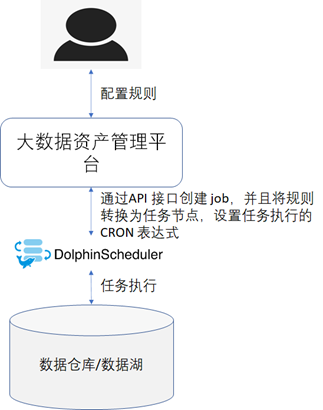
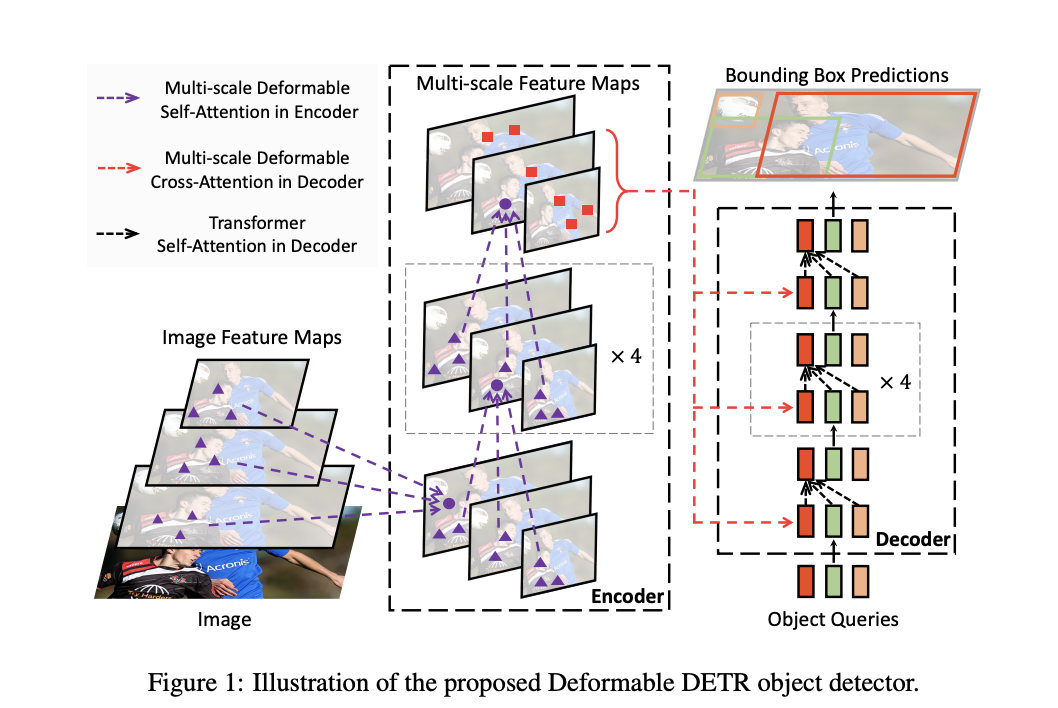
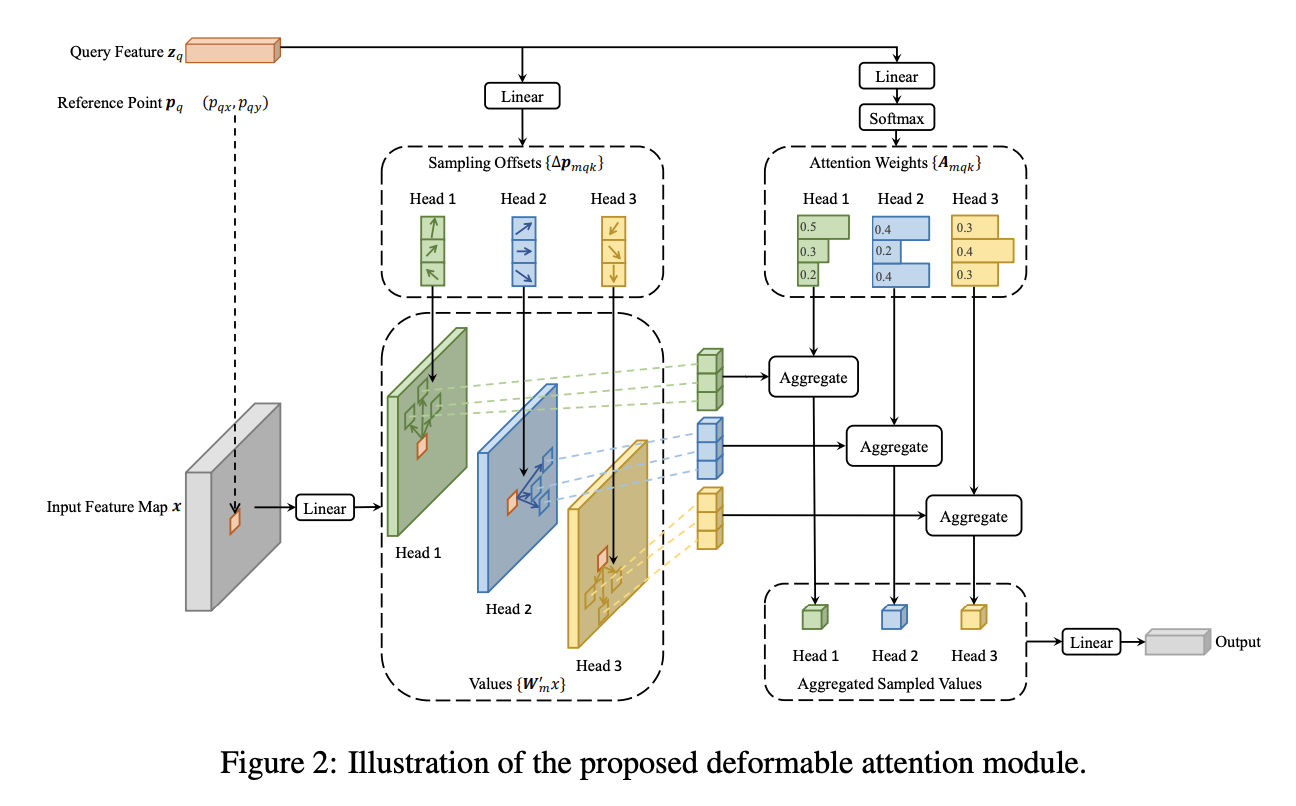
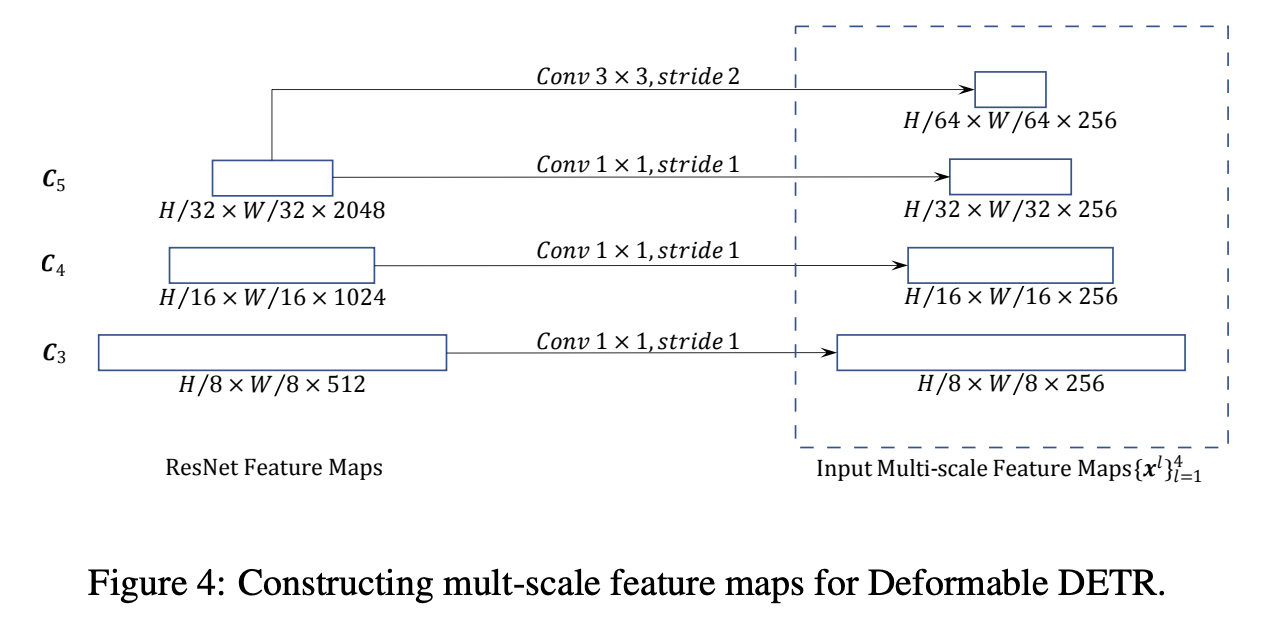
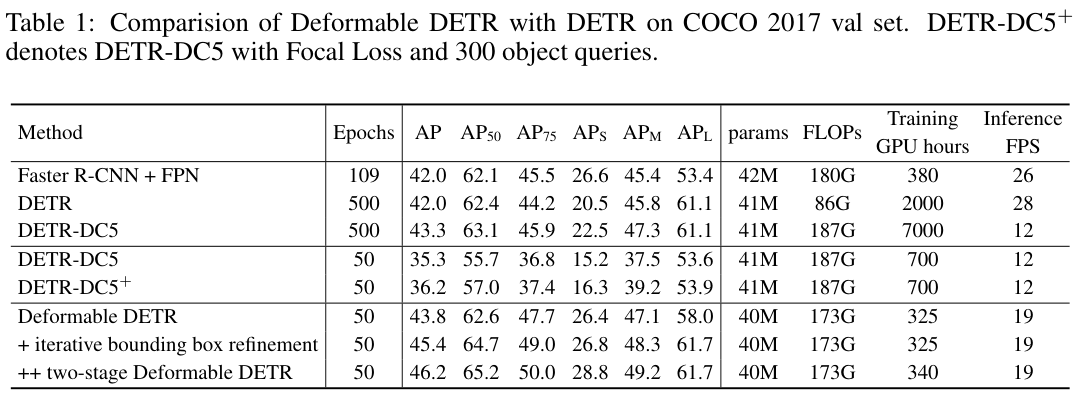
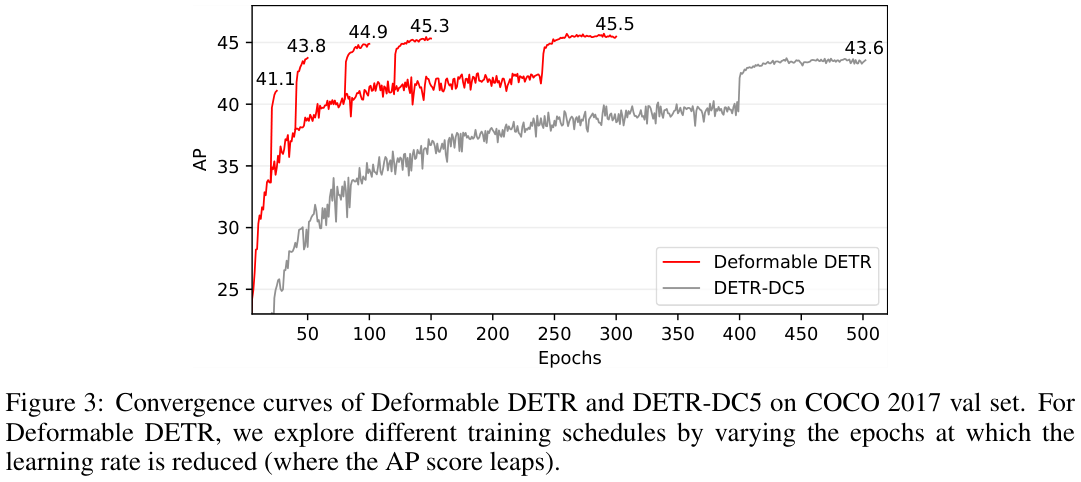
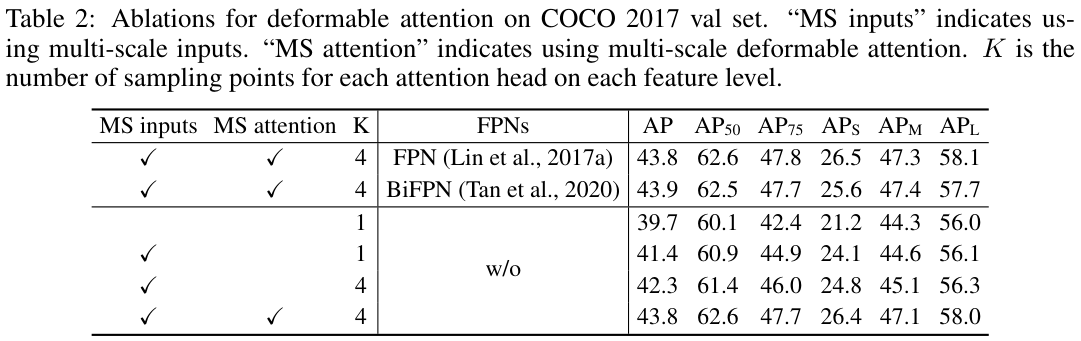
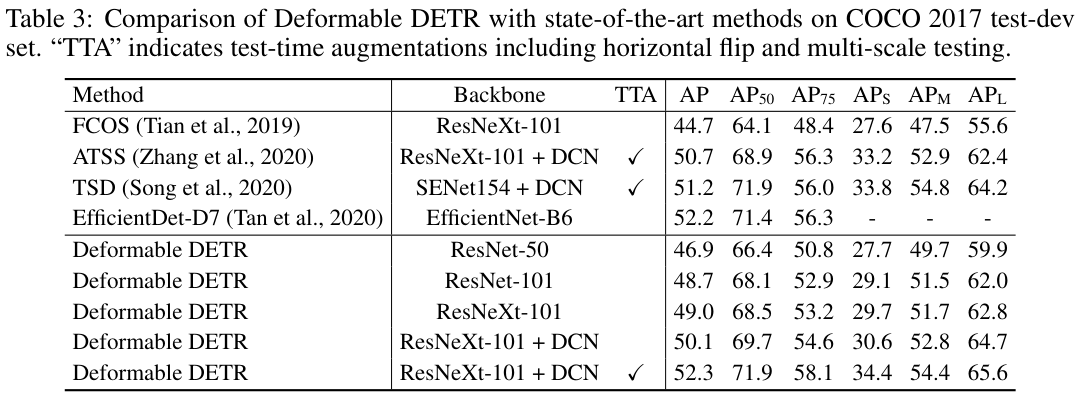
canvas实现手动绘制矩形
开场白
虽然在实际的开发中我们很少去绘制流程图
就算需要,我们也会通过第3方插件去实现
下面我们来简单实现流程图中很小的一部分
手动绘制矩形
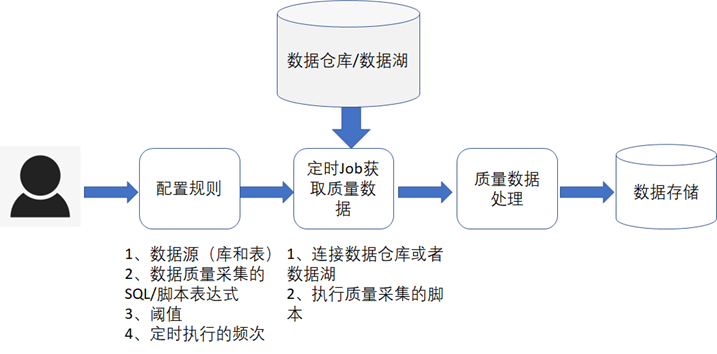
绘制一个矩形的思路
我们这里绘制矩形
会使用到canvas.strokeRect(x,y, w, h)方法绘制一个描边矩形
x:矩形起点的 x 轴坐标。
y:矩形起点的 y 轴坐标。
width:矩形的宽度。正值在右边,负值在左边。
height:矩形的高度。正值下降,负值上升。
注意一下w,h这两个参数的正直和负值。
如果w,h是负数,会出现了2个斜着对称的矩形

绘制一个静态矩形
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
html,body{
/* 去除浏览器内置的margin */
margin: 0;
/* 整个页面铺满 */
height: 100%;
width: 100%;
}
</style>
</head>
<body>
<canvas id="canvas"></canvas>
</body>
<script>
// 获取canvas元素
let canvasEle = document.getElementById('canvas')
// 获取canvas的上下文
const ctx = canvasEle.getContext('2d')
// 设置canvas的大小(宽高) 与屏幕一样宽高
const screenSize = document.documentElement
canvasEle.width = window.screen.availWidth
canvasEle.height = window.screen.availHeight
// 给矩形的设置颜色,设置颜色一定要在绘制之前,否则将会不生效
ctx.strokeStyle = '#a0a'
// 绘制一个路径模式是的矩形,起始坐标100,100, 宽300,高280
ctx.strokeRect(100,100,300,280)
</script>
</html>

手动绘制矩形的基本思路
通过上面我们实现了静态绘制矩形。
如果我们想要手动画一个矩形,需要实现以下几个步骤
1.给canvas注册鼠标按下事件,在按下的时候记录矩形的起始坐标(x,y)
与此同时,还需要在按下时注册鼠标移动事件和抬起事件。
2.在鼠标移动的时候,通过计算得到矩形的宽和高。
计算矩形的宽度和高度时,我们要使用绝对值进行计算。
计算后立即绘制矩形
3.在鼠标抬起时,移除之前注册的鼠标移动事件和抬起事件
手动绘制矩形
<script>
// 获取canvas元素 oCan
let canvasEle = document.getElementById('canvas')
// 获取canvas的上下文
const ctx = canvasEle.getContext('2d')
// 设置canvas的大小(宽高) 与屏幕一样宽高
const screenSize = document.documentElement
canvasEle.width = window.screen.availWidth
canvasEle.height = window.screen.availHeight
// 所有的矩形信息
let rectArr = []
// 给canvas注册事件按下事件
canvasEle.addEventListener('mousedown',canvasDownHandler)
function canvasDownHandler(e){
console.log('按下', e)
rectArr = [e.clientX,e.clientY ]
// 按下的时候需要注册移动事件
canvasEle.addEventListener('mousemove', canvasMoveHandler)
// 抬起事件
canvasEle.addEventListener('mouseup', canvasMouseUpHandler)
}
// 移动的时候我们需要记录起始点和结束点,然后就可以绘制矩形了
function canvasMoveHandler(e){
console.log('我们在移动了', e)
// 在移动的时候就开始绘制矩形
drawRect(rectArr[0], rectArr[1], e.clientX, e.clientY)
}
function drawRect(x1,y1,x2,y2){
// 在计算矩形的宽高时,我们需要使用绝对值来进行计算
// 此时此刻移动的坐标减去最初按下的坐标就是矩形的宽和高
// 如果不用绝对值,可能会出现2个矩形
let rectWidth = Math.abs(x2-x1)
let rectHeight = Math.abs(y2-y1)
// 存储矩形的坐标信息
rectArr = [x1,y1,rectWidth,rectHeight]
ctx.strokeRect(...rectArr)
}
// 当我们鼠标抬起的时候要移除之前注册移动事件和抬起事件
function canvasMouseUpHandler(){
canvasEle.removeEventListener('mousemove', canvasMoveHandler)
canvasEle.removeEventListener('mouseup', canvasMouseUpHandler)
}
</script>


发现问题出现多余的路径
通过上面这张图片,我们虽然绘制手动绘制出了矩形。
但是出现了重复的路径。
我们先分析一下出现重复路径的原因。
我们在每次移动的过程中,都会绘制矩形。
只要我们在绘制前,清空矩形是不是就可以解决这个问题
我们来尝试一下
在绘之前清除多余的路径
function drawRect(x1,y1,x2,y2){
// 在计算矩形的宽高时,我们需要使用绝对值来进行计算
// 此时此刻移动的坐标减去最初按下的坐标就是矩形的宽和高
let rectWidth = Math.abs(x2-x1)
let rectHeight = Math.abs(y2-y1)
// 存储矩形的坐标信息
rectArr = [x1,y1,rectWidth,rectHeight]
// 在绘制矩形前,我们将矩形清空,然后在绘制,就不会出现多余的路径了
ctx.clearRect(0,0, canvasEle.width, canvasEle.height)
// 重新绘制矩形
ctx.strokeRect(...rectArr)
}

机智的小伙伴发现问题了?
有些机智的小伙伴发现:
如果我起始点是右下角,终点是左上角。
即:用户从(900, 1000)拖动到(50, 50)这种情况
按照这样的方向绘制矩形,是不是会出现问题呢?
确实会出现问题。
此时绘制的矩形不会随着我们的方向进行绘制。请看下面的图
如何处理这个问题呢?
主角闪亮登场 canvas.rect
canvas.rect(x,y,w,h)该方法创建一个矩形路径
x:矩形起点的 x 轴坐标。
y:矩形起点的 y 轴坐标。
width:矩形的宽度。正值在右边,负值在左边。
height:矩形的高度。正值下降,负值上升。
这个方法是创建一个矩形路径,创建的路径并不会直接绘制在画布上。
需要调用stroke()或fill()才能显示在画布上。
使用canvas.rect 绘制矩形路径
function drawRect(x1,y1,x2,y2){
let rectWidth = Math.abs(x2-x1)
let rectHeight = Math.abs(y2-y1)
// 绘制之前先清空之前实时移动产生的多余的矩形路径
ctx.clearRect(0,0, canvasEle.width, canvasEle.height)
// 开始画线
ctx.beginPath();
// 绘制路径矩形
ctx.rect(Math.min(x1, x2), Math.min(y1, y2), rectWidth, rectHeight);
// 绘制形状的轮廓。
ctx.stroke();
}

canvas.strokeRect与canvas.rect的异同
区别1功能性: canvas.strokeRect:绘制的是边框。canvas.rect创建矩形的路径(不绘立即绘制在矩形上)
区别2即时性: canvas.strokeRect是立即绘制。canvas.rect不是立即绘制,需要调用stroke()或fill()才能绘制
相同点:
1.都是绘制矩形
2.接受的参数相同
3.都是通过strokeStyle(颜色)和lineWidth(线的粗细)等来设置样式
连续绘制多个矩形
function drawRect(x1,y1,x2,y2){
let rectWidth = Math.abs(x2-x1)
let rectHeight = Math.abs(y2-y1)
let endX = Math.min(x1, x2)
let endY = Math.min(y1, y2)
// 绘制之前先清空之前实时移动产生的多余的矩形路径
ctx.clearRect(0,0, canvasEle.width, canvasEle.height)
// 绘制之前那些存储在 beforeRectArr 数组中的矩形
allRectInfoArr = [endX, endY, rectWidth, rectHeight]
ctx.clearRect(0,0, canvasEle.width, canvasEle.height)
beforeRectArr.forEach(element => {
ctx.beginPath();
ctx.strokeRect(...element)
ctx.stroke();
});
// 开始本次路径
ctx.beginPath();
// 绘制本次的矩形路径
ctx.rect(...allRectInfoArr);
// 开始填充矩形
ctx.stroke();
}
// 当我们鼠标抬起的时候要移除之前注册移动事件和抬起事件
function canvasMouseUpHandler(){
savaBeforeRect()
canvasEle.removeEventListener('mousemove', canvasMoveHandler)
canvasEle.removeEventListener('mouseup', canvasMouseUpHandler)
}
function savaBeforeRect(){
beforeRectArr.push(allRectInfoArr)
}

全部代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
html,body{
/* 去除浏览器内置的margin */
margin: 0;
/* 整个页面铺满 */
height: 100%;
width: 100%;
}
</style>
</head>
<body>
<canvas id="canvas"></canvas>
</body>
<script>
// 获取canvas元素 oCan
let canvasEle = document.getElementById('canvas')
// 获取canvas的上下文
const ctx = canvasEle.getContext('2d')
// 设置canvas的大小(宽高) 与屏幕一样宽高
const screenSize = document.documentElement
canvasEle.width = window.screen.availWidth
canvasEle.height = window.screen.availHeight
// 给矩形的设置颜色
// ctx.strokeStyle = '#a0a'
// // 绘制一个路径模式是的矩形,起始坐标100,100, 宽300,高280
// ctx.strokeRect(100,100,400,280)
// 矩形信息
let rectArr = []
// 所有的矩形信息
allRectInfoArr = []
let beforeRectArr =[]
// 给canvas注册事件按下事件
canvasEle.addEventListener('mousedown',canvasDownHandler)
function canvasDownHandler(e){
rectArr = [e.clientX,e.clientY ]
// 按下的时候需要注册移动事件
canvasEle.addEventListener('mousemove', canvasMoveHandler)
// 抬起事件
canvasEle.addEventListener('mouseup', canvasMouseUpHandler)
}
// 移动的时候我们需要记录起始点和结束点,然后就可以绘制矩形了
function canvasMoveHandler(e){
// 在移动的时候就开始绘制矩形
drawRect(rectArr[0], rectArr[1], e.clientX, e.clientY)
}
function drawRect(x1,y1,x2,y2){
let rectWidth = Math.abs(x2-x1)
let rectHeight = Math.abs(y2-y1)
let endX = Math.min(x1, x2)
let endY = Math.min(y1, y2)
// 绘制之前先清空之前实时移动产生的多余的矩形路径
ctx.clearRect(0,0, canvasEle.width, canvasEle.height)
// 绘制之前那些存储在 beforeRectArr 数组中的矩形
allRectInfoArr = [endX, endY, rectWidth, rectHeight]
beforeRectArr.forEach(element => {
ctx.beginPath();
ctx.strokeRect(...element)
ctx.stroke();
});
// 开始本次路径
ctx.beginPath();
// 绘制本次的矩形路径
ctx.rect(...allRectInfoArr);
// 开始填充矩形
ctx.stroke();
}
// 当我们鼠标抬起的时候要移除之前注册移动事件和抬起事件
function canvasMouseUpHandler(){
savaBeforeRect()
canvasEle.removeEventListener('mousemove', canvasMoveHandler)
canvasEle.removeEventListener('mouseup', canvasMouseUpHandler)
}
function savaBeforeRect(){
beforeRectArr.push(allRectInfoArr)
}
</script>
</html>
尾声
如果小伙伴觉得我写的不错的话
可以给我点个赞吗?感谢了。
后面会继续写:
如何选中矩形,更改矩形大小。
如何在矩形上添加文字。
如何绘制圆,箭头符号等