.NET 8 + Blazor 多租户、模块化、DDD框架、开箱即用
前言
基于 .NET 8 的开源项目,主要使用 WebAPI + Blazor 支持多租户和模块化设计,DDD构建。可以帮助我们轻松地搭建起一个功能完善的Web应用程序。除了帮助你快速构建应用程序之外,项目也可以当做学习资料。我们可以从中了解到多租户、CQRS、DDD架构、云部署、Docker容器化等等前沿技术。
项目简介
dotnet-starter-kit
是一个基于 .NET 8 的开源项目,它采用了Clean Architecture原则,支持多租户和模块化设计。此项目是一个开箱即用的解决方案,非常适合快速开发Web应用程序。
数据库支持
- PostgreSQL
- MySQL
- MSSQL
- Oracle
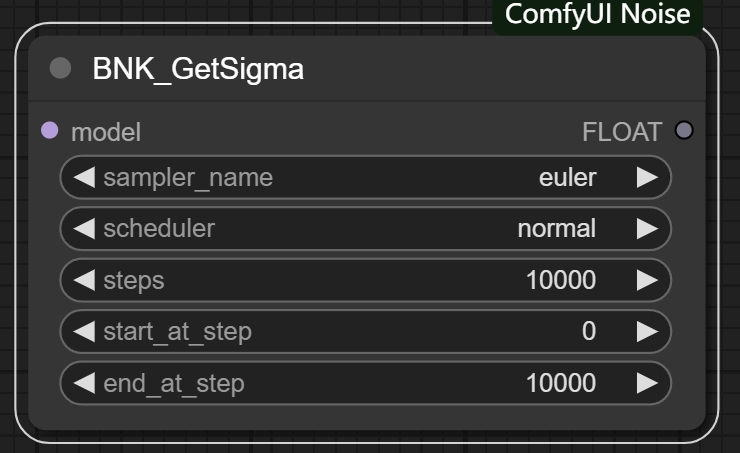
项目技术栈
多租户架构
CQRS (Command Query Responsibility Segregation)
DDD架构
清洁编码标准
Terraform到AWS的云部署
Docker概念
CI/CD管道和工作流
ASP.NET Core 8
Entity Framework Core 8
Blazor
MediatR (用于CQRS模式)
PostgreSQL (数据库)
Redis (缓存)
FluentValidation (数据验证)
运行与部署
1、下载项目
git clone https://github.com/fullstackhero/dotnet-starter-kit.git
2、打开项目
使用Visual Studio打开
./src/FSH.Starter.sln
文件。
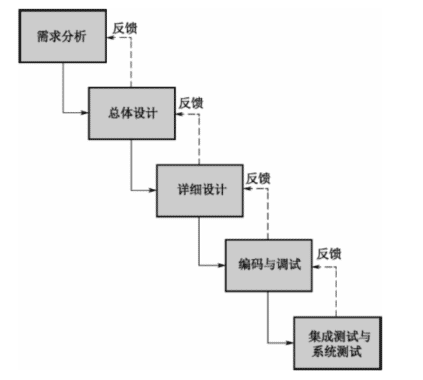
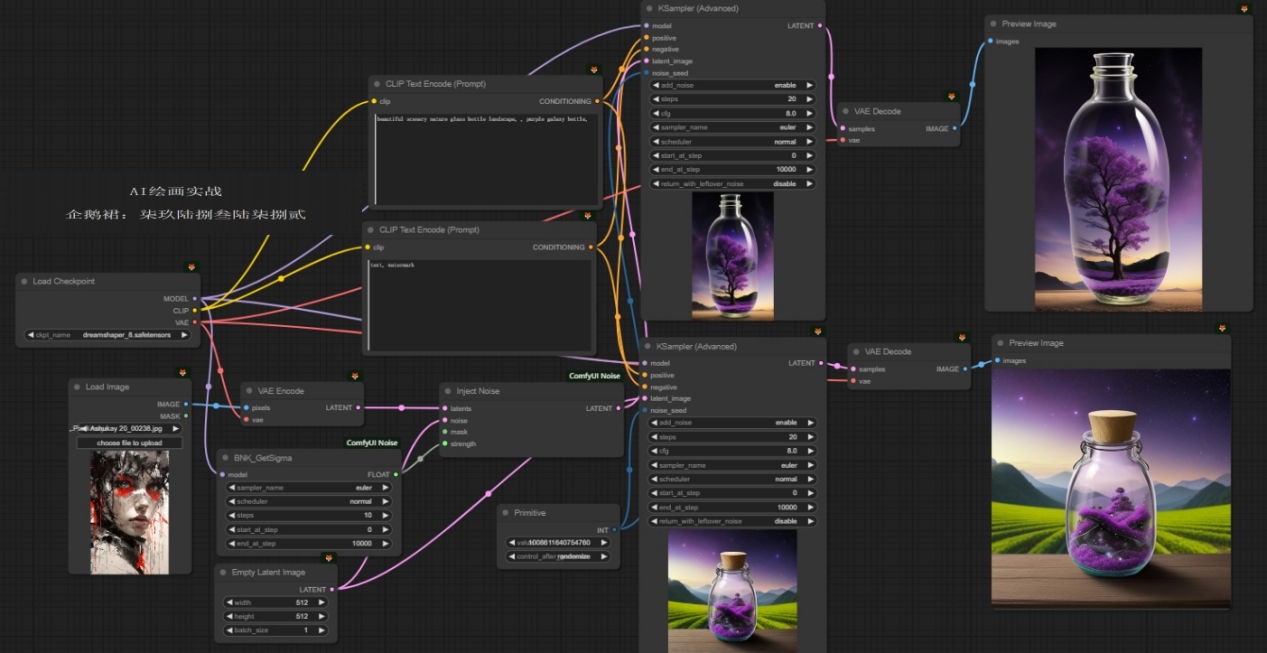
项目结构如下图所示:

3、项目结构
启动
FSH.Starter
解决方案,它包含以下三个项目:
- Aspire Dashboard(默认项目)
- Web API
- Blazor
4、修改连接字符串
在
./src/api/server/appsettings.Development.json
文件中修改
DatabaseOptions
的
ConnectionString
字符串连接。
5、启动项目
分别启动项目:
- Aspire Dashboard: 默认启动,访问地址
https://localhost:7200/ - Web API: 访问地址
https://localhost:7000/swagger/index.html - Blazor: 访问地址
https://localhost:7100/
6、部署
- Docker
: 项目支持Docker,方便容器化部署。 - AWS
: 项目提供了部署到 AWS 的指南。
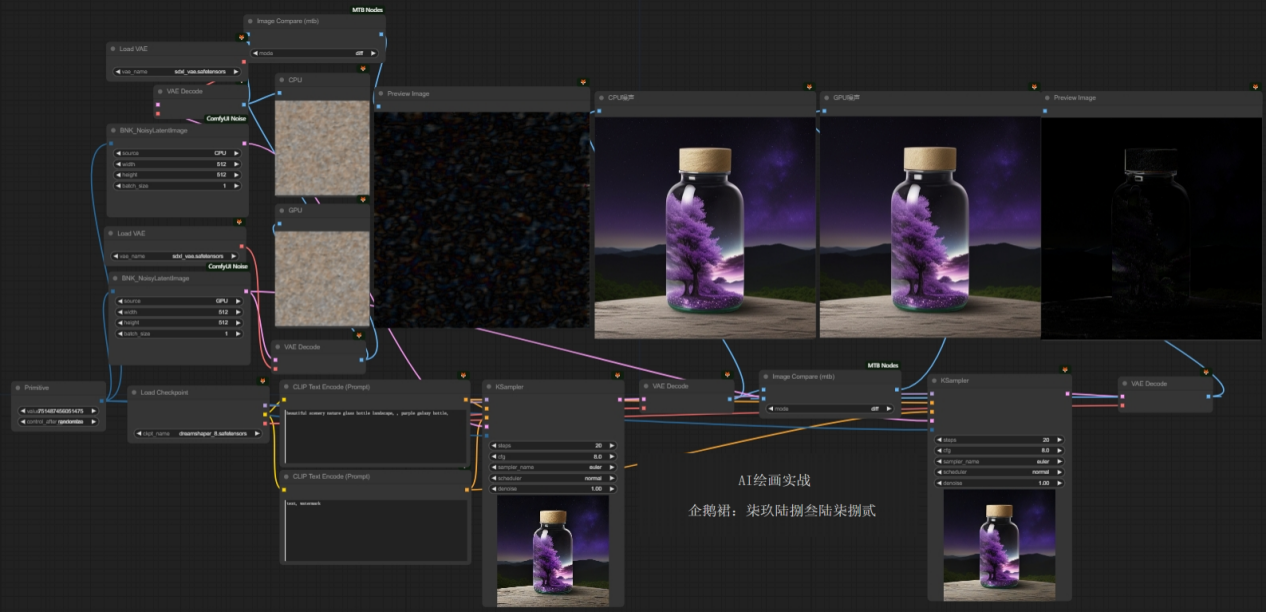
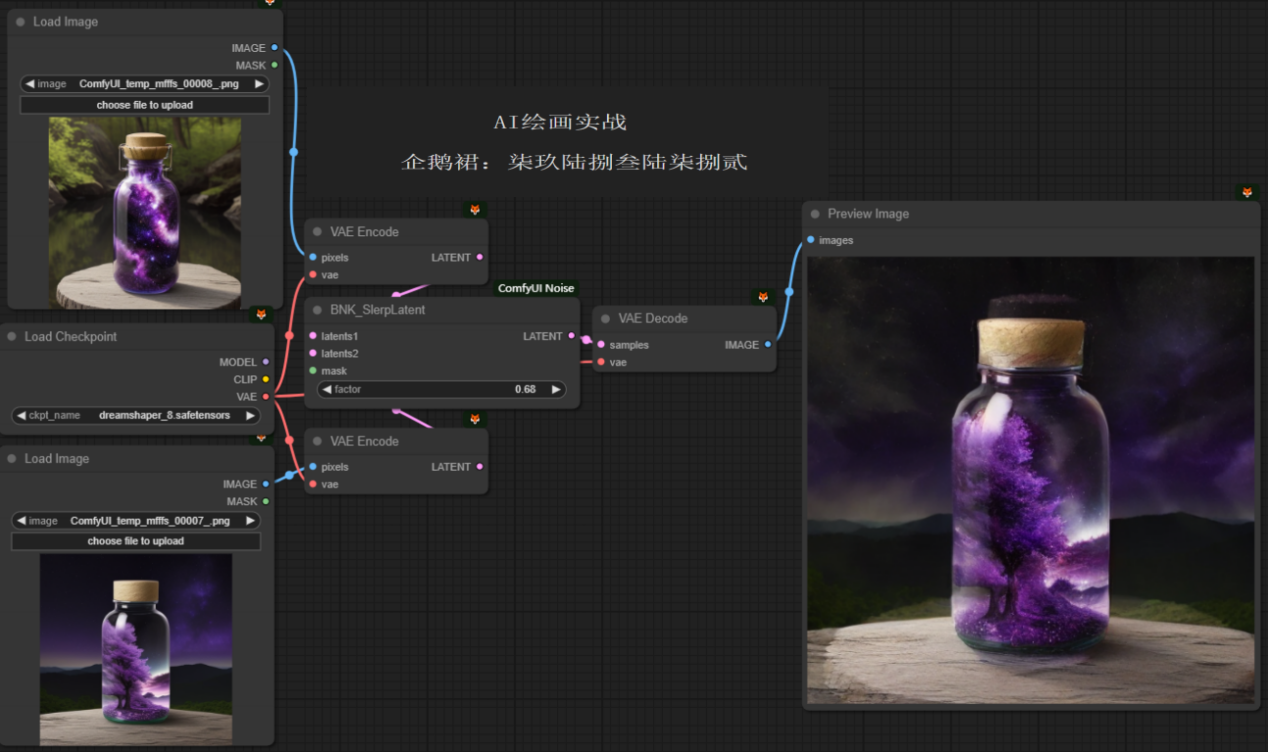
项目展示


项目地址
- Github
https://github.com/fullstackhero/dotnet-starter-kit.git - Gitee
https://gitee.com/xie-bing/dotnet-starter-kit
在线文档
https://fullstackhero.net/

最后
如果你觉得这篇文章对你有帮助,不妨点个赞支持一下!你的支持是我继续分享知识的动力。如果有任何疑问或需要进一步的帮助,欢迎随时留言。
也可以加入微信公众号
[DotNet技术匠]
社区,与其他热爱技术的同行一起交流心得,共同成长!