面向对象的编码设计原则
之前谈DDD时提及过当下很多标榜面向对象的语言,却是以面向过程来实现的问题。这里就从编码设计的角度来顺一下面向对象设计的一些思维。其实就像我正在梳理的设计模式一样,都是些老生常谈的东西,可是往往在实践的时候,这些老生常谈的东西会被“反刍”,总会有种常看常新的感觉。
面向对象思想
其实想要进行DDD实践,不可避免地就要进行OOA和OOD,这里主要是对OOD的一些设计准则和思想进行梳理。
抽象
面向对象的核心技术就是抽象,相比于面向过程基于数据结构进行步骤式命令开发的思维,面向对象则是以人的思维模式去进行思考,其中,对事物共性、本质的提取就是抽象。
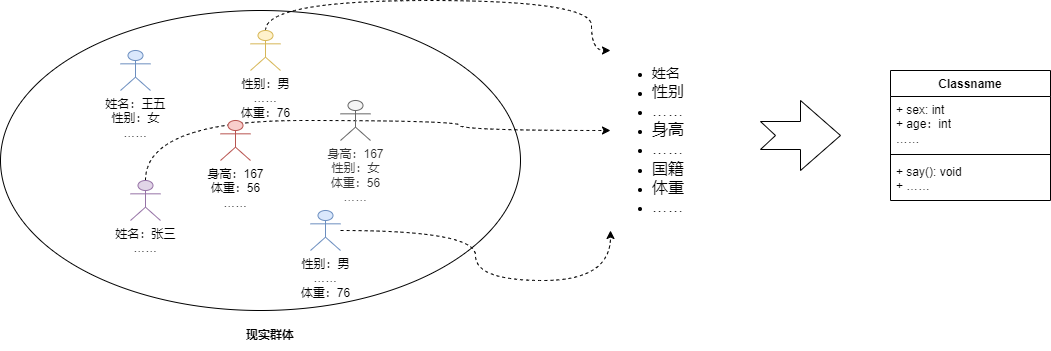
打个比方,人作为现实生活中的一个实体,我们可以很直观的看到,人都会有性别、年龄、身高、体重等等的一些公共属性,除此之外,人还会使用语言沟通,会吃饭,会开车等一系列的行为,于是,我们进行总结,人是一种具有性别、年龄、体重……且会说话、睡觉…的物类,而这个总结,几乎适用于所有的人,于是,人类的概念被概括出来。通过这个过程就会发现,我们的思考过程是,先有了一个模糊的物类,然后在该物类中提取公共的部分进行整和,最后整个模糊的物类就具象化了,整个过程就是归纳、总结。这就是抽象。
对应到编程中,OOP需要对我们程序、业务中的一些主体进行特征的抽取、然后汇总,最后清晰的定义出来,这就是面向对象的第一步,即将实际场景存在或需求中的事物进行泛化,提取公共部分,进行类型的定义。抽象的结果是类型,也就是类。
对象
我们将一个定义抽象出来之后,可以根据这个定义,任意的产生一个具体的实例,这就是编程中的Class与具体的new Object,对象是根据抽象出的类型的实例化,我们定义了人类的特征和行为(即编写了一个Class),便可以根据这个Class,产出一个具体的个体来(new 出一个对象),就像我们每个人生活在地球这个环境中交流。程序也是一样,在面向对象的程序世界中,对象才是主角,程序是一个运行态,显然不是由抽象的类来工作,而是由抽象的类所具象化的一个个具体对象来通信、交流。
面向对象需要在意的几个意识:
- 一切皆是对象
:在程序中,任何事务都是对象,可以把对象看作一个奇特的变量,它可以存储,可以通信,可以从自身来进行各自操作,你总是可以从要解决的问题身上抽象出概念性的组件,然后在程序中将其表示为一个对象。 - 程序是对象的集合,它通过发送消息来告知彼此需要做什么
:程序就像是个自然环境,一个人,一头猪,一颗树,一个斧头,都是这个环境中的具体对象,对象之间相互的通信,操作来完成一件事,这便是程序中的一个流程,要请求调用一个对象的方法,你需要向该对象发送消息。 - 每个对象都有自己的存储空间,可容纳其他对象
:人会有手机,一个人是一个对象,一个手机也是一个对象,而手机可以是人对象中的一部分,或者说,通过封装现有对象,可制作出新型对象。所以,尽管对象的概念非常简单,但在程序中却可达到任意高的复杂程度。 - 每个对象都拥有其类型
:按照通用的说法,任何一个对象,都是某个“类(Class)”的实例,每个对象都必须有其依赖的抽象。 - 同一类所有对象都能接收相同的消息
:这实际是别有含义的一种说法,大家不久便能理解。由于类型为“圆”(Circle)的一个对象也属于类型为“形状”(Shape)的一个对象,所以一个圆完全能接收发送给"形状”的消息。这意味着可让程序代码统一指挥“形状”,令其自动控制所有符合“形状”描述的对象,其中自然包括“圆”。这一特性称为对象的“可替换性”,是OOP最重要的概念之一。
过程思维和对象思维
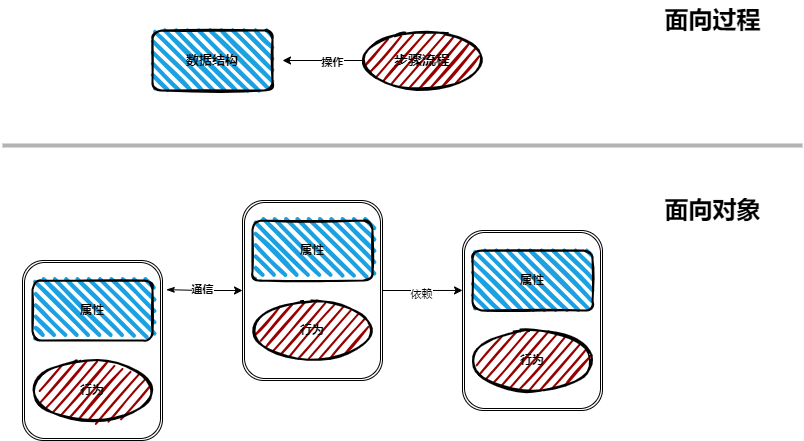
简单讲过程思维是数据结构加操作;对象思维则是一个整体,既包含数据结构又包含操作,也就是面向对象中的属性和行为。
面向对象设计原则
在进行面向对象设计和编码的道路上,众多知名前辈结合自己的实践和认知高度抽象概况出了具有指导思想意义的设计原则。这里的每个原则细细品来都是意味深长,但是需要注意的是,就像数据库范式一样,它是个指导思想,并不是需要一板一眼遵守的“准则”。
SRP-单一职责原则(Single Responsibility Principle)
单一职责的官方定义:
一个类应该只有一个引起它变化的原因
这里变化的原因就是所说的“职责”,如果一个类有多个引起它变化的原因,那么也就意味着这个类有多个职责,再进一步说,就是把多个职责耦合在一起了。这会造成职责的相互影响,可能一个职责的变化,会影响到其他职责的实现,甚至引起其他职责随着变化,这种设计是很脆弱的。
这个原则看起来是最简单和最好理解的,但是实际上是很难完全做到的,难点在于如何区分“职责”。这是个没有标准量化的东西,哪些算职责、到底这个职责有多大的粒度、这个职责如何细化等等,例如:
public classFileUtil {public voidreadFile(String filePath) {//读取文件的代码 }public voidwriteFile(String filePath, String content) {//写入文件的代码 }public voidencryptFile(String filePath) {//加密文件的代码 }public voiddecryptFile(String filePath) {//解密文件的代码 }
}
我们的开发习惯经常会根据一个对象或者概念+操作去定义一个Util,这个Util会作为公共处理代码来帮我们处理系统中关于文件相关的操作。但是严格来讲,这是违背了单一职责原则的,因为如果将来需要修改文件的读取逻辑或加密算法,可能会影响到其他功能,这就违反了单一职责原则。如果想要严格遵守单一职责,应该改为:
//负责文件读取的类 public classFileReader {public voidreadFile(String filePath) {//读取文件的代码 }
}//负责文件写入的类 public classFileWriter {public voidwriteFile(String filePath, String content) {//写入文件的代码 }
}//负责文件加密的类 public classFileEncryptor {public voidencryptFile(String filePath) {//加密文件的代码 }public voiddecryptFile(String filePath) {//解密文件的代码 }
}
现在,每个类都只有一个职责:
FileReader
类只负责读取文件。FileWriter
类只负责写入文件。FileEncryptor
类负责文件的加密和解密。
这样,每个类的变更原因都只有一个,符合单一职责原则。如果需要修改文件读取逻辑,只需要修改
FileReader
类;如果需要修改加密算法,只需要修改
FileEncryptor
类,而不会影响到其他类。但是实际项目中如果真严苛到每个操作都细化为一个类,多半会被人骂SB。
因此,在实际开发中,这个原则最容易被违反,因为这个度的把控是很难的。我们能做的就是基于项目实际情况的操作粒度来把控这个“职责”,如果项目中对于文件的操作,改动和牵扯范围很广,那严格遵守单一职责会带来很好的扩展性和维护性,但是如果项目十分简单,基于公共Util且万年不变,那完全没有必要进行单一职责改造,单体一个项目一个Util足够了。
OCP-开闭原则(Open-Closed Principle)
类应该对扩展开放,对修改关闭。
开闭原则要求的是,类的行为是可以扩展的,而且是在不修改已有代码的情况下进行扩展,也不必改动已有的源代码或者二进制代码。
这看起来好像是矛盾的,但这是指实际的编码过程中,毕竟这是一个指导思想,站在指导思想的角度上来看,也未必矛盾;实现开闭原则的关键就在于合理地抽象、分离出变化与不变化的部分,为变化的部分预留下可扩展的方式,比如,钩子方法或是动态组合对象等。
这个原则看起来也很简单。但事实上,一个系统要全部做到遵守开闭原则,几乎是不可能的,也没这个必要。适度的抽象可以提高系统的灵活性,使其可扩展、可维护,但是过度地抽象,会大大增加系统的复杂程度。应该在需要改变的地方应用开闭原则就可以了,而不用到处使用,从而陷入过度设计。
LSP-里氏替换原则(Liskov Substitution Principle)
子类对象应该能够替换掉它们的父类对象,而不影响程序的行为。
简单来讲就是子类可以替换掉父类在程序中的位置而不影响程序的使用,这是一种基于面向对象的多态的使用。它可以避免在多态的使用过程中出现某些隐蔽的错误。
public abstract classAccount {privateString accountNumber;private doublebalance;public Account(String accountNumber, doublebalance) {this.accountNumber =accountNumber;this.balance =balance;
}publicString getAccountNumber() {returnaccountNumber;
}public doublegetBalance() {returnbalance;
}public void deposit(doubleamount) {
balance+=amount;
System.out.println("Deposited: " + amount + ", New Balance: " +balance);
}public abstract void withdraw(doubleamount);
}//账户的派生类 public class CheckingAccount extendsAccount {private doubleoverdraftLimit;public CheckingAccount(String accountNumber, double balance, doubleoverdraftLimit) {super(accountNumber, balance);this.overdraftLimit =overdraftLimit;
}
@Overridepublic void withdraw(doubleamount) {if (amount <= balance +overdraftLimit) {
balance-=amount;
System.out.println("Withdrew: " + amount + ", New Balance: " +balance);
}else{
System.out.println("Insufficient funds for withdrawal: " +amount);
}
}public doublegetOverdraftLimit() {returnoverdraftLimit;
}
}//里氏替换使用场景 public classBank {private List<Account> accounts = new ArrayList<>();public voidaddAccount(Account account) {
accounts.add(account);
}public voidprocessTransactions() {for(Account account : accounts) {
account.withdraw(100); //假设每个账户都尝试取出100元 account.deposit(50); //假设每个账户都存入50元 }
}
}public classMain {public static voidmain(String[] args) {
Bank bank= newBank();
bank.addAccount(new Account("123456", 1000));
bank.addAccount(new CheckingAccount("789012", 500, 300));
bank.processTransactions();
}
}
这个符合里氏替换原则的样例的关键点是,无论是普通的
Account
对象还是
CheckingAccount
对象,都可以被
Account
类型的变量处理,而不需要任何特殊逻辑来区分它们。这就是里氏替换原则的体现:
CheckingAccount
对象可以无缝替换
Account
对象,而不会破坏
Bank
类的行为。
事实上,当一个类继承了另外一个类,那么子类就拥有了父类中可以继承下来的属性和操作。理论上来说,此时使用子类型去替换掉父类型,应该不会引起原来使用父类型的程序出现错误。
但是,在某些情况下是会出现问题的。比如,如果子类型覆盖了父类型的某些方法,或者是子类型修改了父类型某些属性的值,那么原来使用父类型的程序就可能会出现错误,因为在运行期间,从表面上看,它调用的是父类型的方法,需要的是父类型方法实现的功能,但是实际运行调用的却是子类型覆盖实现的方法,而该方法和父类型的方法并不一样,于是导致错误的产生。
从另外一个角度来说,里氏替换原则是实现开闭的主要原则之一。开闭原则要求对扩展开放,扩展的一个实现手段就是使用继承:而里氏替换原则是保证子类型能够正确替换父类型,只有能正确替换,才能实现扩展,否则扩展了也会出现错误
DIP-依赖倒置原则(Dependence Inversion Principle)
高层模块不应依赖于低层模块,两者都应该依赖于抽象;抽象不应依赖于细节,细节应依赖于抽象
所谓依赖倒置原则,指的是,要依赖于抽象,不要依赖于具体类。要做到依赖倒置典型的应该做到:
- 高层模块不应该依赖于底层模块,二者都应该依赖于抽象。
- 抽象不应该依赖于具体实现,具体实现应该依赖于抽象
很多人觉得,层次化调用的时候,应该是高层调用“底层所拥有的接口”,这是一种典型的误解。事实上,一般高层模块包含对业务功能的处理和业务策略选择,应该被重用,是高层模块去影响底层的具体实现。
因此,这个底层的接口应该是由高层提出的,然后由底层实现的。也就是说底层的接口的所有权在高层模块,因此是一种所有权的倒置。
比较经典的案例应该是COLA中提到数据防腐层设计,相关可以看我的
ISP-接口隔离原则(Interface Segregation Principle)
不应该强迫客户依赖于它们不使用的方法。一个类不应该实现它不需要的接口。
这个原则用来处理那些比较“庞大”的接口,这种接口通常会有较多的操作声明,涉及到很多的职责。客户在使用这样的接口的时候,通常会有很多他不需要的方法,这些方法对于客户来讲,就是一种接口污染,相当于强迫用户在一大堆“垃圾方法”中去寻找他需要的方法。其实有一点“接口的单一职责”的意思。
因此,这样的接口应该被分离,应该按照不同的客户需要来分离成为针对客户的接口。这样的接口中,只包含客户需要的操作声明,这样既方便了客户的使用,也可以避免因误用接口而导致的错误。
分离接口的方式,除了直接进行代码分离之外,还可以使用委托来分离接口,在能够支持多重继承的语言中,还可以采用多重继承的方式进行分离。
通过一个正反案例体会一下,假设我们有一个银行系统,其中包括两种类型的账户:储蓄账户(SavingsAccount)和支票账户(CheckingAccount)。储蓄账户提供存款和获取利息的功能,而支票账户提供存款、取款和透支的功能。
反例:
interfaceBankAccount {void deposit(doubleamount);void withdraw(doubleamount);doublegetInterestRate();
}class SavingsAccount implementsBankAccount {private doublebalance;public SavingsAccount(doubleinitialDeposit) {this.balance =initialDeposit;
}
@Overridepublic void deposit(doubleamount) {
balance+=amount;
}
@Overridepublic void withdraw(doubleamount) {//储蓄账户不允许透支 if (amount <=balance) {
balance-=amount;
}else{throw new IllegalArgumentException("Insufficient funds");
}
}
@Overridepublic doublegetInterestRate() {return 0.03; //假设利息率为3% }
}class CheckingAccount implementsBankAccount {private doublebalance;private doubleoverdraftLimit;public CheckingAccount(double initialDeposit, doubleoverdraftLimit) {this.balance =initialDeposit;this.overdraftLimit =overdraftLimit;
}
@Overridepublic void deposit(doubleamount) {
balance+=amount;
}
@Overridepublic void withdraw(doubleamount) {if (amount <= balance +overdraftLimit) {
balance-=amount;
}else{throw new IllegalArgumentException("Insufficient funds for overdraft");
}
}
@Overridepublic doublegetInterestRate() {//支票账户通常没有利息 return 0.0;
}
}
这里
BankAccount
接口强制要求所有账户实现
getInterestRate()
方法,这违反了ISP,因为不是所有类型的账户都有利息。如果想要符合ISP,应该讲用户公共操作分为两个接口,进一步保证接口功能的单一性。
public interfaceAccount {void deposit(doubleamount);void withdraw(doubleamount);
}public interfaceInterestBearing {doublegetInterestRate();
}public class SavingsAccount implementsAccount, InterestBearing {private doublebalance;public SavingsAccount(doubleinitialDeposit) {this.balance =initialDeposit;
}
@Overridepublic void deposit(doubleamount) {
balance+=amount;
}
@Overridepublic void withdraw(doubleamount) {if (amount <=balance) {
balance-=amount;
}else{throw new IllegalArgumentException("Insufficient funds");
}
}
@Overridepublic doublegetInterestRate() {return 0.03; //假设利息率为3% }
}public class CheckingAccount implementsAccount {private doublebalance;private doubleoverdraftLimit;public CheckingAccount(double initialDeposit, doubleoverdraftLimit) {this.balance =initialDeposit;this.overdraftLimit =overdraftLimit;
}
@Overridepublic void deposit(doubleamount) {
balance+=amount;
}
@Overridepublic void withdraw(doubleamount) {if (amount <= balance +overdraftLimit) {
balance-=amount;
}else{throw new IllegalArgumentException("Insufficient funds for overdraft");
}
}
}
Account
接口包含所有账户共有的操作,而
InterestBearing
接口仅包含与利息相关的操作。
SavingsAccount
类实现了
Account
和
InterestBearing
接口,因为它有利息收益。而
CheckingAccount
类只实现了
Account
接口,因为它没有利息收益。这样,我们就避免了强制要求
CheckingAccount
实现它不需要的
getInterestRate()
方法,从而遵循了接口隔离原则。
LKP-最少知识原则(Least Knowledge Principle)
又叫
迪米特法则(Law of Demeter, LoD)
,所谓最少知识,指的是,只和你的朋友谈话。
这个原则用来指导我们在设计系统的时候,应该尽量减少对象之间的交互,对象只和自己的朋友谈话,也就是只和自己的朋友交互,从而松散类之间的耦合。通过松散类之间的耦合来降低类之间的相互依赖,这样在修改系统的某一个部分的时候,就不会影响其他的部分,从而使得系统具有更好的可维护性。
那么究竟哪些对象才能被当作朋友呢?最少知识原则提供了一些指导。
- 当前对象本身。
- 通过方法的参数传递进来的对象。
- 当前对象所创建的对象。
- 当前对象的实例变量所引用的对象。
- 方法内所创建或实例化的对象。
总之,最少知识原则要求我们的方法调用必须保持在一定的界限范围之内,尽量减少对象的依赖关系。
设计原则与设计模式
通过前面的内容,我们大概能有个粗略答案了,即设计原则是抽象,设计模式有点像“对象”。其实设计原则与设计模式也有点这么个意思。
设计原则大多从思想层面给我们指出了面向对象分析设计的正确方向,是我们进行面向对象分析设计时应该尽力遵守的准则。是一种“抽象”。
而设计模式已经是针对某个场景下某些问题的某个解决方案。也就是说这些设计原则是思想上的指导,而设计模式是实现上的手段,因此设计模式也应该遵守这些原则,换句话说,设计模式就是这些设计原则的一些具体体现。是“对象”。
关于设计原则与设计模式的认识和选择,主要有以下几点:
- 设计原则本身是从思想层面上进行指导,本身是高度概括和原则性的。只是一个设计上的大体方向,其具体实现并非只有设计模式这一种。理论上来说,可以在相同的原则指导下,做出很多不同的实现来。
- 每一种设计模式并不是单一地体现某一个设计原则。事实上,很多设计模式都是融合了很多个设计原则的思想,并不好特别强调设计模式对某个或者是某些设计原则的体现。而且每个设计模式在应用的时候也会有很多的考量,不同使用场景下,突出体现的设计原则也可能是不一样的。
- 这些设计原则只是一个建议指导。事实上,在实际开发中,很少做到完全遵守,总是在有意无意地违反一些或者是部分设计原则。设计工作本来就是一个不断权衡的工作,有句话说得很好:“
设计是一种危险的平衡艺术
”。设计原则只是一个指导,有些时候,还要综合考虑业务功能、实现的难度、系统性能、时间与空间等很多方面的问题。