SLF4J2.0.x与Logback1.3.x的绑定变动还是很大的,不要乱点鸳鸯谱
开心一刻
今天跟我姐聊天
我:我喜欢上了我们公司的一个女同事,她好漂亮,我心动了,怎么办
姐:喜欢一个女孩子不能只看她的外表
我:我知道,还要看她的内在嘛
姐:你想多了,还要看看自己的外表

背景介绍
在
SpringBoot2.7 霸王硬上弓 Logback1.3 → 不甜但解渴
原理分析那部分,我对
Logback
的表述是很委婉的
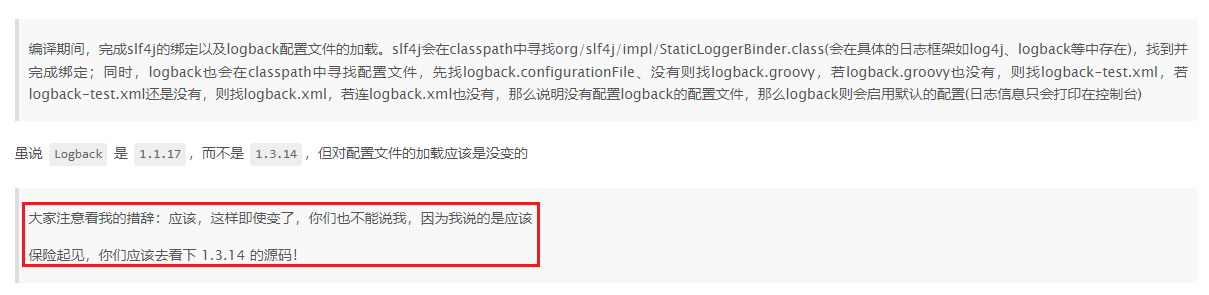
后来想想,作为一个软件开发人员,怎能如此不严谨,真是太不应该了,为表示最诚挚的歉意,请允许我自罚三耳光

作为弥补,接下来我会带你们盘一盘
Logback 1.3.14
的部分源码。参考
从源码来理解slf4j的绑定,以及logback对配置文件的加载
,同样基于两个问题
- SLF4J 与 Logback 是如何绑定的
- Logback 是如何加载配置文件的
来展开分析。在分析之前,我先帮你们解决一个你们可能会有遇到的疑问点
Logback 1.3.14 依赖的 SLF4J 版本怎么是 1.7.36?
假设我们的 pom.xml 内容如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.qsl</groupId>
<artifactId>spring-boot-2_7_18</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.18</version>
</parent>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<logback.version>1.3.14</logback.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<artifactId>spring-boot-starter-logging</artifactId>
<groupId>org.springframework.boot</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
</dependencies>
</project>
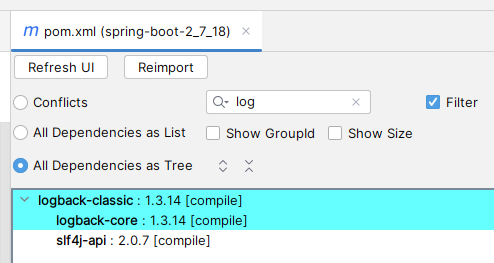
但我们会发现 logback 的依赖树如下
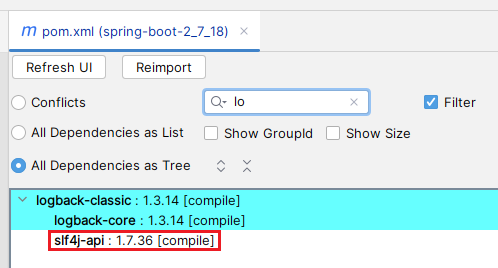
无论是 logback
官配

还是 logback 1.3.14 pom 文件中的依赖
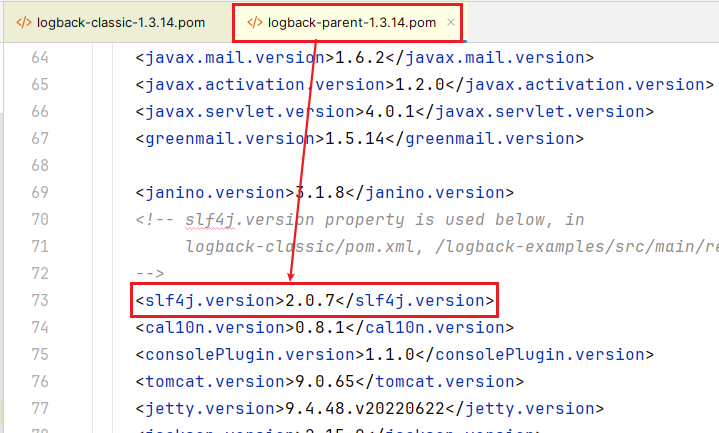
slf4j-api
的版本都是
2.0.x
(
logback 1.3.14
依赖的是
slf4j-api 2.0.7
) ,
slf4j-api 1.7.36
是从哪乱入的?
这是因为引入了父依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.18</version>
</parent>
而
spring-boot-starter-parent
的父依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.7.18</version>
</parent>
在
spring-boot-dependencies
指定了 slf4j 版本
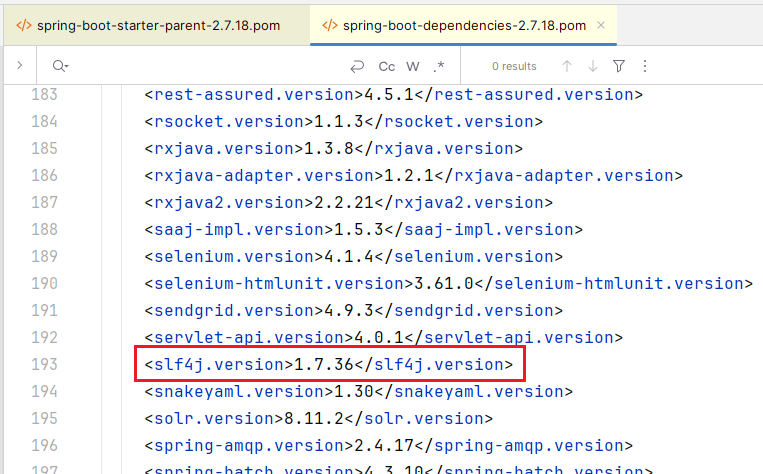
那为什么不是
logback-parent-1.3.14.pom
中的
slf4j.version
生效,而是
spring-boot-dependencies-2.7.18.pom
中的
slf4j.version
生效呢?这就涉及
maven
依赖的优先级了,感兴趣的可以去查阅相关资料,本文就不展开了,因为偏离我们的最初的目标越来越远了
那如何将
slf4j
改成
2.0.7
,提供两种方式
如果不需要
spring-boot
,那就去掉父依赖
spring-boot-starter-parent这就相当于由 logback 带入 slf4j,引入的就是 logback 所依赖的版本
在我们的 pom 文件中指定
<slf4j.version>2.0.7</slf4j.version>这里还是涉及 maven 依赖的优先级,我们自己的 pom 文件中的优先级更高
不管采用哪种方式,反正要把版本搞正确
SLF4J 绑定 Logback
准备测试代码
public class LogbackTest {
private static Logger LOGGER = LoggerFactory.getLogger(LogbackTest.class);
public static void main(String[] args)
{
LOGGER.info("......info");
}
}
应该知道从哪开始跟源码吧,没得选择呀,只能选
getLogger
方法
推荐大家用
debug
的方式去跟,不然容易跟丢;来到
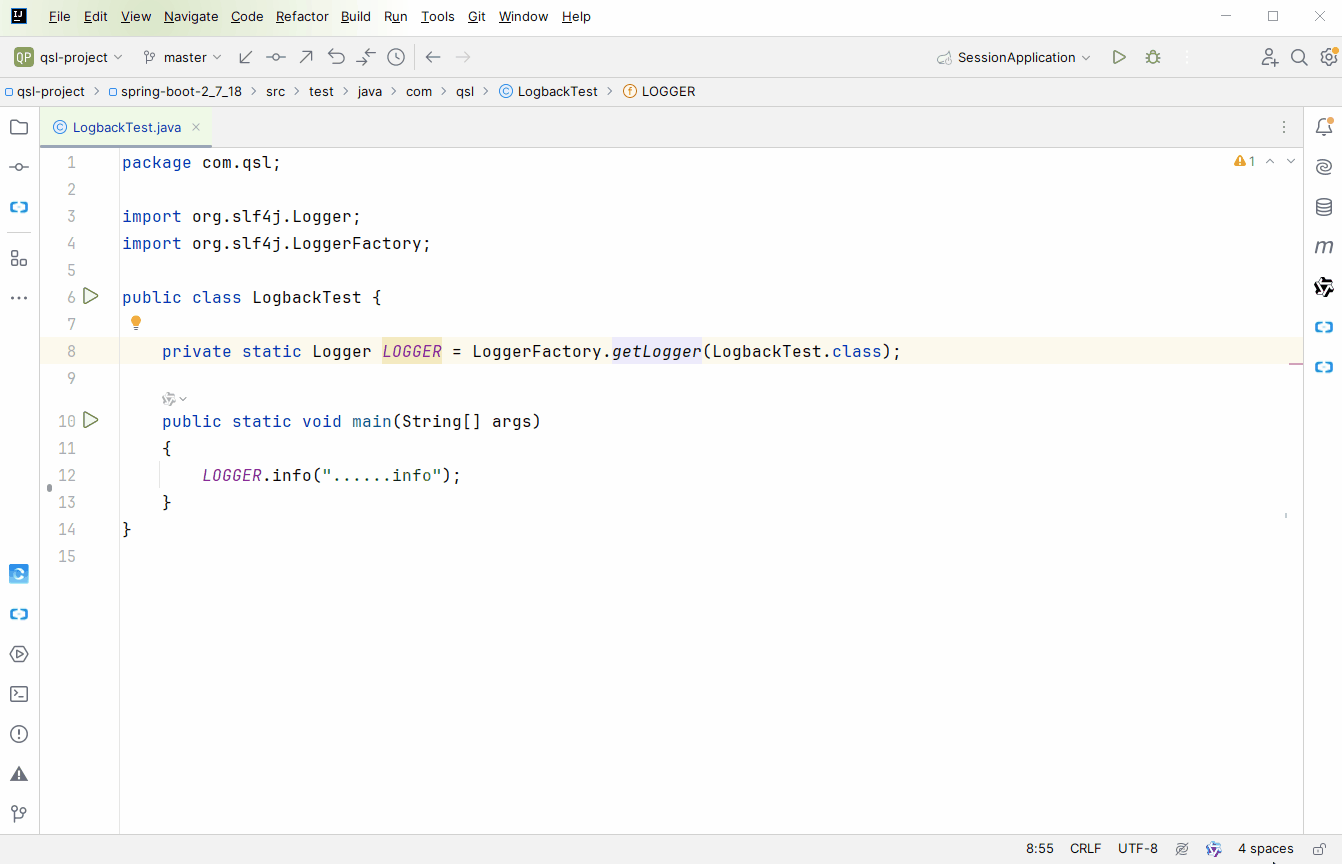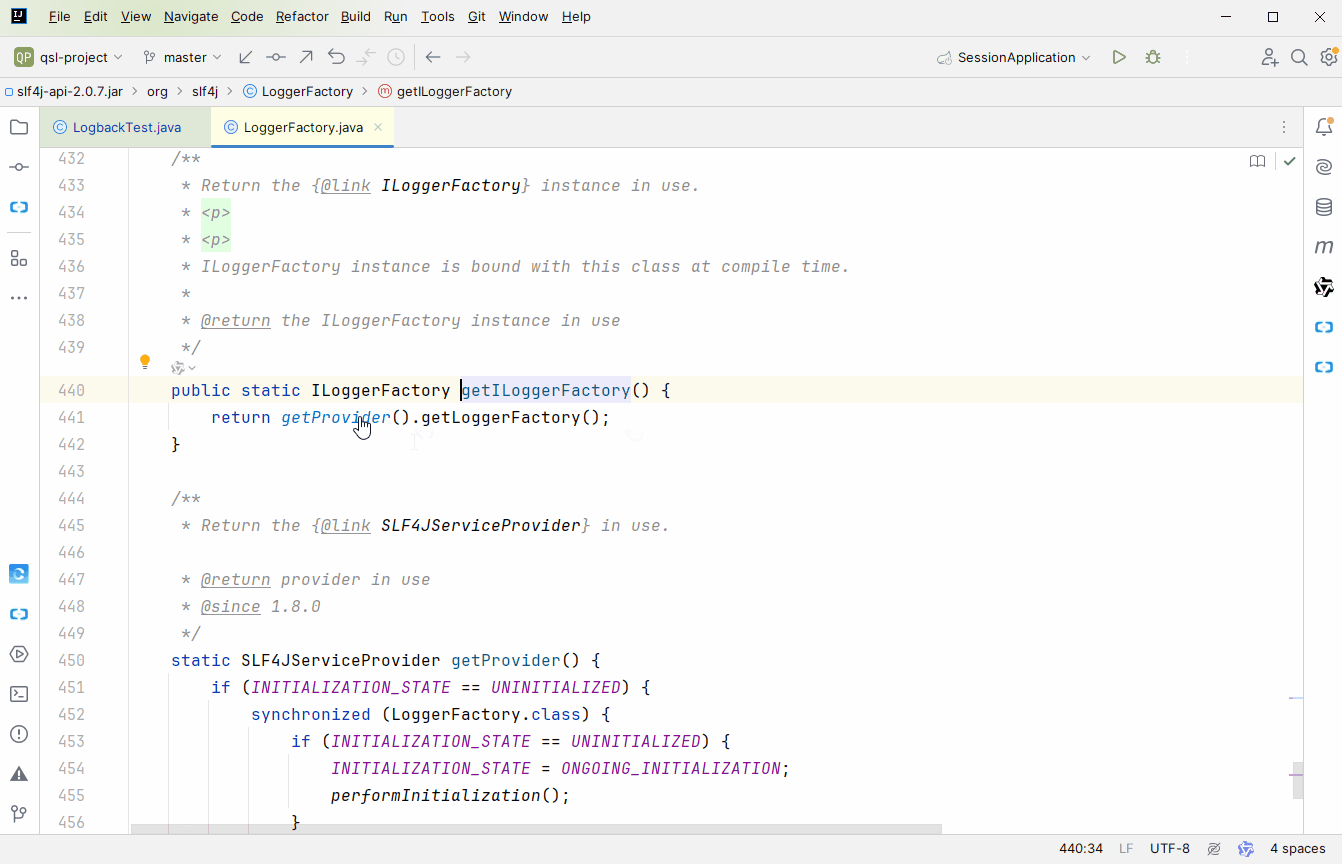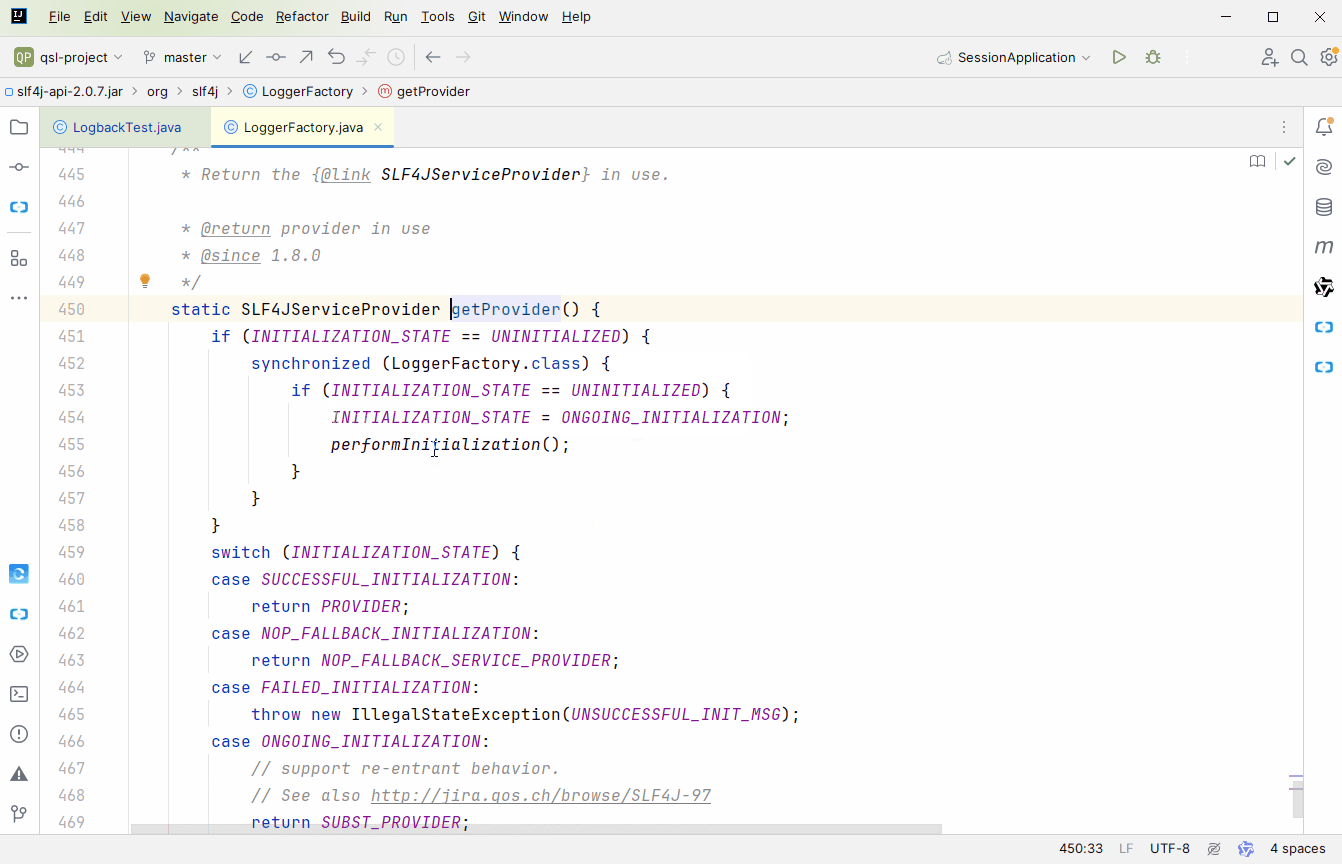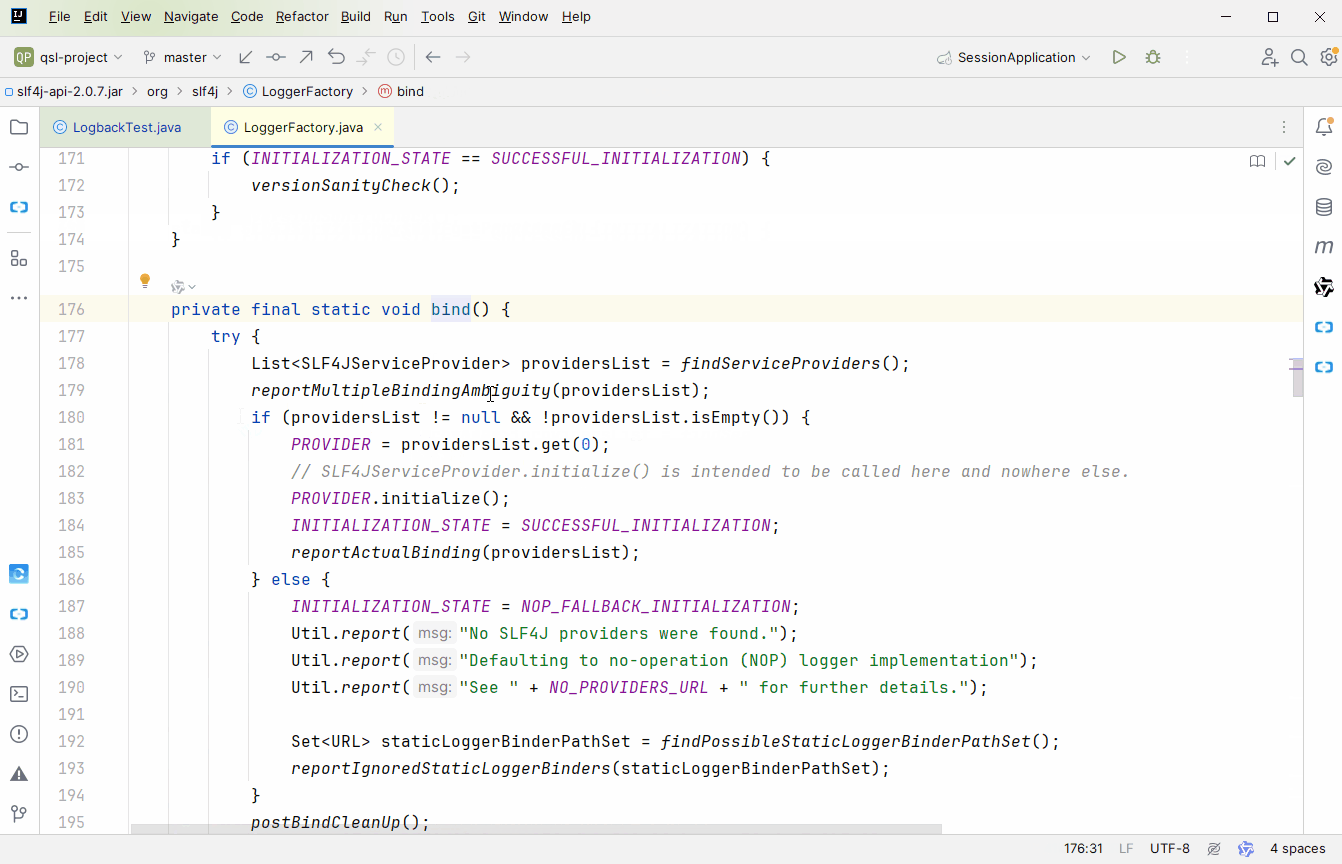
org.slf4j.LoggerFactory#bind
方法,这里完成
slf4j
与具体实现的绑定。bind 方法中有 2 点需要我们自己分析下
findServiceProviders
static List<SLF4JServiceProvider> findServiceProviders() { // retain behaviour similar to that of 1.7 series and earlier. More specifically, use the class loader that // loaded the present class to search for services final ClassLoader classLoaderOfLoggerFactory = LoggerFactory.class.getClassLoader(); ServiceLoader<SLF4JServiceProvider> serviceLoader = getServiceLoader(classLoaderOfLoggerFactory); List<SLF4JServiceProvider> providerList = new ArrayList<>(); Iterator<SLF4JServiceProvider> iterator = serviceLoader.iterator(); while (iterator.hasNext()) { safelyInstantiate(providerList, iterator); } return providerList; }
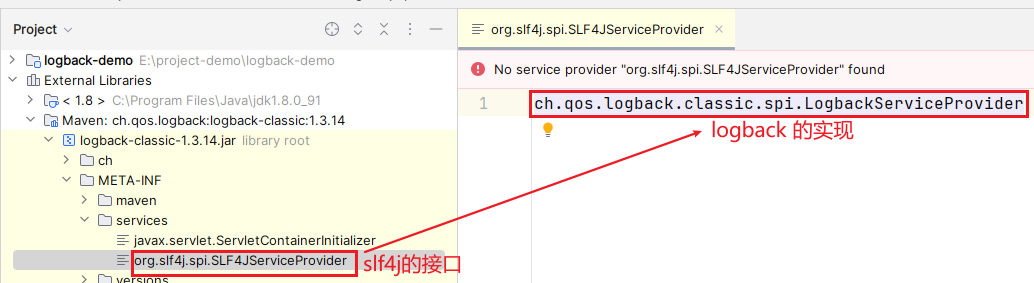
有没有一点熟悉的感觉?大家回顾下
JDK SPI
,是不是恍然大悟了?会去
classpath
下的
META-INF/services
目录下寻找
org.slf4j.spi.SLF4JServiceProvider
文件
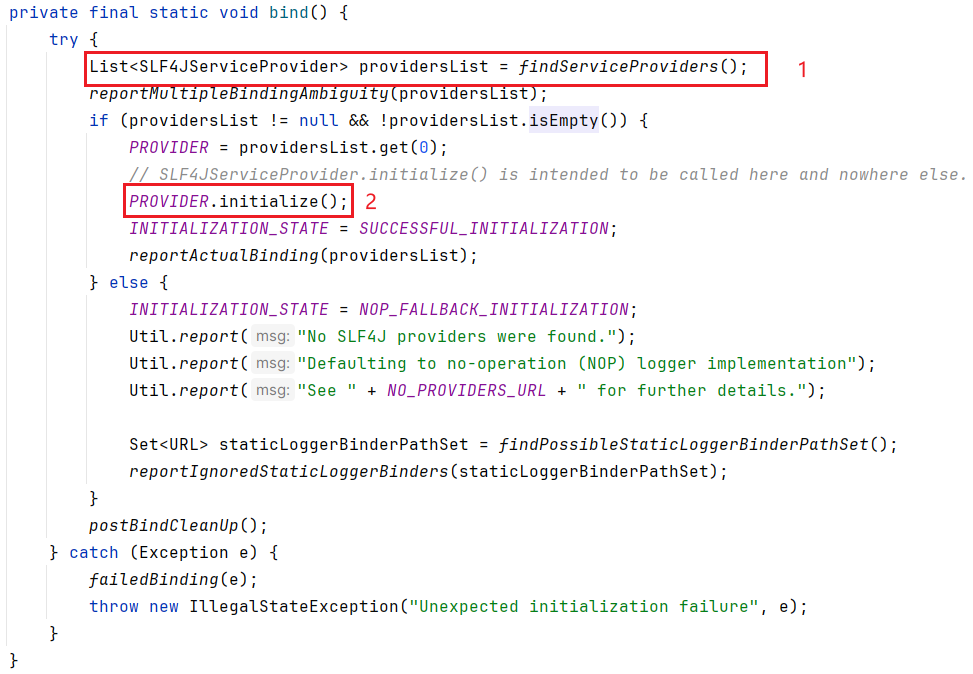
然后读取其中的内容,并实例化
这里拿到的是
Provider
,并非
Loggerinitialize
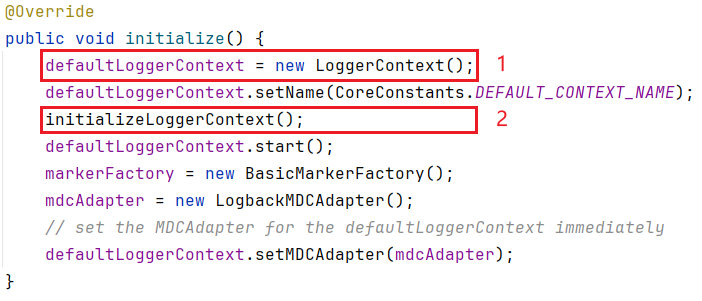
大家注意看下
defaultLoggerContext
的类型
LoggerContext
public class LoggerContext extends ContextBase implements ILoggerFactory, LifeCycle
第 2 点与 Logback 加载配置文件有关,后续再细看,暂且先只看第 1 点
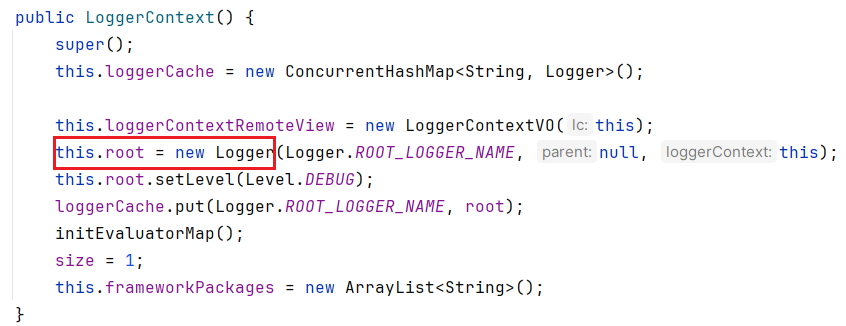
注意看下
Logger
的类型
public final class Logger
implements org.slf4j.Logger, LocationAwareLogger, LoggingEventAware, AppenderAttachable
, Serializable
实现了
org.slf4j.Logger
,这就跟
slf4j
关联起来了接下来出栈,回到
public static ILoggerFactory getILoggerFactory() { return getProvider().getLoggerFactory(); }
getProvider()
已经分析过了,接下来就看
getLoggerFactory()public ILoggerFactory getLoggerFactory() { return defaultLoggerContext; // if (!initialized) { // return defaultLoggerContext; // // // if (contextSelectorBinder.getContextSelector() == null) { // throw new IllegalStateException("contextSelector cannot be null. See also " + NULL_CS_URL); // } // return contextSelectorBinder.getContextSelector().getLoggerContext(); }
非常简单,直接返回
defaultLoggerContext
,defaultLoggerContext 在前面的
initialize
已经讲过,忘记了的小伙伴回到上面看看从
getILoggerFactory()
继续出栈,来到public static Logger getLogger(String name) { ILoggerFactory iLoggerFactory = getILoggerFactory(); return iLoggerFactory.getLogger(name); }
这里的
iLoggerFactory
是不是就是
defaultLoggerContext
?接下来就看
iLoggerFactory.getLogger(name)这个方法虽然略微有点长,但不难,只是有个缓存设计,我就不展开了,你们自行去看
总结下
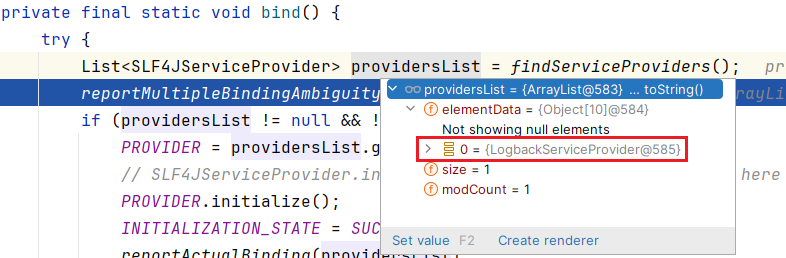
- 通过 SPI 的方式,实现 SLF4JServiceProvider 的绑定(ch.qos.logback.classic.spi.LogbackServiceProvider)
- LogbackServiceProvider 的 initialize 方法会实例化 defaultLoggerContext(ch.qos.logback.classic.LoggerContext implement org.slf4j.ILoggerFactory)
- 通过 defaultLoggerContext 获取 logger(ch.qos.logback.classic.Logger implements org.slf4j.Logger)
- org.slf4j.Logger 绑定 ch.qos.logback.classic.Logger 完成
Logback 加载配置文件
前面已经提到过,
ch.qos.logback.classic.spi.LogbackServiceProvider#initializeLoggerContext
完成对配置文件的加载
private void initializeLoggerContext() {
try {
try {
new ContextInitializer(defaultLoggerContext).autoConfig();
} catch (JoranException je) {
Util.report("Failed to auto configure default logger context", je);
}
// LOGBACK-292
if (!StatusUtil.contextHasStatusListener(defaultLoggerContext)) {
StatusPrinter.printInCaseOfErrorsOrWarnings(defaultLoggerContext);
}
// contextSelectorBinder.init(defaultLoggerContext, KEY);
} catch (Exception t) { // see LOGBACK-1159
Util.report("Failed to instantiate [" + LoggerContext.class.getName() + "]", t);
}
}
一眼就能看出,下一步直接看
autoConfig
,跟进去 2 步,会来到如下方法
public void autoConfig(ClassLoader classLoader) throws JoranException {
// see https://github.com/qos-ch/logback/issues/715
classLoader = Loader.systemClassloaderIfNull(classLoader);
String versionStr = EnvUtil.logbackVersion();
if (versionStr == null) {
versionStr = CoreConstants.NA;
}
loggerContext.getStatusManager().add(new InfoStatus(CoreConstants.LOGBACK_CLASSIC_VERSION_MESSAGE + versionStr, loggerContext));
StatusListenerConfigHelper.installIfAsked(loggerContext);
// invoke custom configurators
List<Configurator> configuratorList = ClassicEnvUtil.loadFromServiceLoader(Configurator.class, classLoader);
configuratorList.sort(rankComparator);
if (configuratorList.isEmpty()) {
contextAware.addInfo("No custom configurators were discovered as a service.");
} else {
printConfiguratorOrder(configuratorList);
}
for (Configurator c : configuratorList) {
if (invokeConfigure(c) == Configurator.ExecutionStatus.DO_NOT_INVOKE_NEXT_IF_ANY)
return;
}
// invoke internal configurators
for (String configuratorClassName : INTERNAL_CONFIGURATOR_CLASSNAME_LIST) {
contextAware.addInfo("Trying to configure with "+configuratorClassName);
Configurator c = instantiateConfiguratorByClassName(configuratorClassName, classLoader);
if(c == null)
continue;
if (invokeConfigure(c) == Configurator.ExecutionStatus.DO_NOT_INVOKE_NEXT_IF_ANY)
return;
}
}
前部分读自定义配置,因为我们没有自定义配置,所以可以忽略,直接看
// invoke internal configurators
for (String configuratorClassName : INTERNAL_CONFIGURATOR_CLASSNAME_LIST) {
contextAware.addInfo("Trying to configure with "+configuratorClassName);
Configurator c = instantiateConfiguratorByClassName(configuratorClassName, classLoader);
if(c == null)
continue;
if (invokeConfigure(c) == Configurator.ExecutionStatus.DO_NOT_INVOKE_NEXT_IF_ANY)
return;
}
INTERNAL_CONFIGURATOR_CLASSNAME_LIST
内容如下
String[] INTERNAL_CONFIGURATOR_CLASSNAME_LIST = {"ch.qos.logback.classic.joran.SerializedModelConfigurator",
"ch.qos.logback.classic.util.DefaultJoranConfigurator", "ch.qos.logback.classic.BasicConfigurator"}
这个 for 循环是一旦
invoke
上,则直接返回,所以是
INTERNAL_CONFIGURATOR_CLASSNAME_LIST
元素从前往后,逐个
invoke
,一旦成功则直接结束;通过
debug
我们会发现
DefaultJoranConfigurator
invoke 上了,其
performMultiStepConfigurationFileSearch
方法寻找配置文件
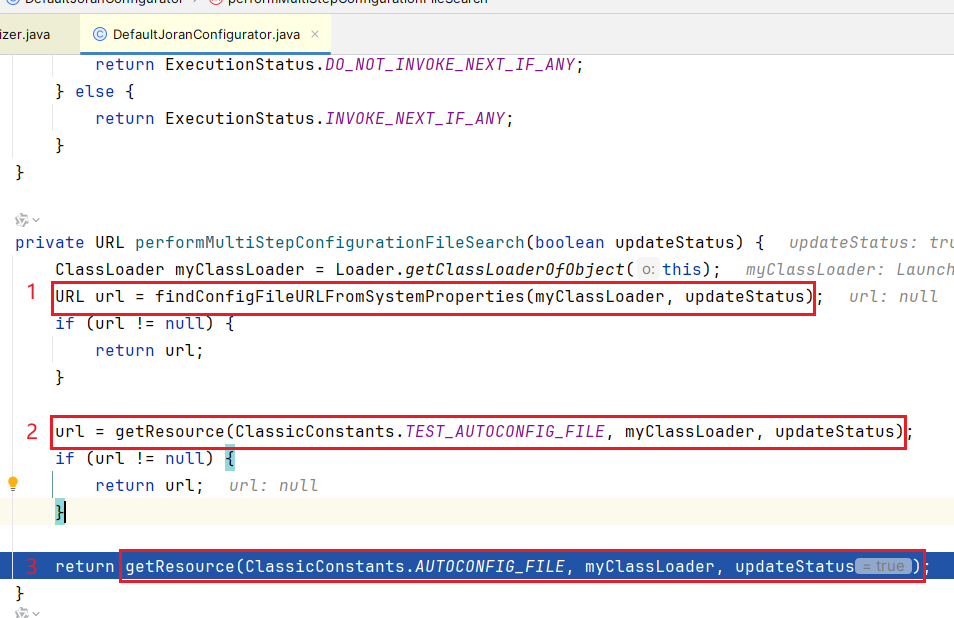
优先级从高到低,会从
classpath
下寻找三个文件
- 寻找
logback.configurationFile - 寻找
logback-test.xml - 寻找
logback.xml
一旦找到,直接返回,不会继续寻找;我们用的是
logback.xml
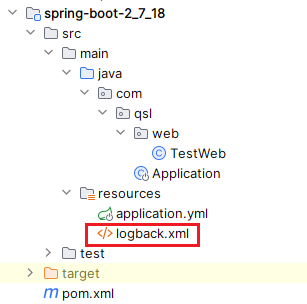
而没有使用其它两个文件,所以生效的是
logback.xml
再回过头去看
背景介绍
中的不严谨处,我们发现
Logback 1.3.14
对配置文件的加载与
Logback 1.1.7
基本一致,只是少了
logback.groovy
的读取;但话说回来,
SLF4J
与
Logback
的绑定过程还是有非常大的变动,大家可以和
从源码来理解slf4j的绑定,以及logback对配置文件的加载
仔细对比

总结
SLF4J 2.0.x 与 Logback 1.3.x 的绑定,采用了
SPI
机制Logback 1.3.x 默认配置文件优先级
logback.configurationFile > logback-test.xml > logback.xml
优先级从高到低一旦读取一个,则直接采用这个,不会继续往下读
所以
SpringBoot2.7 霸王硬上弓 Logback1.3 → 不甜但解渴
中提到的

配置文件必须是 logback.xml
不够严谨,还可以是哪些,你们应该知道了吧?

尽量选择
官配
依赖版本,不要头铁,不要头铁,不要头铁!















