前言
前面介绍了定时器和输出比较,这一节主要介绍一下输入捕获测量输入频率和PWM占空比,然后介绍一下编码器接口。
一、输入捕获
1.什么是输入捕获
当输入的引脚有指定电平跳变时,会将计数器CNT中的值保存在CCR中,这个就称为输入捕获。
2.输入捕获测频率
我们可以通过获取输入的值来测量频率,这里有两个计算的方法:
2.1 测频法
在一个闸门时间T内,对上升沿进行计数,得到计数值N,频率就为=N/T。
2.2 测周法
在一个标准的频率fc下,对上升沿进行计数,得到计数值N,频率就为:fc / N。
3.输入捕获的内部结构
接下来了解一下输入捕获的内部结构,只有了解了内部结构,我们写代码才会很轻松,下图就是输入捕获的内部结构:
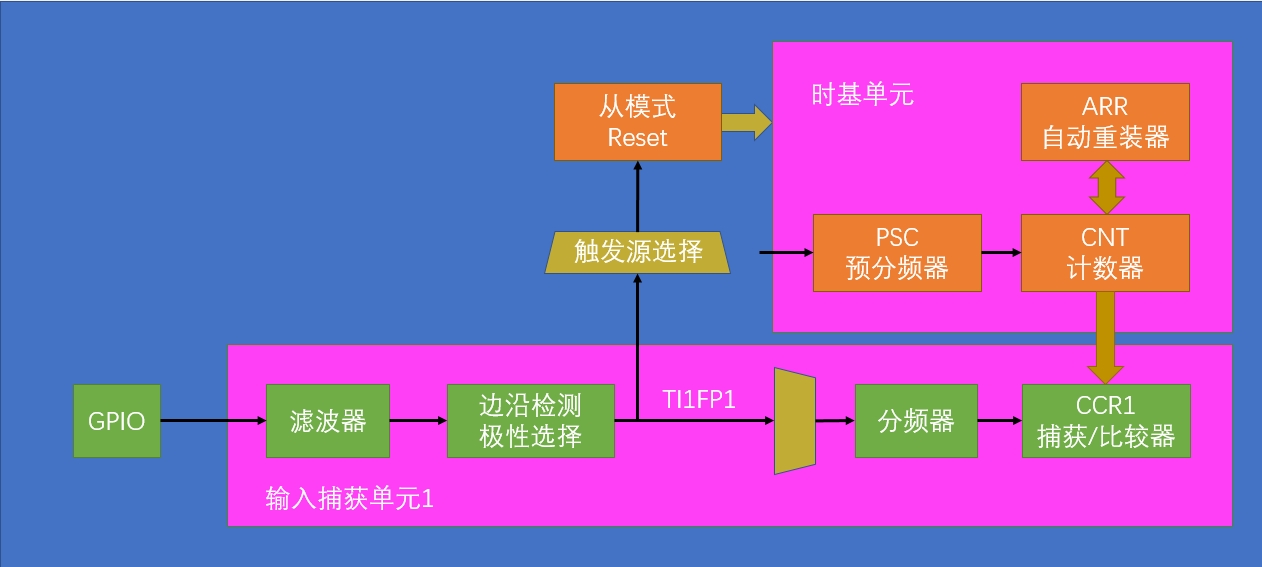
可以看到,从GPIO口输入电平,然后通过输入捕获单元,检测到触发电平,如果是设定的电平就会将CNT中的值保存到CCR中,然后通过配置从模式来将CNT中的值清0。
了解了这个结构后我们大概就知道如何配置输入捕获了。
首先配置外部输入,即GPIO口,然后配置定时器,因为输入捕获是定时器的一个工作模式,然后配置从模式,使用从模式的Reset来清空计数器CNT,这样就是配置好输入捕获了。
我们可以通过读取CCR中的值来计算频率。
4.软件实现
前面了解了硬件结构后,我们就可以使用软件来一一实现了,首先要打开时钟,时钟是stm32中最重要的一个部件,如果不打开时钟,就算配置了也没办法运行。
4.1 打开时钟
这里我们从上面的硬件分析可以得到,其实就是只用开启两个时钟,一个是GPIO的时钟,另一个就是TIM的时钟,输入捕获这个功能是在TIM中的,所以打开了TIM的时钟,输入捕获和输出比较也就打开了。
所以这里的代码就比较简单,我这里使用TIM3作为输入捕获的定时器,那么打开的代码如下:
RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA, ENABLE);
RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM3, ENABLE);
4.2 配置GPIO口
GPIO口做为一个外部信号的输入口,所以要为其设置输入模式,那选择什么模式最好呢?这里可以翻看一下手册:

可以看到GPIO配置为浮空输入,但是其实这里也可以配置为上拉输入,浮空输入就是能很好的捕捉电平的变化,但是没有上拉或者下拉导致不是很稳定,这里因为都是一个电平的跳变,就算是使用上拉,当输入的是高电平后会跳变为低电平,然后再变成高电平,所以这里可以选上拉或者下拉。
如果你不清楚这个跳变到底是什么,你可以选择浮空输入,这样获得的要好一点。
这里就是正常的配置GPIO口即可:
GPIO_InitTypeDef GPIO_InitStruct = {0};
GPIO_InitStruct.GPIO_Mode = GPIO_Mode_IPU; // 这里使用上拉输入
GPIO_InitStruct.GPIO_Pin = GPIO_Pin_6;
GPIO_InitStruct.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOA, &GPIO_InitStruct);
这里是使用的是TIM3的通道1。
4.3 配置TIM
现在需要配置一下TIM了,在配置GPIO那配置的是TIM3的通道1,所以这要配置一下TIM3。
如果你选择的是TIM2,那上面要配置TIM2对应的引脚。
这里的配置方法和之前配置定时器那一样:
TIM_TimeBaseInitTypeDef TIM_TimeBaseInitStruct = {0};
TIM_InternalClockConfig(TIM3); // 使用内部时钟
TIM_TimeBaseInitStruct.TIM_ClockDivision = TIM_CKD_DIV1; // 不分频
TIM_TimeBaseInitStruct.TIM_CounterMode = TIM_CounterMode_Up; // 向上计数
TIM_TimeBaseInitStruct.TIM_Period = 65536 - 1; // 这里需要注意
TIM_TimeBaseInitStruct.TIM_Prescaler = 72 - 1; // 频率
TIM_TimeBaseInitStruct.TIM_RepetitionCounter = 0; // 重复计数器,高级定时器才有的功能
TIM_TimeBaseInit(TIM3, &TIM_TimeBaseInitStruct);
这里的自动重装寄存器是填了一个最大值,是因为这里的输入捕获是用CNT对变化电平进行计数,而CNT中的值和自动重装寄存器ARR中的值一致时,就会使得计数器清0然后发送一个信号,如果这里到了ARR中的值后,还有变化的电平,是不是就会被舍弃。
所以这里为了防止这个问题,我们将ARR中的值设置成最大值,防止出现到了自动重装值时还有变化,所以用个最大的值,防止溢出。
4.4 配置输入捕获
这个也是使用一个结构体来进行配置的,结构体类型为:
typedef struct
{
uint16_t TIM_Channel; /*!< 指定 TIM 通道。
此参数的值可以是 @ref TIM_Channel */
uint16_t TIM_ICPolarity; /*!< 指定输入信号的有效边沿。
此参数的值可以是 @ref TIM_Input_Capture_Polarity */
uint16_t TIM_ICSelection; /*!< 指定输入。
此参数的值可以是 @ref TIM_Input_Capture_Selection */
uint16_t TIM_ICPrescaler; /*!< 指定输入捕获预分频器。
此参数的值可以是 @ref TIM_Input_Capture_Prescaler */
uint16_t TIM_ICFilter; /*!< 指定输入捕获筛选器。
此参数可以是介于 0x0 和 0xF 之间的数字 */
} TIM_ICInitTypeDef;
第一个参数
TIM_Channel
是选择通道,这个是通过之前说的引脚来进行设定的:
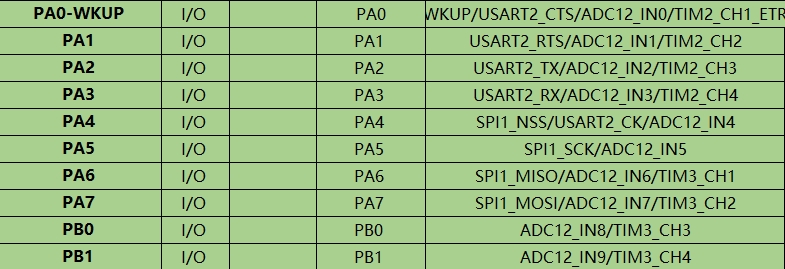
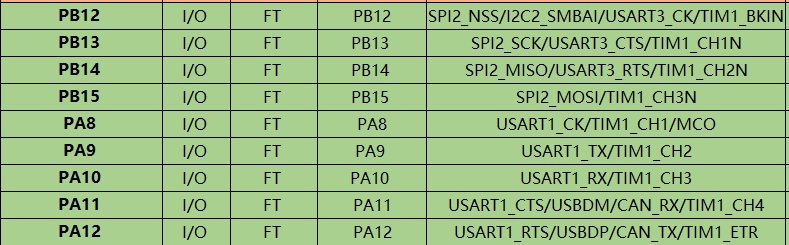

前面比如是设置了TIM3_CH1,那这里就填写
TIM_Channel_1
。
第二个参数
TIM_ICPolarity
,这个参数是选择有效信号的,可以选择
TIM_ICPolarity_Rising
高电平触发,
TIM_ICPolarity_Falling
低电平触发。
第三个参数
TIM_ICSelection
,指定输入,有信号直连
TIM_ICSelection_DirectTI
和交叉
TIM_ICSelection_IndirectTI
。这个需要拿个图来看看:
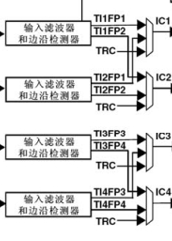
从这可以看到,我们通过选择
TI1FP1
它可以连到两个输入通道,一个是连到输入通道1,另一个连到通道2,直接配置到输入通道1的就叫做直连模式,如果连到输入通道2就叫做交叉模式。
第四个参数
TIM_ICPrescaler
就是分配器。
第五个参数
TIM_ICFilter
这个参数是选择过滤器的分辨率。
了解了结构体后我们就可以配置一下结构体中的内容了,这里我直接使用定时器通道1和输入通道1,所以模式就是直连:
TIM_ICInitStruct.TIM_Channel = TIM_Channel_1;
TIM_ICInitStruct.TIM_ICFilter = 0xF;
TIM_ICInitStruct.TIM_ICPolarity = TIM_ICPolarity_Rising; // 有效电平高电平
TIM_ICInitStruct.TIM_ICPrescaler = TIM_ICPSC_DIV1;
TIM_ICInitStruct.TIM_ICSelection = TIM_ICSelection_DirectTI; // 直连
TIM_ICInit(TIM3, &TIM_ICInitStruct);
这里再举一个例子,我这还是定时器通道1,输入通道变成了通道2,那这就选择交叉模式,代码如下:
TIM_ICInitStruct.TIM_Channel = TIM_Channel_1;
TIM_ICInitStruct.TIM_ICFilter = 0xF;
TIM_ICInitStruct.TIM_ICPolarity = TIM_ICPolarity_Rising; // 有效电平高电平
TIM_ICInitStruct.TIM_ICPrescaler = TIM_ICPSC_DIV1;
TIM_ICInitStruct.TIM_ICSelection = TIM_ICSelection_IndirectTI; // 交叉
TIM_ICInit(TIM3, &TIM_ICInitStruct);
这样就可以通过读取输入通道2中的CCR值来获取有效电平的次数了。
我们可以通过这个来计算PWM的频率和PWM的占空比,一个输入通道来获取PWM频率,另一个通道获取PWM的占空比。
一个通道两个设置的方法如下:
TIM_ICInitStruct.TIM_Channel = TIM_Channel_1;
TIM_ICInitStruct.TIM_ICFilter = 0xF;
TIM_ICInitStruct.TIM_ICPolarity = TIM_ICPolarity_Rising; // 有效电平高电平
TIM_ICInitStruct.TIM_ICPrescaler = TIM_ICPSC_DIV1;
TIM_ICInitStruct.TIM_ICSelection = TIM_ICSelection_DirectTI; // 直连
TIM_ICInit(TIM3, &TIM_ICInitStruct);
TIM_ICInitStruct.TIM_Channel = TIM_Channel_1;
TIM_ICInitStruct.TIM_ICFilter = 0xF;
TIM_ICInitStruct.TIM_ICPolarity = TIM_ICPolarity_Falling; // 有效电平低电平
TIM_ICInitStruct.TIM_ICPrescaler = TIM_ICPSC_DIV1;
TIM_ICInitStruct.TIM_ICSelection = TIM_ICSelection_IndirectTI; // 交叉
TIM_ICInit(TIM3, &TIM_ICInitStruct);
一个通道分别有直连和交叉,然后一个是高电平有效,一个是低电平有效。
4.5 配置从模式
我们在前面知道,需要配置个从模式让从模式去执行
Reset
操作来讲CNT中的值清0,这里只需要使用俩个函数就可以实现,首先是第一个
TIM_SelectInputTrigger
,这个函数是选择触发器源,在这个图中:
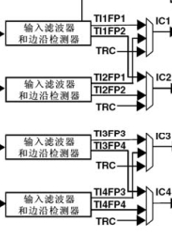
可以看到在边缘检测电路后有四个信号,分别是是
TI1FP1
、
TI2FP2
、
TI3FP3
、
TI4FP4
,这几个信号可以触发从模式,我们先用这个定时器的输入通道后,然后通过
TIM_SelectSlaveMode
函数来设置从模式。
比如说我们上面设置的是TIM3定时器,而且是使用的是TIM3_CH1,那这的设置函数就为:
TIM_SelectInputTrigger(TIM3, TIM_TS_TI1FP1);
TIM_SelectSlaveMode(TIM3, TIM_SlaveMode_Reset);
再比如说,这里是TIM2的CH2,那设置函数为:
TIM_SelectInputTrigger(TIM2, TIM_TS_TI2FP2);
TIM_SelectSlaveMode(TIM2, TIM_SlaveMode_Reset);
这里的信号
TIxFPx
和定时器是什么无关,只和通道有关。stm32f103c8t6只能配置4个输入捕获,所以这里的x是从1到4。
4.6 使能定时器
这个就不详细说了,就是使用
TIM_Cmd()
函数就可以使能了,代码如下:
TIM_Cmd(TIMx, ENABLE);
5.输入捕获测频率和占空比
上面介绍了代码的实现,这里来介绍一下,如果使用输入捕获来获取PWM频率和PWM占空比。
这个的代码实现比较简单,就是设置为输入捕获模式,然后写两个转换函数即可:
#include "ic.h"
void IC_Init()
{
GPIO_InitTypeDef GPIO_InitStruct = {0};
TIM_TimeBaseInitTypeDef TIM_TimeBaseInitStruct = {0};
TIM_ICInitTypeDef TIM_ICInitStruct = {0};
RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA, ENABLE);
RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM3, ENABLE);
GPIO_InitStruct.GPIO_Mode = GPIO_Mode_IPU;
GPIO_InitStruct.GPIO_Pin = GPIO_Pin_7; // 这里使用的是TIM3_CH2
GPIO_InitStruct.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOA, &GPIO_InitStruct);
TIM_InternalClockConfig(TIM3);
TIM_TimeBaseInitStruct.TIM_ClockDivision = TIM_CKD_DIV1;
TIM_TimeBaseInitStruct.TIM_CounterMode = TIM_CounterMode_Up;
TIM_TimeBaseInitStruct.TIM_Period = 65536 - 1;
TIM_TimeBaseInitStruct.TIM_Prescaler = 72 - 1;
TIM_TimeBaseInitStruct.TIM_RepetitionCounter = 0;
TIM_TimeBaseInit(TIM3, &TIM_TimeBaseInitStruct);
TIM_ICInitStruct.TIM_Channel = TIM_Channel_2; // 直连模式要选择通道2
TIM_ICInitStruct.TIM_ICFilter = 0xF;
TIM_ICInitStruct.TIM_ICPolarity = TIM_ICPolarity_Rising;
TIM_ICInitStruct.TIM_ICPrescaler = TIM_ICPSC_DIV1;
TIM_ICInitStruct.TIM_ICSelection = TIM_ICSelection_DirectTI; // 直连模式
TIM_ICInit(TIM3, &TIM_ICInitStruct);
TIM_ICInitStruct.TIM_Channel = TIM_Channel_1; // 交叉模式要选择通道1
TIM_ICInitStruct.TIM_ICFilter = 0xF;
TIM_ICInitStruct.TIM_ICPolarity = TIM_ICPolarity_Falling; // 这里需要和上面设置的有效电平分割开,要不然会出现运行不了的问题,我试过,必须要分开,要不然测试不了。
TIM_ICInitStruct.TIM_ICPrescaler = TIM_ICPSC_DIV1;
TIM_ICInitStruct.TIM_ICSelection = TIM_ICSelection_IndirectTI; // 交叉模式
TIM_ICInit(TIM3, &TIM_ICInitStruct);
TIM_SelectInputTrigger(TIM3, TIM_TS_TI2FP2);
TIM_SelectSlaveMode(TIM3, TIM_SlaveMode_Reset);
TIM_Cmd(TIM3, ENABLE);
}
uint32_t IC_Get_Freq()
{
// 转换为频率
return 1000000 / (TIM_GetCapture2(TIM3) + 1); // 用输入捕获设置的频率除以标准时钟72MHz后得到1000000,然后用这个频率除以获取的N即可得到频率。
}
uint32_t IC_Get_Pulse()
{
// 转换为占空比
return ((TIM_GetCapture1(TIM3) + 1) * 100) / IC_Get_Freq(); // 这个算法是在PWM占空比那说过的。这里不重复
}
这样就可以获取得到PWM的频率和占空比了。
二、编码器接口
1.什么是编码器接口
编码器接口可接收增量(正交)编码器的信号,根据编码器旋转产生的正交信号脉冲,自动控制CNT自增或自减。
下图是一个正交编码器的图:
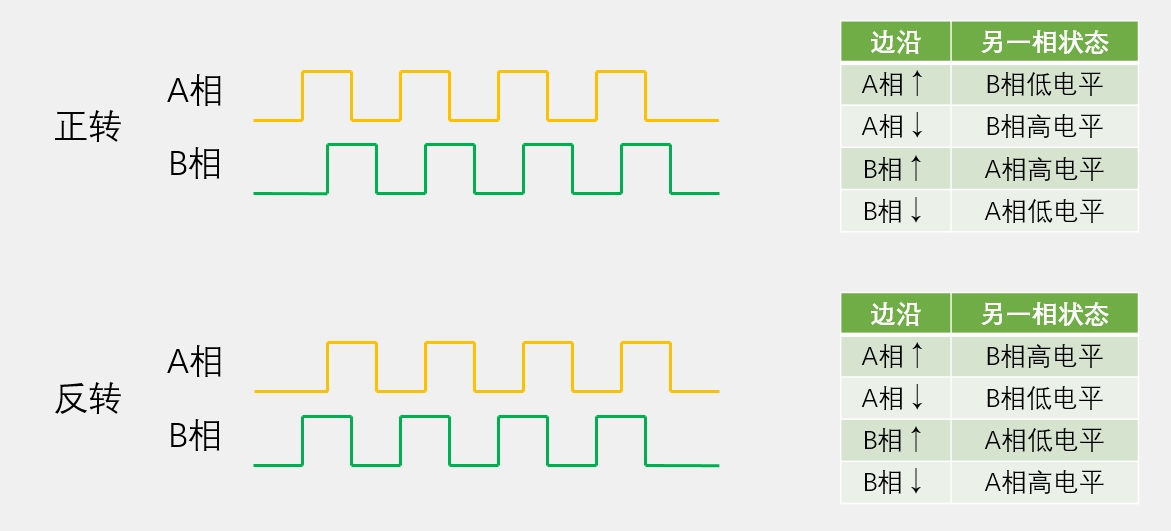
可以看到,编码器的这个波形,A项和B项的波形是相差90度的,所以这两个波形在一起就可以分正和反了。
2.编码器接口的硬件结构
我们可以用前面学过的输入捕获或者是中断来实现编码器的实现,但是,在stm32f103c8t6中设置了一个编码器接口,我们可以直接使用硬件来实现编码器的测试。
硬件结构如下:
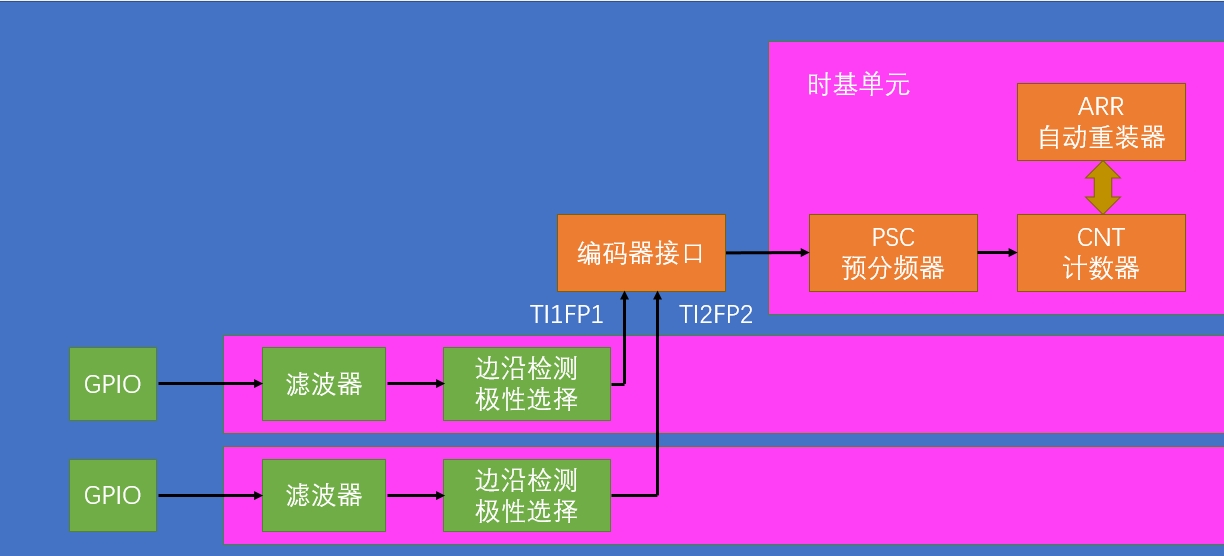
可以看到非常的简单,只需要在前面的基础上增加个编译器接口的配置即可。
使用的函数是:
void TIM_EncoderInterfaceConfig(TIM_TypeDef* TIMx, uint16_t TIM_EncoderMode,uint16_t TIM_IC1Polarity, uint16_t TIM_IC2Polarity);
这个函数就可以设置编码器接口了,首先设置GPIO口,因为我们的这个编码器是需要两个输入的,所以需要设置两个引脚作为输入引脚,然后配置定时器,配置为定时器后需要配置输入捕获,之后就使用上面的函数进行配置编码器接口。
第一个参数
TIMx
是定时器的编号。
第二个参数
TIM_EncoderMode
是使用模式,可以选下面这几个模式:
|
模式
|
解释
|
| TIM_EncoderMode_TI1 |
使用TI1FP1作为编码器设置 |
| TIM_EncoderMode_TI2 |
使用TI2FP2作为编码器设置 |
| TIM_EncoderMode_TI12 |
使用TI1FP1和TI2FP2作为编码器设置 |
第三个参数
TIM_IC1Polarity
是选择TI1FP1是正项还是反向,第四个参数
TIM_IC2Polarity
和第三个参数一样,是选择TI2FP2。
当两个都选择正向或者是反向时,就如下图的时许一样:
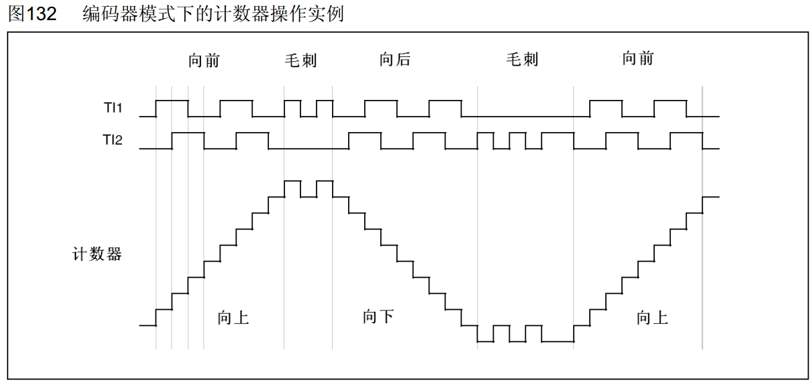
当TI1有上升电平,TI2还是低电平时,计数器就会自增,当TI2有上升电平,TI1是高电平时,计数器也会自增。
当TI1FP1或者TI2FP2有一个是反项时就会变成下面的时许:
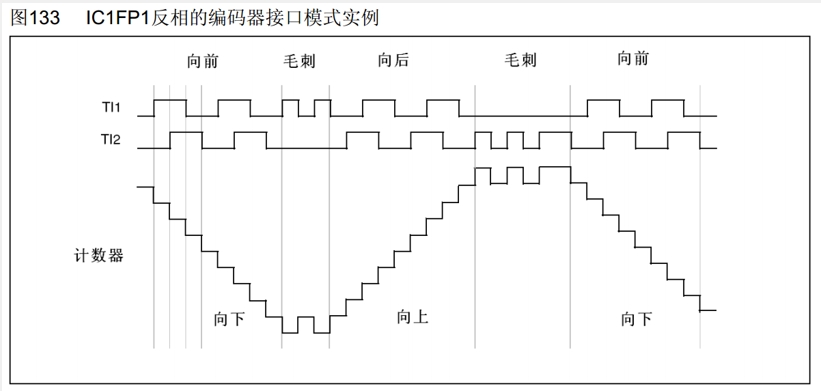
在正向时TI1有上升电平,TI2还是低电平时,计数器就会自增,但反向后就是变成自减了。
也就是说当正向的自增转到反向后就会变成自减。
3.软件实现
硬件结构讲完成后,就可以用代码来对其中的功能进行一个实现了。
3.1 时钟开启
这里的开启时钟也就只需要开启GPIO的时钟和定时器的时钟,因为编码器接口也是定时器的一个附加功能,所以只用开启GPIO和定时器的时钟即可,不需要额外的时钟开启。
3.2 GPIO口配置
这里还是需要配置GPIO口,因为需要外部的编码器的输入,这里选择的引脚和定时器的输入捕获和输出比较一样,需要查看引脚的复用功能是不是在TIM定时器的通道上,如果不在那就不能使用。
这里选择的是定时器3的通道1和通道2,对应的引脚是PA6和PA7。
配置代码如下:
GPIO_InitTypeDef GPIO_InitStruct = {0};
GPIO_InitStruct.GPIO_Pin = GPIO_Pin_6 | GPIO_Pin_7;
GPIO_InitStruct.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOA, &GPIO_InitStruct);
3.3 配置定时器
配置的方法也是和上面一样,打开TIM3定时器,然后配置一系列操作,但这里需要改变一下,预分频器PSC这里就不需要分频,只需要填写1-1即可,1就是不分频,这里是又编码器接口硬件来进行操作即可,然后自动重装寄存器ARR只需要配置最大即可,也不需要TIM指定使用内部时钟,这个时钟也是由编码器接口来提供的。
TIM_TimeBaseTypeDef TIM_TimeBaseStruct = {0};
TIM_TimeBaseStruct.TIM_ClockDivision = TIM_CKD_DIV1;
TIM_TimeBaseStruct.TIM_CounterMode = TIM_CounterMode_Up;
TIM_TimeBaseStruct.TIM_Period = 65536 - 1;
TIM_TimeBaseStruct.TIM_Prescaler = 1 - 1;
TIM_TimeBaseStruct.TIM_RepetitionCounter = 0;
TIM_TimeBaseInit(TIM3, &TIM_TimeBaseStruct);
3.4 配置输入捕获
这里需要注意一下,有些东西在这配置时不需要配置,只需要配置两个参数即可,需要配置的有通道
TIM_Channel
和过滤器的分辨率
TIM_ICFilter
然后其他的不需要配置。
所以这里需要使用一个函数来为结构体赋一个默认值:
TIM_ICInitTypeDef TIM_ICInitStruct = {0};
TIM_ICStructInit(&TIM_ICInitStruct);
TIM_ICInitStruct.TIM_Channel = TIM_Channel_1;
TIM_ICInitStruct.TIM_ICFilter = 0x0F;
TIM_Init(TIM3, &TIM_ICInitStruct);
TIM_ICInitStruct.TIM_Channel = TIM_Channel_2;
TIM_ICInitStruct.TIM_ICFilter = 0x0F;
TIM_Init(TIM3, &TIM_ICInitStruct);
这里可能会比较好奇为什么那些都不配置,比如说预分频器和有效电平和反向,这是因为在配置编码器接口那就已经配置好了的,不需要我们再进行配置,编码器接口会为这个输入捕获一个时钟,所以就不需要分频了,然后反向也是,也是那一个函数就可以配置好了的。
3.5配置编码器接口
这里就使用上面介绍的那个函数即可配置:
TIM_EncoderInterfaceConfig(TIM3, TIM_EncoderMode_TI12, TIM_ICPolarity_Rising, TIM_ICPolarity_Rising);
这里我都设置的是不反向,是为了方便。
3.6 使能定时器
最后使能一下定时器就可以了,使能方法之前介绍了很多遍,这里就不再拉出代码了,下面完整代码中有。
3.7 完整代码
这里为了方便,我把完整代码贴出来:
void Encoder_Init()
{
GPIO_InitTypeDef GPIO_InitStruct = {0};
TIM_TimeBaseInitTypeDef TIM_TimeBaseStruct = {0};
TIM_ICInitTypeDef TIM_ICInitStruct = {0};
RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA, ENABLE);
RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM3, ENABLE);
GPIO_InitStruct.GPIO_Mode = GPIO_Mode_IPU;
GPIO_InitStruct.GPIO_Pin = GPIO_Pin_6 | GPIO_Pin_7;
GPIO_InitStruct.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOA, &GPIO_InitStruct);
TIM_TimeBaseStruct.TIM_ClockDivision = TIM_CKD_DIV1;
TIM_TimeBaseStruct.TIM_CounterMode = TIM_CounterMode_Up;
TIM_TimeBaseStruct.TIM_Period = 65536 - 1;
TIM_TimeBaseStruct.TIM_Prescaler = 1 - 1;
TIM_TimeBaseStruct.TIM_RepetitionCounter = 0;
TIM_TimeBaseInit(TIM3, &TIM_TimeBaseStruct);
TIM_ICInitStruct.TIM_Channel = TIM_Channel_1;
TIM_ICInitStruct.TIM_ICFilter = 0x0F;
TIM_ICInit(TIM3, &TIM_ICInitStruct);
TIM_ICInitStruct.TIM_Channel = TIM_Channel_2;
TIM_ICInitStruct.TIM_ICFilter = 0x0F;
TIM_ICInit(TIM3, &TIM_ICInitStruct);
TIM_EncoderInterfaceConfig(TIM3, TIM_EncoderMode_TI12, TIM_ICPolarity_Rising, TIM_ICPolarity_Rising);
TIM_Cmd(TIM3, ENABLE);
}
总结
通用定时器的相关操作就介绍完成了,后面有机会的话给大家介绍一下高级定时器,高级定时器可以操作三项无刷电机,等后面有时间我做一个无人机会使用到高级定时器。





















