LoRA大模型微调的利器
LoRA模型是小型的Stable Diffusion模型,它们对checkpoint模型进行微小的调整。它们的体积通常是检查点模型的10到100分之一。因为体积小,效果好,所以lora模型的使用程度比较高。
这是一篇面向从未使用过LoRA模型的初学者的教程。你将了解LoRA模型是什么,在哪里找到它们,以及如何在AUTOMATIC1111 GUI中使用它们。然后,你将在文章末尾找到一些LoRA模型的演示。
LoRA模型是什么?
LoRA(Low-Rank Adaptation)是一种微调Stable Diffusion模型的训练技术。
虽然我们已经有像Dreambooth和文本反转这样的训练技术。那么LoRA有什么用呢?
LoRA实际上可以看做是Dreambooth和文本反转embeddings的折中方案。Dreambooth功能虽然强大,但模型文件会比较大(2-7 GB)。文本反转非常小(约100 KB),但能做的事情比较少。
LoRA介于两者之间。它的文件大小更容易管理(2-200 MB),并且训练能力相当不错。
因为checkpoint比较大,所以硬盘空间存储会是一个问题。而LoRA是解决存储问题的优秀方案。
像文本反转一样,
你不能单独使用LoRA模型
。它必须与模型检查点文件一起使用。LoRA通过对配套的模型文件进行小的修改来改变风格。
LoRA是定制AI艺术模型的绝佳方式,而不会占用太多本地存储空间。
LoRA如何工作?
LoRA对Stable Diffusion模型中最关键的部分进行小的修改:
交叉注意力层
。研究人员发现,微调这部分模型就足以实现良好的训练。交叉注意力层是下面Stable Diffusion模型架构中的黄色部分。
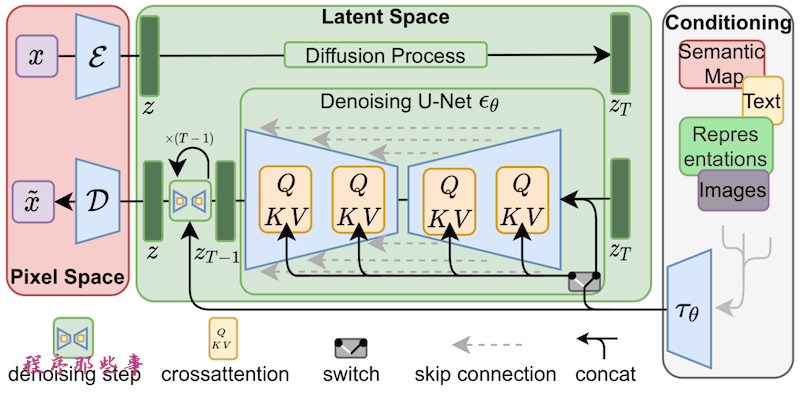
交叉注意力层的权重以
矩阵
的形式排列。矩阵只是按列和行排列的一堆数字,就像Excel电子表格上一样。LoRA模型通过将自己的权重加到这些矩阵上来微调模型。
如果LoRA模型需要存储相同数量的权重,它们的文件怎么会更小呢?
LoRA的技巧是将矩阵分解成两个更小的(低秩)矩阵。
通过这样做,它可以存储更少的数字。让我们通过以下示例来说明。
假设模型有一个100行100列的矩阵。那是10000个数字(100x 100)需要存储在模型文件中。LoRA将矩阵分解成一个1000x2矩阵和一个2x100矩阵。那只有400个数字(100 x 2 + 2 x 100,如果矩阵够更大的话,LoRA模型会减少的更多。这就是为什么LoRA文件要小得多的原因。
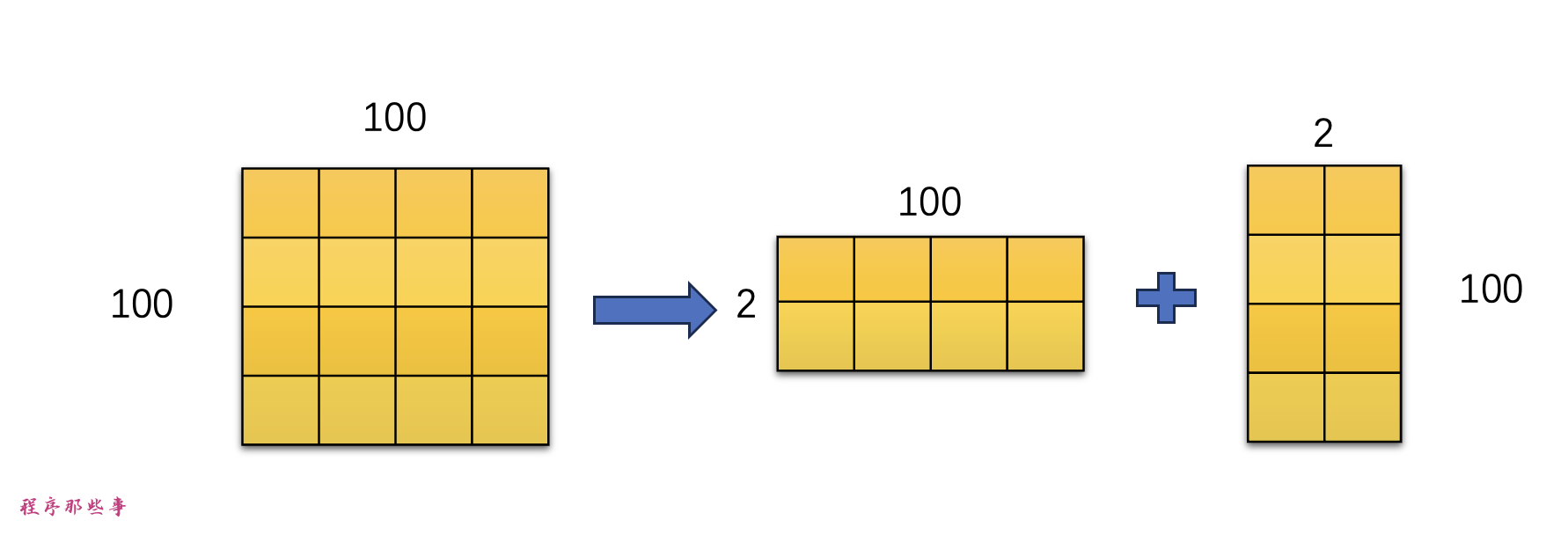
在这个例子中,矩阵的
秩
是2。它比原始尺寸低得多,所以它们被称为
低秩矩阵
。秩可以低至1。
这种操作必定会带来数据上的缺失,但是在交叉注意力层来说,这些损失是无伤大雅的。所以Lora这种做法是可行的。
在哪里找到LoRA模型?
Civitai
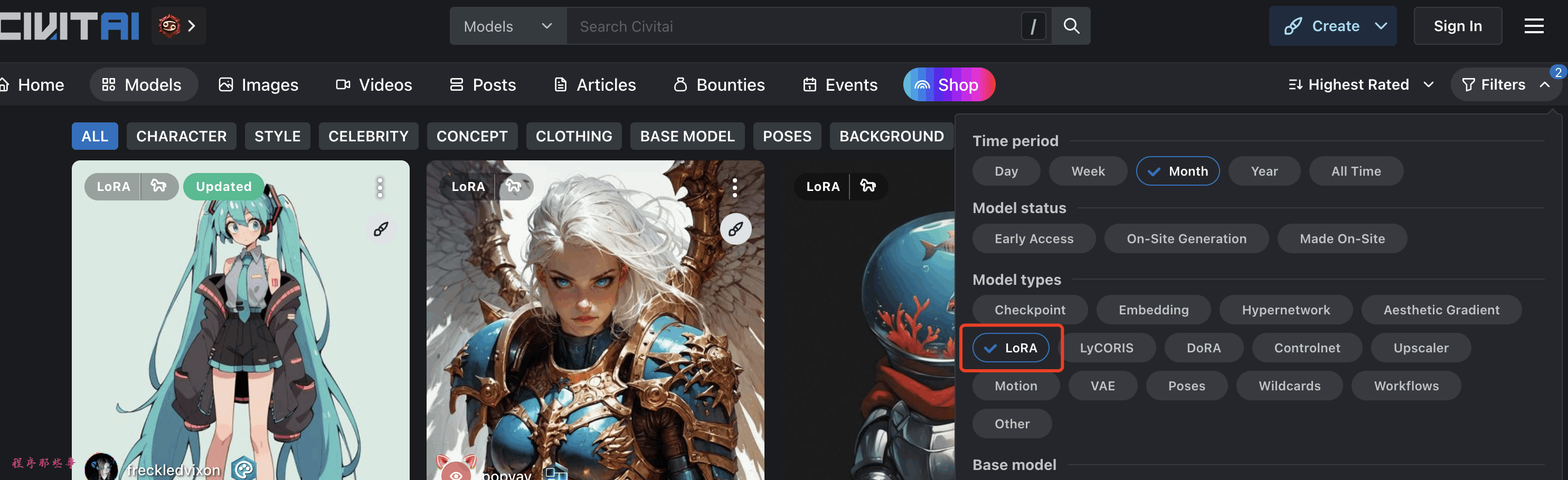
寻找LoRA的首选地点是Civitai。该网站托管了大量LoRA模型的集合。应用LORA过滤器以仅查看LoRA模型。不过里面的大多数模型都是:女性肖像,动漫,现实主义插图风格等。
Hugging Face
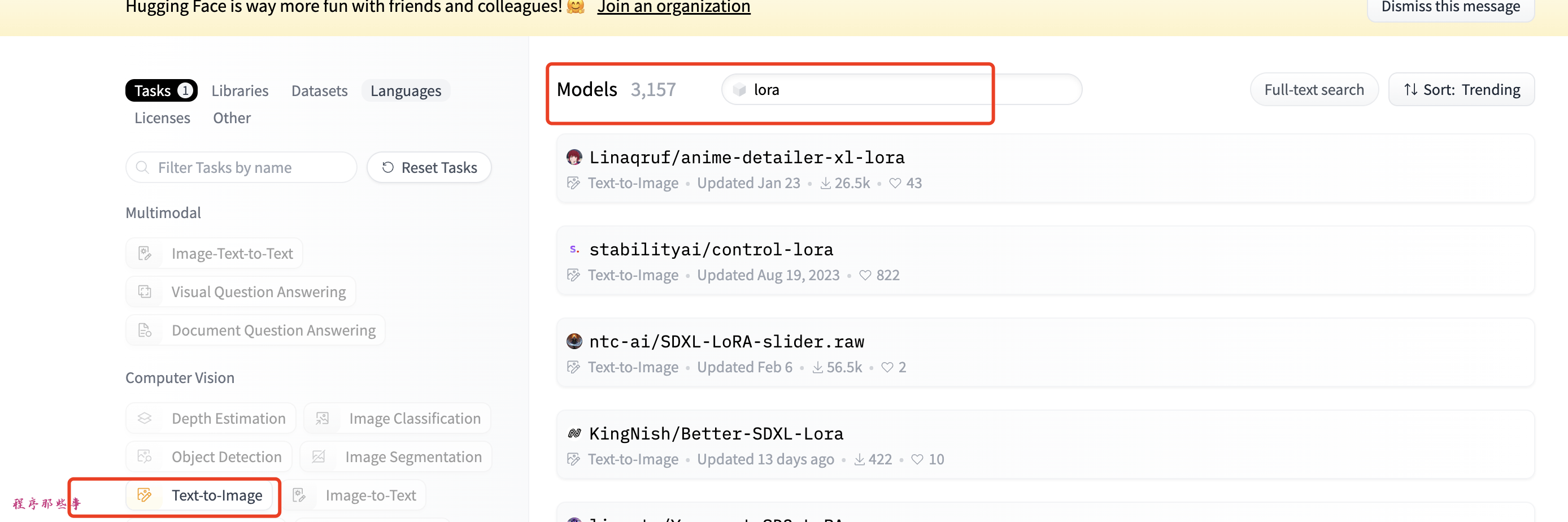
Hugging Face是另一个LoRA库的好来源。你会发现更多种类的LoRA模型。但那里的LoRA模型可能没有C站多,并且也不太直观。因为没有图片预览。
如何使用LoRA?
这里,我将介绍如何在AUTOMATIC1111 Stable Diffusion GUI中使用LoRA模型。
AUTOMATIC1111原生支持LoRA。你不需要安装任何扩展。
第1步:安装LoRA模型
要在AUTOMATIC1111 webui中安装LoRA模型,请将模型文件放入以下文件夹。
stable-diffusion-webui/models/Lora
第2步:在提示中使用LoRA
要在AUTOMATIC1111 Stable Diffusion WebUI中添加带权重的LoRA,请在提示或否定提示中使用以下语法:
<lora: name: weight>
name
是LoRA模型的名称。它可以与文件名不同。
weight
是应用于LoRA模型的权重。默认值为1。将其设置为0将禁用模型。
那么怎么知道lora的名字是什么呢?
其实我们并不需要手动输入lora的名字,我们只需要点击下面的lora标签:
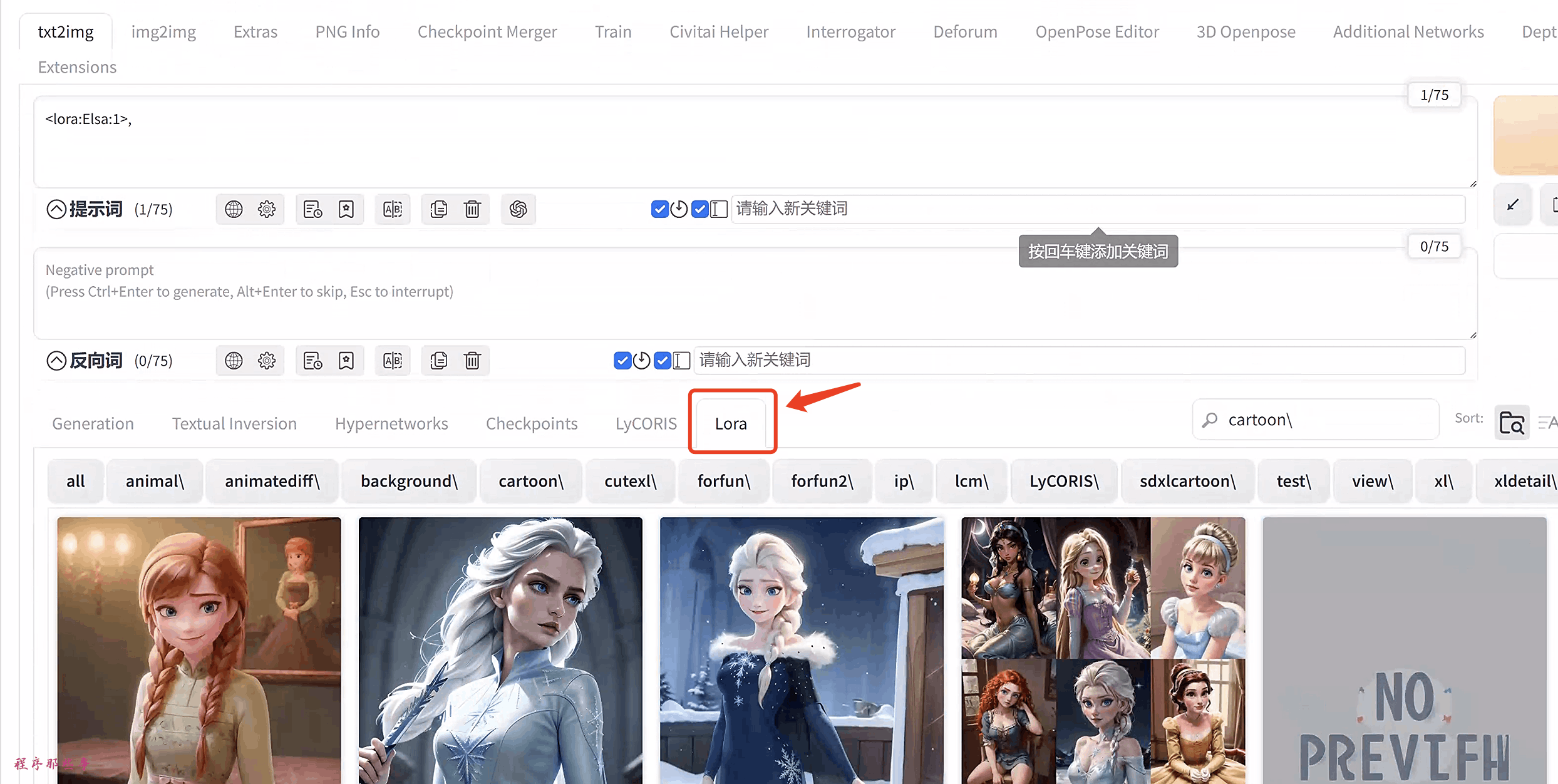
你应该看到一个已安装的LoRA模型列表。单击你想要使用的模型。
LoRA短语将被插入到提示中。
就是这样!
使用LoRA的注意事项
你可以
调整乘数
以增强或调整效果。将乘数设置为0将禁用LoRA模型。你可以在0和1之间调整风格效果。
一些LoRA模型是使用Dreambooth训练的。你需要包括一个
触发关键词
才能使用LoRA模型。你可以在模型页面上找到触发关键词。
类似于嵌入,你可以同时使用
多个LoRA模型
。你也可以将它们与嵌入一起使用。
在AUTOMATIC1111中,LoRA短语不是提示的一部分。在应用LoRA模型后,它将被删除。这意味着你不能使用像[keyword1:keyword2: 0.8]这样的提示语法来使用他们。
实用的LoRA模型
这里介绍一些在实际应用中比较实用的Lora。
add_detail

谁不想要AI图像中更多的细节?细节调整器允许你增加或减少图像中的细节。现在,你可以调整你想要的细节量。
使用正LoRA权重来增加细节,使用负权重来减少细节。
add_saturation
这个lora可以给图片添加一些饱和度,效果如下:

add_brightness
这个lora可以用来控制图片的亮度:

总结
LoRA模型是checkpoint模型的小型修改器。你可以通过在提示中包含一个短语轻松地在AUTOMATIC1111中使用它们。
我将在以后的文章中告诉你如何自己来训练一个LoRA模型。