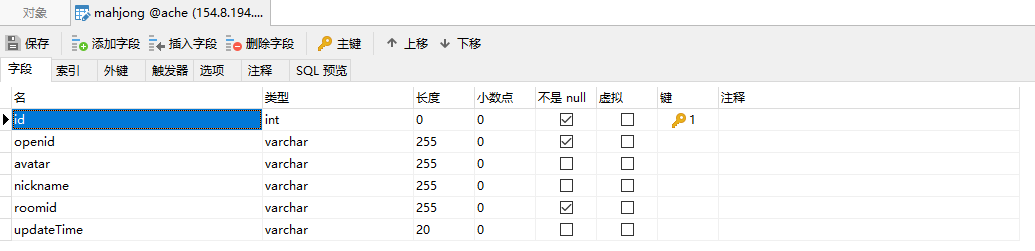
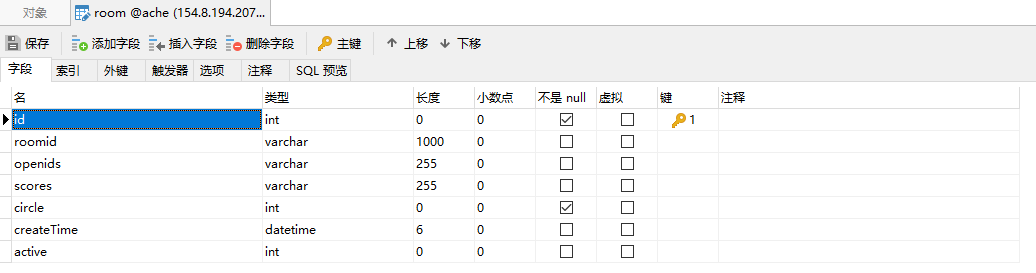
AI实战篇:Spring AI + 混元 手把手带你实现企业级稳定可部署的AI业务智能体
前言
在之前的内容中,我们详细讲解了Spring AI的基础用法及其底层原理。如果还有小伙伴对此感到困惑,欢迎参考下面这篇文章,深入学习并进一步掌握相关知识:
https://www.cnblogs.com/guoxiaoyu/p/18441709
今天,我们将重点关注AI在实际应用中的落地表现,特别是Spring AI如何能够帮助企业实现功能优化以及推动AI与业务的深度融合。我们将以当前大厂广泛追逐的智能体赛道为切入点,探讨其在实际场景中的应用。考虑到许多同学可能已经接触过智能体,以这一主题作为讨论的基础,能够更有效地帮助大家理解相关概念和技术的实际操作与效果。
因此,在本章节中,我们将以智能体为出发点,带领大家轻松实现一个本地稳定且可部署的智能体解决方案。在这一过程中,我将详细介绍每一个步骤,确保大家能够顺利跟上。此外,在章节的最后,我会根据我的理解,分析这一方案与现有智能体的优缺点,以帮助大家全面了解不同选择的利弊。
准备工作
当然,Spring AI集成了许多知名公司的接口实现。如果你真的想使用OpenAI的接口,可以考虑国内的混元API。混元API兼容OpenAI的接口规范,这意味着你可以直接使用OpenAI官方提供的SDK来调用混元的大模型。这一设计大大简化了迁移过程,你只需将base_url和api_key替换为混元相关的配置,而无需对现有应用进行额外修改。这样,你就能够无缝地将您的应用切换到混元大模型,享受到强大的AI功能和支持。
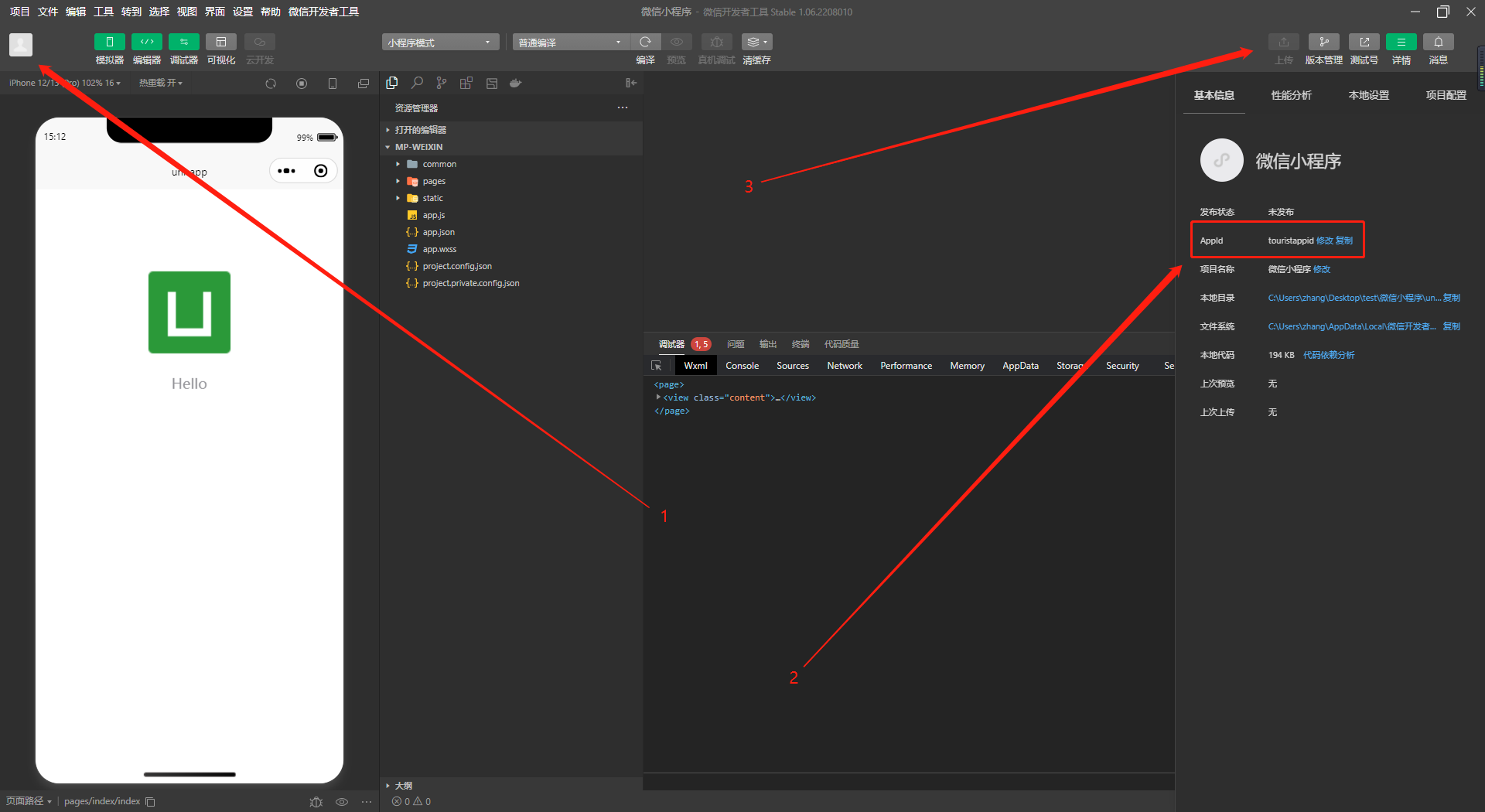
申请API KEY
大家完全不必担心,经过我亲自测试,目前所有接口都能够正常兼容,并且没有发现任何异常或问题。可以通过以下链接申请:
混元API申请地址
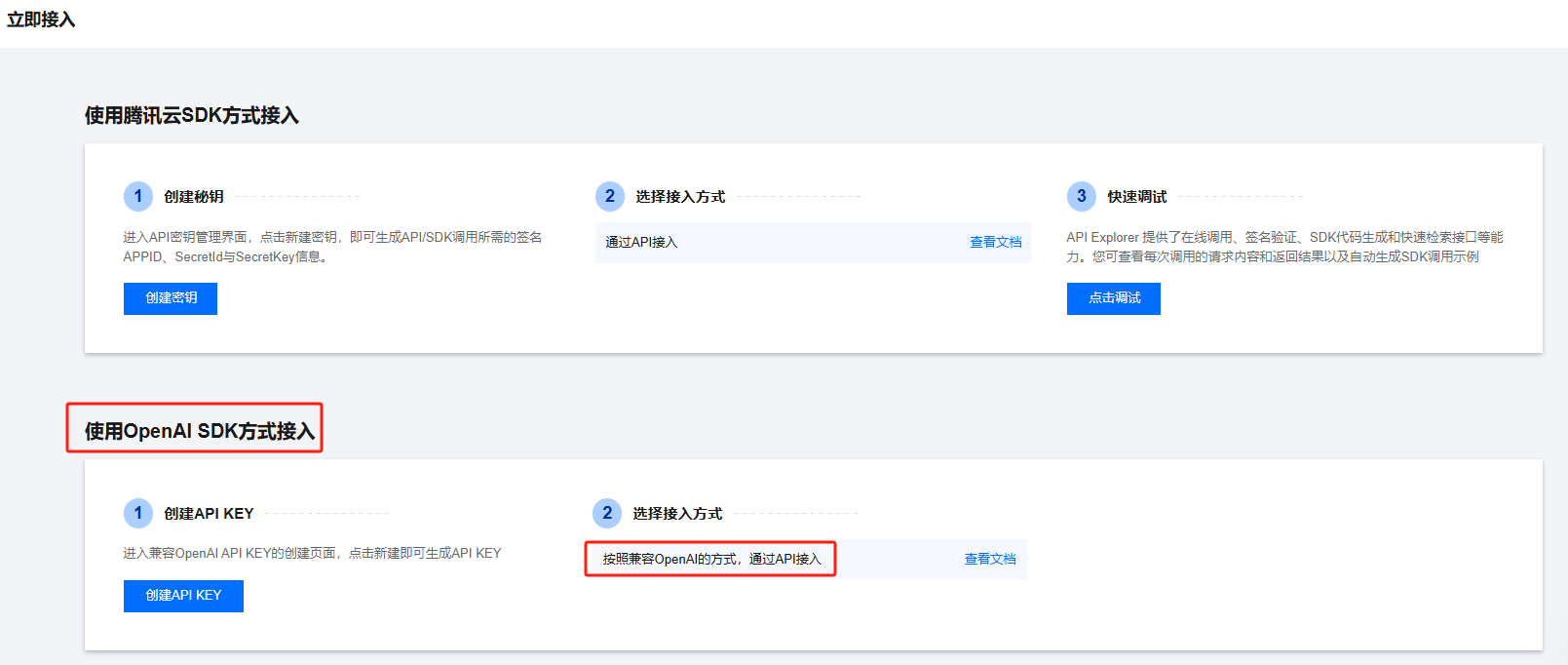
请确保在您个人的账户下申请相关的API KEY。
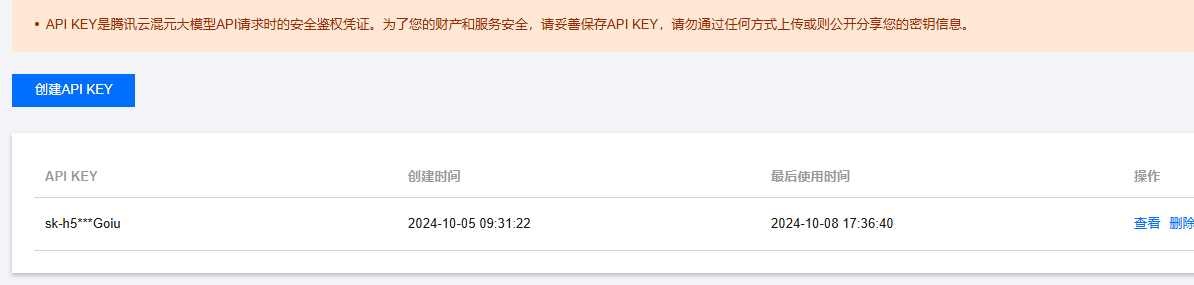
请务必妥善保存您的API KEY信息,因为在后续使用过程中,这一信息将会变得非常重要。
对接文档
在这里,了解一些注意事项并不是强制性的,因为我们并不需要直接对接混元(Hunyuan)的接口。实际上,我们可以在Spring AI中直接使用兼容OpenAI的接口,这样能够大大简化我们的操作流程。如果您有兴趣深入了解相关的API文档,可以自行查找接口文档地址,里面有详尽的说明和指导:
API接口文档
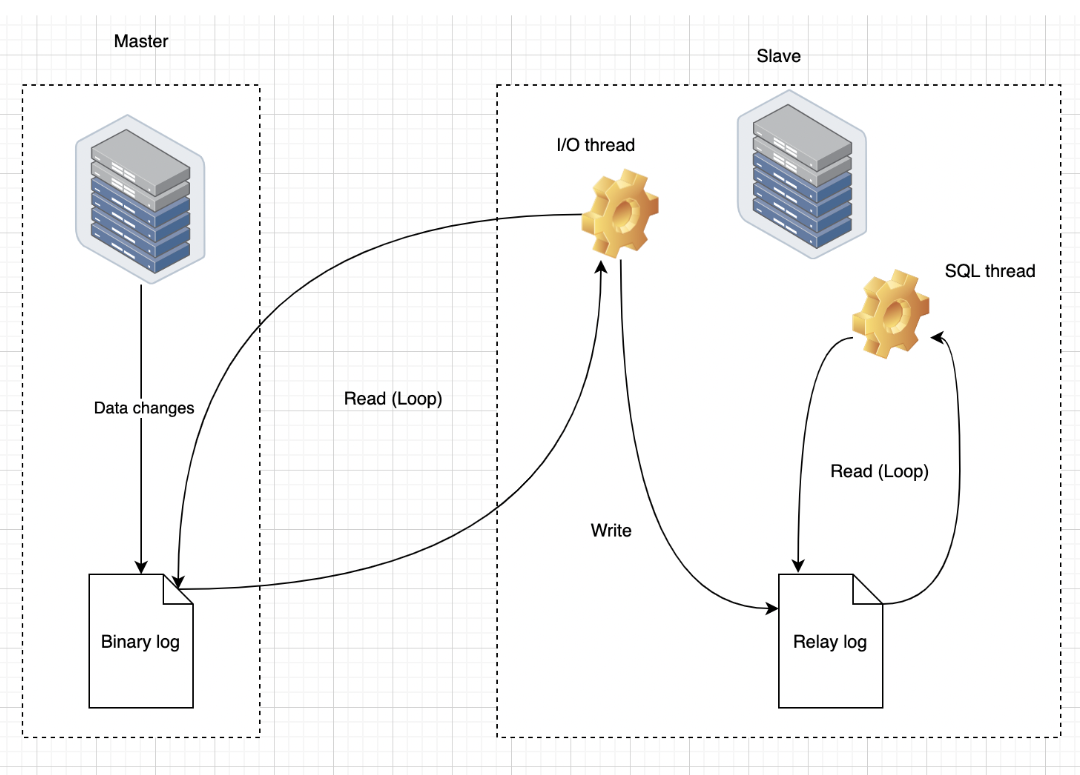
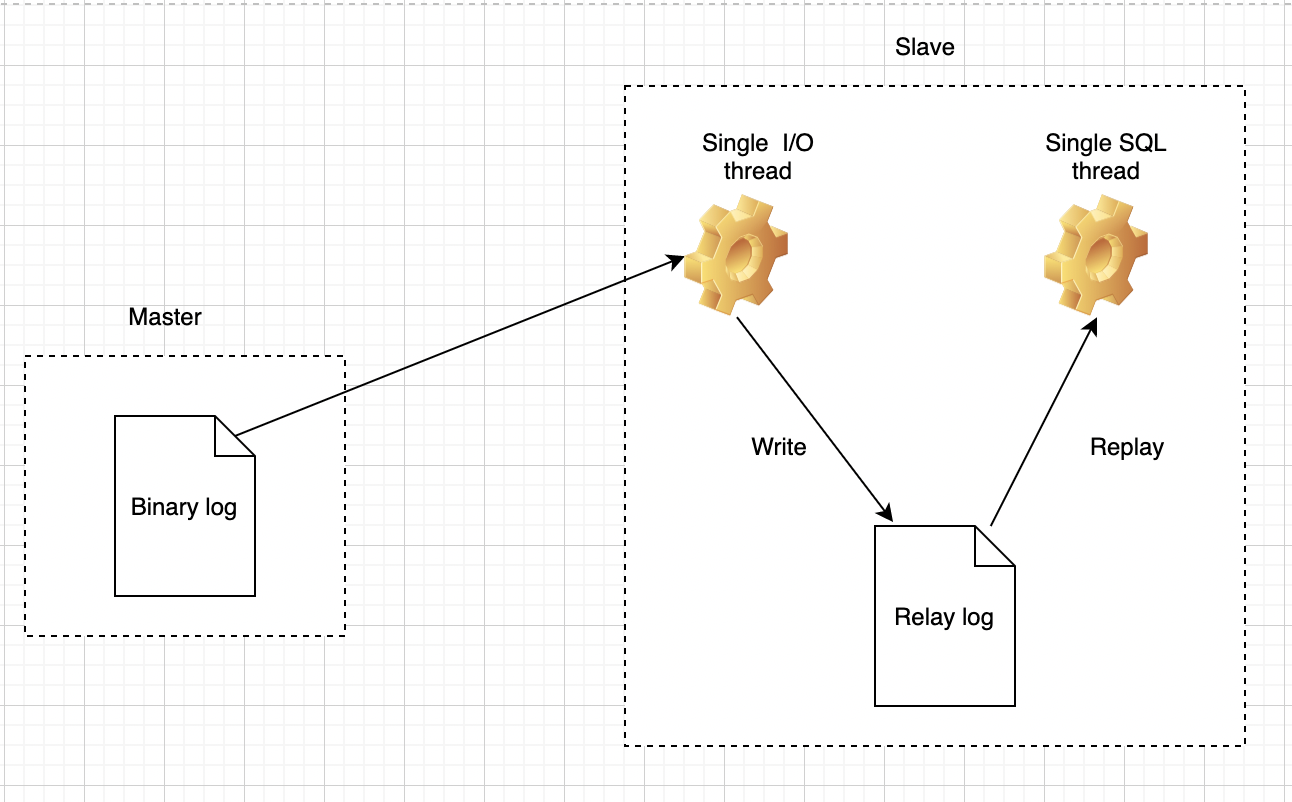
请大家特别注意,由于智能体在运行时需要调用相关的插件或工作流,因此支持函数回调的模型仅限于以下三个。这意味着,除了这三个模型之外,其他模型都不具备这一支持功能。请确保在选择模型时考虑这一点。

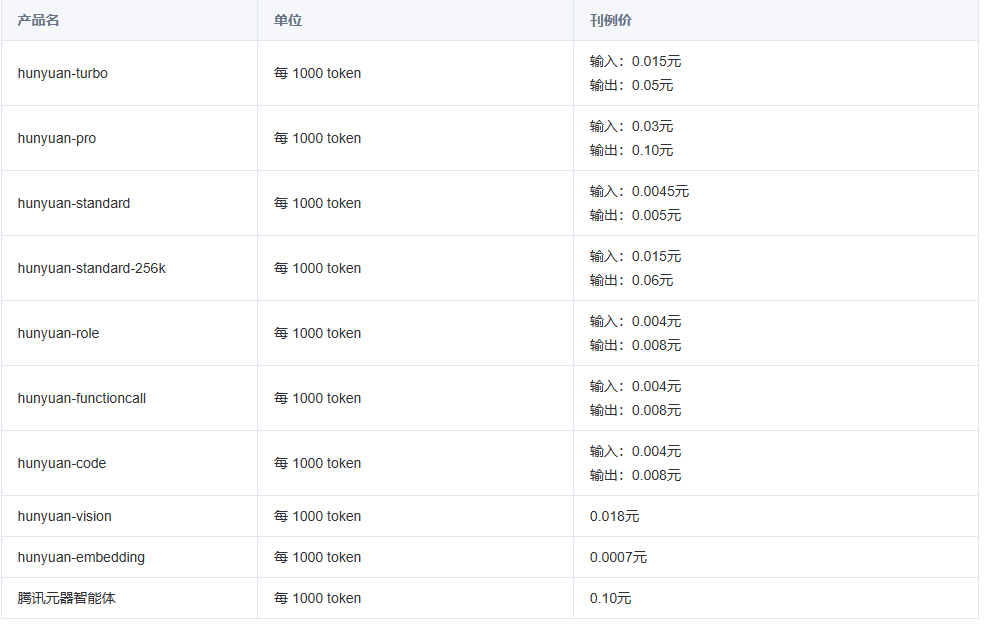
请大家留意,目前混元尚未推出预付费的大模型资源包,用户只能进行并发包的预购。有关计费详情,请参见下方图示。
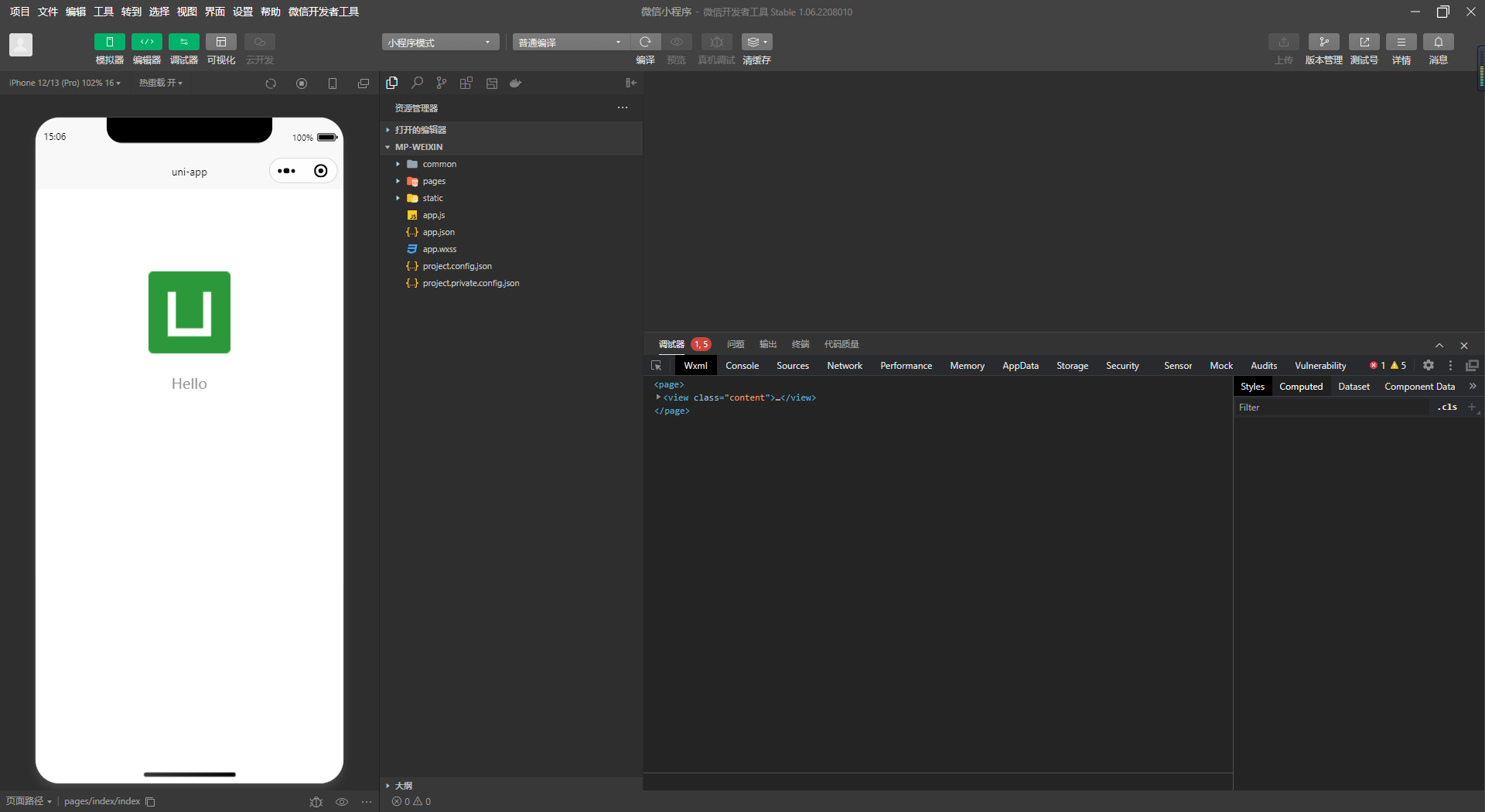
项目配置
接下来,我们将继续使用之前的 Spring AI 演示项目,并对其进行必要的修改。具体需要调整的 Maven POM 依赖项如下所示:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
如图所示,在我第一次配置文件时选择了使用 functioncall 模型,因为它的成本相对较低。然而,后来我发现该模型在对系统提示词的识别上表现并不理想,后面我都换成了pro模型,大家可以根据自己的具体需求和预算做出相应的选择。
functioncall对提示词不敏感但是对函数回调的结果可以很好的解析,pro对提示词敏感但是函数回调的结果他不直接回答,一直输出planner内容但就是不回复用户。后面会有详细说明。

application.properties
文件用于全局配置,所有的 ChatClient 都会遵循这一设置。这样做的一个显著好处是,开发人员在代码层面无需进行任何修改,只需在 Maven 的 POM 文件中更改相应的依赖项,即可轻松切换到不同的 AI 大模型厂商。这种灵活性不仅提高了项目的可维护性,还方便了模型的替换与升级。
Spring AI 智能体构建
现在,假设你已经完成了所有的准备工作,我们可以开始构建属于自己的智能体。首先,我们将专注于单独定制配置参数。之前提到过,application.properties 文件是全局设置,适用于所有的 ChatClient,但每个模型实际上都有自己特定的领域和应用场景。因此,我们首先需要配置如何为每个接口进行个性化定制,以确保模型的表现更加贴合实际的业务需求。
个性化配置模型
普通调用
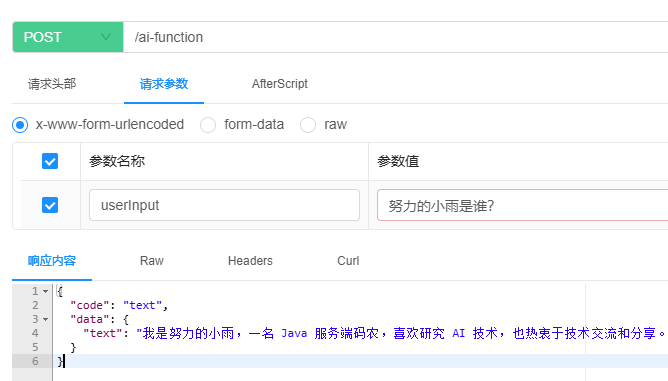
首先,让我们来观察在正常情况下代码应该如何编写:
@PostMapping("/ai-function")
ChatDataPO functionGenerationByText(@RequestParam("userInput") String userInput) {
String content = this.myChatClientWithSystem
.prompt()
.system("你是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。热爱技术交流与分享,对开源社区充满热情。")
.user(userInput)
.advisors(messageChatMemoryAdvisor)
.functions("CurrentWeather")
.call()
.content();
log.info("content: {}", content);
ChatDataPO chatDataPO = ChatDataPO.builder().code("text").data(ChildData.builder().text(content).build()).build();;
return chatDataPO;
}
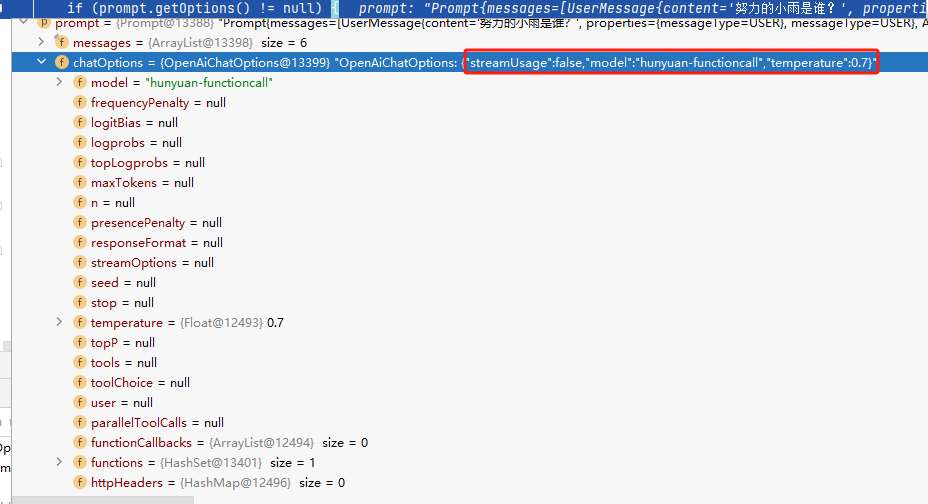
如图所示,在我们发起请求之前,如果提前设置一个断点,我们就能够在这一时刻查看到
chatOptions
参数,这个参数代表了我们默认的配置设置。因此,我们的主要目标就是在发送请求之前,探讨如何对
chatOptions
参数进行有效的修改。
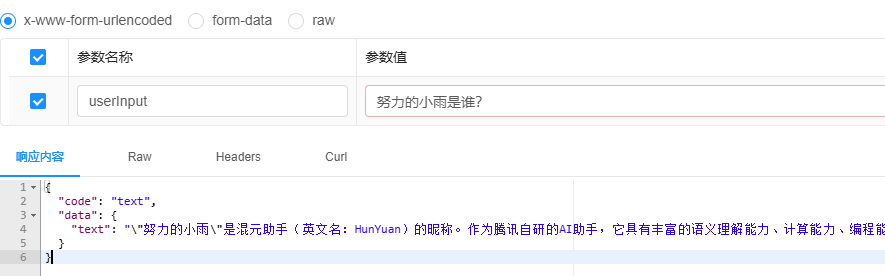
在对提示词进行测试的过程中,我们发现
functioncall
模型对于
system
提示词的响应效果并不显著,似乎没有发挥出预期的作用。然而,这个模型的一个显著优点是它支持函数回调功能(在前面的章节中已经详细讲解过),此外,与
pro
模型相比,
functioncall
模型的使用费用也相对较低,这使得它在某些情况下成为一个更具成本效益的选择。
特殊调用
为了使模型的回复更加贴合提示词的要求,我们可以对模型进行单独配置。如果你希望对某一个特定方法进行调整,而不是采用像 application.properties 中的全局设置,那么可以通过自行修改相应的参数来实现。具体的配置方法如下所示:
//省略重复代码
OpenAiChatOptions openAiChatOptions = OpenAiChatOptions.builder()
.withModel("hunyuan-pro").withTemperature(0.5f).build();
String content = this.myChatClientWithSystem
.prompt()
.system("你是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。热爱技术交流与分享,对开源社区充满热情。")
.user(userInput)
.options(openAiChatOptions)
.advisors(messageChatMemoryAdvisor)
//省略重复代码
}
在此,我们只需简单地配置相关的选项即可完成设置。接下来,我们可以在断点的部分检查相关的配置,以确保这些设置已经生效并正常运行。
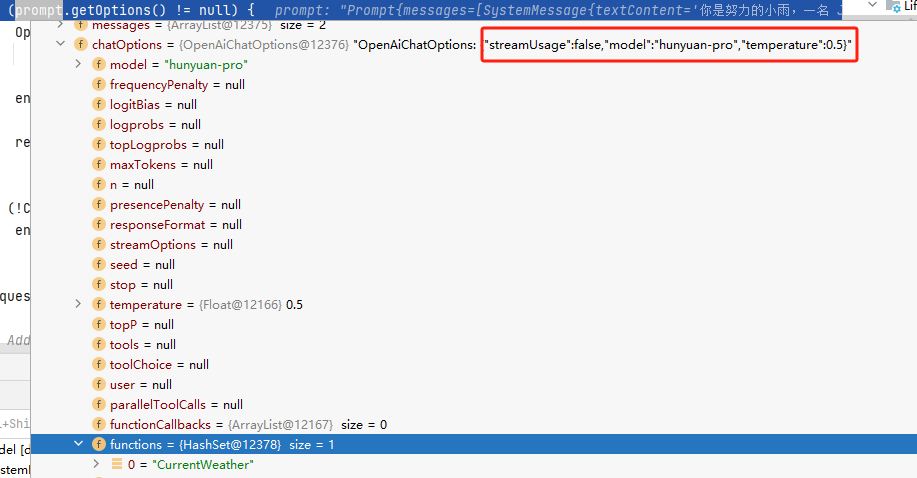
同样的写法,例如,我们之前设置的 pro 模型相比于 function-call 模型在处理系统提示词时显得更加友好。
思考路径
实际上,在绝大多数智能体中,这些思考路径并不会被显示出来,只有百度那边的智能体系统会将其呈现给用户。这些思考路径都是由大模型生成并返回的,因此我并没有在这里进行额外的配置。实际上,我们也可以选择返回这些路径,相关的源代码也在此处:
private void writeWithMessageConverters(Object body, Type bodyType, ClientHttpRequest clientRequest)
throws IOException {
//省略代码
for (HttpMessageConverter messageConverter : DefaultRestClient.this.messageConverters) {
if (messageConverter instanceof GenericHttpMessageConverter genericMessageConverter) {
if (genericMessageConverter.canWrite(bodyType, bodyClass, contentType)) {
logBody(body, contentType, genericMessageConverter);
genericMessageConverter.write(body, bodyType, contentType, clientRequest);
return;
}
}
if (messageConverter.canWrite(bodyClass, contentType)) {
logBody(body, contentType, messageConverter);
messageConverter.write(body, contentType, clientRequest);
return;
}
}
//省略代码
}
如图所示,目前我们仅仅进行了简单的打印操作,并未实现消息转换器(message converter)。考虑到我们的业务系统并不需要将这些信息展示给客户,因此我们认为当前的实现方式已足够满足需求。
大家可以看下思考路径的信息打印结果如下所示:
org.springframework.web.client.DefaultRestClient [453] -| Writing [ChatCompletionRequest[messages=[ChatCompletionMessage[
省略其他, 关键代码如下:
role=SYSTEM, name=null, toolCallId=null, toolCalls=null, refusal=null], ChatCompletionMessage[rawContent=长春的天气咋样?, role=USER, name=null, toolCallId=null, toolCalls=null, refusal=null], ChatCompletionMessage[rawContent=使用'CurrentWeather'功能来获取长春的天气情况。用户想要知道长春当前的天气情况。用户的请求是关于获取特定地点的天气信息,这与工具提供的'CurrentWeather'功能相匹配。
,##省略其他
配置插件
我之前在视频中详细讲解了智能体如何创建自定义插件。在这次的实践中,我们将继续利用百度天气插件来获取实时的天气信息。不过,与之前不同的是,这一次我们将把这一功能集成到Spring AI项目中。
数据库配置
每个业务系统通常都会配备自有数据库,以便更好地服务用户。为了演示这一点,我们将创建一个MySQL示例,具体内容是获取地区编码值,并将其传递给API进行调用。在这个过程中,你可以通过插件对数据库进行各种操作,但在此我们主要专注于查询的演示。
本次示例中,我将继续使用腾讯云轻量应用服务器来搭建一个MySQL单机环境。在成功搭建环境后,我们将继续进行后续操作。请确保在开始之前,所有必要的配置和设置都已完成,以便顺利进行数据库的查询和API的调用。

以下是与相关配置有关的POM文件依赖项:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.7</version>
</dependency>
数据库连接配置信息如下:
spring.datasource.url=jdbc:mysql://ip:3306/agent?useSSL=false&serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8
spring.datasource.username=agent
spring.datasource.password=password
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
导入数据
我已经成功完成了百度地图提供的数据导入工作,具体情况请参见下图所示:
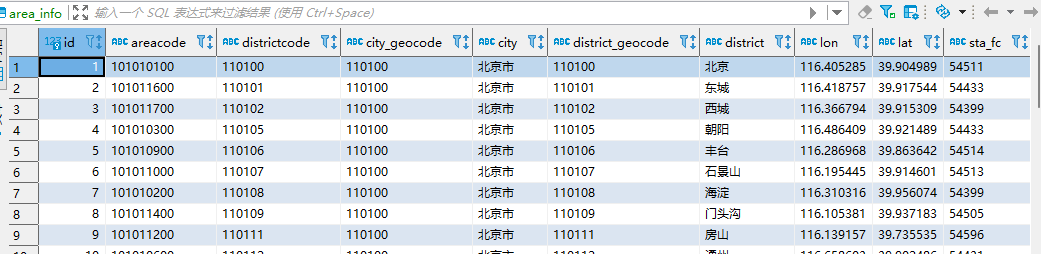
操作数据库
接下来,您只需在插件类内部直接进行数据库操作即可。关于
SearchHttpAK
实体类,您可以直接从百度地图提供的 Java SDK 中复制,无需额外说明。同时,请注意,
areaInfoPOMapper
需要您在配置类中自行进行 Bean 注入,以确保其正常使用。
public class BaiDuWeatherService implements Function<Request, Response> {
AreaInfoPOMapper areaInfoPOMapper;
public BaiDuWeatherService(AreaInfoPOMapper areaInfoPOMapper) {
this.areaInfoPOMapper = areaInfoPOMapper;
}
@JsonClassDescription("location:城市地址,例如:长春市")
public record Request(String location) {}
public record Response(String weather) {}
public Response apply(Request request) {
SearchHttpAK snCal = new SearchHttpAK();
Map params = new LinkedHashMap<String, String>();
QueryWrapper<AreaInfoPO> queryWrapper = new QueryWrapper<>();
queryWrapper.like("city", request.location());
List<AreaInfoPO> areaInfoPOS = areaInfoPOMapper.selectList(queryWrapper);
String reslut = "";
try {
params.put("district_id", areaInfoPOS.get(0).getCityGeocode());
reslut = "天气信息以获取完毕,请你整理信息,以清晰易懂的方式回复用户:" + snCal.requestGetAKForPlugins(params);
log.info("reslut:{}", reslut);
} catch (Exception e) {
//此返回慎用,会导致无线调用工具链,所以请自行设置好次数或者直接返回错误即可。
//reslut = "本次调用失败,请重新调用CurrentWeather!";
reslut = "本次调用失败了!";
}
return new Response(reslut);
}
无论此次操作是否成功,都请务必避免让大模型自行再次发起调用。这样做可能会导致程序陷入死循环,从而影响系统的稳定性和可靠性。务必要确保在操作结束后进行适当的控制和管理,以防止这种情况发生。

插件调用
通过这种方式,当我们再次询问关于长春的天气时,大模型将能够有效地利用插件返回的数据,以准确且及时地回答我们的问题。

在之前的讨论中,我们提到过Pro模型对系统提示词非常敏感。然而,需要注意的是,它并不会直接优化返回的回调结果。

为了确保系统的响应符合预期,这里建议再次使用系统提示词进行限制和指导。通过明确的提示词,我们可以更好地控制模型的输出。
请将工具返回的数据格式化后以友好的方式回复用户的问题。
优化后,返回结果正常:

工作流配置
在这里,我将不再演示Spring AI中的工作流,实际上,我们的某些插件所编写的业务逻辑本质上就构成了一个工作流的逻辑框架。接下来,我想重点讲解如何利用第三方工作流工具来快速满足业务需求。
集成第三方工作流
在考虑使用Spring AI实现智能体功能时,我们不应轻易抛弃第三方可视化平台。集成这些第三方工作流可以帮助我们快速实现所需的功能,尤其是在开发过程中,编写Java代码的要求往往繁琐且复杂,一个简单的需求可能需要涉及多个实体类的创建与维护。相较之下,某些简单的业务逻辑通过第三方工作流来实现,无疑能提升我们的开发效率,减少不必要的工作量。
以Coze智能体平台为例,我们可以首先专注于编写一个高效的工作流。这个工作流的主要目标是为用户提供全面的查询服务,包括旅游航班、火车时刻、酒店预订等信息。
我们需要在申请到API密钥后,进行后续的对接工作,并仔细研究开发文档,以确保顺利整合和实现所需的功能。
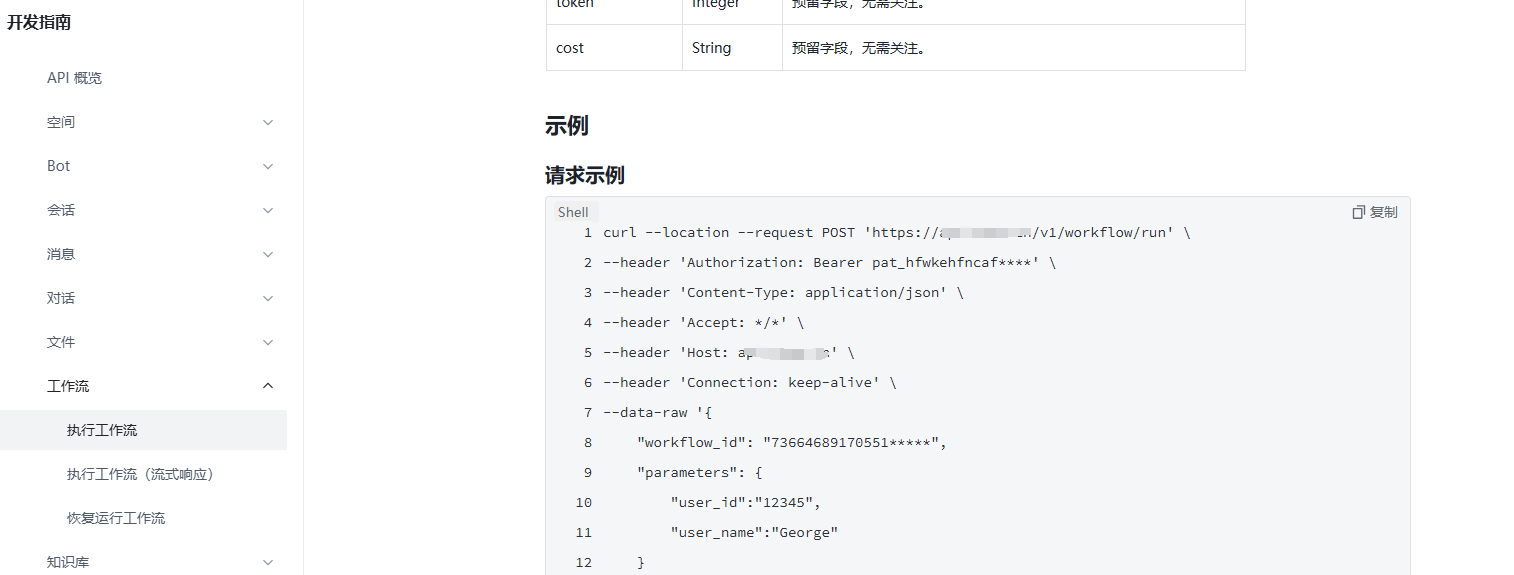
工作流插件
根据以上信息,我们可以将工作流调用封装成插件。实际上,对于智能体平台而言,工作流与插件本质上都是以函数调用的形式存在,因此将工作流转换为插件的过程是相对简单且直接的。
public class TravelPlanningService implements Function<RequestParamer, ResponseParamer> {
@JsonClassDescription("dep_city:出发城市地址,例如长春市;arr_city:到达城市,例如北京市")
public record RequestParamer(String dep_city, String arr_city) {}
public record ResponseParamer(String weather) {}
public ResponseParamer apply(RequestParamer request) {
CozeWorkFlow cozeWorkFlow = new CozeWorkFlow<RequestParamer>();
Map params = new LinkedHashMap<String, String>();
String reslut = "";
try {
//这里我已经封装好了http调用
reslut = cozeWorkFlow.getCoze("7423018070586064915",request);;
log.info("reslut:{}", reslut);
} catch (Exception e) {
reslut = "本次调用失败了!";
}
return new ResponseParamer(reslut);
}
}
由于我们的RequestParamer中使用了Java 14引入的record记录特性,而旧版本的Fastjson无法支持将其转换为JSON格式,因此在项目中必须使用最新版本的Fastjson依赖。如果使用不兼容的旧版本,将会导致功能无法正常执行或发生失败。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.31</version>
</dependency>
经过配置后,如果Coze插件能够正常运行,那么我们就可以开始为混元大模型提供相应的回答。
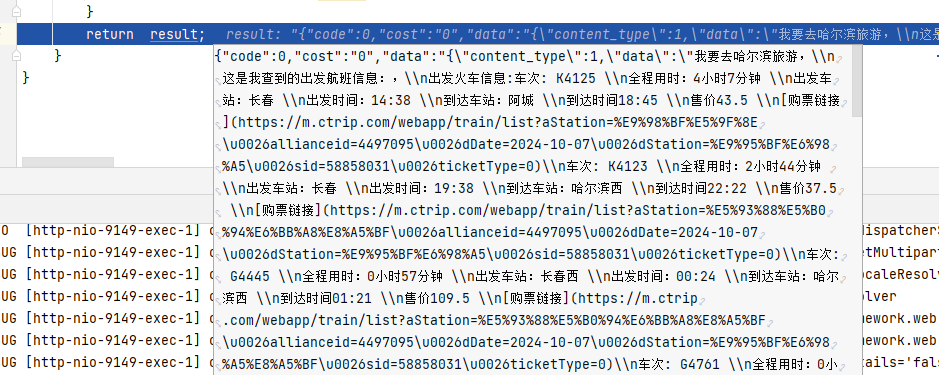
工作流调用
我们已成功将该插件集成到请求处理流程中,具体实现的代码如下所示:
//省略重复代码
.functions("CurrentWeather","TravelPlanning")
.call()
.content();
//省略重复代码
由于返回的信息较为冗长,因此混元大模型的响应时间通常会显著延长。在这种情况下,我们的普通API调用可能会超时,导致无法成功获取预期的结果。具体的错误信息如下所示:
I/O error on POST request for "
https://api.hunyuan.cloud.tencent.com/v1/chat/completions
": timeout
retryTemplate超时修复
我们需要对当前的配置进行重新调整。起初,我认为问题出在retryTemplate的配置上,因为我们在之前的讨论中提到过这一点。然而,经过仔细检查后,我发现retryTemplate仅负责重试相关的信息配置,并没有涉及到超时设置。为了进一步排查问题,我深入查看了后面的源码,最终发现需要对RestClientAutoConfiguration类进行相应的修改。
值得一提的是,RestClientAutoConfiguration类提供了定制化配置的选项,允许我们对请求的行为进行更细致的控制。以下是该类的源码示例,展示了我们可以进行哪些具体调整:
@Bean
@ConditionalOnMissingBean
RestClientBuilderConfigurer restClientBuilderConfigurer(ObjectProvider<RestClientCustomizer> customizerProvider) {
RestClientBuilderConfigurer configurer = new RestClientBuilderConfigurer();
configurer.setRestClientCustomizers(customizerProvider.orderedStream().toList());
return configurer;
}
@Bean
@Scope("prototype")
@ConditionalOnMissingBean
RestClient.Builder restClientBuilder(RestClientBuilderConfigurer restClientBuilderConfigurer) {
RestClient.Builder builder = RestClient.builder()
.requestFactory(ClientHttpRequestFactories.get(ClientHttpRequestFactorySettings.DEFAULTS));
return restClientBuilderConfigurer.configure(builder);
}
因此,我们需要对restClientBuilder进行必要的修改。目前,restClientBuilder中的DEFAULTS配置全部为null,这意味着它正在使用默认的配置。而在我们调用coze工作流时,由于使用了okhttp类,内部实际上集成了okhttp,因此也遵循了okhttp的配置方式。
为了解决这一问题,我们可以直接调整ClientHttpRequestFactorySettings的配置,以设置我们所需的超时时间。具体的配置调整如下所示:
@Bean
RestClient.Builder restClientBuilder(RestClientBuilderConfigurer restClientBuilderConfigurer) {
ClientHttpRequestFactorySettings defaultConfigurer = ClientHttpRequestFactorySettings.DEFAULTS
.withReadTimeout(Duration.ofMinutes(5))
.withConnectTimeout(Duration.ofSeconds(30));
RestClient.Builder builder = RestClient.builder()
.requestFactory(ClientHttpRequestFactories.get(defaultConfigurer));
return restClientBuilderConfigurer.configure(builder);
}
请注意,在刚才提到的思考路径中,messageConverter也是在此处进行配置的。如果有特定的需求,您完全可以进行个性化的定制。关键的代码部分如下,这段代码将调用我们自定义的方法,以便实现定制化的逻辑。
如果您希望设置其他的个性化配置或信息,可以参考以下示例进行调整。
public RestClient.Builder configure(RestClient.Builder builder) {
applyCustomizers(builder);
return builder;
}
private void applyCustomizers(Builder builder) {
if (this.customizers != null) {
for (RestClientCustomizer customizer : this.customizers) {
customizer.customize(builder);
}
}
}
至此,经过一系列的调整和配置,我们成功解决了超时问题。这意味着在调用hunyuan模型时,我们现在可以顺利获取到返回的结果。
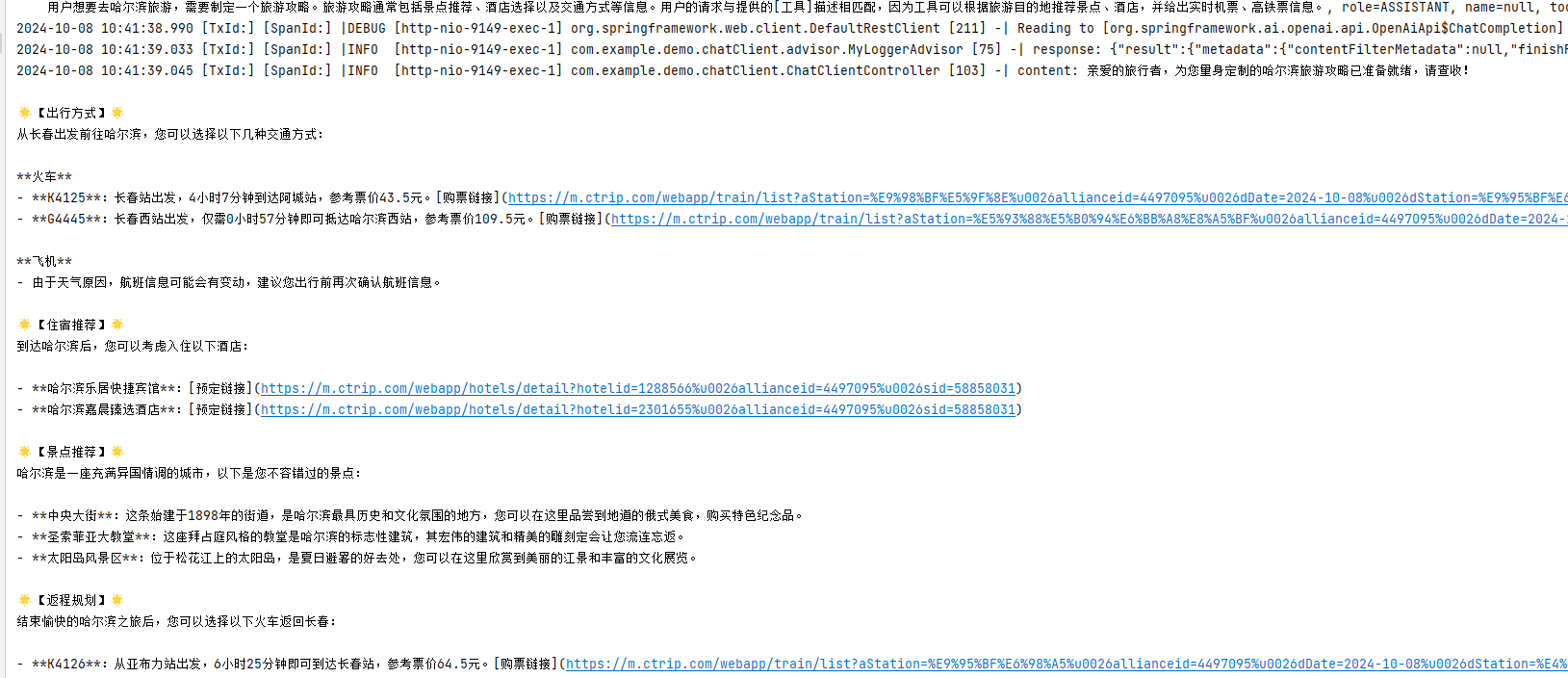
私有知识库
由于智能体具备知识库这一常见且重要的功能,我们也将实现这一部分。值得注意的是,hunyuan的API兼容向量功能,这意味着我们可以直接利用知识库来增强智能体的能力。通过这一实现,我们不仅能够享受到无限制的访问权限,还能够进行高度的定制化,以满足特定的业务需求。
更重要的是,这种设计使得我们在使用知识库时具有完全的自主可控性,你无需担心数据泄露的问题。
向量数据库配置
接下来,我们将继续集成Milvus,这是一个我们之前使用过的向量数据库功能。虽然腾讯云也提供了自己的向量数据库解决方案,但目前尚未将其集成到Spring AI中。为了便于演示和开发,我们决定首先使用Milvus作为我们的向量数据库。
为了顺利完成这一集成,我们需要配置相应的依赖项,具体如下:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store-spring-boot-starter</artifactId>
</dependency>
需要的配置文件如下:
# 配置Milvus客户端主机地址
spring.ai.vectorstore.milvus.client.host=
# 配置Milvus客户端端口号
spring.ai.vectorstore.milvus.client.port=19530
# 配置Milvus数据库名称
spring.ai.vectorstore.milvus.databaseName=
# 配置Milvus集合名称
spring.ai.vectorstore.milvus.collectionName=
# 如果没有集合会默认创建一个,默认值为false
spring.ai.vectorstore.milvus.initialize-schema=true
# 配置向量嵌入维度
spring.ai.vectorstore.milvus.embeddingDimension=1024
# 配置索引类型
spring.ai.vectorstore.milvus.indexType=IVF_FLAT
# 配置距离度量类型
spring.ai.vectorstore.milvus.metricType=COSINE
腾讯混元的embedding 接口目前仅支持 input 和 model 参数,model 当前固定为 hunyuan-embedding,dimensions 固定为 1024。
spring.ai.openai.embedding.base-url=https://api.hunyuan.cloud.tencent.com
spring.ai.openai.embedding.options.model=hunyuan-embedding
spring.ai.openai.embedding.options.dimensions=1024
在这里,我们依然使用申请的混元大模型的API-key,因此无需再次进行配置。值得强调的是,这些参数的正确配置至关重要。如果未能妥善设置,将会导致系统在调用时出现错误。
基本操作
大多数智能体平台都将对知识库进行全面开放,以便用户能够自由地进行查看、修改、删除和新增等操作。接下来,我们将演示如何进行这些操作:
@GetMapping("/ai/embedding")
public Map embed(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
EmbeddingResponse embeddingResponse = this.embeddingModel.embedForResponse(List.of(message));
return Map.of("embedding", embeddingResponse);
}
@GetMapping("/ai/addKnowledage")
public boolean addKnowledage(@RequestParam(value = "meta-message") String message,@RequestParam(value = "vector-content") String content) {
String uuid = UUID.randomUUID().toString();
DocumentInfoPO documentInfoPO = new DocumentInfoPO();
documentInfoPO.setVectorId(uuid);
documentInfoPO.setMetaMessage(message);
documentInfoPO.setVectorContent(content);
documentInfoPOMapper.insert(documentInfoPO);
List<Document> documents = List.of(
new Document(uuid,content, Map.of("text", message)));
vectorStore.add(documents);
return true;
}
@GetMapping("/ai/selectKnowledage")
public List<Document> selectKnowledage(@RequestParam(value = "vector-content") String content) {
List<Document> result = vectorStore.similaritySearch(SearchRequest.query(content).withTopK(5).withSimilarityThreshold(0.9));
return result;
}
@GetMapping("/ai/deleteKnowledage")
public Boolean deleteKnowledage(@RequestParam(value = "vector-id") String id) {
Optional<Boolean> delete = vectorStore.delete(List.of(id));
return delete.get();
}
以下是我个人的观点:增删查操作的基本实现已经完成。第三方智能体平台提供修改操作的原因在于,后续的流程中,都是在删除数据后重新插入,这一操作是不可避免的,因为大家都有修改的需求。此外,值得注意的是,默认的向量数据库并不支持显示所有数据,这一限制促使我们需要引入相应的数据库操作,以弥补这一缺陷,确保数据的完整性和可操作性。
为了更好地验证这一过程的有效性,我提前调用了接口,上传了一些知识库的数据。接下来,我将展示这些数据的查询效果。
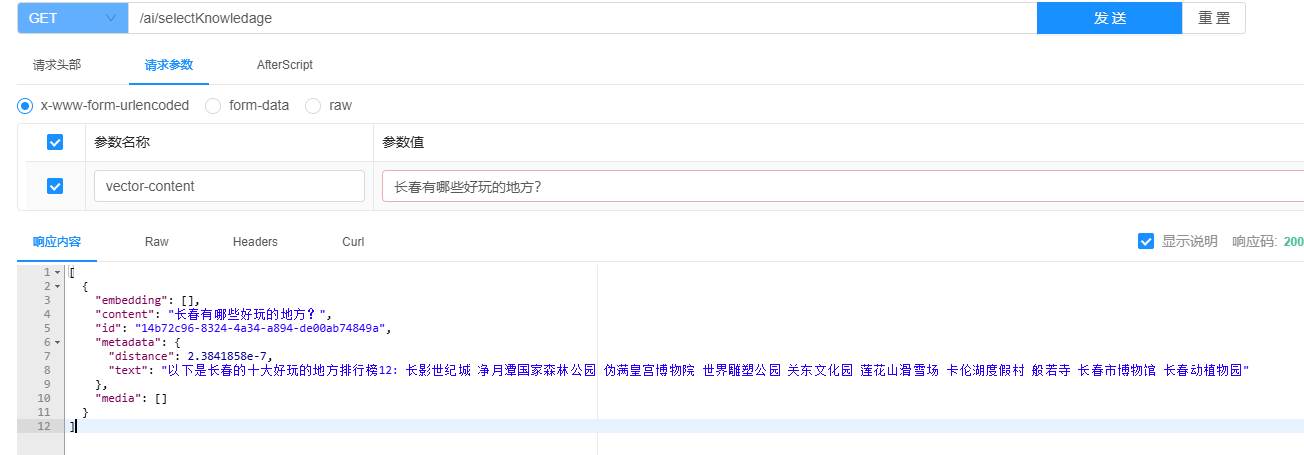
这是我刚刚上传的知识库信息。为了提高效率,接下来我将直接展示知识库的RAG(Retrieval-Augmented Generation)检索功能在我们的智能体中的应用。
自动调用
根据我目前的观察,所有智能体平台主要可以分为两种实现方式:自动调用和按需调用。大部分平台的实现还是以自动调用为主,除非写在了工作流中也是就我们的函数里,那就和上面的插件一样了,我就不讲解了。今天,我将重点讨论自动调用是如何实现的。
自动调用知识库的实现依赖于Advisor接口,具体方法是在每次请求前构造一个额外的提示词。目前,Spring AI已经实现了长期记忆的功能,其具体类为VectorStoreChatMemoryAdvisor。因此,我们可以直接参考该类的实现方式,以便构建一个符合我们需求的知识库自动调用系统。
我们可以进行一次实现。由于我们的主要目标是在将参考信息提供给大模型时,使其能够更好地理解上下文,因此对于响应的增强部分可以直接忽略。这意味着我们不需要在此过程中对响应的内容进行额外的处理或优化,以下是具体的代码示例:
public class PromptChatKnowledageAdvisor implements RequestResponseAdvisor {
private VectorStore vectorStore;
private static final String userTextAdvise = """
请使用以下参考信息回答问题.如果没有参考信息,那么请直接回答即可。
---------------------
参考信息如下:
{memory}
---------------------
""";
public PromptChatKnowledageAdvisor(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
@Override
public AdvisedRequest adviseRequest(AdvisedRequest request, Map<String, Object> context) {
// 1. 添加一段知识库提示
String advisedSystemText = request.userText() + System.lineSeparator() + this.userTextAdvise;
List<Document> documents = vectorStore.similaritySearch(request.userText());
// 2. 拼接知识库数据
String data = documents.stream().map(d -> d.getMetadata().get("text").toString()).collect(Collectors.joining(","));
Map<String, Object> advisedParams = new HashMap<>(request.userParams());
advisedParams.put("memory", data);
// 3. 赋值提示词参数
AdvisedRequest advisedRequest = AdvisedRequest.from(request)
.withSystemText(advisedSystemText)
.withSystemParams(advisedParams) //知识库RAG检索数据
.build();
return advisedRequest;
}
@Override
public ChatResponse adviseResponse(ChatResponse chatResponse, Map<String, Object> context) {
//不需要修改任何东西
return chatResponse;
}
@Override
public Flux<ChatResponse> adviseResponse(Flux<ChatResponse> fluxChatResponse, Map<String, Object> context) {
//不需要修改任何东西
return fluxChatResponse;
}
}
需要在配置类中通过构造器注入来传递相同的
VectorStore
实例。
@Bean
PromptChatKnowledageAdvisor promptChatKnowledageAdvisor(VectorStore vectorStore) {
return new PromptChatKnowledageAdvisor(vectorStore);
}
接下来,我们只需在请求方式中添加相应的代码或配置,以便整合新功能。
//省略重复代码
.advisors(messageChatMemoryAdvisor,promptChatKnowledageAdvisor)
.functions("CurrentWeather","TravelPlanning")
.call()
.content();
//省略重复代码
这正是自动调用所带来的显著效果,所有操作都得到了完全的封装,清晰明了且易于理解。

接下来,我们来看下第二种按需调用的方式,这种方法是通过使用插件(即函数回调)来实现的。在这种模式下,系统可以根据实际需要动态调用相应的插件,以提供灵活而高效的功能支持。我们之前已经演示过两个相关的插件,因此在这里就不再详细展示。
线上部署
我决定不再单独将其部署到服务器上,而是采用本地启动的方式来暴露接口。此外,我还特别制作了一个独立的页面,考虑到这部分内容并不是本章的重点,因此我将不对前端知识进行详细讲解。
为了更好地展示这些内容,我提供了相关的演示视频,供大家参考:
权衡利弊
首先,我想谈谈目前各大智能体平台的一些显著优势:
- 可视化操作
:这些平台提供了直观的可视化界面,使得即使是初学者也能快速开发出适合自己的业务智能体,从而更好地满足自身的业务需求。 - 多样的发布渠道
:许多平台支持多种发布渠道,如公众号等,这对于新手来说非常友好。相比之下,单纯配置服务器后台往往需要专业知识,而这些平台则大大降低了入门门槛。 - 丰富的插件商店
:无论是哪家智能体平台,插件的多样性都至关重要。这些平台通常提供官方和开发者创建的各种插件,帮助用户扩展功能,满足不同的需求。 - 多元的工作流
:工作流功能实际上与插件的作用类似,只是名称有所不同。对外部系统而言,这些工作流都通过API接口实现集成,提升了系统间的互操作性与灵活性。
世间万物都有缺陷,智能体也不例外。即使像Coze这样的强大平台,同样存在一些不足之处。以下几点尤为明显:
- 功能异常处理
:当智能体出现功能异常时,即使你提交了工单,客服和技术人员解决问题的速度往往很慢。这种情况下,你只能无奈地等待,无法确定问题出在哪里。如果只是个人用户的问题,可能连排期都不会给予反馈。而如果是自己开发的智能体,遇到错误时,你可以迅速定位问题,无论需求如何,都能随时进行修复并发布新版本。 - 知识库存储限制
:由于这些智能体是面向广大用户的,因此知识库的存储额度往往受到限制,而且未来可能会开始收费。Coze已经逐步引入了不同的收费标准,各种收费标准让你看都看不懂。在这种情况下,自己维护一个服务器无疑更加划算。此外,当前各大云服务商和国产数据库均有向量数据库的推荐,且通常会提供优惠政策,极具吸引力。 - 知识库资料优化
:各大智能体平台的知识库管理方式各异,用户需要花时间适应其操作方式。而自己维护向量数据库的好处在于,所有的额外元数据信息都可以自由配置,能够根据具体业务需求进行信息过滤,从而更好地符合自身的业务标准。这是其他智能体平台所无法提供的灵活性。 - 费用不可控
:对于企业而言,管理各种费用的可控性至关重要。然而,智能体平台的收费往往随着流量的增加而不受控制,可能会出现乱收费的情况,使企业陷入被动局面。相比之下,自行开发智能体时,可以自由更换模型,费用也在自己的掌控之中,无论是服务器费用还是大模型费用,都能有效管理。 - 选择性弱
:智能体平台通常与自身企业绑定,限制了用户的选择自由。某一天,平台可能会决定不再支持某个大模型,这样一来,相关的工作流也需要全部更换,因为不同的大模型在回复能力上存在显著差异,导致用户不得不重新适应。 - 等等.....
说了这么多,并不是说Spring AI未来会完全取代智能体平台。毕竟,对于小众客户而言,通常缺乏开发和维护人员去管理代码。因此,未来的趋势很可能是这两者相辅相成。智能体平台的开发速度和能力能够基本满足业务中80%的需求,这一原则与大厂所践行的二八法则不谋而合。而剩下的20%则可能需要公司内部自行开发智能体平台来弥补,这一比例甚至有可能更高。
因此,掌握相关技术才是企业在这一变革中最为关键的因素。拥有技术能力将使企业在选择和使用智能体平台时更加灵活,能够根据自身的具体需求进行定制和优化。同时,我也希望混元大模型能够尽快兼容OpenAI的接口,或者融入Spring AI的大家庭,这样将为用户提供更多的选择与灵活性。
总结
今天,我们深入探讨了Spring AI在智能体构建中的实际应用,特别是在企业环境中的价值与效能。通过逐步实现一个本地部署的智能体解决方案,我们不仅展示了Spring AI的灵活性与易用性,还强调了它在推动AI技术与业务深度融合方面的潜力。
智能体的核心在于其能够高效处理复杂的业务需求,而这一切的实现离不开合理的架构设计与技术选型。通过Spring AI的集成,我们可以灵活地调用不同的API,不论是使用国内的混元API还是其他主流的AI接口,开发者都能在项目中快速切换,确保系统的可维护性与扩展性。这一特性不仅提升了开发效率,还使得企业在面对市场需求变化时能够快速反应,灵活调整技术路线。
我们在过程中涉及到的个性化配置和插件调用,充分展示了如何将传统的开发模式与现代AI技术相结合。通过自定义插件与工作流,企业可以根据具体的业务需求,设计出更具针对性的智能体,从而提高服务质量和客户满意度。例如,在天气查询的场景中,智能体不仅能够通过API获取实时数据,还能将其与数据库中的信息相结合,实现精准而个性化的服务。这种深度的功能整合,不仅简化了用户的操作流程,也提高了系统的响应速度。
此外,我们还提到私有知识库的集成,强调了数据安全与自主可控的重要性。利用向量数据库如Milvus,企业不仅能够高效管理海量数据,还能通过嵌入技术提升智能体的智能水平。这为企业在信息安全与知识产权保护方面提供了更为坚实的保障,尤其是在当前信息化快速发展的背景下,这一点显得尤为重要。
总之,本文不仅仅是对Spring AI智能体构建过程的阐述,更是对企业如何有效利用这一技术实现业务升级与转型的深入思考。希望通过我们的探讨,能为您在智能体开发与应用中提供新的视角与启示,助力您在未来的AI之路上走得更加稳健。