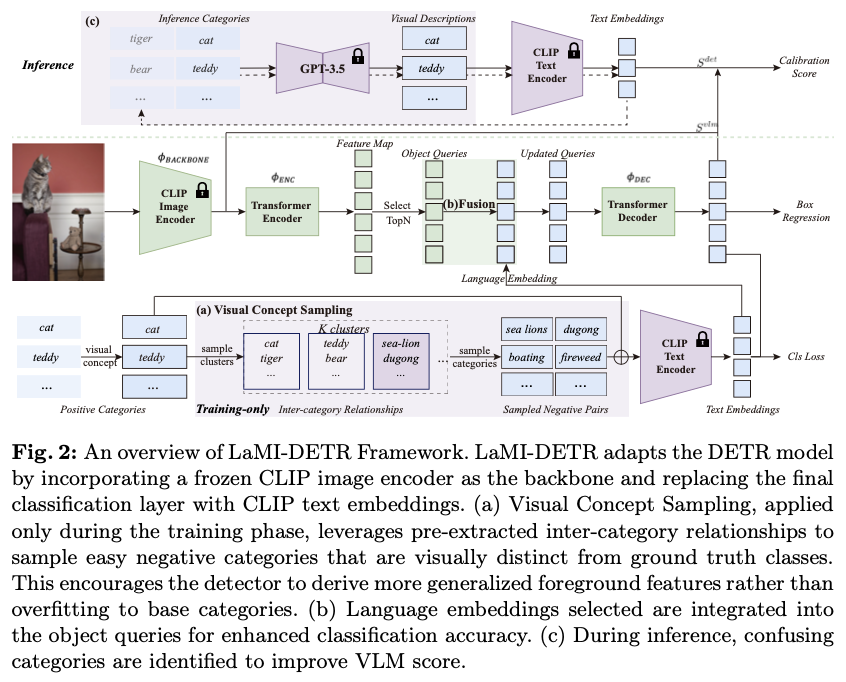
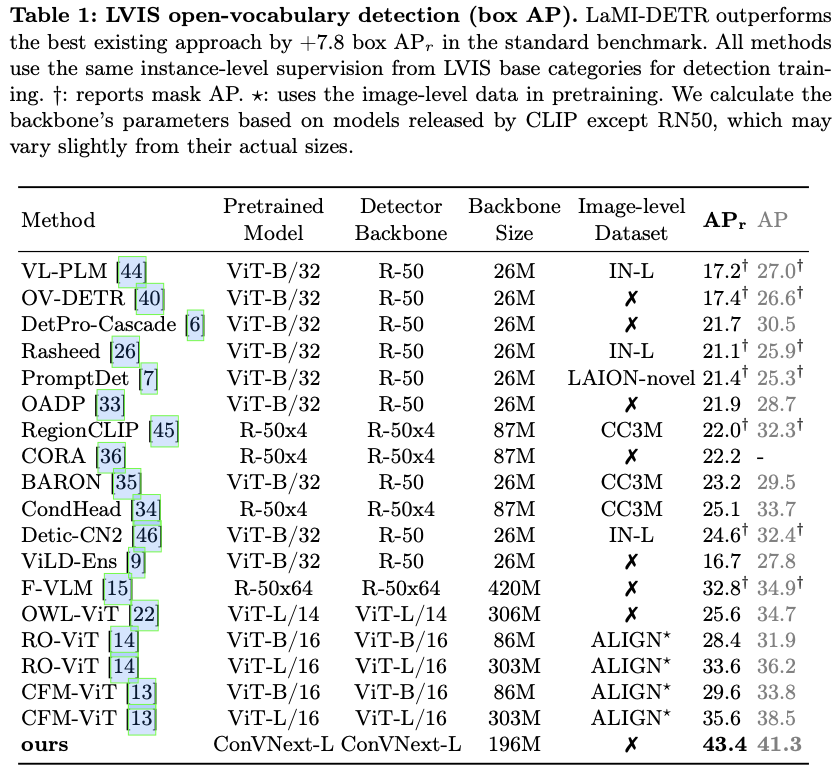
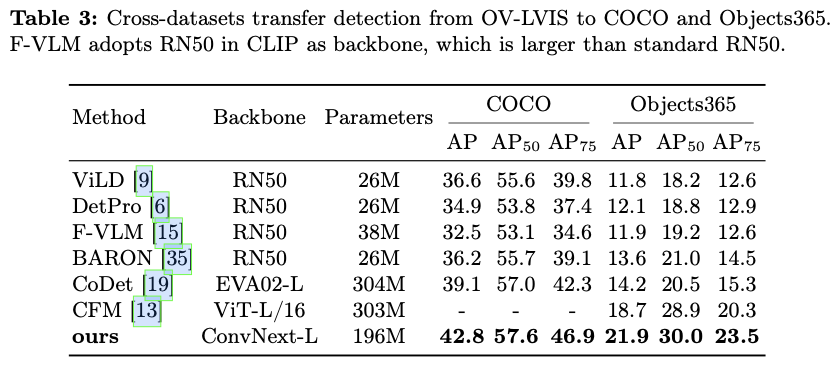
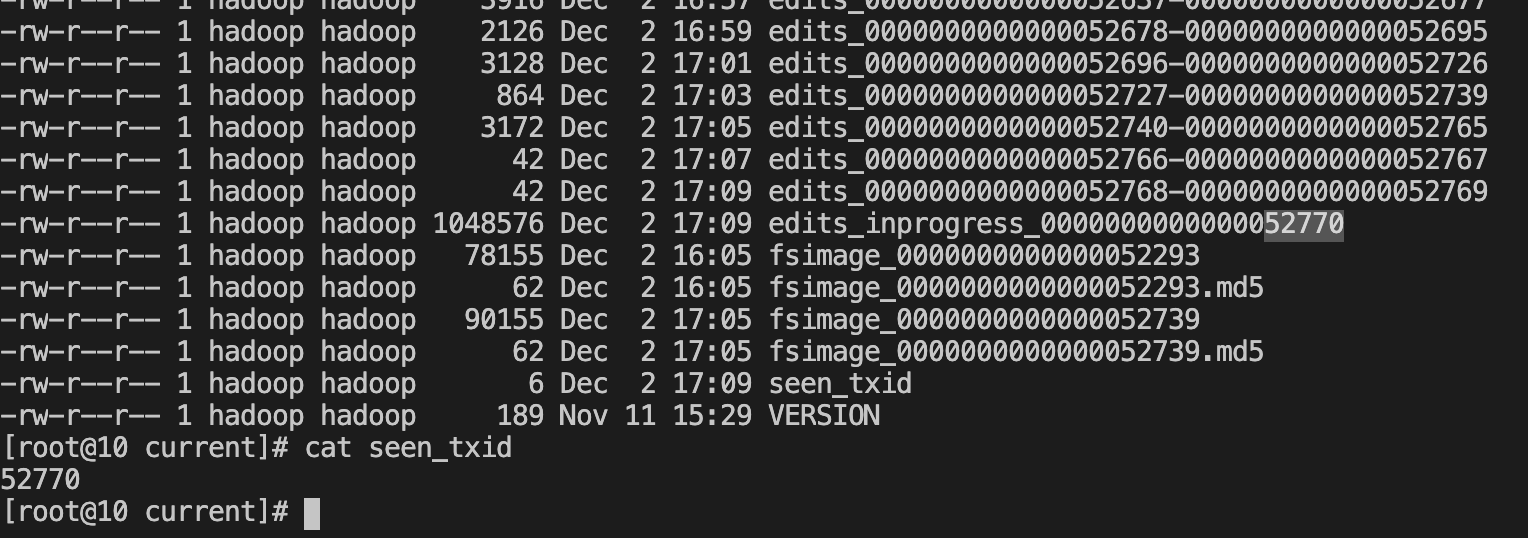
〇、Gateway API 的背景
第一阶段:Service
初始的 Kubernetes 内部服务向外暴露,
使用的是自身的 LoadBlancer 和 NodePort 类型的 Service
。
在集群规模逐渐扩大的时候,这种 Service 管理的方式满足不了我们的需求。
- 比如 NodePort 需要大量的端口难以维护,多了一层 NAT,请求量大会对性能有影响;
- LoadBlancer 需要每个 Service 都有一个外部负载均衡器。
第二阶段:Ingress
接着 Kubernetes 提供了一个内置的资源对象 Ingress API 来暴露 HTTP 服务给外部用户。
Ingress 的创建,是为了标准化的将 Kubernetes 中的服务流量暴露给外部,
Ingress API 通过引入路由功能,克服了默认服务类型 NodePort 和 LoadBalancer 的限制
。
在创建 Ingress 资源的时候通过 IngressClass 指定该网关使用的控制器,主要是靠
Ingress 控制器不断监听
Kubernetes API Server 中 IngressClass 以及 Ingress 资源的的变动,配置或更新入口网关和路由规则。
IngressClass 实现了网关与后台的解耦,但也有着很多的局限性。
- Ingress 配置过于简单,只支持 http 和 https 协议的服务路由和负载均衡,缺乏对其他协议和定制化需求的支持;
- 对于 http 协议的路由,只支持 host 和 path 的匹配,对于高级路由只能通过注解来实现,当然这取决于 Ingress 控制器的实现方式,不同的 Ingress 控制器使用不同的注解,来扩展功能,使用注解对于 Ingress 的可用性大打折扣;
- 路由无法共享一个命名空间的网关,不够灵活;
- 网关的创建和管理的权限没有划分界限,开发需要配置路由以及网关。
当然也有很多第三方的网关组件,例如 istio 和 apisix 等。
它们提供了丰富的流量管理功能,如负载均衡、动态路由、动态 upstream、A/B测试、金丝雀发布、限速、熔断、防御恶意攻击、认证、监控指标、服务可观测性、服务治理等,还可以处理南北流量以及服务之间的东西向流量。对外提供路由功能,对内提供流量筛选,已经很好的满足了当下网络环境的所有需求。
但对于小集群来说,这两个网关的部署成本有点高,而且太多类型的网关,不同的配置项、独立的开发接口、接口的兼容性、学习成本、使用成本、维护成本以及迁移成本都很高。
第三阶段:Gateway API
这种情况下,就急需一种
兼容所有厂商 API 的接口网关
,所以 Kubernetes 推出了 Gateway API。
一、Gateway API 简介
Gateway API 是 Kubernetes 1.19 版本引入的一种新的 API 规范,会成为 Ingress 的下一代替代方案。主要原因是 Ingress 资源对象不能很好的满足网络需求,很多场景下 Ingress 控制器都需要通过定义 annotations 或者 crd 来进行功能扩展,这对于使用标准和支持是非常不利的,新推出的 Gateway API 旨在通过可扩展的面向角色的接口来增强服务网络。
Gateway API(之前叫 Service API)是由 SIG-NETWORK 社区管理的开源项目,项目地址:https://gateway-api.sigs.k8s.io/。
Gateway API 有着 Ingress 的所有功能,且提供更丰富的功能。
- 面向角色。
通过角色划分将各层规则配置关注点分离,实现规则配置上的解耦;
- 规范化路由和后端。
支持类型化的路由资源和不同类型的后端,灵活地支持各种协议(如 HTTP、tcp、gRPC 等)和各种后端服务(如 Kubernetes Service、存储桶或函数);
- 支持基于 Header 头的匹配、流量权重等核心功能。
这些功能在 Ingress 中只能通过自定义注解才能实现;
- 允许自定义资源链接到 API 的各个层。
这就允许在 API 结构的适当位置进行更精细的定制;
- 允许独立的路由资源绑定到同一个网关。
这使得团队可以安全地共享跨命名空间 namespace 基础资源,使其更适应多云环境;
- 支持适配器插件。
可以扩展新的负载均衡算法、控制规则和协议解析器,满足更加复杂的网络需求;
- 提供了基于 L4/L7 协议层的负载均衡功能和流量控制功能。
可以根据不同的负载和需求来调整服务间的流量分配。可以在 API 层面实现安全认证和授权,并支持 TLS 终止、OAuth2、JWT 等常见的安全机制。
与 Ingress Api 工作类似的,Gateway Controller 会持续监视 Kubernetes API Server 中的 GatewayClass 和 Gateway 对象的变动,根据集群运维的配置来创建或更新其对应的网关和路由。
其实,
API 网关、入口控制器和服务网格的
核心都是一种代理
,目的在于内外部服务通信。
当前版本
Gateway API
目前的最新版本是 v1.1(2024年6月)。
此版本将服务网格和 GRPCRoute 的支持从实验阶段转移到了标准通道,意味着这些功能现在是一般可用(GA)状态。
还引入了会话持久性和客户端证书验证等新的实验性特性,增强了 Gateway API 的功能范围。
v1.1 版本的发布标志着四个关键特性从实验阶段变成了稳定版,这表明对 API 的稳定性有了足够的信心,并且会提供向后兼容性的保证。
Gateway API 发展时间还是比较短的,相信随着时间的推进,Gateway API 的各方面功能将不断完善,以应对不同场景的需求。包括性能、扩展性、传输过程中的加密和身份验证等。
适用场景
主要有以下几个应用场景:
- 多版本部署。
如果您的应用程序有多个版本,您可以使用 HTTPRoute 来将流量路由到不同的版本,以便测试和逐步升级。例如,您可以将一部分流量路由到新版本进行测试,同时保持旧版本的运行。
- A/B 测试。
HTTPRoute 可以通过权重分配来实现 A/B 测试。您可以将流量路由到不同的后端服务,并为每个服务指定一个权重,以便测试不同版本的功能和性能。
- 动态路由。
HTTPRoute 支持基于路径、请求头、请求参数和请求体等条件的动态路由。这使得您可以根据请求的不同属性将流量路由到不同的后端服务,以满足不同的需求。
- 重定向。
HTTPRoute 支持重定向,您可以将某些请求重定向到另一个 URL 上,例如将旧的 URL 重定向到新的 URL。
- 微服务 API 聚合与管理。
在微服务架构中,服务数量众多,管理这些服务的 API 接口变得复杂。Gateway API 可以提供统一的入口,实现API的路由、负载均衡、认证授权等功能,使开发者可以专注于业务逻辑的实现。
- 安全加固。
安全是 API 管理中的首要考量。Gateway API 支持多种认证方式,如 OAuth2.0、JWT 等,以及 IP 黑白名单、请求限流等安全策略,有效防止 API 滥用和攻击。
- 流量控制与监控。
面对突发的流量高峰,Gateway API 能够自动进行流量控制,通过设置 QPS 限制、熔断机制等,确保服务的高可用性。同时,其内置的监控和日志功能让运维人员能实时掌握 API 调用情况。
目前 Gateway API 还处于开发阶段,尽管 Gateway API 还不算成熟和稳定,但由于其强大的功能和作为 Kubernetes 官方项目的影响力,已经获得大量项目的支持和兼容。
例如 Apache APISIX,它来实现高性能、高可用性的 API 网关,通过 Gateway API 实现请求路由、安全认证、限流等功能。同时,Apache APISIX 还支持灰度发布、集群管理和插件机制等特性,可以满足大部分企业级 API 网关的需求。
二、详解
2.1 资源类型
Gateway API 是 Kubernetes 中的一个 API 资源集合,包括 GatewayClass、Gateway、HTTPRoute、TCPRoute、Service 等,这些资源共同为各种网络用例构建模型。
其中最主要有三种对象类型:GatewayClass、Gateway、Route,下文将逐一简单介绍下。
2.1.1 GatewayClass
GatewayClass 定义了一组共享配置和行为的 Gateway,GatewayClass 是一个集群范围的资源,必须至少定义一个 GatewayClass,Gateway 引用该 GatewayClass 才能够生效。
每个 GatewayClass 必须关联一个控制器 Controller ,控制器可以处理多个 GatewayClass。控制器 Controller 作用就是持续监视 Kubernetes API Server 中的 GatewayClass 和 Gateway 对象的变动,创建或更新其对应的网关和路由配置。
通俗讲 GatewayClass 就是一类 Gateway 的集合的入口,Gateway 想要实现转发必须要关联到某一个 GatewayClass 上,而 GatewayClass 也需要关联到一个网关控制器 Controller,控制器可以监听 API Server 资源中 GatewayClass 以及 Gateway 的变化。

比如 Istio、Traefik、Apisix 等根据 Gateway Api 的标准和要求,实现了一个 Controller,能够让 Gateway 依赖 GatewayClass 创建对应的网关。
一般 GatewayClass 不需要人工手动创建,参与支持 Gateway Api 工程的第三方网关组件安装时会自动创建。
GatewayClass 与控制器 Controller 使用 spec.controllerName 关联。
下面是一个最精简的 GatewayClass 示例:
apiVersion: gateway.networking.k8s.io/v1 # 指定了使用的 API 版本,v1:第一个稳定版本
kind: GatewayClass # 资源类型为 GatewayClass
metadata: # 包含资源的元数据信息
name: example-class # 指定了 GatewayClass 的名称,这个名称在集群中应该是唯一的
spec: # 指定 GatewayClass 的具体配置
controllerName: example.com/gateway-controller # 指定与该 GatewayClass 相关联的控制器名称
2.1.2 Gateway
Gateway 负责外部请求到集群内的流量接入,以及往后转发,定义了对特定负载均衡器配置的请求。
Gateway
实现了 GatewayClass 配置和行为的约定
,该资源可以由
运维人员
直接创建,也可以由处理
GatewayClass 的控制器
创建。
Gateway 资源是一个中间层,需要定义所要监听的端口、协议、TLS 配置等信息,可以
将网络流量的管理和控制集中到一个位置
,提高集群的可用性和安全性。
配置完成后,由 GatewayClass 绑定的 Controller 为我们提供一个具体存在的 Pod 作为流量入口。
下面是一个精简的 Gateway 资源示例:
apiVersion: gateway.networking.k8s.io/v1 # 指定了使用的 API 版本
kind: Gateway # 定义了资源类型为 Gateway
metadata: # 包含了资源的元数据信息
name: example-gateway # 指定了 Gateway 的名称,在集群中应该是【唯一】的
spec: # 指定了 Gateway 的具体配置
gatewayClassName: example-class # 指定了这个 Gateway 所属的 GatewayClass 名称,必填
listeners: # 定义了一个或多个监听器,每个监听器代表一种协议和一个端口号,必填
# name 指定了监听器的名称,在 Gateway 中应该是【唯一】的
# 未指定时,匹配所有主机名。对于不需要基于主机名匹配的协议,此字段将被忽略
- name: http # 指定了监听器的名称,在 Gateway 中应该是【唯一】的
hostname: www.gateway.*.com # 定义一个域名,一般为泛域名、匹配来自该域名的流量
protocol: HTTP # 指定了监听器使用的协议
port: 80 # 指定了监听器使用的端口号
allowedRoutes: # 定义了允许哪些路由通过该监听器
namespaces: # 指定了允许路由的命名空间范围
from: All # All 表示允许所有命名空间
- name: https
protocol: HTTPS # 协议为 https
port: 81
allowedRoutes:
namespaces:
from: All
tls: # 为 HTTPS 配置加密协议
mode: Terminate # 加密协议类型,Terminate 或 Passthrough
certificateRefs: # 定义了一个或多个证书引用,用于验证服务器身份
- kind: Secret # 指定了证书引用的类型
name: cafe-secret # 指定了证书引用的名称
namespace: default # 指定了证书引用所在的命名空间
addresses: # 定义了一个或多个地址,用于接收流量
- value: "192.168.1.1" # 指定了 IP 地址的值
type: IPAddress # 指定了地址的类型
在此示例中,若未指定 addresses 字段,则对应实现的控制器负责将地址或主机名设置到 Gateway 之上。该地址用作网络端点,用于处理路由中定义的后端网络端点的流量。
Addresses:定义为此 Gateway 请求的网络地址。用于指定该 Gateway 可以通过哪些网络地址访问的,此字段非必填。Addresses 字段表示外部流量将使用的“Gateway 外部”的地址,该流量绑定到此网关的地址。这可以是外部负载均衡器或其他网络基础架构的 IP 地址或主机名,或者其他一些流量将被发送到的地址。
两个加密协议类型:
- Terminate:将加密的流量
解密
,并将明文流量
转发
到后端服务。这种模式需要在网关处配置证书和密钥,以便对客户端和服务器之间的流量进行加密和解密,确保数据安全性。
- Passthrough:将加密的流量
原样转发
到后端服务。这种模式不需要在网关处配置证书和密钥,因为 TLS 连接只在后端服务处终止。这种模式适用于需要将 TLS 流量直接传递到后端服务的场景,如需要对后端服务进行更细粒度的访问控制或流量监控的情况。
不同的监听器协议,支持不同的 TLS 模式和路由类型:
| 监听器协议 |
TLS 模式 |
路由类型 |
| TLS |
Passthrough |
TLSRoute |
| TLS |
Terminate |
TCPRoute |
| HTTPS |
Terminate |
HTTPRoute |
2.1.3 ReferenceGrant
ReferenceGrant 可用于在 Gateway API 中启用跨命名空间引用。特别的,Router 可能会将流量转发到其他命名空间中的后端,或者 Gateway 可能会引用另一个命名空间中的 Secret。

如果从其命名空间外部引用一个对象,则该对象的所有者必须创建一个 ReferenceGrant 资源以显式允许该引用,否则跨命名空间引用是无效的。ReferenceGrant 由两个列表组成,一个是引用来源的资源列表,另一个是被引用的资源列表。
- from 列表允许你指定可能引用 to 列表中描述的项目的资源的 group、kind、namespace。
- to 列表允许你指定可能被 from 列表中描述的项目引用的资源组和种类。命名空间在 to 列表中不是必需的,因为引用授予只能用于允许引用与引用授予相同的命名空间中的资源,每个 ReferenceGrant 仅支持一个 From 和 To 部分。
以下示例,显示命名空间 foo 中的 HTTP 路由如何引用命名空间 bar 中的服务。在此示例中,bar 命名空间中的引用授予明确允许从 foo 命名空间中的 HTTP 路由引用服务。
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cross-namespace-tls-gateway
namespace: gateway-api-example-ns1
spec:
gatewayClassName: istio
listeners:
- name: https
protocol: HTTPS
port: 443
hostname: "*.cai-inc.com"
tls:
mode: Terminate
certificateRefs:
- kind: Secret
group: ""
name: allow-ns1-gateways-to-ref-secrets
namespace: gateway-api-example-ns2
---
apiVersion: gateway.networking.k8s.io/v1
kind: ReferenceGrant
metadata:
name: allow-ns1-gateways-to-ref-secrets
namespace: gateway-api-example-ns2
spec:
from:
- group: gateway.networking.k8s.io
kind: Gateway
namespace: gateway-api-example-ns1
to:
- group: ""
kind: Secret
2.1.4 Route
一个 Gateway 可以包含一个或多个 Route 引用,每个 Route 都要绑定一个 Gateway。
这些 Route 的作用是将一个子集的流量引导到一个特定的服务上。
目前支持 4 种路由类型:HTTPRoute、TLSRoute、TCPRoute、GRPCRoute。
HTTPRoute 适用于多路复用 HTTP 或 HTTPS 请求,并使用 HTTP 请求进行路由或修改的场景,比如使用 HTTP Headers 头进行路由,url路径的重定向或者重写,灰度发布涉及权重等。
HTTPRoute 的配置示例如下:
apiVersion: gateway.networking.k8s.io/v1beta1
kind: HTTPRoute
metadata:
name: httproute-example
spec:
parentRefs: # 定义此路由要绑定到的 Gateway
- name: gateway-istio
hostnames:
- "zcy.cai-inc.com"
rules:
- matches: ## 前缀为 monitor 的服务转发到后端 monitor-center 的6099端口
- path:
type: PathPrefix
value: /monitor
# 指定后端服务的引用,它包含一个后端服务的列表,每个服务由名称和端口号组成
# 可以使用不同的负载均衡算法,将请求路由到后端服务的其中一个实例中,实现负载均衡
# 如果未指定后端列表,则规则不进行转发
backendRefs:
- name: monitor-center1 ## 90%的流量转发给monitor-center1
port: 6099
weight: 90
- name: monitor-center2
port: 6099
weight: 10
# 由一个或多个匹配条件组成,这些匹配条件可以基于HTTP请求的各种属性进行匹配
# (如请求method方法、path路径、headers头部、queryParams查询参数等)
# 从而确定哪些请求应该被路由到该规则对应的后端服务
- matches: ## 请求头包含 env=prod 前缀为 /api2/otel 的服务转发到 otel-dashboard 的7099
- headers: ## Exact 精确匹配,也可以使用支持 POSIX、PCRE 或正则表达式
- name: env
type: Exact
value: prod
path:
type: PathPrefix
value: "/api2/otel"
# 对传入请求进行更细粒度的控制,定义了必须在请求或响应生命周期中完成的处理步骤
# 例如修改请求的头部、转发请求到其他服务、将请求重定向到不同的 URL 等
# 它们由一组规则组成,每个规则都包含一个或多个过滤器
# 这些过滤器可以在请求被路由到后端服务之前或之后进行处理,以实现各种不同的功能
filters:
- type: RequestHeaderModifier ## 请求头添加 cookie=test1
requestHeaderModifier:
add:
- name: cookie
value: test1
# - type: RequestHeaderModifier ## 请求头修改已存在的 cookie=test2
# requestHeaderModifier:
# set:
# - name: cookie
# value: test2
# - type: RequestHeaderModifier ## 删除请求头 cookie
# requestHeaderModifier:
# remove: ["cookie"]
- type: ResponseHeaderModifier ## 添加响应头
responseHeaderModifier:
add:
- name: X-Header-Add-1
value: header-add-1
- name: X-Header-Add-2
value: header-add-2
- type: RequestRedirect
requestRedirect:
scheme: https
statusCode: 301
backendRefs:
- name: otel-dashboard
port: 7099
其中,关于 hostnames:
定义用于匹配 HTTP 请求的主机头的主机名列表,当请求匹配主机名时,将选择 HTTPRoute 执行请求路由。主机名是由 RFC 3986 定义的网络主机的完全限定域名,但要注意的是:不允许使用 IP;禁止使用端口;可以使用通配符标签(*)前缀,但通配符标签必须单独出现作为第一个标签;如果未指定主机名,则匹配所有绑定在 Gateway 上的路由。
当 Gateway 的 Listener 和 HTTPRoute 中都指定了主机名,只有有交集的主机名才会绑定到 Listener,没有绑定的 HTTPRoute 的 RouteParentStatus 中 Accepted 为 False 状态。
如果多个 HTTPRoute 指定重叠的主机名(例如,通配符匹配和精确匹配主机名重叠),则优先给予最长匹配主机名字符数的 HTTPRoute 的规则。
TLSRoute 用于 TLS 连接,通过 SNI 进行区分,它适用于希望使用 SNI 作为主要路由方法的地方,并且对 HTTP 等更高级的协议不感兴趣,连接的字节流不经任何检查就被代理到后端。它的配置和 HTTPRoute 类似,不同点在于 rules 的配置中只有 backendRefs, 没有 matches 和 filters,官网对 TLSRoute 介绍不多,可能建议 tls 统一配置在 Gateway 处,详情请看上面
3.1.2 Gateway
中的 tls 相关配置。
注:SNI(Server Name Indication)是 TLS 协议的一种扩展,用于在 TLS 握手过程中传递服务器的域名信息。
TCPRoute(和 UDPRoute)可以
根据目的 IP 地址、目的端口号和协议等匹配规则来确定流量,将 TCP 流量动态路由到符合应用需求的后端服务上
。
完成 TCPRoute 路由的配置,需要在绑定的 Gateway listeners.protocol 配置为 TCP。
Gateway 中的
listeners.name
与 TCPRoute 的
parentRefs.sectionName
绑定区分后端的服务 service。通过这种方式,每个 TCP 路由将自身绑定到网关上的不同端口,以便 Gateway.listeners.name --> TCPRoute.parentRefs.sectionName --> service 从集群外部获取端口 XXX 的流量。
它的配置和 TLSRoute 类似,与 HTTPRoute 相比 rules 的配置中只有 backendRefs,没有 matches 和 filters。
apiVersion: gateway.networking.k8s.io/v1beta1
kind: Gateway
metadata:
name: tcp-gateway
spec:
gatewayClassName: istio
listeners:
- name: foo # 与 TCPRoute sectionName 绑定
protocol: TCP # tcp 协议
port: 8080
allowedRoutes: # 绑定为 TCPRoute
kinds:
- kind: TCPRoute
- name: bar
protocol: TCP
port: 8090
allowedRoutes:
kinds:
- kind: TCPRoute
apiVersion: gateway.networking.k8s.io/v1alpha2
kind: TCPRoute
metadata:
name: tcp-app-1
spec:
parentRefs:
- name: tcp-gateway
sectionName: foo # 对应 Gateway 的 listeners.name
rules:
- backendRefs:
- name: foo-service
port: 6000
---
apiVersion: gateway.networking.k8s.io/v1alpha2
kind: TCPRoute
metadata:
name: tcp-app-2
spec:
parentRefs:
- name: tcp-gateway
sectionName: bar
rules:
- backendRefs:
- name: bar-service
port: 6000
GRPCRoute 用于路由 gRPC 请求,包括按主机名、gRPC 服务、gRPC 方法或 HTTP/2 头匹配请求的能力。
支持 GRPCRoute 的网关需要支持 HTTP/2,否则报错不支持的协议“UnsupportedProtocol”。
虽然可以通过 HTTPRoute 或自定义的 CRD 来路由 gRPC,但从长远来看,这会导致生态系统的碎片化。
gRPC 是一种业界广泛采用的流行 RPC 框架,该协议在 k8s 项目本身中被广泛地应用于许多接口,
由于 gRPC 在 k8s 项目和应用层网络中的重要性
,因此不允许过度细分,
强制规定使用 GRPCRoute 来路由 gRPC
。
支持 GRPC 路由的实现必须强制 GRPCRoute 和 HTTPRoute 之间 hostnames 的唯一性。
如果 HTTP 路由或 GRPC 路由类型的路由 A 附加到 Gateway Listener,并且该 Listener 已经绑定了其他类型的另一个路由 B,并且 A 和 B 的 hostnames 交集非空,则路由 A 不会实现,建议对 gRPC 和非 gRPC HTTP 流量使用不同的主机名。
GRPCRoute 与 HTTPRoute rules 规则基本一致,定义了基于条件匹配 matches、过滤器 filters 以及将请求转发到后端 backendRefs。不同点在于 GRPCRoute.rules.matches 只支持 method 和 headers,headers参数为数组类型,method 参数为非数组。method 和 headers 匹配只支持精确匹配 Exact 和正则匹配 RegularExpression,且不能包含 / 字符。GRPCRoute.rules.filters 中不支持 url 重定向以及重写。
注:RPC(Remote Procedure Call)即远程过程调用,是一种网络通信协议,用于实现分布式系统中不同计算机之间的函数或方法调用
apiVersion: gateway.networking.k8s.io/v1alpha2
kind: GRPCRoute
metadata:
name: grpcroute
spec:
parentRefs: # 绑定 Gateway
- name: gateway-istio
hostnames: # 绑定主机名
- my.example.com
rules:
- matches:
- method: # 包含 com.example.User.Login 方法且头部包含 version: "2"
service: com.example.User
method: Login
headers:
- type: Exact
name: version
value: "2"
backendRefs: # 不配置则不会转发
- name: foo-svc
port: 50051
- matches: # 包含 grpc.reflection.v1.ServerReflection 方法添加请求头 my-header:bar
- method:
service: grpc.reflection.v1.ServerReflection
filters:
- type: RequestHeaderModifier
requestHeaderModifier:
add:
- name: my-header
value: bar
backendRefs:
- name: bar-svc1
port: 50052
weight: 90
- name: bar-svc2
port: 50052
weight: 10
2.1.5 路由绑定
Gateway API 支持跨 Namespace 路由 Route,网关 Gateway 和路由 Route 可以部署到不同的命名空间中。
路由可以跨 Namespace 边界绑定到网关的能力
需要 Gateway 和 Route 双方协商同意
。Route 和 Gateway 资源具有内置的控制,以允许或限制它们之间如何相互选择。当 Route 绑定到 Gateway 时,代表应用在 Gateway 上配置了底层的负载均衡器或代理。
一个 Kubernetes 集群管理员在 Infra 命名空间中部署了一个名为 shared-gw 的 Gateway,供不同的应用团队使用,以便将其应用暴露在集群之外。团队 A 和团队 B(分别在命名空间 "A" 和 "B" 中)将他们的 Route 绑定到这个 Gateway。它们互不相识,
只要它们的 Route 规则互不冲突,就可以继续隔离运行
。团队 C 有特殊的网络需求(可能是性能、安全或关键性),他们需要
一个专门的 Gateway 来代理他们的应用到集群外
。团队 C 在 "C" 命名空间中部署了自己的 Gateway dedicated-gw,该 Gateway 只能由 "C" 命名空间中的应用使用。不同命名空间及 Gateway 与 Route 的绑定关系如下图所示:
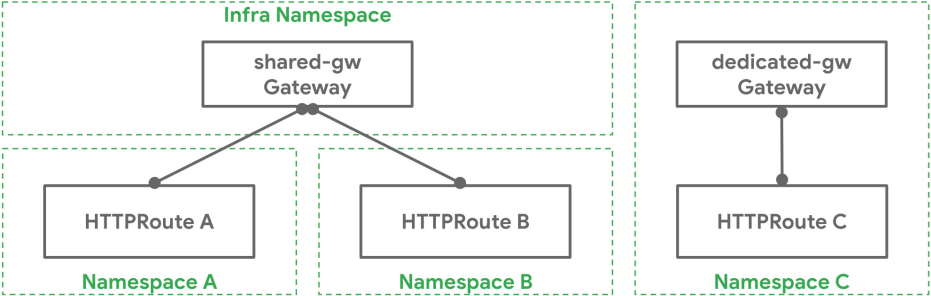
网关和路由的绑定是双向的:只有网关所有者和路由所有者都同意绑定才会成功。
这种双向关系存在的原因有两个:
- 路由所有者不想通过他们不知道的路径,过度暴露他们的应用程序。
- 网关所有者不希望某些应用程序或团队,在未经允许的情况下使用网关。例如,内部服务不应该通过互联网网关可访问。
网关支持管理路由来源约束,使用 listeners 字段限制可以附加的路由。
网关支持命名空间和路由类型作为附加约束,不符合附加约束的任何路由都无法附加到该网关上。
路由通过父引用字段 parentRefs 显式引用它们要附加到的网关。
这些共同创建了一个协议,使基础设施所有者和应用程序所有者能够独立定义应用程序如何通过网关公开,有效地降低了管理开销。如何将路由与网关绑定:
- 一对一:
网关和路由可以由一个所有者部署和使用,并具有一对一的关系。团队 C 就是一个例子。
- 一对多:
一个网关可以有许多路由与之绑定,这些路由由来自不同命名空间的不同团队所拥有。团队 A 和 B 就是这样的一个例子。
- 多对一:
路由也可以绑定到多个网关,允许一个路由同时控制不同 IP、负载均衡器或网络上的应用暴露。
将路由附加到网关的简单步骤:
- Route 需要在其 parentRefs 字段中引用 Gateway;
- Gateway 上至少有一个监听器允许其附加。
总之,
网关选择路由,路由控制它们的暴露
。当网关选择一个允许自己暴露的路由时,那么该路由将与网关绑定。当路由与网关绑定时,意味着它们的集体路由规则被配置在了由该网关管理的底层负载均衡器或代理服务器上。
2.1.6 路由选择
Gateway 根据 Route 元数据、Route 资源的种类、命名空间和标签来选择 Route。Route 实际上被绑定到 Gateway 中的监听器上,因此每个监听器都有一个 listeners.allowedRoutes 字段,它通过以下一个或多个标准来选择 Route:
- Kind:
网关监听器 allowedRoutes.kinds 只能选择单一类型的路由资源。可以是 HTTPRoute、TCPRoute 或自定义 Route 类型。
- Namespace:
Gateway 还可以通过 allowedRoutes.namespaces 字段控制可以从哪些 Namespace 中选择 Route。
其中,namespaces.from 支持三种可能的值:
- SameNamespace 是默认选项。只有与该网关相同的命名空间中的路由才会被选择。
- All 将选择来自所有命名空间的 Route。
- Selector 意味着该网关将选择由 Namespace 标签选择器选择的 Namespace 子集的 Route。当使用 Selector 时,那么 namespaces.selector 字段可用于指定标签选择器。All 或 SameNamespace 不支持该字段。
下面的 Gateway 将在集群中的所有 Namespace 中选择 otel: true 的所有 HTTPRoute 资源。
apiVersion: gateway.networking.k8s.io/v1beta1
kind: Gateway
metadata:
name: gatewayDemo
namespace: gateway-istio
spec:
gatewayClassName: istio
listeners:
- name: http
port: 80
protocol: HTTP
allowedRoutes:
kinds:
- kind: HTTPRoute
namespaces:
from: Selector
selector:
matchLabels:
otel: "true"
---
apiVersion: v1
kind: Namespace
metadata:
name: routeDemo-example
labels:
otel: "true"
---
# HTTPRoute
apiVersion: gateway.networking.k8s.io/v1beta1
kind: HTTPRoute
metadata:
name: routeDemo
namespace: routeDemo-example
spec:
parentRefs:
- kind: Gateway
name: gatewayDemo
namespace: gateway-istio
rules:
- backendRefs:
- name: otel
port: 7099
2.1.7 资源类型的组合,以及简单的请求数据流
GatewayClass、Gateway、xRoute 和 Service 的组合将定义一个可实现的负载均衡器。下图说明了不同资源之间的关系。

使用反向代理实现的网关的典型客户端/网关 API 请求流程如下所示:
客户端向 http://foo.example.com 发出请求
DNS 将域名解析为 Gateway 网关地址
反向代理在监听器上接收请求,并使用 Host Header 来匹配 HTTPRoute
(可选)反向代理可以根据 HTTPRoute 的匹配规则进行路由
(可选)反向代理可以根据 HTTPRoute 的过滤规则修改请求,即添加或删除 headers
最后,反向代理根据 HTTPRoute 的 forwardTo 规则,将请求转发给集群中的一个或多个对象,即服务。
2.2 面向角色特性
Gateway API 的面向角色特性就是,通过角色划分将各层规则配置关注点分离,实现规则配置上的解耦。
基础设施都是为了共享而建的
,共享基础设施有一个共同的挑战,那就是
如何为基础设施用户提供灵活性的同时还能被所有者控制
。Gateway API
通过
面向角色
的设计来实现这一目标
,通过
将资源对象分离
,实现配置上的解耦,可以
由不同的角色的人员来管理
,平衡了灵活性和集中控制,解决了入口网关创建与管理职责界限的划分。
不同角色的配合如下图:

GatewayClass 资源是集群统一部署的,由平台提供,后续才需要其他角色的介入,如下图:

一个
集群管理员(Cluster Operator)
创建了从 GatewayClass 派生的 Gateway 资源:foo。该 Gateway 对访问 foo.example.com 的流量进行了统一的 TLS 配置并设置了默认策略(Default Policies)。
在和集群管理员达成一致后,
负责存储的开发人员(Store Developer)
创建了一个 HTTPRoute,将访问 foo.example.com/store/ 的流量导入到 Store namespace 下的 foo-store 服务中,并且对这些流量进行了加权分发,将 90%的流量导入到 foo-store v1 中,另外 10%的流量导入到 foo-store v2 中。
另外一边,
负责网站的开发人员(Site Developer)
也创建了一个 HTTPRoute,将访问 foo.example.com/site/ 的流量导入到 Site namespace 下的 foo-site 服务中。
Store 和 Site 团队在他们自己的 namespaces 中运行,但是将他们的 Routes 绑定到同一个共享 Gateway,允许他们独立控制自己的路由逻辑。
这种用户模型在
为基础设施提供灵活性的同时也保证了对不同角色之间的控制
。
三、实现方案(略)
目前已经有很多 Gateway API 的控制器实现方案了,比如 Contour、Google Kubernetes Engine、Istio、Traefik 等等。
关于如何实现,本文将不再介绍,可参考以下参考链接。
参考:
https://cloud.tencent.com/developer/article/2321881
https://zhuanlan.zhihu.com/p/627229130
https://docs.youdianzhishi.com/k8s/network/gateway-api/
https://kubernetes.io/zh-cn/docs/concepts/services-networking/gateway/