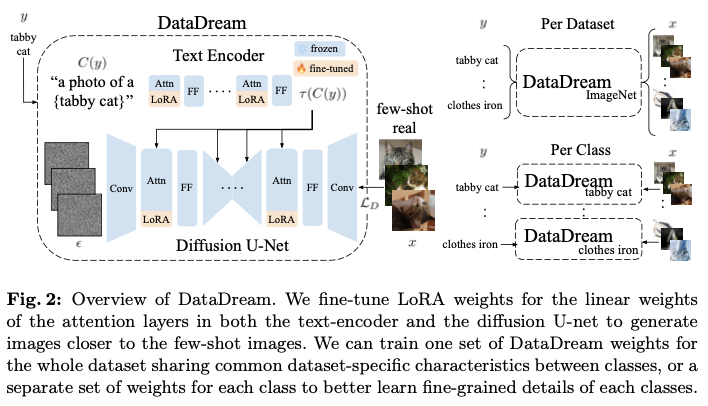
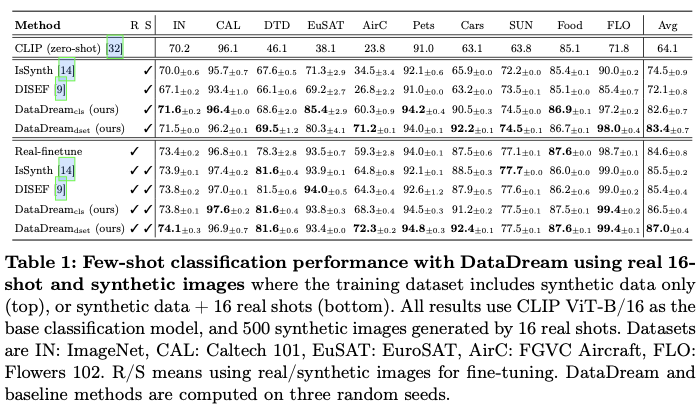
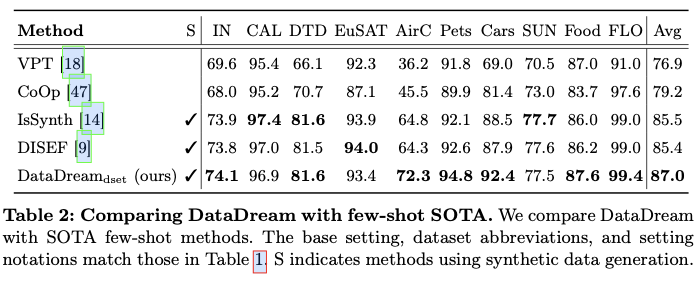
【设计模式】适配器模式
设计模式
一、介绍
适配器模式是一种结构型设计模式, 它能使接口不兼容的对象能够相互合作。
适配器可担任两个对象间的封装器,它会接收对于一个对象的调用,并将其转换为另一个对象可识别的格式和接口。
适配器模式在 PHP 代码中很常见。 基于一些遗留代码的系统常常会使用该模式。 在这种情况下, 适配器让遗留代码与现代的类得以相互合作。
应用场景:
(1)当你希望使用某个类,但是其接口与其他代码不兼容时,可以使用适配器类。
(2)如果您需要复用一些类,他们处于同一个继承体系,并且他们又有了额外的一些共同的方法,但是这些共同的方法不是所有在这一继承体系中的子类所具有的共性。
二、优缺点
优点:
- 单一职责原则:你可以将接口或数据转换代码从程序主要业务逻辑中分离。
- 开闭原则:只要客户端代码通过客户端接口与适配器进行交互, 你就能在不修改现有客户端代码的情况下在程序中添加新类型的适配器。
缺点:
- 代码整体复杂度增加,因为需要新增一系列接口和类。
三、核心结构
Adapter(适配器):最主要的就是这个适配器类,用于适配、扩展功能或接口。
四、代码实现
1、应用场景1
当你希望使用某个类,但是其接口与其他代码不兼容时,可以使用适配器类。
例如:有一台电脑显示器本身是VGA的数据线,但现在你手里只有HDMI的数据线,这个时候只有有个适配器(转接头)就可以使用。
(1)LcdInterface类本身相当于电脑显示屏,vga()方法相当于电脑显示屏自带的vga格式的接口
<?php/**
* Created by PhpStorm
* Author: fengzi
* Date: 2024/8/1
* Time: 15:47*/namespace app\admin\service\mode\adapter\other;/**
* LcdInterface接口类本身相当于电脑显示屏
* vga()方法相当于电脑显示屏自带的vga格式的接口*/ interfaceLcdInterface
{public functionvga();
}
(2)适配器(转接头)
<?php/**
* Created by PhpStorm
* Author: fengzi
* Date: 2024/8/1
* Time: 15:54*/namespace app\admin\service\mode\adapter\other;/**
* 适配器(转接头)*/ class Adapter implementsLcdInterface
{private NewDataCable $chinaPlug;public function __construct(NewDataCable $chinaPlug) {$this->chinaPlug = $chinaPlug;
}/**
* 使用适配器,将HDMI接口转换为VGA格式
* 相当于显示器还是使用VGA接口,但是通过适配器,将HDMI接口转换为VGA接口
* @return void
* @Author: fengzi
* @Date: 2024/10/11 14:20*/ public functionvga()
{//TODO: Implement plug120V() method. $this->chinaPlug->hdmi();echo '使用适配器,将HDMI接口转换为VGA格式' . PHP_EOL;
}
}
(3)新的数据线类,支持HDMI接口。
<?php/**
* Created by PhpStorm
* Author: fengzi
* Date: 2024/8/1
* Time: 15:50*/namespace app\admin\service\mode\adapter\other;/**
* 新的数据线类,支持HDMI接口*/ classNewDataCable
{public functionhdmi() {echo "HDMI接口" . PHP_EOL;
}
}
(4)调用方式
<?php/**
* Created by PhpStorm
* Author: fengzi
* Date: 2024/7/30
* Time: 11:29*/namespace app\admin\controller\mode\adapter;useapp\admin\service\mode\adapter\other\Adapter;useapp\admin\service\mode\adapter\other\NewDataCable;classAdapterController
{/**
* 当你希望使用某个类,但是其接口与其他代码不兼容时,可以使用适配器类。
* @return void
* @Author: fengzi
* @Date: 2024/10/10 15:41*/ public functionchange()
{$adapter = new Adapter(newNewDataCable());
$adapter->vga();
dd('转换结束,可以使用');
}
}
(5)结果展示

2、应用场景2
如果您需要复用一些类,他们处于同一个继承体系,并且他们又有了额外的一些共同的方法,但是这些共同的方法不是所有都在这一继承体系中的子类所具有的共性。
例如:有一个相同类型的类文件,里面有你要用的方法,但又不全面。这个时候就可以使用适配器继承老的接口类,再去实现没有的方法后去使用。
(1)公共的计算器接口类
<?php/**
* Created by PhpStorm
* Author: fengzi
* Date: 2024/7/30
* Time: 11:30*/namespace app\admin\service\mode\adapter;/**
* 计算器的接口类*/ interfaceCalculator
{/**
* 加法
* @param string $a 加数
* @param string $b 加数
* @param int|null $scale 小数点后保留位数
* @return mixed
* @Author: fengzi
* @Date: 2024/7/30 11:37*/ public function add(string $a, string $b, ?int $scale=null);/**
* 减法
* @param string $minuend 被减数
* @param string $subtrahend 减数
* @param int|null $scale 小数点后保留位数
* @return mixed
* @Author: fengzi
* @Date: 2024/7/30 11:39*/ public function subtract(string $minuend, string $subtrahend, ?int $scale=null);/**
* 乘法
* @param string $a 乘数
* @param string $b 乘数
* @param int|null $scale 小数点后保留位数
* @return mixed
* @Author: fengzi
* @Date: 2024/7/30 11:41*/ public function multiply(string $a, string $b, ?int $scale=null);/**
* 除法
* @param string $dividend 被除数
* @param string $divisor 除数
* @param int|null $scale 小数点后保留位数
* @return mixed
* @Author: fengzi
* @Date: 2024/7/30 11:44*/ public function divide(string $dividend, string $divisor, int $scale=null);
}
(2)公共接口类的具体实现
<?php/**
* Created by PhpStorm
* Author: fengzi
* Date: 2024/7/30
* Time: 11:31*/namespace app\admin\service\mode\adapter;/**
* 简单的计算类*/ class SimpleCalculator implementsCalculator
{/**
* 加法
* @param string $a 加数
* @param string $b 加数
* @param int|null $scale 小数点后保留位数
* @return string
* @Author: fengzi
* @Date: 2024/7/30 11:37*/ public function add(string $a, string $b, int $scale=null): string{//TODO: Implement add() method. return bcadd($a, $b, $scale);
}/**
* 减法
* @param string $minuend 被减数
* @param string $subtrahend 减数
* @param int|null $scale 小数点后保留位数
* @return string
* @Author: fengzi
* @Date: 2024/7/30 11:39*/ public function subtract(string $minuend, string $subtrahend, ?int $scale=null): string{//TODO: Implement subtract() method. return bcsub($minuend, $subtrahend, $scale);
}/**
* 乘法
* @param string $a 乘数
* @param string $b 乘数
* @param int|null $scale 小数点后保留位数
* @return string
* @Author: fengzi
* @Date: 2024/7/30 11:41*/ public function multiply(string $a, string $b, int $scale=null): string{//TODO: Implement multiply() method. return bcmul($a, $b, $scale);
}/**
* 除法
* @param string $dividend 被除数
* @param string $divisor 除数
* @param int|null $scale 小数点后保留位数
* @return string
* @throws \Exception
* @Author: fengzi
* @Date: 2024/7/30 11:44*/ public function divide(string $dividend, string $divisor, int $scale=null): string{//TODO: Implement divide() method. if ($divisor == 0) {throw new \Exception("除数不能为零");
}return bcdiv($dividend, $divisor, $scale);
}
}
(3)继承公共接口类后扩展了其他方法的接口类
<?php/**
* Created by PhpStorm
* Author: fengzi
* Date: 2024/7/30
* Time: 11:36*/namespace app\admin\service\mode\adapter;/**
* 高级计算类*/ interface AdvancedCalculator extendsCalculator
{/**
* 指数
* @param mixed $base 底数
* @param mixed $exponent 指数
* @return mixed
* @Author: fengzi
* @Date: 2024/7/30 11:53*/ public function power(mixed $base, mixed $exponent);/**
* 平方根
* @param float $number
* @return mixed
* @Author: fengzi
* @Date: 2024/7/30 11:55*/ public function squareRoot(float $number);
}
(4)适配器适配所有方法
<?php/**
* Created by PhpStorm
* Author: fengzi
* Date: 2024/7/30
* Time: 11:59*/namespace app\admin\service\mode\adapter;/**
* 适配器*/ class CalculatorAdapter implementsAdvancedCalculator
{private Calculator $simpleCalculator;public function __construct(SimpleCalculator $simpleCalculator)
{$this->simpleCalculator = $simpleCalculator;
}/**
* 指数运算
* @param mixed $base
* @param mixed $exponent
* @return float|int|mixed|object
* @Author: fengzi
* @Date: 2024/10/11 14:51*/ public function power(mixed $base, mixed $exponent)
{//TODO: Implement power() method. return pow($base, $exponent);
}/**
* 平方根
* @param $number
* @return float|mixed
* @Author: fengzi
* @Date: 2024/10/11 14:52*/ public function squareRoot($number)
{//TODO: Implement squareRoot() method. return sqrt($number);
}/**
* 加法
* @param string $a
* @param string $b
* @param int|null $scale
* @return mixed|string
* @Author: fengzi
* @Date: 2024/10/11 14:52*/ public function add(string $a, string $b, ?int $scale = null)
{//TODO: Implement add() method. return $this->simpleCalculator->add($a, $b, $scale);
}/**
* 减法
* @param string $minuend
* @param string $subtrahend
* @param int|null $scale
* @return mixed|string
* @Author: fengzi
* @Date: 2024/10/11 14:52*/ public function subtract(string $minuend, string $subtrahend, ?int $scale = null)
{//TODO: Implement subtract() method. return $this->simpleCalculator->subtract($minuend, $subtrahend, $scale);
}/**
* 乘法
* @param string $a
* @param string $b
* @param int|null $scale
* @return mixed|string
* @Author: fengzi
* @Date: 2024/10/11 14:52*/ public function multiply(string $a, string $b, ?int $scale = null)
{//TODO: Implement multiply() method. return $this->simpleCalculator->multiply($a, $b, $scale);
}/**
* 除法
* @param string $dividend
* @param string $divisor
* @param int|null $scale
* @return mixed|string
* @throws \Exception
* @Author: fengzi
* @Date: 2024/10/11 14:53*/ public function divide(string $dividend, string $divisor, int $scale = null)
{//TODO: Implement divide() method. return $this->simpleCalculator->divide($dividend, $divisor, $scale);
}
}
(5)适配器调用方式
<?php/**
* Created by PhpStorm
* Author: fengzi
* Date: 2024/7/30
* Time: 11:29*/namespace app\admin\controller\mode\adapter;useapp\admin\service\mode\adapter\CalculatorAdapter;useapp\admin\service\mode\adapter\SimpleCalculator;classAdapterController
{public functionindex()
{$calculatorAdapter = new CalculatorAdapter(newSimpleCalculator());$res = $calculatorAdapter->squareRoot(4);
dd($res);
}
}
(6)结果展示