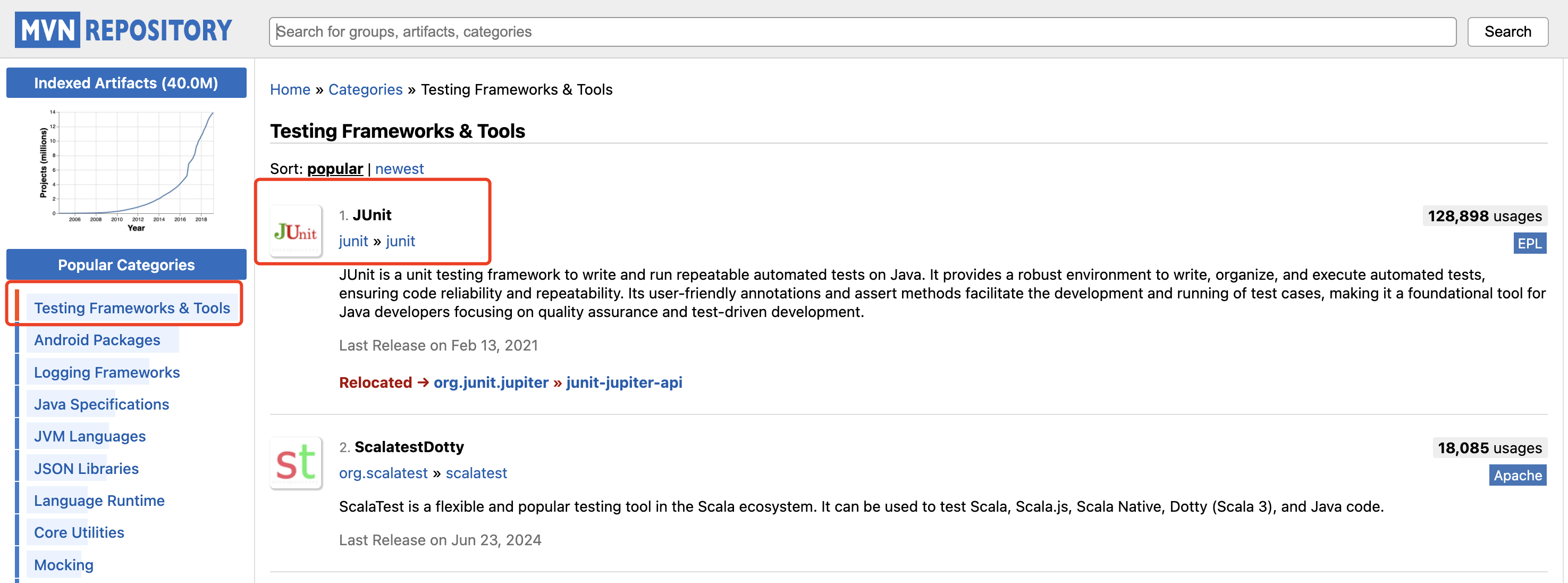
打开 Maven仓库,左边选项栏排在第一的就是测试框架与工具,今天的文章,V 哥要来聊一聊程序员必备的测试框架JUnit 的源码实现,整理的学习笔记,分享给大家。
有人说,不就一个测试框架嘛,有必要去了解它的源码吗?确实,在平时的工作中,我们只要掌握如何使用 JUnit 框架来帮我们测试代码即可,搞什么源码,相信我,只有看了 JUnit 框架的源码,你才会赞叹,真是不愧是一款优秀的框架,它的源码设计思路与技巧,真的值得你好好研读一下,学习优秀框架的实现思想,不就是优秀程序员要干的事情吗。
JUnit 是一个广泛使用的 Java 单元测试框架,其源码实现分析可以帮助开发者更好地理解其工作原理和内部机制,并学习优秀的编码思想。
JUnit 框架的源码实现过程中体现了多种优秀的设计思想和编程技巧,这些不仅使得 JUnit 成为一个强大且灵活的测试框架,也值得程序员在日常开发中学习和借鉴。V 哥通过研读源码后,总结了以下是一些关键点:
面向对象设计
:JUnit 充分运用了面向对象的封装、继承和多态特性。例如,
TestCase
类作为基类提供了共享的测试方法和断言工具,而具体的测试类继承自
TestCase
来实现具体的测试逻辑。
模板方法模式
:JUnit 的
TestCase
类使用了模板方法设计模式,定义了一系列模板方法如
setUp()
、
runTest()
和
tearDown()
,允许子类重写这些方法来插入特定的测试逻辑。
建造者模式
:JUnit 在构造测试套件时使用了建造者模式,允许逐步构建复杂的测试结构。例如,
JUnitCore
类提供了方法来逐步添加测试类和监听器。
策略模式
:JUnit 允许通过不同的
Runner
类来改变测试执行的策略,如
BlockJUnit4ClassRunner
和
Suite
。这种设计使得 JUnit 可以灵活地适应不同的测试需求。
装饰者模式
:在处理测试前置和后置操作时,JUnit 使用了装饰者模式。例如,
@RunWith
注解允许开发者指定一个
Runner
来装饰测试类,从而添加额外的测试行为。
观察者模式
:JUnit 的测试结果监听器使用了观察者模式。多个监听器可以订阅测试事件,如测试开始、测试失败等,从而实现对测试过程的监控和结果的收集。
依赖注入
:JUnit 支持使用注解如
@Mock
和
@InjectMocks
来进行依赖注入,这有助于解耦测试代码,提高测试的可读性和可维护性。
反射机制
:JUnit 广泛使用 Java 反射 API 来动态发现和执行测试方法,这提供了极大的灵活性,允许在运行时动态地构建和执行测试。
异常处理
:JUnit 在执行测试时,对异常进行了精细的处理。它能够区分测试中预期的异常和意外的异常,从而提供更准确的测试结果反馈。
解耦合
:JUnit 的设计注重组件之间的解耦,例如,测试执行器(Runner)、测试监听器(RunListener)和测试结果(Result)之间的职责清晰分离。
可扩展性
:JUnit 提供了丰富的扩展点,如自定义的
Runner
、
TestRule
和
Assertion
方法,允许开发者根据需要扩展框架的功能。
参数化测试
:JUnit 支持参数化测试,允许开发者为单个测试方法提供多种输入参数,这有助于用一个测试方法覆盖多种测试场景。
代码的模块化
:JUnit 的源码结构清晰,模块化的设计使得各个部分之间的依赖关系最小化,便于理解和维护。
通过学习和理解 JUnit 框架的这些设计思想和技巧,程序员可以在自己的项目中实现更高质量的代码和更有效的测试策略。
1. 面向对象设计
JUnit 框架的
TestCase
是一个核心类,它体现了面向对象设计的多个方面。以下是
TestCase
实现过程中的一些关键点,以及源码示例和分析:
- 封装
:
TestCase
类封装了测试用例的所有逻辑和相关数据。它提供了公共的方法来执行测试前的准备 (
setUp
) 和测试后的清理 (
tearDown
),以及其他测试逻辑。
public class TestCase extends Assert implements Test {
// 测试前的准备
protected void setUp() throws Exception {
}
// 测试后的清理
protected void tearDown() throws Exception {
}
// 运行单个测试方法
public void runBare() throws Throwable {
// 调用测试方法
method.invoke(this);
}
}
- 继承
:
TestCase
允许其他测试类继承它。子类可以重写
setUp
和
tearDown
方法来执行特定的初始化和清理任务。这种继承关系使得测试逻辑可以复用,并且可以构建出层次化的测试结构。
public class MyTest extends TestCase {
@Override
protected void setUp() throws Exception {
// 子类特有的初始化逻辑
}
@Override
protected void tearDown() throws Exception {
// 子类特有的清理逻辑
}
// 具体的测试方法
public void testSomething() {
// 使用断言来验证结果
assertTrue("预期为真", someCondition());
}
}
- 多态
:
TestCase
类中的断言方法 (
assertEquals
,
assertTrue
等) 允许以不同的方式使用,这是多态性的体现。开发者可以针对不同的测试场景使用相同的断言方法,但传入不同的参数和消息。
public class Assert {
public static void assertEquals(String message, int expected, int actual) {
// 实现断言逻辑
}
public static void assertTrue(String message, boolean condition) {
// 实现断言逻辑
}
}
- 抽象类
:虽然
TestCase
不是一个抽象类,但它定义了一些抽象概念,如测试方法 (
runBare
),这个方法可以在子类中以不同的方式实现。这种抽象允许
TestCase
类适应不同的测试场景。
public class TestCase {
// 抽象的测试方法执行逻辑
protected void runBare() throws Throwable {
// 默认实现可能包括异常处理和断言调用
}
}
- 接口实现
:
TestCase
实现了
Test
接口,这表明它具有测试用例的基本特征和行为。通过实现接口,
TestCase
保证了所有测试类都遵循相同的规范。
public interface Test {
void run(TestResult result);
}
public class TestCase extends Assert implements Test {
// 实现 Test 接口的 run 方法
public void run(TestResult result) {
// 运行测试逻辑
}
}
我们可以看到
TestCase
类的设计充分利用了面向对象编程的优势,提供了一种灵活且强大的方式来组织和执行单元测试。这种设计不仅使得测试代码易于编写和维护,而且也易于扩展和适应不同的测试需求,你get 到了吗。
2. 模板方法模式
模板方法模式是一种行为设计模式,它在父类中定义了算法的框架,同时允许子类在不改变算法结构的情况下重新定义算法的某些步骤。在 JUnit 中,
TestCase
类就是使用模板方法模式的典型例子。
以下是
TestCase
类使用模板方法模式的实现过程和源码分析:
- 定义算法框架
:
TestCase
类定义了测试方法执行的算法框架。这个框架包括测试前的准备 (
setUp
)、调用实际的测试方法 (
runBare
) 以及测试后的清理 (
tearDown
)。
public abstract class TestCase implements Test {
// 模板方法,定义了测试执行的框架
public void run(TestResult result) {
// 测试前的准备
setUp();
try {
// 调用实际的测试方法
runBare();
} catch (Throwable e) {
// 异常处理,可以被子类覆盖
result.addError(this, e);
} finally {
// 清理资源,确保在任何情况下都执行
tearDown();
}
}
// 测试前的准备,可以被子类覆盖
protected void setUp() throws Exception {
}
// 测试方法的执行,可以被子类覆盖
protected void runBare() throws Throwable {
for (int i = 0; i < fCount; i++) {
runTest();
}
}
// 测试后的清理,可以被子类覆盖
protected void tearDown() throws Exception {
}
// 执行单个测试方法,通常由 runBare 调用
public void runTest() throws Throwable {
// 实际的测试逻辑
}
}
- 允许子类扩展
:
TestCase
类中的
setUp
、
runBare
和
tearDown
方法都是
protected
,这意味着子类可以覆盖这些方法来插入自己的逻辑。
public class MyTestCase extends TestCase {
@Override
protected void setUp() throws Exception {
// 子类的初始化逻辑
}
@Override
protected void runBare() throws Throwable {
// 子类可以自定义测试执行逻辑
super.runBare();
}
@Override
protected void tearDown() throws Exception {
// 子类的清理逻辑
}
// 实际的测试方法
public void testMyMethod() {
// 使用断言来验证结果
assertTrue("测试条件", condition);
}
}
- 执行测试方法
:
runTest
方法是实际执行测试的地方,通常在
runBare
方法中被调用。
TestCase
类维护了一个测试方法数组
fTests
,
runTest
方法会遍历这个数组并执行每个测试方法。
public class TestCase {
// 测试方法数组
protected final Vector tests = new Vector();
// 添加测试方法到数组
public TestCase(String name) {
tests.addElement(name);
}
// 执行单个测试方法
public void runTest() throws Throwable {
// 获取测试方法
Method runMethod = null;
try {
runMethod = this.getClass().getMethod((String) tests.elementAt(testNumber), (Class[]) null);
} catch (NoSuchMethodException e) {
fail("Missing test method: " + tests.elementAt(testNumber));
}
// 调用测试方法
runMethod.invoke(this, (Object[]) null);
}
}
通过模板方法模式,
TestCase
类为所有测试用例提供了一个统一的执行模板,确保了测试的一致性和可维护性。同时,它也允许开发者通过覆盖特定的方法来定制测试的特定步骤,提供了灵活性。这种设计模式在 JUnit 中的成功应用,展示了它在构建大型测试框架中的价值。
3. 建造者模式
在JUnit中,建造者模式主要体现在
JUnitCore
类的使用上,它允许以一种逐步构建的方式运行测试。
JUnitCore
类提供了一系列的静态方法,允许开发者逐步添加测试类和配置选项,最终构建成一个完整的测试运行实例。以下是
JUnitCore
使用建造者模式的实现过程和源码分析:
- 构建测试运行器
:
JUnitCore
类提供了一个运行测试的入口点。通过
main
方法或
run
方法,可以启动测试。
public class JUnitCore {
// 运行测试的main方法
public static void main(String[] args) {
runMain(new JUnitCore(), args);
}
// 运行测试的方法,可以添加测试类和监听器
public Result run(Class<?>... classes) {
return run(Request.classes(Arrays.asList(classes)));
}
// 接受请求对象的方法
public Result run(Request request) {
// 实际的测试运行逻辑
return run(request.getRunner());
}
// 私有方法,执行测试并返回结果
private Result run(Runner runner) {
Result result = new Result();
RunListener listener = result.createListener();
notifier.addFirstListener(listener);
try {
notifier.fireTestRunStarted(runner.getDescription());
runner.run(notifier);
notifier.fireTestRunFinished(result);
} finally {
removeListener(listener);
}
return result;
}
}
- 创建请求对象
:
Request
类是建造者模式中的建造者类,它提供了方法来逐步添加测试类和其他配置。
public class Request {
// 静态方法,用于创建包含测试类的请求
public static Request classes(Class<?>... classes) {
return new Request().classes(Arrays.asList(classes));
}
// 向请求中添加测试类
public Request classes(Collection<Class<?>> classes) {
// 添加测试类逻辑
return this; // 返回自身,支持链式调用
}
// 获取构建好的Runner
public Runner getRunner() {
// 创建并返回Runner逻辑
}
}
- 链式调用
:
Request
类的方法设计支持链式调用,这是建造者模式的一个典型特征。每个方法返回
Request
对象的引用,允许继续添加更多的配置。
// 示例使用
Request request = JUnitCore.request()
.classes(MyTest.class, AnotherTest.class)
// 可以继续添加其他配置
;
Runner runner = request.getRunner();
Result result = new JUnitCore().run(runner);
- 执行测试
:一旦通过
Request
对象构建好了测试配置,就可以通过
JUnitCore
的
run
方法来执行测试,并获取结果。
// 执行测试并获取结果
Result result = JUnitCore.run(request);
靓仔们,我们可以看到
JUnitCore
和
Request
的结合使用体现了建造者模式的精髓。这种模式允许开发者以一种非常灵活和表达性强的方式来构建测试配置,然后再运行它们。建造者模式的使用提高了代码的可读性和可维护性,并且使得扩展新的配置选项变得更加容易。
4. 策略模式
策略模式允许在运行时选择算法的行为,这在JUnit中体现为不同的
Runner
实现。每种
Runner
都定义了执行测试的特定策略,例如,
BlockJUnit4ClassRunner
是JUnit 4的默认
Runner
,而
JUnitCore
允许通过传递不同的
Runner
来改变测试执行的行为。
以下是
Runner
接口和几种实现的源码分析:
- 定义策略接口
:
Runner
接口定义了所有测试运行器必须实现的策略方法。
run
方法接受一个
RunNotifier
参数,它是JUnit中的一个观察者,用于通知测试事件。
public interface Runner {
void run(RunNotifier notifier);
Description getDescription();
}
- 实现具体策略
:JUnit 提供了多种
Runner
实现,每种实现都有其特定的测试执行逻辑。
BlockJUnit4ClassRunner
是JUnit 4 的默认运行器,它使用注解来识别测试方法,并按顺序执行它们。
public class BlockJUnit4ClassRunner extends ParentRunner<TestResult> {
@Override
protected void runChild(FrameworkMethod method, RunNotifier notifier) {
runLeaf(methodBlock(method), description, notifier);
}
protected Statement methodBlock(FrameworkMethod method) {
// 创建一个Statement,可能包含@Before, @After等注解的处理
}
}
Suite
是一个
Runner
实现,它允许将多个测试类组合成一个测试套件。
public class Suite extends ParentRunner<Runner> {
@Override
protected void runChild(Runner runner, RunNotifier notifier) {
runner.run(notifier);
}
}
- 上下文配置
:
JUnitCore
作为上下文,它根据传入的
Runner
执行测试。
public class JUnitCore {
public Result run(Request request) {
Runner runner = request.getRunner();
return run(runner);
}
private Result run(Runner runner) {
Result result = new Result();
RunNotifier notifier = new RunNotifier();
runner.run(notifier);
return result;
}
}
- 使用
@RunWith
注解
:开发者可以使用
@RunWith
注解来指定测试类应该使用的
Runner
。
@RunWith(Suite.class)
public class MyTestSuite {
// 测试类组合
}
- 自定义
Runner
:开发者也可以通过实现自己的
Runner
来改变测试执行的行为。
public class MyCustomRunner extends BlockJUnit4ClassRunner {
public MyCustomRunner(Class<?> klass) throws InitializationError {
super(klass);
}
@Override
protected Statement withBefores(FrameworkMethod method, Object target, Statement statement) {
// 自定义@Before注解的处理
}
}
- 运行自定义
Runner
:
JUnitCore.runClasses(MyCustomRunner.class, MyTest.class);
通过策略模式,JUnit 允许开发者根据不同的测试需求选择不同的执行策略,或者通过自定义
Runner
来扩展测试框架的功能。这种设计提供了高度的灵活性和可扩展性,使得JUnit能够适应各种复杂的测试场景。
5. 装饰者模式
装饰者模式是一种结构型设计模式,它允许用户在不修改对象自身的基础上,向一个对象添加新的功能。在JUnit中,装饰者模式被用于增强测试类的行为,比如通过
@RunWith
注解来指定使用特定的
Runner
类来运行测试。
以下是
@RunWith
注解使用装饰者模式的实现过程和源码分析:
- 定义组件接口
:
Runner
接口是JUnit中所有测试运行器的组件接口,它定义了运行测试的基本方法。
public interface Runner extends Describable {
void run(RunNotifier notifier);
Description getDescription();
}
- 创建具体组件
:
BlockJUnit4ClassRunner
是JUnit中一个具体的
Runner
实现,它提供了执行JUnit 4测试的基本逻辑。
public class BlockJUnit4ClassRunner extends ParentRunner<T> {
protected BlockJUnit4ClassRunner(Class<?> klass) throws InitializationError {
super(klass);
}
// 实现具体的测试执行逻辑
}
- 定义装饰者抽象类
:
ParentRunner
类是一个装饰者抽象类,它提供了装饰
Runner
的基本结构和默认实现。
public abstract class ParentRunner<T> implements Runner {
protected Class<?> fTestClass;
protected Statement classBlock;
public void run(RunNotifier notifier) {
// 装饰并执行测试
}
// 其他公共方法和装饰逻辑
}
- 实现具体装饰者
:通过
@RunWith
注解,JUnit允许开发者指定一个装饰者
Runner
来增强测试类的行为。例如,
Suite
类是一个装饰者,它可以运行多个测试类。
@RunWith(Suite.class)
@Suite.SuiteClasses({Test1.class, Test2.class})
public class AllTests {
// 这个类使用SuiteRunner来运行包含的测试类
}
- 使用
@RunWith
注解
:开发者通过在测试类上使用
@RunWith
注解来指定一个装饰者
Runner
。
@RunWith(CustomRunner.class)
public class MyTest {
// 这个测试类将使用CustomRunner来运行
}
- 自定义
Runner
:开发者可以实现自己的
Runner
来提供额外的功能,如下所示:
public class CustomRunner extends BlockJUnit4ClassRunner {
public CustomRunner(Class<?> klass) throws InitializationError {
super(klass);
}
@Override
protected Statement withBefores(FrameworkMethod method, Object target, Statement statement) {
// 添加@Before注解的处理
return super.withBefores(method, target, statement);
}
@Override
protected Statement withAfters(FrameworkMethod method, Object target, Statement statement) {
// 添加@After注解的处理
return super.withAfters(method, target, statement);
}
}
- 运行时创建装饰者
:在JUnit的运行时,根据
@RunWith
注解的值,使用反射来实例化对应的
Runner
装饰者。
public static Runner getRunner(Class<?> testClass) throws InitializationError {
RunWith runWith = testClass.getAnnotation(RunWith.class);
if (runWith == null) {
return new BlockJUnit4ClassRunner(testClass);
} else {
try {
// 使用反射创建指定的Runner装饰者
return (Runner) runWith.value().getConstructor(Class.class).newInstance(testClass);
} catch (Exception e) {
throw new InitializationError("Couldn't create runner for class " + testClass, e);
}
}
}
通过使用装饰者模式,JUnit 允许开发者通过
@RunWith
注解来灵活地为测试类添加额外的行为,而无需修改测试类本身。这种设计提高了代码的可扩展性和可维护性,同时也允许开发者通过自定义
Runner
来实现复杂的测试逻辑。
6. 观察者模式
观察者模式是一种行为设计模式,它定义了对象之间的一对多依赖关系,当一个对象状态发生改变时,所有依赖于它的对象都会得到通知并自动更新。在JUnit中,观察者模式主要应用于测试结果监听器,以通知测试过程中的各个事件,如测试开始、测试失败、测试完成等。
以下是JUnit中观察者模式的实现过程和源码分析:
- 定义观察者接口
:
TestListener
接口定义了测试过程中需要通知的事件的方法。
public interface TestListener {
void testAborted(Test test, Throwable t);
void testAssumptionFailed(Test test, AssumptionViolatedException e);
void testFailed(Test test, AssertionFailedError e);
void testFinished(Test test);
void testIgnored(Test test);
void testStarted(Test test);
}
- 创建主题
:
RunNotifier
类作为主题,维护了一组观察者列表,并提供了添加、移除观察者以及通知观察者的方法。
public class RunNotifier {
private final List<TestListener> listeners = new ArrayList<TestListener>();
public void addListener(TestListener listener) {
listeners.add(listener);
}
public void removeListener(TestListener listener) {
listeners.remove(listener);
}
protected void fireTestRunStarted(Description description) {
for (TestListener listener : listeners) {
listener.testStarted(null);
}
}
// 其他类似fireTestXXXStarted/Finished等方法
}
- 实现具体观察者
:具体的测试结果监听器实现
TestListener
接口,根据测试事件执行相应的逻辑。
public class MyTestListener implements TestListener {
@Override
public void testStarted(Test test) {
// 测试开始时的逻辑
}
@Override
public void testFinished(Test test) {
// 测试结束时的逻辑
}
// 实现其他TestListener方法
}
- 注册观察者
:在测试运行前,通过
RunNotifier
将具体的监听器添加到观察者列表中。
RunNotifier notifier = new RunNotifier();
notifier.addListener(new MyTestListener());
- 通知观察者
:在测试执行过程中,
RunNotifier
会调用相应的方法来通知所有注册的观察者关于测试事件的信息。
protected void run(Runner runner) {
// ...
runner.run(notifier);
// ...
}
- 使用
JUnitCore
运行测试
:
JUnitCore
类使用
RunNotifier
来运行测试,并通知注册的监听器。
public class JUnitCore {
public Result run(Request request) {
Runner runner = request.getRunner();
return run(runner);
}
private Result run(Runner runner) {
Result result = new Result();
RunNotifier notifier = new RunNotifier();
notifier.addListener(result.createListener());
runner.run(notifier);
return result;
}
}
- 结果监听器
:
Result
类本身也是一个观察者,它实现了
TestListener
接口,用于收集测试结果。
public class Result implements TestListener {
public void testRunStarted(Description description) {
// 测试运行开始时的逻辑
}
public void testRunFinished(long elapsedTime) {
// 测试运行结束时的逻辑
}
// 实现其他TestListener方法
}
通过观察者模式,JUnit 允许开发者自定义测试结果监听器,以获取测试过程中的各种事件通知。这种模式提高了测试框架的灵活性和可扩展性,使得开发者可以根据自己的需求来监控和响应测试事件。
7. 依赖注入
依赖注入是一种常见的设计模式,它允许将组件的依赖关系从组件本身中解耦出来,通常通过构造函数、工厂方法或 setter 方法注入。在 JUnit 中,依赖注入主要用于测试领域,特别是与 Mockito 这样的模拟框架结合使用时,可以方便地注入模拟对象。
以下是
@Mock
和
@InjectMocks
注解使用依赖注入的实现过程和源码分析:
Mockito 依赖注入注解
:
@Mock
注解用于创建模拟对象。
@InjectMocks
注解用于将模拟对象注入到测试类中。
使用
@Mock
创建模拟对象
:
- 在测试类中,使用
@Mock
注解的字段将自动被 Mockito 框架在测试执行前初始化为模拟对象。
public class MyTest {
@Mock
private Collaborator mockCollaborator;
// 其他测试方法...
}
- 使用
@InjectMocks
进行依赖注入
:
- 当测试类中的对象需要依赖其他模拟对象时,使用
@InjectMocks
注解可以自动注入这些模拟对象。
@RunWith(MockitoJUnitRunner.class)
public class MyTest {
@Mock
private Collaborator mockCollaborator;
@InjectMocks
private MyClass testClass;
// 测试方法...
}
MockitoJUnitRunner
:
@RunWith(MockitoJUnitRunner.class)
指定了使用 Mockito 的测试运行器,它负责设置测试环境,包括初始化模拟对象和注入依赖。
Mockito 框架初始化过程
:
- 在测试运行前,Mockito 框架会查找所有使用
@Mock
注解的字段,并创建相应的模拟对象。
- 接着,对于使用
@InjectMocks
注解的字段,Mockito 会进行反射检查其构造函数和成员变量,使用创建的模拟对象进行依赖注入。
Mockito 注解处理器
:
- Mockito 框架内部使用注解处理器来处理
@Mock
和
@InjectMocks
注解。这些处理器在测试执行前初始化模拟对象,并在必要时注入它们。
public class MockitoAnnotations {
public static void initMocks(Object testClass) {
// 查找并初始化 @Mock 注解的字段
for (Field field : Reflections.fieldsAnnotatedWith(testClass.getClass(), Mock.class)) {
field.setAccessible(true);
try {
field.set(testClass, MockUtil.createMock(field.getType()));
} catch (IllegalAccessException e) {
throw new RuntimeException("Unable to inject @Mock for " + field, e);
}
}
// 查找并处理 @InjectMocks 注解的字段
for (Field field : Reflections.fieldsAnnotatedWith(testClass.getClass(), InjectMocks.class)) {
// 注入逻辑...
}
}
}
测试方法执行
:
- 在测试方法执行期间,如果测试类中的实例调用了被
@Mock
注解的对象的方法,实际上是调用了模拟对象的方法,可以进行行为验证或返回预设的值。
Mockito 模拟行为
:
- 开发者可以使用 Mockito 提供的 API 来定义模拟对象的行为,例如使用
when().thenReturn()
或
doThrow()
等方法。
when(mockCollaborator.someMethod()).thenReturn("expected value");
通过依赖注入,JUnit 和 Mockito 的结合使用极大地简化了测试过程中的依赖管理,使得测试代码更加简洁和专注于测试逻辑本身。同时,这也提高了测试的可读性和可维护性。
8. 反射机制
在JUnit中,反射机制是实现动态测试发现和执行的关键技术之一。反射允许在运行时检查类的信息、创建对象、调用方法和访问字段,这使得JUnit能够在不直接引用测试方法的情况下执行它们。以下是使用Java反射API来动态发现和执行测试方法的实现过程和源码分析:
- 获取类对象
:首先,使用
Class.forName()
方法获取测试类的
Class
对象。
Class<?> testClass = Class.forName("com.example.MyTest");
- 获取测试方法列表
:通过
Class
对象,使用Java反射API获取类中所有声明的方法。
Method[] methods = testClass.getDeclaredMethods();
- 筛选测试方法
:遍历方法列表,筛选出标记为测试方法的
Method
对象。在JUnit中,这通常是通过
@Test
注解来标识的。
List<FrameworkMethod> testMethods = new ArrayList<>();
for (Method method : methods) {
if (method.isAnnotationPresent(Test.class)) {
testMethods.add(new FrameworkMethod(method));
}
}
- 创建测试方法的封装对象
:JUnit使用
FrameworkMethod
类来封装
Method
对象,提供额外的功能,如处理
@Before
、
@After
注解。
public class FrameworkMethod {
private final Method method;
public FrameworkMethod(Method method) {
this.method = method;
}
public Object invokeExplosively(Object target, Object... params) throws Throwable {
try {
return method.invoke(target, params);
} catch (IllegalAccessException | InvocationTargetException e) {
throw new Exception("Failed to invoke " + method, e.getCause());
}
}
}
- 调用测试方法
:使用
FrameworkMethod
的
invokeExplosively()
方法,在指定的测试实例上调用测试方法。
public class BlockJUnit4ClassRunner extends ParentRunner<MyClass> {
@Override
protected void runChild(FrameworkMethod method, RunNotifier notifier) {
runLeaf(new Statement() {
@Override
public void evaluate() throws Throwable {
Object target = new MyClass();
method.invokeExplosively(target);
}
}, methodBlock(method), notifier);
}
}
处理测试方法的执行
:在
invokeExplosively()
方法中,使用
Method
对象的
invoke()
方法来执行测试方法。这个方法能够处理方法的访问权限,并调用实际的测试逻辑。
异常处理
:在执行测试方法时,可能会抛出异常。JUnit需要捕获这些异常,并适当地处理它们,例如将测试失败通知给
RunNotifier
。
整合到测试运行器
:将上述过程整合到JUnit的测试运行器中,如
BlockJUnit4ClassRunner
,它负责创建测试实例、调用测试方法,并处理测试结果。
通过使用Java反射API,JUnit能够以一种非常灵活和动态的方式来执行测试方法。这种机制不仅提高了JUnit框架的通用性和可扩展性,而且允许开发者在不修改测试类代码的情况下,通过配置和注解来控制测试的行为。反射机制是JUnit强大功能的一个重要支柱。
9. 异常处理
在JUnit中,异常处理是一个精细的过程,确保了测试执行的稳定性和结果的准确性。JUnit区分了预期的异常(如测试中显式检查的异常)和未预期的异常(如错误或未捕获的异常),并相应地报告这些异常。以下是JUnit中异常处理的实现过程和源码分析:
- 测试方法执行
:在测试方法执行时,JUnit会捕获所有抛出的异常。
public void runBare() throws Throwable {
Throwable exception = null;
try {
method.invoke(target);
} catch (InvocationTargetException e) {
exception = e.getCause();
} catch (IllegalAccessException e) {
exception = e;
} catch (IllegalArgumentException e) {
exception = e;
} catch (SecurityException e) {
exception = e;
}
if (exception != null) {
runAfters();
throw exception;
}
}
- 预期异常的处理
:使用
@Test(expected = Exception.class)
注解可以指定测试方法预期抛出的异常类型。如果实际抛出的异常与预期不符,JUnit会报告测试失败。
@Test(expected = SpecificException.class)
public void testMethod() {
// 测试逻辑,预期抛出 SpecificException
}
- 断言异常
:
Assert
类提供了
assertThrows
方法,允许在测试中显式检查方法是否抛出了预期的异常。
public static <T extends Throwable> T assertThrows(
Class<T> expectedThrowable, Executable executable, String message) {
try {
executable.execute();
fail(message);
} catch (Throwable actualException) {
if (!expectedThrowable.isInstance(actualException)) {
throw new AssertionFailedError(
"Expected " + expectedThrowable.getName() + " but got " + actualException.getClass().getName());
}
@SuppressWarnings("unchecked")
T result = (T) actualException;
return result;
}
}
异常的分类
:JUnit将异常分为两种类型:
AssertionError
和
Throwable
。
AssertionError
通常表示测试失败,而
Throwable
可能表示测试中的严重错误。
异常的报告
:在捕获异常后,JUnit会将异常信息报告给
RunNotifier
,以便进行适当的处理。
protected void runChild(FrameworkMethod method, RunNotifier notifier) {
runLeaf(new Statement() {
@Override
public void evaluate() throws Throwable {
try {
method.invokeExplosively(testInstance);
} catch (Throwable e) {
notifier.fireTestFailure(new Failure(method, e));
}
}
}, describeChild(method), notifier);
}
- 异常的监听
:
RunNotifier
监听器可以捕获并处理测试过程中抛出的异常,例如记录失败或向用户报告错误。
public void addListener(TestListener listener) {
listeners.add(listener);
}
// 在测试执行过程中调用
notifier.fireTestFailure(new Failure(method, e));
自定义异常处理
:开发者可以通过实现自定义的
TestListener
来捕获和处理测试过程中的异常。
异常的传播
:在某些情况下,JUnit允许异常向上传播,使得测试框架或IDE能够捕获并显示给用户。
通过精细的异常处理,JUnit确保了测试的准确性和可靠性,同时提供了灵活的错误报告机制。这使得开发者能够快速定位和解决问题,提高了开发和测试的效率。
10. 解耦合
在JUnit中,解耦合是通过将测试执行的不同方面分离成独立的组件来实现的,从而提高了代码的可维护性和可扩展性。以下是解耦合实现过程的详细分析:
- 测试执行器(Runner)
:
Runner
接口定义了执行测试的方法,每个具体的
Runner
实现负责运行测试用例的逻辑。
public interface Runner {
void run(RunNotifier notifier);
Description getDescription();
}
- 测试监听器(RunListener)
:
RunListener
接口定义了测试过程中的事件回调方法,用于监听测试的开始、成功、失败和结束等事件。
public interface RunListener {
void testRunStarted(Description description);
void testRunFinished(Result result);
void testStarted(Description description);
void testFinished(Description description);
// 其他事件回调...
}
- 测试结果(Result)
:
Result
类实现了
RunListener
接口,用于收集和存储测试执行的结果。
public class Result implements RunListener {
private List<Failure> failures = new ArrayList<>();
@Override
public void testRunFinished(Result result) {
// 收集测试运行结果
}
@Override
public void testFailure(Failure failure) {
// 收集测试失败信息
failures.add(failure);
}
// 其他RunListener方法实现...
}
职责分离
:
Runner
负责执行测试逻辑,
RunListener
负责监听测试事件,而
Result
负责收集测试结果。这三者通过接口和回调机制相互协作,但各自独立实现。
使用
RunNotifier
协调
:
RunNotifier
类作为协调者,维护了
RunListener
的注册和事件分发。
public class RunNotifier {
private final List<RunListener> listeners = new ArrayList<>();
public void addListener(RunListener listener) {
listeners.add(listener);
}
public void fireTestRunStarted(Description description) {
for (RunListener listener : listeners) {
listener.testRunStarted(description);
}
}
// 其他事件分发方法...
}
- 测试执行流程
:在测试执行时,
Runner
会创建一个
RunNotifier
实例,然后执行测试,并在适当的时候调用
RunNotifier
的事件分发方法。
public class BlockJUnit4ClassRunner extends ParentRunner {
@Override
protected void runChild(FrameworkMethod method, RunNotifier notifier) {
RunBefores runBefores = new RunBefores(noTestsYet, method, null);
Statement statement = new RunAfters(runBefores, method, null);
statement.evaluate();
}
@Override
public void run(RunNotifier notifier) {
// 初始化测试运行
Description description = getDescription();
notifier.fireTestRunStarted(description);
try {
// 执行测试
runChildren(makeTestRunNotifier(notifier, description));
} finally {
// 测试运行结束
notifier.fireTestRunFinished(result);
}
}
}
结果收集和报告
:测试完成后,
Result
对象会包含所有测试的结果,可以被用来生成测试报告或进行其他后续处理。
解耦合的优势
:通过将测试执行、监听和结果收集分离,JUnit允许开发者自定义测试执行流程(通过自定义
Runner
)、添加自定义监听器(通过实现
RunListener
接口)以及处理测试结果(通过操作
Result
对象)。
这种解耦合的设计使得JUnit非常灵活,易于扩展,同时也使得测试代码更加清晰和易于理解。开发者可以根据需要替换或扩展框架的任何部分,而不影响其他部分的功能。
11. 可扩展性
JUnit的可扩展性体现在多个方面,包括自定义
Runner
、
TestRule
和断言(Assertion)方法。以下是这些可扩展性点的实现过程和源码分析:
自定义 Runner
自定义
Runner
允许开发者定义自己的测试运行逻辑。以下是创建自定义
Runner
的步骤:
- 实现Runner接口
:创建一个类实现
Runner
接口,并实现
run
方法和
getDescription
方法。
public class CustomRunner extends Runner {
private final Class<?> testClass;
public CustomRunner(Class<?> testClass) throws InitializationError {
this.testClass = testClass;
}
@Override
public Description getDescription() {
// 返回测试描述
}
@Override
public void run(RunNotifier notifier) {
// 自定义测试运行逻辑
}
}
- 使用@RunWith注解
:在测试类上使用
@RunWith
注解来指定使用自定义的
Runner
。
@RunWith(CustomRunner.class)
public class MyTests {
// 测试方法...
}
自定义 TestRule
TestRule
接口允许开发者插入测试方法执行前后的逻辑。以下是创建自定义
TestRule
的步骤:
- 实现TestRule接口
:创建一个类实现
TestRule
接口。
public class CustomTestRule implements TestRule {
@Override
public Statement apply(Statement base, FrameworkMethod method, Object target) {
// 返回一个Statement,包装原始的测试逻辑
}
}
- 使用@Rule注解
:在测试类或方法上使用
@Rule
注解来指定使用自定义的
TestRule
。
public class MyTests {
@Rule
public CustomTestRule customTestRule = new CustomTestRule();
// 测试方法...
}
自定义 Assertion 方法
JUnit提供了一个
Assert
类,包含许多断言方法。开发者也可以添加自己的断言方法:
- 扩展Assert类
:创建一个工具类,添加自定义的静态方法。
public class CustomAssertions {
public static void assertEquals(String message, int expected, int actual) {
if (expected != actual) {
throw new AssertionFailedError(message);
}
}
}
- 使用自定义断言
:在测试方法中调用自定义的断言方法。
public void testCustomAssertion() {
CustomAssertions.assertEquals("Values should be equal", 1, 2);
}
源码分析
以下是使用自定义
Runner
、
TestRule
和断言方法的示例:
// 自定义Runner
public class CustomRunner extends Runner {
public CustomRunner(Class<?> klass) throws InitializationError {
// 初始化逻辑
}
@Override
public Description getDescription() {
// 返回测试的描述信息
}
@Override
public void run(RunNotifier notifier) {
// 自定义测试执行逻辑,包括调用测试方法和处理测试结果
}
}
// 自定义TestRule
public class CustomTestRule implements TestRule {
@Override
public Statement apply(Statement base, FrameworkMethod method, Object target) {
// 包装原始的测试逻辑,可以在测试前后执行额外的操作
return new Statement() {
@Override
public void evaluate() throws Throwable {
// 测试前的逻辑
base.evaluate();
// 测试后的逻辑
}
};
}
}
// 使用自定义Runner和TestRule的测试类
@RunWith(CustomRunner.class)
public class MyTests {
@Rule
public CustomTestRule customTestRule = new CustomTestRule();
@Test
public void myTest() {
// 测试逻辑,使用自定义断言
CustomAssertions.assertEquals("Expected and actual values should match", 1, 1);
}
}
通过这些自定义扩展,JUnit允许开发者根据特定需求调整测试行为,增强测试框架的功能,实现高度定制化的测试流程。这种可扩展性是JUnit强大适应性的关键因素之一。
12. 参数化测试
参数化测试是JUnit提供的一项功能,它允许为单个测试方法提供多种输入参数,从而用一个测试方法覆盖多种测试场景。以下是参数化测试的实现过程和源码分析:
- 使用
@Parameterized
注解
:首先,在测试类上使用
@RunWith(Parameterized.class)
来指定使用参数化测试的
Runner
。
@RunWith(Parameterized.class)
public class MyParameterizedTests {
// 测试方法的参数
private final int input;
private final int expectedResult;
// 构造函数,用于接收参数
public MyParameterizedTests(int input, int expectedResult) {
this.input = input;
this.expectedResult = expectedResult;
}
// 测试方法
@Test
public void testWithParameters() {
// 使用参数进行测试
assertEquals(expectedResult, someMethod(input));
}
// 获取参数来源
@Parameters
public static Collection<Object[]> data() {
return Arrays.asList(new Object[][] {
{ 1, 2 },
{ 2, 4 },
{ 3, 6 }
});
}
}
- 定义测试参数
:使用
@Parameters
注解的方法来定义测试参数。这个方法需要返回一个
Collection
,其中包含参数数组的列表。
@Parameters
public static Collection<Object[]> parameters() {
return Arrays.asList(new Object[][] {
// 参数列表
});
}
- 构造函数注入
:参数化测试框架会通过构造函数将参数注入到测试实例中。
public MyParameterizedTests(int param1, String param2) {
// 使用参数初始化测试用例
}
参数化测试的执行
:JUnit框架会为
@Parameters
方法中定义的每一组参数创建测试类的实例,并执行测试方法。
自定义参数源
:除了使用
@Parameters
注解的方法外,还可以使用
Parameterized.ParametersRunnerFactory
注解来指定自定义的参数源。
@RunWith(value = Parameterized.class, runnerFactory = MyParametersRunnerFactory.class)
public class MyParameterizedTests {
// 测试方法和参数...
}
public class MyParametersRunnerFactory implements ParametersRunnerFactory {
@Override
public Runner createRunnerForTestWithParameters(TestWithParameters test) {
// 返回自定义的参数化运行器
}
}
- 使用
Arguments
辅助类
:在JUnit 4.12中,可以使用
Arguments
类来简化参数的创建。
@Parameters
public static Collection<Object[]> data() {
return Arrays.asList(
Arguments.arguments(1, 2),
Arguments.arguments(2, 4),
Arguments.arguments(3, 6)
);
}
- 源码分析
:
Parameterized
类是实现参数化测试的核心。它使用
ParametersRunnerFactory
来创建
Runner
,然后为每组参数执行测试方法。
public class Parameterized {
public static class ParametersRunnerFactory implements RunnerFactory {
@Override
public Runner create(Description description) {
return new BlockJUnit4ClassRunner(description.getTestClass()) {
@Override
protected List<Runner> getChildren() {
// 获取参数并为每组参数创建Runner
}
};
}
}
// 其他实现...
}
通过参数化测试,JUnit允许开发者编写更灵活、更全面的测试用例,同时保持测试代码的简洁性。这种方法特别适合于需要多种输入组合来验证逻辑正确性的场景。
13. 代码的模块化
代码的模块化是软件设计中的一种重要实践,它将程序分解为独立的、可重用的模块,每个模块负责一部分特定的功能。在JUnit框架中,模块化设计体现在其清晰的包结构和类的设计上。以下是JUnit中模块化实现的过程和源码分析:
- 包结构
:JUnit的源码按照功能划分为不同的包(packages),每个包包含一组相关的类。
// 核心包,包含JUnit的基础类和接口
org.junit
// 断言包,提供断言方法
org.junit.Assert
// 运行器包,负责测试套件的运行和管理
org.junit.runner
// 规则包,提供测试规则,如测试隔离和初始化
org.junit.rules
- 接口定义
:JUnit使用接口(如
Test
、
Runner
、
TestRule
)定义模块的契约,确保模块间的松耦合。
public interface Test {
void run(TestResult result);
}
public interface Runner {
void run(RunNotifier notifier);
Description getDescription();
}
- 抽象类
:使用抽象类(如
Assert
、
Runner
、
TestWatcher
)为模块提供共享的实现,同时保留扩展的灵活性。
public abstract class Assert {
// 断言方法的默认实现
}
public abstract class Runner implements Describable {
// 测试运行器的默认实现
}
- 具体实现
:为每个抽象类或接口提供具体的实现,这些实现类可以在不同的测试场景中重用。
public class TestCase extends Assert implements Test {
// 测试用例的具体实现
}
public class BlockJUnit4ClassRunner extends ParentRunner {
// 测试类的运行器实现
}
依赖倒置
:通过依赖接口而非具体实现,JUnit的模块可以在不修改其他模块的情况下进行扩展或替换。
服务提供者接口(SPI)
:JUnit使用服务提供者接口来发现和加载扩展模块,如测试规则(
TestRule
)。
public interface TestRule {
Statement apply(Statement base, Description description);
}
- 模块化测试执行
:JUnit允许开发者通过
@RunWith
注解指定自定义的
Runner
,这允许对测试执行过程进行模块化定制。
@RunWith(CustomRunner.class)
public class MyTests {
// ...
}
- 参数化测试模块
:参数化测试通过
@Parameters
注解和
Parameterized
类实现模块化,允许为测试方法提供不同的输入参数集。
@RunWith(Parameterized.class)
public class MyParameterizedTests {
@Parameters
public static Collection<Object[]> data() {
// 提供参数集
}
}
- 解耦的事件监听
:
RunNotifier
和
RunListener
接口的使用使得测试事件的监听和处理可以独立于测试执行逻辑。
public class RunNotifier {
public void addListener(RunListener listener);
// ...
}
- 测试结果的模块化处理
:
Result
类实现了
RunListener
接口,负责收集和报告测试结果,与测试执行逻辑解耦。
通过这种模块化设计,JUnit提供了一个灵活、可扩展的测试框架,允许开发者根据自己的需求添加自定义的行为和扩展功能。这种设计不仅提高了代码的可维护性,也方便了重用和测试过程的定制。
最后
以上就是V哥在 JUnit 框架源码学习时总结的13个非常值得学习的点,希望也可以帮助到你提升编码的功力,欢迎关注威哥爱编程,一起学习框架源码,提升编程技巧,我是 V哥,爱 编程,一辈子。