18 Python如何操作文件?
本篇是 Python 系列教程第 18 篇,更多内容敬请访问我的 Python 合集
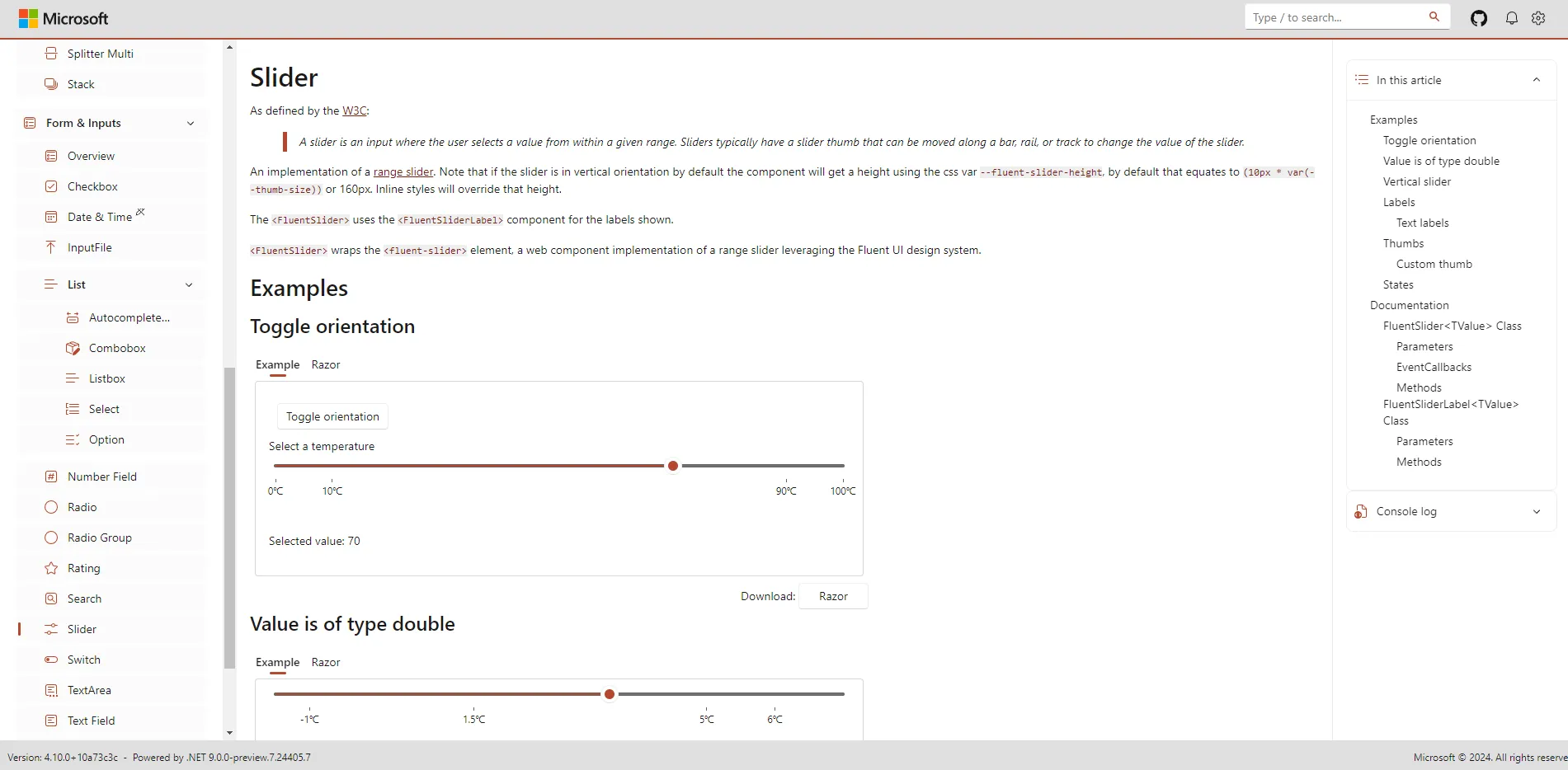
1 打开文件
通常使用内置的
open(文件路径, 模式, encoding="utf-8")
函数。
- 文件路径:可以是相对路径或绝对路径。
- 模式:(可选)决定了文件打开后如何处理文件。
- encoding:(可选)编码方式。
常见的模式有:
- 'r' (默认):只读模式,如果文件不存在,则会引发 FileNotFoundError。
- 'w':写入模式,如果文件存在则会清空内容再写入,如果文件不存在则创建新文件。
- 'a':追加模式,在文件末尾追加内容,如果文件不存在则创建新文件。
- 'b':二进制模式,用于处理二进制文件(如图像、音频等)。
- '+':更新模式,用于同时进行读写操作。
可以将这些模式组合起来使用,例如:
- 'rb':以二进制模式读取文件。
- 'wb':以二进制模式写入文件。
- 'ab':以二进制模式追加内容到文件。
- 'r+':读写模式,可以读取和写入文件。
- 'w+':写入并读取模式,先写入后读取。
- 'a+':追加并读取模式,先追加后读取。
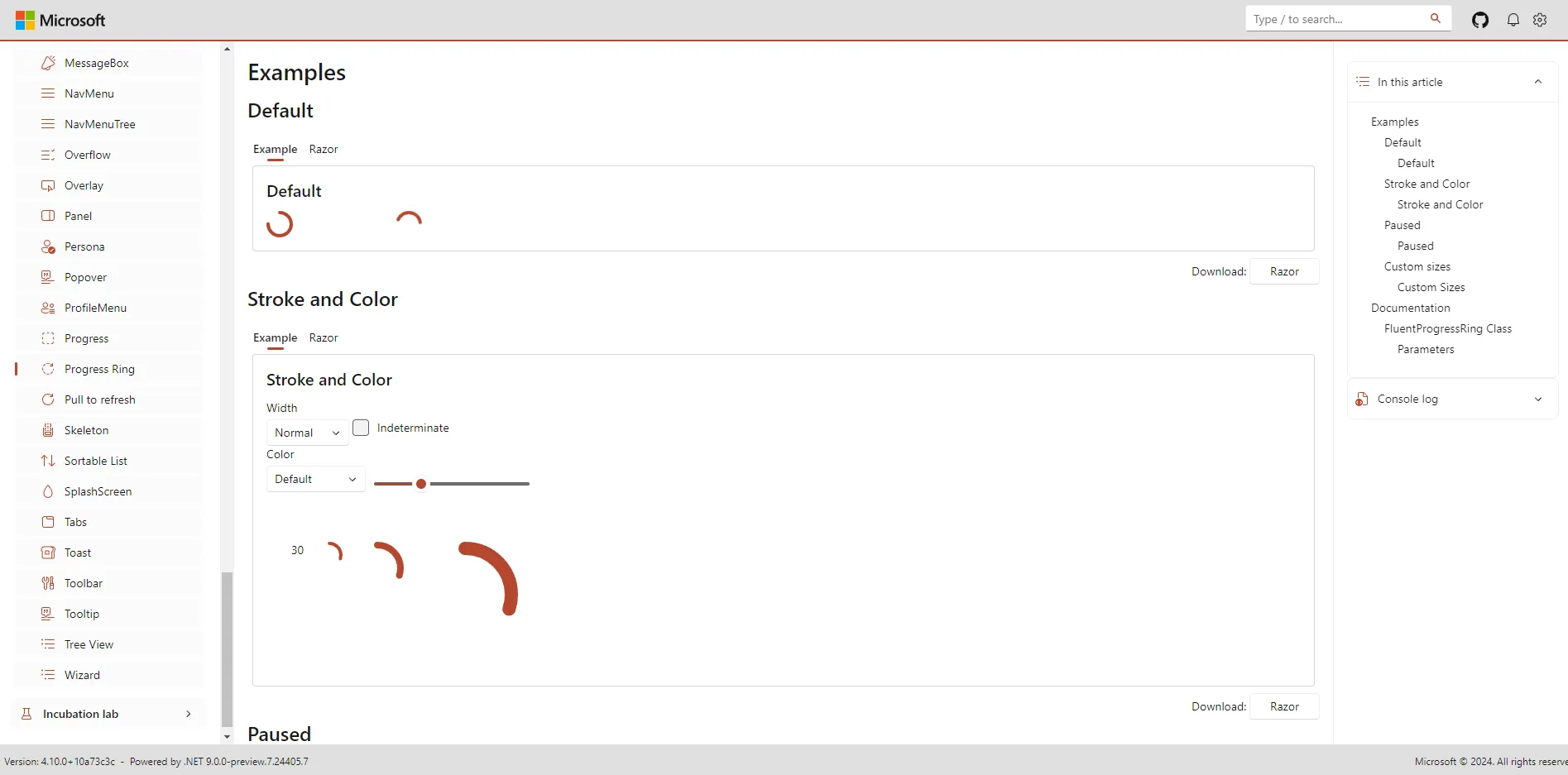
2 文件读取
如果
open()
函数执行成功,会返回一个文件对象。后续可以对这个对象进行读取或写入操作。
f = open('./data.txt', 'r', encoding='utf-8')
文件对象有个
read()
方法,会一次性读取文件里的所有内容,并返回字符串格式。
实例:
file = open('data.txt', 'r', encoding="utf-8")
print(file.read())
注意:
- 如果调用过
read()
后再次调用,会返回空,因为程序会记录文件被读取的位置,第一次
read()
时已经读到文件末尾,第二次
read()
后面就没有内容了。 - 大文件也不适合用
read()
,因为会一次性读取文件的所有内容,可能挤爆内存。
上面说大文件不适合用
read()
,那有别的替换方案吗?当然有,解决方案就是一次性只读取部分内容,如:
- 给
read()
传一个数字参数如
read(1024)
,表示一次读多少字节,下次再调用
read(1024)
时就会继续从上次的结束位置读取。 - 使用
readline()
,此方法一次只会读取一行内容,是根据换行符来判断本行结尾的,而且换行符也会被当做内容的一部分被读取。
上面的两种方式可搭配
while
循环来用,另外还有一个
readlines()
方法,会一次性返回所有行,组成一个字符串列表,一般搭配
for
循环使用。
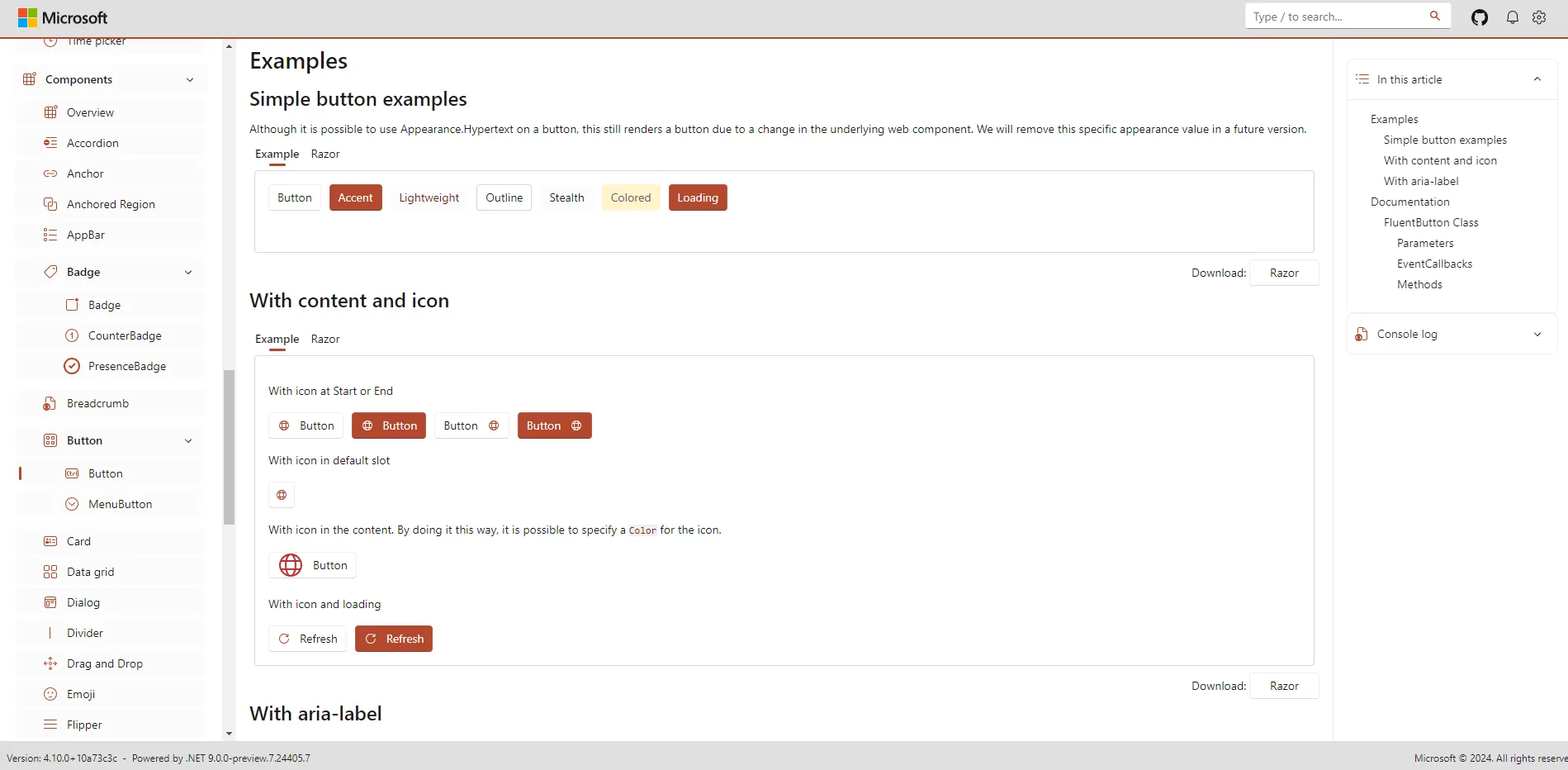
3 文件写入
调用
open()
函数时第二个参数传
w
或
a
就可以进行文件写入操作。这里说明一点,如果第二个参数是
r
,且文件不存在就会报
FileNotFoundError
错误,但是
w
或
a
就不会报错,它会自动创建一个文件。
在打开或创建文件之后就可以调用文件对象的
write()
方法进行写入操作了。
示例:
with open('data.txt', 'w', encoding="utf-8") as file:
file.write("hello ")
file.write("python")
data.txt内容:
hello python
注意
write()
方法并不会自动换行,需要手动添加换行符,如把代码改成
file.write("hello\n")
,data.txt就会变成:
hello
python
如果我们使用
w
模式,文件就只能写入不能读取,如果我们想先读取再写入,可以用
r+
模式
4 关闭文件
文件操作完毕后,文件对象需要调用一个
close()
方法关闭文件释放资源。
每次文件操作完毕后都应该关闭文件,但是有可能会粗心忘记关闭,怎么办呢?我们可以在调用
open()
函数打开文件的时候使用
with
关键字,然后用
as
指定读取到的文件,这样在
with
代码块执行完后文件就会被自动关闭了,实例:
# 使用 with 语句来读取文件
with open('data.txt', 'r', encoding='utf-8') as file:
for line in file.readlines():
print(line.strip())