ECharts 是一款由百度开源的数据可视化工具,它提供了丰富的图表类型,如折线图、柱状图、饼图、散点图、
雷达图
、地图、K线图、热力图、仪表盘等,以及丰富的交互功能。ECharts 组件的核心功能实现原理主要包括以下几个方面:
数据驱动
:
ECharts 采用数据驱动的设计理念,图表的生成和更新都是基于数据的。用户通过设置
option
对象来描述图表的配置,包括数据、坐标轴、系列类型、图例等信息。
Canvas 或 SVG 渲染
:
ECharts 支持使用 Canvas 或 SVG 作为底层渲染引擎。Canvas 适合动态或实时的图表渲染,而 SVG 适合静态或交互较多的图表。ECharts 默认使用 Canvas 渲染。
响应式布局
:
ECharts 支持响应式布局,图表容器的大小可以动态变化,图表会根据容器的大小自动缩放。
动画效果
:
ECharts 提供了丰富的动画效果,包括数据的渐显、数据的过渡动画等,使得数据的变化更加直观和生动。
交互功能
:
ECharts 支持多种交互功能,如工具提示(Tooltip)、数据缩放(DataZoom)、图例开关(Legend)、坐标轴缩放(AxisZoom)等,增强了用户的交互体验。
事件监听
:
ECharts 提供了事件监听机制,用户可以监听并响应图表的各种事件,如点击、悬浮、数据项选择等,从而实现复杂的交互逻辑。
多维度数据展示
:
ECharts 允许用户在图表中展示多维度的数据,例如在散点图中通过数据点的颜色和大小来表示额外的维度。
扩展性和定制性
:
ECharts 提供了扩展和定制的能力,用户可以通过自定义系列(Custom Series)和扩展插件来实现特殊的图表效果。
性能优化
:
ECharts 进行了一系列的性能优化,如懒渲染、脏矩形渲染、层级渲染等,以支持大数据量的图表渲染。
多语言支持
:
ECharts 支持多语言,可以根据用户的语言偏好显示不同的文本内容。
组件化设计
:
ECharts 的图表由多个组件组成,如标题(Title)、工具箱(Toolbox)、图例(Legend)、坐标轴(Axis)、数据系列(Series)等,每个组件都有独立的配置项。
数据转换和处理
:
ECharts 提供了数据转换和处理的功能,如数据的过滤、排序、聚合等,使得数据可以按照用户的需要进行展示。
ECharts 的实现原理涉及到了计算机图形学、数据结构、动画设计等多个领域的知识。它的设计哲学是简单、灵活、可扩展,这使得它成为了数据可视化领域非常受欢迎的工具之一。
下面我们以实现雷达图为例,来介绍具体的代码实现案例。
如何使用 ECharts 实现一个交互式的雷达图?
要使用 ECharts 实现一个交互式的雷达图,我们需要设置雷达图的配置项,并且可以通过监听用户的交互事件来增强图表的互动性,废话不多说,上代码:
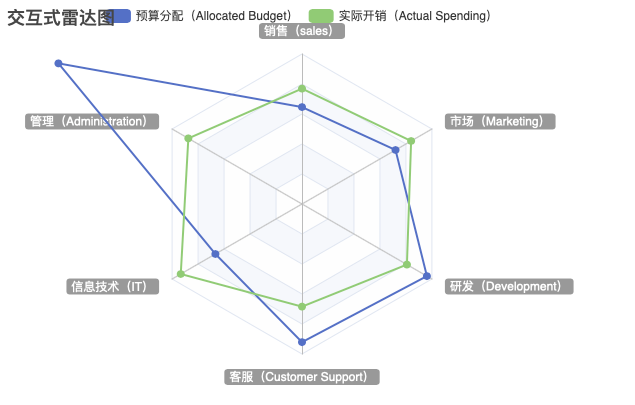
步骤1:引入ECharts库
首先,在你的HTML文件中引入ECharts库:
<script src="https://cdn.jsdelivr.net/npm/echarts/dist/echarts.min.js"></script>
步骤2:创建图表容器
在HTML文件中,为雷达图创建一个容器:
<div id="main" style="width: 600px;height:400px;"></div>
步骤3:编写雷达图配置
在JavaScript中,初始化ECharts实例并配置雷达图。我们需要定义雷达图的指标(indicator),数据(series)以及其他配置项。
var myChart = echarts.init(document.getElementById('main'));
var option = {
title: {
text: '交互式雷达图'
},
tooltip: {},
legend: {
data: ['预算分配(Allocated Budget)', '实际开销(Actual Spending)']
},
radar: {
// shape: 'circle',
name: {
textStyle: {
color: '#fff',
backgroundColor: '#999',
borderRadius: 3,
padding: [3, 5]
}
},
indicator: [
{ name: '销售(sales)', max: 6500},
{ name: '管理(Administration)', max: 16000},
{ name: '信息技术(Information Technology)', max: 30000},
{ name: '客服(Customer Support)', max: 38000},
{ name: '研发(Development)', max: 52000},
{ name: '市场(Marketing)', max: 25000}
]
},
series: [{
name: '预算 vs 开销(Budget vs spending)',
type: 'radar',
// areaStyle: {normal: {}},
data : [
{
value : [4200, 30000, 20000, 35000, 50000, 18000],
name : '预算分配(Allocated Budget)'
},
{
value : [5000, 14000, 28000, 26000, 42000, 21000],
name : '实际开销(Actual Spending)'
}
]
}]
};
myChart.setOption(option);
步骤4:添加交互功能
我们可以通过监听ECharts提供的事件来添加交互功能,例如
click
事件、
mouseover
事件等。
myChart.on('click', function (params) {
// 点击雷达图的某个区域时的交互逻辑
console.log(params.name); // 打印点击的区域名称
});
myChart.on('mouseover', function (params) {
// 鼠标悬浮在雷达图的某个区域时的交互逻辑
console.log(params.seriesName); // 打印鼠标悬浮的数据系列名称
});
步骤5:测试雷达图
完事,我们在浏览器中打开HTML文件,查看雷达图是否按预期显示,并且看下交互功能是否正常工作。
来解释一下
- 雷达图配置
:在
option
对象中,
radar
属性定义了雷达图的结构,包括指标(indicator)的最大值和名称。
series
属性定义了数据系列,每个系列可以表示一组数据。
- 事件监听
:通过
myChart.on
方法监听图表事件,当用户与图表交互时(如点击或悬浮),可以执行相应的逻辑。
如何使用 ECharts 实现一个带有多个系列的雷达图?
进一步看看,我们要在 ECharts 中实现一个带有多个系列的雷达图,就需要在配置项中定义多个系列(series),每个系列可以表示一组数据。来看一下代码实现:
步骤1:引入ECharts库
首先,在我们的HTML文件中引入ECharts库:
<script src="https://cdn.jsdelivr.net/npm/echarts/dist/echarts.min.js"></script>
步骤2:创建图表容器
在HTML文件中,为雷达图创建一个容器:
<div id="main" style="width: 600px;height:400px;"></div>
步骤3:编写雷达图配置
在JavaScript中,初始化ECharts实例并配置雷达图。我们需要定义雷达图的指标(indicator),多个数据系列(series)以及其他配置项。
var myChart = echarts.init(document.getElementById('main'));
var option = {
title: {
text: '多系列雷达图'
},
tooltip: {},
legend: {
data: ['系列1', '系列2']
},
radar: {
// shape: 'circle',
name: {
textStyle: {
color: '#fff',
backgroundColor: '#999',
borderRadius: 3,
padding: [3, 5]
}
},
indicator: [
{ name: '维度1', max: 100},
{ name: '维度2', max: 100},
{ name: '维度3', max: 100},
{ name: '维度4', max: 100},
{ name: '维度5', max: 100}
]
},
series: [{
name: '系列1',
type: 'radar',
data : [
{
value : [80, 70, 90, 60, 70],
name : '系列1'
}
]
},
{
name: '系列2',
type: 'radar',
data : [
{
value : [90, 80, 70, 90, 80],
name : '系列2'
}
]
}]
};
myChart.setOption(option);
步骤4:测试雷达图
现在可以在浏览器中打开这个HTML文件,来查看雷达图是否按预期显示,并且多个系列是否正确展示,就不展示效果图了。
来解释一下代码实现
- 雷达图配置
:在
option
对象中,
radar
属性定义了雷达图的结构,包括指标(indicator)的最大值和名称。
series
属性定义了多个数据系列,每个系列可以表示一组数据。
- 数据系列
:每个系列通过
type: 'radar'
指定为雷达图类型,
data
属性包含一个数组,数组中的每个对象代表一个数据点,
value
属性是一个数组,包含了每个维度的值。
如何为 ECharts 雷达图设置不同的颜色和标签?
在 ECharts 中为雷达图设置不同的颜色和标签,可以通过配置项中的
series
和
radar
属性来实现:
步骤1:引入ECharts库
在HTML文件中引入ECharts库:
<script src="https://cdn.jsdelivr.net/npm/echarts/dist/echarts.min.js"></script>
步骤2:创建图表容器
在HTML文件中,为雷达图创建一个容器:
<div id="main" style="width: 600px;height:400px;"></div>
步骤3:编写雷达图配置
在JavaScript中,初始化ECharts实例并配置雷达图,我们就可以在
series
中设置不同的颜色和标签。
var myChart = echarts.init(document.getElementById('main'));
var option = {
title: {
text: '多系列雷达图'
},
tooltip: {},
legend: {
data: ['系列1', '系列2']
},
radar: {
// shape: 'circle',
name: {
textStyle: {
color: '#fff',
backgroundColor: '#999',
borderRadius: 3,
padding: [3, 5]
}
},
indicator: [
{ name: '维度1', max: 100},
{ name: '维度2', max: 100},
{ name: '维度3', max: 100},
{ name: '维度4', max: 100},
{ name: '维度5', max: 100}
],
splitLine: {
lineStyle: {
color: 'rgba(255, 255, 255, 0.5)'
}
},
splitArea: {
areaStyle: {
color: ['rgba(114, 172, 209, 0.2)', 'rgba(114, 172, 209, 0.4)', 'rgba(114, 172, 209, 0.6)', 'rgba(114, 172, 209, 0.8)', 'rgba(114, 172, 209, 1)']
}
}
},
series: [{
name: '系列1',
type: 'radar',
color: '#f9713c', // 设置系列颜色
data : [
{
value : [80, 70, 90, 60, 70],
name : '系列1'
}
]
},
{
name: '系列2',
type: 'radar',
color: '#b3e4a1', // 设置系列颜色
data : [
{
value : [90, 80, 70, 90, 80],
name : '系列2'
}
]
}]
};
myChart.setOption(option);
步骤4:测试雷达图
接下来测试一下,在浏览器中打开HTML文件,查看雷达图,每个系列具有不同的颜色和标签。
继续解释一下代码实现
- 颜色设置
:在
series
配置中,通过
color
属性为每个系列设置不同的颜色。
- 标签设置
:在
radar
配置中,
name
属性定义了雷达图中每个维度的标签样式,包括文本颜色和背景颜色。
- 分割线和区域颜色
:
splitLine
和
splitArea
属性分别定义了雷达图的分割线和区域颜色,可以设置为渐变色或不同的颜色。
如何为 ECharts 雷达图添加动态数据更新功能?
为 ECharts 雷达图添加动态数据更新功能,我们可以使用 JavaScript 的定时器(如
setInterval
)来定期从服务器获取新数据,并使用 ECharts 提供的
setOption
方法来更新图表:
步骤1:引入ECharts库
在HTML文件中引入ECharts库:
<script src="https://cdn.jsdelivr.net/npm/echarts/dist/echarts.min.js"></script>
步骤2:创建图表容器
在HTML文件中,为雷达图创建一个容器:
<div id="main" style="width: 600px;height:400px;"></div>
步骤3:初始化雷达图
在JavaScript中,初始化ECharts实例并设置初始的雷达图配置。
var myChart = echarts.init(document.getElementById('main'));
var option = {
// 雷达图的初始配置
// ...
};
myChart.setOption(option);
步骤4:定义数据更新函数
创建一个函数来获取新数据并更新雷达图。我们可以使用 AJAX 请求从服务器获取数据,或者使用任何其他方法来获取数据。
function fetchDataAndUpdateChart() {
// 假设这是获取数据的函数,可以是AJAX请求或其他方式
// 这里使用setTimeout模拟数据更新
setTimeout(function () {
var newData = {
value: [Math.random() * 100, Math.random() * 100, Math.random() * 100, Math.random() * 100, Math.random() * 100],
name: '动态数据'
};
// 更新雷达图数据
myChart.setOption({
series: [{
name: '系列1',
data: [newData]
}]
});
// 递归调用以实现定期更新
fetchDataAndUpdateChart();
}, 2000); // 每2秒更新一次数据
}
// 初始调用数据更新函数
fetchDataAndUpdateChart();
O了,完美展示一下效果。
解释代码
- 初始化雷达图
:设置雷达图的初始配置,包括标题、工具提示、图例、雷达指标、系列等。
- 动态数据更新
:通过
fetchDataAndUpdateChart
函数定期获取新数据,并使用
setOption
方法更新雷达图。在这个例子中,使用
setTimeout
来模拟定期从服务器获取数据。
- 递归调用
:在
fetchDataAndUpdateChart
函数的末尾递归调用自身,以实现定时更新数据。
最后
以上就是使用 ECharts 来实现雷达图的案例介绍,使用 ECharts实现数据大屏的展示,可以很炫,比如像这样的图:
https://www.bocloud.com.cn/manager/upload/202303/07/202303071455311822.png

好了,今天的内容就到这里,欢迎关注威哥爱编程,原创不易,感谢点赞关注评论,支持一下呗。