论文阅读翻译之Deep reinforcement learning from human preferences
论文阅读翻译之Deep reinforcement learning from human preferences
关于
- 首次发表日期:2024-09-11
- 论文原文链接:
https://arxiv.org/abs/1706.03741 - 论文arxiv首次提交日期:12 Jun 2017
- 使用KIMI,豆包和ChatGPT等机翻,然后人工润色
- 如有错误,请不吝指出
Deep reinforcement learning from human preferences(基于人类偏好的深度强化学习)
Abstract (摘要)
对于复杂的强化学习(RL)系统来说,要与现实世界环境有效互动,我们需要向这些系统传达复杂目标。在这项工作中,我们探索了以(非专家)人类对轨迹段对的偏好来定义目标。我们展示了这种方法可以在没有奖励函数的情况下有效解决复杂的RL任务,包括Atari游戏和模拟机器人运动,同时仅需对不到1%的代理与环境交互提供反馈。这大大降低了人类监督的成本,使其能够实际应用于最先进的强化学习系统。为了展示我们方法的灵活性,我们表明可以在大约一小时的人类参与时间内成功训练出复杂的新行为。这些行为和环境比以往任何从人类反馈中学到的都要复杂得多。
1 Introduction (引言)
最近在将强化学习 (RL) 扩展到大规模问题上取得的成功,主要得益于那些具有明确奖励函数的领域(Mnih等, 2015, 2016; Silver等, 2016)。不幸的是,许多任务的目标是复杂的、定义不清的或难以明确说明的。克服这一限制将大大扩展深度强化学习的潜在影响,并可能进一步扩大机器学习的应用范围。
例如,假设我们想使用强化学习训练一个机器人来清洁桌子或炒鸡蛋。如何构建一个合适的奖励函数并不明确,而这个奖励函数需要依赖机器人的传感器数据。我们可以尝试设计一个简单的奖励函数,大致捕捉预期的行为(intended behavior),但这通常会导致机器人行为优化我们的奖励函数,但机器人行为并实际上却不符合我们的偏好。这种困难是构成近期关于我们价值观(values)与强化学习系统目标不一致的基础(Bostrom, 2014; Russell, 2016; Amodei等, 2016)。如果我们能够成功地向智能体(agent)传达我们的实际目标,将是解决这些问题的关键一步。
如果我们拥有所需任务的示范,就可以通过逆向强化学习 (Ng 和 Russell, 2000) 提取一个奖励函数,然后使用该奖励函数来训练通过强化学习训练一个智能体。更直接的方式是使用模仿学习(imitation learning)来复制示范的行为。然而,这些方法并不适用于人类难以演示的行为(例如控制一个具有多自由度且形态与人类差异很大的机器人)。
另一种方法是允许人类对系统当前的行为提供反馈,并利用这些反馈来定义任务。原则上,这符合强化学习的范式,但直接将人类反馈作为奖励函数对于需要数百或数千小时经验的强化学习系统来说成本过高。为了能够在实际上基于人类反馈训练深度强化学习系统,我们需要将所需反馈的量减少几个数量级。
我们的方法是从人类反馈中学习奖励函数,然后优化这个奖励函数。这种基本方法之前已经被考虑过,但我们面对的是如何将其扩展到现代深度强化学习中的挑战,并展示了迄今为止从人类反馈中学到的最复杂的行为。
总之,我们希望找到一个解决方案来处理没有明确指定奖励函数的顺序决策问题,这个解决方案应该满足以下条件:
- 能够解决我们只能
识别
期望行为但不一定能够示范的任务, - 允许非专家用户教导智能体,
- 能够扩展到大型问题,且
- 在用户反馈方面经济高效。
我们的算法在训练策略优化当前预测的奖励函数的同时,根据人类的偏好拟合一个奖励函数(见图1)。我们要求人类比较智能体行为的短视频片段,而不是提供绝对的数值评分。我们发现,在某些领域,进行比较对人类来说更容易,同时在学习人类偏好时同样有效。比较短视频片段的速度几乎与比较单个状态一样快,但我们证明,这种比较方式显著更有帮助。此外,我们还表明,在线收集反馈能够提高系统性能,并防止它利用所学奖励函数的漏洞。
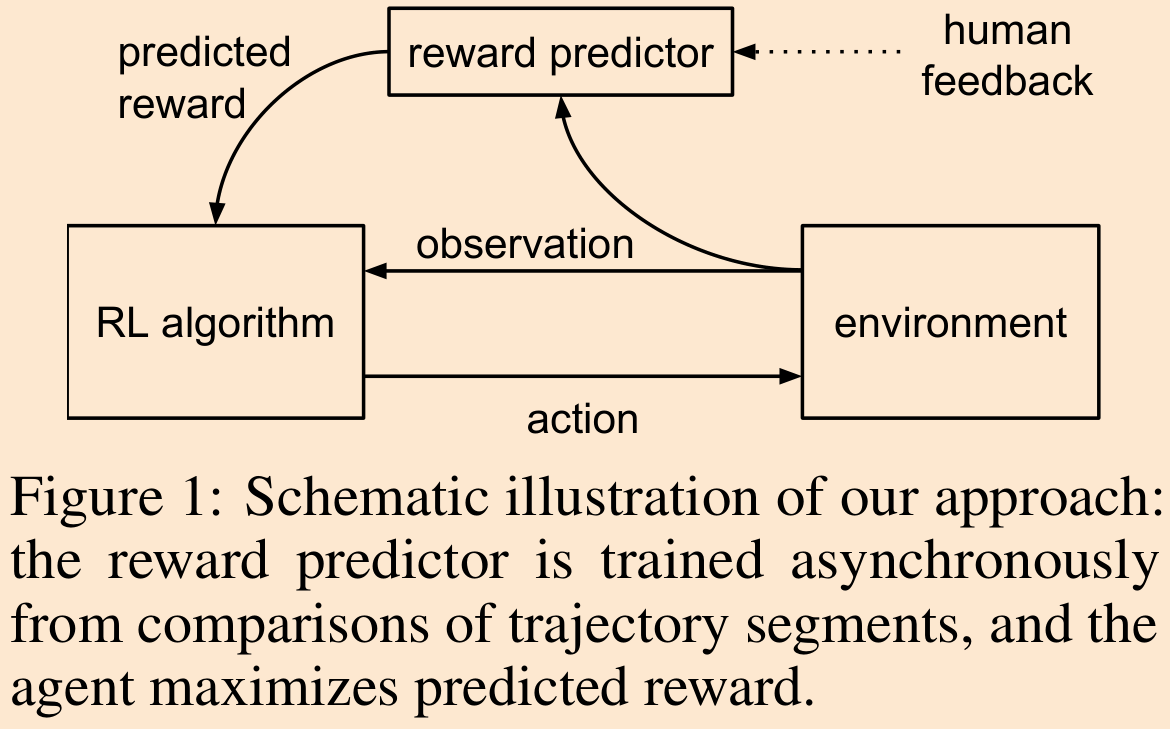
我们的实验在两个领域进行:Arcade Learning Environment(Bellemare等, 2013)中的Atari游戏,以及物理模拟器MuJoCo(Todorov等, 2012)中的机器人任务。我们展示了即使是非专家人类提供的少量反馈,从十五分钟到五小时不等,也足以学习大多数原始的强化学习任务,即使奖励函数不可观察。随后我们在每个领域中考虑了一些新行为,例如完成后空翻或按照交通流向驾驶。我们证明了我们的算法能够通过大约一小时的反馈学习这些行为——即使很难通过手工设计奖励函数来激励这些行为。
1.1 Related Work(相关研究)
大量研究探索了基于人类评分或排序的强化学习,包括 Akrour 等 (2011)、Pilarski 等 (2011)、Akrour 等 (2012)、Wilson 等 (2012)、Sugiyama 等 (2012)、Wirth 和 Fürnkranz (2013)、Daniel 等 (2015)、El Asri 等 (2016)、Wang 等 (2016) 和 Wirth 等 (2016)。另一些研究则关注从偏好而非绝对奖励值出发的强化学习问题 (Fürnkranz 等, 2012; Akrour 等, 2014),以及在非强化学习环境中通过人类偏好进行优化的研究 (Machwe 和 Parmee, 2006; Secretan 等, 2008; Brochu 等, 2010; Sørensen 等, 2016)。
我们的算法遵循与Akrour等人(2012)和Akrour等人(2014)相同的基本方法。他们研究了四个自由度的连续域和小的离散域,在这些域中,他们可以假设奖励在手编码特征的期望中是线性的。我们则研究具有几十个自由度的物理任务和没有手工设计特征的 Atari 任务;我们环境的复杂性迫使我们使用不同的强化学习算法和奖励模型,并应对不同的算法权衡。一个显著的区别在于,Akrour等人(2012)和Akrour等人(2014)是从整个轨迹中获取偏好,而不是短片段。因此,虽然我们收集了多两个数量级的比较,但我们的实验所需的人类时间少于一个数量级。其他区别主要在于调整我们的训练程序,以应对非线性奖励模型和现代深度强化学习,例如使用异步训练和集成方法。
我们对反馈引导的方法与 Wilson 等人 (2012) 的研究非常接近。然而,Wilson 等人 (2012) 假设奖励函数是到某个未知“目标”策略的距离(该策略本身是手工编码特征的线性函数)。他们通过贝叶斯推理拟合这个奖励函数,而不是执行强化学习,他们根据目标策略的最大后验估计 (MAP) 生成轨迹。他们的实验涉及的是从其贝叶斯模型中抽取的“合成”人类反馈,而我们进行了从非专家用户收集反馈的实验。目前尚不清楚 Wilson 等人 (2012) 的方法是否可以扩展到复杂任务,或是否能够处理真实的人类反馈。
MacGlashan 等 (2017)、Pilarski 等 (2011)、Knox 和 Stone (2009)、以及 Knox (2012) 进行了一些涉及基于真实人类反馈的强化学习实验,尽管他们的算法方法并不十分相似。在 MacGlashan 等 (2017) 和 Pilarski 等 (2011) 的研究中,学习仅在人工训练者提供反馈的回合(episodes)中进行。这在像 Atari 游戏这样的领域似乎是不可行的,因为学习高质量策略需要数千小时的经验,即使对于我们考虑的最简单任务,这种方法的成本也过于昂贵。TAMER(Knox, 2012; Knox 和 Stone, 2013)也学习奖励函数,但他们考虑的是更简单的设置(settings),在这些设置中,期望的策略可以相对快速地学习。
我们的工作也可以看作是合作逆向强化学习框架( cooperative inverse reinforcement learning framework)(Hadfield-Menell 等, 2016)的一个特定实例。这个框架考虑了一个人类和机器人在环境中互动的两人游戏,目的是最大化人类的奖励函数。在我们的设置中,人类只能通过表达他们的偏好来与这个游戏进行互动。
与之前的所有工作相比,我们的关键贡献是将人类反馈扩展到深度强化学习,并学习更复杂的行为。这符合将奖励学习方法扩展到大型深度学习系统的最新趋势,例如逆强化学习(Finn等人,2016年)、模仿学习(Ho和Ermon,2016年;Stadie等人,2017年)、半监督技能泛化(Finn等人,2017年)以及从示范中引导强化学习(Silver等人,2016年;Hester等人,2017年)。
2 Preliminaries and Method(预备知识与方法)
2.1 Setting and Goal(配置与目标)
我们考虑一个智能体在一系列步骤中与环境进行交互;在每个时刻
\(t\)
,智能体从环境中接收观察
\(o_t \in \mathcal{O}\)
,然后向环境发送动作
\(a_t \in \mathcal{A}\)
。
在传统的强化学习中,环境还会提供奖励
\(r_t \in \mathbb{R}\)
,智能体的目标是最大化奖励的折扣和(discounted sum of rewards)。与假设环境生成奖励信号不同,我们假设有一位人类监督者可以在
轨迹片段
(trajectory segments)之间表达偏好。轨迹片段是观察和动作的序列,
\(\sigma=\left(\left(o_0, a_0\right),\left(o_1, a_1\right), \ldots,\left(o_{k-1}, a_{k-1}\right)\right) \in(\mathcal{O} \times \mathcal{A})^k\)
。我们用
\(\sigma^1 \succ \sigma^2\)
表示人类更偏好轨迹片段
\(\sigma^1\)
而非轨迹片段
\(\sigma^2\)
。非正式地说,智能体的目标是生成人类偏好的轨迹,同时尽量减少向人类询问的次数。
更确切地说,我们将通过两种方式评估我们算法的行为:
定量:
我们说偏好
\(\succ\)
是由一个奖励函数
[1]
\(r: \mathcal{O} \times \mathcal{A} \rightarrow \mathbb{R}\)
生成的,如果
\]
每当
\]
如果人类的偏好是由奖励函数
\(r\)
生成的,那么我们的智能体应当根据
\(r\)
获得高的总奖励。因此,如果我们知道奖励函数
\(r\)
,我们就能对代理进行量化评估。理想情况下,代理应达到的奖励几乎与其使用强化学习来优化
\(r\)
时一样高。
定性
:有时我们没有奖励函数来对行为进行定量评估(这正是我们的方法在实际中有用的情况)。在这些情况下,我们只能定性地评估智能体满足人类偏好的程度。在本文中,我们将从一个用自然语言表达的目标开始,要求人类根据智能体实现该目标的情况来评估智能体的行为,然后展示智能体尝试实现该目标的视频。
我们的基于轨迹片段比较的模型与 Wilson 等人 (2012) 中使用的轨迹偏好查询非常相似,不同之处在于我们不假设可以将系统重置为任意状态
[2]
,并且我们的片段通常从不同的状态开始。这使得人类比较的解释(interpretation of human comparisons)变得更加复杂,但我们展示了即使人类评分者对我们的算法不了解,我们的算法也能够克服这一难题。
2.2 Our Method(我们的方法)
在每个时刻,我们的方法维持一个策略
\(\pi: \mathcal{O} \rightarrow \mathcal{A}\)
和一个奖励函数估计
\(\hat{r}: \mathcal{O} \times \mathcal{A} \rightarrow \mathbb{R}\)
,它们均由深度神经网络参数化。
这些网络通过三个过程进行更新:
- 策略
\(\pi\)
与环境交互,生成一组轨迹
\(\left\{\tau^1, \ldots, \tau^i\right\}\)
。使用传统的强化学习算法更新
\(\pi\)
的参数,以最大化预测奖励的总和
\(r_t=\hat{r}\left(o_t, a_t\right)\)
。 - 从步骤1生成的轨迹
\(\left\{\tau^1, \ldots, \tau^i\right\}\)
中选择片段对
\(\left(\sigma^1, \sigma^2\right)\)
,并将它们发送给人类进行比较。 - 通过监督学习优化映射
\(\hat{r}\)
的参数,以拟合迄今为止从人类收集的比较结果。
2.2.1 Optimizing the Policy (对策略进行优化)
在使用
\(\hat{r}\)
计算奖励后,我们面临的是一个传统的强化学习问题。我们可以使用任何适合该领域的强化学习算法来解决这个问题。一个细微之处在于,奖励函数
\(\hat{r}\)
可能是非平稳的(non-stationary),这使我们倾向于选择对奖励函数变化具有鲁棒性的算法。这导致我们专注于策略梯度方法(policy gradient methods),这些方法已经成功应用于这类问题(Ho 和 Ermon, 2016)。
在本文中,我们使用
优势演员-评论员(advantage actor-critic)
(A2C;Mnih 等, 2016)来玩 Atari 游戏,并使用
信赖域策略优化(trust region policy optimization)
(TRPO;Schulman 等, 2015)来执行模拟机器人任务。在每种情况下,我们都使用了被发现对传统强化学习任务有效的参数设置。我们唯一调整的超参数是 TRPO 的熵奖励(entropy bonus),因为 TRPO 依赖信赖域来确保足够的探索,如果奖励函数不断变化,这可能导致探索不足。
我们将
\(\hat{r}\)
生成的奖励归一化(normalized)为均值为零、标准差恒定。这是一个典型的预处理步骤,尤其适合于我们的学习问题,因为奖励的位置(position of the rewards)在我们的学习过程中是未定的。
2.2.2 Preference Elicitation(偏好获取)
人类监督者会看到两个可视化的轨迹片段,以短视频片段的形式呈现。在我们所有的实验中,这些视频片段的时长在 1 到 2 秒之间。
然后,人类指示他们更喜欢哪个片段,或者表示两个片段同样优秀,或者表示他们无法比较这两个片段。
人类的判断记录在数据库
\(\mathcal{D}\)
中,形式为三元组
\(\left(\sigma^1, \sigma^2, \mu\right)\)
,其中
\(\sigma^1\)
和
\(\sigma^2\)
是两个片段,
\(\mu\)
是一个在
\(\{1,2\}\)
上的分布,表示用户更喜欢哪个片段。如果人类选择一个片段为更优,则
\(\mu\)
将所有权重放在该选择上。如果人类标记这两个片段为同样可取,则
\(\mu\)
是均匀分布。最后,如果人类标记这两个片段不可比较,则该比较将不包含在数据库中。
2.2.3 Fitting the Reward Function (拟合奖励函数)
我们可以将奖励函数估计
\(\hat{r}\)
视为一个偏好预测器,如果我们将
\(\hat{r}\)
看作解释人类判断的潜在因素,并假设人类选择偏好片段
\(\sigma^i\)
的概率呈指数地取决于在片段长度上潜在奖励的合计值:
[3]
\tag{1}
\]
我们选择
\(\hat{r}\)
以最小化这些预测与实际人类标签之间的交叉熵损失:
\]
这遵循了从成对偏好估计评分函数Bradley-Terry模型(Bradley和Terry,1952),并且是Luce-Shephard选择规则(Luce,2005;Shepard,1957)在轨迹片段上的偏好的特化。它可以理解为将奖励等同于一个偏好排序尺度(preference ranking scale),类似于为国际象棋开发的著名的 Elo 排名系统(Elo,1978)。就像两个国际象棋棋手的 Elo 分数之差估计了一个棋手在一盘国际象棋比赛中击败另一个棋手的概率一样,两个轨迹片段的预测奖励之差估计了人类选择一个而不是另一个的概率。
我们实际的算法对这个基本方法进行了一些修改,早期实验发现这些修改很有帮助,并在第3.3节中进行了分析:
- 我们拟合一个预测器的集合(ensemble),每个预测器都是在从
\(\mathcal{D}\)
中抽样的
\(|\mathcal{D}|\)
个三元组上训练的(允许重复抽样)。估计值
\(\hat{r}\)
通过独立地对每个预测器进行归一化,然后对结果取平均来定义。 - 数据中有
\(1/e\)
的部分被保留,作为每个预测器的验证集。我们使用
\(\ell_2\)
正则化,并调整正则化系数,以保持验证损失在训练损失的1.1到1.5倍之间。在某些领域,我们还应用 dropout 进行正则化。 - 我们不是像公式 1 中描述的那样直接应用 softmax,而是假设人类有 10%的概率随机均匀地(uniformly)做出响应。概念上,这种调整是必要的,因为人类评估者有一个固定的犯错误概率,这个概率不会随着奖励差异变得极端而衰减至0。
2.2.4 Selecting Queries (选择查询)
我们根据奖励函数估计器的不确定性近似来决定如何查询偏好,这类似于Daniel等人(2014)的方法:我们采样大量的长度为
\(k\)
的轨迹片段对,使用我们集合中的每个奖励预测器来预测每一对中哪个片段会被偏好,然后选择那些在集合成员之间预测方差最高的轨迹。这是一种粗糙的近似,第三节中的消融实验表明,在某些任务中它实际上损害了性能。理想情况下,我们希望基于查询的信息价值来查询(Akrour等人, 2012; Krueger等人, 2016),但我们留待未来的工作进一步探索这一方向。