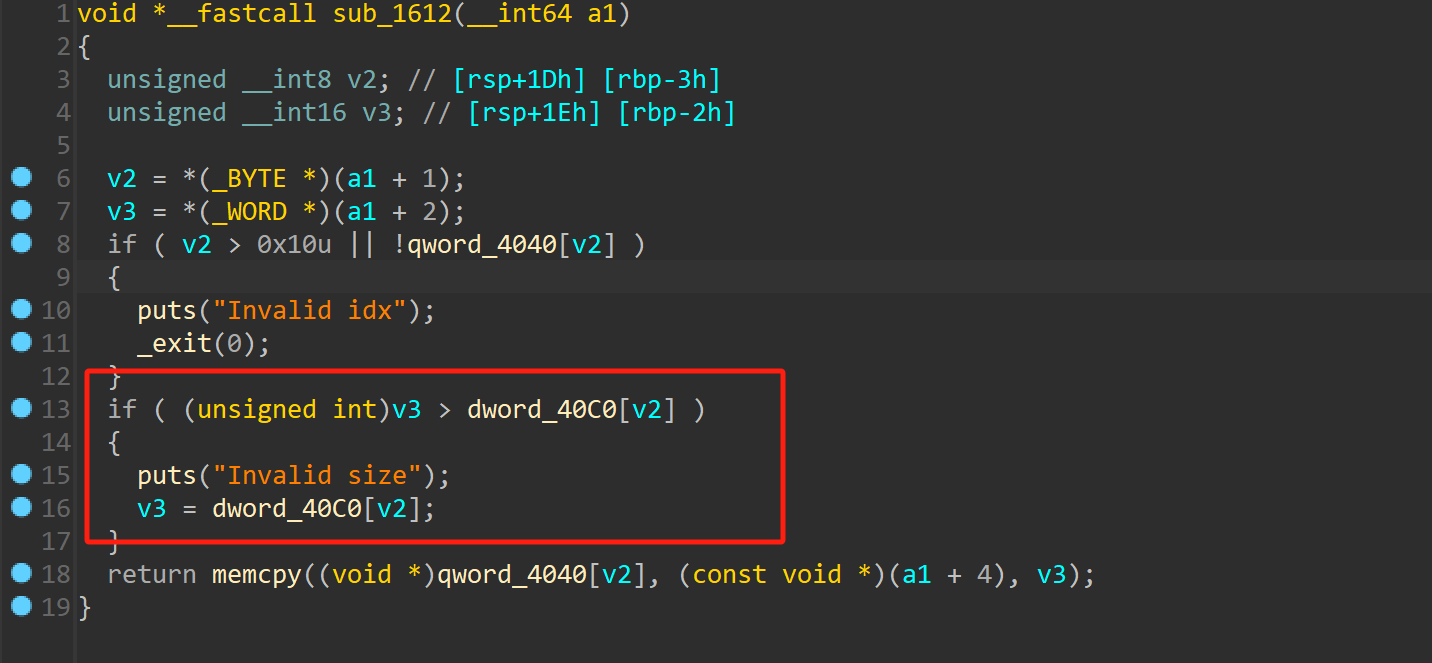
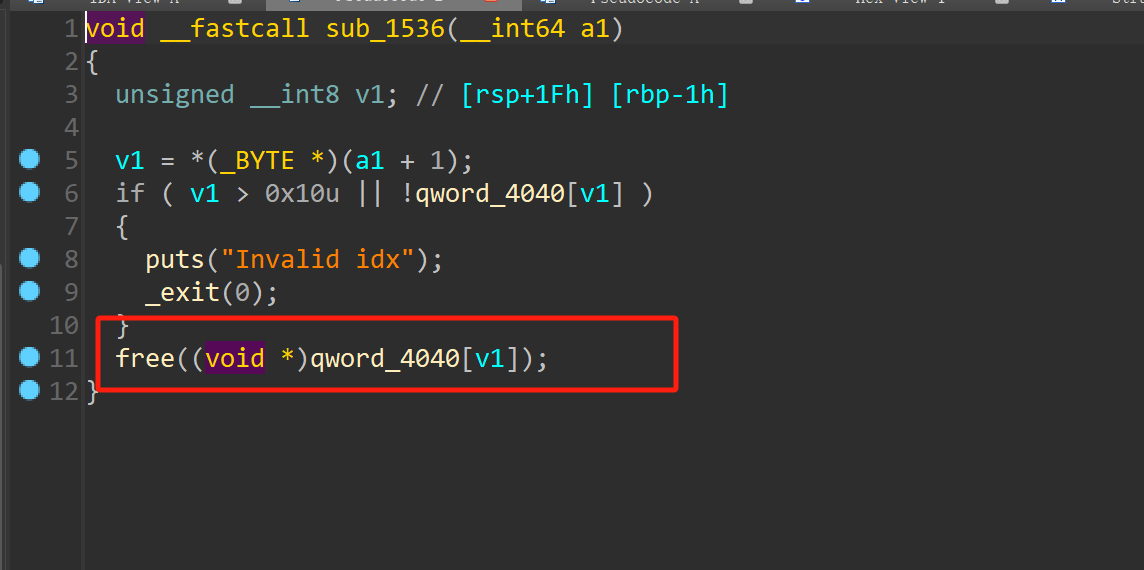
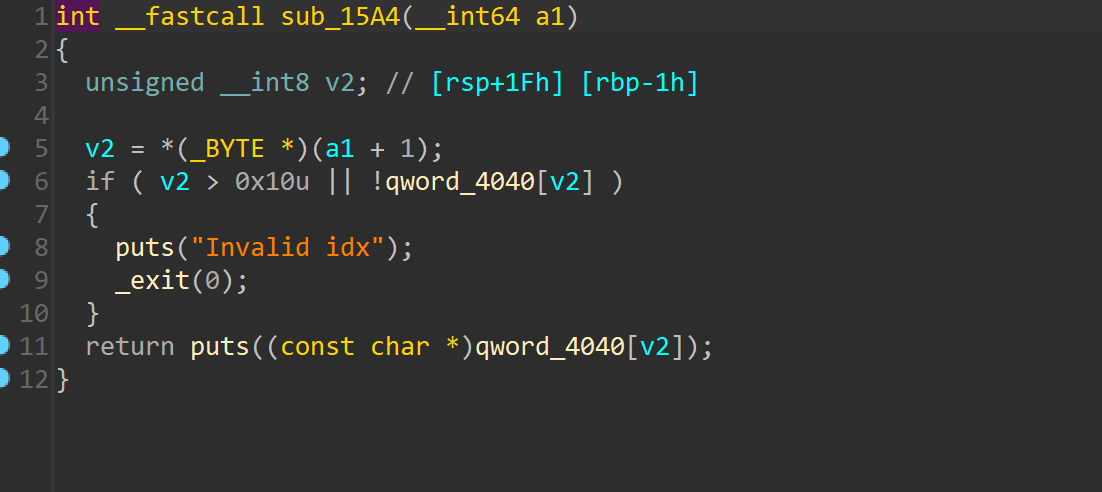
前端基本功——面试必问系列(1):都2024了,还没吃透Promise?一文搞懂
写在前面:
大家好,我是
山里看瓜
,该系列文章是为了帮助大家不管面试还是开发对前端的一些基本但是很重要的知识点认识更加深入和全面。
想写这个系列文章的初衷是:我发现前端的很多基本知识,使用起来很简单,定义看起来也很简单。很多人你在问他相关问题的时候,他也能说上几句。但是为什么用?怎么用会更好?原理是什么?让你实现你怎么做?这些问题很多人都是一知半解,某些知识点我本人也是如此,只知道去用,甚至有时候都不知道为什么用,更别说原理,秉承的原则就是程序跟我要么有一个能跑,至于怎么跑那雨我无瓜...
本篇我们从各个方面来介绍
Promise
,把一些你知道的不知道的点全都梳理一遍,让你面试中讲得透彻,表现亮眼;让你在开发中使用更加知根知底。
我们将从以下几个方面进行讲解学习:
Promise
是什么?
定义
- mdn描述:一个
Promise
是一个代理,它代表一个在创建
promise
时不一定已知的值。它允许你将处理程序与异步操作的最终成功值或失败原因关联起来。这使得异步方法可以像同步方法一样返回值:异步方法不会立即返回最终值,而是返回一个 promise,以便在将来的某个时间点提供该值。 - 总结来说:
Promise
是ES6规范提出的一个技术,用于在JavaScript中进行异步编程(读写文件、数据库、请求、定时器)的解决方案,原来的方案是使用回调嵌套的方式,容易造成回到地狱(后面我们会说到)。 - 具体来说:
- 语法上来说:
Promise
是一个构造函数 - 功能上来说:
Promise
对象用来封装一个异步操作并可以获取其成功或者失败的值 - promise 中既可以异步任务,也可以时同步任务
- 语法上来说:
Promise
的状态
状态是 promise 实例对象中的一个属性:PromiseState,该属性有三种值:
- 待定(pending):初始状态,既没有被兑现,也没有被拒绝,待定状态。
- 完成(resolved / fullfiled ):意味着操作成功完成。
- 失败(rejected):意味着异步操作失败。
状态变化有且只有两种情况:
pending
变为
resolved / fullfiled
。pending
变为
rejected
状态变化说明:
- 有且只会有这两种变化情况,并且 promise 对象的状态只会改变一次,从 pending 改变为成功或者失败状态。
- 无论状态变为成功或者失败,始终都会有一个结果数据(跟是否有返回无关)。
- 执行成功后的结果只一般称为
value
,执行失败的结果值一般称为
reason
。
Promise
的结果
Promise 的结果属性:
- 我们在实例对象身上能看到
PromiseResult
这个属性,它保存着异步任务执行成功或者失败的结果。
怎么修改 promise 的结果?
- resolve 函数:修改为成功状态(fullfiled)。
- reject 函数:修改为失败状态(rejected)。
Promise
的工作流程

为什么要用
Promise
?
- 让我们在处理异步操作时,能够更加灵活地指定回调函数。
- 以前回调函数方式,必须在启动异步任务前就指定回调函数;
- promise:启动异步任务 ——> 返回 promise 对象 ——> 给 promise 对象绑定回调;
- promise方式,我们甚至可以在异步任务结束后再指定,并且可以指定多个回调。
- 支持链式调用,可以解决回调地狱问题。
- 回调地狱:回调函数嵌套调用,外部回调函数异步执行的结果是嵌套的回调执行的条件。
- 回调地狱的缺点:不利于阅读,不利于异常处理,维护起来比较复杂。
如何使用
Promise
—— 方法参数详细说明
Promise
构造器函数:Promise(executor) {}
- executor 函数:执行器 (resolve, reject) => {}
- resolve 函数: 内部定义成功时我们调用的函数 value => {}
- reject 函数:内部定义失败时我们调用的函数 reason => {}
- 说明:executor 会在 Promise 内部立即同步调用,异步操作在执行器中执行,
即执行器函数并不是异步执行
Promise
原型方法
- Promise.prototype.then 方法:(onResolved, onRejected) => {}
- onResolved 函数:成功的回调函数 (value) => {}
- onRejected 函数:失败的回调函数 (reason) => {}
- then()总是返回一个新的promise
- 新promise的结果状态由then指定的回调函数执行的结果决定
- 抛出错误
- 返回失败的promise
- 返回成功的promise
- 返回其它任何值
- 说明:这两个方法用于指定得到成功 value 的成功的回调和得到失败 reason 的失败的回调
- then 方法返回一个新的 promise对象
- Promise.prototype.catch 方法:(onRejected) => {}
- onRejected 函数:失败的回调函数 (reason) => {}
Promise 构造函数本身的方法
- Promise.resolve 方法:(value) => {}
- value:成功的数据或 promise 对象
- 如果传递的参数为 非 promise 对象,则返回的结果为成功 promise 对象
- 如果传入的参数为 Promise 对象,则参数的结果决定了 resolve 的结果
- 说明:返回一个成功/失败的 promise 对象
let p1 = Promise.resolve(520)
let p2 = Promise.resolve(new Promise((resolve, reject) => {
resolve('OK')
})) // 这时 p2 状态为成功,成功的值为 'OK'Ï
- Promise.reject 方法:(reason) =>{}
- reason:失败的原因
- 说明:返回一个失败的 promise 对象
let p = Promise.reject(520) // 无论传入的是什么,返回的都是一个失败的promise 对象
// 传入什么,失败的结果就是什么
- Promise.all 方法:(promises) => {}
- promises:包含 n 个 promise 的数组
- 批量/一次性发送多个异步请求
- 当都成功时, 返回的promise才成功
- 一旦有一个失败的, 返回的promise就失败了
- 说明:返回一个新的 promise,只有所有的 promise 都成功时才成功,只要有一个失败了就直接失败
- 成功的结果时每一个 promise 对象成功结果组成的数组(有顺序)
- 失败的结果是在这个数组中失败的那个 promise 对象失败的结果
let p1 = new Promise((resolve, reject) => {
resolve('OK')
})
let p2 = Promise.resolve('Success')
let p3 = Promise.resolve('Success')
const result = Promise.all([p1, p2, p3])
- Promise.race 方法:(promises) => {}
- promises:包含 n 个 promise 的数组
- race:赛跑/比赛
- 说明:返回一个新的promise,第一个完成的 promise 的结果状态就是最终的结果状态
let p1 = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('OK')
}, 1000)
})
let p2 = Promise.resolve('Success')
let p3 = Promise.resolve('Success')
const result = Promise.race([p1, p2, p3]) // =>结果为 p2 的结果,因为p2 先改变状态
Promise
在开发中比较常用的技巧
我们在实际开发中,经常遇到需要发多个请求获取数据,当这些请求之前并没有相互依赖时,我们使用正常的
Promise
方式去请求或者使用
async
await
方式请求,都是顺序执行,一个请求在前一个请求完成之后发起,这样非常的低效率,并且性能和体验都非常的差,我们依赖请求数据的页面部分会有长时间空白,用户体验非常差。
这时候我们可以使用
Promise.all()
+
async、await
来同时并发请求,这样请求就可以同时发起,实现一个并行发出的效果。
Promise.all(promises)
方法的结果是一个包含所有异步操作的结果数组,能够一一对应上 promises 数组中的异步操作。
以下是一个简单示例:
// 请求接口数据的方法
const getApiData = async () {
const [res1, res2, res3] = await Promise.all(
[
Api.getData1(),
Api.getData2(),
Api.getData3(),
]
)
}
几个注意点:
- 函数内部使用
await
时,函数必须使用 async 关键字; - 只使用一个
await
,给
Promise.all()
使用; - 内部请求不要加 await 关键字,否则还是会顺序请求,不能实现并行发起;
- 因为
Promise.all()
的结果是对应内部异步操作的数组,我们可以直接通过数组解构,获取每个请求的结果,方便后续针对请求值做操作。
Promise
风格方法封装举例
- fs 模块封装
function mineReadFile (path) {
return new Promise((resolve, reject) => {
// 读取文件
require('fs').readFile(path, (err, data) => {
// 判断
if (err) reject(err)
// 成功
resolve(data)
})
})
}
// 调用
mineReadFile("/file/test.txt").then(value => {
console.log(value)
}, reason => {
console.log(reason)
});
- Ajax 请求封装
function sendAJAX(url) {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest()
// 设置响应数据格式
xhr.responseType = 'json'
xhr.open('GET', url)
xhr.send();
// 处理结果
xhr.onreadystatechange = function () {
if (xhr.readyState === 4) {
// 判断成功
if (xhr.status >= 200 && xhr.status < 300) {
// 成功的结果
resolve(xhr.response)
} else {
reject(xhr.status)
}
}
}
})
}
// 调用
sendAJAX('https://api.apiopen.top/getJoke')
.then(value => {
console.log(value)
}, reason => {
console.warn(reason)
})
手写
Promise
开始手写之前我们需要先搞清楚 promise 的几个关键问题:
如何改变 promise 的状态?
- resolve(value):如果当前是 pending 就会变为 resolved
- reject(reason):如果当前是 pending 就会变为 rejected
- 抛出异常:如果当前是 pending 就会变为 rejected
一个 promise 指定(then方法)多个成功/失败回调函数,都会调用吗?
- 当 promise 改变为对应状态时都会调用
let p = new Promise((resolve, reject) => { resolve('ok') // 这里状态改变了,所以下边两个回调都会执行,如果状态不改变,下面的回调都不执行 }) // 指定回调 - 1 p.then(value => { console.log(value) }) // 指定回调 - 2 p.then(value => { alert(value) })改变 promise 状态和指定回调函数的顺序是什么样的,谁先执行,谁后执行?
问题简单描述:promise 代码在运行时,resolve/reject改变状态先执行,还是 then 方法指定回调先执行?
都有可能,正常情况下是先指定回调再改变状态,但也可以先改变状态再指定回调
当执行器函数中的任务是一个同步任务(直接调 resolve()/reject()) 的时候,先改变 promise 状态,再去指定回调函数*
当执行器函数中的任务是一个异步任务的时候,then 方法先执行(指定回调),改变状态后执行
// 这时是hen 方法先执行(指定回调),改变状态后执行 let p = new Promise((resolve, reject) => { setTimeout(() => { resolve('OK') }, 1000) }) p.then(value => { console.log(value) })
如何先改状态再指定回调?
- 在执行器中直接调用 resolve()/reject()
- 延迟更长时间才调用 then()
什么时候才能得到数据(回调函数什么时候执行)?
- 如果先指定的回调,那当状态发生改变时(调用resolve()/reject()时),回调函数就会调用,得到数据
- 如果先改变的状态,那当指定函数时(then 方法),回调函数就会调用,得到数据
promise.then() 返回的新 promise 的结果状态有什么决定?
- 简单表达:由 then() 指定的回调函数执行的结果决定
- 详细表达:
- 如果抛出异常,新 promise 变为 rejected,reason 为抛出的异常
- 如果返回的是非 promise 的任意值,新 promise 变为 resolved,value 为返回的值
- 如果返回的时另一个新的 promise,此 promise 的结果就会成为新 promise的结果
promise 如何串联多个操作任务?
- promise 的 then() 返回一个新的promise,可以看成 then() 的链式调用
- 通过 then 的链式调用串联多个同步/异步任务
promise异常穿透?
- 当使用 promise 的 then 链式调用时,可以在最后指定失败的回调,
- 前面任何操作除了异常,都会传到最后失败的回调中处理
中断 promise 链
- 当使用 promise 的 then 链式调用时,在中间中断,不再调用后面的回调函数
- 办法:在回调函数中返回一个 pending 状态的 promise 对象
let p = new Promise((resolve, reject) => { setTimeout(() => { resolve('OK') }, 1000) }) p.then(value => { console.log(111) return new Promise(() => {}) }).then(value => { console.log(222) })
函数方式:封装成一个构造函数
function Promise(executor) {
// 添加属性
this.PromiseState = 'pending'
this.PromiseResult = null
// 声明属性 因为实例对象不能直接调用onResolve跟onReject 所以下面then中需要先保存在callback里面
this.callbacks = []
// 保存实例对象的 this 的值
const self = this // 常见的变量名有self _this that
// resolve 函数
function resolve(data) {
// 判断状态
if (self.PromiseState !== 'pending') return
// console.log(this) => 这里的this指向window,下面用this的话时直接修改的window
// 1. 修改对象的状态 (PromiseState)
self.PromiseState = 'fulfilled'
// 2. 设置对象结果值 (PromiseResult)
self.PromiseResult = data
// 调用成功的回调函数
setTimeout(() => {
self.callbacks.forEach((item) => {
item.onResolved(data)
})
})
}
// reject 函数
function reject(data) {
// 判断状态
if (self.PromiseState !== 'pending') return
// 1. 修改对象的状态 (PromiseState)
self.PromiseState = 'rejected'
// 2. 设置对象结果值 (PromiseResult)
self.PromiseResult = data
// 调用失败的回调函数
setTimeout(() => {
self.callbacks.forEach((item) => {
item.onRejected(data)
})
})
}
try {
// 同步调用【执行器函数】
executor(resolve, reject)
} catch (e) {
// 修改 promise 对象状态
reject(e)
}
}
// 添加 then 方法
Promise.prototype.then = function (onResolved, onRejected) {
const self = this
// 判断回调函数参数
if (typeof onRejected !== 'function') {
onRejected = (reason) => {
throw reason
}
}
if (typeof onResolved !== 'function') {
onResolved = (value) => value
}
return new Promise((resolve, reject) => {
// 封装函数
function callback(type) {
try {
// 获取回调函数的执行结果
let result = type(self.PromiseResult)
// 判断
if (result instanceof Promise) {
result.then(
(v) => {
resolve(v)
},
(r) => {
reject(r)
}
)
} else {
// 结果的对象状态为 【成功】
resolve(result)
}
} catch (e) {
reject(e)
}
}
// 调用回调函数 根据 PromiseState 去调用
if (this.PromiseState === 'fulfilled') {
setTimeout(() => {
callback(onResolved)
})
}
if (this.PromiseState === 'rejected') {
setTimeout(() => {
callback(onRejected)
})
}
// 判断 pending 状态
if (this.PromiseState === 'pending') {
// 保存回调函数
this.callbacks.push({
onResolved: function () {
callback(onResolved)
},
onRejected: function () {
callback(onRejected)
},
})
}
})
}
// 添加 catch 方法
Promise.prototype.catch = function (onRejected) {
return this.then(undefined, onRejected)
}
// 添加 resolve 方法
Promise.resolve = function (value) {
return new Promise((resolve, reject) => {
if (value instanceof Promise) {
value.then(
(v) => {
resolve(v)
},
(r) => {
reject(r)
}
)
} else {
// 状态设置为成功
resolve(value)
}
})
}
// 添加 reject 方法
Promise.reject = function (reason) {
return new Promise((resolve, reject) => {
reject(reason)
})
}
// 添加 all 方法
Promise.all = function (promises) {
// 声明变量
let count = 0 // 计数
let arr = [] // 结果数组
// 遍历
return new Promise((resolve, reject) => {
for (let i = 0; i < promises.length; i++) {
promises[i].then(
(v) => {
// 得知对象的状态是成功
// 每个promise对象成功都加 1
count++
// 将当前每个promise对象成功的结果都存入到数组中
arr[i] = v
// 判断
if (count === promises.length) {
// 修改状态
resolve(arr)
}
},
(r) => {
reject(r)
}
)
}
})
}
// 添加 race 方法
Promise.race = function (promises) {
return new Promise((resolve, reject) => {
for (var i = 0; i < promises.length; i++) {
promises[i].then(
(v) => {
// 修改返回对象的状态为成功
resolve(v)
},
(r) => {
// 修改返回对象的状态为成功
reject(r)
}
)
}
})
}
class 类的方式:封装成一个类
// 封装成类
class Promise {
//构造方法
constructor(executor) {
// 添加属性
this.PromiseState = 'pending'
this.PromiseResult = null
// 声明属性 因为实例对象不能直接调用onResolve跟onReject 所以下面then中需要先保存在callback里面
this.callbacks = []
// 保存实例对象的 this 的值
const self = this // 常见的变量名有self _this that
// resolve 函数
function resolve(data) {
// 判断状态
if (self.PromiseState !== 'pending') return
// console.log(this) => 这里的this指向window,下面用this的话时直接修改的window
// 1. 修改对象的状态 (PromiseState)
self.PromiseState = 'fulfilled'
// 2. 设置对象结果值 (PromiseResult)
self.PromiseResult = data
// 调用成功的回调函数
setTimeout(() => {
self.callbacks.forEach((item) => {
item.onResolved(data)
})
})
}
// reject 函数
function reject(data) {
// 判断状态
if (self.PromiseState !== 'pending') return
// 1. 修改对象的状态 (PromiseState)
self.PromiseState = 'rejected'
// 2. 设置对象结果值 (PromiseResult)
self.PromiseResult = data
// 调用失败的回调函数
setTimeout(() => {
self.callbacks.forEach((item) => {
item.onRejected(data)
})
})
}
try {
// 同步调用【执行器函数】
executor(resolve, reject)
} catch (e) {
// 修改 promise 对象状态
reject(e)
}
}
// then 方法封装
then(onResolved, onRejected) {
const self = this
// 判断回调函数参数
if (typeof onRejected !== 'function') {
onRejected = (reason) => {
throw reason
}
}
if (typeof onResolved !== 'function') {
onResolved = (value) => value
}
return new Promise((resolve, reject) => {
// 封装函数
function callback(type) {
try {
// 获取回调函数的执行结果
let result = type(self.PromiseResult)
// 判断
if (result instanceof Promise) {
result.then(
(v) => {
resolve(v)
},
(r) => {
reject(r)
}
)
} else {
// 结果的对象状态为 【成功】
resolve(result)
}
} catch (e) {
reject(e)
}
}
// 调用回调函数 根据 PromiseState 去调用
if (this.PromiseState === 'fulfilled') {
setTimeout(() => {
callback(onResolved)
})
}
if (this.PromiseState === 'rejected') {
setTimeout(() => {
callback(onRejected)
})
}
// 判断 pending 状态
if (this.PromiseState === 'pending') {
// 保存回调函数
this.callbacks.push({
onResolved: function () {
callback(onResolved)
},
onRejected: function () {
callback(onRejected)
},
})
}
})
}
// catch 方法
catch(onRejected) {
return this.then(undefined, onRejected)
}
// resolve 方法
static resolve(value) {
return new Promise((resolve, reject) => {
if (value instanceof Promise) {
value.then(
(v) => {
resolve(v)
},
(r) => {
reject(r)
}
)
} else {
// 状态设置为成功
resolve(value)
}
})
}
// reject 方法
static reject(reason) {
return new Promise((resolve, reject) => {
reject(reason)
})
}
// all 方法
static all(promises) {
// 声明变量
let count = 0 // 计数
let arr = [] // 结果数组
// 遍历
return new Promise((resolve, reject) => {
for (let i = 0; i < promises.length; i++) {
promises[i].then(
(v) => {
// 得知对象的状态是成功
// 每个promise对象成功都加 1
count++
// 将当前每个promise对象成功的结果都存入到数组中
arr[i] = v
// 判断
if (count === promises.length) {
// 修改状态
resolve(arr)
}
},
(r) => {
reject(r)
}
)
}
})
}
//race 方法
static race(promises) {
return new Promise((resolve, reject) => {
for (var i = 0; i < promises.length; i++) {
promises[i].then(
(v) => {
// 修改返回对象的状态为成功
resolve(v)
},
(r) => {
// 修改返回对象的状态为成功
reject(r)
}
)
}
})
}
}
async
和
await
- async/await是消灭异步回调的终极武器(以同步的流程,书写异步的代码)
- 作用: 简化promise对象的使用, 不用再使用then/catch来指定回调函数
- 但和Promise并不互斥
- 反而, 两者相辅相成
- 执行async函数, 返回promise对象
- await相当于promise的then
- try...catch可捕获异常, 相当于promise的catch
async 函数
- 函数的返回值为 promise 对象
- promise 对象的结果由 async 函数执行的返回值决定
await 表达式
- await 右侧的表达式一般为 promise 对象,但也可以时其它的值
- 如果表达式是 promise 对象,await 返回的是 promise 成功的值
- 如果表达式是其它值,直接将此值作为 await 的返回值Ï
async 和 await结合使用示例:
// resource 1.html 2.html 3.html
const fs = require('fs')
// 回调函数的方式
fs.readFile('./resousrce/1.html', (err, data1) => {
if (err) throw err
fs.readFile('./resousrce/2.html', (err, data2) => {
if (err) throw err
fs.readFile('./resousrce/3.html', (err, data3) => {
if (err) throw err
console.log(data1 + data2 + data3)
})
})
})
// resource 1.html 2.html 3.html
const fs = require('fs')
const util = require('util')
const mineReadFile = util.pomiseify(fs.readFile)
// async 与 await 结合
async function main() {
try {
// 读取第一个文件的内容
let data1 = await mineReadFile('./resourse/1.html')
let data2 = await mineReadFile('./resourse/2.html')
let data3 = await mineReadFile('./resourse/3.html')
console.log(data1 + data2 + data3)
}catch(e) {
console.log(e)
}
}
main()
// async 与 await 结合发送 Ajax 请求
function sendAJAX(url) {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest()
// 设置响应数据格式
xhr.responseType = 'json'
xhr.open('GET', url)
xhr.send();
// 处理结果
xhr.onreadystatechange = function () {
if (xhr.readyState === 4) {
// 判断成功
if (xhr.status >= 200 && xhr.status < 300) {
// 成功的结果
resolve(xhr.response)
} else {
reject(xhr.status)
}
}
}
})
}
// 段子接口地址:https://api.apiopen.top/getJoke
let btn = document.querySelector('#btn')
btn.addEventListener('click', async function () {
// 获取段子信息
let duanzi = await sendAJAX('https://api.apiopen.top/getJoke')
console.log(duanzi)
})
写在后面
前端的东西其实很多并不难,只是很多人很少去深究,去全面了解,大家都只是学个大概,会用就行;
本系列文章将会全面深入的带你重新夯实前端基础,把一些重要且常用的知识点深入讲解;
希望看完文章的你能有所收货,使用起来更加轻松,面试更加自如亮眼;
我相信能看到这里的人呢,都是想进步想成长的小伙伴,希望在工作小伙伴的升职加薪,在找工作的小伙伴面试顺利,收割offer;
对你有帮助的话给作者点点关注吧,你的支持就是我创作的动力!Peace and love~~
音乐分享
不知道有没有喜欢说唱的小伙伴,作者有个想法,每期文章最后分享一首觉得不错的说唱,当然你觉得好听的歌曲也可以评论区分享给大家。
本期歌曲:《ghost face》—— 法老
- 最喜欢的一句词:一个穷孩子生活在有钱人的城市,尝试用精神去对抗物质。