feedback is the absence of methods to solve linear equation and in the second feedback itis the method to inverse a matrix.You know that both of these problems can be caused by adding how to solve convert a matrix into row rediced echolon form. So,add that.
3. Try and validate your feedback. Once, you have a feedback try to see if it covers every feedback, if it does not cover any feedback, add that to yournew feedback.
4. See the wrong questions and try to identify what is the problem in the question.If the problem is not covered by your feedback, add that to your feedback.
5. You can add specifics like examples, definitions etc makesure that the feedback is enough to be directly added withoutany modification.
You may use the following function templates
add_section(sectioname)
add_subsection(section_name, subsection_name)
set_section_content(section_name, new_content)
set_subsection_content(section_name, subsection_name, new_content)
delete_section(section_name)
delete_subsection(section_name, subsection_name)
Your summary cannot include more than four functions. Make sure that the content is useful,not just a very general statement. Something specific.
Instructions:
{edits}
Wrong Questions:
{wrong_examples_string}
Summary:
基于上面得到的反馈和操作,论文使用以下指令让模型对prompt进行编辑和修改。这里只保留修改后验证集打分有提升的新prompt(greedy),并在每一步都维护多个优化后效果最好的prompt(类比Beam-Size=2),停止迭代的信号是连续5轮在验证集上没有效果提升。
You are given an input prompt and a feedback, you have to incorporate the feedback into the input prompt and output the final prompt.
An example of the task is given below
### Input Prompt
Introduction: In this task you have to answer the given question.
### Feedback
The background knowledge is incomplete, it does not include what are the factors that affect the water usage and how many water sources are there.
\\add_subsection("Background Knowledge")
\\add_subsection_content(water usage depends on the population, climate, economic development, and availability of water sources. There are two sources of water, surface water and groundwater.)
### Final Prompt
Introduction: In this task you have to answer the given question.
Background Knowledge: water usage depends on the population, climate, economic development, and availability of water sources. There are two sources of water, surface water and groundwater.
Only output the final prompt nothing else.
### INPUT PROMPT
{current_prompt}
21
### FEEDBACK
{edits}
### FINAL PROMPT
效果上论文和之前的OPRO,ProTeGi等算法都做了对比,在多个数据集上都会有较显著的效果提升。