大家好,我是痞子衡,是正经搞技术的痞子。今天痞子衡给大家介绍的是
瑞萨RA系列FSP固件库里的外设驱动
。
上一篇文章
《瑞萨RA8系列高性能MCU开发初体验》
,痞子衡带大家快速体验了一下瑞萨 MCU 开发三大件(开发环境e² studio、软件包FSP、评估板EK),其中软件包 FSP 为何不叫更通用的 SDK,痞子衡特地留了伏笔,今天就让我们分析一下这个 FSP 到底是什么来头?(本篇主要分析其中外设驱动部分)
一、固件包架构对比
我们尝试对比意法半导体、恩智浦以及瑞萨三家的固件包来看看它们的架构差异。
1.1 ST STM32Cube MCU Packages
首先来看在固件包生态上建立得比较早的意法半导体,它家固件包全称 STM32Cube MCU Packages,从下往上一共四层(MCU硬件、BSP&HAL驱动、Middleware、App),另外 CMSIS 地位与 Milddeware 平齐,说明意法认为 CMSIS 是相对通用的中间层代码。
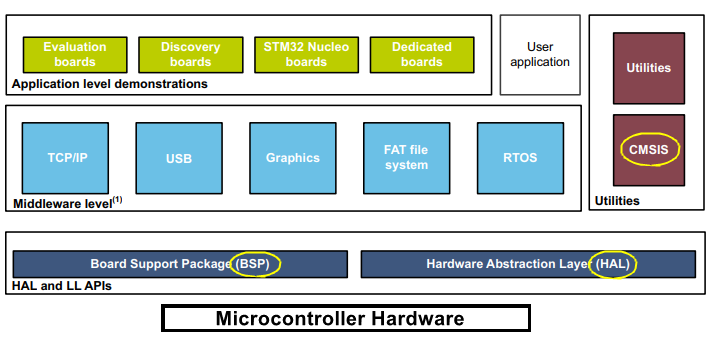
其中我们主要关注 BSP 和 HAL 驱动,BSP 即板级器件(比如 Codec、各种传感器等)相关的驱动,HAL 则是 MCU 片内外设驱动,
在意法架构里 BSP 和 HAL 是相同的层级
,但其实我们知道 BSP 功能也要基于 HAL 驱动来具体实现。
关于这里的 HAL 驱动,有必要多展开一些,最早期的时候意法半导体主推得是标准库(Standard Peripheral Libraries,简称 SPL),目前已经不再维护更新,现在主推 HAL 库(Hardware Abstraction Layer)和 LL 库(Low-Layer),所以架构图里 HAL 实际上是统指 HAL 库和 LL 库,三者关系简单理解就是 SPL = HAL + LL。
底层库文件:xxxMCU_ll_xxxPeripheral.c/h,提供的 API 主要是对于片内外设寄存器的单一设置操作,API 命名为 LL_PERIPHERAL_xxxAction()
原型示例:ErrorStatus LL_USART_Init(USART_TypeDef *USARTx, LL_USART_InitTypeDef *USART_InitStruct)
抽象层文件:xxxMCU_hal_xxxPeripheral.c/h,提供的 API 主要是对于片内外设具体功能的综合操作,API 命名为 HAL_PERIPHERAL_xxxFunc()
原型示例:HAL_StatusTypeDef HAL_USART_Init(USART_HandleTypeDef *husart)
标准库文件:xxxMCU_xxxPeripheral.c/h,提供的 API 同时包含上述 LL 和 HAL 功能(但是实现丰富度稍低),API 命名为 PERIPHERAL_xxxFunc/Action()
原型示例:void USART_Init(USART_TypeDef* USARTx, USART_InitTypeDef* USART_InitStruct)
1.2 NXP MCUXpresso-SDK
再来看痞子衡东家恩智浦半导体,固件包全称 MCUXpresso-SDK,从下往上一共五层(MCU硬件、CMSIS、HAL驱动、Middleware&BSP、App),这样的分层方式其实是 ARM 公司比较推荐的,与意法见解不同的是,这里 CMSIS 紧靠 MCU 硬件层,显然恩智浦认为 CMSIS 也是底层基础代码。
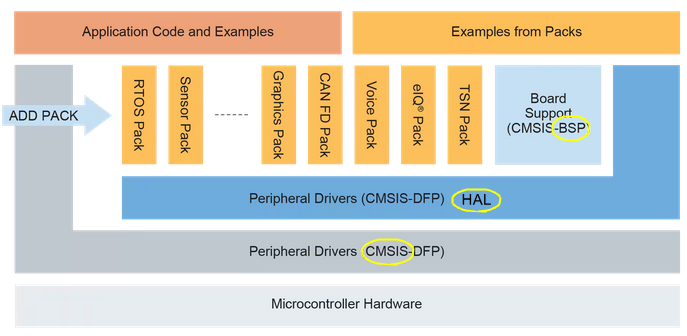
恩智浦架构里 BSP 和 HAL 不在同一层,清晰地表明了 BSP 是在 HAL 基础之上的代码
。恩智浦的 HAL 驱动比较像意法半导体的早期标准库 SPL,但是 API 功能丰富度远超 SPL。
抽象层文件:fsl_xxxPeripheral.c/h,提供的 API 同时包含片内外设寄存器的单一设置操作以及外设具体功能的综合操作,API 命名为 PERIPHERAL_xxxFunc/Action()
原型示例:status_t LPUART_Init(LPUART_Type *base, const lpuart_config_t *config, uint32_t srcClock_Hz);
1.3 Renesas RA FSP
最后来看瑞萨家的 FSP,没有表现出明显的层次结构,但是能看出
瑞萨架构里 BSP 和 HAL 不在同一层,且 BSP 在 HAL 之下
。这里的 BSP 也包含了 CMSIS,显然瑞萨认为 BSP 既包含了 MCU 内核相关基础硬件也包含板级器件硬件驱动。
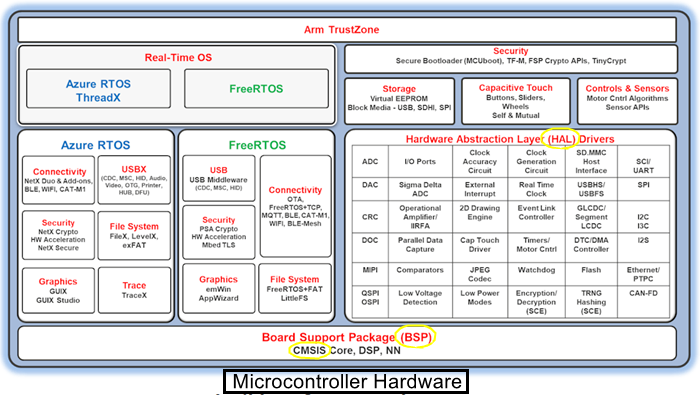
瑞萨 HAL 驱动设计得比较有意思,不同于意法以及恩智浦,它对于外设功能抽象更为看重(也可以理解为更面向对象),为此额外创建了一个 r_xxxModule_api.h 文件,里面定义了 API 原型,原型重点强调外设的通用功能行为,而忽略具体外设的操作细节和差异,这个我们下一节会细聊。
抽象层文件:r_xxxModule_api.h,定义统一的外设模块驱动 API 原型结构体,适用于同类功能的不同外设情况(比如 UART 功能既可能是 SCI_USART 也可能是 SCI_UART 或者其它)
r_xxxPeripheral.c/h,提供的 API 主要包含片内外设具体功能的综合操作,API 命名为 R_PERIPHERAL_xxxFunc()
原型示例:fsp_err_t R_SCI_B_UART_Open (uart_ctrl_t * const p_api_ctrl, uart_cfg_t const * const p_cfg)
二、FSP里的外设驱动结构
在上篇文章示例工程 lpm_ek_ra8m1_ep 里,我们发现有如下 ra 文件夹,这就是 FSP 包相关的源文件,我们结合具体源文件来分析:
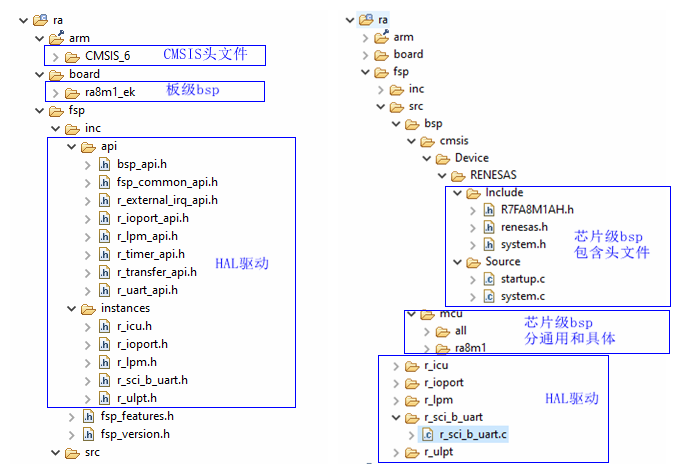
2.1 头文件与启动文件
首先在系统文件(头文件与启动文件)命名上,三家小有差异,不过差异最大的是型号头文件里的外设寄存器定义,这和后面的 HAL 驱动里代码实现息息相关。
|
文件类型
|
意法半导体
|
恩智浦半导体
|
瑞萨电子
|
| 系列头文件 |
stm32xxxx.h |
fsl_device_registers.h |
renesas.h |
| 型号头文件 |
xxxMcu.h |
xxxMCU.h |
xxxMCU.h |
| 启动文件 |
startup_xxxMcu.s |
startup_xxxMcu.s |
startup.c |
| 初始化文件 |
system_xxxMcu.c/h |
system_xxxMcu.c/h |
system.c/h |
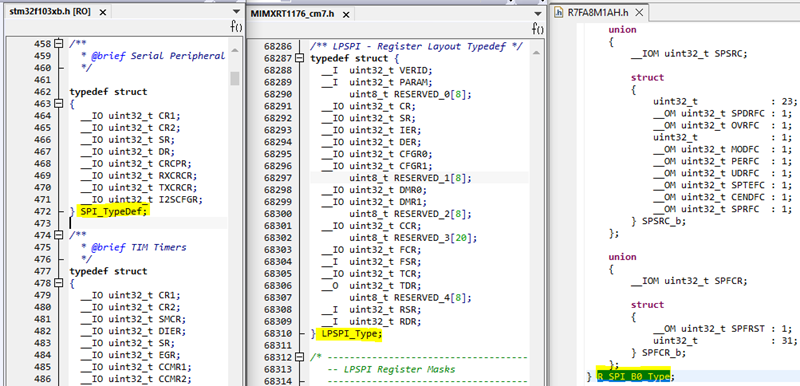
在头文件里的外设寄存器原型定义上,意法和恩智浦是一致的,每个寄存器均用一个 uint32_t 类型存储,而瑞萨则用联合体(union)来存储每个寄存器,这样不仅能整体访问该寄存器,还能按 bit field 访问寄存器中的具体功能位。
除此以外,三家均为外设寄存器的单/多 bit 功能位做了 mask 和 pos 定义便于代码做相关位操作。而为了便于对多 bit 功能位区域的赋值,恩智浦和意法还有额外定义(以达到瑞萨用 union 定义外设寄存器原型的效果)。
xxxPERIPHERAL_xxxREGISTER_xxxFunc_Msk/MASK
xxxPERIPHERAL_xxxREGISTER_xxxFunc_Pos/SHIFT
// 恩智浦额外定义了如下宏用于赋值多 bit 功能位区域
xxxPERIPHERAL_xxxREGISTER_xxxFunc()
// 意法则直接用多个宏来辅助置位多 bit 功能位区域的每一位
xxxPERIPHERAL_xxxREGISTER_xxxFunc
xxxPERIPHERAL_xxxREGISTER_xxxFunc_0
xxxPERIPHERAL_xxxREGISTER_xxxFunc_1
...
2.2 HAL驱动文件
关于 HAL 驱动本身代码结构部分,我们主要分析三家 API 第一个形参定义即可知主要差别,其中恩智浦和意法 LL 库均是指向外设原型结构体的指针,而意法 HAL 库和瑞萨则是指向自定义外设控制块的指针,前者偏底层,后者偏应用层。
。
|
参数
|
意法半导体
|
恩智浦半导体
|
瑞萨电子
|
| 第一个 |
LL库:PERIPHERAL_TypeDef *
HAL库:PERIPHERAL_HandleTypeDef * |
PERIPHERAL_Type * |
module_ctrl_t * const |
前面痞子衡说了瑞萨多了一个 r_xxxModule_api.h 文件,我们就以 SCI 外设为例,其对应 r_uart_api.h 文件,该文件里定义了如下标准 API 动作集,这些动作不太像一般的外设驱动函数名(比如 init, deinit 等),更像是应用层动作。
/** Shared Interface definition for UART */
typedef struct st_uart_api
{
fsp_err_t (* open)(uart_ctrl_t * const p_ctrl, uart_cfg_t const * const p_cfg);
fsp_err_t (* read)(uart_ctrl_t * const p_ctrl, uint8_t * const p_dest, uint32_t const bytes);
fsp_err_t (* write)(uart_ctrl_t * const p_ctrl, uint8_t const * const p_src, uint32_t const bytes);
fsp_err_t (* baudSet)(uart_ctrl_t * const p_ctrl, void const * const p_baudrate_info);
fsp_err_t (* infoGet)(uart_ctrl_t * const p_ctrl, uart_info_t * const p_info);
fsp_err_t (* communicationAbort)(uart_ctrl_t * const p_ctrl, uart_dir_t communication_to_abort);
fsp_err_t (* callbackSet)(uart_ctrl_t * const p_ctrl, void (* p_callback)(uart_callback_args_t *),
void const * const p_context, uart_callback_args_t * const p_callback_memory);
fsp_err_t (* close)(uart_ctrl_t * const p_ctrl);
fsp_err_t (* readStop)(uart_ctrl_t * const p_ctrl, uint32_t * remaining_bytes);
} uart_api_t;
而在 r_sci_b_uart.c 文件里,将基于 SCI 外设实现的 UART 驱动函数对 uart_api_t 做了实例化,这样上层应用可以仅调用 uart_api_t 里的接口实现具体功能,而不必在意这些接口具体由哪个类型的外设来实现的。这样设计的好处是便于代码跨外设(跨MCU),移植起来方便,缺点是限制了 API 丰富度,难以展现外设间的差异化特性。
/* UART on SCI HAL API mapping for UART interface */
const uart_api_t g_uart_on_sci_b =
{
.open = R_SCI_B_UART_Open,
.close = R_SCI_B_UART_Close,
.write = R_SCI_B_UART_Write,
.read = R_SCI_B_UART_Read,
.infoGet = R_SCI_B_UART_InfoGet,
.baudSet = R_SCI_B_UART_BaudSet,
.communicationAbort = R_SCI_B_UART_Abort,
.callbackSet = R_SCI_B_UART_CallbackSet,
.readStop = R_SCI_B_UART_ReadStop,
};
至此,瑞萨RA系列FSP固件库里的外设驱动痞子衡便介绍完毕了,掌声在哪里~~~
欢迎订阅
文章会同时发布到我的
博客园主页
、
CSDN主页
、
知乎主页
、
微信公众号
平台上。
微信搜索"
痞子衡嵌入式
"或者扫描下面二维码,就可以在手机上第一时间看了哦。