写在前面
Spring的核心思想就是容器,当容器refresh的时候,外部看上去风平浪静,其实内部则是一片惊涛骇浪,汪洋一片。Springboot更是封装了Spring,遵循约定大于配置,加上
自动装配的机制
。很多时候我们只要引用了一个依赖,几乎是零配置就能完成一个功能的装配。
由spring提供的、在容器或bean生命周期各个阶段、供spring框架回调使用的函数方法,即为扩展点。扩展点体现了Spring框架的灵活性、业务亲和性。使开发人员可以在不修改spring源码的情况下,对容器和bean的行为、属性进行额外的管理。
想要把
自动装配
玩的转,就必须要了解spring对于
bean的构造生命周期
以及各个扩展接口,当然了解了bean的各个生命周期也能促进我们加深对spring的理解。业务代码也能合理利用这些扩展点写出更优雅的代码。
在网上搜索spring扩展点,发现很少有博文说的很全的,只有一些常用的扩展点的说明。所以在这篇文章里,我总结了几乎Spring & Springboot所有的扩展接口,各个扩展点的使用场景,并整理出一个bean在spring中从被加载到初始化到销毁的所有可扩展点的顺序调用图。
本文不讲原理,只将扩展点与使用方式讲清楚,特别是调用顺序,原理可以移步
IOC系列文章
,
Bean的生命周期
,后续会不断更新对应原理及源码解析。大家可以
把这篇文章当成一个工具书
,当忘了执行顺序时,或者忘了如何使用这个扩展方式时,可以再回过头来看看。
ApplicationContextInitializer
org.springframework.context.ApplicationContextInitializer
介绍
这是整个spring容器在刷新之前初始化
ConfigurableApplicationContext
的回调接口,简单来说,就是在
容器刷新refresh之前调用
此类的
initialize
方法。这个接口的主要目的是在 Spring 应用上下文初始化的早期阶段进行一些配置或调整,以便在上下文加载后可以使用这些配置。
此接口,
Spring Framework
自己没有提供任何的实现类,但在
SpringBoot
对它有较多的扩展实现。
使用场景
- 在应用启动时进行环境配置:可以使用
ApplicationContextInitializer
来在应用上下文初始化时进行一些环境相关的配置,例如设置系统属性、加载外部配置文件等。
public class EnvironmentInitializer implements ApplicationContextInitializer<ConfigurableApplicationContext> {
@Override
public void initialize(ConfigurableApplicationContext applicationContext) {
ConfigurableEnvironment environment = applicationContext.getEnvironment();
environment.setActiveProfiles("development");
System.out.println("配置文件设置为development");
}
}
- 注册自定义的
BeanFactoryPostProcessor
或者
BeanPostProcessor
:
ApplicationContextInitializer
可以用来注册自定义的
BeanFactoryPostProcessor
或者
BeanPostProcessor
,以便在 Bean 初始化之前或之后进行某些自定义处理。
public class CustomBeanFactoryPostProcessorInitializer implements ApplicationContextInitializer<ConfigurableApplicationContext> {
@Override
public void initialize(ConfigurableApplicationContext applicationContext) {
applicationContext.addBeanFactoryPostProcessor(beanFactory -> {
// 添加自定义的 BeanFactoryPostProcessor
System.out.println("添加了自定义BeanFactory后处理器...");
});
}
}
- 动态地添加
PropertySource
:可以在初始化过程中动态地添加
PropertySource
,以便后续的 Bean 定义和初始化过程中可以使用这些属性。
public class PropertySourceInitializer implements ApplicationContextInitializer<ConfigurableApplicationContext> {
@Override
public void initialize(ConfigurableApplicationContext applicationContext) {
MutablePropertySources propertySources = applicationContext.getEnvironment().getPropertySources();
propertySources.addFirst(new MapPropertySource("customPropertySource", Collections.singletonMap("customKey", "customValue")));
System.out.println("已添加自定义属性源");
}
}
Spring环境下添加扩展点
在Spring环境下自定义实现一个
ApplicationContextInitializer
让并且它生效的方式有三种:
- 手动调用的setXXX方法添加
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext();
// Add initializer
context.addApplicationListener(new TestApplicationContextInitializer());
// Set config locations and refresh context
context.setConfigLocation("classpath:applicationContext.xml");
context.refresh();
// Use the context
// ...
context.close();
- Spring 的 XML 配置文件中注册
<context:initializer class="com.seven.springsrpingbootextentions.extentions.TestApplicationContextInitializer"/>
- web.xml 文件配置
<context-param>
<param-name>contextInitializerClasses</param-name>
<param-value>com.seven.springsrpingbootextentions.extentions.TestApplicationContextInitializer</param-value>
</context-param>
SpringBoot环境下添加扩展点
示例,展示了如何实现一个ApplicationContextInitializer来添加一个自定义的属性源:
public class TestApplicationContextInitializer implements ApplicationContextInitializer<ConfigurableApplicationContext> {
@Override
public void initialize(ConfigurableApplicationContext applicationContext) {
MutablePropertySources propertySources = applicationContext.getEnvironment().getPropertySources();
// 创建自定义的属性源
Map<String, Object> customProperties = new HashMap<>();
customProperties.put("custom.property", "custom value");
MapPropertySource customPropertySource = new MapPropertySource("customPropertySource", customProperties);
// 将自定义属性源添加到应用程序上下文的属性源列表中
propertySources.addFirst(customPropertySource);
}
}
在SpringBoot中让它生效的方式也有三种:
- 在启动类中用
springApplication.addInitializers(new TestApplicationContextInitializer())
语句加入
@SpringBootApplication
public class MySpringExApplication {
public static void main(String[] args) {
SpringApplication application = new SpringApplication(MySpringExApplication.class);
application.addInitializers(new TestApplicationContextInitializer()); // 直接在SpringApplication中添加
application.run(args);
}
}
- application配置文件 配置
com.seven.springsrpingbootextentions.extentions.TestApplicationContextInitializer
# application.yml文件
context:
initializer:
classes: com.seven.springsrpingbootextentions.extentions.TestApplicationContextInitializer
- Spring
SPI
扩展,在spring.factories中加入(官方推荐):
com.seven.springsrpingbootextentions.extentions.TestApplicationContextInitializer
SpringBoot内置的ApplicationContextInitializer
DelegatingApplicationContextInitializer
:使用环境属性
context.initializer.classes
指定的初始化器(initializers)进行初始化工作,如果没有指定则什么都不做。通过它使得我们可以把自定义实现类配置在
application.properties
里成为了可能。
ContextIdApplicationContextInitializer
:设置Spring应用上下文的ID,Id设置为啥值会参考环境属性:
- spring.application.name
- vcap.application.name
- spring.config.name
- spring.application.index
- vcap.application.instance_index
- 如果这些属性都没有,ID使用application。
ConfigurationWarningsApplicationContextInitializer
:对于一般配置错误在日志中作出警告
ServerPortInfoApplicationContextInitializer
:将内置servlet容器实际使用的监听端口写入到Environment环境属性中。这样属性
local.server.port
就可以直接通过
@Value
注入到测试中,或者通过环境属性Environment获取。
SharedMetadataReaderFactoryContextInitializer
:创建一个 SpringBoot 和 ConfigurationClassPostProcessor 共用的 CachingMetadataReaderFactory对象。实现类为:ConcurrentReferenceCachingMetadataReaderFactory
ConditionEvaluationReportLoggingListener
:将ConditionEvaluationReport写入日志。
BeanFactoryPostProcessor
org.springframework.beans.factory.config.BeanFactoryPostProcessor
介绍
这个接口是
beanFactory
的扩展接口,调用时机在spring在读取
beanDefinition
信息之后,实例化bean之前。虽然此时不能再注册beanDefinition,但是可以趁着bean没有实例化,可以修改 Spring 容器启动时修改其内部的
BeanDefinition
。通过实现
BeanFactoryPostProcessor
接口,开发者可以在 Bean 实例化之前修改 Bean 的定义元数据,例如Scope、依赖查找方式、初始化方法、修改属性值、添加额外的元数据等,进而影响初始化行为。
在应用程序启动时,Spring容器会自动检测并调用所有实现了BeanFactoryPostProcessor接口的类的postProcessBeanFactory方法。开发人员可以利用这个方法来实现自定义的逻辑,从而实现一些高级的自定义逻辑和功能扩展。此方法只调用一次,
同时记住不要在这里做Bean的实例化
。
使用场景
- 修改 Bean 属性:可以动态地改变某些配置属性或者注入额外的依赖。
public class PropertyModifierBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
BeanDefinition beanDefinition = beanFactory.getBeanDefinition("myBean");
MutablePropertyValues propertyValues = beanDefinition.getPropertyValues();
propertyValues.addPropertyValue("propertyName", "newValue");
}
}
- 动态注册 Bean:可以根据配置文件或者系统环境变量来决定是否注册某个 Bean。
public class ConditionalBeanRegistrar implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
if (someCondition()) {
BeanDefinitionBuilder beanDefinitionBuilder = BeanDefinitionBuilder.genericBeanDefinition(MyBean.class);
beanFactory.registerBeanDefinition("myConditionalBean", beanDefinitionBuilder.getBeanDefinition());
}
}
private boolean someCondition() {
// 自定义条件逻辑
return true;
}
}
- 修改 Bean 定义:可以修改 Bean 的作用域、初始化和销毁方法等定义信息。
public class ScopeModifierBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
BeanDefinition beanDefinition = beanFactory.getBeanDefinition("myBean");
beanDefinition.setScope(BeanDefinition.SCOPE_PROTOTYPE);
}
}
- 属性占位符替换:可以使用
PropertyPlaceholderConfigurer
实现
BeanFactoryPostProcessor
接口,来替换 Bean 定义中的属性占位符。
public class CustomPropertyPlaceholderConfigurer extends PropertyPlaceholderConfigurer {
@Override
protected void processProperties(ConfigurableListableBeanFactory beanFactory, Properties props)
throws BeansException {
super.processProperties(beanFactory, props);
// 自定义属性处理逻辑
}
}
其它使用场景:
- 配置中心集成
:当需要从外部配置中心(如 Spring Cloud Config 或 Apache Zookeeper)动态加载配置并修改 Bean 定义时,可以使用
BeanFactoryPostProcessor
。
- 多环境支持
:根据不同的环境(如开发、测试、生产环境)动态修改 Bean 的定义,确保不同环境下的 Bean 配置有所不同。
- 动态注册 Bean
:在应用运行时,根据条件动态注册或者取消 Bean,比如在某些特定条件下才需要注册某些 Bean。
- 复杂业务应用
:有时候会需要根据复杂的业务规则动态调整 Bean 的配置,这时候
BeanFactoryPostProcessor
非常有用。
BeanDefinitionRegistryPostProcessor
org.springframework.beans.factory.support.BeanDefinitionRegistryPostProcessor
介绍
BeanDefinitionRegistryPostProcessor为容器级后置处理器。
容器级的后置处理器会在Spring容器初始化后、刷新前执行一次,用于动态注册Bean到容器
。
通过 BeanFactoryPostProcessor 的子类 BeanDefinitionRegistryPostProcessor,可以注册一个你自己的BeanDefinition对象到容器中,等待容器内部依次调用进行对象实例化就能当bean用了。
BeanDefinitionRegistryPostProcessor用于在bean解析后实例化之前通过BeanDefinitionRegistry对BeanDefintion进行增删改查。
前文介绍的BeanFactoryPostProcessor是这个接口的父类
,因此实现BeanDefinitionRegistryPostProcessor这个接口,也可以重写其父类。但实现了BeanDefinitionRegistryPostProcessor的postProcessBeanFactory方法会先执行,再执行实现了BeanFactoryPostProcessor的postProcessBeanFactory。具体看调用顺序图
使用场景
- 修改现有的 BeanDefinition:可以在 Bean 实例化之前修改现有的
BeanDefinition
,如更改其属性值或作用域。
public class BeanDefinitionModifier implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
System.out.println("在 postProcessBeanDefinitionRegistry 中修改现有的 BeanDefinition");
if (registry.containsBeanDefinition("myExistingBean")) {
BeanDefinition beanDefinition = registry.getBeanDefinition("myExistingBean");
MutablePropertyValues propertyValues = beanDefinition.getPropertyValues();
propertyValues.add("propertyName", "newValue");
}
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
// 此方法可以留空或用于进一步处理
}
}
- 条件性地注册 Bean:基于某些条件(如环境变量、配置文件等)动态注册或取消注册某些 Bean。
public class ConditionalBeanRegistrar implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
System.out.println("在 postProcessBeanDefinitionRegistry 中根据条件注册 Bean");
if (someCondition()) {
AbstractBeanDefinition beanDefinition = BeanDefinitionBuilder
.genericBeanDefinition(ConditionalBean.class)
.getBeanDefinition();
registry.registerBeanDefinition("conditionalBean", beanDefinition);
}
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
// 此方法可以留空或用于进一步处理
}
private boolean someCondition() {
// 自定义条件逻辑
return true;
}
}
- 扫描和注册自定义注解的 Bean:实现自定义注解的扫描逻辑,并动态注册这些注解标注的 Bean。
public class CustomAnnotationBeanRegistrar implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
System.out.println("在 postProcessBeanDefinitionRegistry 中扫描并注册自定义注解的 Bean");
// 自定义扫描逻辑,假设找到一个类 MyAnnotatedBean
AbstractBeanDefinition beanDefinition = BeanDefinitionBuilder
.genericBeanDefinition(MyAnnotatedBean.class)
.getBeanDefinition();
registry.registerBeanDefinition("myAnnotatedBean", beanDefinition);
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
// 此方法可以留空或用于进一步处理
}
}
- 比如依赖Redis.jar,如果该依赖jar存在,则用
redis当缓存
,否则就用
本地缓存
。这个需求完全可以在postProcessBeanDefinitionRegistry中利用Class.forName判断依赖,存在的话则注册对应class到容器。
@Configuration
public class AppConfig {
@Bean
public static BeanDefinitionRegistryPostProcessor customBeanDefinitionRegistryPostProcessor() {
return new BeanDefinitionRegistryPostProcessor() {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
System.out.println("在 postProcessBeanDefinitionRegistry 中根据条件注册缓存实现类");
try {
// 检查 Redis 依赖是否存在
Class.forName("redis.clients.jedis.Jedis");
System.out.println("检测到 Redis 依赖,注册 RedisCacheService");
AbstractBeanDefinition redisCacheBeanDefinition = BeanDefinitionBuilder
.genericBeanDefinition(RedisCacheService.class)
.getBeanDefinition();
registry.registerBeanDefinition("cacheService", redisCacheBeanDefinition);
} catch (ClassNotFoundException e) {
System.out.println("未检测到 Redis 依赖,注册 LocalCacheService");
AbstractBeanDefinition localCacheBeanDefinition = BeanDefinitionBuilder
.genericBeanDefinition(LocalCacheService.class)
.getBeanDefinition();
registry.registerBeanDefinition("cacheService", localCacheBeanDefinition);
}
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
// 此方法可以留空或用于进一步处理
}
};
}
}
- Mybatis就是用BeanFactoryPostProcessor去注册的mapper
MapperScannerConfigurer
的主要功能是通过扫描指定的包路径,找到所有标注了
@Mapper
注解(或其他指定注解)的接口,并将这些接口注册为 Spring 的 BeanDefinition。这样,Spring 容器在启动时会自动创建这些 Mapper 接口的代理对象,并将其注入到需要的地方。
以下是
MapperScannerConfigurer
的核心代码片段:
// org.mybatis.spring.mapper.MapperScannerConfigurer#postProcessBeanDefinitionRegistry
public class MapperScannerConfigurer implements BeanDefinitionRegistryPostProcessor, ApplicationContextAware {
private String basePackage;
private ApplicationContext applicationContext;
public void setBasePackage(String basePackage) {
this.basePackage = basePackage;
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
ClassPathMapperScanner scanner = new ClassPathMapperScanner(registry);
//设置其资源加载器为当前的 ApplicationContext
scanner.setResourceLoader(this.applicationContext);
scanner.registerFilters();
//调用 scanner.scan(this.basePackage) 方法,扫描指定的包路径,找到所有符合条件的 Mapper 接口,并将它们注册为 Spring 的 BeanDefinition。
scanner.scan(this.basePackage);
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
// 此方法可以留空或用于进一步处理
}
}
BeanPostProcessor
org.springframework.beans.factory.config.BeanPostProcessor
介绍
BeanPostProcessor
接口定义了两个基本的Bean初始化回调方法,在属性赋值前后执行。
postProcessBeforeInitialization
:在 Bean 初始化方法(如
@PostConstruct
、
InitializingBean.afterPropertiesSet
或自定义初始化方法)调用之前执行;返回的对象将是实际注入到容器中的 Bean,如果返回 null,则该 Bean 不会被注册。可用于创建代理类
postProcessAfterInitialization
:初始化bean之后,返回的对象将是实际注入到容器中的 Bean,如果返回 null,则该 Bean 不会被注册。
使用场景
- 初始化前后进行自定义逻辑:在 Bean 初始化之前或之后执行一些自定义的操作,例如设置一些属性、进行依赖注入、执行某些检查等。
@Component
public class CustomBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof MyBean) {
System.out.println("bean初始化前: " + beanName);
((MyBean) bean).setName("Modified Name Before Initialization");
}
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof MyBean) {
System.out.println("bean初始化后: " + beanName);
}
return bean;
}
}
public class MyBean {
private String name;
public MyBean(String name) {
this.name = name;
}
public void setName(String name) {
this.name = name;
}
public void init() {
System.out.println("bean正在init: " + name);
}
@Override
public String toString() {
return "MyBean{name='" + name + "'}";
}
- 代理对象的生成:在
postProcessAfterInitialization
方法中生成 Bean 的代理对象,用于 AOP(面向切面编程)或其他用途。
@Component
public class ProxyBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof MyBean) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(bean.getClass());
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("Before method: " + method.getName());
Object result = proxy.invokeSuper(obj, args);
System.out.println("After method: " + method.getName());
return result;
}
});
return enhancer.create();
}
return bean;
}
}
- 日志记录和监控:记录 Bean 的初始化过程,进行性能监控、日志记录等。
@Component
public class LoggingBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("开始初始化bean: " + beanName);
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("初始化bean结束: " + beanName);
return bean;
}
}
- 自动装配和注入:在初始化前后进行自动装配和注入,例如通过反射为某些字段注入值。
@Component
public class AutowireBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
Field[] fields = bean.getClass().getDeclaredFields();
for (Field field : fields) {
if (field.isAnnotationPresent(AutowireCustom.class)) {
field.setAccessible(true);
try {
field.set(bean, "Injected Value");
} catch (IllegalAccessException e) {
throw new BeansException("Failed to autowire field: " + field.getName(), e) {};
}
}
}
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
}
@Retention(RetentionPolicy.RUNTIME)
public @interface AutowireCustom {
}
public class MyBean {
@AutowireCustom
private String customField;
public MyBean() {
}
@Override
public String toString() {
return "MyBean{customField='" + customField + "'}";
}
}
InstantiationAwareBeanPostProcessor
org.springframework.beans.factory.config.InstantiationAwareBeanPostProcessor
介绍
该接口继承了
BeanPostProcessor
接口,因为InstantiationAwareBeanPostProcessor也属于Bean级的后置处理器,区别如下:
BeanPostProcess
接口只
在bean的初始化阶段进行扩展
(注入spring上下文前后),而
InstantiationAwareBeanPostProcessor
接口在此基础上增加了3个方法,把可扩展的范围增加了实例化阶段和属性注入阶段。
该类主要的扩展点有以下6个方法,其中有两个是BeanPostProcessor的扩展,主要在bean生命周期的两大阶段:
实例化阶段
和
初始化阶段
,下面一起进行说明,按调用顺序为:
postProcessBeforeInstantiation
:在Bean实例化之前调用,如果返回null,一切按照正常顺序执行;如果返回的是一个实例的对象,那么
postProcessAfterInstantiation()
会执行,其他的扩展点将不再触发。
postProcessAfterInstantiation
:在Bean实例化之后调用,可以对已实例化的Bean进行进一步的自定义处理。
postProcessPropertyValues
(方法在spring5.1版本后就已弃用):bean已经实例化完成,在属性注入时阶段触发,
@Autowired
,
@Resource
等注解原理基于此方法实现;可以修改Bean的属性值或进行其他自定义操作,
当postProcessAfterInstantiation返回true才执行。
postProcessBeforeInitialization
(BeanPostProcessor的扩展):初始化bean之前,相当于把bean注入spring上下文之前;可用于创建代理类,如果返回的不是 null(也就是返回的是一个代理类) ,那么后续只会调用 postProcessAfterInitialization() 方法
postProcessAfterInitialization
(BeanPostProcessor的扩展):初始化bean之后,相当于把bean注入spring上下文之后;返回值会影响 postProcessProperties() 是否执行,其中返回 false 的话,是不会执行。
postProcessProperties()
:在 Bean 设置属性前调用;用于修改 bean 的属性,如果返回值不为空,那么会更改指定字段的值
注意:InstantiationAwareBeanPostProcessor和 BeanPostProcessor 是可以同时被实现的,并且也会同时生效,但是InstantiationAwareBeanPostProcessor的
执行时机要稍早于BeanPostProcessor
;具体看上面调用顺序图
InstantiationAwareBeanPostProcessor
提供了更细粒度的控制,可以在 Bean 的实例化和属性设置过程中插入自定义逻辑。无论是替换默认的实例化过程、控制依赖注入,还是修改属性值,
InstantiationAwareBeanPostProcessor
都提供了强大的灵活性和可扩展性,使得开发者可以在 Bean 的生命周期中进行更精细的控制。
使用场景
- 在实例化之前替换 Bean:替换默认的 Bean 实例化过程,可能是返回一个代理对象。
@Component
public class CustomInstantiationAwareBeanPostProcessor implements InstantiationAwareBeanPostProcessor {
@Override
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
if (beanClass == MyBean.class) {
System.out.println("实例化之前替换 Bean: " + beanName);
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(beanClass);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("调用方法: " + method.getName());
return proxy.invokeSuper(obj, args);
}
});
return enhancer.create();
}
return null;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("初始化之后的 Bean: " + beanName);
return bean;
}
}
- 控制实例化后的依赖注入过程:在实例化后但在依赖注入之前进行一些自定义逻辑。
@Component
public class DependencyInjectionControlPostProcessor implements InstantiationAwareBeanPostProcessor {
@Override
public boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException {
if (bean instanceof MyBean) {
System.out.println("实例化之后控制依赖注入: " + beanName);
return false; // 不进行默认的依赖注入
}
return true;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("初始化之后的 Bean: " + beanName);
return bean;
}
}
- 修改属性值:在属性值设置过程中进行干预,修改或添加属性值。
@Component
public class PropertyModificationPostProcessor implements InstantiationAwareBeanPostProcessor {
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) throws BeansException {
if (bean instanceof MyBean) {
System.out.println("设置属性值之前: " + beanName);
// 修改属性值的逻辑
}
return pvs;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("初始化之后的 Bean: " + beanName);
return bean;
}
}
SmartInstantiationAwareBeanPostProcessor
org.springframework.beans.factory.config.SmartInstantiationAwareBeanPostProcessor
介绍
SmartInstantiationAwareBeanPostProcessor
与其他扩展点最明显的不同,就是在实际的业务开发场景中应用到的机会并不多,主要是在Spring内部应用。
该扩展接口有3个触发点方法:
predictBeanType
:该触发点发生在
postProcessBeforeInstantiation
之前(也就是在 InstantiationAwareBeanPostProcessor的方法之前,在图上并没有标明,因为
一般不太需要扩展这个点
),这个方法用于预测Bean的类型,返回第一个预测成功的Class类型,如果不能预测,则返回null;当调用
BeanFactory.getType(name)
时当通过bean的名字无法得到bean类型信息时就调用该回调方法来决定类型信息。
determineCandidateConstructors
:该触发点发生在
postProcessBeforeInstantiation
之后,用于决定使用哪个构造器构造Bean,返回的是该bean的所有构造函数列表;如果不指定,默认为null,即bean的无参构造方法。用户可以扩展这个点,来自定义选择相应的构造器来实例化这个bean。
getEarlyBeanReference
:该触发点发生在
postProcessAfterInstantiation
之后,主要用于Spring循环依赖问题的解决,如果Spring中检测不到循环依赖,这个方法不会被调用;当存在Spring循环依赖这种情况时,当bean实例化好之后,为了防止有循环依赖,会提前暴露回调方法,用于bean实例化的后置处理,会在InstantiationAwareBeanPostProcessor#postProcessBeforeInstantiation方法触发执行之后执行;
注意:同InstantiationAwareBeanPostProcessor,由于SmartInstantiationAwareBeanPostProcessor 是 InstantiationAwareBeanPostProcessor的子类,因此也SmartInstantiationAwareBeanPostProcessor 也同样能扩展 InstantiationAwareBeanPostProcessor的所有方法。但是如果有两个类分别重写了 SmartInstantiationAwareBeanPostProcessor 和 InstantiationAwareBeanPostProcessor 的方法,那么
重写 InstantiationAwareBeanPostProcessor 的类的方法 会先于 重写了 SmartInstantiationAwareBeanPostProcessor的类的方法
(注意,这里说的是两者都有的方法)。
使用场景
- 自定义构造函数选择:在实例化 Bean 时,选择特定的构造函数。
@Component
public class CustomConstructorSelectionPostProcessor implements SmartInstantiationAwareBeanPostProcessor {
@Override
public Constructor<?>[] determineCandidateConstructors(Class<?> beanClass, String beanName) throws BeansException {
if (beanClass == MyBean.class) {
System.out.println("选择自定义构造函数: " + beanName);
try {
return new Constructor<?>[] { beanClass.getConstructor(String.class) };
} catch (NoSuchMethodException e) {
throw new BeansException("找不到指定的构造函数", e) {};
}
}
return null;
}
}
public class MyBean {
private String name;
public MyBean() {
this.name = "Default Name";
}
public MyBean(String name) {
this.name = name;
}
@Override
public String toString() {
return "MyBean{name='" + name + "'}";
}
}
- 解决循环依赖问题:通过提供早期 Bean 引用,解决循环依赖问题。
@Component
public class EarlyBeanReferencePostProcessor implements SmartInstantiationAwareBeanPostProcessor {
@Override
public Object getEarlyBeanReference(Object bean, String beanName) throws BeansException {
if (bean instanceof MyBean) {
System.out.println("获取早期 Bean 引用: " + beanName);
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(bean.getClass());
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("调用方法: " + method.getName());
return proxy.invokeSuper(obj, args);
}
});
return enhancer.create();
}
return bean;
}
}
- 预测 Bean 类型:在 Bean 实例化之前,预测 Bean 的类型。
@Component
public class BeanTypePredictionPostProcessor implements SmartInstantiationAwareBeanPostProcessor {
@Override
public Class<?> predictBeanType(Class<?> beanClass, String beanName) throws BeansException {
if (beanClass == MyBean.class) {
System.out.println("预测 Bean 类型: " + beanName);
return MyBean.class;
}
return null;
}
}
MergedBeanDefinitionPostProcessor
org.springframework.beans.factory.support.MergedBeanDefinitionPostProcessor
介绍
MergedBeanDefinitionPostProcessor 继承自 BeanPostProcessor。调用的时机是,在实例化之后进行的调用,只要是收集bean上的属性的,比如收集标记了某些注解的字段或者方法,都可以基于MergedBeanDefinitionPostProcessor来进行扩展。
对于不同方式导入的Bean定义,如果存在重复对同一个Bean的定义,则会根据allowBeanDefinitionOverriding属性是否设置为true,判断是否允许Bean定义的覆盖,如果不允许,则抛出异常。而在Bean实例化之前,会进行BeanDefinition类型的归一化,即 mergeBeanFintion ,统一转换为RootBeanfintion进行后续处理。当然,这里的merge更多指代的是父子Bean定义的合并。
也用于收集bean上的注解,比如常见的@Value、@NacosValue、@Mapper等,再将收集好的数据缓存在injectionMetadataCache中,以便后续比如属性注入的时候使用。
该接口有两个扩展方法:
postProcessMergedBeanDefinition
:此方法在Spring将多个Bean定义合并为一个
RootBeanDefinition
之后,但在实例化Bean之前被调用。主要作用是让开发者有机会在Bean定义合并后,对其进行进一步的定制和调整。使用场景如下:
- 自定义注解处理
:处理自定义注解并将其应用于Bean定义。
- 属性修改
:在Bean实例化之前对Bean定义中的某些属性进行调整或设置默认值。
resetBeanDefinition
:此方法在Bean定义被重置时调用。它通常用于清理或重置与特定Bean定义相关的状态或缓存。使用场景如下:
- 状态清理
:清理缓存或临时状态,以便Bean定义可以被重新解析。
- 重置自定义元数据
:在Bean定义被重置时,重置自定义的元数据或状态。
使用场景
- 对合并后的 Bean 定义信息进行修改:在 Bean 实例化之前,修改其定义信息,例如添加属性值或修改构造函数参数。
@Component
public class CustomMergedBeanDefinitionPostProcessor implements MergedBeanDefinitionPostProcessor, BeanPostProcessor {
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
if (beanType == MyBean.class) {
System.out.println("合并后的 Bean 定义信息, Bean 名称: " + beanName);
// 修改合并后的 Bean 定义信息
beanDefinition.getPropertyValues().add("name", "修改后的名称");
}
}
@Override
public void resetBeanDefinition(String beanName) {
System.out.println("重置 Bean 定义信息, Bean 名称: " + beanName);
// 实现重置逻辑
}
}
public class MyBean {
private String name;
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "MyBean{name='" + name + "'}";
}
}
- 实现通用的自定义逻辑:在所有 Bean 实例化之前,执行一些通用的自定义逻辑。
@Component
public class CommonLogicMergedBeanDefinitionPostProcessor implements MergedBeanDefinitionPostProcessor, BeanPostProcessor {
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
System.out.println("处理合并后的 Bean 定义信息, Bean 名称: " + beanName);
// 添加通用的自定义逻辑,例如给所有 Bean 添加某个属性
beanDefinition.getPropertyValues().add("commonProperty", "通用属性值");
}
@Override
public void resetBeanDefinition(String beanName) {
System.out.println("重置 Bean 定义信息, Bean 名称: " + beanName);
// 实现重置逻辑
}
}
public class MyBean {
private String name;
private String commonProperty;
public void setName(String name) {
this.name = name;
}
public void setCommonProperty(String commonProperty) {
this.commonProperty = commonProperty;
}
@Override
public String toString() {
return "MyBean{name='" + name + "', commonProperty='" + commonProperty + "'}";
}
}
- 条件性地重置 Bean 定义信息:在某些条件下重置 Bean 的定义信息,使得下一次的实例化可以使用更新后的定义信息。
@Component
public class ConditionalResetMergedBeanDefinitionPostProcessor implements MergedBeanDefinitionPostProcessor, BeanPostProcessor {
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
System.out.println("处理合并后的 Bean 定义信息, Bean 名称: " + beanName);
// 这里可以根据条件决定是否修改 Bean 定义
if (beanName.equals("conditionalBean")) {
beanDefinition.getPropertyValues().add("name", "重置后的名称");
}
}
@Override
public void resetBeanDefinition(String beanName) {
System.out.println("重置 Bean 定义信息, Bean 名称: " + beanName);
// 这里可以实现条件性重置逻辑
}
}
public class ConditionalBean {
private String name;
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "ConditionalBean{name='" + name + "'}";
}
}
BeanNameAware
org.springframework.beans.factory.BeanNameAware
介绍
这个类是Aware扩展的一种,触发点在bean的初始化之前,也就是
postProcessBeforeInitialization
之前,这个类的触发点方法只有一个:
setBeanName
。
用于让 Bean 获得其在 Spring 容器中的名称。实现了
BeanNameAware
接口的 Bean 可以在初始化时获得自身的 Bean 名称,这在某些需要根据 Bean 名称进行逻辑处理的场景非常有用。
使用场景
- 记录或日志输出 Bean 名称:在某些应用场景中,开发者可能希望在 Bean 初始化时记录或输出 Bean 的名称。这对调试和日志记录非常有帮助。
@Component
public class LoggingBean implements BeanNameAware {
private String beanName;
@Override
public void setBeanName(String name) {
this.beanName = name;
System.out.println("设置 Bean 名称: " + name);
}
public void doSomething() {
System.out.println("正在执行某些操作, 当前 Bean 名称: " + beanName);
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
LoggingBean loggingBean = context.getBean(LoggingBean.class);
loggingBean.doSomething();
}
}
- 根据 Bean 名称实现条件性逻辑:有时,一个 Bean 可能需要根据其名称决定执行不同的逻辑。例如,可以在初始化过程或某些方法调用中根据 Bean 名称执行特定操作。
@Component
public class ConditionalLogicBean implements BeanNameAware {
private String beanName;
@Override
public void setBeanName(String name) {
this.beanName = name;
System.out.println("设置 Bean 名称: " + name);
}
public void performAction() {
if ("conditionalLogicBean".equals(beanName)) {
System.out.println("执行特定逻辑, 因为这是 conditionalLogicBean");
} else {
System.out.println("执行普通逻辑");
}
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
ConditionalLogicBean conditionalLogicBean = context.getBean(ConditionalLogicBean.class);
conditionalLogicBean.performAction();
}
}
- 动态注册多个同类型的 Bean:在某些复杂的应用场景中,可能需要动态注册多个同类型的 Bean,并且需要根据名称区分它们。实现
BeanNameAware
接口可以很方便地获取和使用这些 Bean 的名称。
@Component("beanA")
public class DynamicBeanA implements BeanNameAware {
private String beanName;
@Override
public void setBeanName(String name) {
this.beanName = name;
System.out.println("设置 Bean 名称: " + name);
}
public void execute() {
System.out.println("执行 Bean: " + beanName);
}
}
@Component("beanB")
public class DynamicBeanB implements BeanNameAware {
private String beanName;
@Override
public void setBeanName(String name) {
this.beanName = name;
System.out.println("设置 Bean 名称: " + name);
}
public void execute() {
System.out.println("执行 Bean: " + beanName);
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
DynamicBeanA beanA = (DynamicBeanA) context.getBean("beanA");
DynamicBeanB beanB = (DynamicBeanB) context.getBean("beanB");
beanA.execute();
beanB.execute();
}
}
BeanClassLoaderAware
org.springframework.beans.factory.BeanClassLoaderAware
介绍
用于让一个 Bean 获取到加载它的
ClassLoader
。实现这个接口的 Bean 会在其属性设置完成后、初始化方法调用之前被注入
ClassLoader
。该接口定义了一个方法:
void setBeanClassLoader(ClassLoader classLoader)
:在某些需要动态加载类的场景中,获取
ClassLoader
是非常有用的。
使用场景
- 动态加载类:有时候,我们可能需要在运行时动态加载类,利用
BeanClassLoaderAware
可以方便地获取到
ClassLoader
来实现这一需求。
@Component
public class DynamicClassLoader implements BeanClassLoaderAware {
private ClassLoader classLoader;
@Override
public void setBeanClassLoader(ClassLoader classLoader) {
this.classLoader = classLoader;
System.out.println("已设置类加载器");
}
public void loadClass(String className) {
try {
Class<?> clazz = classLoader.loadClass(className);
System.out.println("已加载类:" + clazz.getName());
} catch (ClassNotFoundException e) {
System.out.println("类未找到:" + className);
}
}
}
@SpringBootApplication
public class AppConfig {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(AppConfig.class, args);
DynamicClassLoader dynamicClassLoader = context.getBean(DynamicClassLoader.class);
dynamicClassLoader.loadClass("java.util.ArrayList");
dynamicClassLoader.loadClass("不存在的类");
}
}
- 检查类的可用性:在某些情况下,我们可能需要检查某个类是否在当前的类路径中可用。利用
BeanClassLoaderAware
可以方便地实现这一需求。
@Component
public class ClassAvailabilityChecker implements BeanClassLoaderAware {
private ClassLoader classLoader;
@Override
public void setBeanClassLoader(ClassLoader classLoader) {
this.classLoader = classLoader;
System.out.println("已设置类加载器");
}
public boolean isClassAvailable(String className) {
try {
Class<?> clazz = classLoader.loadClass(className);
System.out.println("类可用:" + clazz.getName());
return true;
} catch (ClassNotFoundException e) {
System.out.println("类不可用:" + className);
return false;
}
}
}
@SpringBootApplication
public class AppConfig {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(AppConfig.class, args);
ClassAvailabilityChecker checker = context.getBean(ClassAvailabilityChecker.class);
checker.isClassAvailable("java.util.HashMap");
checker.isClassAvailable("不存在的类");
}
}
- 加载资源文件:通过
BeanClassLoaderAware
获取的
ClassLoader
,我们还可以方便地加载资源文件。
@Component
public class ResourceLoader implements BeanClassLoaderAware {
private ClassLoader classLoader;
@Override
public void setBeanClassLoader(ClassLoader classLoader) {
this.classLoader = classLoader;
System.out.println("已设置类加载器");
}
public void loadResource(String resourcePath) {
InputStream inputStream = classLoader.getResourceAsStream(resourcePath);
if (inputStream != null) {
System.out.println("资源已加载:" + resourcePath);
} else {
System.out.println("资源未找到:" + resourcePath);
}
}
}
@SpringBootApplication
public class AppConfig {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(AppConfig.class, args);
ResourceLoader resourceLoader = context.getBean(ResourceLoader.class);
resourceLoader.loadResource("application.properties");
resourceLoader.loadResource("不存在的资源");
}
}
BeanFactoryAware
org.springframework.beans.factory.BeanFactoryAware
介绍
这个类只有一个触发点,发生在bean的实例化之后,注入属性之前,也就是Setter之前。这个类的扩展点方法为
setBeanFactory
,可以拿到
BeanFactory
这个属性,从而能够进行更复杂的 Bean 操作。例如,动态获取其他 Bean、检查 Bean 的状态等。
使用场景
- 动态获取其他 Bean:通过实现
BeanFactoryAware
接口,一个 Bean 可以在运行时动态获取其他 Bean。这在一些需要解耦的场景下非常有用。
@Component
public class DynamicBeanFetcher implements BeanFactoryAware {
private BeanFactory beanFactory;
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
this.beanFactory = beanFactory;
System.out.println("注入 BeanFactory 实例");
}
public void fetchAndUseBean() {
MyBean myBean = beanFactory.getBean(MyBean.class);
System.out.println("获取到的 Bean 实例: " + myBean);
}
}
@Component
public class MyBean {
@Override
public String toString() {
return "这是 MyBean 实例";
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
DynamicBeanFetcher fetcher = context.getBean(DynamicBeanFetcher.class);
fetcher.fetchAndUseBean();
}
}
- 检查 Bean 的状态:通过
BeanFactoryAware
,可以在运行时检查某个 Bean 是否存在或者其状态,这对一些需要动态检查 Bean 状态的场景非常有用。
@Component
public class BeanStateChecker implements BeanFactoryAware {
private BeanFactory beanFactory;
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
this.beanFactory = beanFactory;
System.out.println("注入 BeanFactory 实例");
}
public void checkBeanState() {
boolean exists = beanFactory.containsBean("myBean");
System.out.println("MyBean 是否存在: " + exists);
}
}
@Component("myBean")
public class MyBean {
@Override
public String toString() {
return "这是 MyBean 实例";
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
BeanStateChecker checker = context.getBean(BeanStateChecker.class);
checker.checkBeanState();
}
}
- 创建复杂 Bean 的初始化逻辑:在一些复杂的业务场景中,有时需要在 Bean 初始化时执行一些复杂的逻辑,例如动态创建其他 Bean 并注入到当前 Bean 中。通过
BeanFactoryAware
可以实现这一点。
@Component
public class ComplexBeanInitializer implements BeanFactoryAware {
private BeanFactory beanFactory;
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
this.beanFactory = beanFactory;
System.out.println("注入 BeanFactory 实例");
}
public void initializeComplexBean() {
MyBean myBean = beanFactory.getBean(MyBean.class);
System.out.println("初始化复杂 Bean, 获取到的 MyBean 实例: " + myBean);
// 在这里可以执行复杂的初始化逻辑
}
}
@Component
public class MyBean {
@Override
public String toString() {
return "这是 MyBean 实例";
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
ComplexBeanInitializer initializer = context.getBean(ComplexBeanInitializer.class);
initializer.initializeComplexBean();
}
}
ApplicationContextAwareProcessor
org.springframework.context.support.ApplicationContextAwareProcessor
介绍
该类本身并没有扩展点,而是 BeanPostProcessor 扩展接口的具体实现,但是该类内部却有6个扩展点可供实现 ,这些扩展点的触发时机在bean实例化之后,初始化之前。
可以看到,该类用于执行各种驱动接口,在bean实例化之后,属性填充之后。其内部有6个扩展点可供实现,这几个接口都是Spring预留的重点扩展实现,与Spring的
Bean的生命周期
密切相关,以下按照扩展点调用顺序介绍:
EnvironmentAware
:用于获取
EnviromentAware
的一个扩展类,这个变量非常有用, 可以获得系统内的所有参数;另外也可以通过注入的方式来获得Environment,用哪种方式需要以实现场景而决定。当然个人认为这个Aware没必要去扩展,因为spring内部都可以通过注入的方式来直接获得。
EmbeddedValueResolverAware
:用于获取
StringValueResolver
的一个扩展类,
StringValueResolver
可以获取基于String类型的properties的变量;但一般我们都用
@Value
的方式来获取properties的变量,用哪种方式需要以实现场景而决定。如果实现了这个Aware接口,把
StringValueResolver
缓存起来,通过这个类去获取
String
类型的变量,效果是一样的。
ResourceLoaderAware
:用于获取
ResourceLoader
的一个扩展类,
ResourceLoader
可以用于获取classpath内所有的资源对象。
ApplicationEventPublisherAware
:用于获取
ApplicationEventPublisher
的一个扩展类,
ApplicationEventPublisher
可以用来发布事件;这个对象也可以通过spring注入的方式来获得,结合
ApplicationListener
来共同使用,下文在介绍
ApplicationListener
时会详细提到。
MessageSourceAware
:用于获取
MessageSource
的一个扩展类,
MessageSource
主要用来做国际化。
ApplicationContextAware
:用来获取
ApplicationContext
的一个扩展类,
ApplicationContext
就是spring上下文管理器,可以手动的获取任何在spring上下文注册的bean。较多的做法是扩展这个接口来缓存spring上下文,包装成静态方法。
同时
ApplicationContext
也实现了
BeanFactory
,
MessageSource
,
ApplicationEventPublisher
等接口,也可以用来做相关接口的事情。
使用场景
- 动态获取其他 Bean:通过实现
ApplicationContextAware
接口,Bean 可以在运行时动态获取其他 Bean,这在一些需要解耦的场景下非常有用。
@Component
public class DynamicBeanFetcher implements ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
System.out.println("注入 ApplicationContext 实例");
}
public void fetchAndUseBean() {
MyBean myBean = applicationContext.getBean(MyBean.class);
System.out.println("获取到的 Bean 实例: " + myBean);
}
}
@Component
public class MyBean {
@Override
public String toString() {
return "这是 MyBean 实例";
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
DynamicBeanFetcher fetcher = context.getBean(DynamicBeanFetcher.class);
fetcher.fetchAndUseBean();
}
}
- 使用 ApplicationContext 进行事件发布:在一些场景中,Bean 可能需要发布事件。通过实现
ApplicationContextAware
接口,可以方便地获取
ApplicationContext
实例并发布事件。
@Component
public class EventPublisherBean implements ApplicationContextAware, ApplicationEventPublisherAware {
private ApplicationContext applicationContext;
private ApplicationEventPublisher eventPublisher;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
System.out.println("注入 ApplicationContext 实例");
}
@Override
public void setApplicationEventPublisher(ApplicationEventPublisher eventPublisher) {
this.eventPublisher = eventPublisher;
}
public void publishCustomEvent(String message) {
CustomEvent customEvent = new CustomEvent(this, message);
eventPublisher.publishEvent(customEvent);
System.out.println("发布自定义事件: " + message);
}
}
public class CustomEvent extends ApplicationEvent {
private String message;
public CustomEvent(Object source, String message) {
super(source);
this.message = message;
}
public String getMessage() {
return message;
}
}
@Component
public class CustomEventListener {
@EventListener
public void handleCustomEvent(CustomEvent event) {
System.out.println("接收到自定义事件: " + event.getMessage());
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
EventPublisherBean publisher = context.getBean(EventPublisherBean.class);
publisher.publishCustomEvent("这是一个自定义事件消息");
}
}
- 获取环境信息:通过实现
ApplicationContextAware
接口,Bean 可以访问
ApplicationContext
,并从中获取环境配置信息,例如读取配置文件中的属性值。
@Component
public class EnvironmentAwareBean implements ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
System.out.println("注入 ApplicationContext 实例");
}
public void printEnvironmentProperty() {
Environment environment = applicationContext.getEnvironment();
String propertyValue = environment.getProperty("example.property");
System.out.println("读取到的环境属性值: " + propertyValue);
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
@PropertySource("classpath:application.properties")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
EnvironmentAwareBean environmentAwareBean = context.getBean(EnvironmentAwareBean.class);
environmentAwareBean.printEnvironmentProperty();
}
}
@PostConstruct
javax.annotation.PostConstruct
介绍
可以看出来其本身不是Spring定义的注解,但是Spring提供了具体的实现。这个并不算一个扩展点,其实就是一个标注。其作用是在bean的初始化阶段,如果对一个方法标注了
@PostConstruct
,会先调用这个方法。这里重点是要关注下这个标准的触发点,这个触发点是在
postProcessBeforeInitialization
之后,
InitializingBean.afterPropertiesSet
之前。
注意:
- 使用@PostConstruct注解标记的方法不能有参数,除非是拦截器,可以采用拦截器规范定义的InvocationContext对象。
- 使用@PostConstruct注解标记的方法不能有返回值,实际上如果有返回值,也不会报错,但是会忽略掉;
- 使用@PostConstruct注解标记的方法不能被static修饰,但是final是可以的;
使用场景
使用场景与 InitializingBean 类似,具体看下文
InitializingBean
org.springframework.beans.factory.InitializingBean
介绍
这个类,顾名思义,也是用来初始化bean的。
InitializingBean
接口为bean提供了初始化方法的方式,它只在bean实例化、属性注入后的提供了一个扩展点
afterPropertiesSet
方法,凡是继承该接口的类,在初始前、属性赋值后,都会执行该方法。这个
扩展点的触发时机
在
postProcessAfterInitialization
之前。
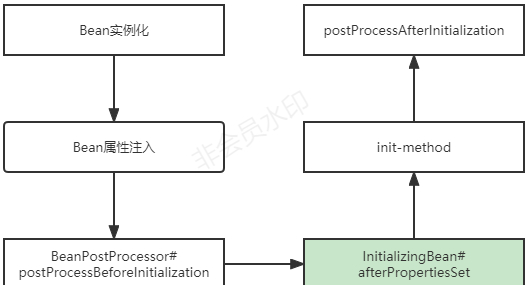
注意:
- 与InitializingBean#afterPropertiesSet()类似效果的是
init-method
,但是需要注意的是InitializingBean#afterPropertiesSet()执行时机要略早于init-method;
- InitializingBean#afterPropertiesSet()的调用方式是在bean初始化过程中真接调用bean的afterPropertiesSet();
- bean自定义属性init-method是通过java反射的方式进行调用 ;
使用场景
- 初始化资源:可以在 Bean 初始化后自动启动一些资源,如数据库连接、文件读取等。
public class NormalBeanA implements InitializingBean{
@Overrideimport org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Component;
@Component
public class ResourceInitializer implements InitializingBean {
@Override
public void afterPropertiesSet() {
// 模拟资源初始化
System.out.println("资源初始化:建立数据库连接");
}
public void performAction() {
System.out.println("资源使用:执行数据库操作");
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
ResourceInitializer initializer = context.getBean(ResourceInitializer.class);
initializer.performAction();
}
}
- 设置初始值
@Component
public class InitialValueSetter implements InitializingBean {
private String initialValue;
@Override
public void afterPropertiesSet() {
initialValue = "默认值";
System.out.println("设置初始值:" + initialValue);
}
public void printValue() {
System.out.println("当前值:" + initialValue);
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
InitialValueSetter valueSetter = context.getBean(InitialValueSetter.class);
valueSetter.printValue();
}
}
- 加载配置:可以在 Bean 初始化后加载必要的配置,如从文件或数据库中读取配置。
@Component
public class ConfigLoader implements InitializingBean {
private String configValue;
@Override
public void afterPropertiesSet() {
// 模拟配置加载
configValue = "配置值";
System.out.println("加载配置:" + configValue);
}
public void printConfig() {
System.out.println("当前配置:" + configValue);
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
ConfigLoader configLoader = context.getBean(ConfigLoader.class);
configLoader.printConfig();
}
}
SmartInitializingSingleton
org.springframework.beans.factory.SmartInitializingSingleton
介绍
这个接口中只有一个方法
afterSingletonsInstantiated
,其作用是是 在spring容器管理的所有单例对象(非懒加载对象)初始化完成之后调用的回调接口。其触发时机为
postProcessAfterInitialization
之后。
注意:
- 实现SmartInitializingSingleton接口的bean的作用域必须是单例,afterSingletonsInstantiated()才会触发;
- afterSingletonsInstantiated()触发执行时,
非懒加载的单例bean
已经完成实现化、属性注入以及相关的初始化操作;
- afterSingletonsInstantiated()的执行时机是在DefaultListableBeanFactory#preInstantiateSingletons();
使用场景
- 全局初始化操作:可以在所有单例 Bean 初始化后执行一些全局性的初始化操作,比如设置缓存、启动全局调度任务等。
@Component
public class GlobalInitializer implements SmartInitializingSingleton {
@Override
public void afterSingletonsInstantiated() {
// 模拟全局初始化操作
System.out.println("全局初始化操作:启动全局调度任务");
}
}
检查系统状态:可以用于在所有单例 Bean 初始化之后检查系统状态,确保系统运行在预期状态下。
加载全局配置:可以在所有单例 Bean 初始化后加载全局配置,如从文件或数据库中读取配置,并应用到系统中。
FactoryBean
org.springframework.beans.factory.FactoryBean
介绍
一般情况下,Spring通过
反射机制
利用bean的class属性指定支线类去实例化bean,在某些情况下,实例化Bean过程比较复杂,如果按照传统的方式,则需要在bean中提供大量的配置信息。Spring为此提供了一个
org.springframework.bean.factory.FactoryBean
的工厂类接口,用户可以通过实现该接口定制实例化Bean的逻辑。
FactoryBean
接口对于Spring框架来说占有重要的地位,Spring自身就提供了70多个
FactoryBean
的实现。它们隐藏了实例化一些复杂bean的细节,给上层应用带来了便利。
触发点:例如其他框架技术与Spring集成的时候,如mybatis与Spring的集成,mybatis是通过SqlSessionFactory创建出Sqlsession来执行sql的,那么Service层在调用Dao层的接口来执行数据库操作时肯定得持有SqlSessionFactory,那么问题来了:Spring容器怎么才能持有SqlSessionFactory呢?答案就是SqlSessionFactoryBean,它实现了FactoryBean接口。
FactoryBean 与 BeanFactory 的区别
- FactoryBean接口有三个方法:
- getObject():用于获取bean,主
要应用在创建一些复杂的bean的场景
;
- getObjectType():返回这个工厂创建的 Bean 实例的类型。
- isSingleton():用于判断返回bean是否属于单例,默认trure,通俗说就是工厂bean;
- BeanFactory是Spring bean容器的根接口,ApplicationContext是Spring bean容器的高级接口,继承于BeanFactory,通俗理解就是生成bean的工厂;
使用场景
- 创建复杂对象:使用
FactoryBean
可以帮助我们创建那些需要复杂配置或初始化的对象。
class ComplexObject {
private String name;
private int value;
public ComplexObject(String name, int value) {
this.name = name;
this.value = value;
}
@Override
public String toString() {
return "ComplexObject{name='" + name + "', value=" + value + "}";
}
}
@Component
public class ComplexObjectFactoryBean implements FactoryBean<ComplexObject> {
@Override
public ComplexObject getObject() {
// 创建复杂对象
ComplexObject complexObject = new ComplexObject("复杂对象", 42);
System.out.println("创建复杂对象:" + complexObject);
return complexObject;
}
@Override
public Class<?> getObjectType() {
return ComplexObject.class;
}
@Override
public boolean isSingleton() {
return true;
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
ComplexObject complexObject = context.getBean(ComplexObject.class);
System.out.println("获取复杂对象:" + complexObject);
}
}
- 动态切换实现:假设我们需要根据某些条件动态切换 Bean 的具体实现类,可以使用
FactoryBean
。
interface Service {
void execute();
}
class ServiceImplA implements Service {
@Override
public void execute() {
System.out.println("执行服务实现A");
}
}
class ServiceImplB implements Service {
@Override
public void execute() {
System.out.println("执行服务实现B");
}
}
@Component
public class DynamicServiceFactoryBean implements FactoryBean<Service> {
private boolean useServiceA = true; // 可以通过配置或条件动态设置
@Override
public Service getObject() {
if (useServiceA) {
System.out.println("创建服务实现A");
return new ServiceImplA();
} else {
System.out.println("创建服务实现B");
return new ServiceImplB();
}
}
@Override
public Class<?> getObjectType() {
return Service.class;
}
@Override
public boolean isSingleton() {
return true;
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
Service service = context.getBean(Service.class);
service.execute();
}
}
- 延迟初始化:
FactoryBean
可以用于延迟初始化某些 Bean,
只有在第一次获取时才进行实例化
。
class LazyObject {
public LazyObject() {
System.out.println("懒对象被创建");
}
public void doSomething() {
System.out.println("懒对象执行操作");
}
}
@Component
public class LazyObjectFactoryBean implements FactoryBean<LazyObject> {
@Override
public LazyObject getObject() {
System.out.println("创建懒对象实例");
return new LazyObject();
}
@Override
public Class<?> getObjectType() {
return LazyObject.class;
}
@Override
public boolean isSingleton() {
return true;
}
}
@Configuration
@ComponentScan(basePackages = "com.seven")
public class AppConfig {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
System.out.println("获取懒对象实例前");
LazyObject lazyObject = context.getBean(LazyObject.class);
System.out.println("获取懒对象实例后");
lazyObject.doSomething();
}
}
CommandLineRunner和ApplicationRunner
org.springframework.boot.CommandLineRunner
介绍
这两个是Springboot中新增的扩展点,之所以将这两个扩展点放在一起,是因为它两个功能特性高度相似,不同的只是名字、扩展方法形参数类型、执行先后的一些小的不同。
这两个接口触发时机为整个项目启动完毕后,自动执行。如果有多个
CommandLineRunner
,可以利用
@Order
来进行排序。
注意:
- CommandLineRunner和ApplicationRunner都有一个扩展方法run(),但是run()形参数类型不同;
- CommandLineRunner.run()方法的形参数类型是String... args,ApplicationRunner.run()的形参数类型是ApplicationArguments args;
- CommandLineRunner.run()的执行时机要晚于ApplicationRunner.run()一点;
- CommandLineRunner和ApplicationRunner触发执行时机是在Spring容器、Tomcat容器正式启动完成后,可以正式处理业务请求前,即项目启动的最后一步;
- CommandLineRunner和ApplicationRunner可以应用的场景:项目启动前,热点数据的预加载、清除临时文件、读取自定义配置信息等;
使用场景
- 初始化数据:使用
CommandLineRunner
可以在应用启动后初始化一些必要的数据,例如从数据库加载某些配置或插入初始数据。
@Component
public class DataInitializer implements CommandLineRunner {
@Override
public void run(String... args) {
System.out.println("初始化数据:插入初始数据");
// 模拟插入初始数据
insertInitialData();
}
private void insertInitialData() {
System.out.println("插入数据:用户表初始数据");
}
}
- 启动后执行任务:使用
CommandLineRunner
可以在应用启动后执行一些特定的任务,比如发送一个通知或启动一些背景任务。
@Component
public class TaskExecutor implements CommandLineRunner {
@Override
public void run(String... args) {
System.out.println("启动后执行任务:发送启动通知");
// 模拟发送启动通知
sendStartupNotification();
}
private void sendStartupNotification() {
System.out.println("通知:应用已启动");
}
}
- 读取命令行参数:使用
CommandLineRunner
可以获取并处理命令行参数,这对于需要根据启动参数动态配置应用的场景非常有用。
@Component
public class CommandLineArgsProcessor implements CommandLineRunner {
@Override
public void run(String... args) {
System.out.println("处理命令行参数:");
for (String arg : args) {
System.out.println("参数:" + arg);
}
}
}
@SpringBootApplication
public class AppConfig {
public static void main(String[] args) {
SpringApplication.run(AppConfig.class, new String[]{"参数1", "参数2", "参数3"});
}
}
ApplicationListener 和 ApplicationContextInitializer
org.springframework.context.ApplicationListener
介绍
准确的说,这个应该不算spring&springboot当中的一个扩展点,
ApplicationListener
可以监听某个事件的
event
,触发时机可以穿插在业务方法执行过程中,用户可以自定义某个业务事件。但是spring内部也有一些内置事件,这种事件,可以穿插在启动调用中。我们也可以利用这个特性,来自己做一些内置事件的监听器来达到和前面一些触发点大致相同的事情。
接下来罗列下spring主要的内置事件:
- ContextRefreshedEvent
ApplicationContext 被初始化或刷新时,该事件被发布。这也可以在
ConfigurableApplicationContext
接口中使用
refresh()
方法来发生。此处的初始化是指:所有的Bean被成功装载,后处理Bean被检测并激活,所有Singleton Bean 被预实例化,
ApplicationContext
容器已就绪可用。
- ContextStartedEvent
当使用
ConfigurableApplicationContext
(ApplicationContext子接口)接口中的 start() 方法启动
ApplicationContext
时,该事件被发布。你可以调查你的数据库,或者你可以在接受到这个事件后重启任何停止的应用程序。
- ContextStoppedEvent
当使用
ConfigurableApplicationContext
接口中的
stop()
停止
ApplicationContext
时,发布这个事件。你可以在接受到这个事件后做必要的清理的工作
- ContextClosedEvent
当使用
ConfigurableApplicationContext
接口中的
close()
方法关闭
ApplicationContext
时,该事件被发布。一个已关闭的上下文到达生命周期末端;它不能被刷新或重启
- RequestHandledEvent
这是一个 web-specific 事件,告诉所有 bean HTTP 请求已经被服务。只能应用于使用DispatcherServlet的Web应用。在使用Spring作为前端的MVC控制器时,当Spring处理用户请求结束后,系统会自动触发该事件
使用场景
- 监听自定义事件:使用
ApplicationListener
可以监听和处理自定义事件。
// 定义自定义事件
class CustomEvent extends ApplicationEvent {
private final String message;
public CustomEvent(Object source, String message) {
super(source);
this.message = message;
}
public String getMessage() {
return message;
}
}
// 监听自定义事件
@Component
public class CustomEventListener implements ApplicationListener<CustomEvent> {
@Override
public void onApplicationEvent(CustomEvent event) {
System.out.println("监听到自定义事件:处理事件");
handleCustomEvent(event);
}
private void handleCustomEvent(CustomEvent event) {
System.out.println("处理自定义事件:" + event.getMessage());
}
}
@Component
public class EventPublisher implements ApplicationEventPublisherAware {
private ApplicationEventPublisher eventPublisher;
@Override
public void setApplicationEventPublisher(ApplicationEventPublisher eventPublisher) {
this.eventPublisher = eventPublisher;
}
public void publishCustomEvent(final String message) {
System.out.println("发布自定义事件:" + message);
CustomEvent customEvent = new CustomEvent(this, message);
eventPublisher.publishEvent(customEvent);
}
}
@SpringBootApplication
public class AppConfig {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(AppConfig.class, args);
EventPublisher publisher = context.getBean(EventPublisher.class);
publisher.publishCustomEvent("这是自定义事件的消息");
}
}
@PreDestroy
javax.annotation.PreDestroy
介绍
@PreDestroy
与
@PostConstruct
一样,是 Java EE 中的一个注解,用于在 Spring 容器销毁 Bean 之前执行特定的方法。这个注解通常用于释放资源、关闭连接、清理缓存等操作。与
@PostConstruct
类似,
@PreDestroy
注解的方法会在 Bean 被销毁之前被调用。
使用场景
使用场景与 DisposableBean 类似,具体看下文。
DisposableBean
org.springframework.beans.factory.DisposableBean
介绍
这个扩展点也只有一个方法:
destroy()
,其触发时机为当此对象销毁、Spring容器关闭时,会自动执行这个方法。比如说运行
applicationContext.registerShutdownHook
时,就会触发这个方法。这个扩展点基本上用不到
注意:
- DisposableBean是一个接口,为Spring bean提供了一种释放资源的方式 ,只有一个扩展方法destroy();
- 实现DisposableBean接口,并重写destroy(),可以在Spring容器销毁bean的时候获得一次回调;
- destroy()的回调执行时机是Spring容器关闭,需要销毁所有的bean时;
- 与InitializingBean比较类似的是,InitializingBean#afterPropertiesSet()是在bean初始化的时候触发执行,DisposableBean#destroy()是在bean被销毁的时候触发执行
使用场景
- 释放数据库连接,清理临时文件:在应用被关闭时,释放数据库连接以确保资源被正确地回收,删除临时文件以确保磁盘空间被正确释放。
@Component
public class DatabaseConnectionManager implements DisposableBean {
@Override
public void destroy() {
System.out.println("释放数据库连接:关闭连接");
// 模拟关闭数据库连接
closeConnection();
}
private void closeConnection() {
System.out.println("数据库连接已关闭");
}
}
总结
我们从这些spring&springboot的扩展点当中,大致可以窥视到整个
bean的生命周期
。在业务开发或者写中间件业务的时候,可以合理利用spring提供给我们的扩展点,在spring启动的各个阶段内做一些事情。以达到自定义初始化的目的。
本人也在持续学习中,因此此篇总结如果有错误或者疏漏的地方,恳请评论或联系我进行指正,本文将持续迭代中~
。
关于作者
来自一线程序员Seven的探索与实践,持续学习迭代中~
本文已收录于我的个人博客:
https://www.seven97.top
公众号:seven97,欢迎关注~


































