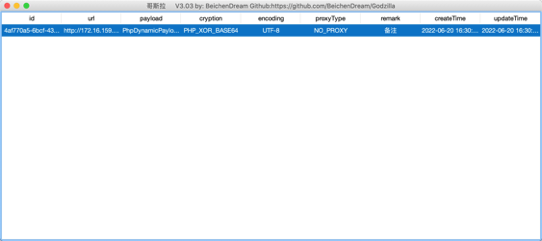
.NET 8 + WPF 企业级工作流系统
推荐一款基于.NET 8、WPF、Prism.DryIoc、MVVM设计模式、Blazor以及MySQL数据库构建的企业级工作流系统的WPF客户端框架-AIStudio.Wpf.AClient 6.0。
项目介绍
框架采用了 Prism 框架来实现 MVVM 模式,不仅简化了 MVVM 的典型应用场景,还充分利用了依赖注入(DI)、消息传递以及容器管理的优势。
网上有很多标准的MVVM的使用方法,但是没有形成一个系统级的框架。本框架从登录到具体业务的使用,还有自动升级都搭建完成。
另外框架还引入了面向切面编程(AOP)和模型关联映射(MAP)等高级特性,进一步增强了系统的扩展性和灵活性。

功能模块
1、自动更新软件。
2、使用 Prism.DryIoc 而非 Prism.Unity。
3、用 Prism 实现 AvalonDock 步骤。
4、通过 AOP 记录日志。
5、代码生成器的设计思路。
6、工作流实现策略(含编辑器和后端)。
7、创建自定义安装界面的安装包方法。
8、本地服务启动方法。
9、通用 CRUD 配置,无需定义类,直接在数据库中添加数据。
10、实现拖拽编程。
11、与BS(blazor)使用相同的结构模式,如果BS与CS进行代码统一。
12、Prism 区域窗口多开与区域注册隔离实现。
快速预览
WPF客户端下载可以直接运行,默认配置文件 AIStudio.Wpf.Client.exe.Config
<appSettings> <addkey="Title"value="AIStudio" /> <addkey="Language"value="中文" /> <addkey="FontSize"value="16" /> <addkey="FontFamily"value="宋体" /> <addkey="Accent"value="BlueGray" /> <addkey="Theme"value="BaseGray11" /> <addkey="NavigationLocation"value="Left" /> <addkey="NavigationAccent"value="Dark" /> <addkey="TitleAccent"value="Normal" /> <addkey="ToolBarLocation"value="Top" /> <addkey="Version"value="1.0.20201115-rc3" /> <addkey="ServerIP"value="http://localhost:5000/" /> <addkey="UpdateAddress"value="http://localhost:5000//update" /> </appSettings>
1、快速预览方式1
其中ServerIP就是后台接口地址。
账号密码:Admin,Admin。
2、快速预览方式2
不需要服务器,客户端直接使用SQLite本地数据,客户端独立运行。
账号密码Admin, Admin
<addkey="ServerIP"value=""/> <addkey="UpdateAddress"value="http://localhost:5000/Update/AutoUpdater.xml"/> <addkey="ConString"value="Data Source=Admin.db"/> <addkey="DatabaseType"value="SQLite"/> <addkey="DeleteMode"value="Logic"/>
注释掉ServerIP,那么是使用efcore获取数据,改变ConString和DatabaseType即可。另外,默认数据库删除模式为软删除。
3、快速预览方式3
启动ServiceMonitor,点击启动服务,待本地服务启动后,可运行客户端进行连接。
<addkey="ServerIP"value="http://localhost:5000" />

快速预览方式可直接在登录界面进行切换。

项目框架
6.0的框架如下


系统扩展 :如果需要扩展自己的页面,只需要按照这个工程的目录进行扩展即可。

项目功能
1、快速代码生成
在数据库添加新表。
选择代码生成菜单,选中查询回来的新表,区域为你所加界面的工程,比如默认值Base_Manage,将把页面加到AIStudio.Wpf.Base_Manage工程下。
点击生成即可,重新启动客户端即可快速预览(前提是服务端也用代码生成器生成(在web端的代码生成器)了相应的控制器与接口)

2、大屏界面(可拖拽,可全屏)

3、Form 表单

表单-代码生成,是代码生成器的一种补充。

4、通用crud方法
读取数据库配置,生成DataGrid,完全不需要类,后台完成相关接口,前台不需要更改任何代码,只需要在数据库插入脚本即可。
根据类直接生成DataGrid

5、大文件上传与下载


6、多窗口、多屏模式

项目地址
Github:
https://github.com/akwkevin/aistudio.-wpf.-aclient
Gitee:
https://gitee.com/akwkevin/aistudio.-wpf.-aclient
控件库:
如果你觉得这篇文章对你有帮助,不妨点个赞支持一下!你的支持是我继续分享知识的动力。如果有任何疑问或需要进一步的帮助,欢迎随时留言。
也可以加入微信公众号
[DotNet技术匠]
社区,与其他热爱技术的同行一起交流心得,共同成长!
优秀是一种习惯,欢迎大家留言学习!