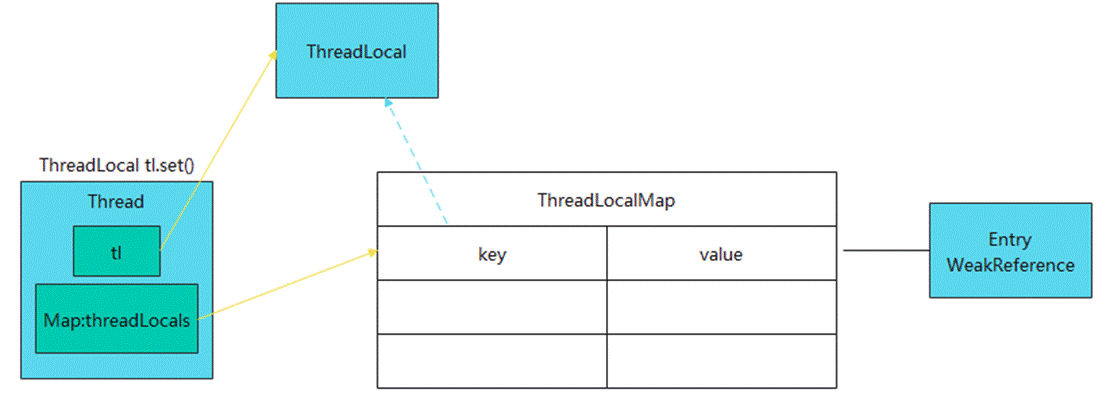
在云计算的浪潮中,基础设施管理变得越来越复杂。如何高效地配置和管理云资源,成为了每个开发者和运维工程师必须面对的挑战。Terraform,作为一种强大的基础设施即代码(IaC)工具,为我们提供了一种简洁而有效的解决方案。
在这篇博客中,我将深入探讨Terraform的功能与使用场景,帮助你理解其在云资源管理中的重要性。同时,我会详细介绍Terraform的安装步骤,以便你能快速上手。
这篇博客特别适合入门级读者,内容详尽易懂,确保即使是初学者也能顺利跟随。我将通过实际操作,使用Terraform在AWS上创建各种基础设施资源,包括VPC、子网、路由表、网关、安全组、EC2实例、EBS卷和弹性IP(EIP)。此外,我还将分享如何创建EKS的IAM角色,定义EKS的Terraform配置文件,以及如何配置EKS Node Group的IAM角色和节点组,一步一步创建EKS集群。
每个Terraform文件都将配有详尽的解释,让你清晰理解每一行代码的意义和作用。无论你是云计算新手还是希望提升技能的专业人士,这篇博客都将为你提供实用的指导和深入的见解,帮助你轻松迈入Terraform的世界。让我们一起开始这段充满乐趣的学习之旅吧!
一、
Terraform 简介
1. 特性与使用场景
Terraform 是一个开源的基础设施即代码(Infrastructure as Code, IaC)工具,由 HashiCorp 开发。它允许用户通过配置文件以编程方式管理云基础设施、物理设备以及其他服务的资源。以下是 Terraform 的一些关键特性和使用场景:
基础设施即代码
Terraform 使用简单的声明性配置语言(HCL,HashiCorp Configuration Language),使用户能够定义和管理他们的基础设施。这种方式带来了多个优势:
- 版本控制
: 通过将配置文件存储在版本控制系统中,用户可以跟踪基础设施的历史变更,轻松回滚到先前的状态。
- 共享和复用
: 配置文件可以作为代码库的一部分进行共享,促进团队成员之间的协作和最佳实践的传递。
- 审计和合规性
: 明确的配置文件使得基础设施的审计和合规性检查变得简单,通过对比配置文件和实际状态,可以快速识别不一致性。
多云支持
Terraform 支持多种云服务提供商,包括 AWS、Azure、Google Cloud、阿里云等,用户可以在一个配置文件中同时管理不同云环境的资源。这种多云管理能力带来了如下好处:
- 灵活性
: 企业可以根据需求和成本优化选择合适的云服务提供商,而无需重新编写大量配置代码。
- 灾难恢复
: 可以在不同云环境中实现资源备份和故障转移,提升业务连续性。
- 集成能力
: 不同云提供商的服务可以无缝集成,构建跨云应用架构。
状态管理
Terraform 会维护一个关于当前基础设施状态的文件(状态文件),以便在后续的变更中跟踪和管理资源的状态。状态管理的优势包括:
- 一致性
: 状态文件确保用户对资源的操作是基于最新状态的,防止并发修改导致的冲突。
- 变更检测
: 在应用新配置之前,Terraform 会根据状态文件与配置文件的比较,提供清晰的变更计划,确保用户了解即将进行的操作。
- 远程状态
: 支持将状态文件存储在远程后端(如 S3),便于团队协作和提高安全性。
资源依赖管理
Terraform 能够自动处理资源之间的依赖关系,确保在创建或修改资源时,按照正确的顺序进行操作。这减少了手动处理依赖的复杂性,提高了自动化水平。具体来说:
- 自动排序
: 用户不必手动指定创建顺序,Terraform 会根据资源之间的引用关系自动处理。
- 并行处理
: 通过识别独立资源,Terraform 可以并行创建或删除资源,缩短整体执行时间。
可扩展性
Terraform 提供了丰富的插件和模块,用户可以通过自定义模块来扩展 Terraform 的功能,实现更复杂的基础设施架构。可扩展性的特点包括:
- 社区贡献
: Terraform 拥有一个活跃的社区,用户可以方便地找到现成的模块并进行集成,减少重复工作。
- 模块化设计
: 用户可以将常用的配置封装成模块,提高配置的复用性和可读性。
跨团队协作
Terraform 的配置文件可以与 Git 等版本控制系统结合使用,支持团队协作。团队协作的优势包括:
- 代码审查
: 团队成员可以对基础设施的变更进行审查,确保变更经过充分验证,提升基础设施的稳定性。
- 透明性
: 通过版本控制,所有团队成员都能清楚地看到基础设施的变更历史和决策过程,促进知识的共享。
使用场景
- 创建和管理云基础设施
: 通过 Terraform,用户可以轻松创建和管理各种云资源,如 VPC、EC2 实例、RDS 数据库、EKS 集群等,提升管理效率。
- 实现持续集成和持续交付(CI/CD)中的基础设施自动化
: 将基础设施配置纳入 CI/CD 流程,确保环境一致性,降低手动操作的风险。
- 配置和管理多个环境
: 使用 Terraform,用户可以轻松配置和管理开发、测试和生产环境的基础设施,保证环境之间的一致性。
- 通过模块化设计实现基础设施的复用
: 用户可以创建和共享模块,以便在不同项目中复用相同的基础设施配置。
总之,Terraform 是一个强大且灵活的工具,能够帮助开发团队以代码的方式高效管理云基础设施,提升运维效率和灵活性。通过 Terraform,用户能够在多云环境中实现自动化和标准化,适应快速变化的业务需求。
2. Terraform 工作原理和工作流程
Terraform 是一个基础设施即代码(IaC)工具,通过以下几个步骤来管理基础设施:
配置文件(.tf 文件)
: 用户首先通过编写 Terraform 配置文件来定义所需的基础设施。这些文件使用 HCL(HashiCorp Configuration Language)语言,描述资源的类型、属性和配置。
初始化(terraform init)
: 在开始使用 Terraform 之前,用户需要运行
terraform init
命令。这一步会初始化工作目录,下载所需的提供程序(如 AWS、Azure 等),并准备后续的操作。
生成执行计划(terraform plan)
: 使用
terraform plan
命令,Terraform 会读取配置文件并生成执行计划,展示将要执行的操作(如创建、更新或删除资源)。这一步允许用户预览即将进行的变更,避免意外操作。
应用变更(terraform apply)
: 在确认执行计划后,用户可以运行
terraform apply
命令,Terraform 会根据生成的计划实际执行相应的操作,创建、更新或删除云资源。
状态管理
: Terraform 会维护一个状态文件(
terraform.tfstate
),记录当前基础设施的状态。这个文件用于跟踪资源的实际状态,以便在后续操作中进行对比和管理。
变更管理
: 当需要对基础设施进行更改时,用户只需修改配置文件,然后重复执行
plan
和
apply
流程。Terraform 会自动识别资源的变更,并进行相应的更新。
销毁资源(terraform destroy)
: 当不再需要某些资源时,用户可以运行
terraform destroy
命令,Terraform 会删除所有配置文件中定义的资源,确保清理工作整洁。
通过这些步骤,Terraform 能够以一致性和可预测的方式管理和部署基础设施,使用户在整个基础设施生命周期中保持对资源的控制和管理。
3. Terraform基本使用概念
3.1 Provider
3.2 Terraform状态文件
- 定义
:
terraform.tfstate
是 Terraform 用来跟踪已管理资源状态的文件。它存储了当前基础设施的详细信息。
- 作用
: 这个文件帮助 Terraform 在执行计划(
terraform plan
)和应用(
terraform apply
)时了解哪些资源已经创建、哪些需要更新或删除。
- 注意事项
: 状态文件敏感且重要,应妥善保管,避免直接修改。为了提高安全性,通常建议使用远程后端(如 S3)存储状态文件。
3.3 Terraform配置文件
3.4 变量文件
3.5 输出文件
二、
环境准备
1. 安装 Terraform
请根据自己的操作系统参考 https://developer.hashicorp.com/terraform/install,本文之列出常见的操作系统安装方式。
brew tap hashicorp/tap
brew install hashicorp/tap/terraform
https://releases.hashicorp.com/terraform/1.9.8/terraform_1.9.8_windows_amd64.zip
Ubuntu/Debian
wget -O- https://apt.releases.hashicorp.com/gpg | sudo gpg --dearmor -o /usr/share/keyrings/hashicorp-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/hashicorp-archive-keyring.gpg] https://apt.releases.hashicorp.com $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/hashicorp.list
sudo apt update && sudo apt install terraform
CentOS/RHEL
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://rpm.releases.hashicorp.com/RHEL/hashicorp.repo
sudo yum -y install terraform
2. 配置 AWS CLI
确保配置的访问密钥拥有足够的权限。
详情可参考:
https://www.cnblogs.com/Sunzz/p/18432935
2.1. 创建
~/.aws/config文件
内容如下:
[default]
region = us-west-1
其中region请根据你的实际情况进行修改即可
2.2 创建
~/.aws/credentials文件
内容如下:
[default]
aws_access_key_id = AKIA2LXD....
aws_secret_access_key = ZvQllpYL.....
转载请著名原文地址:
https://www.cnblogs.com/Sunzz/p/18498915
3. 初始化
terraform
3.1 创建
variables.tf
文件
variables.tf用来存多次用到的变量
内容如下:
variable "aws_region" {
default = "us-west-1"
}
定义了使用的区域,这里使用us-west-1,请根据你的实际情况进行修改。
3.2 创建
provider.tf
文件
配置定义了 Terraform 使用的
providers
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.0"
}
}
}
provider "aws" {
region = var.aws_region
}
解释
3.3 初始化
初始化过程中会用到国外的一些网络资源,由于众所周知的原因,下载的时候可能出现一些问题,这里建议直接使用你的工具即可。
根据实际情况修改ip和端口
export https_proxy=http://127.0.0.1:7890
export http_proxy=http://127.0.0.1:7890
terraform init
输出如下:
Initializing the backend...
Initializing provider plugins...
- Finding hashicorp/aws versions matching ">= 4.0.0"...
- Installing hashicorp/aws v5.72.1...
- Installed hashicorp/aws v5.72.1 (signed by HashiCorp)
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
三、创建aws 网络资源
本文每次创建之前我都会先创建对应资源的tf文件,一种资源一个tf文件,比如所有的ec2都放在一个ec2.tf文件中。
然后都会执行
terraform
plan -out=tf.plan
来预演一下执行结果,防止出错。
terraform plan -out=tf.plan
是一个“预演”工具。它不会真的去创建或改动资源,而是生成一个详细的计划,告诉我们“如果执行,会做哪些具体更改”。这个计划可以保存成一个文件(比如这里的
tf.plan
),这样我们可以先检查它,确保没问题后,再真正去执行。这不仅减少了出错的机会,还让我们随时知道哪些资源会被创建、修改或删除。
1. 创建vpc
编写vpc.tf文件
resource "aws_vpc" "tf_vpc" {
cidr_block = "10.10.0.0/16"
enable_dns_hostnames = true
enable_dns_support = true
tags = {
Name = "tf-vpc"
}
}
解释:
resource "aws_vpc" "tf_vpc"
: 定义了一个 AWS VPC 资源,名称为
tf_vpc
。你可以在 Terraform 配置中引用这个名称。
cidr_block = "10.10.0.0/16"
: 这是 VPC 的 CIDR(无类域间路由)块,指定了 IP 地址范围。
10.10.0.0/16
表示该 VPC 可以使用从
10.10.0.0
到
10.10.255.255
的所有 IP 地址。
enable_dns_hostnames = true
: 启用 DNS 主机名。设置为
true
时,AWS 将为 VPC 中的 EC2 实例分配 DNS 主机名,这样你可以通过 DNS 名称而不是 IP 地址访问这些实例。
enable_dns_support = true
: 启用 DNS 支持。这意味着 VPC 将能够解析 DNS 名称。这对于在 VPC 内部使用 AWS 服务和实例之间的通信非常重要。
tags = { Name = "tf-vpc" }
: 为 VPC 添加标签。在 AWS 控制台中,标签可以帮助你识别和管理资源。这里的标签将 VPC 命名为 "tf-vpc"。
预执行
terraform plan -out=tf.plan
terraform plan
terraform plan -out=tf.plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the
following symbols:
+ create
Terraform will perform the following actions:
# aws_vpc.tf_vpc will be created
+ resource "aws_vpc" "tf_vpc" {
+ arn = (known after apply)
+ cidr_block = "10.10.0.0/16"
+ default_network_acl_id = (known after apply)
+ default_route_table_id = (known after apply)
+ default_security_group_id = (known after apply)
+ dhcp_options_id = (known after apply)
+ enable_dns_hostnames = true
+ enable_dns_support = true
+ enable_network_address_usage_metrics = (known after apply)
+ id = (known after apply)
+ instance_tenancy = "default"
+ ipv6_association_id = (known after apply)
+ ipv6_cidr_block = (known after apply)
+ ipv6_cidr_block_network_border_group = (known after apply)
+ main_route_table_id = (known after apply)
+ owner_id = (known after apply)
+ tags = {
+ "Name" = "tf-vpc"
}
+ tags_all = {
+ "Name" = "tf-vpc"
}
}
Plan: 1 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
创建vpc
terraform apply tf.plan
aws_vpc.tf_vpc: Creating...
aws_vpc.tf_vpc: Still creating... [10s elapsed]
aws_vpc.tf_vpc: Creation complete after 13s [id=vpc-0f2e1cdca0cf5a306]
转载请著名原文地址:
https://www.cnblogs.com/Sunzz/p/18498915
2. 创建子网
新建变量
给
variables.tf添加如下内容:
variable "az_1" {
description = "Availability Zone for the first subnet"
type = string
default = "us-west-1a"
}
variable "az_2" {
description = "Availability Zone for the second subnet"
type = string
default = "us-west-1b"
}
解释:
variable "az_1/2"
:
description
: 提供了一个简短的说明,指明这个变量代表第一个子网的可用区。
type
: 指定变量的数据类型为字符串 (
string
)。
default
: 设置默认值为
"us-west-1a/b"
。如果在 Terraform 配置中没有为此变量提供其他值,则将使用这个默认值。
定义子网配置的subnet.tf文件
# 定义第一个子网 tf-subnet01 (10.10.1.0/24, 使用变量指定可用区)
resource "aws_subnet" "tf_subnet01" {
vpc_id = aws_vpc.tf_vpc.id
cidr_block = "10.10.1.0/24"
availability_zone = var.az_1 # 使用变量代替硬编码的可用区
tags = {
Name = "tf-subnet01"
}
}
# 定义第二个子网 tf-subnet02 (10.10.2.0/24, 使用变量指定可用区)
resource "aws_subnet" "tf_subnet02" {
vpc_id = aws_vpc.tf_vpc.id
cidr_block = "10.10.2.0/24"
availability_zone = var.az_2
tags = {
Name = "tf-subnet02"
}
}
解释:
resource "aws_subnet" "tf_subnet01"
: 声明创建一个名为
tf_subnet01
的子网资源。
vpc_id = aws_vpc.tf_vpc.id
: 关联此子网到之前定义的虚拟私有云(VPC)。
aws_vpc.tf_vpc.id
引用已创建的 VPC 的 ID。
cidr_block = "10.10.1.0/24"
: 定义子网的 CIDR 块,这里表示子网的 IP 地址范围是
10.10.1.0
到
10.10.1.255
,总共有 256 个地址(包括网络地址和广播地址)。
availability_zone = var.az_1
: 指定此子网所在的可用区,使用了之前定义的变量
az_1
,而不是硬编码。这使得配置更灵活,便于修改和维护。
预执行
terraform plan -out=tf.plan
terraform plan
terraform plan -out=tf.plan
aws_vpc.tf_vpc: Refreshing state... [id=vpc-0f2e1cdca0cf5a306]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the
following symbols:
+ create
Terraform will perform the following actions:
# aws_subnet.tf_subnet01 will be created
+ resource "aws_subnet" "tf_subnet01" {
+ arn = (known after apply)
+ assign_ipv6_address_on_creation = false
+ availability_zone = "us-west-1a"
+ availability_zone_id = (known after apply)
+ cidr_block = "10.10.1.0/24"
+ enable_dns64 = false
+ enable_resource_name_dns_a_record_on_launch = false
+ enable_resource_name_dns_aaaa_record_on_launch = false
+ id = (known after apply)
+ ipv6_cidr_block_association_id = (known after apply)
+ ipv6_native = false
+ map_public_ip_on_launch = false
+ owner_id = (known after apply)
+ private_dns_hostname_type_on_launch = (known after apply)
+ tags = {
+ "Name" = "tf-subnet01"
}
+ tags_all = {
+ "Name" = "tf-subnet01"
}
+ vpc_id = "vpc-0f2e1cdca0cf5a306"
}
# aws_subnet.tf_subnet02 will be created
+ resource "aws_subnet" "tf_subnet02" {
+ arn = (known after apply)
+ assign_ipv6_address_on_creation = false
+ availability_zone = "us-west-1b"
+ availability_zone_id = (known after apply)
+ cidr_block = "10.10.2.0/24"
+ enable_dns64 = false
+ enable_resource_name_dns_a_record_on_launch = false
+ enable_resource_name_dns_aaaa_record_on_launch = false
+ id = (known after apply)
+ ipv6_cidr_block_association_id = (known after apply)
+ ipv6_native = false
+ map_public_ip_on_launch = false
+ owner_id = (known after apply)
+ private_dns_hostname_type_on_launch = (known after apply)
+ tags = {
+ "Name" = "tf-subnet02"
}
+ tags_all = {
+ "Name" = "tf-subnet02"
}
+ vpc_id = "vpc-0f2e1cdca0cf5a306"
}
Plan: 2 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
创建子网
terraform apply "tf.plan"
terraform apply "tf.plan"
aws_subnet.tf_subnet01: Creating...
aws_subnet.tf_subnet02: Creating...
aws_subnet.tf_subnet01: Creation complete after 2s [id=subnet-08f8e4b2c62e27989]
aws_subnet.tf_subnet02: Creation complete after 2s [id=subnet-019490723ad3e940a]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
3.创建网关
创建定义网关的internet_gateway.tf文件
resource "aws_internet_gateway" "tf_igw" {
vpc_id = aws_vpc.tf_vpc.id
tags = {
Name = "tf-igw"
}
}
解释
resource "aws_internet_gateway" "tf_igw"
: 声明创建一个名为
tf_igw
的互联网网关资源。
vpc_id = aws_vpc.tf_vpc.id
: 将此互联网网关与之前创建的虚拟私有云(VPC)关联。通过引用
aws_vpc.tf_vpc.id
,确保该网关可以与指定的 VPC 一起使用。
tags
: 为互联网网关添加标签,
Name = "tf-igw"
。标签有助于用户在 AWS 控制台中管理和识别该资源。
预执行
terraform plan -out=tf.plan
tf plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the
following symbols:
+ create
Terraform will perform the following actions:
# aws_internet_gateway.tf_igw will be created
+ resource "aws_internet_gateway" "tf_igw" {
+ arn = (known after apply)
+ id = (known after apply)
+ owner_id = (known after apply)
+ tags = {
+ "Name" = "tf-igw"
}
+ tags_all = {
+ "Name" = "tf-igw"
}
+ vpc_id = "vpc-0f2e1cdca0cf5a306"
}
Plan: 1 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
执行创建网关
terraform apply "tf.plan"
输出如下:
aws_internet_gateway.tf_igw: Creating...
aws_internet_gateway.tf_igw: Creation complete after 2s [id=igw-08ec2f3357e8725df]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
4. 创建路由表
定义route_table.tf
resource "aws_route_table" "tf_route_table" {
vpc_id = aws_vpc.tf_vpc.id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.tf_igw.id
}
tags = {
Name = "tf-route-table"
}
}
解释
预执行创建路由表
terraform plan
terraform plan -out=tf.plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the
following symbols:
+ create
Terraform will perform the following actions:
# aws_route_table.tf_route_table will be created
+ resource "aws_route_table" "tf_route_table" {
+ arn = (known after apply)
+ id = (known after apply)
+ owner_id = (known after apply)
+ propagating_vgws = (known after apply)
+ route = [
+ {
+ cidr_block = "0.0.0.0/0"
+ gateway_id = "igw-08ec2f3357e8725df"
# (12 unchanged attributes hidden)
},
]
+ tags = {
+ "Name" = "tf-route-table"
}
+ tags_all = {
+ "Name" = "tf-route-table"
}
+ vpc_id = "vpc-0f2e1cdca0cf5a306"
}
Plan: 1 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
执行创建路由表
terraform apply "tf.plan"
输出如下:
aws_route_table.tf_route_table: Creating...
aws_route_table.tf_route_table: Creation complete after 3s [id=rtb-0ae4b29ae8d6881ed]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
5. 关联路由表和子网
创建route_table_association.tf
# 关联子网和路由表
resource "aws_route_table_association" "tf_route_table_association_01" {
subnet_id = aws_subnet.tf_subnet01.id
route_table_id = aws_route_table.tf_route_table.id
}
resource "aws_route_table_association" "tf_route_table_association_02" {
subnet_id = aws_subnet.tf_subnet02.id
route_table_id = aws_route_table.tf_route_table.id
}
解释
resource "aws_route_table_association" "tf_route_table_association_01"
: 声明创建一个名为
tf_route_table_association_01
的路由表关联资源。该资源用于将子网和路由表连接起来。
subnet_id = aws_subnet.tf_subnet01.id
: 指定要关联的子网,引用之前创建的子网
tf_subnet01
的 ID。这意味着该路由表将应用于这个子网中的所有实例。
route_table_id = aws_route_table.tf_route_table.id
: 指定要关联的路由表,引用之前创建的路由表
tf_route_table
的 ID。通过这个引用,确保路由表与指定的子网关联。
预执行
terraform plan -out=tf.plan
查看代码
terraform plan -out=tf.plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the
following symbols:
+ create
Terraform will perform the following actions:
# aws_route_table_association.tf_route_table_association_01 will be created
+ resource "aws_route_table_association" "tf_route_table_association_01" {
+ id = (known after apply)
+ route_table_id = "rtb-0ae4b29ae8d6881ed"
+ subnet_id = "subnet-08f8e4b2c62e27989"
}
# aws_route_table_association.tf_route_table_association_02 will be created
+ resource "aws_route_table_association" "tf_route_table_association_02" {
+ id = (known after apply)
+ route_table_id = "rtb-0ae4b29ae8d6881ed"
+ subnet_id = "subnet-019490723ad3e940a"
}
Plan: 2 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
转载请著名原文地址:https://www.cnblogs.com/Sunzz/p/18498915
执行关联
terraform apply "tf.plan"
输出如下:
aws_route_table_association.tf_route_table_association_01: Creating...
aws_route_table_association.tf_route_table_association_02: Creating...
aws_route_table_association.tf_route_table_association_01: Creation complete after 1s [id=rtbassoc-0999e44cc1cfb7f09]
aws_route_table_association.tf_route_table_association_02: Creation complete after 1s [id=rtbassoc-0190cb61bd5850d86]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
四、创建ec2
1. 创建密钥对
生成密钥对
ssh-keygen -t rsa -b 4096 -f ~/.ssh/tf-keypair
创建key_pair.tf文件
resource "aws_key_pair" "tf-keypair" {
key_name = "tf-keypair"
public_key = "ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQC42p8Ly5xXtaQPbBoKiVVSuU0HKhK38I5DtPhijhZrVZmhRpW5yD6pbCXmFLnIFTFNb....."
}
解释:
resource "aws_key_pair" "tf-keypair"
: 声明创建一个名为
tf-keypair
的密钥对资源。这是一个 AWS EC2 密钥对,用于通过 SSH 访问 EC2 实例。
key_name = "tf-keypair"
: 指定密钥对的名称为
tf-keypair
。在 AWS 控制台中,该密钥对将以这个名称显示。
public_key = "ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQC42p8Ly5xXtaQPbBoKiVVSuU0HKhK38I5DtPhijhZrVZmhRpW5yD6pbCXmFLnIFTFNb....."
:
- 提供公钥的内容,使用 SSH 公钥格式。这个公钥将被存储在 AWS 中,而相应的私钥则由用户保管,用于通过 SSH 连接到 EC2 实例。
- 注意:公钥必须是有效的 SSH 公钥格式,且通常会以
ssh-rsa
开头,后面跟着密钥数据和可选的注释。
- 其中public_key 就是
~/.ssh/tf-keypair.pub的内容
预执行
terraform plan -out=tf.plan
terraform plan
terraform plan -out=tf.plan
aws_vpc.tf_vpc: Refreshing state... [id=vpc-0f2e1cdca0cf5a306]
aws_subnet.tf_subnet01: Refreshing state... [id=subnet-08f8e4b2c62e27989]
aws_subnet.tf_subnet02: Refreshing state... [id=subnet-019490723ad3e940a]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the
following symbols:
+ create
Terraform will perform the following actions:
# aws_key_pair.tf-keypair will be created
+ resource "aws_key_pair" "tf-keypair" {
+ arn = (known after apply)
+ fingerprint = (known after apply)
+ id = (known after apply)
+ key_name = "tf-keypair"
+ key_name_prefix = (known after apply)
+ key_pair_id = (known after apply)
+ key_type = (known after apply)
+ public_key = "ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQC42p8Ly5xXtaQPbBoKiVVSuU0HKhK38ua0arfBYQF++/QFRJZ7+/fmeES7P0+//+vKjWnwdf67BIu0RyoA+MFpztYn58hDKdAmSeEXCpp4cOojgFmgnf1+p3MdaOvnT379YT....."
+ tags_all = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
执行创建密钥对
terraform apply "tf.plan"
结果如下:
aws_key_pair.tf-keypair: Creating...
aws_key_pair.tf-keypair: Creation complete after 1s [id=tf-keypair]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
2.创建安全组
创建security_group.tf文件
resource "aws_security_group" "tf_security_group" {
name = "tf-security-group"
description = "Security group for allowing specific inbound traffic"
vpc_id = aws_vpc.tf_vpc.id
# ICMP (ping) 入站规则
ingress {
from_port = -1
to_port = -1
protocol = "icmp"
cidr_blocks = ["0.0.0.0/0"]
description = "Allow ICMP (ping) traffic"
}
# SSH (22) 入站规则
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
description = "Allow SSH traffic"
}
# HTTP (80) 入站规则
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
description = "Allow HTTP traffic"
}
# HTTPS (443) 入站规则
ingress {
from_port = 443
to_port = 443
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
description = "Allow HTTPS traffic"
}
# 默认出站规则:允许所有出站流量
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
description = "Allow all outbound traffic"
}
tags = {
Name = "tf-security-group"
}
}
解释
ingress
规则
:
icmp
放行所有 ICMP 流量,用于允许 ping。
tcp
规则放行 22 (SSH)、80 (HTTP)、443 (HTTPS) 端口。
egress
规则
:
预执行
terraform plan -out=tf.plan
terraform plan
terraform plan -out=tf.plan
aws_key_pair.tf-keypair: Refreshing state... [id=tf-keypair]
aws_vpc.tf_vpc: Refreshing state... [id=vpc-0f2e1cdca0cf5a306]
aws_subnet.tf_subnet01: Refreshing state... [id=subnet-08f8e4b2c62e27989]
aws_subnet.tf_subnet02: Refreshing state... [id=subnet-019490723ad3e940a]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the
following symbols:
+ create
Terraform will perform the following actions:
# aws_security_group.tf_security_group will be created
+ resource "aws_security_group" "tf_security_group" {
+ arn = (known after apply)
+ description = "Security group for allowing specific inbound traffic"
+ egress = [
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "Allow all outbound traffic"
+ from_port = 0
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "-1"
+ security_groups = []
+ self = false
+ to_port = 0
},
]
+ id = (known after apply)
+ ingress = [
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "Allow HTTP traffic"
+ from_port = 80
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "tcp"
+ security_groups = []
+ self = false
+ to_port = 80
},
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "Allow HTTPS traffic"
+ from_port = 443
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "tcp"
+ security_groups = []
+ self = false
+ to_port = 443
},
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "Allow ICMP (ping) traffic"
+ from_port = -1
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "icmp"
+ security_groups = []
+ self = false
+ to_port = -1
},
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "Allow SSH traffic"
+ from_port = 22
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "tcp"
+ security_groups = []
+ self = false
+ to_port = 22
},
]
+ name = "tf-security-group"
+ name_prefix = (known after apply)
+ owner_id = (known after apply)
+ revoke_rules_on_delete = false
+ tags = {
+ "Name" = "tf-security-group"
}
+ tags_all = {
+ "Name" = "tf-security-group"
}
+ vpc_id = "vpc-0f2e1cdca0cf5a306"
}
Plan: 1 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
执行创建安全组
terraform apply "tf.plan"
输出如下:
terraform apply "tf.plan"
aws_security_group.tf_security_group: Creating...
aws_security_group.tf_security_group: Creation complete after 5s [id=sg-0907b4ae2d4bd9592]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
3.创建ec2
先定义ami内容,方便后边作用变量直接使用,编辑
variables.tf新增如下内容。这里使用了amazon linux和ubuntu 24.04的镜像
修改variables.tf
variable "amazon_linux_ami" {
description = "AMI ID for Amazon Linux"
type = string
default = "ami-0cf4e1fcfd8494d5b" # 替换为你的Amazon Linux AMI ID
}
variable "ubuntu_ami" {
description = "AMI ID for Ubuntu"
type = string
default = "ami-0da424eb883458071" # 替换为你的Ubuntu 24.04 AMI ID
}
创建ec2.tf文件
# 第一个 EC2 实例
resource "aws_instance" "tf-ec2-01" {
ami = var.amazon_linux_ami
instance_type = "t2.micro"
subnet_id = aws_subnet.tf_subnet01.id
key_name = aws_key_pair.tf-keypair.key_name
vpc_security_group_ids = [aws_security_group.tf_security_group.id]
root_block_device {
volume_size = 10
}
tags = {
Name = "tf-ec2-01"
}
}
# 第二个 EC2 实例
resource "aws_instance" "tf-ec2-02" {
ami = var.ubuntu_ami
instance_type = "t2.micro"
subnet_id = aws_subnet.tf_subnet02.id
key_name = aws_key_pair.tf-keypair.key_name
vpc_security_group_ids = [aws_security_group.tf_security_group.id]
root_block_device {
volume_size = 10
}
tags = {
Name = "tf-ec2-02"
}
}
配置说明
- AMI ID 参数化
: 以便在不同环境中灵活指定 AMI
- instance_type
: 指定实例规格
- subnet_id
: 指定子网,这里使用前边创建的
- 安全组和密钥对
:
key_name
和 vpc_security_group_ids 分别设置为之前创建的
tf-keypair
和
tf-security-group
。
root_block_device
:将
volume_size
设置为 10GB,以指定每个实例的系统盘大小。
转载请著名原文地址:
https://www.cnblogs.com/Sunzz/p/18498915
预执行
terraform plan -out=tf.plan
terraform plan
terraform plan -out=tf.plan
aws_key_pair.tf-keypair: Refreshing state... [id=tf-keypair]
aws_vpc.tf_vpc: Refreshing state... [id=vpc-0f2e1cdca0cf5a306]
aws_subnet.tf_subnet02: Refreshing state... [id=subnet-019490723ad3e940a]
aws_subnet.tf_subnet01: Refreshing state... [id=subnet-08f8e4b2c62e27989]
aws_security_group.tf_security_group: Refreshing state... [id=sg-0907b4ae2d4bd9592]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the
following symbols:
+ create
Terraform will perform the following actions:
# aws_instance.tf-ec2-01 will be created
+ resource "aws_instance" "tf-ec2-01" {
+ ami = "ami-0cf4e1fcfd8494d5b"
+ arn = (known after apply)
+ associate_public_ip_address = (known after apply)
+ availability_zone = (known after apply)
+ cpu_core_count = (known after apply)
+ cpu_threads_per_core = (known after apply)
+ disable_api_stop = (known after apply)
+ disable_api_termination = (known after apply)
+ ebs_optimized = (known after apply)
+ get_password_data = false
+ host_id = (known after apply)
+ host_resource_group_arn = (known after apply)
+ iam_instance_profile = (known after apply)
+ id = (known after apply)
+ instance_initiated_shutdown_behavior = (known after apply)
+ instance_state = (known after apply)
+ instance_type = "t2.micro"
+ ipv6_address_count = (known after apply)
+ ipv6_addresses = (known after apply)
+ key_name = "tf-keypair"
+ monitoring = (known after apply)
+ outpost_arn = (known after apply)
+ password_data = (known after apply)
+ placement_group = (known after apply)
+ placement_partition_number = (known after apply)
+ primary_network_interface_id = (known after apply)
+ private_dns = (known after apply)
+ private_ip = (known after apply)
+ public_dns = (known after apply)
+ public_ip = (known after apply)
+ secondary_private_ips = (known after apply)
+ security_groups = (known after apply)
+ source_dest_check = true
+ subnet_id = "subnet-08f8e4b2c62e27989"
+ tags = {
+ "Name" = "tf-ec2-01"
}
+ tags_all = {
+ "Name" = "tf-ec2-01"
}
+ tenancy = (known after apply)
+ user_data = (known after apply)
+ user_data_base64 = (known after apply)
+ user_data_replace_on_change = false
+ vpc_security_group_ids = [
+ "sg-0907b4ae2d4bd9592",
]
+ capacity_reservation_specification (known after apply)
+ cpu_options (known after apply)
+ ebs_block_device (known after apply)
+ enclave_options (known after apply)
+ ephemeral_block_device (known after apply)
+ maintenance_options (known after apply)
+ metadata_options (known after apply)
+ network_interface (known after apply)
+ private_dns_name_options (known after apply)
+ root_block_device {
+ delete_on_termination = true
+ device_name = (known after apply)
+ encrypted = (known after apply)
+ iops = (known after apply)
+ kms_key_id = (known after apply)
+ throughput = (known after apply)
+ volume_id = (known after apply)
+ volume_size = 10
+ volume_type = (known after apply)
}
}
# aws_instance.tf-ec2-02 will be created
+ resource "aws_instance" "tf-ec2-02" {
+ ami = "ami-0da424eb883458071"
+ arn = (known after apply)
+ associate_public_ip_address = (known after apply)
+ availability_zone = (known after apply)
+ cpu_core_count = (known after apply)
+ cpu_threads_per_core = (known after apply)
+ disable_api_stop = (known after apply)
+ disable_api_termination = (known after apply)
+ ebs_optimized = (known after apply)
+ get_password_data = false
+ host_id = (known after apply)
+ host_resource_group_arn = (known after apply)
+ iam_instance_profile = (known after apply)
+ id = (known after apply)
+ instance_initiated_shutdown_behavior = (known after apply)
+ instance_state = (known after apply)
+ instance_type = "t2.micro"
+ ipv6_address_count = (known after apply)
+ ipv6_addresses = (known after apply)
+ key_name = "tf-keypair"
+ monitoring = (known after apply)
+ outpost_arn = (known after apply)
+ password_data = (known after apply)
+ placement_group = (known after apply)
+ placement_partition_number = (known after apply)
+ primary_network_interface_id = (known after apply)
+ private_dns = (known after apply)
+ private_ip = (known after apply)
+ public_dns = (known after apply)
+ public_ip = (known after apply)
+ secondary_private_ips = (known after apply)
+ security_groups = (known after apply)
+ source_dest_check = true
+ subnet_id = "subnet-019490723ad3e940a"
+ tags = {
+ "Name" = "tf-ec2-02"
}
+ tags_all = {
+ "Name" = "tf-ec2-02"
}
+ tenancy = (known after apply)
+ user_data = (known after apply)
+ user_data_base64 = (known after apply)
+ user_data_replace_on_change = false
+ vpc_security_group_ids = [
+ "sg-0907b4ae2d4bd9592",
]
+ capacity_reservation_specification (known after apply)
+ cpu_options (known after apply)
+ ebs_block_device (known after apply)
+ enclave_options (known after apply)
+ ephemeral_block_device (known after apply)
+ maintenance_options (known after apply)
+ metadata_options (known after apply)
+ network_interface (known after apply)
+ private_dns_name_options (known after apply)
+ root_block_device {
+ delete_on_termination = true
+ device_name = (known after apply)
+ encrypted = (known after apply)
+ iops = (known after apply)
+ kms_key_id = (known after apply)
+ throughput = (known after apply)
+ volume_id = (known after apply)
+ volume_size = 10
+ volume_type = (known after apply)
}
}
Plan: 2 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
执行创建ec2
terraform apply "tf.plan"
输出:
aws_instance.tf-ec2-01: Creating...
aws_instance.tf-ec2-02: Creating...
aws_instance.tf-ec2-02: Still creating... [10s elapsed]
aws_instance.tf-ec2-01: Still creating... [10s elapsed]
aws_instance.tf-ec2-01: Creation complete after 16s [id=i-0f8d63e600d93f6b0]
aws_instance.tf-ec2-02: Creation complete after 16s [id=i-0888d477cdf36aea0]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
4.创建ebs
新增ebs.tf文化
resource "aws_ebs_volume" "ebs_ec2_01" {
availability_zone = var.az_1 # 使用变量代替硬编码的可用区
size = 20
type = "gp3"
tags = {
Name = "ebs-ec2-01"
}
}
resource "aws_ebs_volume" "ebs_ec2_02" {
availability_zone = var.az_2
size = 20
type = "gp3"
tags = {
Name = "ebs-ec2-02"
}
}
解释
resource "aws_ebs_volume" "ebs_ec2_01"
: 声明创建一个名为
ebs_ec2_01
的 EBS 卷资源。
availability_zone = var.az_1
: 指定该 EBS 卷的可用区,使用之前定义的变量
az_1
,这样可以灵活地选择卷所在的可用区而不需要硬编码。
size = 20
: 设置 EBS 卷的大小为 20 GB。这个参数决定了卷的存储容量。
type = "gp3"
: 指定 EBS 卷的类型为
gp3
,这是 AWS 提供的一种通用型 SSD 卷类型,适合大多数工作负载。
tags = { Name = "ebs-ec2-01" }
: 为 EBS 卷添加标签,指定其名称为
ebs-ec2-01
,便于在 AWS 控制台中识别和管理。
预执行
terraform plan -out=tf.plan
terraform plan
terraform plan -out=tf.plan
aws_key_pair.tf-keypair: Refreshing state... [id=tf-keypair]
aws_vpc.tf_vpc: Refreshing state... [id=vpc-0f2e1cdca0cf5a306]
aws_subnet.tf_subnet02: Refreshing state... [id=subnet-019490723ad3e940a]
aws_subnet.tf_subnet01: Refreshing state... [id=subnet-08f8e4b2c62e27989]
aws_security_group.tf_security_group: Refreshing state... [id=sg-0907b4ae2d4bd9592]
aws_instance.tf-ec2-02: Refreshing state... [id=i-0888d477cdf36aea0]
aws_instance.tf-ec2-01: Refreshing state... [id=i-0f8d63e600d93f6b0]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the
following symbols:
+ create
Terraform will perform the following actions:
# aws_ebs_volume.ebs_ec2_01 will be created
+ resource "aws_ebs_volume" "ebs_ec2_01" {
+ arn = (known after apply)
+ availability_zone = "us-west-1a"
+ encrypted = (known after apply)
+ final_snapshot = false
+ id = (known after apply)
+ iops = (known after apply)
+ kms_key_id = (known after apply)
+ size = 20
+ snapshot_id = (known after apply)
+ tags = {
+ "Name" = "ebs-ec2-01"
}
+ tags_all = {
+ "Name" = "ebs-ec2-01"
}
+ throughput = (known after apply)
+ type = "gp3"
}
# aws_ebs_volume.ebs_ec2_02 will be created
+ resource "aws_ebs_volume" "ebs_ec2_02" {
+ arn = (known after apply)
+ availability_zone = "us-west-1b"
+ encrypted = (known after apply)
+ final_snapshot = false
+ id = (known after apply)
+ iops = (known after apply)
+ kms_key_id = (known after apply)
+ size = 20
+ snapshot_id = (known after apply)
+ tags = {
+ "Name" = "ebs-ec2-02"
}
+ tags_all = {
+ "Name" = "ebs-ec2-02"
}
+ throughput = (known after apply)
+ type = "gp3"
}
Plan: 2 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
执行创建ebs
terraform apply "tf.plan"
输出如下:
terraform apply "tf.plan"
aws_ebs_volume.ebs_ec2_02: Creating...
aws_ebs_volume.ebs_ec2_01: Creating...
aws_ebs_volume.ebs_ec2_02: Still creating... [10s elapsed]
aws_ebs_volume.ebs_ec2_01: Still creating... [10s elapsed]
aws_ebs_volume.ebs_ec2_01: Creation complete after 12s [id=vol-0aac9f1302376328a]
aws_ebs_volume.ebs_ec2_02: Creation complete after 12s [id=vol-06bd472f44eadaf02]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
5.将 EBS 磁盘附加到 EC2
新增ebs_attachment.tf文件
resource "aws_volume_attachment" "attach_ebs_to_ec2_01" {
device_name = "/dev/xvdh" # 设备名称,可根据需求更改
volume_id = aws_ebs_volume.ebs_ec2_01.id
instance_id = aws_instance.tf-ec2-01.id
}
resource "aws_volume_attachment" "attach_ebs_to_ec2_02" {
device_name = "/dev/xvdh"
volume_id = aws_ebs_volume.ebs_ec2_02.id
instance_id = aws_instance.tf-ec2-02.id
}
解释
resource "aws_volume_attachment" "attach_ebs_to_ec2_01"
: 声明了一个名为
attach_ebs_to_ec2_01
的 EBS 卷附件资源,属于
aws_volume_attachment
类型。这个资源负责将 EBS 卷与 EC2 实例关联。
device_name = "/dev/xvdh"
: 指定 EBS 卷在 EC2 实例上的设备名称。这里使用的是
/dev/xvdh
,可以根据需求更改。这个名称在实例中将用于引用该 EBS 卷。
volume_id = aws_ebs_volume.ebs_ec2_01.id
: 引用之前创建的 EBS 卷
ebs_ec2_01
的 ID,以指定要附加的卷。通过引用资源的 ID,可以确保操作的是正确的资源。
instance_id = aws_instance.tf-ec2-01.id
: 引用要将 EBS 卷附加到的 EC2 实例
tf-ec2-01
的 ID。这样可以明确指定哪个实例将使用该 EBS 卷。
预执行
terraform plan -out=tf.plan
terraform plan
terraform plan -out=tf.plan
aws_ebs_volume.ebs_ec2_02: Refreshing state... [id=vol-06bd472f44eadaf02]
aws_vpc.tf_vpc: Refreshing state... [id=vpc-0f2e1cdca0cf5a306]
aws_ebs_volume.ebs_ec2_01: Refreshing state... [id=vol-0aac9f1302376328a]
aws_key_pair.tf-keypair: Refreshing state... [id=tf-keypair]
aws_subnet.tf_subnet02: Refreshing state... [id=subnet-019490723ad3e940a]
aws_subnet.tf_subnet01: Refreshing state... [id=subnet-08f8e4b2c62e27989]
aws_security_group.tf_security_group: Refreshing state... [id=sg-0907b4ae2d4bd9592]
aws_instance.tf-ec2-01: Refreshing state... [id=i-0f8d63e600d93f6b0]
aws_instance.tf-ec2-02: Refreshing state... [id=i-0888d477cdf36aea0]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the
following symbols:
+ create
Terraform will perform the following actions:
# aws_volume_attachment.attach_ebs_to_ec2_01 will be created
+ resource "aws_volume_attachment" "attach_ebs_to_ec2_01" {
+ device_name = "/dev/xvdh"
+ id = (known after apply)
+ instance_id = "i-0f8d63e600d93f6b0"
+ volume_id = "vol-0aac9f1302376328a"
}
# aws_volume_attachment.attach_ebs_to_ec2_02 will be created
+ resource "aws_volume_attachment" "attach_ebs_to_ec2_02" {
+ device_name = "/dev/xvdh"
+ id = (known after apply)
+ instance_id = "i-0888d477cdf36aea0"
+ volume_id = "vol-06bd472f44eadaf02"
}
Plan: 2 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
执行附加磁盘
terraform apply "tf.plan"
输出:
aws_volume_attachment.attach_ebs_to_ec2_01: Creating...
aws_volume_attachment.attach_ebs_to_ec2_02: Creating...
aws_volume_attachment.attach_ebs_to_ec2_02: Still creating... [10s elapsed]
aws_volume_attachment.attach_ebs_to_ec2_01: Still creating... [10s elapsed]
aws_volume_attachment.attach_ebs_to_ec2_01: Still creating... [20s elapsed]
aws_volume_attachment.attach_ebs_to_ec2_02: Still creating... [20s elapsed]
aws_volume_attachment.attach_ebs_to_ec2_02: Still creating... [30s elapsed]
aws_volume_attachment.attach_ebs_to_ec2_01: Still creating... [30s elapsed]
aws_volume_attachment.attach_ebs_to_ec2_02: Creation complete after 33s [id=vai-439503465]
aws_volume_attachment.attach_ebs_to_ec2_01: Creation complete after 33s [id=vai-1312740159]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
6. 创建eip和关联eip到ec2实例
新增eip.tf文件
# 为 tf-ec2-01 创建 EIP
resource "aws_eip" "tf_eip_01" {
vpc = true
tags = {
Name = "tf-eip-01"
}
}
# 为 tf-ec2-02 创建 EIP
resource "aws_eip" "tf_eip_02" {
vpc = true
tags = {
Name = "tf-eip-02"
}
}
解释
resource "aws_eip" "tf_eip_01"
: 声明了一个名为
tf_eip_01
的弹性 IP 资源,属于
aws_eip
类型。弹性 IP 是 AWS 提供的一种静态 IPv4 地址,可以在不同的 EC2 实例之间动态迁移。
vpc = true
: 指定这个弹性 IP 是用于 VPC(虚拟私有云)的。如果设置为
true
,则弹性 IP 将与 VPC 关联。这是因为在 VPC 中使用的弹性 IP 地址与传统的 EC2 实例弹性 IP 有所不同。
tags = { Name = "tf-eip-01" }
: 为该弹性 IP 添加一个标签,名称为
tf-eip-01
。标签用于管理和识别资源,使得在 AWS 控制台或使用其他工具时能够更方便地找到和管理该资源。
新增eip_association.tf文件
# 关联 EIP 到 tf-ec2-01 实例
resource "aws_eip_association" "tf_eip_association_01" {
instance_id = aws_instance.tf-ec2-01.id
allocation_id = aws_eip.tf_eip_01.id
}
# 关联 EIP 到 tf-ec2-02 实例
resource "aws_eip_association" "tf_eip_association_02" {
instance_id = aws_instance.tf-ec2-02.id
allocation_id = aws_eip.tf_eip_02.id
}
解释
resource "aws_eip_association" "tf_eip_association_01"
: 声明了一个名为
tf_eip_association_01
的资源,属于
aws_eip_association
类型。这个资源用于建立弹性 IP 和 EC2 实例之间的关联。
instance_id = aws_instance.tf-ec2-01.id
: 指定要与弹性 IP 关联的 EC2 实例的 ID。这里引用了之前定义的 EC2 实例
tf-ec2-01
的 ID。
allocation_id = aws_eip.tf_eip_01.id
: 指定要关联的弹性 IP 的分配 ID。这里引用了之前创建的弹性 IP
tf_eip_01
的 ID。
预执行
terraform plan -out=tf.plan
terraform plan
terraform plan -out=tf.plan
aws_key_pair.tf-keypair: Refreshing state... [id=tf-keypair]
aws_ebs_volume.ebs_ec2_01: Refreshing state... [id=vol-0aac9f1302376328a]
aws_ebs_volume.ebs_ec2_02: Refreshing state... [id=vol-06bd472f44eadaf02]
aws_vpc.tf_vpc: Refreshing state... [id=vpc-0f2e1cdca0cf5a306]
aws_internet_gateway.tf_igw: Refreshing state... [id=igw-08ec2f3357e8725df]
aws_subnet.tf_subnet02: Refreshing state... [id=subnet-019490723ad3e940a]
aws_subnet.tf_subnet01: Refreshing state... [id=subnet-08f8e4b2c62e27989]
aws_security_group.tf_security_group: Refreshing state... [id=sg-0907b4ae2d4bd9592]
aws_route_table.tf_route_table: Refreshing state... [id=rtb-0ae4b29ae8d6881ed]
aws_instance.tf-ec2-01: Refreshing state... [id=i-0f8d63e600d93f6b0]
aws_instance.tf-ec2-02: Refreshing state... [id=i-0888d477cdf36aea0]
aws_route_table_association.tf_route_table_association_02: Refreshing state... [id=rtbassoc-0190cb61bd5850d86]
aws_route_table_association.tf_route_table_association_01: Refreshing state... [id=rtbassoc-0999e44cc1cfb7f09]
aws_volume_attachment.attach_ebs_to_ec2_01: Refreshing state... [id=vai-1312740159]
aws_volume_attachment.attach_ebs_to_ec2_02: Refreshing state... [id=vai-439503465]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the
following symbols:
+ create
Terraform will perform the following actions:
# aws_eip.tf_eip_01 will be created
+ resource "aws_eip" "tf_eip_01" {
+ allocation_id = (known after apply)
+ association_id = (known after apply)
+ carrier_ip = (known after apply)
+ customer_owned_ip = (known after apply)
+ domain = (known after apply)
+ id = (known after apply)
+ instance = (known after apply)
+ network_border_group = (known after apply)
+ network_interface = (known after apply)
+ private_dns = (known after apply)
+ private_ip = (known after apply)
+ public_dns = (known after apply)
+ public_ip = (known after apply)
+ public_ipv4_pool = (known after apply)
+ tags = {
+ "Name" = "tf-eip-01"
}
+ tags_all = {
+ "Name" = "tf-eip-01"
}
+ vpc = true
}
# aws_eip.tf_eip_02 will be created
+ resource "aws_eip" "tf_eip_02" {
+ allocation_id = (known after apply)
+ association_id = (known after apply)
+ carrier_ip = (known after apply)
+ customer_owned_ip = (known after apply)
+ domain = (known after apply)
+ id = (known after apply)
+ instance = (known after apply)
+ network_border_group = (known after apply)
+ network_interface = (known after apply)
+ private_dns = (known after apply)
+ private_ip = (known after apply)
+ public_dns = (known after apply)
+ public_ip = (known after apply)
+ public_ipv4_pool = (known after apply)
+ tags = {
+ "Name" = "tf-eip-02"
}
+ tags_all = {
+ "Name" = "tf-eip-02"
}
+ vpc = true
}
# aws_eip_association.tf_eip_association_01 will be created
+ resource "aws_eip_association" "tf_eip_association_01" {
+ allocation_id = (known after apply)
+ id = (known after apply)
+ instance_id = "i-0f8d63e600d93f6b0"
+ network_interface_id = (known after apply)
+ private_ip_address = (known after apply)
+ public_ip = (known after apply)
}
# aws_eip_association.tf_eip_association_02 will be created
+ resource "aws_eip_association" "tf_eip_association_02" {
+ allocation_id = (known after apply)
+ id = (known after apply)
+ instance_id = "i-0888d477cdf36aea0"
+ network_interface_id = (known after apply)
+ private_ip_address = (known after apply)
+ public_ip = (known after apply)
}
Plan: 4 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
执行创建eip和关联ec2
terraform apply "tf.plan"
结果如下:
aws_eip.tf_eip_02: Creating...
aws_eip.tf_eip_01: Creating...
aws_eip.tf_eip_01: Creation complete after 2s [id=eipalloc-0a9cdbc84013614f5]
aws_eip.tf_eip_02: Creation complete after 2s [id=eipalloc-0ed1c932d9a7a305a]
aws_eip_association.tf_eip_association_01: Creating...
aws_eip_association.tf_eip_association_02: Creating...
aws_eip_association.tf_eip_association_02: Creation complete after 1s [id=eipassoc-0b517a49d76639054]
aws_eip_association.tf_eip_association_01: Creation complete after 1s [id=eipassoc-0e0359ad952266802]
Apply complete! Resources: 4 added, 0 changed, 0 destroyed.
转载请著名原文地址:
https://www.cnblogs.com/Sunzz/p/18498915
7.通过控制后台查看创建的结果
通过控制台可以看到,实例名字、类型、可用区、公网IP、安全组、密钥、磁盘等都是符合我们在tf中定义的。

再直接登录到服务器上看下,确保网络、安全组都是可用的
ssh ec2-user@52.9.19.52 -i ~/.ssh/tf-keypair

五、创建EKS
1. 创建EKS所需的网络资源
创建eks所用的子网并关联路由表文件
eks_subnets.tf内容如下
resource "aws_subnet" "tf_eks_subnet1" {
vpc_id = aws_vpc.tf_vpc.id
cidr_block = "10.10.81.0/24"
availability_zone = var.az_1
map_public_ip_on_launch = true
tags = {
Name = "tf_eks_subnet1"
}
}
resource "aws_subnet" "tf_eks_subnet2" {
vpc_id = aws_vpc.tf_vpc.id
cidr_block = "10.10.82.0/24"
availability_zone = var.az_2
map_public_ip_on_launch = true
tags = {
Name = "tf_eks_subnet2"
}
}
# 将路由表关联到子网tf_eks_subnet1
resource "aws_route_table_association" "tf_eks_subnet1_association" {
subnet_id = aws_subnet.tf_eks_subnet1.id
route_table_id = aws_route_table.tf_route_table.id
}
# 将路由表关联到子网tf_eks_subnet2
resource "aws_route_table_association" "tf_eks_subnet2_association" {
subnet_id = aws_subnet.tf_eks_subnet2.id
route_table_id = aws_route_table.tf_route_table.id
}
解释
resource "aws_subnet" "tf_eks_subnet1"
: 声明了一个名为
tf_eks_subnet1
的资源,类型为
aws_subnet
,用于创建一个新的子网。
vpc_id = aws_vpc.tf_vpc.id
: 指定子网所属的虚拟私有云(VPC)的 ID。这里引用了之前定义的 VPC
tf_vpc
的 ID,以将此子网关联到相应的 VPC。
cidr_block = "10.10.81.0/24"
: 指定子网的 CIDR 块(Classless Inter-Domain Routing),这表示该子网的 IP 地址范围为
10.10.81.0
到
10.10.81.255
,可以容纳 256 个 IP 地址。
availability_zone = var.az_1
: 指定子网所在的可用区(Availability Zone),这里使用了变量
az_1
,允许灵活配置子网的可用区。
map_public_ip_on_launch = true
: 指定在此子网中启动的实例是否自动分配公共 IP 地址。设置为
true
表示新启动的实例将自动获得公共 IP,允许它们直接访问互联网。
resource "aws_route_table_association" "tf_eks_subnet1_association"
: 声明了一个名为
tf_eks_subnet1_association
的资源,类型为
aws_route_table_association
,用于创建路由表与子网之间的关联。
subnet_id = aws_subnet.tf_eks_subnet1.id
: 指定要关联的子网的 ID。这里引用了之前定义的子网
tf_eks_subnet1
的 ID。
route_table_id = aws_route_table.tf_route_table.id
: 指定要关联的路由表的 ID。这里引用了之前定义的路由表
tf_route_table
的 ID。
预创建
terraform plan -out=tf.plan
tf plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
+ create
Terraform will perform the following actions:
# aws_route_table_association.tf_eks_subnet1_association will be created
+ resource "aws_route_table_association" "tf_eks_subnet1_association" {
+ id = (known after apply)
+ route_table_id = "rtb-0ae4b29ae8d6881ed"
+ subnet_id = (known after apply)
}
# aws_route_table_association.tf_eks_subnet2_association will be created
+ resource "aws_route_table_association" "tf_eks_subnet2_association" {
+ id = (known after apply)
+ route_table_id = "rtb-0ae4b29ae8d6881ed"
+ subnet_id = (known after apply)
}
# aws_subnet.tf_eks_subnet1 will be created
+ resource "aws_subnet" "tf_eks_subnet1" {
+ arn = (known after apply)
+ assign_ipv6_address_on_creation = false
+ availability_zone = "us-west-1a"
+ availability_zone_id = (known after apply)
+ cidr_block = "10.10.81.0/24"
+ enable_dns64 = false
+ enable_resource_name_dns_a_record_on_launch = false
+ enable_resource_name_dns_aaaa_record_on_launch = false
+ id = (known after apply)
+ ipv6_cidr_block_association_id = (known after apply)
+ ipv6_native = false
+ map_public_ip_on_launch = true
+ owner_id = (known after apply)
+ private_dns_hostname_type_on_launch = (known after apply)
+ tags = {
+ "Name" = "tf_eks_subnet1"
}
+ tags_all = {
+ "Name" = "tf_eks_subnet1"
}
+ vpc_id = "vpc-0f2e1cdca0cf5a306"
}
# aws_subnet.tf_eks_subnet2 will be created
+ resource "aws_subnet" "tf_eks_subnet2" {
+ arn = (known after apply)
+ assign_ipv6_address_on_creation = false
+ availability_zone = "us-west-1b"
+ availability_zone_id = (known after apply)
+ cidr_block = "10.10.82.0/24"
+ enable_dns64 = false
+ enable_resource_name_dns_a_record_on_launch = false
+ enable_resource_name_dns_aaaa_record_on_launch = false
+ id = (known after apply)
+ ipv6_cidr_block_association_id = (known after apply)
+ ipv6_native = false
+ map_public_ip_on_launch = true
+ owner_id = (known after apply)
+ private_dns_hostname_type_on_launch = (known after apply)
+ tags = {
+ "Name" = "tf_eks_subnet2"
}
+ tags_all = {
+ "Name" = "tf_eks_subnet2"
}
+ vpc_id = "vpc-0f2e1cdca0cf5a306"
}
Plan: 4 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
创建子网
terraform apply "tf.plan"
输出如下:
aws_subnet.tf_eks_subnet2: Creating...
aws_subnet.tf_eks_subnet1: Creating...
aws_subnet.tf_eks_subnet1: Still creating... [10s elapsed]
aws_subnet.tf_eks_subnet2: Still creating... [10s elapsed]
aws_subnet.tf_eks_subnet2: Creation complete after 13s [id=subnet-0a30534a829758774]
aws_route_table_association.tf_eks_subnet2_association: Creating...
aws_subnet.tf_eks_subnet1: Creation complete after 13s [id=subnet-01b5d98060f0063ef]
aws_route_table_association.tf_eks_subnet1_association: Creating...
aws_route_table_association.tf_eks_subnet1_association: Creation complete after 1s [id=rtbassoc-08fef5fee4d037035]
aws_route_table_association.tf_eks_subnet2_association: Creation complete after 1s [id=rtbassoc-0ec12dc9868d6316a]
Apply complete! Resources: 4 added, 0 changed, 0 destroyed.
2. 创建EKS安全组
eks_security_group.tf
这里放开所有只是为了演示,请勿用在生产环境中
resource "aws_security_group" "eks_allow_all" {
name = "eks_allow_all"
description = "Security group that allows all inbound and outbound traffic"
vpc_id = aws_vpc.tf_vpc.id
// 允许所有入站流量
ingress {
from_port = 0
to_port = 0
protocol = "-1" // -1 表示所有协议
cidr_blocks = ["0.0.0.0/0"] // 允许来自所有 IP 的流量
}
// 允许所有出站流量
egress {
from_port = 0
to_port = 0
protocol = "-1" // -1 表示所有协议
cidr_blocks = ["0.0.0.0/0"] // 允许流量发送到所有 IP
}
}
解释
resource "aws_security_group" "eks_allow_all"
: 声明一个名为
eks_allow_all
的资源,类型为
aws_security_group
,用于创建安全组。
name = "eks_allow_all"
: 设置安全组的名称为
eks_allow_all
。
description = "Security group that allows all inbound and outbound traffic"
: 为安全组提供描述,说明这个安全组的作用是允许所有入站和出站流量。
vpc_id = aws_vpc.tf_vpc.id
: 指定安全组所属的 VPC,引用了之前定义的 VPC 的 ID。
入站规则(
ingress
)
ingress { ... }
:
定义入站规则,允许流量进入安全组。
from_port = 0
和
to_port = 0
: 这表示允许所有端口的流量(0到0表示所有端口)。
protocol = "-1"
:
-1
表示所有协议,包括 TCP、UDP 和 ICMP 等。
cidr_blocks = ["0.0.0.0/0"]
: 允许来自所有 IP 地址的流量(0.0.0.0/0 表示任意 IP)。
出站规则(
egress
)
egress { ... }
:
定义出站规则,允许流量离开安全组。
from_port = 0
和
to_port = 0
: 同样允许所有端口的流量。
protocol = "-1"
: 表示所有协议。
cidr_blocks = ["0.0.0.0/0"]
: 允许流量发送到所有 IP 地址。
预创建
terraform plan -out=tf.plan
tf plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
+ create
Terraform will perform the following actions:
# aws_security_group.eks_allow_all will be created
+ resource "aws_security_group" "eks_allow_all" {
+ arn = (known after apply)
+ description = "Security group that allows all inbound and outbound traffic"
+ egress = [
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ from_port = 0
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "-1"
+ security_groups = []
+ self = false
+ to_port = 0
# (1 unchanged attribute hidden)
},
]
+ id = (known after apply)
+ ingress = [
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ from_port = 0
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "-1"
+ security_groups = []
+ self = false
+ to_port = 0
# (1 unchanged attribute hidden)
},
]
+ name = "eks_allow_all"
+ name_prefix = (known after apply)
+ owner_id = (known after apply)
+ revoke_rules_on_delete = false
+ tags_all = (known after apply)
+ vpc_id = "vpc-0f2e1cdca0cf5a306"
}
Plan: 1 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
创建安全组
terraform apply "tf.plan"
输出如下:
aws_security_group.eks_allow_all: Creating...
aws_security_group.eks_allow_all: Creation complete after 7s [id=sg-0db88cd4ca4b95099]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
3. 创建 EKS 集群 IAM 角色
创建
eks_iam_roles.tf文件
data "aws_iam_policy_document" "assume_role" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["eks.amazonaws.com"]
}
actions = ["sts:AssumeRole"]
}
}
resource "aws_iam_role" "eks-cluster" {
name = "eks-cluster"
assume_role_policy = data.aws_iam_policy_document.assume_role.json
}
resource "aws_iam_role_policy_attachment" "eks-cluster-AmazonEKSClusterPolicy" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSClusterPolicy"
role = aws_iam_role.eks-cluster.name
}
resource "aws_iam_role_policy_attachment" "eks-cluster-AmazonEKSVPCResourceController" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSVPCResourceController"
role = aws_iam_role.eks-cluster.name
}
解释
这段代码定义了一个 IAM 角色及其权限策略,用于 Amazon EKS 集群的创建和管理。以下是详细解释:
数据源部分
data "aws_iam_policy_document" "assume_role"
:
IAM 角色部分
resource "aws_iam_role" "eks-cluster"
:
IAM 角色策略附件
resource "aws_iam_role_policy_attachment" "eks-cluster-AmazonEKSClusterPolicy"
:
- 关联 Amazon EKS Cluster Policy 到 IAM 角色。
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSClusterPolicy"
: 指定要附加的策略 ARN。
role = aws_iam_role.eks-cluster.name
: 将策略附加到之前创建的
eks-cluster
角色。
resource "aws_iam_role_policy_attachment" "eks-cluster-AmazonEKSVPCResourceController"
:
- 关联 Amazon EKS VPC Resource Controller 策略到 IAM 角色。
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSVPCResourceController"
: 指定要附加的策略 ARN。
role = aws_iam_role.eks-cluster.name
: 将策略附加到之前创建的
eks-cluster
角色。
预创建
terraform plan -out=tf.plan
tf plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
+ create
Terraform will perform the following actions:
# aws_iam_role.eks-cluster will be created
+ resource "aws_iam_role" "eks-cluster" {
+ arn = (known after apply)
+ assume_role_policy = jsonencode(
{
+ Statement = [
+ {
+ Action = "sts:AssumeRole"
+ Effect = "Allow"
+ Principal = {
+ Service = "eks.amazonaws.com"
}
+ Sid = ""
},
]
+ Version = "2012-10-17"
}
)
+ create_date = (known after apply)
+ force_detach_policies = false
+ id = (known after apply)
+ managed_policy_arns = (known after apply)
+ max_session_duration = 3600
+ name = "eks-cluster"
+ name_prefix = (known after apply)
+ path = "/"
+ role_last_used = (known after apply)
+ tags_all = (known after apply)
+ unique_id = (known after apply)
+ inline_policy (known after apply)
}
# aws_iam_role_policy_attachment.eks-cluster-AmazonEKSClusterPolicy will be created
+ resource "aws_iam_role_policy_attachment" "eks-cluster-AmazonEKSClusterPolicy" {
+ id = (known after apply)
+ policy_arn = "arn:aws:iam::aws:policy/AmazonEKSClusterPolicy"
+ role = "eks-cluster"
}
# aws_iam_role_policy_attachment.eks-cluster-AmazonEKSVPCResourceController will be created
+ resource "aws_iam_role_policy_attachment" "eks-cluster-AmazonEKSVPCResourceController" {
+ id = (known after apply)
+ policy_arn = "arn:aws:iam::aws:policy/AmazonEKSVPCResourceController"
+ role = "eks-cluster"
}
Plan: 3 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
创建eks iam role
terraform apply "tf.plan"
输出如下:
aws_iam_role.eks-cluster: Creating...
aws_iam_role.eks-cluster: Creation complete after 2s [id=eks-cluster]
aws_iam_role_policy_attachment.eks-cluster-AmazonEKSVPCResourceController: Creating...
aws_iam_role_policy_attachment.eks-cluster-AmazonEKSClusterPolicy: Creating...
aws_iam_role_policy_attachment.eks-cluster-AmazonEKSVPCResourceController: Creation complete after 1s [id=eks-cluster-20241027124651622300000001]
aws_iam_role_policy_attachment.eks-cluster-AmazonEKSClusterPolicy: Creation complete after 1s [id=eks-cluster-20241027124651968900000002]
Apply complete! Resources: 3 added, 0 changed, 0 destroyed.
4. 创建EKS集群
编写eks_cluster.tf
文件
resource "aws_eks_cluster" "tf-eks" {
name = "tf-eks"
version = var.eks_version # 指定 EKS 版本
role_arn = aws_iam_role.eks-cluster.arn
vpc_config {
subnet_ids = [
aws_subnet.tf_eks_subnet1.id,
aws_subnet.tf_eks_subnet2.id
]
security_group_ids = [aws_security_group.eks_allow_all.id] # 引用之前创建的安全组
endpoint_public_access = true # 公有访问
endpoint_private_access = true # 私有访问
public_access_cidrs = ["0.0.0.0/0"] # 允许从任何地方访问
}
# # 启用日志
# enabled_cluster_log_types = [
# "api",
# "audit",
# "authenticator",
# "controllerManager",
# "scheduler",
# ]
depends_on = [
aws_iam_role_policy_attachment.eks-cluster-AmazonEKSClusterPolicy,
aws_iam_role_policy_attachment.eks-cluster-AmazonEKSVPCResourceController,
]
}
参数解释
name
:指定集群的名称为
tf-eks
。
version
:指定 EKS 的版本,使用变量
var.eks_version
,这样可以方便地在不同环境中调整。
role_arn
:指定用于 EKS 集群的 IAM 角色 ARN,通常这个角色需要有相应的权限策略。
subnet_ids
:指定 EKS 集群所在的子网,允许使用多个子网 ID,以便在高可用性场景中部署。
security_group_ids
:引用之前创建的安全组,用于控制集群的网络流量。
endpoint_public_access
:设置为
true
,表示允许通过公共网络访问 EKS API 端点。
endpoint_private_access
:设置为
true
,表示允许在 VPC 内部访问 EKS API 端点。
public_access_cidrs
:允许访问集群的 CIDR 范围,这里设置为
["0.0.0.0/0"]
,表示允许任何 IP 地址访问,这可能会带来安全风险。- 日志部分注释了,若启用,可以指定需要记录的集群日志类型,包括 API、审计、身份验证器、控制器管理器和调度程序等。
depends_on
:确保在创建 EKS 集群之前,所需的 IAM 角色策略已经附加,确保资源的创建顺序正确
预创建
terraform plan -out=tf.plan
tf plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
+ create
Terraform will perform the following actions:
# aws_eks_cluster.tf-eks will be created
+ resource "aws_eks_cluster" "tf-eks" {
+ arn = (known after apply)
+ certificate_authority = (known after apply)
+ cluster_id = (known after apply)
+ created_at = (known after apply)
+ endpoint = (known after apply)
+ id = (known after apply)
+ identity = (known after apply)
+ name = "tf-eks"
+ platform_version = (known after apply)
+ role_arn = "arn:aws:iam::xxxxxxxx:role/eks-cluster"
+ status = (known after apply)
+ tags_all = (known after apply)
+ version = "1.31"
+ kubernetes_network_config (known after apply)
+ vpc_config {
+ cluster_security_group_id = (known after apply)
+ endpoint_private_access = true
+ endpoint_public_access = true
+ public_access_cidrs = [
+ "0.0.0.0/0",
]
+ security_group_ids = [
+ "sg-0db88cd4ca4b95099",
]
+ subnet_ids = [
+ "subnet-01b5d98060f0063ef",
+ "subnet-0a30534a829758774",
]
+ vpc_id = (known after apply)
}
}
Plan: 1 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
创建
terraform apply "tf.plan"
输出如下:
aws_eks_cluster.tf-eks: Creating...
aws_eks_cluster.tf-eks: Still creating... [10s elapsed]
aws_eks_cluster.tf-eks: Still creating... [20s elapsed]
aws_eks_cluster.tf-eks: Still creating... [30s elapsed]
......
.......
aws_eks_cluster.tf-eks: Still creating... [7m21s elapsed]
aws_eks_cluster.tf-eks: Still creating... [7m31s elapsed]
aws_eks_cluster.tf-eks: Creation complete after 7m35s [id=tf-eks]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
5. 创建Node Group IAM
创建tf文件
eks_node_group_iam.tf
resource "aws_iam_role" "eks-nodegroup-role" {
name = "eks-nodegroup-role"
assume_role_policy = jsonencode({
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "ec2.amazonaws.com"
}
}]
Version = "2012-10-17"
})
}
resource "aws_iam_role_policy_attachment" "eks-nodegroup-role-AmazonEKSWorkerNodePolicy" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy"
role = aws_iam_role.eks-nodegroup-role.name
}
resource "aws_iam_role_policy_attachment" "eks-nodegroup-role-AmazonEKS_CNI_Policy" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy"
role = aws_iam_role.eks-nodegroup-role.name
}
resource "aws_iam_role_policy_attachment" "eks-nodegroup-role-AmazonEC2ContainerRegistryReadOnly" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly"
role = aws_iam_role.eks-nodegroup-role.name
}
解释
这段代码定义了一个 IAM 角色,用于 Amazon EKS 节点组,并附加了必要的权限策略。以下是详细解释:
IAM 角色定义
resource "aws_iam_role" "eks-nodegroup-role"
:
创建一个名为
eks-nodegroup-role
的 IAM 角色,供 EKS 节点使用。
assume_role_policy = jsonencode({ ... })
: 定义角色的信任策略,允许特定服务假设此角色。
Statement = [{ ... }]
: 定义角色的权限声明。
Action = "sts:AssumeRole"
: 允许的操作,即假设角色。
Effect = "Allow"
: 该声明的效果是允许。
Principal = { Service = "ec2.amazonaws.com" }
: 允许
ec2.amazonaws.com
服务(即 EC2 实例)来假设此角色,这样 EKS 节点才能获得权限。
Version = "2012-10-17"
: 定义策略语言的版本。
IAM 角色策略附件
resource "aws_iam_role_policy_attachment" "eks-nodegroup-role-AmazonEKSWorkerNodePolicy"
:
- 将 Amazon EKS Worker Node Policy 附加到节点组角色。
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy"
: 指定要附加的策略 ARN。
role = aws_iam_role.eks-nodegroup-role.name
: 将策略附加到之前创建的
eks-nodegroup-role
角色。
resource "aws_iam_role_policy_attachment" "eks-nodegroup-role-AmazonEKS_CNI_Policy"
:
- 将 Amazon EKS CNI Policy 附加到节点组角色。
policy_arn = "arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy"
: 指定要附加的策略 ARN。
role = aws_iam_role.eks-nodegroup-role.name
: 将策略附加到之前创建的
eks-nodegroup-role
角色。
resource "aws_iam_role_policy_attachment" "eks-nodegroup-role-AmazonEC2ContainerRegistryReadOnly"
:
- 将 Amazon EC2 Container Registry Read Only Policy 附加到节点组角色。
policy_arn = "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly"
: 指定要附加的策略 ARN。
role = aws_iam_role.eks-nodegroup-role.name
: 将策略附加到之前创建的
eks-nodegroup-role
角色。
预创建
terraform plan -out=tf.plan
tf plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
+ create
Terraform will perform the following actions:
# aws_iam_role.eks-nodegroup-role will be created
+ resource "aws_iam_role" "eks-nodegroup-role" {
+ arn = (known after apply)
+ assume_role_policy = jsonencode(
{
+ Statement = [
+ {
+ Action = "sts:AssumeRole"
+ Effect = "Allow"
+ Principal = {
+ Service = "ec2.amazonaws.com"
}
},
]
+ Version = "2012-10-17"
}
)
+ create_date = (known after apply)
+ force_detach_policies = false
+ id = (known after apply)
+ managed_policy_arns = (known after apply)
+ max_session_duration = 3600
+ name = "eks-nodegroup-role"
+ name_prefix = (known after apply)
+ path = "/"
+ role_last_used = (known after apply)
+ tags_all = (known after apply)
+ unique_id = (known after apply)
+ inline_policy (known after apply)
}
# aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEC2ContainerRegistryReadOnly will be created
+ resource "aws_iam_role_policy_attachment" "eks-nodegroup-role-AmazonEC2ContainerRegistryReadOnly" {
+ id = (known after apply)
+ policy_arn = "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly"
+ role = "eks-nodegroup-role"
}
# aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEKSWorkerNodePolicy will be created
+ resource "aws_iam_role_policy_attachment" "eks-nodegroup-role-AmazonEKSWorkerNodePolicy" {
+ id = (known after apply)
+ policy_arn = "arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy"
+ role = "eks-nodegroup-role"
}
# aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEKS_CNI_Policy will be created
+ resource "aws_iam_role_policy_attachment" "eks-nodegroup-role-AmazonEKS_CNI_Policy" {
+ id = (known after apply)
+ policy_arn = "arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy"
+ role = "eks-nodegroup-role"
}
Plan: 4 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
创建node group iam
terraform apply "tf.plan"
输出:
aws_iam_role.eks-nodegroup-role: Creating...
aws_iam_role.eks-nodegroup-role: Creation complete after 2s [id=eks-nodegroup-role]
aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEKS_CNI_Policy: Creating...
aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEC2ContainerRegistryReadOnly: Creating...
aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEKSWorkerNodePolicy: Creating...
aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEC2ContainerRegistryReadOnly: Creation complete after 1s [id=eks-nodegroup-role-20241027130604526800000001]
aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEKS_CNI_Policy: Creation complete after 1s [id=eks-nodegroup-role-20241027130604963000000002]
aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEKSWorkerNodePolicy: Creation complete after 2s [id=eks-nodegroup-role-20241027130605372700000003]
Apply complete! Resources: 4 added, 0 changed, 0 destroyed.
转载请著名原文地址:
https://www.cnblogs.com/Sunzz/p/18498915
6. 创建Node Group
定义
eks_node_group.tf文件
resource "aws_eks_node_group" "node_group1" {
cluster_name = aws_eks_cluster.tf-eks.name
node_group_name = "node_group1"
ami_type = "AL2_x86_64"
capacity_type = "ON_DEMAND"
disk_size = 20
instance_types = ["t3.medium"]
node_role_arn = aws_iam_role.eks-nodegroup-role.arn
subnet_ids = [
aws_subnet.tf_eks_subnet1.id,
aws_subnet.tf_eks_subnet2.id
]
scaling_config {
desired_size = 1
max_size = 2
min_size = 1
}
update_config {
max_unavailable = 1
}
depends_on = [
aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEKSWorkerNodePolicy,
aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEKS_CNI_Policy,
aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEC2ContainerRegistryReadOnly,
]
# remote_access {
# ec2_ssh_key = aws_key_pair.tf-keypair.key_name
# source_security_group_ids = [
# aws_security_group.tf_security_group.id
# ]
# }
}
resource "aws_eks_node_group" "node_group2" {
cluster_name = aws_eks_cluster.tf-eks.name
node_group_name = "node_group2"
ami_type = "AL2_x86_64"
capacity_type = "ON_DEMAND"
disk_size = 20
instance_types = ["t3.medium"]
node_role_arn = aws_iam_role.eks-nodegroup-role.arn
subnet_ids = [
aws_subnet.tf_eks_subnet1.id,
aws_subnet.tf_eks_subnet2.id
]
scaling_config {
desired_size = 1
max_size = 2
min_size = 1
}
update_config {
max_unavailable = 1
}
depends_on = [
aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEKSWorkerNodePolicy,
aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEKS_CNI_Policy,
aws_iam_role_policy_attachment.eks-nodegroup-role-AmazonEC2ContainerRegistryReadOnly,
]
# remote_access {
# ec2_ssh_key = aws_key_pair.tf-keypair.key_name
# source_security_group_ids = [
# aws_security_group.tf_security_group.id
# ]
# }
}
解释
EKS 节点组定义
resource "aws_eks_node_group" "node_group1"
: 创建一个名为
node_group1
的 EKS 节点组。
cluster_name = aws_eks_cluster.tf-eks.name
: 指定该节点组所属的 EKS 集群,引用之前创建的
tf-eks
集群的名称。
node_group_name = "node_group1"
: 设置节点组的名称为
node_group1
。
ami_type = "AL2_x86_64"
: 指定节点组使用的 Amazon Machine Image (AMI) 类型,这里使用的是 Amazon Linux 2 (AL2) 的 x86_64 架构。可选的有
AL2_x86_64 AL2_x86_64_GPU AL2_ARM_64 CUSTOM BOTTLEROCKET_ARM_64 BOTTLEROCKET_x86_64 BOTTLEROCKET_ARM_64_NVIDIA BOTTLEROCKET_x86_64_NVIDIA WINDOWS_CORE_2019_x86_64 WINDOWS_FULL_2019_x86_64 WINDOWS_CORE_2022_x86_64 WINDOWS_FULL_2022_x86_64],
capacity_type = "ON_DEMAND"
: 设置实例的容量类型为按需(On-Demand),即按使用付费,而非预留。
disk_size = 20
: 为每个节点指定根卷的大小,这里设置为 20 GB。
instance_types = ["t3.medium"]
: 指定节点的实例类型,这里使用的是
t3.medium
类型。
node_role_arn = aws_iam_role.eks-nodegroup-role.arn
: 指定节点组的 IAM 角色 ARN,允许节点访问必要的 AWS 服务。
subnet_ids = [ ... ]
: 定义节点组将要使用的子网,引用
tf_eks_subnet1
和
tf_eks_subnet2
的 ID。这些子网是 EKS 节点运行的网络环境。
扩展和更新配置
scaling_config { ... }
:
- 设置节点组的扩展配置。
desired_size = 1
: 默认启动一个节点。
max_size = 2
: 节点组最多可以扩展到 2 个节点。
min_size = 1
: 节点组至少保留一个节点。
update_config { ... }
:
- 配置节点组的更新策略。
max_unavailable = 1
: 更新过程中,最多可以有一个节点不可用。
依赖关系
depends_on = [ ... ]
: 指定该资源的依赖关系,确保在创建节点组之前,相关的 IAM 角色策略附加操作已经完成。
远程访问配置(被注释掉)
remote_access { ... }
(被注释掉):
- 此部分配置远程访问选项,允许 SSH 访问节点组。
ec2_ssh_key = aws_key_pair.tf-keypair.key_name
: 指定用于 SSH 访问的 EC2 密钥对。
source_security_group_ids = [ ... ]
: 指定允许 SSH 访问的安全组。
预创建
terraform plan -out=tf.plan
tf plan
Terraform will perform the following actions:
# aws_eks_node_group.node_group1 will be created
+ resource "aws_eks_node_group" "node_group1" {
+ ami_type = "AL2_x86_64"
+ arn = (known after apply)
+ capacity_type = "ON_DEMAND"
+ cluster_name = "tf-eks"
+ disk_size = 20
+ id = (known after apply)
+ instance_types = [
+ "t3.medium",
]
+ node_group_name = "node_group1"
+ node_group_name_prefix = (known after apply)
+ node_role_arn = "arn:aws:iam::xxxxxx:role/eks-nodegroup-role"
+ release_version = (known after apply)
+ resources = (known after apply)
+ status = (known after apply)
+ subnet_ids = [
+ "subnet-01b5d98060f0063ef",
+ "subnet-0a30534a829758774",
]
+ tags_all = (known after apply)
+ version = (known after apply)
+ scaling_config {
+ desired_size = 1
+ max_size = 2
+ min_size = 1
}
+ update_config {
+ max_unavailable = 1
}
}
# aws_eks_node_group.node_group2 will be created
+ resource "aws_eks_node_group" "node_group2" {
+ ami_type = "AL2_x86_64"
+ arn = (known after apply)
+ capacity_type = "ON_DEMAND"
+ cluster_name = "tf-eks"
+ disk_size = 20
+ id = (known after apply)
+ instance_types = [
+ "t3.medium",
]
+ node_group_name = "node_group2"
+ node_group_name_prefix = (known after apply)
+ node_role_arn = "arn:aws:iam::xxxxx:role/eks-nodegroup-role"
+ release_version = (known after apply)
+ resources = (known after apply)
+ status = (known after apply)
+ subnet_ids = [
+ "subnet-01b5d98060f0063ef",
+ "subnet-0a30534a829758774",
]
+ tags_all = (known after apply)
+ version = (known after apply)
+ scaling_config {
+ desired_size = 1
+ max_size = 2
+ min_size = 1
}
+ update_config {
+ max_unavailable = 1
}
}
Plan: 2 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Saved the plan to: tf.plan
To perform exactly these actions, run the following command to apply:
terraform apply "tf.plan"
创建Node Group
terraform apply "tf.plan"
输出如下:
aws_eks_node_group.node_group2: Creating...
aws_eks_node_group.node_group1: Creating...
aws_eks_node_group.node_group1: Still creating... [10s elapsed]
......
aws_eks_node_group.node_group1: Creation complete after 1m41s [id=tf-eks:node_group1]
aws_eks_node_group.node_group2: Still creating... [1m50s elapsed]
aws_eks_node_group.node_group2: Creation complete after 1m52s [id=tf-eks:node_group2]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
7. 获取EKS信息
新增eks_output.tf
# 输出 EKS 集群的名称
output "eks_cluster_name" {
value = aws_eks_cluster.tf-eks.name
description = "The name of the EKS cluster"
}
# 输出 EKS 集群的 ARN(Amazon Resource Name)
output "eks_cluster_arn" {
value = aws_eks_cluster.tf-eks.arn
description = "The ARN of the EKS cluster"
}
# 输出 EKS 集群的 API 服务器端点
output "eks_cluster_endpoint" {
value = aws_eks_cluster.tf-eks.endpoint
description = "The endpoint of the EKS cluster"
}
# 输出 EKS 集群的当前状态
output "eks_cluster_status" {
value = aws_eks_cluster.tf-eks.status
description = "The status of the EKS cluster"
}
# 输出与 EKS 集群关联的 VPC ID
output "eks_cluster_vpc_id" {
value = aws_eks_cluster.tf-eks.vpc_config[0].vpc_id
description = "The VPC ID associated with the EKS cluster"
}
# 输出与 EKS 集群关联的安全组 ID
output "eks_cluster_security_group_ids" {
value = aws_eks_cluster.tf-eks.vpc_config[0].cluster_security_group_id
description = "The security group IDs associated with the EKS cluster"
}
# 输出用于访问 EKS 集群的 kubeconfig 配置
output "kubeconfig" {
value = <<EOT
apiVersion: v1
clusters:
- cluster:
server: ${aws_eks_cluster.tf-eks.endpoint}
certificate-authority-data: ${aws_eks_cluster.tf-eks.certificate_authority[0].data}
name: ${aws_eks_cluster.tf-eks.name}
contexts:
- context:
cluster: ${aws_eks_cluster.tf-eks.name}
user: ${aws_eks_cluster.tf-eks.name}
name: ${aws_eks_cluster.tf-eks.name}
current-context: ${aws_eks_cluster.tf-eks.name}
kind: Config
preferences: {}
users:
- name: ${aws_eks_cluster.tf-eks.name}
user:
exec:
apiVersion: client.authentication.k8s.io/v1beta1
command: aws
args:
- eks
- get-token
- --cluster-name
- ${aws_eks_cluster.tf-eks.name}
EOT
description = "Kubeconfig for accessing the EKS cluster"
}
由于output.tf只是获取已经创建的资源信息,不涉及资源的修改,所以可以直接apply
terraform
apply
Apply complete! Resources: 0 added, 0 changed, 0 destroyed.
Outputs:
eks_cluster_arn = "arn:aws:eks:us-west-1:xxxxx:cluster/tf-eks"
eks_cluster_endpoint = "https://D59BB0103962C6BEABC8271AC16B34EC.gr7.us-west-1.eks.amazonaws.com"
eks_cluster_name = "tf-eks"
eks_cluster_security_group_ids = "sg-0159f56ebd2d93a38"
eks_cluster_status = "ACTIVE"
eks_cluster_vpc_id = "vpc-0361291552eab4047"
kubeconfig = <<EOT
apiVersion: v1
clusters:
- cluster:
server: https://D59BB0103962C6BEABC8271AC16B34EC.gr7.us-west-1.eks.amazonaws.com
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURCVENDQWUyZ0F3SUJBZ0lJSG83cjJJV.....
name: tf-eks
contexts:
- context:
cluster: tf-eks
user: tf-eks
name: tf-eks
current-context: tf-eks
kind: Config
preferences: {}
users:
- name: tf-eks
user:
exec:
apiVersion: client.authentication.k8s.io/v1beta1
command: aws
args:
- eks
- get-token
- --cluster-name
- tf-eks
EOT
8. 配置kubeconfig
方式1
根据上边生成的kubeconfig内容配置~/.kube/config即可
方式2
执行命令生成kubeconfig文件
aws eks update-kubeconfig --region us-west-1 --name tf-eks
查看集群节点数量
kubectl get no
kubectl get no
NAME STATUS ROLES AGE VERSION
ip-10-10-81-13.us-west-1.compute.internal Ready <none> 3m48s v1.31.0-eks-a737599
ip-10-10-82-102.us-west-1.compute.internal Ready <none> 4m1s v1.31.0-eks-a737599
查看集群允许的pod数量
kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system aws-node-8zjcn 2/2 Running 0 4m55s
kube-system aws-node-n4ns8 2/2 Running 0 4m42s
kube-system coredns-6486b6fd59-hkcnb 1/1 Running 0 20m
kube-system coredns-6486b6fd59-hz75m 1/1 Running 0 20m
kube-system kube-proxy-fbdv9 1/1 Running 0 4m42s
kube-system kube-proxy-nnb2r 1/1 Running 0 4m55s
9. 创建nginx应用
编辑nginx-deployment.yaml文件
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3 # 副本数量
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.26 # 指定 Nginx 镜像版本
ports:
- containerPort: 80 # 暴露容器端口
创建nginx-deployment
kubectl apply -f nginx-deployment.yaml

10.回顾创建的tf文件
至此我们已经创建了一堆tf文件,大家也可以一起创建所有的tf文件,最后再
terraform plan
详情如下:

9.销毁资源
terraform destroy
总结
经过一段时间的深入探索与编写,这篇博客成为了我迄今为止最费时间和最长的一篇作品。从研究Terraform的功能到实际操作在AWS上创建各种资源,每一个步骤都需要细致的推敲与反复的验证。这不仅让我更加熟悉Terraform的强大功能,也让我在分享知识的过程中收获了许多。
在这篇博文中,我力求以详尽的内容和清晰的解释帮助读者轻松入门,尤其是针对那些初学者。我希望这些努力能为读者提供实用的指导,帮助他们在云计算的道路上迈出坚实的第一步。这段旅程虽然漫长,但每一个字都承载着我对Terraform的热情和对知识分享的期待。希望你们能在这篇博客中找到灵感和启发!